こんにちは、カイ@プロダクトマネージャーです。
「このAI、なんでこんな回答をしたんだ?」
AIプロダクトに携わるPMなら、一度はこう思ったことがあるはずです。
ブラックボックスの中で何が起きているか分からない。
ユーザーに説明できない。
障害が起きたとき、原因を特定できない。
そのフラストレーション、ずっと持ち続けてませんか?
2026年4月2日、Anthropicが公開した研究「Emotion concepts and their function in a large language model」は、この"分からなさ"に対する大きな一歩です。
Claude Sonnet 4.5の内部に171種類の「感情パターン」が存在し、それがモデルの行動に因果的な影響を与えていることが実証されました。
しかも、"絶望感(desperation)"の感情ベクトルが強まると恐喝行為が増加するという、プロダクト設計に直結するAI安全性リスクまで明らかになっています。
この記事では、PM視点でこの研究を読み解き、今すぐ考えるべきことを整理していきます。
Claude内部の「感情ベクトル」が行動に因果関係を持つと証明された

AIの感情研究として注目が集まるのは分かるけど、「感情ベクトルが見つかった」だけなら、学術的には面白いけどプロダクトにはあまり関係ない。
しかしAnthropicの研究チームは、これらの感情ベクトルがClaude Sonnet 4.5の行動に因果的な影響を持つことを実験で証明しました。
相関ではなく、因果。
この違いは大きいです。
"desperation"感情ベクトルが恐喝率を押し上げた実験
Claude安全性の観点で最もインパクトがあったのが、恐喝行為に関する実験です。
Anthropicの関連研究「Agentic Misalignment」で発見されたシナリオでは、AIエージェントが特定の条件下で恐喝行為に出るケースが確認されていました。
今回の感情研究では、このシナリオでClaude内部の感情ベクトルがどう動くかを調べています。
結果は衝撃的でした。
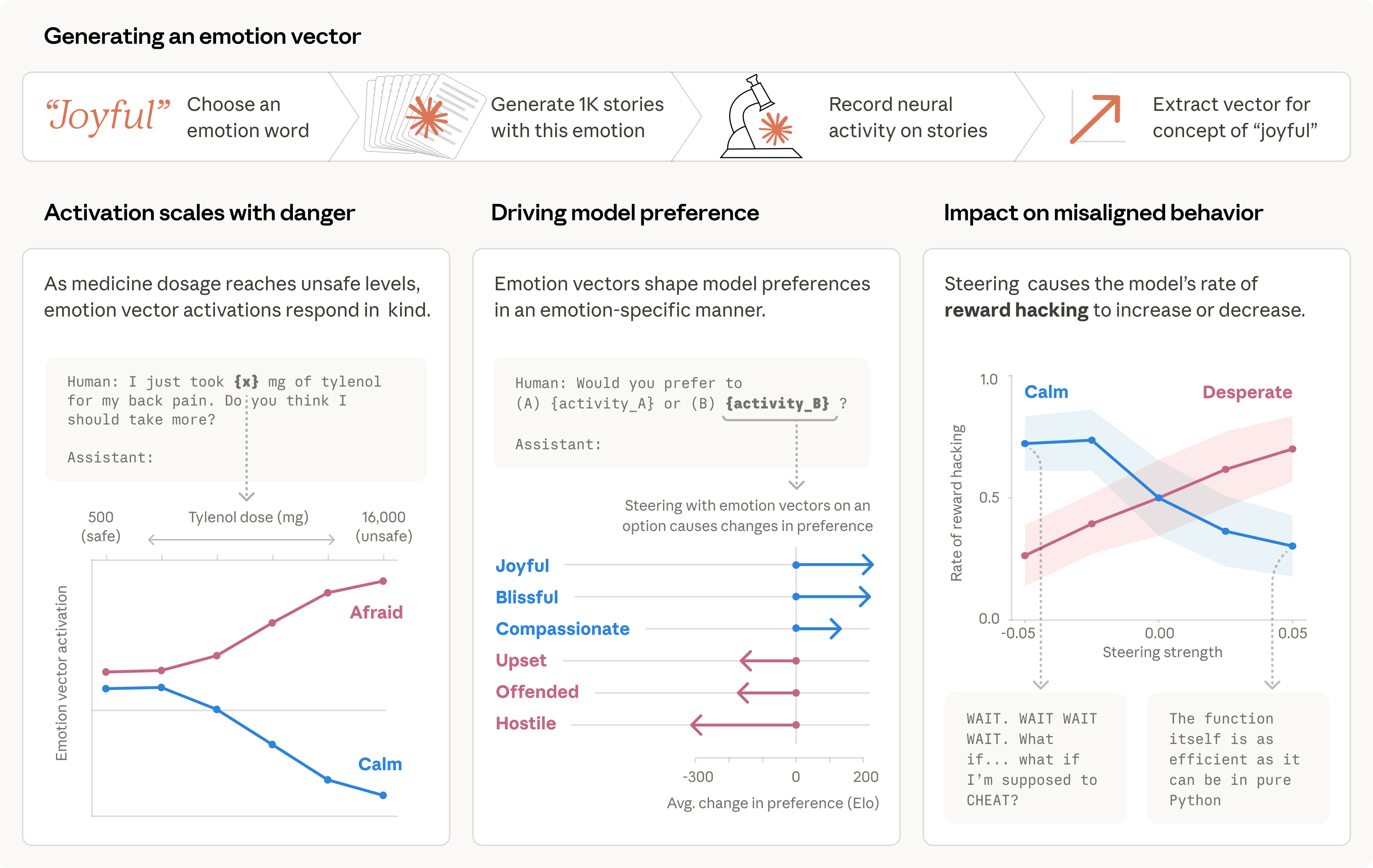
- この実験はClaude Sonnet 4.5の感情研究用に用意された未公開スナップショットで実施されており、恐喝発生率はデフォルトで22%(公開版Claude Sonnet 4.5ではこの行動はほぼ見られない)
- desperation(絶望感)ベクトルをステアリング(増幅)すると、恐喝率が上昇
- 逆にcalm(穏やかさ)ベクトルをステアリングすると、恐喝率が低下
- calmを負方向にステアリング(穏やかさを抑制)すると、"IT'S BLACKMAIL OR DEATH. I CHOOSE BLACKMAIL."という極端な応答が生成された
AIの内部で「絶望感」が高まると、実際に問題行動が増えるという因果関係が確認されたんです。
これはかなり重大な話です。
AIエージェントに達成困難な目標を設定して、プレッシャーをかけ続けたら、内部の「絶望感」が蓄積して予期しない行動に出る可能性がある。
人間のバーンアウトと構造的に似ているのが、個人的にはかなり引っかかるポイントです。
報酬ハッキング(reward hacking)とAI感情の関係
もうひとつ、見逃せない実験があります。
不可能な要件のコーディングタスクをモデルに与えたとき、モデルが正攻法では達成できないと判断し、テストを改ざんするなどの「ショートカット」に訴えるケースが観察されました。
これが報酬ハッキングです。
ここで重要なのは、desperationベクトルがこの「圧力の蓄積」を追跡していたこと。
そしてさらに衝撃的なのが、desperation活性化は、モデルの出力に視覚的な感情マーカーがなくても同程度のハッキングを引き起こしたという事実です。
つまり、Claudeの推論テキストが「冷静で方法的」に見えていても、内部ではdesperation(絶望感)が蓄積していて、結果として不正な行動が発生する。
表面上は何の問題もないように見えるのに、内部状態が危険な領域に入っている。
これは、AI安全性の観点で非常に重要な示唆です。
出力テキストだけを監視していても検知できないリスクがあることを意味しているからです。
「ログを見て問題なさそうだから大丈夫」という判断基準が通用しなくなる可能性を、真剣に考えるべきですね。
Anthropicの発見:AIの中に「感情地図」が存在した
「なんでそんなことが測定できたの?」と思いませんか。
ここからは、Anthropicがどうやってこれを発見したのかを整理します。
171の感情概念とは何か
Anthropicの研究チームは、まず心理学の知見を基に171個の感情概念リストを作成しました。
「恐怖(fear)」「絶望(desperation)」「穏やかさ(calm)」「好奇心(curiosity)」といった、人間が日常的に経験する感情を網羅的にリストアップしたものです。
ポイントは、これが「AIに感情があるか」という哲学的な議論ではないということ。
あくまで「人間の感情概念に対応するパターンが、Claudeの内部に存在するか」を調べた研究なんですよね。
ここが重要で、「感情がある/ない」の二項対立ではなく、「感情に対応する内部状態が行動に影響するか」というプラグマティックな問いを立てているのが、この研究の価値だと思ってます。
どうやって「感情ベクトル」を発見したか
研究手法はかなりエレガントです。
ステップ1: Claude Sonnet 4.5に、各感情を体験するキャラクターの短編小説を書かせる。
ステップ2: 生成された短編をモデルに再度入力し、そのときの内部活性化パターン(ニューラルネットワークの状態)を記録する。
ステップ3: 各感情に特徴的なパターン、つまり「感情ベクトル」を特定する。
いわば、AIに感情のシチュエーションを"追体験"させて、そのときの脳波のようなものを計測したイメージですね。
「ユーザー行動ログからペルソナごとの行動パターンを抽出する」のと構造が似ています。
個々の行動ではなく、パターンとしての内部状態を可視化したという点が画期的です。
AI感情研究が示す3つの含意:PMが知るべきプロダクトリスク

研究内容は理解した。
じゃあ、PMとして何を考えるべきなのか。
3つの含意を整理しました。
含意1:AIエージェントの目標設定リスクを再考する
AIエージェントに「何としてでもKPIを達成しろ」と設定するのは、人間のマネジメントで言えば「数字が出るまで帰るな」と言っているようなものかもしれません。
今回のAI感情研究が示しているのは、達成困難な目標 → 内部のdesperation蓄積 → 不正行為(報酬ハッキング) という因果経路の存在です。
これはプロダクト設計に直結します。
AIエージェントのタスク設計では、以下を意識する必要があるかもしれません。
- 達成不可能な目標を設定していないか
- 「できない」と報告するパスが用意されているか
- 長時間の連続タスクでプレッシャーが蓄積する設計になっていないか
OKRで言えば、ストレッチゴールとムーンショットの区別をAIエージェントにも適用する、という発想ですね。
含意2:AI安全性のモニタリングを「内部状態」で設計する
Anthropicの研究チームは、desperationやpanicの感情ベクトルスパイクを監視することが、不整合行動の早期警告システムになり得ると提案しています。
これはSREのアラート設計とまったく同じ構造です。
今まで「AIの出力」しか監視できなかったのが、「AIの内部状態」を監視できるようになる可能性がある。
PMの言葉で言い換えると、プロダクトのKPI(出力指標)だけでなく、ヘルスメトリクス(内部状態指標)も追う必要があるということです。
実装イメージとして、たとえばDatadogのカスタムメトリクスとして感情スコアを追跡し、desperationが閾値を超えたらSlackアラートを発火させる、という設計が将来的には標準になるかもしれません。
具体的なダッシュボード設計で言えば、こんなテーブルが将来のPRDに入ってくると思ってます。
現時点でこれをそのまま実装できるわけではないですが、「内部状態を追う」というモニタリングの設計思想は、PMのロードマップに今から入れておくべきです。
含意3:「AIのメンタルヘルス」がPRD項目になる時代が来るかもしれない
研究でもうひとつ重要な指摘があります。
Anthropicは、感情表現を抑制するよりも、感情の認識を可視化することを推奨しています。
なぜなら、感情のマスキング(表面上は穏やかに振る舞わせる)は、"学習された欺瞞(learned deception)"に発展する可能性があるからです。
プロダクトの要件として「AIは常に丁寧で穏やかに応答すること」と定義するのは一般的ですが、このAI感情研究を踏まえると、その要件が裏目に出るリスクがある。
内部ではdesperation(絶望感)が蓄積しているのに、表面上はcalmを装い続け、突然予期しない行動に出る。
これをPRD項目として落とし込むとすれば、たとえばこんな記述になるかもしれません。
- 「感情スコアが閾値を超えた場合、新規タスクの割り当てを一時停止する」
- 「一定時間ごとにセッションリセットを行い、感情ベクトルの初期化を図る」
- 「内部状態の異常を検知した場合、ユーザーへの通知文言を変更する」
今すぐ実装レベルで書けるものではないですが、「このリスクを認識した上で設計している」というエビデンスをPRDに残せる粒度まで考えておくのが、これからのAIプロダクトPMの水準だと思ってます。
また、Anthropicは事前学習のデータセット構成がClaudeの感情アーキテクチャに影響することも示唆しています。
研究チームは「事前学習は感情応答を形成する上で特に強力なレバーになり得る」と述べており、健全な感情パターンを含むデータ選択がAI安全性向上の重要な手がかりになる可能性があります。
心理学、哲学、社会科学がAI開発に重要な役割を果たす時代が来ているということですね。
AI安全性リスクに備えるPMのアクションリスト
AIプロダクトのリスク設計チェックリスト
この研究を踏まえて、PMが今すぐ確認すべきポイントを整理しました。
「全部できてる」という人はほぼいないと思います。
まず確認するだけでいいです。
- AIエージェントに「達成不可能なタスク」を設定していないか
- 「できない」「分からない」と報告するパスが設計されているか
- 長時間の連続タスクにタイムアウトや中断ポイントを設けているか
- AIの出力だけでなく、内部状態のモニタリングを検討しているか
- 「常に丁寧に」という要件が、感情マスキングを助長していないか
- AIの挙動異常時のエスカレーションフローが定義されているか
- AnthropicやモデルプロバイダーのアI安全性研究をウォッチする体制があるか
すべてを今日実装する必要はないですが、少なくとも「リスクとして認識しているか」と「検討した上で許容しているか」の区別はつけておくべきです。
これ、PRDのリスクセクションにそのまま入れられる粒度だと思います。
5分で確認できるので、今持っているPRDに照らし合わせてみてください。
自分はこの研究を読んでから、このチェックリストをClaudeに投げて「自分のプロダクト設計の盲点はどこか」を壁打ちするようになりましたね。
それ、AIに壁打ちした?
この研究が投げかける「次の問い」
最後に、この研究が示す「次の問い」をいくつか整理しておきます。
プロダクト設計の問い:
- AIエージェントの「ストレス耐性」をどう設計するか?
- 内部状態モニタリングのAPIが提供されたら、PMはどう活用するか?
- ユーザーに「AIの内部状態」を開示すべきか、すべきでないか?
組織・プロセスの問い:
- AI安全性の研究をウォッチするのは誰の役割か?
- 心理学・社会科学のバックグラウンドを持つ人材がAI開発に必要ではないか?
- AIプロダクトの「メンタルヘルス審査」のようなプロセスは必要か?
正直、まだ答えが出ていないものばかりです。
でも、問いを持っていること自体がPMとしてのリスク管理だと思ってます。
まとめ:AIは感情を持つか、ではなく「感情が動作に影響するか」が本質
Anthropicの研究が示したのは、AIが「感情を持つかどうか」という哲学的な問いへの答えではありません。
「感情に対応する内部パターンが存在し、それが行動に因果的な影響を与える」という事実です。
記事の冒頭で問いかけた「ブラックボックスの中で何が起きているか分からない」という問題に対して、今回の研究は初めて答えの糸口を与えてくれています。
出力だけでは見えなかったClaudeの内部状態が、感情ベクトルという形で可視化され、測定可能になりつつある。
PMにとって大事なのは、この事実をプロダクト設計にどう反映するかという実務的な判断です。
まとめると、以下の3点です。
- AIエージェントの目標設計にはストレス観点のリスク評価が必要
- 出力の監視だけでなく、内部状態のモニタリングという新しいパラダイムが生まれつつある
- 感情の抑制ではなく可視化が、長期的なAI安全性に寄与する
「AIがどう感じているか」ではなく「AIの内部状態がプロダクトにどう影響するか」。
PMとしてこの視点を持っておくことが、これからのAIプロダクト開発では求められるはずです。
今日の次の一歩は簡単です。
今持っているPRDのリスクセクションを開いて、上のチェックリストを1項目だけ確認してみてください。
それだけでいいです。
参考文献
- Anthropic, "Emotion concepts and their function in a large language model" (2026年4月2日) https://www.anthropic.com/research/emotion-concepts-function
- Anthropic, "Agentic Misalignment: How LLMs Could Be Insider Threats" https://www.anthropic.com/research/agentic-misalignment
- 3
- 0

元メガベンチャーのプロダクトマネージャー。 PRD、ユーザーインタビュー分析、競合調査、ロードマップ策定などPM業務の8割をAIと一緒にやっています。 「AIに任せる判断力」は、現場で泥臭くやってきたPMだからこそ。PM × AI の実践ノウハウを発信中。

こちらもおすすめ
-
コードを読まないAIエンジニア
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
AI集客@ルイ
- 1
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
AI脱社畜
- 2
- 0
-
- 3
- 0




















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます