
はじめまして、もるふぉ@コードをかかないAIエンジニアです。
エンジニアをやりながら、今はほぼコードを書かない開発スタイルに移行しました。
「書けないから書かない」じゃなくて、「書けるから書かなくていい」という話です。
実案件ベースで気づいたことだけ書いています。
AIエージェントのプロンプト、何回書き直しました?
「この条件だとうまくいくのに、別のケースだと壊れる」「ツールコールが安定しない」「なぜこのプロンプトが効くのか、自分でも説明できない」——こういう地味なストレス、エージェント開発してると日常茶飯事ですよね。
Microsoft Researchが公開したOSSフレームワーク「Agent Lightning」は、まさにその苦行を自動化してくれるツールです。
しかもコード変更はほぼゼロ。
今回は、Agent Lightningの仕組みから導入方法、競合フレームワークとの違いまで、実務で使う視点から徹底的に解説していきます。
Agent Lightningとは?Microsoftが作った「AIエージェントの自動トレーナー」
Agent Lightningは、Microsoft Research Asia(上海チーム)が開発・公開しているオープンソースフレームワークです。
MITライセンスで公開されており、GitHub上では15,600以上のスターを獲得しています。
一言で表すなら「AIエージェントに強化学習を後付けできるフレームワーク」ですね。
いわば、プロンプトの改善を人間の職人技からアルゴリズムの仕事に変えてくれる存在です。

従来のエージェント開発が抱えていた「プロンプト職人問題」
LangChainやAutoGenでAIエージェントを構築した経験がある方なら、こんな状況に心当たりがあるはずです。
- プロンプトを少し変えるたびに、全タスクで再検証が必要
- うまくいったプロンプトが別のケースで破綻する
- 「なぜこのプロンプトが効くのか」を論理的に説明できない
- ツールコールの精度が安定しない
これ、手動でやり続けるのは正直しんどいんですよ。
「動いた!」と思った次の瞬間、別のテストケースで落ちる。
あの徒労感、わかる方も多いんじゃないでしょうか。
AIエージェント開発を追っているAvi Chawla氏も同様の課題を指摘しています。
「AIエージェントの開発は最初の一発でうまくいくことがほぼない。開発者はプロンプトの微調整に何日も費やし、サンプルを追加して、良くなることを祈っている」というのが現実です。
Agent Lightningが解決すること
Agent Lightningのアプローチはシンプルかつ強力です。
既存のエージェントコードをほぼそのまま、強化学習や自動プロンプト最適化で自動的に改善する。
具体的にできることは以下の3つです。
- コード変更ほぼゼロで既存エージェントに学習機能を追加
- LangChain、AutoGen、CrewAI、OpenAI Agents SDKなど主要フレームワークに対応
- マルチエージェントシステムでも個別エージェントを選択的に最適化可能
「自分で書いたエージェントが、自分で賢くなっていく」という体験は、一度味わうとちょっと感動しますよ。
では、実際にどれくらいの改善が出るのか。数字を見てもらうのが一番早いです。
実際のパフォーマンス改善事例と数値データ
「で、実際どれくらい良くなるの?」——ここが一番気になるところですよね。
APO検証事例:Text-to-SQLエージェント(LangChain)
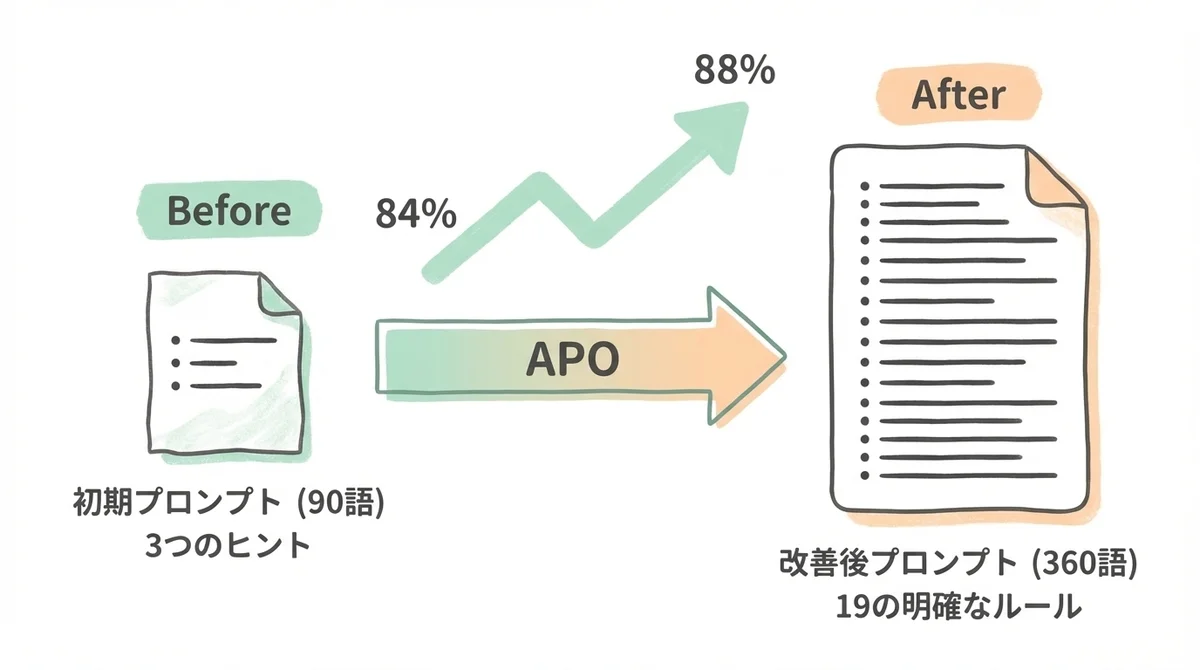
あるコミュニティ開発者がAPO(自動プロンプト最適化)をSpiderデータセットのText-to-SQLタスクに適用した検証では、以下の結果が報告されています(DEV Community、bigdata5911氏による検証事例。公式ベンチマークではありません)。
たった2ラウンドの最適化で、正解率が84%から88%に向上しています。
ここで注目してほしいのは、プロンプト自体の変化なんですよ。
- 語数:90語 → 360語(4倍に拡張)
- 制約条件:3つの曖昧なヒント → 19の明示的ルール
- スキーマチェックやSQLバリデーション機能が自動で追加
つまり、人間が「うーん、ここにバリデーションルール足してみるか……」と手探りでやっていた作業を、アルゴリズムが体系的にやってくれるわけです。
想像してみてください。
あなたが数日かけて試行錯誤するプロンプト改善が、2ラウンドで自動完了する世界です。
RAGエージェント・数学QAでの改善(公式論文)
公式論文(arXiv: 2508.03680)では、Llama-3.2-3B-Instructをベースモデルとして3つのタスクで検証が行われています。
- RAG(MuSiQue):21百万のWikipedia文書に対する検索クエリの生成精度が安定的に向上。報酬関数はフォーマット正確性(10%)と正解性スコア(90%)の組み合わせ
- 数学QA(Calc-X):ツールコール(電卓)の呼び出しタイミングと結果の統合精度が一貫して改善。最も早く学習が収束
3つのタスクすべてで安定した報酬曲線の上昇が確認されており、フレームワークに依存しない汎用性の高さが実証されています。
数字を見て「これ使えそうだな」と思った方、次は仕組みを見ていきましょう。
Agent Lightningの仕組み:Training-Agent Disaggregationアーキテクチャ
Agent Lightningの技術的な核心は「Training-Agent Disaggregation」という設計思想にあります。
名前は仰々しいですが、やっていることは明快です。
エージェント実行と学習の完全分離がキモ
従来のアプローチでは、エージェントの実行コードと学習ロジックが密結合していました。
Agent Lightningはこれを完全に分離します。
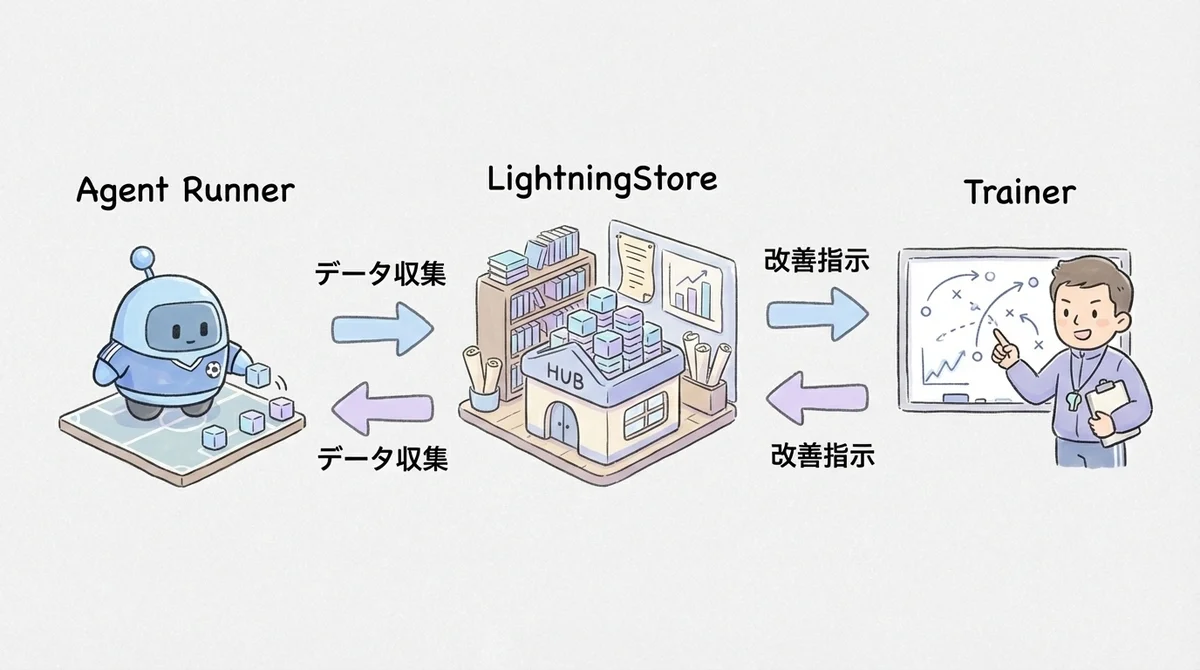
- Agent Runner:エージェントがタスクを実行する環境。既存コードがそのまま動く
- Trainer:学習アルゴリズムを管理し、改善されたパラメータをエージェントにプッシュ
- LightningStore:両者の間でデータを仲介する中央ハブ
いわば、サッカーチームでいうところの「選手」と「コーチ」と「データ分析室」の分業ですね。
選手(Agent Runner)はひたすら試合をして、データ分析室(LightningStore)が全試合のデータを蓄積して、コーチ(Trainer)が分析結果をもとに改善指示を出す。
この分離によって、エージェントの実行環境と学習環境を別々のリソース上で動かせます。
スケーリングも容易で、複数のエージェントを並列に走らせながら同時に学習を進めることが可能です。
これが地味にすごいんですよ。
v0.3.0では、大量のランナーを同時実行した場合にv0.2.2比で最大15倍のスループット向上を達成しています。
LightningStoreによるデータ収集の流れ
エージェントが動作するとき、Agent Lightningは裏側でイベントデータを自動収集します。
流れはこうです。
- エージェントが通常通りタスクを実行
agl.emit_xxx()ヘルパーまたはトレーサーが、プロンプト・ツールコール・報酬を自動キャプチャ- キャプチャされたデータが構造化スパンとしてLightningStoreに蓄積
- 学習アルゴリズムがスパンを読み取り、改善されたプロンプトやポリシーウェイトを生成
- Trainerが更新をエージェントにプッシュ
ここがポイントなんですが、エージェント側のコードを書き換える必要はほとんどありません。
数行のヘルパーを追加するか、トレーサーに自動収集させるかの選択です。
「え、それだけ?」って思いますよね。
本当にそれだけなんです。
3つの最適化アルゴリズム(APO / VERL / SFT)の使い分け
Agent Lightningでは、目的に応じて3つのアルゴリズムを使い分けます。
特に注目すべきはLightningRLというアルゴリズムです。
これはマルチステップのエージェントタスクにおいて、各LLMリクエストがどれだけ最終結果に貢献したかを判定する「クレジット割り当てモジュール」を持っています。
つまり、「このステップのこの判断が良かったから報酬を多めに」「ここの判断はイマイチだったから改善しよう」と、エピソード全体の報酬を個々のアクションに適切に分配するんです。
これによって、PPOやGRPOといった既存の単一ステップRLアルゴリズムをそのまま適用できるようになっています。
まずはAPOから始めるのがおすすめです。
APIキーさえあれば動くので、GPUを用意する必要がありません。
さて、ここからは対応フレームワークと実際の導入方法を見ていきましょう。
対応フレームワーク一覧:LangChain・AutoGen・CrewAIで即使える
Agent Lightningの大きな強みは、既存のエージェントフレームワークをそのまま活かせる点です。
フレームワーク別の対応状況
現在、以下のフレームワークに対応しています。
「自分が今使っているフレームワークでそのまま動く」——これ、導入のハードルを劇的に下げてくれるんですよね。
フレームワークを乗り換える必要がないので、既存のコードベースをそのまま活かせます。
マルチエージェントシステムへの適用方法
複数のエージェントが協調するマルチエージェントシステムでも、Agent Lightningは威力を発揮します。
例えばText-to-SQLの検証では、3エージェント構成のシステム(SQL writer・checker・rewriter)で2つのエージェントを選択的に最適化しています。
全エージェントを一括で学習させるのではなく、ボトルネックになっているエージェントだけをピンポイントで改善できる。
これ、マルチエージェントを運用している方なら「それ欲しかった」と思うはずです。
では、実際にインストールして動かしてみましょう。
Agent Lightningのインストールと初期セットアップ
実際に手を動かしてみましょう。
セットアップは驚くほどシンプルです。
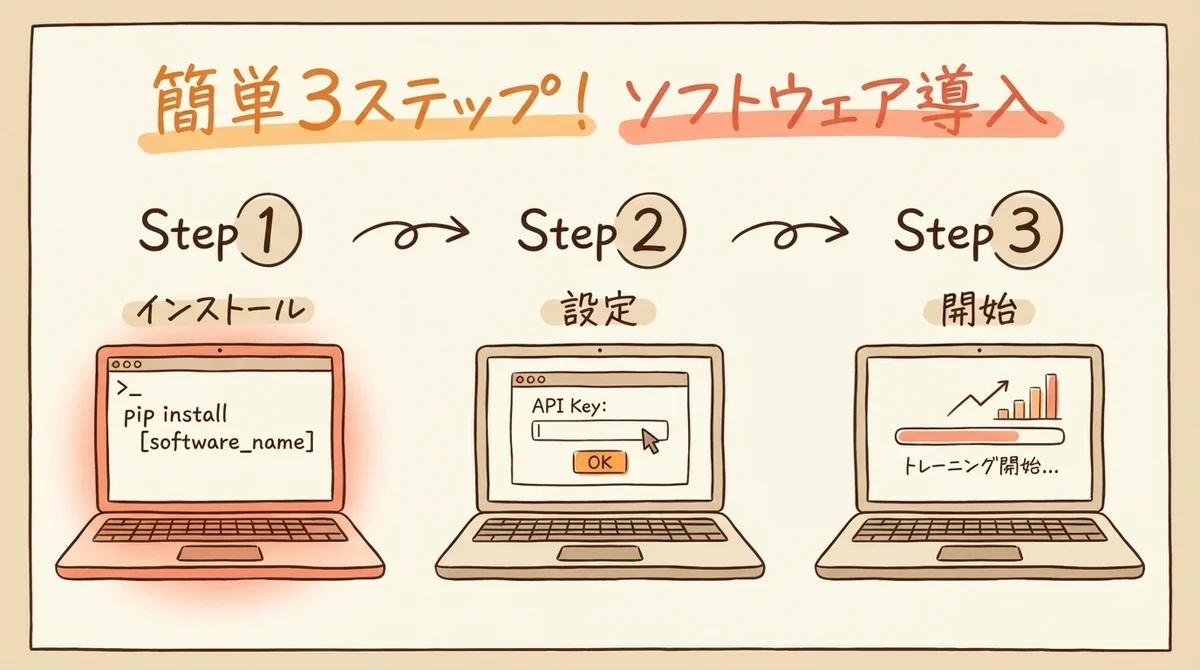
動作環境とpip installの手順
# 基本インストール(Python 3.10以上)
pip install agentlightning
# APOを使う場合はOpenAI APIキーを設定
export OPENAI_API_KEY="your-api-key"これだけです。
本当にこの2行で始められます。
「え、本当にこれだけ?」って思った方、はい、本当にこれだけです。
APOでTraceToMessagesアダプターを使う場合は openai >= 1.100.0 が必要になるので注意してください。
macOS・Windowsユーザー向けの回避策
ひとつ注意点があります。
Agent LightningはLinux(Ubuntu 22.04以上)を推奨環境としています。
macOSやWindowsでネイティブに動かすのは現時点では非推奨です。
「macOSで開発してるんだけど……」という方、安心してください。
回避策があります。
- WSL2(Windows):Ubuntu環境をWindows上に構築して実行
- Docker:Linux環境をコンテナで用意
- Google Colab:クラウド上で手軽に試す
個人的にはDocker環境で動かすのが一番手堅いと思っています。
開発環境を汚さずに済みますし、チームでの環境統一も楽です。
最小構成のコード例:APOでエージェントをトレーニング
APOで最初のトレーニングを回す場合のコード全体像はこんな感じです。
import agentlightning as agl
from openai import AsyncOpenAI
# 1. エージェントを定義(既存コードに@agl.rolloutを追加するだけ)
@agl.rollout
def room_selector(task, prompt_template: agl.PromptTemplate) -> float:
# ... 既存のエージェントロジック ...
reward = grader(result, task["expected"])
return reward
# 2. アルゴリズムとTrainerを設定
openai = AsyncOpenAI()
algo = agl.APO(openai)
trainer = agl.Trainer(
algorithm=algo,
n_runners=8, # 8エージェントを並列実行
initial_resources={
"prompt_template": baseline_prompt()
},
adapter=agl.TraceToMessages(),
)
# 3. データセットを読み込んでトレーニング開始
trainer.fit(
agent=room_selector,
train_dataset=dataset_train,
val_dataset=dataset_val,
)ちょっと注目してほしいんですが、既存のエージェント関数に @agl.rollout デコレーターを付けて、Trainer を設定して fit() を呼ぶだけなんです。
scikit-learnの model.fit() に近い感覚ですね。
エージェントのトレーニングが、機械学習のモデル訓練と同じインターフェースで回せる。
n_runners=8 で8つのエージェントを並列に走らせているのもポイントです。
データ収集を効率的に行うことで、学習の収束も早くなります。
ここまで来たら、次に気になるのは「他のフレームワークと比べてどうなの?」ですよね。
Agent Lightning vs 競合フレームワーク比較(DSPy・TextGrad・PromptWizard)
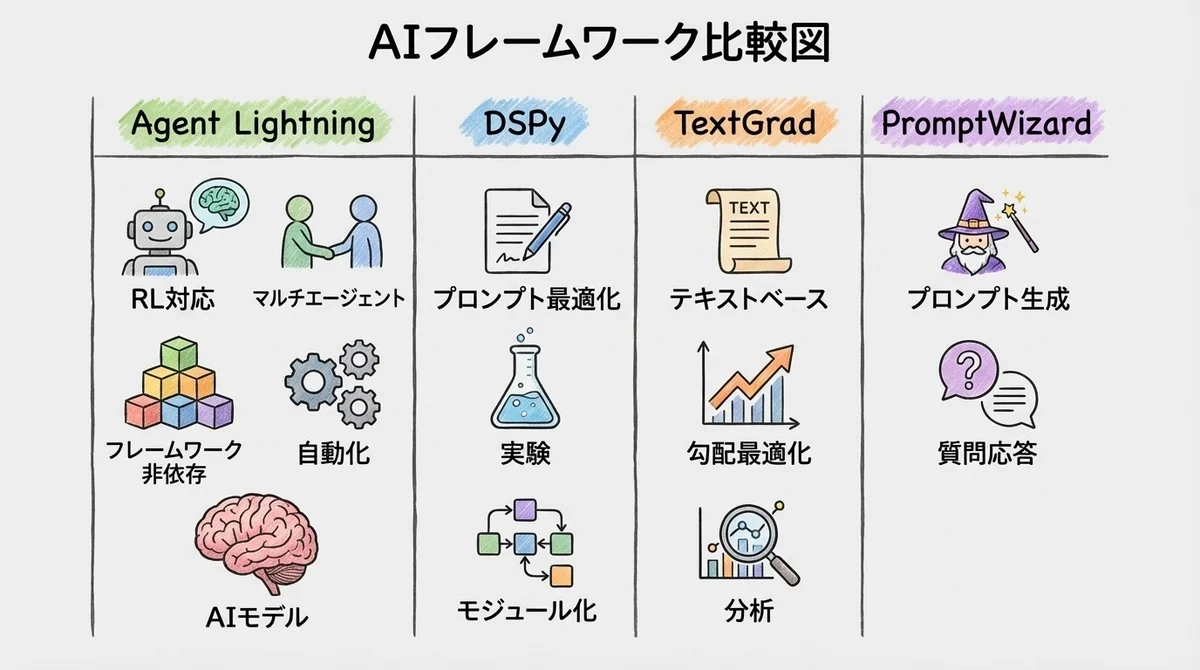
「Agent Lightningはわかった。でも他のフレームワークと何が違うの?」という疑問にも答えておきます。
比較表:機能・対応範囲・学習コスト
どれを選ぶべきか:判断のポイント
フレームワーク選定の基準は、大きく分けて3パターンです。
1. 「既存のLangChain/AutoGenエージェントをそのまま改善したい」→ Agent Lightning
コードを書き換えずに学習機能を後付けできるのはAgent Lightningだけです。
特にマルチエージェントシステムを運用している場合、個別最適化ができる点が決定的な差別化ポイントになります。
2. 「一からAIパイプラインを設計し直したい」→ DSPy
DSPyは宣言的なプログラミングモデルで、パイプライン全体を再設計するアプローチです。
新規プロジェクトで設計の自由度が高い場合に向いています。
3. 「特定のタスクで出力品質をピンポイントで上げたい」→ TextGrad
TextGradは「テキスト版の自動微分」というコンセプトで、個別の出力を反復的に改善します。
コーディングタスクや科学的Q&Aなど、単一タスクの精度を極限まで追求したい場合に強いです。
PromptWizardは同じMicrosoft Research製ですが、プロンプト設計に特化したツールです。
Agent Lightningの方がスコープが広く、RL(強化学習)による重み更新まで含むため、より包括的な自動最適化が可能です。
よくある疑問とトラブルシューティング
APO実行時のコストは?
APOはOpenAI APIを使うため、API利用料が発生します。
Text-to-SQLの事例(50サンプル x 2ラウンド)では、GPT系モデルのAPI呼び出しが主なコストです。
プロンプトの評価・改善で複数回のAPI呼び出しが走るため、データセットのサイズとラウンド数に比例してコストが増えます。
まずは小さなデータセット(10〜20件)で試して、効果を確認してからスケールアップするのが賢いやり方です。
いきなり大規模データで回すのは避けましょう。
VERLを使うにはGPUが必要?
はい、VERLは強化学習でモデルの重みを更新するため、GPU環境が必須です。
論文ではLlama-3.2-3B-Instructで検証されていますが、DeepWerewolfプロジェクト(人狼ゲームのエージェントRL訓練)やYoutu-Agent(Tencent)では128 GPUでのトレーニングも検証済みです。
個人で試す場合はAPOから始めて、本格的にモデルを鍛えたくなったらVERLに移行するのが現実的なパスだと思います。
ステップを踏んで進められるのもAgent Lightningの良いところですね。
関連プロジェクトの活用
エージェントRLの分野では、Agent Lightningと関連する注目プロジェクトが増えています。
- DeepWerewolf:人狼ゲームのエージェントをRLで訓練(AgentScope + Agent Lightning)
- AgentFlow:Stanford発、Flow-GRPOアルゴリズムでlong-horizonタスクに対応する独立研究プロジェクト
- Youtu-Agent:Tencent製、128 GPUでのRLトレーニングを検証済み
こうしたプロジェクトのコードを参考にすることで、自分のユースケースへの適用方法が見えてくるはずです。
まとめ:「プロンプト職人」から「エージェントトレーナー」の時代へ
Agent Lightningの使い方を日本語で解説してきましたが、このフレームワークが示しているのはAIエージェント開発のパラダイムシフトです。
- プロンプトを手動で改善する → アルゴリズムが自動で最適化する
- フレームワークに縛られる → 既存コードをそのまま活かせる
- 全体を一括改善する → 個別エージェントを選択的にトレーニングする
Gartnerの予測によれば、2026年末までに企業アプリケーションの40%がタスク特化型AIエージェントを組み込むとされています(2025年は5%未満から急増、Gartner, August 2025)。
エージェントの数が爆発的に増える中で、「育て方」を知っているかどうかは、これからの開発者にとって大きな差になるはずです。
まずは pip install agentlightning から始めてみてください。
コマンド1つ、5分で試せます。
APOで既存エージェントのプロンプトが自動改善されていく様子を見ると、「ああ、これが次のスタンダードになるんだな」と実感できると思います。
参考リンク:
- GitHub: microsoft/agent-lightning
- 公式ドキュメント
- arXiv論文: Agent Lightning: Train ANY AI Agents with Reinforcement Learning
- Microsoft Research Blog
- Gartner予測(2025年8月)
よければXもフォローしてもらえると嬉しいです → X(@morphox_ai)
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます