
はじめまして、もるふぉ@コードをかかないAIエンジニアです。
エンジニアをやりながら、今はほぼコードを書かない開発スタイルに移行しました。
「書けないから書かない」じゃなくて、「書けるから書かなくていい」という話です。
実案件ベースで気づいたことだけ書いています。
「来月の売上、どれくらいになりそう?」——この質問、エンジニアなら一度は経営陣から聞かれたことがあるんじゃないでしょうか。
「予測モデル組めばいけますよ」とは言ったものの、ARIMAのパラメータ調整で3日溶かしたり、Prophetの季節性設定で沼にハマったり。
挙句の果てに「で、いつできるの?」って詰められるあの感じ、地味にストレスたまりますよね。
そこに登場したのが、Googleが開発した時系列基盤モデル「TimesFM」です。
驚くべきは、トレーニング不要でどんな時系列データでも即座に予測できること。 しかも2026年2月からは、Googleスプレッドシートからも使えるようになりました。
つまり、今まで「モデル構築に3日、チューニングに1週間」だった時系列予測が、スプレッドシートにデータを入れてボタンを押すだけで完了するんです。
この記事では、TimesFMの仕組みからビジネス活用、既存手法との比較、実際の始め方まで、エンジニア視点でわかりやすく解説します。
TimesFMとは?——時系列基盤モデルが変える予測の常識
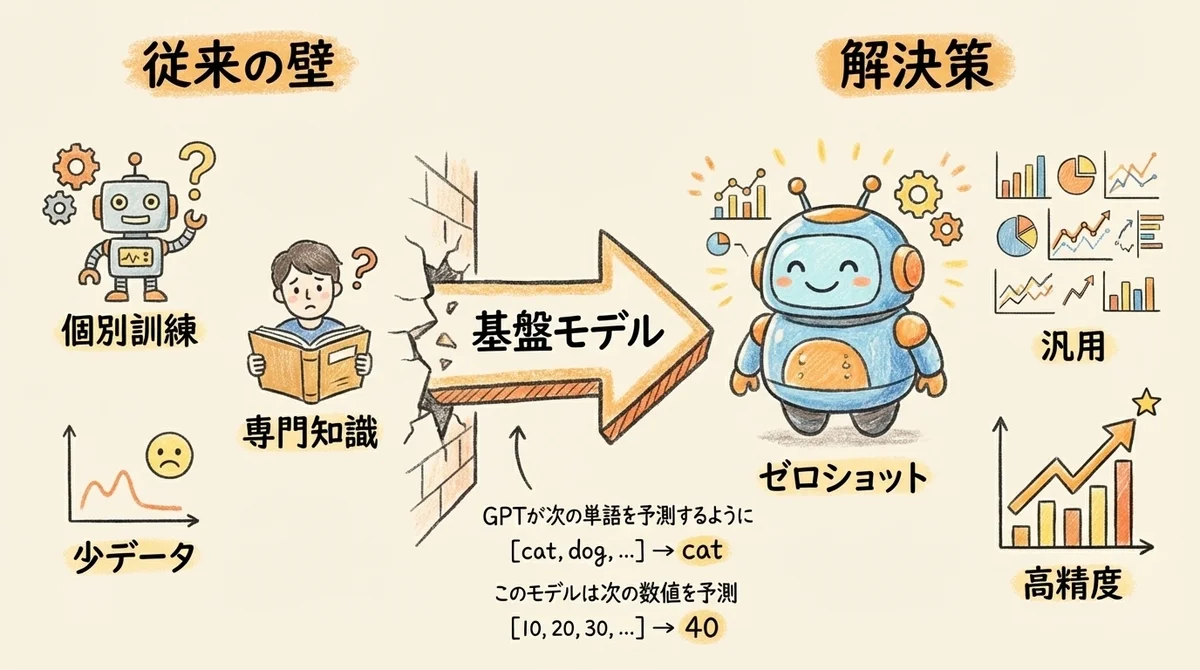
従来の時系列予測AIが抱えていた3つの壁
時系列予測をやろうとすると、大きく3つの壁にぶつかります。
- データごとにモデルを訓練する必要がある: 売上データで予測したければ売上データで学習、天気データなら天気データで学習。 汎用的なモデルがなかった。
- 専門知識が必要: ARIMAの次数選定、Prophetのパラメータ調整……統計やPythonのスキルがないと始められない。
- データが少ないと精度が出ない: 新規事業や新商品は過去データが少なく、まともな予測ができない。
「予測したいデータはあるけど、使いこなせない」——これが多くの企業のリアルだったんですよね。

TimesFMが解決する「3つのこと」
TimesFMは、時系列基盤モデルという新しいアプローチでこの壁を壊しました。
ここ、ちょっと注目してください。
- トレーニング不要(ゼロショット予測): データを渡すだけで、事前学習済みの知識をもとに即座に予測を返してくれる。 個別のモデル構築が不要なんです。
- 汎用性: 売上、天気、交通量、株価——どんな種類の時系列データにも対応できる。 「この数字の未来を教えて」と渡せばOK。
- 高精度: 1,000億(100 billion)以上の実世界データポイントで事前学習済み。 個別に訓練した専用モデルに匹敵する精度を、ゼロショットで出せる。
ChatGPTが膨大なテキストデータから「文章のパターン」を学んだように、TimesFMは「数字の変動パターン」を学んでいます。
いわば「数字の未来を予測するGPT」みたいなものですね。
1,000億の実データで事前学習——何がすごいのか
TimesFMはGoogle Researchが開発した時系列基盤モデルで、トップカンファレンスICML 2024に採択された論文がベースになっています。
学術的な裏付けがしっかりあるモデルです。
技術的なポイントを簡潔にまとめると:
- アーキテクチャ: デコーダーのみのTransformer(GPTやClaudeと同じ設計思想)
- 学習データ: 交通量、天気、需要予測など多種多様な1,000億(100 billion)以上の実データポイント
- パッチベースのトークン化: 時系列データを「パッチ」という塊に分割して、LLMがテキストをトークンに分割するのと同じように処理する
- ライセンス: Apache 2.0でオープンソース公開
これが地味にすごいんですよ。
LLMが「次の単語」を予測するのと同じ仕組みで、このモデルは「次の数値」を予測している。 テキストの世界で起きた基盤モデル革命が、時系列データの世界にも来たということです。
バージョン変遷と2.5の主要進化点
TimesFMはリリース以来、着実にバージョンアップを重ねています。
意外だったのが、2.5ではパラメータ数を500Mから200Mに減らしているんですよね。
「大きければいいわけではない」——効率化と精度を両立させた設計思想がここに表れています。
さらにコンテキスト長が8倍に拡張され(2.0→2.5比較)、より長期的なトレンドを捉えた予測が可能になりました。
想像してみてください。 これまで「直近2,048時点分」しか見られなかったのが、「16,384時点分」を一気に俯瞰できるようになった。 たとえば日次データなら、約5.6年分→約44.9年分のデータを一度に参照できる計算です。
また、不確実性を含んだ分位数予測もサポートしており、「いつ頃、どのくらいの確率で、この値になるか」という幅を持った予測ができます。
ゼロショットからファインチューニング対応まで
このモデルはゼロショット(そのまま使う)でも十分な精度が出ますが、自分のデータに合わせてファインチューニングすることも可能です。
- ゼロショット: データを渡すだけで即予測。 ほとんどのユースケースはこれで十分。
- ファインチューニング: 特定ドメインのデータで追加学習させて精度を上げる。 上級者向け。
- 共変量サポート(XReg): 祝日フラグや天候データなど、予測に影響する外部要因も入力できる。
つまり「まずゼロショットで試して、もっと精度が欲しくなったらファインチューニング」という段階的なアプローチができるんですよね。
モデルはHugging Face(google/timesfm-2.5-200m-pytorch)からすぐにダウンロード可能です。
GitHub(google-research/timesfm)でもソースコードが公開されています。
でも、本当にすごいのはここからです。

Googleスプレッドシートで使えるようになった(2026年2月〜)
Connected SheetsとBigQuery MLによるTimesFM統合
ここからが、自分が一番テンション上がったポイントです。
2026年2月、GoogleはBigQuery MLに組み込まれたTimesFMを、Connected Sheets経由でGoogleスプレッドシートから直接利用できるようにしました。
つまり、SQLもPythonも書かずに、スプレッドシートのUI操作だけで時系列予測ができるんです。
これ、何がヤバいかっていうと、今まで「データサイエンティストに依頼して、2週間待って、結果をもらう」だったワークフローが、「自分で5分で予測結果を出す」に変わるんですよ。
BigQuery MLにはもともとAI.FORECAST関数としてTimesFMが統合されていましたが、Connected Sheetsとの連携によって、普段スプレッドシートを使っている人がそのまま予測機能にアクセスできるようになりました。
異常検知もAI.DETECT_ANOMALIES関数で利用可能です。
操作の流れ
Connected Sheets経由でこのAIモデルを使う流れは、ざっくりこんな感じです。
- BigQueryにデータを準備する: 売上データや需要データをBigQueryテーブルに格納
- Connected Sheetsで接続: Googleスプレッドシートから「データ」→「コネクタ」→ BigQueryプロジェクトを選択
- 予測関数を実行: Connected Sheetsの操作画面からAI.FORECAST関数を呼び出す
- 結果をグラフで確認: 予測結果がスプレッドシートに返ってくるので、そのままグラフ化
「え、それだけ?」って思いますよね。
本当にそれだけなんですよ。 エクセル感覚で未来予測ができる時代が来ました。
誰が使えるか・料金・日本での展開状況
Connected SheetsでTimesFMを使うための条件をまとめておきます。
- 利用対象: すべてのGoogle Workspaceユーザーおよび個人Googleアカウントのユーザー(2026年2月16日〜段階的ロールアウト)
- Google Cloudアカウント: BigQueryの利用が前提(無料枠あり)
- 地域制限: BigQuery MLのTimesFMは全地域で利用可能。 日本からもアクセスできる。
- 料金: BigQueryのクエリ処理料金がかかる(オンデマンドの場合、1TiB処理あたり約$6.25)。 ただし毎月1TBの無料枠あり。
個人のGoogleアカウントでもConnected Sheetsの時系列予測機能を利用できます。 BigQueryのGoogle Cloudアカウントを用意するだけで、すぐに試せます。
「でもお高いんでしょ?」——いえ、無料枠の範囲でかなりのことができます。
さて、ここまで仕組みと使い方を見てきましたが、実際のビジネスではどう活用できるのか、具体的なシナリオを見ていきましょう。
ビジネスでのTimesFM活用シナリオ——需要予測からKPIまで
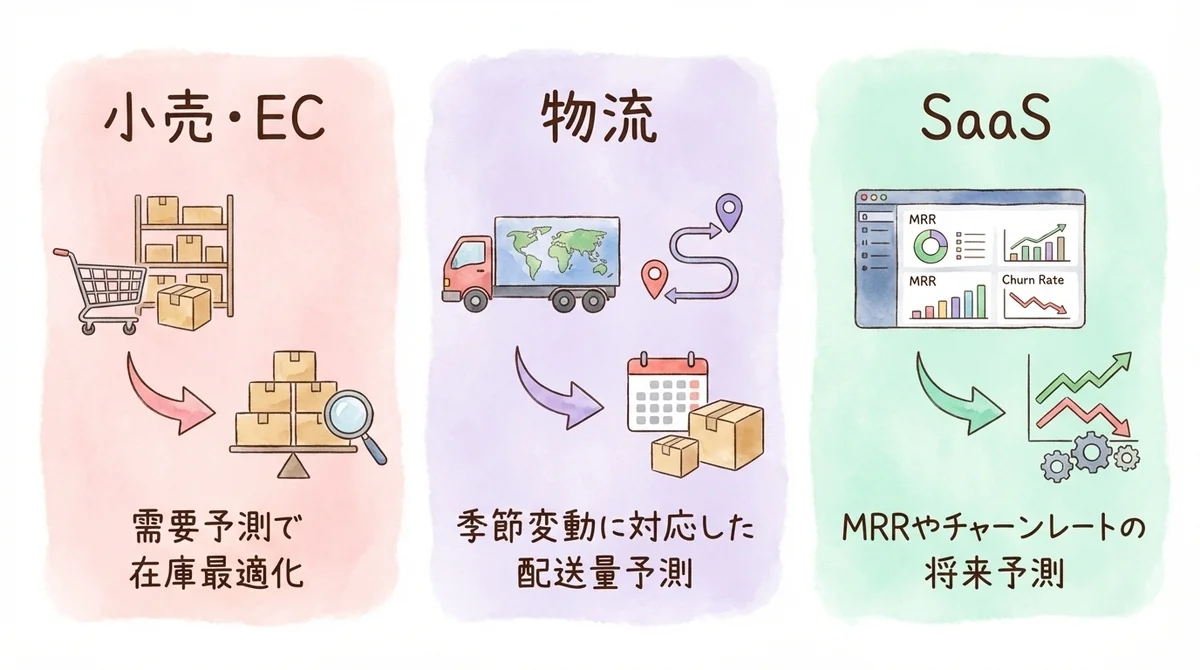
小売・EC:在庫管理と需要予測
一番わかりやすいユースケースが、小売・ECの需要予測です。
従来のアプローチ: データサイエンティストが過去の販売データを整形し、Pythonでモデルを構築・チューニング。 結果が出るまで1〜2週間かかり、毎月更新のたびに同じ作業が繰り返される。
このツールを使えば: 過去の売上CSVをBigQueryにアップロードし、スプレッドシートからAI.FORECASTを実行するだけ。 来月の売上予測が即日出力され、季節変動やセール時期のピーク把握にも対応できる。
発注の過不足(在庫過多による廃棄コスト・欠品による機会損失)を防ぐための意思決定材料を、担当者自身が手軽に作れるようになるわけです。
交通・物流:配送量の季節変動への対応
物流業界でも時系列予測AIは大きな武器になります。
従来のアプローチ: 過去の配送実績を担当者が集計し、経験則や前年比で繁忙期の人員・車両を計画。 急な需要変動に対応しきれないことも多い。
TimesFMなら: 天候・曜日・祝日フラグ(共変量)を加味した需要変動予測が可能。 このモデルの学習データには交通データが大量に含まれているので、この領域は特に精度が期待できます。 繁忙期のピークを事前に数値で把握し、体制構築を早めることができます。
SaaS・サービス業:KPI予測と意思決定の高速化
SaaS企業のKPI予測にも活用できます。
従来のアプローチ: MRRやチャーンレートの将来予測は、Excelの手作業集計か、データチームへの分析依頼待ち。 経営会議での数値が「直感と経験」ベースになりがち。
TimesFMなら: 過去のMRRや解約率データをBigQueryに入れておけば、来月・来四半期の数値をスプレッドシートで即座に可視化できる。 チャーンの増加傾向を早期に検知し、「先手の意思決定」が可能になります。
「うちのデータでもいけるかも」と思った方、次のセクションで既存手法との違いを整理しておきます。
TimesFM vs Prophet vs ARIMA——どれを使うべきか?
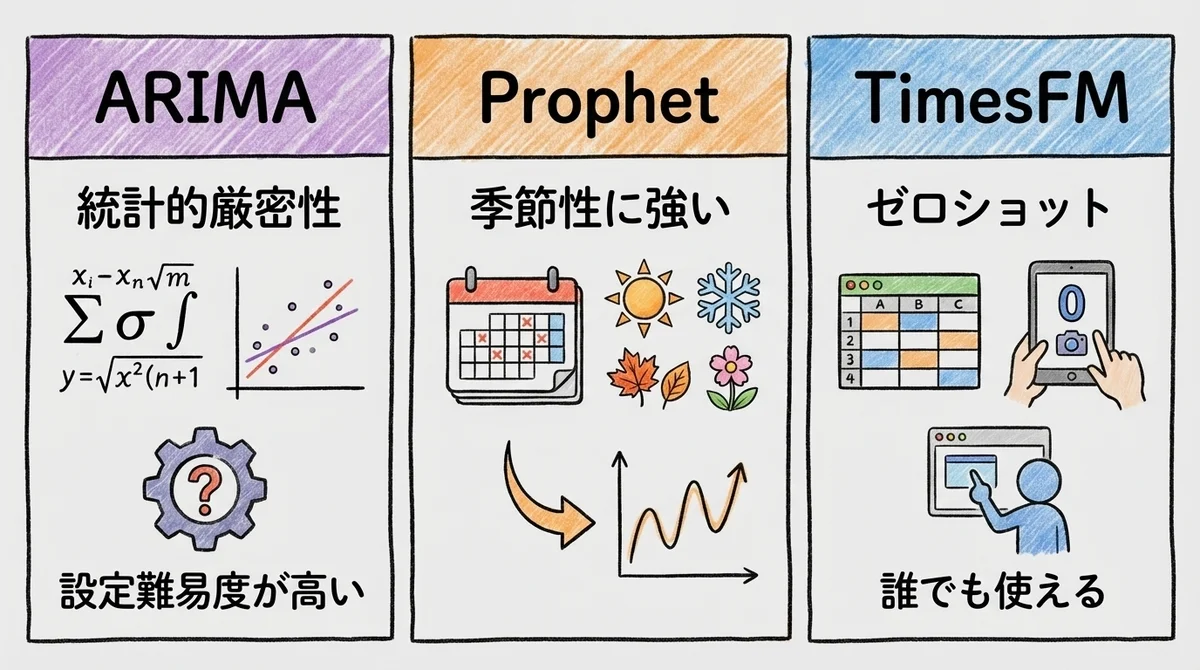
比較表(設定難易度・精度・活用場面)
時系列予測の代表的な手法を比較してみます。
なお、Amazonも「Chronos-2」という時系列基盤モデルを公開しており、一部のベンチマーク(GIFT-Eval)ではTimesFM 2.5を上回る成績を出しています。 この分野は競争が激しく、今後もモデルの進化が加速していきそうです。
「どれを使うべきか」判断フローチャート
迷ったら、こんな感じで選ぶのがおすすめです。
- コードを書きたくない → TimesFM(Connected Sheets経由)
- Pythonが使える + 季節性が重要 → Prophet(季節性分解が得意)
- 統計的な厳密性や検定が必要 → ARIMA(理論的背景が明確)
- どんなデータでもまず手軽に試したい → TimesFM(ゼロショット)
- すでにBigQueryを使っている → TimesFM(BigQuery ML統合が最も楽)
正直、「まず試す」ならTimesFM一択です。
トレーニング不要で即座に結果が出るので、「このデータで予測する意味があるか」の判断材料にもなります。 そこからProphetやARIMAに移行するのは全然ありです。
では、実際に手を動かしてみましょう。
TimesFMを試してみたい人へ——入門3ステップ
ステップ1:スプレッドシートから試す(Connected Sheets経由)
最もハードルが低い方法です。 コマンド一つ打たずに始められます。
- Google Cloudの無料トライアル($300クレジット)に登録
- BigQueryにサンプルの時系列データをアップロード
- GoogleスプレッドシートからConnected Sheetsで接続
- AI.FORECAST関数で予測を実行
BigQueryの無料枠(毎月1TBのクエリ処理)の範囲内であれば、追加費用なしで試せます。
やらない理由がないですよね。
ステップ2:BigQuery MLからSQLで試す
SQLが書ける人なら、BigQueryコンソールから直接TimesFMを使えます。
BigQuery MLのAI.FORECAST関数を呼び出すだけで、既存のBigQueryテーブルに対して時系列予測を実行できます。
異常検知が必要な場合はAI.DETECT_ANOMALIES関数も利用可能です。
Connected Sheetsよりも細かい制御ができるので、パラメータを調整したい場合はこちらがおすすめです。
ステップ3:PythonでTimesFMを本格利用(Colab / ローカル)
Pythonで直接モデルを動かしたい場合は、以下の手順で始められます。
pip install timesfmimport torch
import numpy as np
import timesfm
# 推奨設定
torch.set_float32_matmul_precision("high")
# モデルのロード
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained(
"google/timesfm-2.5-200m-pytorch",
torch_compile=True,
)
# 予測設定(公式推奨パラメータ)
model.compile(timesfm.ForecastConfig(
max_context=1024,
max_horizon=256,
normalize_inputs=True,
use_continuous_quantile_head=True,
force_flip_invariance=True,
infer_is_positive=True,
fix_quantile_crossing=True,
))
# 予測実行
point_forecast, quantile_forecast = model.forecast(
horizon=12,
inputs=[
np.linspace(0, 1, 100), # 線形トレンド
np.sin(np.linspace(0, 20, 67)) # 周期データ
]
)Google Colabなら環境構築不要で即実行できます。 ローカルで動かす場合は、Python 3.11以上と32GB以上のRAMが推奨されています(公式推奨値)。
- GitHub: google-research/timesfm
- Hugging Face: google/timesfm-2.5-200m-pytorch
まとめ——まず試して、データに「未来を語らせる」
LLMが「言葉」を誰でも扱える時代を作ったように、TimesFMは「数字の予測」を誰でも使える時代を作ろうとしています。
このモデルの本質的なインパクトは、「予測の民主化」にあります。
これまで時系列予測は「専門家の仕事」でした。 ARIMAのパラメータを理解し、Pythonを書き、モデルを評価できる人間だけが扱えるものだった。
それが今、スプレッドシートを操作できる人間なら誰でも使えるようになった。 この変化は、ツールの進化というよりも「誰がデータ活用の主役になれるか」が変わったと言えると思っています。
次に取るべきアクションとして、3つ提案します。
- 今日試す(所要時間:30分〜): Google Cloudアカウントを作り、手元の売上や需要データをBigQueryにアップロードして、Connected SheetsでAI.FORECASTを実行してみる。 「こんなに簡単に予測できるのか」という体験が、次の一手を変えます。
- 社内のボトルネックに当てる: 「毎月集計が大変」「予測精度が低くて在庫がずれる」——そういう業務上の課題にTimesFMを当ててみる。 PoC(概念実証)として試す価値は十分あります。
- Pythonで深掘りする: ゼロショットで精度が物足りなければ、ファインチューニングや共変量(祝日・天候フラグ)の追加を試す。 HuggingFaceのモデルページやGitHubのサンプルコードが参考になります。
「データはあるが活用できていない」という企業は多いはずです。 このツールは、その眠っているデータに「未来を語らせる」ための、最も手軽な入口になると思います。
まずはGoogleスプレッドシートから、手元のデータで試してみてください。
よければXもフォローしてもらえると嬉しいです → X(@morphox_ai)
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 4
- 0
-
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 4
- 0
-
- 1
- 0
-
プロンプト画伯
- 3
- 0
-
- 1
- 0
-
- 6
- 0
-
AI脱社畜
- 6
- 0
-
- 4
- 1
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
- 3
- 1
-
- 1
- 0
-
- 1
- 0
-
- 5
- 1
-
- 2
- 0
-
- 3
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 5
- 0













AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます