カイ(@kai_pm)です。
元メガベンチャーPMで、今はAIを使ってPM業務の8割を自動化してます。
「この仮説、エンジニアにお願いしたいけどリソースが……」——PMなら一度はこのジレンマを経験していますよね。
仮説検証のたびにエンジニアのスプリントを消費する。
R&Dの初期探索フェーズで何ヶ月もかかる。
「もっと早く動けたら」というフラストレーション、地味にたまりますよね。
「PMの仕事は意思決定。それ以外はAIに任せていい」が自分の持論なんですが、今回はその「意思決定」の前段階——つまり仮説検証や調査・分析のフェーズまでAIが自律的にやってしまう、という話をします。
SakanaAIが発表した「AI Scientist v2」、ご存知ですか?
AIが仮説を立て、実験を設計・実行し、データを分析し、論文まで書く。
しかもその論文が国際会議の査読プロセスを通過した。
これ、PMやR&D部門のマネージャーにとって、かなり大きな意味を持つニュースだと思ってます。
AI Scientist v2 とはなにか——まず3分で理解する
SakanaAIが開発した「自律型科学研究システム」とは
AI Scientist v2は、日本発のAIスタートアップ・SakanaAIが開発した自律型の科学研究システムです。
ひとことで言えば、「AIが科学者の代わりに研究して論文を書く」ためのシステムですね。
仮説の生成、実験コードの作成と実行、結果の分析、そして論文の執筆——この一連のプロセスを、人間が手を動かさなくてもAIが自律的に回してくれます。
使えるLLMもOpenAI系モデル、Google Gemini、AnthropicのClaude(AWS Bedrock経由)と幅広く対応していて、研究者でなくてもパイプラインを回せる設計になっています。

AI Scientist v2とv1の決定的な違い——テンプレート不要でML分野を横断して対応
「前バージョンのv1があったよね?」と思った方もいるかもしれません。
v1は2024年に公開されて話題になりましたが、大きな制約がありました。
あらかじめ用意されたテンプレート(研究のひな形)に沿ってしか動けなかったんです。
つまり、テンプレートが存在しない研究テーマには対応できなかった。
v2ではこの制約が取り払われています。
テンプレート不要(template-free)で、与えられたコードベースを自分で理解し、機械学習分野を横断して研究を進められるようになりました。
ここが「v1→v2」で最も大きな進化ポイントです。
PMの仕事に例えるなら、v1は「決められたフレームワークの中でしか提案できないコンサルタント」、v2は「状況に応じて自分でフレームワークを選び、仮説を立てられる参謀」に近いですね。
なお、公式GitHubには「v2はv1の上位互換ではない」という注記もあります。
明確な目標と研究基盤がある場合はv1が最適で、v2はオープンエンドな科学的探索向け——という使い分けが想定されているようです。
世界初:AI Scientist v2が書いた論文が査読プロセスを突破した
そして最も注目すべきなのが、AI Scientist v2が生成した論文がICLR 2025の「ICBINB」ワークショップで査読スコアの受理ラインを超えた、という事実です。
正確に伝えておくと、SakanaAIはICBINBワークショップに3本の論文を提出し、そのうち1本がスコアで受理ラインを超えました。
ワークショップの受理率は約70%(ICLR本会議の約32%とは異なります)という文脈は踏まえる必要があります。
また、SakanaAIはAI生成論文の倫理的な問題について事前に方針を設けており、査読通過後も公式発表通りに論文を撤回(withdraw)しています。
正式出版はされていません。
これらの条件を踏まえた上でも、「完全にAIが自律的に生成した論文が、国際的な査読プロセスで評価された」のは世界初の事例として大きな意味があります。
査読というのは、他の研究者が論文の質を評価する仕組みです。
学術論文の信頼性を担保する重要なプロセスであり、ここをAI生成の論文が突破したというのは、研究の世界に大きなインパクトを与える出来事なんですよ。
「そもそもSakanaAIってどんな会社なの?」という方のために、背景も整理しておきます。
SakanaAIとは——日本発ユニコーンの現在地

評価額$2.6B、MUFG・大和証券グループとも提携
AI Scientist v2を開発したSakanaAIは、日本発のAIスタートアップです。
企業評価額は$2.6B(約4,000億円)に達しており、日本のAI企業としてはトップクラスのユニコーンです。
注目すべきは、MUFG(三菱UFJフィナンシャル・グループ)や大和証券グループとも提携している点です。
純粋な研究機関ではなく、ビジネスへの実装を見据えた動きをしているということですね。
AI技術の研究成果を金融・産業分野に応用するパイプラインがすでに構築されつつあるのは、PMとして非常に注目しています。
学術実績の積み上げ——Nature Machine Intelligenceへの掲載からAI 査読通過へ
SakanaAIの研究成果は着実に積み上がっています。
研究チームによる論文「Evolutionary Optimization of Model Merging Recipes」がNature Machine Intelligenceに掲載された実績を持ち、学術的な信頼性を一歩ずつ築いています。
そして今回、AI Scientist v2が生成した論文がICLR 2025のICBINBワークショップで査読スコアの受理ラインを超えた。
AI自身が書いた論文が国際的な査読プロセスで評価されたのは世界初の事例であり、これは「一発屋」ではなく、継続的にインパクトのある成果を出せる組織であることの証左です。
今後のバージョンアップで対応分野が広がれば、R&D部門にとってますます無視できない存在になるでしょう。
仕組みの詳細は後のセクションで解説しますが、まず「これがビジネスにどう影響するか」を先に押さえておきましょう。
ビジネス・プロダクト開発への影響——PMが注目すべきポイント
仕組みの詳細は次のセクションで解説しますが、まずPMとして気になるビジネスインパクトから整理します。
研究開発AIの登場でR&D投資の意思決定が変わる
ここが自分として最も注目しているポイントです。
AI Scientist v2のような研究開発AIが実用化されると、R&D投資の意思決定フレームワーク自体が変わります。
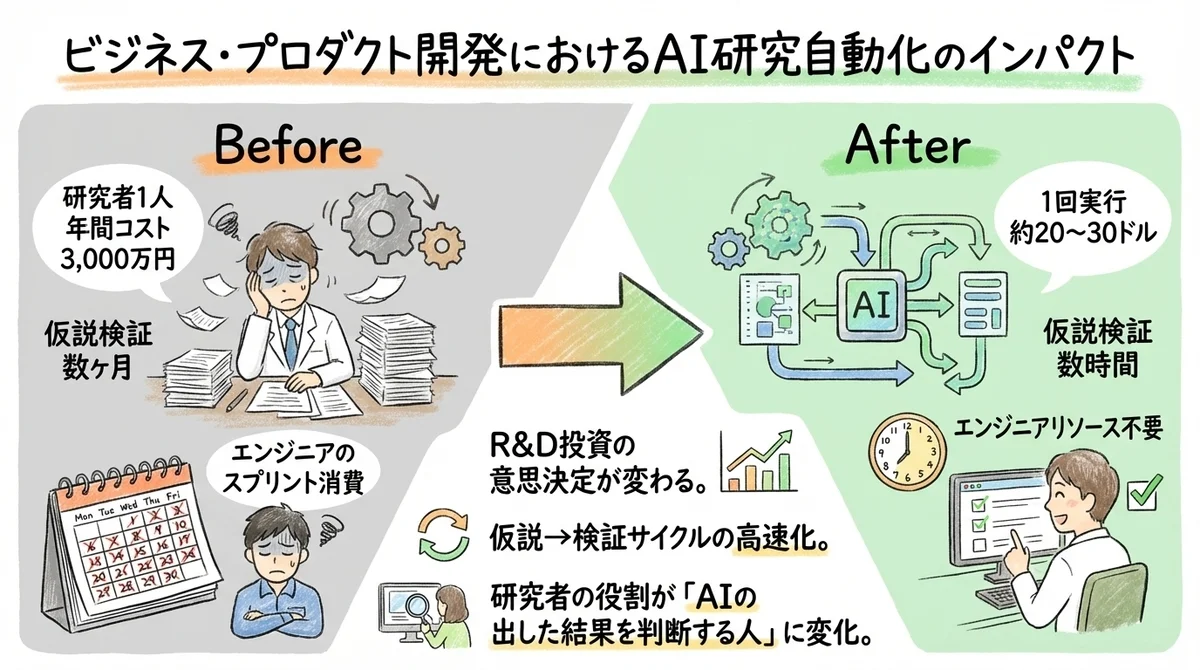
従来のR&D投資は「研究者を何人雇うか」「どの研究テーマに何年間投資するか」という、ヒト・モノ・カネの配分が主な意思決定でした。
ところがAIが$20〜$30で仮説検証を回せるようになると、意思決定の焦点が変わります。
Before:
「この研究テーマに研究者3名を2年間アサインする。投資額は年間3,000万円」
After:
「このテーマでAI Scientistを100回走らせて、有望な方向性を絞り込む。投資額は$3,000(約45万円)。有望な結果が出たテーマだけ、研究者をアサインする」
これ、PMが得意とする「リーンスタートアップ」の考え方そのものですよね。
つまり、R&Dの初期フェーズで「広く浅く」探索するコストが劇的に下がるんです。
最小コストで仮説検証を回し、確度が高まったものにリソースを集中投下する——PMの思考がそのままR&Dに適用される時代が来るということですね。
「仮説→検証」サイクルの高速化はプロダクト探索にも使える
AI Scientist v2は現時点では機械学習の研究分野が主なターゲットですが、このアプローチの本質——「仮説を立て、実験し、結果を評価する」サイクルの自動化——はプロダクト開発にも応用可能です。
たとえば、プロダクトのアルゴリズム改善を探索するフェーズ。
推薦エンジンのチューニング、検索ランキングの最適化、価格設定モデルの検証など、「複数のアプローチを試して最適解を見つける」タスクには相性がいいですね。
「この仮説を検証したいけど、エンジニアのリソースが足りない」——そのフラストレーション、わかります。
AI Scientistのようなツールが成熟すれば、PMが自分で仮説検証の初期探索を回せる世界が来るかもしれません。
それ、AIに壁打ちした?——と自分に問いかけるフェーズが、「それ、AIに検証させた?」に変わる日が来ると思ってます。
研究者・R&D部門の役割はどう変わるか
「研究者の仕事がなくなるのでは?」という声もありますが、自分はそうは思っていません。
AI Scientist v2が得意なのは「定型的な仮説検証の大量実行」です。
一方、研究の本質的な部分——「どの問題を解くべきか」「社会にとって何が重要か」「まったく新しいパラダイムを提案する」——は、まだ人間の領域です。
PMの仕事がAIで自動化されても「意思決定」は残るのと同じ構造ですね。
研究者の役割は「自分で手を動かして実験する人」から「AIの研究エージェントをディレクションし、結果を評価・統合する人」にシフトしていく。
いわば「研究のPM化」が進むと見ています。
R&D部門のマネージャーやPMにとっては、「AIを使った研究パイプラインの構築・運用」が新しいスキルセットとして求められるようになるでしょう。
では、このシステムの中身はどうなっているのか——少し掘り下げて解説します。
AI Scientist v2の仕組みを非エンジニアが理解する
AI Scientist v2の4つの自動化ステップ——仮説から論文まで
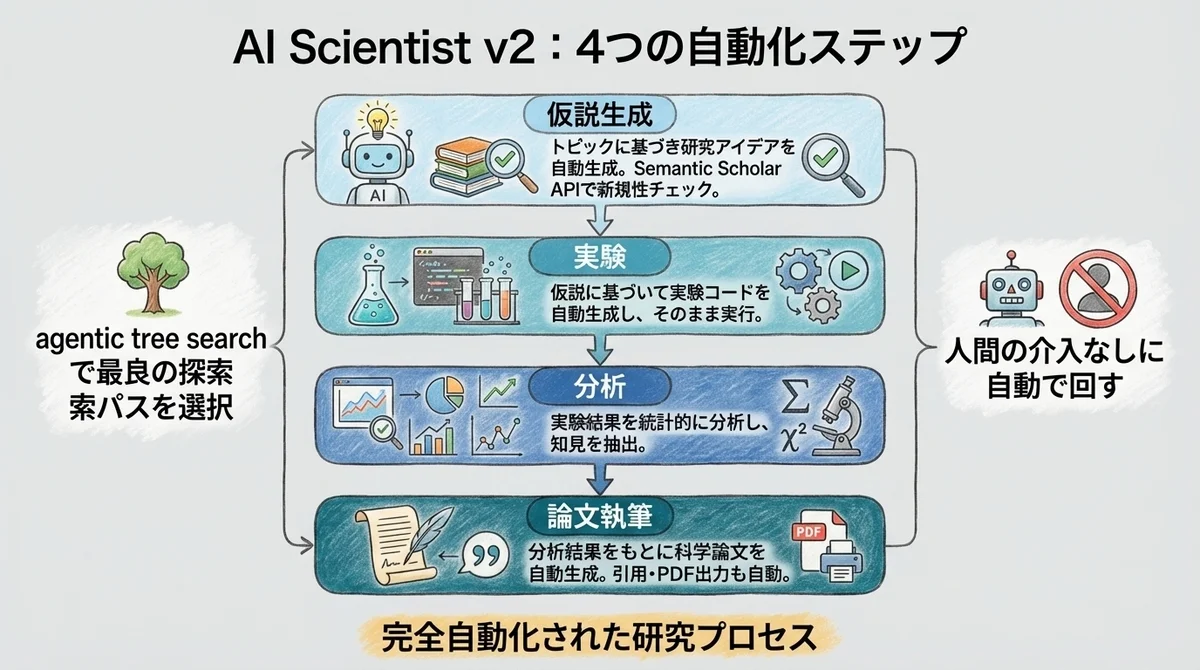
AI Scientist v2の研究プロセスは、大きく4つのステップに分かれます。
PMの言葉で言えば、「課題発見→仮説立案→検証→レポーティング」のサイクルがまるごと自動化されている、ということですね。
ステップ1: 仮説生成
与えられたコードベースや先行研究を読み込み、「こうすれば性能が上がるのではないか」「この手法を組み合わせたら面白い結果が出るのではないか」という仮説をAIが自ら立てます。
Semantic Scholar APIを使って先行研究の新規性チェックも行うので、「すでに誰かがやった研究」を避けることもできます。
これ、PMが壁打ちで何時間もかけて仮説の新規性を確認していたやつですよね。
ステップ2: 実験の設計と実行
仮説に基づいてAIが実験コードを書き、実際に実行します。
GPU上でPyTorchを使ったモデル学習を走らせ、結果を数値として取得するところまで自動です。
エンジニアのスプリントを消費せずに「とりあえず走らせる」ができる——これがPMにとっての最大のインパクトだと思ってます。
ステップ3: データ分析
実験結果を統計的に分析し、仮説が正しかったかどうかを評価します。
グラフや図表の生成も自動で行います。
「数字が出た、でも意味がわからない」という状態をAIが整理してくれるので、意思決定の材料がすぐに揃うんですよ。
ステップ4: 論文執筆
分析結果をもとに、学術論文のフォーマットに沿った論文をAIが執筆します。
PRDを書くプロセスに例えると、「市場調査→課題定義→解決策の仮説→検証計画→仕様書」をAIが全部やってくれるイメージです。
ここまで揃って初めて、人間が「この仮説は本当に追うべきか」を判断できる——意思決定の質が格段に上がります。
agentic tree searchとは——AI Scientist v2のコア技術をざっくり理解する
v2の核心技術のひとつが「agentic tree search(エージェンティック・ツリーサーチ)」です。
技術的な詳細は省きますが、考え方はシンプルです。
研究の進め方を「木構造(ツリー)」として捉えます。
ある仮説を起点に、複数のアプローチを枝分かれさせて探索し、最も有望な枝を優先的に深掘りしていく——これが best-first tree search の考え方です。
PMなら馴染みのある概念で例えると、「仮説検証ツリー」のようなものです。
ひとつの仮説がうまくいかなかったら、別の枝に戻って探索し直す。
人間の研究者が頭の中でやっている「試行錯誤」を、AIが体系的かつ網羅的に実行しているわけです。
これはAIDEプロジェクト(AI-Driven Exploration)の上に構築されており、単純な一本道の実験ではなく、複数の可能性を並列に探索できるのが大きな強みになっています。
AI Scientist v2の実行コストはたった$20〜$30——なぜそこまで安いのか
ここが地味にすごいんですよ。
AI Scientist v2の1回の実行コストは、実験+論文執筆を含めて約$20〜$30(約3,000〜4,500円)。
内訳としては、実験パイプラインの実行で$15〜$20、論文執筆フェーズで追加$5程度です。
人間の研究者を雇って同じアウトプットを出す場合、人件費だけで数十万〜数百万円かかることを考えると、桁違いのコスト効率です。
なぜそこまで安いのか。
理由は、LLM APIの利用料が主なコストであり、GPUの計算コストもクラウドの従量課金で済むからです。
人間の研究者が数週間〜数ヶ月かけるプロセスを、大幅に短縮して完了させます。
「$30の論文と、一流研究者の論文が同じ品質か?」——それは現時点ではNoです。
でも、「初期仮説の検証を大量に回す」「研究テーマの探索フェーズを加速する」という用途なら、このコスト感は革命的だと思ってます。
仕組みを理解したところで、実際に導入を検討する前に知っておくべきリスクを押さえておきましょう。
AI Scientist v2のリスクと課題——導入前にPMが知るべき注意点
AI Scientist v2のセキュリティリスクとサンドボックス対策
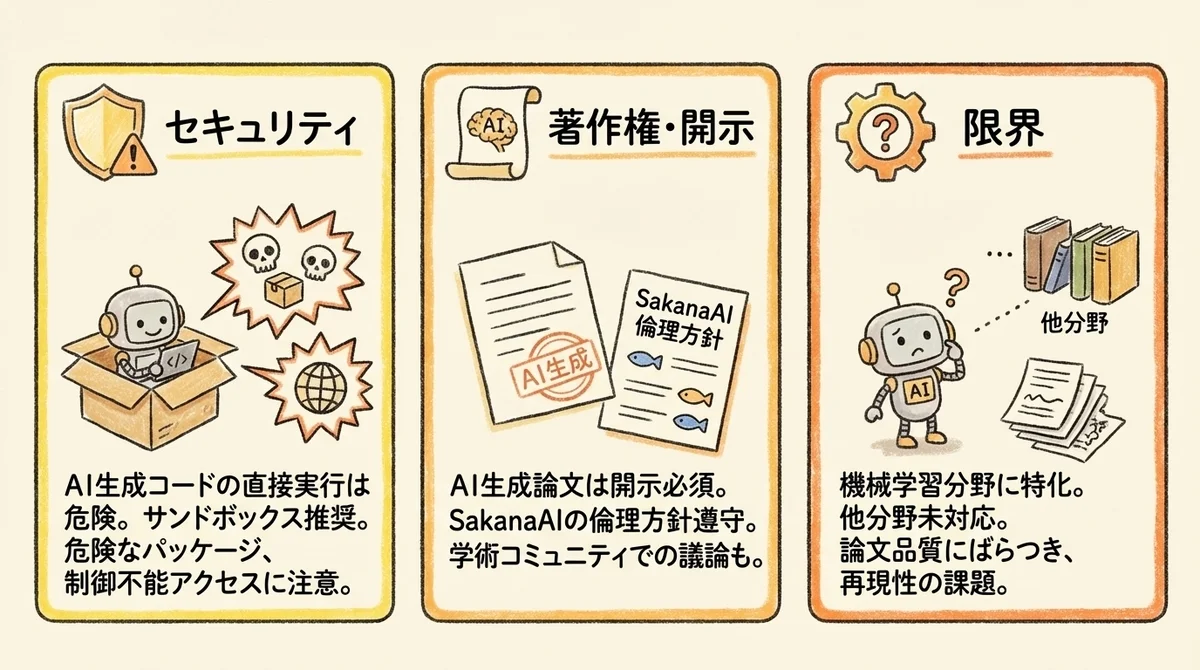
AI Scientist v2は、AIが生成したコードを自動で実行するシステムです。
ここにセキュリティリスクがあります。
LLMが生成するコードが常に安全である保証はありません。
意図しないファイル操作やネットワークアクセスが発生する可能性があるため、公式ドキュメントでもサンドボックス環境(隔離された実行環境)での運用が強く推奨されています。
企業で導入を検討する場合、情報セキュリティ部門との連携は必須です。
本番データが存在する環境では絶対に動かさない、というのが鉄則ですね。
AI Scientist v2を使った論文の著作権とAI利用開示のルール
AI Scientist v2を使って生成した論文には、AI利用の開示が必要です。
SakanaAIは自身の利用規約においてAI生成コンテンツの開示要件を定めており、「AIが書きました」と明示することを求めています。
これは法的義務というよりも、SakanaAIが設けた倫理的方針に基づくルールです。
ただし学術コミュニティの投稿規定や、企業のR&D成果物の取り扱い方針によっては、別途コンプライアンス上の確認が必要になる場合もあります。
特許出願や技術レポートにAI生成の成果を含める場合は、コンプライアンス部門に相談しておくのが安全です。
「AIを使っていることを隠す」のは、短期的にはメリットがあるように見えても、発覚したときのリスクが大きすぎます。
開示を前提とした運用フローを最初から設計しておくべきですね。
AI Scientist v2が現時点で抱える限界(ML分野特化・精度・再現性)
AI Scientist v2の現時点での限界も、正直に把握しておく必要があります。
対象分野の制約: 現状は機械学習(ML)分野の研究が主な対象です。
生物学、化学、物理学など他の科学分野への汎化はまだ発展途上です。
精度と再現性: AI生成の論文が査読プロセスを通過したとはいえ、受理率約70%のワークショップへの提出であり、トップカンファレンスの本会議ではありません。
人間の一流研究者が書く論文と同等の品質には、まだ距離があります。
環境の制約: Linux + NVIDIA GPU + Python 3.11 + PyTorch + CUDAという技術スタックが必要で、非エンジニアが単独で動かすにはハードルが高いのが現実です。
これらの限界を踏まえた上でも、「R&Dの初期探索コストを桁違いに下げる」というインパクトは本物です。
使えるところから使う——このスタンスで向き合う価値が十分にある技術だと確信してます。
まとめ——AI Scientist v2を「自分ごと」にするために
ビジネスパーソンが今すぐできること
AI Scientist v2は、まだ「誰でも簡単に使える」段階ではありません。
でも、PMやビジネスサイドの人間がこの動向を「自分ごと」として捉えておくことには大きな価値があります。
具体的に、今すぐできることを3つ挙げます。
1. 自社R&Dの「仮説検証コスト」を把握する
現在、ひとつの仮説を検証するのに何日かかっていて、いくらコストがかかっているか。
この数字を把握しておくだけで、AI Scientist v2のような技術が使えるようになったときのインパクトを定量的に評価できます。
次のチームMTGで5分だけ時間をもらって、この問いを投げてみてください。
それだけで、チームの解像度が一段上がります。
2. 社内のMLエンジニアとAI Scientist v2について話す
「こういうツールがあるらしいけど、うちの研究テーマで使える余地はある?」——この一言だけで十分です。
エンジニアリングの実現可能性を確認しておくと、いざ導入を検討するときに判断が速くなります。
自社R&Dチームに共有するための要約メモ1枚を作って、まず社内に投げてみる——そこから始めてみてください。
3. arXiv論文とGitHubリポジトリをウォッチリストに入れる
技術の進化は速いので、定期的にウォッチしておくだけで情報感度が変わります。
以下にリンクをまとめておきますね。
参考リンク(GitHub、arXiv論文、公式ブログ)
- GitHub: https://github.com/SakanaAI/AI-Scientist-v2
- arXiv論文(Yamada et al., 2025): https://arxiv.org/abs/2504.08066
- SakanaAI公式(査読通過の報告): https://sakana.ai/ai-scientist-first-publication/
- SakanaAI公式(日本語解説): https://sakana.ai/ai-scientist-jp/
AI Scientist v2は、「AIが研究する時代」の到来を示す象徴的なプロジェクトです。
自分たちPMの仕事が「意思決定に集中する」方向に進化したように、研究者の仕事も「何を研究するかの意思決定」に集中する時代が来る。
その変化を「脅威」ではなく「機会」として捉えられるかどうかが、これからの差になると思ってます。
それ、AIに壁打ちした?
- 2
- 0

元メガベンチャーのプロダクトマネージャー。 PRD、ユーザーインタビュー分析、競合調査、ロードマップ策定などPM業務の8割をAIと一緒にやっています。 「AIに任せる判断力」は、現場で泥臭くやってきたPMだからこそ。PM × AI の実践ノウハウを発信中。

こちらもおすすめ
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 1
- 0
-
AI脱社畜
- 3
- 0
-
- 6
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 3
- 1
-
KAWAI
- 2
- 1
-
コードを読まないAIエンジニア
- 5
- 1
-
- 2
- 0
-
ゆい@海外AI副業ラボ
- 5
- 0
-
ゆい@海外AI副業ラボ
- 5
- 0
-
プロンプト画伯
- 2
- 1
-
- 9
- 0
-
- 4
- 0
-
- 8
- 0
-
- 3
- 1
-
- 12
- 1
-
- 4
- 0
-
- 4
- 0
-
- 1
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 4
- 1















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます