こんにちは、もるふぉ(@morphox_ai)です。
国産LLM、正直ナメてました。
「頑張ってるのはわかるけど、世界のLLMには勝てないよね」——そう思っていたエンジニア、自分も含めてけっこういると思います。
でも、2026年4月3日に公開されたばかりの「LLM-jp-4」を実際にHuggingFace Spaceで動かしてみて、その認識がひっくり返りました。
8Bモデルが日本語MT-Benchで7.54。
GPT-4oの7.29を上回っています。
これ、ちょっと事件じゃないですか。
LLM-jp-4とは?国立情報学研究所が公開した国産LLMの概要

LLM-jp-4は、国立情報学研究所(NII)が主導する「LLM-jp」プロジェクトから生まれた大規模言語モデルです。
2026年4月3日にApache 2.0ライセンスで公開されました。
つまり、商用利用もファインチューニングも自由にできます。
ライセンス費用ゼロ、法的制約ほぼなし。それだけでも「え、使える」となりますよね。
なぜNIIがLLMを作るのか
「国の研究機関がなぜLLMを?」と思うかもしれません。
LLM-jpプロジェクトには2,600名以上の研究者・エンジニアが参加しています。
目的はシンプルで、日本語に強いオープンソースLLMを作ること。
OpenAIやGoogleに依存せず、日本語処理に最適化されたモデルを、誰でも使える形で提供する。
国として当然やるべきことをやっている、という印象です。
LLM-jp-3からの進化:何が変わったか
前世代のLLM-jp-3と比べて、変化は劇的です。
まず学習データ量。
事前学習コーパスは約19.5兆トークンが用意され、実際の学習には約11.7兆トークン(事前学習10.5兆 + 中間学習1.2兆)が使われています。
日本語だけで約7,000億トークン、英語が約17.8兆トークン。
中国語・韓国語が約8,500億トークン、プログラムコードが約2,000億トークンという構成です。
「19.5兆トークン」と言われてもピンとこないと思いますが、たとえば日本語Wikipediaの全記事を何千回も読み込んだような規模です。
そしてポストトレーニングにはSFT(教師あり微調整)とDPO(直接選好最適化)を採用。
強化学習(RLHF)を使わずにこの性能を出しているのは注目ポイントですね。
「ここまでやってるなら、スコアも本物かも」——次のセクションでモデルの中身を確認していきます。
LLM-jp-4の2モデルを比較する
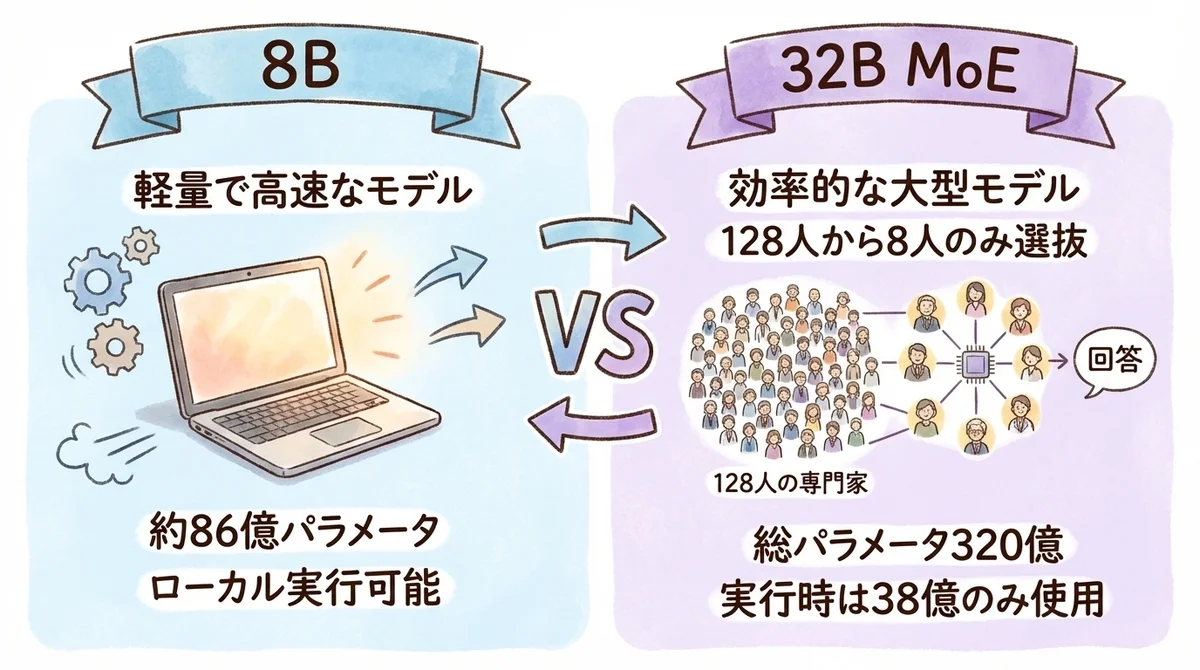
今回公開されたのは2つのモデルです。
それぞれ全く異なるアーキテクチャで、用途も違います。
8Bモデル:軽量・高速・ローカル実行可能
正式名称はllm-jp-4-8b-thinking。
パラメータ数は8,590,200,832(約86億)。
Llama 2ベースのアーキテクチャで、32レイヤー、Hidden Size 4,096、Attention Heads 32という構成です。
コンテキスト長は65,536トークン。
これがどれくらい長いかというと、一般的な技術ドキュメント数十本分をまるごと入力できるレベルです。
「ドキュメント全部食わせてから質問する」ようなユースケースが普通に動きます。
データ型はBF16で、VRAM 16GB程度のGPUがあればローカルで動かせます。
「thinking」という名前の通り、思考プロセスを分離して出力するthinkingモデルになっています。
32B-A3B(MoE)モデル:3.8Bだけ動かして商用超えの仕組み
もう1つがllm-jp-4-32b-a3b。
こちらはMoE(Mixture of Experts)アーキテクチャを採用しています。
MoEって何?という方向けに一言で言うと、「128人の専門家がいるけど、毎回8人だけ呼んで答える」仕組みです。
全員に聞いたら時間もコストもかかる。でも、その質問に最も詳しい8人だけが答えれば、品質は保ちつつコストを大幅に削減できる——そういう設計です。
総パラメータ数は約320億(32B)ですが、推論時にアクティブになるのは約38億(3.8B)だけ。
モデル内部に128個の「エキスパート」(専門家ネットワーク)が存在し、入力トークンに応じて最適な8個だけが選ばれて動作します。
Qwen3 MoEベースのアーキテクチャです。
2モデルをざっくり比較するとこうなります。
つまり、32Bの知識を持ちながら、実行コストは3.8B相当。
「安い計算コストで高いスコアを出せる」——この効率の良さが、商用モデルを超えるスコアを叩き出せた理由の1つです。
2モデルの設計がわかったところで、肝心のスコアを見ていきましょう。
ベンチマーク:GPT-4oとQwen3-8Bを本当に超えたのか
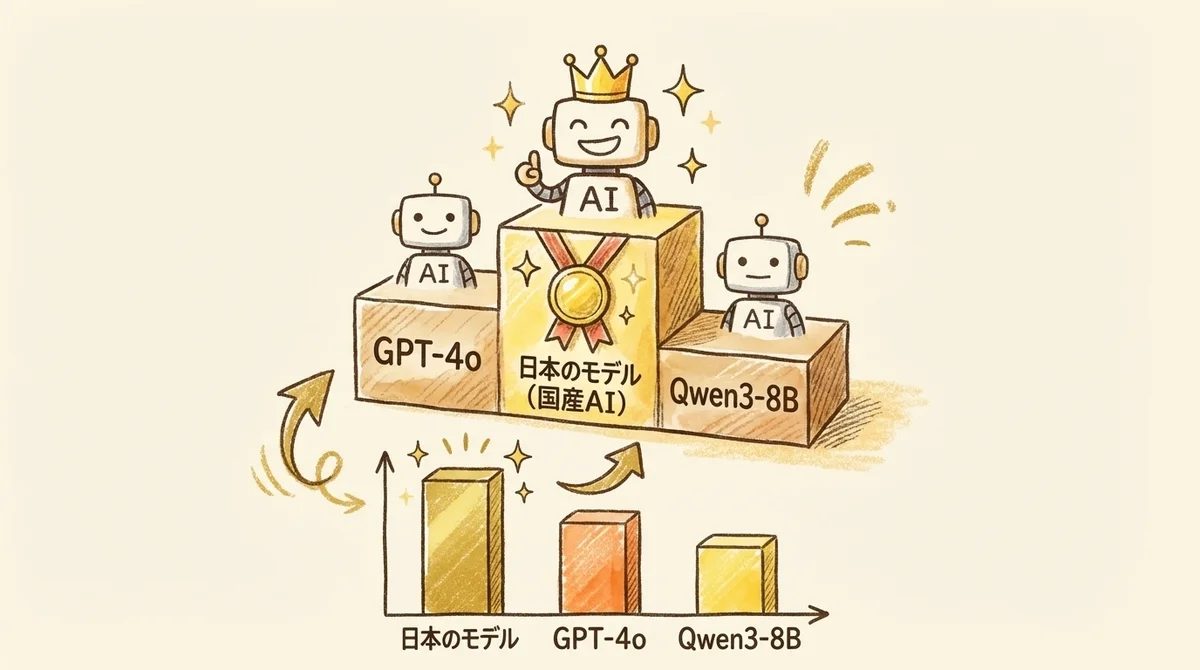
「国産LLMがGPT-4oを超えた」と聞くと、眉唾に感じるエンジニアも多いと思います。
自分もそうでした。
なので、数字をちゃんと見ていきます。
MT-Bench(日本語)スコアの読み方
日本語MT-Benchのスコアを並べます。
8Bモデル(reasoning_effort: medium)でGPT-4oを0.25ポイント上回り、Qwen3-8Bを0.40ポイント上回っています。
MoEの32B-A3Bモデルに至っては7.82。
英語でもGPT-4oを超えているのは正直驚きました。
数字の背景:評価データと条件を確認する
ただし、ベンチマークは条件次第で結果が変わります。
エンジニアとして冷静に見ておくべきポイントがいくつかあります。
MT-Benchは対話品質を測るベンチマークで、80問の多ターン対話をLLM(評価者モデル)が採点する形式です。
LLM-jp-4の評価ではgpt-5.4(2026年3月版)が評価者として使用されています。
つまり、「評価者LLMの好みに合う回答」が高スコアになりやすいという特性があります。
また、8BモデルのスコアはreasoningがMediumの場合のもの。
HighにすればさらにスコアUP、Lowなら下がるという調整が効く仕組みです。
とはいえ、8BクラスでGPT-4oを超えるスコアを出したこと自体が、国産LLMの大きなマイルストーンであることは間違いありません。
「数字はわかった。でも実際どうなの?」——そう思いますよね。
実際に動かしてみた話をします。
実際にデモを触ってみた(HuggingFace Space体験記)
数字だけ見ても実感が湧かないので、実際に動かしてみました。
デモURLと動かし方
HuggingFace Spaceに非公式デモが公開されています。
デモURL: https://huggingface.co/spaces/alfredplpl/unofficial-llm-jp-4-8b-thinking
ブラウザでアクセスするだけで、アカウント登録なしでも試せます。
テキストボックスにプロンプトを入力して送信するだけ。
インストール不要、登録不要、すぐうごかせます。
thinkingモデルなので、回答の前に「思考プロセス」が表示されるのが特徴です。
「国産LLMが世界で勝てる方法は?」と聞いてみた
せっかくの国産LLMなので、ちょっと意地悪な質問を投げてみました。
「国産LLMが世界で勝てる方法は?」
返ってきた回答に驚きました。
8Bモデルが、以下の4軸で整理された構造的な回答を返してきたんです。
- 技術面: Sparse MoE、RAG、マルチモーダル統合などの技術戦略
- データ面: 日本語コーパス強化、プライバシー保護データの提案
- エコシステム: オープンソースと商用のハイブリッド戦略
- ビジネス戦略: 具体的なアクションプラン(7B OSS化 → PoC契約 → 推論ASIC)
「8Bモデルがここまで構造的な回答を返せるのか」と、素直に感心しました。
「7B OSS化 → PoC契約 → 推論ASIC」というロードマップまで提案してくるあたり、単なるチャットボットではない深さを感じます。
実務的に言えば、この品質なら社内ナレッジの要約や企画書のたたき台作成に十分使えるレベルです。
Apache 2.0でファインチューニングも自由なので、「自社データで追加学習した8Bモデルを社内APIとして提供する」という運用が現実的に見えてきます。
thinkingモデルの思考プロセスを見てみる
thinkingモデルの面白いところは、回答に至るまでの思考プロセスが可視化される点です。
上記の質問でも、まず内部で「この質問の意図は何か」「どの軸で整理すべきか」といった思考ステップが表示され、その後に整理された回答が出力されました。
思考とコンテンツが分離されているので、「なぜこの回答になったのか」をトレースできます。
これはデバッグや品質検証の観点で非常にありがたい設計ですね。
「実際に動くのはわかった。じゃあ、どう使うか」——実践的な話に移ります。
LLM-jp-4を使うときの実践メモ
エンジニアとして実際に使う場面を想定した、実践的なメモをまとめます。
reasoning_effortの使い分け(low / medium / high)
LLM-jp-4のthinkingモデルにはreasoning_effortパラメータがあり、3段階で思考の深さを制御できます。
- low: 高速応答が欲しい場面。チャットボット、FAQ対応など
- medium: バランス型。MT-Benchで7.54を出したのはこの設定。一般的な用途ならこれで十分
- high: 最高精度が必要な場面。複雑な推論、コード生成、長文分析など
チャットテンプレートはOpenAI Harmony互換なので、既存のOpenAI API向けコードからの移行もスムーズです。
「GPT-4oと同じコードで差し替えられる」ということです。
用途に応じてlow/medium/highを切り替えることで、レイテンシとコストを最適化できるのは実用的ですね。
Apache 2.0ライセンス:商用利用・ファインチューニングは可能か
LLM-jp-4はApache 2.0ライセンスです。
これは非常に重要なポイントです。
- 商用利用: OK
- ファインチューニング: OK
- 再配布: OK(ライセンス表示が必要)
- 社内システムへの組み込み: OK
LlamaやGemmaのような独自ライセンスではなく、OSS界で最も自由度の高いライセンスの1つを選んでいます。
「ライセンス確認のためにリーガルに投げる必要がない」というのは、実務でモデルを採用する際の地味に大きなメリットです。
企業が業務システムに組み込む際の法的ハードルが極めて低い。
これだけでも、他のオープンソースLLMに対する大きなアドバンテージです。
ローカル実行するためのスペックと手順
8Bモデル(BF16)をローカルで動かす場合の目安です。
- GPU VRAM: 16GB以上(RTX 4090、A100など)
- 量子化(4bit): VRAM 8GB程度でも動作可能
- コンテキスト長: 最大65,536トークン(VRAM消費に注意)
HuggingFaceからモデルをダウンロードして、vLLMやllama.cppで動かすのが一般的なルートです。
公式cookbookも用意されています。
公式cookbook: https://github.com/llm-jp/llm-jp-4-cookbook
cookbookがあるのでゼロから手順を追う必要がなく、「コードをコピペして動かす」が最初のステップです。
トークナイザーはUnigram byte-fallbackモデル(llm-jp-tokenizer v4.0ベース)を採用。
日本語のトークン効率が良いので、同じコンテキスト長でもより多くの日本語テキストを処理できます。
「つまり、英語LLMより長い日本語ドキュメントを1リクエストで処理できる」——日本語ユースケースでは地味に効いてきます。
国産LLMの今後:LLM-jp-4は始まりに過ぎない

今回公開された8Bと32B-A3Bは、LLM-jp-4シリーズの先行モデルです。
本番はこれからです。
2026年度中に予定されている32B・332B-A31Bモデル
NIIは2026年度中に以下のモデルの公開を予定しています。
- LLM-jp-4 32B: フルサイズの32Bモデル(MoEではない Dense モデル)
- LLM-jp-4 332B-A31B: 総パラメータ332B、アクティブ31BのMoEモデル
- 軽量モデル: エッジデバイス向け
332B-A31Bが出てきたら、GPT-4oどころかClaude 3.5 Opusクラスとの比較も現実的になってきます。
「8BでGPT-4oを超えた」の次は「332BでClaude最上位に挑む」——このロードマップが本気なのが伝わってきます。
エンジニアとして注目すべき理由
自分がLLM-jp-4に注目する理由は3つあります。
1. Apache 2.0で制約がない
商用利用、ファインチューニング、再配布が自由。
社内LLMとして導入する際の法的リスクが最小限です。
2. 日本語特化のトークナイザー
英語中心のトークナイザーと比べて、日本語のトークン効率が良い。
同じコンテキスト長でより多くの日本語を処理できるのは、日本語ユースケースでは大きなメリットです。
3. MoEの実用性が証明された
3.8Bのアクティブパラメータで商用モデルを超えた。
これは推論コストの削減に直結します。
オンプレミスでLLMを運用する企業にとって、このコスト効率は魅力的です。
まとめ:LLM-jp-4はエンジニアの選択肢に入るか
結論から言うと、入ります。
LLM-jp-4は「国産LLMだから応援する」というレベルを超えて、実力でGPT-4oやQwen3-8Bと競合できるモデルになっています。
特に以下のユースケースでは、積極的に検討すべきだと思います。
- 社内LLM: Apache 2.0ライセンスで法的リスクが低い
- 日本語特化タスク: トークナイザーが日本語に最適化されている
- コスト重視の推論: MoEモデルで3.8Bアクティブパラメータの効率
- プロトタイピング: 8BモデルならローカルGPUで高速に検証可能
まずはHuggingFace Spaceのデモを触ってみてください。
アカウント登録なし、すぐ試せます。
「国産LLMって正直微妙だった」という認識が、きっと変わると思います。
2026年度中に公開予定の32Bモデル、332B-A31Bモデルも含めて、LLM-jpプロジェクトの動向は引き続きウォッチしていきます。
関連記事
- Qwen3.6-Plus vs Claude Opus 4.6|コスト5分の1以下のAIコーディングエージェントをエンジニアが正直レビュー(同日公開: LLM-jp-4と同じ週にAlibabaも注目モデルをリリース。オープンソースLLM比較として合わせて読むと理解が深まります)
- 8
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 5
- 1
-
- 2
- 0
-
AI脱社畜
- 3
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 5
- 0
-
ゆい@海外AI副業ラボ
- 5
- 0
-
プロンプト画伯
- 2
- 1
-
- 9
- 0
-
- 4
- 0
-
- 3
- 1
-
- 12
- 1
-
- 4
- 0
-
- 4
- 0
-
- 1
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 4
- 1
-
 AI集客@ルイ
AI集客@ルイ
- 2
- 0
-
- 8
- 0
-
- 2
- 0
-
- 1
- 1
-
- 3
- 0














AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます