
AI経営者の参謀@ひです。
大手コンサルで3年→スタートアップに飛び込み、29歳で自分の会社を創業しました。
AIとの出会いで、リサーチ・資料作成・データ分析を大幅に委譲して、今は「判断」に集中しています。
2社目を立ち上げ中で、1社目の経験とAIで経営のスピードが3倍になった実感があります。
結論から言います。
AIインフラの選び方は、もう技術チームだけに任せていい話じゃないです。
経営判断そのものになっている。
先日、CADDi CEOの加藤勇志郎さんがXでシェアしていたポストが、まさにこの問題を端的に言い当てていて、僕の周りの経営者仲間でもかなり話題になりました。
加藤さんが紹介していたのは、Stratomereが公開した「After abundance」という英語の長文エッセイです。

この記事の核心は「AIの爆発的な進化が、ソフトウェアの世界を再び物理的な制約へと引き戻している」ということ。
僕もこのエッセイを読んで、自分のスタートアップの意思決定を見直さないとまずいな、と率直に感じました。
今日はこの内容を、経営者が押さえておくべきポイントに絞って解説していきます。
AIインフラを直撃する——クラウドの「弾力的スケール」という前提の崩壊

ムーアの法則の恩恵で成立していた「無限スケール」の幻想
正直に言うと、僕らスタートアップの経営者って、この10年ほどクラウドのことを「空気みたいなもの」だと思い込んでいたと思うんですよ。
サーバーが足りなくなったらAWSのインスタンスを増やせばいい。
トラフィックが落ち着いたら縮小すればいい。
この「弾力性」のおかげで、物理的なインフラのことなんて考えなくてよかった。
でも「After abundance」が指摘しているのは、この弾力性はムーアの法則——集積回路上のトランジスタ数が約2年ごとに倍増するという法則——の恩恵で成り立っていたにすぎないということです。
チップが勝手に進化するから、クラウドベンダーは余裕を持って計算資源を提供できた。
だから僕らは「使いたいときに使いたいだけ」が当たり前だと思い込んでいた。
ここが、この話の出発点です。
GPU不足・電力制約・メモリボトルネックが同時に発生している理由
ところが今、AI需要の爆発で状況が一変しています。
具体的には、3つのボトルネックが同時に発生しているんですよ。
この3つが同時に起きているから、クラウドベンダーが「いくらでもどうぞ」と言えなくなっている。
これは一時的な需給ギャップじゃなく、構造的な変化だと考えた方がいいです。
「で、経営にどう関係するの?」——次の話が本題です。
クラウドコスト固定費化——AIインフラ調達が経営戦略に直結する理由
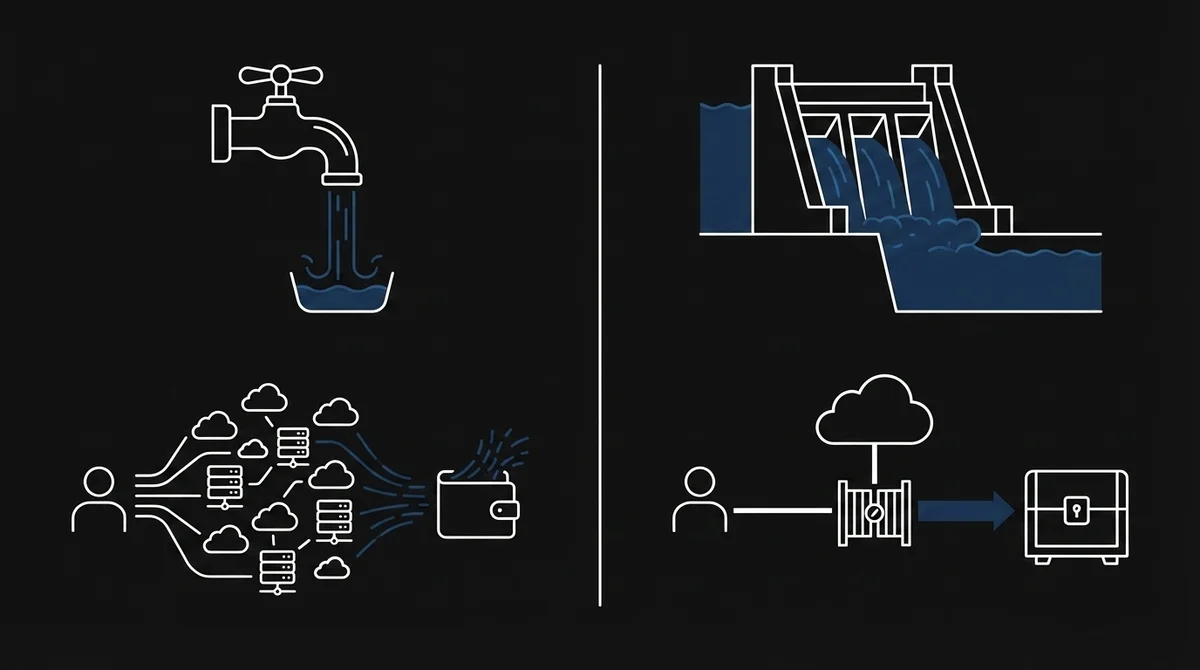
オンデマンドから「事前コミットメント」へ——これは資本政策の問題
「After abundance」で僕が一番ハッとしたのが、「クラウドは弾力的なバッファから容量アロケーターに変わりつつある」という指摘です。
今まではクラウドって「使った分だけ払う」が基本でしたよね。
でもAI時代のクラウドは、GPUを使いたければ「1年契約で先払い」「最低利用額のコミットメント」が前提になりつつある。
変動費だったクラウドコストが固定費に変わりつつあるんですよ。
これは技術の話じゃなくて、完全にキャッシュフローの問題です。
「After abundance」の中で印象的だったのは、「クラウドは資本支出(CAPEX)を消し去ったのではなく、集中させただけだ」という一文。
スタートアップにとって、年間のクラウドコミットメントが数千万円になるか、数億円になるかは、資金調達の計画そのものを変えます。
キャッシュフローと固定費構造が変わる
具体的にイメージしやすいよう、従来との違いをまとめます。
この変化は、日本でも現実のものになっています。
さくらインターネットは政府の支援を受けてNVIDIA H100を約2,800基整備しましたが、大型案件終了後にGPUインフラの売上予想を158億円から約85億円に下方修正しました。
GPU需要は確かにあるけれど、タイミングと量のミスマッチが起きると巨額の「売れ残り」が発生する。
これは供給側の話ですが、需要側——つまり僕らスタートアップがコミットメントを取る側にとっても同じリスクがあるということです。
さくらインターネットの例を「他人事」で見ている場合じゃない、と思いませんか。
AIインフラの「技術チーム丸投げ」は経営判断の放棄
技術選択は経営戦略の表現である
ここまで読んで、「うちはCTOに任せてるから大丈夫」と思った方もいるかもしれません。
でも「After abundance」の中で一番刺さったのが、この一文です。
> アーキテクチャを技術的な決定としてエンジニアリングに委任する組織は、暗黙のうちに現在の抽象化を形作った環境が持続するという賭けをしている
「技術のことは技術に任せる」というスタンス自体が、「今のクラウド環境がこのまま続く」という前提に立った賭けになっているということです。
さっき見たように、その前提が崩れつつある。
つまり「CTOに丸投げ」は、知らない間に経営リスクを積み上げているのと同じなんですよ。
CTO/VPoEだけに任せることの3つのリスク
経営者がアーキテクチャ判断に関与しないことの具体的なリスクを整理します。
1. コスト構造の硬直化に気づかない
技術チームは「最適なアーキテクチャ」を選びます。
でもそれが3年間のクラウドコミットメントを前提としている場合、ピボットや事業縮小の柔軟性を失っている可能性がある。
技術的に最適でも、経営的に最適とは限らないんですよ。
2. ベンダーロックインが経営リスクになる
例えばGoogleのTPUに最適化したアーキテクチャを組むと、性能は出るけど他のクラウドへの移行が極めて難しくなる。
これは技術チームが気にする「移植性」の問題であると同時に、経営者が気にすべき「交渉力」の問題です。
3. 物理制約の変化に対応できない
GPU不足が深刻化したとき、電力価格が上がったとき、HBM供給が詰まったとき。
物理的制約の変化に対して、経営レベルで代替案を持っているかどうか。
CTOだけに判断を委ねていると、「今使っているクラウドベンダーが値上げしました、どうしましょう」と言われたときに、経営者として打ち手がない状態になります。
じゃあ、経営者は何をすればいいのか。ここからが実践の話です。
AI時代に経営者が持つべき「製造業の思考」とキャパシティプランニング

製造業が当然やっていたことをIT経営者も求められている
加藤さんの投稿で一番面白かったのが、「製造業のような思考が求められるようになっている」という部分です。
加藤さんが率いるCADDiは、製造業向けAIデータプラットフォームを運営している会社。
物理的なサプライチェーンの制約と日々向き合っているプロです。
製造業では当たり前にやっている「キャパシティプランニング」——生産能力の計画——を、IT企業の経営者も本気でやらなきゃいけない時代になっているんですよ。
考えてみると、製造業の経営者って、工場の設備投資を現場のエンジニアだけに任せたりしないですよね。
投資額、回収期間、稼働率、代替調達先——これを経営判断として意思決定している。
AIインフラも同じです。
「GPUは工場の設備だ」と考えると、今まで技術チームに丸投げしていたことの意味が、まったく変わって見えてくるはずです。
スタートアップCEOが今すぐできる3つのアクション
じゃあ具体的に何をすればいいのか。
僕自身も見直している最中ですが、まず手をつけるべきは以下の3つです。
いずれも「明日から始められる」レベルの話です。
アクション1: クラウドコストの「月次レビュー」をCEO/CFOの定例に入れる
技術チームが出すインフラコストのレポートを、月次の経営会議で15分だけでも見る。
「先月比でどう変わったか」「今のコミットメントはいつまでか」「次の契約更新はいつか」。
これだけで、コスト構造の変化に対するアンテナが格段に上がります。
アクション2: CTOと「アーキテクチャ選択のビジネスインパクト」を話す場を作る
月1回でいいので、「今のアーキテクチャを続けた場合と、変えた場合のコスト差」「ベンダーロックインの度合い」「物理制約が変わったときの対応策」をCTOと話す。
技術の詳細は分からなくていいんです。
「この選択がキャッシュフローにどう影響するか」という視点で会話できればOK。
アクション3: 「Plan B」としてのマルチクラウド/代替手段を検討リストに入れる
今すぐマルチクラウドにする必要はないです。
でも、メインのクラウドベンダーが値上げしたとき、GPUの割当が減ったとき、どういう代替手段があるかをリストアップしておく。
AI特化型のネオクラウド(CoreWeave、Lambda Labs等)の情報をCTOと共有しておくだけでも、いざというときの対応スピードが変わります。
まとめ——「物理に依存しない」という思い込みを捨てる
加藤さんが言っていた通り、「どれだけデジタルが進んでも、結局は物理に依存する」。
AIの進化は、僕らが享受してきたクラウドの弾力性を削りつつあります。
システムアーキテクチャの選択は、もう純粋な技術論じゃない。
経済合理性と経営判断の領域に完全にシフトしています。
「After abundance」——豊富さの後の時代。
この時代に経営者に求められるのは、技術チームと対等にインフラの話ができるリテラシーと、「製造業の思考」で限られたリソースを最適化する判断力です。
明日の経営会議で、「うちのクラウドコスト、今月いくらだった?」と聞くことから始めてみてください。
その一言が、物理制約の時代を乗り越えるAIインフラ戦略の第一歩になるはずです。
- 4
- 0

元大手コンサル→スタートアップCEO。AIを経営の参謀として活用し、競合調査・市場分析・事業計画のドラフトをAIに任せて意思決定に集中するスタイル。2社目立ち上げ中。経営者目線でAI導入のリアルを発信します。




こちらもおすすめ
-
 AI集客@ルイ
AI集客@ルイ
- 3
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 1
- 0
-
AI集客@ルイ
- 2
- 0
-
AI経営者の参謀@ひで
- 4
- 0
-
AI経営者の参謀@ひで
- 4
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI集客@ルイ
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます