
はじめまして、もるふぉ@コードをかかないAIエンジニアです。
エンジニアをやりながら、今はほぼコードを書かない開発スタイルに移行しました。
「書けないから書かない」じゃなくて、「書けるから書かなくていい」という話です。
実案件ベースで気づいたことだけ書いています。
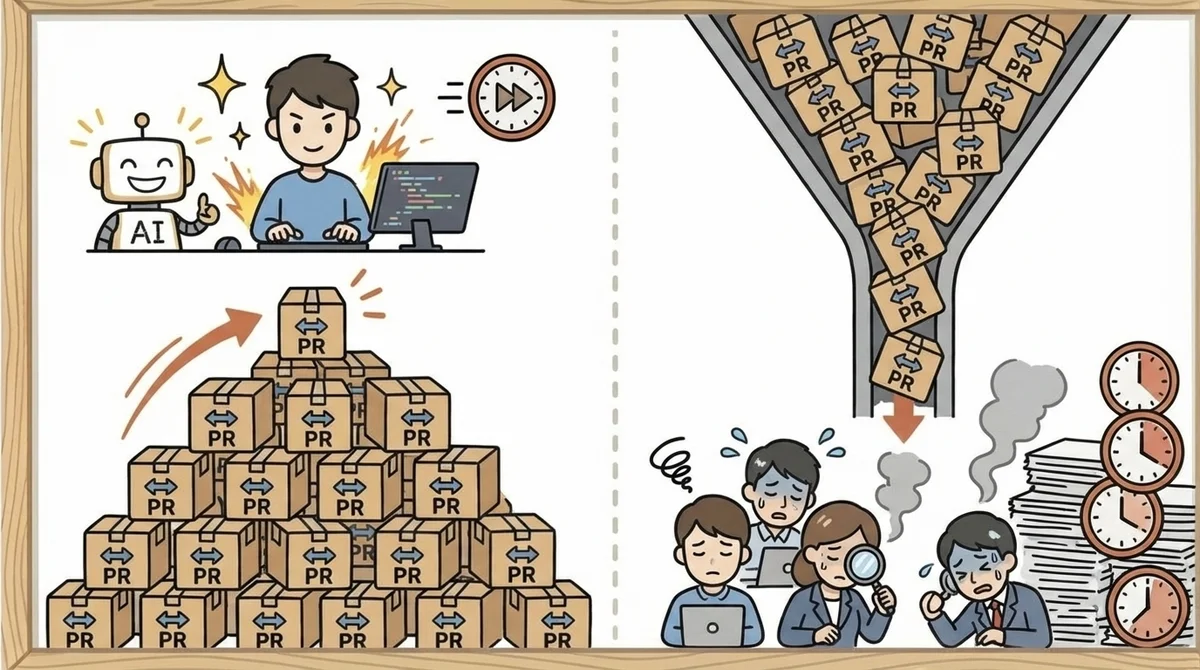
「AI使ってるのに、なぜかチーム全体は速くなってない」。
そんなモヤモヤ、ありませんか。
個人の生産性は確かに上がった。
PRもバンバン出る。
でもレビューが追いつかない、品質がバラつく、結局誰が何を見ればいいのか分からない。
自分もClaude Code(Opus 4.6)で日々の開発を回しているシニアエンジニアですが、最初はこの「人間とAIの線引き」にかなり悩みました。
結論から言うと、AIエージェントに任せるのは「How(どうやるか)」、人間が握るのは「Why(なぜやるか)」と「What(何をやるか)」。
この記事では、OpenAI・Anthropic・Stripeといった先進企業の事例をもとに、ハーネスエンジニアリングにおける「人間がやること」「AIがやること」の役割分担を整理します。
最後にチェックリストも用意したので、明日から自分のチームで使ってもらえるはずです。
なぜ今、役割分担を明確にするのか
「全部AIエージェントに任せたらどうなるか」という実験から分かったこと
OpenAIでは、3名のエンジニアが「手書きコード一切禁止」という制約のもと、Codexだけで社内製品を構築する実験を行いました。
5ヶ月で約100万行のコードが生成され、コードベースのほぼすべてがAI自身によって書かれたそうです。
ここで面白いのが、OpenAIが意図的に採用した「Ralph Wiggumループ」という仕組みです。
エージェントが自分のPRを自分でレビューし、さらに他のエージェントにもレビューを依頼して、全員が満足するまでループを繰り返すんですよ。
つまり、AIエージェントによるコードレビューが自律的に回り続ける状態を最初から設計として組み込んでいます。
「Codexが見えないものは存在しない」という原則をOpenAI自身が語っていますが、これは裏を返せば「AIが見えない問題は誰かが見なければならない」ということです。
100万行をAIが書いても、人間の役割はなくならない。
むしろ、何を見るべきかの判断がこれまで以上に重要になっているんですよね。
役割が曖昧なままだと起きること
ここ、ちょっと注目してほしいデータがあります。
DORA 2025レポート(約5,000人を対象にした調査)は「AIで個人は速くなっても、組織全体のデリバリーパフォーマンスは期待ほど改善しない」と指摘しています。
DORA 2025の知見を裏付けるFaros AIのテレメトリデータ(10,000人以上の開発者対象)では、こんなデータが出ています。
- マージPR数: +98%
- コードレビュー時間: +91%
- PRサイズ: +154%
想像してみてください。
PRが2倍に増えて、1つ1つのサイズも2.5倍。
レビューする側の負荷がどれだけ膨らむか。
個人が速くなった恩恵が、組織の別の場所でボトルネックとして出てくるわけです。
Findyの実験結果もこれを裏付けていて、シニア層は3〜5割の生産性向上が見られた一方、若手層は2〜3割の生産性低下が報告されています。
AIは力を増幅するけれど、力そのものを作り出すわけではないんですよね。
だからこそ「何を人間がやり、何をAIエージェントに任せるか」の線引きが、今すぐ必要なんです。
では、そもそもハーネスエンジニアリングとは何か。
まだピンと来てない方のために、30秒で整理します。
ハーネスエンジニアリングとは何か(30秒で理解する)
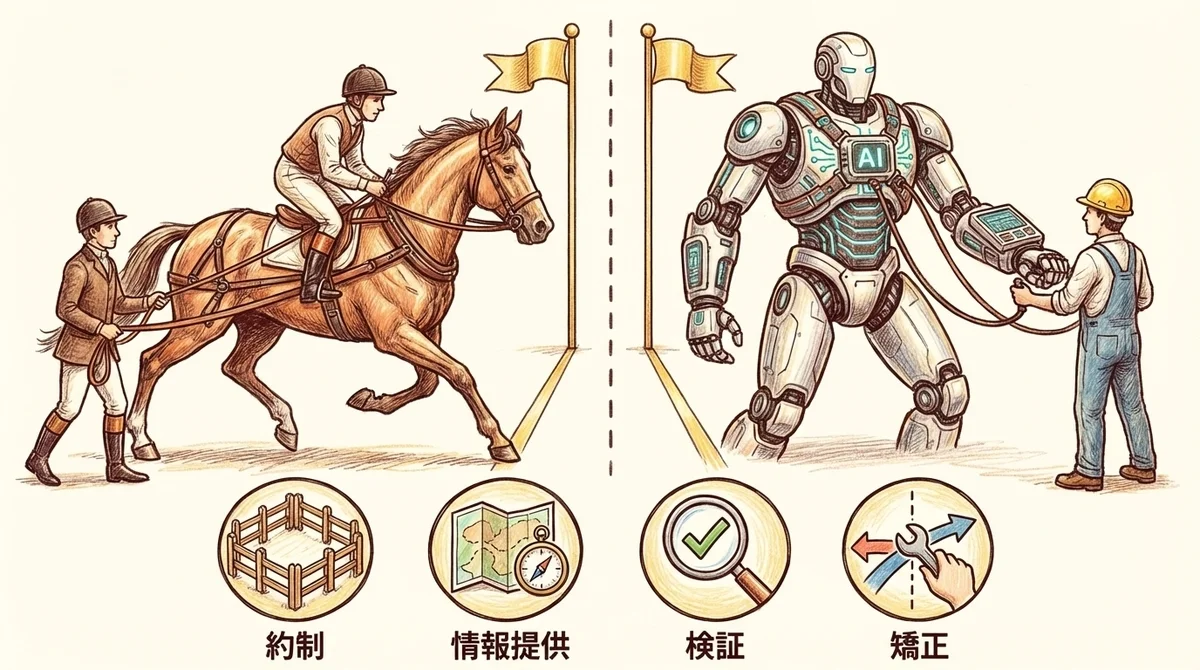
馬具(ハーネス)のアナロジーで考える
ハーネスエンジニアリングの「ハーネス」は、もともと馬具のことです。
馬は強い力を持っていますが、ハーネスなしでは暴れるだけで目的地には着きません。
AIエージェントも同じで、すごい実装力を持っていても、制御する仕組みがなければ暴走します。
この「制御する仕組み」を設計・構築するのがハーネスエンジニアリングです。
で、これが地味にすごい話なんですが、LangChainはモデルを一切変えずにハーネスだけを改善して、ベンチマークスコアを52.8%から66.5%に向上させました。
モデルの性能じゃないんですよ。
ハーネスの設計だけで13.7ポイントも上がる。
つまり、自分たちが設計する「AIの使い方」そのものが、AIの性能以上にアウトプットを左右するということです。
OpenAIとHashiCorpが示した定義
HashiCorp共同創業者のMitchell Hashimotoは、ハーネスエンジニアリングを「エージェントがミスをしたとき、そのミスが二度と起きないようにソリューションを設計すること」と定義しています。
いわば、新メンバーがやらかしたときに「次からこうしてね」じゃなくて「そもそもやらかせない仕組みにしよう」と考えるのと同じ発想ですね。
より具体的に分解すると、ハーネスには4つの役割があります。
- 制約(Constrain): エージェントに何ができるかを制限する
- 情報提供(Inform): エージェントに何をすべきかを知らせる
- 検証(Verify): エージェントが正しく実行したかを検証する
- 修正(Correct): エージェントが間違ったときに修正する
この4つの役割のうち、どれを人間が担い、どれをAIエージェント(自動化)に任せるかが、この記事のテーマです。
いよいよ本題に入ります。
まずは「人間がやるべきこと」から見ていきましょう。
人間がやるべきこと(WhyとWhatの担い手)

目的・方向性の決定(Why)
「なぜこの機能を作るのか」「ビジネス上の優先度はどうか」「ユーザーにとって本当に必要か」。
これらの判断はAIにはできません。
AIはWhyを与えられて初めて動けます。
たとえば「検索機能を作って」とだけ言われても、AIは全文検索なのかファセット検索なのか、そもそも検索が本当に必要なのかは判断できないですよね。
人間がWhyを握り続けることが、ハーネスエンジニアリングの大前提です。
コンテキストの言語化(CLAUDE.md・AGENTS.md)
AIエージェントに仕事を任せるなら、コンテキストを言語化しなければなりません。
Claude Codeの生みの親であり責任者を務めるBoris Chernyは、CLAUDE.mdを約2,500トークンの「コントロールパネル」として設計しています。
2ヶ月以上にわたって小さな編集すら手でしないほどAIに実装を委ねていますが、その裏側にはこの緻密なコンテキスト設計があるわけです。
「大変そう」って思いますよね。
でも、コンテキスト設計は一度やれば資産になります。
プロジェクトに新メンバーが入るたびにオンボーディング資料を作るのと同じで、一度書いてしまえばずっと使い回せるんですよ。
OpenAIのAGENTS.mdも興味深くて、約100行の目次にとどめ、詳細はdocs/ディレクトリに段階的に配置する設計になっています。
ここで重要なのは、CLAUDE.mdやAGENTS.mdを書くのは人間の仕事だということです。
m2AIの記事では「Hook単体ではClaudeの行動を制御できない」と報告されており、CLAUDE.md + Hook + Skillsの3つが最小構成として必要とされています。
さらにタグで優先度を明示すると遵守率が劇的に向上するという知見もあります。
アーキテクチャと制約の設計
アーキテクチャそのものがハーネスになるという視点は、ここがかなり重要です。
DDD/レイヤードアーキテクチャで設計すれば、AIエージェントが「どのファイルを触るべきか」が自明になります。
dependency-cruiserのようなツールで依存方向違反を機械的に検出すれば、AIが勝手にアーキテクチャを壊すことを防げます。
つまり、人間がアーキテクチャを正しく設計すれば、AIへの指示が自然と簡潔になるんですよ。
いわば、よくできたRailsアプリなら「app/modelsにモデル書いて」だけで通じるのと同じ原理です。
ガードレールの設計(CI・コードレビュー自動化・型チェック)
StripeのBlueprintsパターンが参考になります。
エージェントが自律的に動くステップと、決定論的に検証するステップを交互に配置する設計です。
Stripeのエンジニアは「モデルがシステムを動かすのではない。システムがモデルを動かす」と明言しています。
これ、エンジニアなら鳥肌が立つ発想じゃないですか。
具体的には、ローカルリント(5秒以下)を通してからCI実行、失敗したら自動修正、1回だけ再実行、2回失敗したら人間に返却というフローです。
多層防御の考え方も有効で、型システム → 静的解析 → テスト → AIレビュー → 人間のレビューという順に防御層を重ねます。
このガードレールを設計するのは人間の仕事であり、AIエージェントに「自分を縛るルール」を作らせるのは構造的に無理があります。
実は自分も最初、CLAUDE.mdにルールを書かないままClaude Codeに実装を任せたことがあって、RailsのAPIコントローラーがN+1クエリだらけのコードを量産してしまったことがあります。
「includes書いてくれると思ってた」のは完全に自分の思い込みで、ガードレールがなければAIはただ動くだけなんですよね。
その失敗以来、CLAUDE.mdにはパフォーマンス要件とアーキテクチャルールを必ず書くようにしています。
品質基準の定義と最終承認
カスタムリンターのエラーメッセージに修復手順を埋め込むというOpenAIのアプローチは秀逸です。
エラーが出たときにAIが「どう直せばいいか」を即座に理解できるようになります。
品質基準を定義し、その基準をAIが読める形で記述する。
これは人間にしかできない仕事です。
エージェントの失敗を「環境改善」に変える判断
AIエージェントが失敗したとき、その個別のミスを修正するのではなく、CLAUDE.mdやガードレールを改善して「二度と起きない」ようにする。
まさにHashimotoの定義そのままですが、この判断ができるのは人間だけです。
Anthropicでは10〜20%のセッションが中止されますが、並列実行しているので問題にならないそうです。
失敗を個別対処ではなく環境改善に変える思考が、ハーネスエンジニアリングの本質だと感じています。
ここまでが人間の領域です。
では、AIはどこまでやれるのか。
正直、ここからがワクワクする話です。
AIエージェントがやるべきこと(Howと実行の担い手)

コード実装(反復的なHowの処理)
前述のとおり、Boris Chernyが実証しているように、コード実装はAIエージェントの領域です。
コードベースのほぼすべてをAIが生成するという事実が、これを裏付けています。
人間が設計したWhatを、AIエージェントがHowに変換して実装する。
この分業が最も効率的です。
コードレビューと品質チェックの自動化
AIによるコードレビュー自動化は、多層防御の一層として機能します。
エージェントを役割ごとに分離するアプローチも効果的で、tdd-web-engineer、code-reviewer、perf-reviewer、spec-reviewer、task-issue-creatorのように専門化させることで精度が上がります。
ただし、最終承認は人間が行うという前提です。
テスト実行・エラー修正の自律ループ
AIが書く → テスト実行 → 失敗 → 修正 → 再実行のループを自律的に回せるのは大きな強みです。
Chrome DevTools MCPを使えば、エージェントに「目」を与えることができます。
ブラウザの実際の表示を確認しながらテストを修正できるので、UIの問題も自律的に解決できるようになります。
PR作成と並列処理
ここが一番インパクトのある話かもしれません。
Stripeの事例が象徴的です。
Slackで5タスクをMinionsに投げてコーヒーを取りに行き、戻ると5つのPRが出来ている。
週に1,300以上のPRがマージされ、そのすべてが人間の手書きコードゼロだそうです。
想像してみてください。
コーヒー1杯飲んでいる間に、5つのPRが待っている世界です。
Anthropicでもローカル5セッション + Web 5〜10セッション同時実行という使い方をしています。
「完全に正しくないPRでも、エンジニアが20分で磨けるなら十分な勝利」というStripeの考え方は、役割分担の本質を突いています。
ドキュメントの初稿生成
ドキュメント作成はAIエージェントが得意な領域です。
人間が構成と品質基準を定義し、AIが初稿を生成し、人間がレビューする。
このフローが最も効率的だと実感しています。
判断が難しいグレーゾーン
コードレビューはどこまで人間がやるべきか
「コードを全行読むようなレビューはしていない」というエンジニアの声があります。
多層防御が機能していれば、人間レビューの粒度は変えられるという考え方です。
型チェック・リンター・AIレビューを通過したコードであれば、人間はアーキテクチャレベルの妥当性だけ確認すれば十分かもしれません。
ただし、これはガードレールの成熟度に依存します。
ガードレールが未整備な段階で人間レビューを省略するのは危険です。
設計判断の委譲ラインをどう引くか
「このAPIのレスポンス形式をどうするか」はAIに任せてよい判断です。
一方で「マイクロサービスに分割するかどうか」は人間が決めるべきです。
判断基準はシンプルで、影響範囲が広く、可逆性が低い判断は人間がやるということです。
逆に、影響範囲が限定的で、後から変更できる判断はAIエージェントに任せて問題ありません。
「信頼できるまで」の育て方
新メンバーの育成と同じで、最初は細かくレビューし、信頼度が上がったら粒度を下げていくのが現実的です。
CLAUDE.mdの改善サイクルが「育成」に相当します。
AIが失敗するたびにCLAUDE.mdを改善し、同じ失敗が起きなくなったら、そのタスクへの監視を緩める。
この繰り返しで、徐々にAIエージェントに委譲できる範囲が広がっていきます。
ハーネスエンジニアリングの人間 vs AI 役割分担チェックリスト

以下の表を自チームの状況に合わせてカスタマイズして使ってください。
ポイントは、人間の仕事が「Why(なぜやるか)」と「What(何をやるか)」に集中し、AIエージェントの仕事が「How(どうやるか)」に集中していることです。
シニアエンジニアとしての実感
役割を明確にしたら変わったこと
自分がこの役割分担を意識するようになってから、大きく変わったのは「設計に集中できるようになった」ことです。
以前はコードを書きながら設計も考えていましたが、今はCLAUDE.mdとアーキテクチャの設計に集中し、実装はClaude Codeに任せています。
並列でセッションを走らせることで、1人で複数タスクを同時に進められるようになりました。
もちろん最初からうまくいったわけではなく、CLAUDE.mdの試行錯誤に時間がかかりました。
でも、その投資は確実にリターンがあります。
これから求められる人間側のスキル
コードを書く力そのものより、以下の3つのスキルが重要になると感じています。
- コンテキストを言語化する力: CLAUDE.mdやAGENTS.mdに「何を書くか」を判断する能力
- アーキテクチャを設計する力: AIエージェントが迷わない構造を作る能力
- AIの出力を評価する力: 生成されたコードやPRの品質を素早く判断する能力
これらはどれも「シニアエンジニアが元々持っていたスキル」の延長線上にあります。
AI時代だからといって、まったく新しいスキルが必要になるわけではありません。
ここまで読んでくれた方には、きっと安心感があるんじゃないでしょうか。
よくある質問(Q&A)
Q: ハーネスエンジニアリングで人間は何をすればいいですか?
A: 大きく3つです。(1)「なぜ作るか」のWhyを決める、(2)CLAUDE.mdやアーキテクチャでAIエージェントが動ける環境を設計する、(3)AIの出力を最終承認し、失敗をガードレール改善に変える。コード実装・コードレビュー自動化・テスト実行はAIエージェントに委ねます。
Q: AIエージェントに任せてはいけない作業はどれですか?
A: 影響範囲が広く、可逆性が低い判断はすべて人間が担うべきです。具体的には、要件定義・アーキテクチャ設計・ガードレール設計・品質基準の定義・障害対応の優先度判断などが該当します。
Q: CLAUDE.mdには何を書けばいいですか?
A: プロジェクトの技術スタック・アーキテクチャルール・パフォーマンス要件・やってはいけないことの4つを最低限書きましょう。タグで重要度を明示すると遵守率が上がります。Boris Chernyは約2,500トークンを目安としています。
まとめ:ハーネスエンジニアリング時代の人間の価値
人間の価値は「コードを書くこと」から「AIエージェントを正しく動かす仕組みを作ること」にシフトしています。
整理すると、人間の仕事は3つです。
- Whyを握る: なぜ作るのか、何を優先するのかを決める
- ハーネスを設計する: CLAUDE.md、アーキテクチャ、ガードレールを構築する
- 品質を担保する: 最終承認と、失敗を環境改善に変える判断をする
Howの実行はAIエージェントに任せる。
この役割分担を明確にすることが、個人にとってもチームにとっても最初の一歩です。
まずは今日、自分のプロジェクトのCLAUDE.mdを開いて(なければ作って)、「人間が判断すべきこと」を1行だけ書いてみてください。
5分で終わります。
その小さな一歩が、ハーネスエンジニアリングの実践そのものです。
よければXもフォローしてもらえると嬉しいです → X(@morphox_ai)
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます