
「AIが人間の脳の反応を予測できる」と聞いて、どう思いますか?
正直、僕も最初は「またSFっぽい話か」と思いました。
でも、それがあなたの仕事・研究・日常に直結する話だとしたら、どうでしょう。
Meta AIが2026年3月に発表したTRIBE v2(Trimodal Brain Encoder)の詳細を見て、僕は完全に考えが変わりました。
これ、本当に人間の脳が映像や音声にどう反応するかを、かなりの精度で予測してしまうんです。
しかも、一度も脳をスキャンしたことがない人の反応まで予測できてしまう。
720人以上のfMRI(機能的磁気共鳴画像法)データを含む大規模データセットで構築・評価されたこのモデルは、神経科学の研究を根本から変える可能性を秘めています。
この記事では、TRIBE v2の仕組みからその衝撃的な性能、そして「これが実現すると何が変わるのか」まで、できるだけわかりやすく解説していきます。
TRIBE v2とは何か──脳反応を予測する新しい基盤モデル
名前の意味と開発元(Meta FAIR)
TRIBE v2の正式名称は「TRImodal Brain Encoder v2」です。
「Trimodal(トリモーダル)」とは、映像・音声・テキストの3つのモダリティ(情報の種類)を同時に扱えるという意味です。
開発したのは、Meta社の基礎AI研究部門「FAIR(Fundamental AI Research)」のBrain and AIチーム。
FacebookやInstagramの親会社Metaが、なぜ脳科学の研究を?と思うかもしれませんが、実はMetaはAIと神経科学の交差点に長年注力してきた企業なんです。
前バージョンのTRIBE v1とAlgonauts 2025での受賞
TRIBE v2には前身となる「TRIBE v1」があります。
このv1は、2025年に開催された脳モデリングコンペティション「Algonauts 2025」で、260以上のチームの中から1位を獲得しました。
10億パラメータのアーキテクチャで、わずか4人分の低解像度fMRIデータから訓練されたモデルが、世界中の研究チームを抑えてトップに立ったんです。
そして今回のv2は、そのアーキテクチャをベースに、データ量も解像度も桁違いにスケールアップしたバージョンです。
ここからが面白いんですが、具体的にどんな仕組みで脳の反応を予測しているのか、見ていきましょう。
TRIBE v2の技術的仕組み──3段階パイプライン
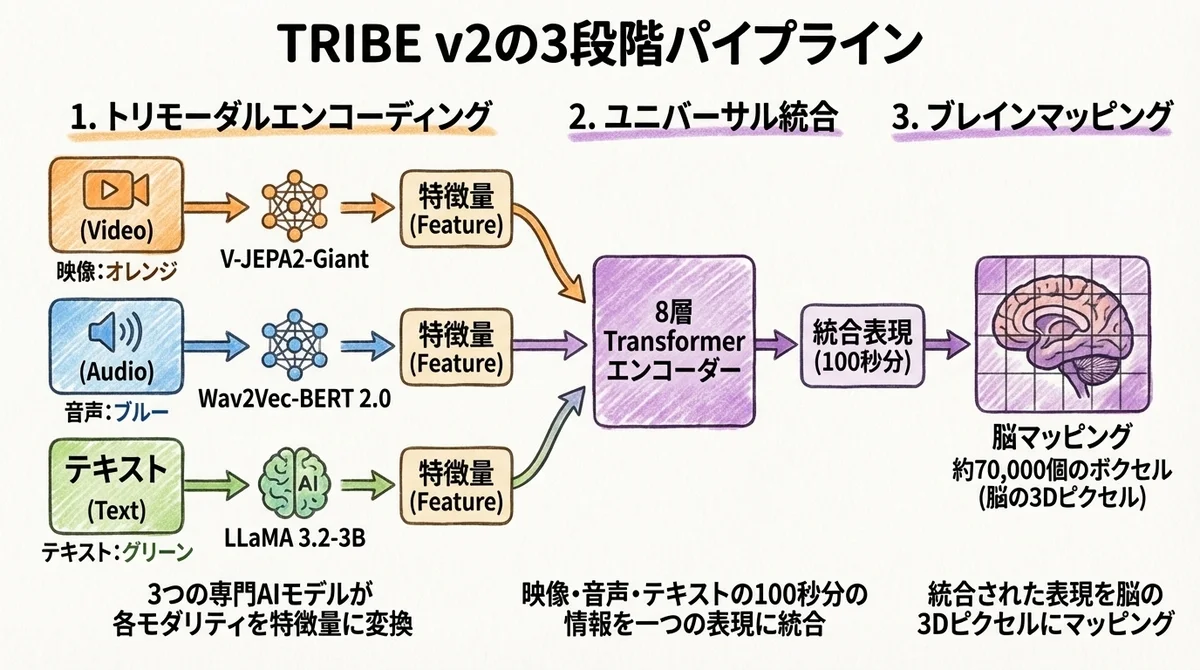
TRIBE v2が脳反応を予測するプロセスは、大きく3つのステップに分かれています。
料理に例えると、「食材の下ごしらえ」→「食材を混ぜ合わせる」→「個人の好みに合わせて味付けする」というイメージです。
ステップ1: トリモーダルエンコーディング(LLaMA / V-JEPA2 / Wav2Vec-BERT)
最初のステップでは、入力された刺激(映画の映像、音声、テキストなど)を、それぞれ専門のAIモデルで処理します。
- 映像: Meta独自のV-JEPA2-Giantが担当。直前4秒間の64フレームを処理します
- 音声: Wav2Vec-BERT 2.0が担当。音声を2Hzにリサンプリングして処理します
- テキスト: MetaのLLaMA 3.2-3Bが担当。言語情報を抽出します
ここがミソなんですが、これらのモデルはすべて「凍結」(パラメータ固定)された状態で使われています。
つまり、すでに膨大なデータで学習済みの最先端AIモデルを、いわば「超高性能な翻訳機」として活用しているんです。
ステップ2: ユニバーサル統合(8層Transformer)
3つのモデルから出力された特徴量は、次に8層・8ヘッドのTransformerエンコーダーに渡されます。
このTransformerは、100秒間のウィンドウにわたって映像・音声・テキストの情報を統合します。
これが何をしているかというと、「映像で猫が映っている」「音声で猫の鳴き声がする」「テキストで猫について話している」という別々の情報を、脳が処理するように一つの表現にまとめ上げているんです。
人間の脳も、目で見た情報と耳で聞いた情報を統合して理解していますよね。
TRIBE v2は、まさにその統合プロセスを再現しています。
ステップ3: ブレインマッピング(70,000ボクセル)
最後のステップが、統合された表現を個人の脳の反応パターンにマッピングする段階です。
ここでの出力先は、なんと約70,000個のボクセル。
ボクセルとは、脳の3Dピクセルのようなもので、fMRIで計測される脳活動の最小単位です。
前バージョンのTRIBE v1が約1,000個の脳領域しか予測できなかったのに対し、TRIBE v2は約70倍の解像度を実現しています。
この解像度があれば、「顔を見たときの反応」と「風景を見たときの反応」の違いはもちろん、英語の文章を聞いたときと中国語の文章を聞いたときの脳の反応の違いまで区別できます。
3段階の仕組みがわかったところで、従来モデルと比べて何がどれだけ変わったのかを見ていきましょう。
TRIBE v2と従来モデルの比較──性能の飛躍
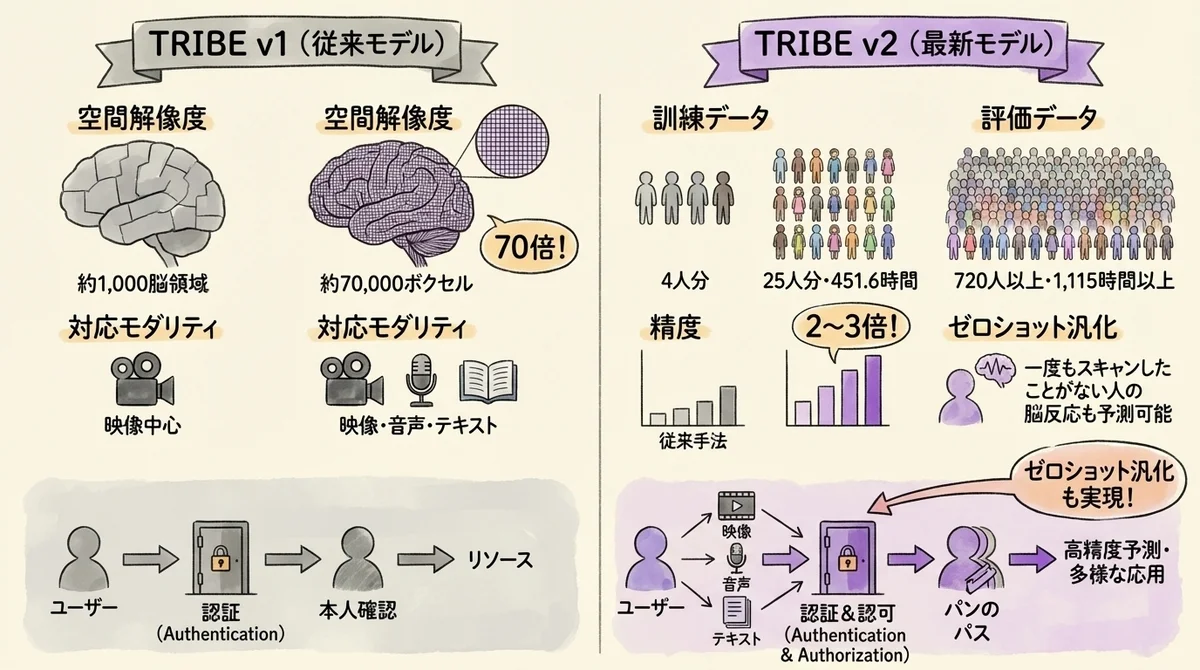
解像度70倍・精度2〜3倍の向上
数字で見ると、TRIBE v2の進化がいかに劇的かがわかります。
映画を観ているときの脳反応予測でも、オーディオブックを聴いているときの予測でも、従来の線形エンコーディングモデルに比べて2〜3倍の精度向上を達成しています。
ゼロショット汎化──初見の人物・言語にも対応
個人的にここが一番アツいポイントです。
TRIBE v2は、一度も脳スキャンをしたことがない人の脳反応を予測できます。
いわゆる「ゼロショット汎化」と呼ばれる能力で、再訓練なしに未知の被験者の脳活動を高精度で推定します。
これが何を意味するかというと、あなたがfMRI装置に一度も入ったことがなくても、TRIBE v2はあなたが映画を観たときにどの脳領域が活性化するかを、ある程度予測できるということです。
予測精度が実測を上回るケースも
ここが本当に衝撃的なんですが、TRIBE v2のゼロショット予測は、個人の実際のfMRI記録よりも正確にグループ平均の脳反応を推定できるケースがあります。
高解像度のHuman Connectome Project(HCP)7Tデータセットでは、グループ相関(R_group)が約0.4に達し、被験者個人のグループ予測性の中央値の2倍の精度を記録しました。
つまり、ある映像に対する「平均的な人間の脳の反応」を知りたい場合、実際に一人の人間をスキャンするよりも、TRIBE v2に予測させたほうが正確な結果が得られることがあるんです。
これは控えめに言って、革命的です。
この性能を支えているのが「仮想脳実験」という新しい発想です。その概念を次のセクションで見ていきましょう。
インシリコ神経科学とは──TRIBE v2が実現する仮想脳実験

fMRIスキャンを不要にするデジタルツイン
「インシリコ(in silico)神経科学」という言葉を聞いたことはありますか?
「インビトロ(試験管内)」「インビボ(生体内)」になぞらえて、「コンピューター上で(シリコンチップ上で)」実験を行うことを指します。
TRIBE v2が実現するのは、まさにこの「脳のデジタルツイン」です。
従来の神経科学研究では、一つの実験を行うために被験者を募集し、fMRI装置の予約を取り、一人ずつスキャンして、データを解析する必要がありました。
時間もコストも膨大にかかります。
TRIBE v2があれば、コンピューター上で「この映像を見せたら、脳のどの部分がどう反応するか」をシミュレーションできるようになります。
数千の仮想実験をコンピューター上で実施できる意義
これが研究者にとってどれだけ大きいか、想像してみてください。
今まで1つの実験に数ヶ月かかっていたものが、コンピューター上で数千パターンのシミュレーションを一気に回せるようになるんです。
実際に、TRIBE v2はすでにいくつかの古典的な神経科学の実験結果を「再発見」しています。
例えば、脳の「紡錘状回顔領域(FFA)」が顔の認識に特化していることや、「ブローカ野」が言語処理に関わっていることなど、数十年の実験研究で確立された知見を、TRIBE v2はデータから自動的に導き出しました。
これは、モデルの予測が実際の脳の仕組みを正しく捉えている証拠です。
では、この仮想脳実験の力は、現実の世界でどんな変化をもたらすのでしょうか。
TRIBE v2の応用先──医療・BCI・AI研究
ブレインコンピュータインターフェース(BCI)の開発加速
BCI(ブレインコンピュータインターフェース)は、脳の信号を読み取ってコンピューターを操作する技術です。
TRIBE v2のゼロショット予測能力を使えば、BCIの「個人ごとの初期キャリブレーション」にかかる時間を大幅に短縮できます。
具体的には、現在は新しいユーザーが初めてBCIを使う際に数時間〜数十時間かかるキャリブレーションが、将来的には数分程度に短縮される可能性があります。
筆者の見立てでは、2030年代には「買ってすぐ使えるBCI」の実現に向けた重要なピースになり得ると考えています。
神経疾患(失語症・感覚処理障害)への新しいアプローチ
医療分野での応用も期待されています。
例えば、失語症の患者さんの脳がどのように言語を処理しているかをシミュレーションすることで、その人に最適なリハビリプログラムを設計できるようになるかもしれません。
実際に患者さんに何度もfMRIを受けてもらわなくても、過去の限られたデータからTRIBE v2が反応を補完し、リハビリの精度向上に役立てられるシナリオが現実的になってきています。
感覚処理障害を持つ方への応用についても、筆者の見立てでは今後3〜5年以内に臨床研究への活用が始まる可能性があると考えています。
脳の仕組みからより良いAIを作る
個人的にワクワクするのが、この逆方向のアプローチです。
TRIBE v2は、人間の脳がどのように情報を処理しているかの「地図」を高解像度で提供します。
この地図を活用すれば、人間の脳の効率的な情報処理のメカニズムをAIの設計に取り入れることができます。
例えば、人間の脳が映像と音声をどのように統合しているかを理解することで、マルチモーダルAIの設計をより効果的に改善できるかもしれません。
脳科学がAIを進化させ、進化したAIがさらに脳科学を深める。
この好循環が、TRIBE v2によって加速されようとしています。
こうした応用の広がりを後押しするのが、Metaのオープンソース戦略です。
MetaのオープンソースとCC BY-NCライセンスの意図
HuggingFace / GitHub / デモの公開内容
TRIBE v2は、以下のすべてがオープンに公開されています。
- モデルの重み: HuggingFace(facebook/tribev2)で公開
- ソースコード: GitHub(facebookresearch/tribev2)で公開
- インタラクティブデモ: aidemos.atmeta.com/tribev2で体験可能
- 論文: TRIBE v1のアーキテクチャに関する論文がICLR 2026に採択。TRIBE v2の詳細論文はarXivにて公開中
デモサイトでは、実際に映像や音声を入力して、脳のどの領域がどう反応するかを視覚的に確認できます。
ぜひ一度触ってみてください。
「あ、こんなふうに脳が反応するんだ」という新鮮な驚きがあるはずです。
なぜ非商用ライセンスなのか──Metaの戦略的背景
ライセンスはCC BY-NC(クリエイティブ・コモンズ 表示-非営利)です。
つまり、研究目的や非商用目的では自由に使えますが、商用利用には別途許可が必要です。
Metaがこのライセンスを選んだ背景には、いくつかの戦略的な意図が読み取れます。
まず、研究コミュニティへの貢献。
脳科学は全人類にとって重要な研究分野であり、オープンにすることで研究が加速します。
実際にMetaは、LLaMAシリーズでも同様のアプローチを取っており、オープンソースで研究者コミュニティのエコシステムを構築してきました。
一方で、脳データという極めてセンシティブな領域を扱うモデルだからこそ、商用利用に一定の歯止めをかけておくという判断も見えます。
脳活動の予測技術が広告ターゲティングなどに無制限に使われることへの懸念に、先手を打った形とも言えるでしょう。
この「商用利用への歯止め」は、次のセクションで触れる倫理的な問題とも深く結びついています。
残された課題と倫理的論点
fMRIの時間分解能の限界
TRIBE v2は非常に強力なモデルですが、万能ではありません。
最大の技術的制約は、fMRIそのものの時間分解能です。
fMRIは血流の変化を通じて脳活動を間接的に計測しますが、その時間分解能は秒単位です。
一方、実際の神経活動はミリ秒単位で起きています。
つまり、TRIBE v2が予測しているのは、あくまでfMRIで捉えられる「ゆっくりとした脳活動の変化」であり、瞬間的な神経発火のパターンまでは追えていません。
ただし、これはTRIBE v2の問題というよりも、fMRIという計測手法自体の限界です。
将来的に、より高い時間分解能を持つ脳計測技術のデータが加われば、モデルの予測もさらに精緻化されるでしょう。
脳データのプライバシーと商業利用リスク
もう一つ、避けて通れないのが倫理的な問題です。
「AIが脳の反応を予測できる」ということは、裏を返せば「人間の内面的な反応を外部から推測できる」ということでもあります。
例えば、ある広告に対して脳がどう反応するかを予測できれば、より効果的な(あるいは操作的な)マーケティングが可能になりかねません。
現時点ではCC BY-NCライセンスで商用利用が制限されていますが、この技術が発展していく中で、脳データのプライバシー保護に関する法整備やガイドラインの策定が急務になるでしょう。
研究としての可能性と、社会的なリスクのバランスをどう取るか。
これは技術者だけでなく、社会全体で考えていく必要がある問題です。
TRIBE v2についてよくある質問
Q. TRIBE v2は無料で使えますか?
A. はい、研究・非商用目的であれば無料で利用できます。モデルの重みはHuggingFace(facebook/tribev2)、ソースコードはGitHub(facebookresearch/tribev2)で公開されています。商用利用の場合はCC BY-NCライセンスに基づき、Meta FAIRへの別途連絡が必要です。
Q. TRIBE v2は日本語にも対応していますか?
A. TRIBE v2が使用するLLaMA 3.2は多言語対応モデルであり、論文では英語以外の言語(フランス語・オランダ語)での脳反応予測にも有効であることが示されています。日本語への対応については公式に明記されていませんが、多言語基盤モデルの特性から一定の汎化が期待できます。
Q. TRIBE v2をすぐに試す方法はありますか?
A. Meta公式のインタラクティブデモ(aidemos.atmeta.com/tribev2/)でブラウザから体験できます。映像や音声を入力すると、脳のどの領域がどう反応するかをリアルタイムで可視化できます。
Q. TRIBE v2とTRIBE v1の違いは何ですか?
A. 主な違いは解像度(約1,000脳領域から約70,000ボクセルへ70倍増)、訓練データ規模(4人分から25人分へ拡大)、対応モダリティ(映像中心から映像・音声・テキストのトリモーダルへ)の3点です。精度も従来手法比2〜3倍に向上しています。
まとめ──TRIBE v2が示す神経科学×AIの未来
TRIBE v2は、AIと神経科学の融合がどこまで進んでいるかを鮮やかに示すモデルです。
25人分・451.6時間の訓練データと、720人以上・1,115時間以上に及ぶ評価データセット。
約70,000ボクセルという前バージョンの70倍の解像度。
従来手法の2〜3倍の精度。
そしてゼロショットで未知の個人の脳反応を予測し、場合によっては実測すら上回る推定精度。
これだけの数字を並べても、実感がわきにくいかもしれません。
でも、ひとつだけ問いを残しておきたいと思います。
「あなたの脳がどんな映像に強く反応するか、AIがあなた自身よりも正確に知っている世界」が来たとき、あなたはそれをどう使いたいですか?
まずはデモサイトで、この技術を体感してみてください。
映像や音声に対して脳がどう反応するかを可視化する体験は、きっと新鮮な驚きをもたらしてくれるはずです。
- 3
- 0

元メガベンチャーのプロダクトマネージャー。 PRD、ユーザーインタビュー分析、競合調査、ロードマップ策定などPM業務の8割をAIと一緒にやっています。 「AIに任せる判断力」は、現場で泥臭くやってきたPMだからこそ。PM × AI の実践ノウハウを発信中。

こちらもおすすめ
-
プロンプト画伯
- 4
- 0
-
コードを読まないAIエンジニア
- 3
- 0
-
- 3
- 0
-
- 5
- 1
-
- 2
- 0
-
AI脱社畜
- 3
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 5
- 0
-
ゆい@海外AI副業ラボ
- 5
- 0
-
- 2
- 1
-
- 9
- 0
-
- 4
- 0
-
- 8
- 0
-
- 3
- 1
-
- 12
- 1
-
- 4
- 0
-
- 4
- 0
-
- 1
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 4
- 1
-
 AI集客@ルイ
AI集客@ルイ
- 2
- 0
-
- 3
- 0















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます