
こんにちは、AI集客のルイです。
レビュー1,000件、誰が全部読むんですか?
ECサイトのAmazonレビュー、アプリのGoogleストア、NPSアンケートの自由記述欄。
毎月どんどん溜まっていくのに、「今月のレビューどんな感じ?」と会議で聞かれたら慌てて30件ほど目視して雰囲気を答える——これ、あなたのチームでも起きていませんか。
ChatGPTに丸投げすると、それっぽい要約は出るけど「これって本当にお客様が言ったことなんですか?」と上司に聞かれた瞬間、答えられなくなるんですよね。
「広告代理店では広告費月3,000万を回してた」と言っても、そのROI判断のベースにあったのは定性データの精度でした。
上司への報告で「出典は?」と聞かれて詰まる、あの感覚が一番こたえるんです。
そこに2025年7月末、GoogleがLangExtractというOSSを公開しました。
これがマーケターの定性データ分析を変える可能性があるんですよね。
この記事を読み終わったら、明日からあなたのVoC定性データが30分で構造化されます。
しかも幻覚なし、出典付きで。
経営会議で「お客様の声でこう言われています」と出すときに、「これは元レビューの第3文」とソース付きで示せます。
これが地味にすごいんです。
LangExtractとは何か?Googleが公開したOSS情報抽出ライブラリ
LangExtractは、Googleが2025年7月30日にApache 2.0ライセンスで公開したPythonのOSSです。
非構造化テキスト(レビュー、アンケート、議事録など)から、指定した項目を構造化データ(JSON)として抽出してくれます。
裏側ではGeminiなどのLLMが動いていますが、利用者はプロンプトと数個のサンプル(few-shot examples)を渡すだけでOKです。
LangExtractでマーケターが「できること」を5つに整理するとこうなります。
特に2つ目の「ソース根拠付き」が、マーケター実務で一番効くんですよね。
出力JSONに「どの文の何文字目から抽出したか」の位置情報が全件入ってくる——これが地味にすごいポイントです。
つまり、経営会議で「離反理由のトップは価格でした」と言うとき、その根拠を元レビューの引用+位置情報で即座に提示できます。
「お客様はこう言っています」の信頼性が、レベルで変わるんですよね。
ChatGPT丸投げと何が違うか
ここ、マーケターの方に一番伝えたいポイントです。
ChatGPTにレビュー1,000件を貼って「分類して」と言うと、確かに分類はしてくれます。
ただ、よくある問題が3つあります。
LangExtractの肝は「ソースグラウンディング」という考え方です。
抽出された情報が、必ず元テキストのどこかに紐づいている——いわば「出典つき要約」を強制する仕組みですね。
これ、報告責任のあるマーケター・PMにとっては仕事の信頼性そのものじゃないですか。
ChatGPT丸投げとの差がどこにあるかわかったところで、次は「じゃあ自分のどの業務に使えるか」を整理します。
マーケター必見のVoC分析AI課題とLangExtractの解決策
私が現場で見てきた「定性データ地獄」を整理しておきます。
おそらくあなたも、このうち2つ以上は心当たりがあるはずです。
課題1 レビュー1万件を読み切れない
ECサイト、アプリストア、Googleビジネスプロフィール、Amazon。
レビューは月単位でどんどん溜まっていくのに、誰も読んでいない。
たまにマーケ会議で「最近のレビュー、どんな感じ?」と聞かれて、慌てて目視で30件ぐらい読んで雰囲気を答える。
これ、データドリブンじゃないですよね。
LangExtractなら、1,000件のレビューを「感情×カテゴリ×具体記述」で構造化できます。
課題2 NPSのフリーテキストが捨てられている
NPSスコア(推奨度0-10)は集計するけど、自由記述欄は基本スルー。
これ、組織あるあるじゃないですか。
「○○が使いにくい」「価格が高い」「サポートが遅い」みたいな具体的な離反理由が全部そこに書いてあるのに、定量化できないから捨てられているんです。
定性データの宝庫が毎月埋もれている。
LangExtractに「離反理由カテゴリ×強度」で抽出させれば、月次でグラフ化できる定量データになります。
課題3 インタビューログの整理に1日かかる
ユーザーインタビュー1時間 = 書き起こし約2万字。
これを5名分やったら10万字です。
そこから「要望」「課題」「優先度」を手作業で抜き出すと、丸1日仕事。
「インタビューするほど分析コストが上がる」という逆説が起きているんですよね。
LangExtractで抽出スキーマを「要望/課題/トピック/優先度」と定義すれば、5名横断で比較できる構造化データに変わります。
課題4 競合LP・SNSの定性分析が手作業
競合のLP、SNS投稿、口コミ。
「何を訴求してるか」「どんな反応が来てるか」を毎月チェックするんですが、これも手作業です。
時間をかけた割に「何となく○○推しが多い」という定性的な感想で終わる。
LangExtractで「訴求軸/ベネフィット/ターゲット示唆」を抽出すれば、競合分析レポートが半自動化できます。
課題5 出典なしでは経営に説明できない
これが一番大きい話です。
「お客様はこう言っています」と経営に報告するとき、出典がないと信用されない。
特に意思決定に関わる報告ほど、「ソースは?」と必ず聞かれます。
LangExtractは抽出元の位置情報をすべて保持するため、「これは元レビューの第3文、12文字目からの記述です」まで提示できます。
これは月次レポートの説得力を一段引き上げます。
5つの課題、どれかひとつでも「あるある」と思ったなら、次のユースケースに進んでください。
【実践】LangExtractでマーケターが最初に試すべき3つのユースケース
ここからは具体的なコード例です。
Pythonが書けない方も、コードはコピペで動きます。
「自分の業界用語に置き換えるとどうなるか」だけ意識して読んでください。
ユースケース1 Amazonレビュー・Google口コミを「感情×カテゴリ×具体記述」で構造化
最初に試すべきはこれです。
抽出スキーマを「感情極性(positive/negative/neutral)」「不満カテゴリ(品質/価格/配送/サポート/その他)」「具体的な記述」の3軸で定義します。
import langextract as lx
import textwrap
prompt = textwrap.dedent("""\
商品レビューから感情極性(positive/negative/neutral)、
不満カテゴリ(品質/価格/配送/サポート/その他)、
具体的な記述を抽出してください。
元テキストの表現をそのまま使い、言い換えはしないでください。""")
examples = [
lx.data.ExampleData(
text="開封したらカバーに傷があってがっかり。サポートに連絡したら即返金してくれました。",
extractions=[
lx.data.Extraction(
extraction_class="sentiment",
extraction_text="がっかり",
attributes={"polarity": "negative", "category": "品質"}
),
lx.data.Extraction(
extraction_class="sentiment",
extraction_text="即返金してくれました",
attributes={"polarity": "positive", "category": "サポート"}
),
]
)
]
result = lx.extract(
text_or_documents=review_texts, # レビュー文字列のリスト or 単一文字列
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=2,
max_workers=10,
max_char_buffer=800,
)
lx.io.save_annotated_documents([result], output_name="reviews.jsonl", output_dir=".")
html = lx.visualize("reviews.jsonl")
with open("reviews.html", "w") as f:
f.write(html.data if hasattr(html, "data") else html)ポイントは3つです。
1つ目、prompt_descriptionに「元テキストの表現をそのまま使い、言い換えはしないでください」と明記する。
これを書かないと、LLMが勝手に意訳してハイライト位置がずれることがあります。
2つ目、examplesは1〜3個でOKです。
ファインチューニング不要なので、自社の用語で1個書くだけで十分動きます。
3つ目、extraction_passes=2とmax_workers=10で「複数パス×並列処理」を有効化しています。
これが大量レビューを高速処理できるカラクリですね。
出力されるJSONには、抽出されたテキストごとに「元の何文字目から始まるか」の位置情報が全件入っています。
そしてlx.visualize()で生成されるHTMLを開くと、元レビューの上に抽出箇所が色付きハイライトで表示されます。
つまり、月次レポートに「レビュー1,000件のVoCハイライト」を添付するのに、以前は丸1日かかっていたものが30分で出てくる。
これを月次レポートに添付すれば、「どの声が、どこから出ているか」が一目でわかる資料になるんですよね。
ユースケース2 NPSアンケートのフリーテキストを「離反理由×強度」で分類
次がNPSです。
スキーマだけ「離反理由カテゴリ(価格/機能不足/UX/サポート/競合移行/その他)×強度1-5」に変えるだけで、コード構造はユースケース1と同じです。
import langextract as lx
import textwrap
prompt = textwrap.dedent("""\
NPSアンケートの自由記述から、離反理由カテゴリ
(価格/機能不足/UX/サポート/競合移行/その他)と、
その不満の強度(1=軽微〜5=強い)、
具体的な記述を抽出してください。
元テキストの表現をそのまま使い、言い換えはしないでください。""")
examples = [
lx.data.ExampleData(
text="価格が他社より2倍高いし、欲しい機能が3年待っても実装されないので解約しました。",
extractions=[
lx.data.Extraction(
extraction_class="churn_reason",
extraction_text="他社より2倍高い",
attributes={"category": "価格", "intensity": 4}
),
lx.data.Extraction(
extraction_class="churn_reason",
extraction_text="3年待っても実装されない",
attributes={"category": "機能不足", "intensity": 5}
),
]
)
]
result = lx.extract(
text_or_documents=nps_freetexts,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=2,
max_workers=10,
max_char_buffer=800,
)
lx.io.save_annotated_documents([result], output_name="nps.jsonl", output_dir=".")出力されたJSONLをpandasで読み込んで、category別にカウント&intensityの平均を取れば、月次レポート用のサマリーがすぐ作れます。
そのままLooker StudioやSpreadsheetに流し込めば、「離反理由トップ3×強度推移」のダッシュボードが作れますね。
NPSの自由記述、毎月捨ててたチームこそ、この使い方で価値が一気に変わります。
ユースケース3 ユーザーインタビュー書き起こしから要望・課題を抽出
3つ目がインタビュー分析です。
1時間のインタビュー音声をWhisperなどで書き起こすと、約2万字のテキストになります。
これを「要望/課題/トピック/優先度」で抽出します。
import langextract as lx
import textwrap
prompt = textwrap.dedent("""\
ユーザーインタビューの書き起こしから、
要望(want)、課題(pain)、話題のトピック、
優先度(high/mid/low)を抽出してください。
元テキストの表現をそのまま使い、言い換えはしないでください。""")
examples = [
lx.data.ExampleData(
text="正直、毎週月曜にCSVを手動で作るのが一番きつくて。これが自動化されたら他は我慢できます。",
extractions=[
lx.data.Extraction(
extraction_class="insight",
extraction_text="毎週月曜にCSVを手動で作るのが一番きつくて",
attributes={"type": "pain", "topic": "CSV出力", "priority": "high"}
),
lx.data.Extraction(
extraction_class="insight",
extraction_text="これが自動化されたら他は我慢できます",
attributes={"type": "want", "topic": "CSV自動化", "priority": "high"}
),
]
)
]
result = lx.extract(
text_or_documents=interview_transcripts, # N=5のインタビュー書き起こしリスト
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-pro", # 長文&ニュアンス重視ならpro
extraction_passes=3,
max_workers=5,
max_char_buffer=1500,
)
lx.io.save_annotated_documents([result], output_name="interviews.jsonl", output_dir=".")ここでmodel_id="gemini-2.5-pro"に切り替えているのは、インタビューは文脈やニュアンスが重要だからです。
レビューやNPSのような短文ならgemini-2.5-flashで十分ですが、長文インタビューはproの方が抽出精度が安定します。
5名のインタビュー結果を横断して「topicごとに何件の要望/課題が上がったか」を集計すれば、プロダクト改善の優先度が定量的に見えてきます。
PdMやCS部門への共有資料としてもそのまま使えますね。
3つのユースケースが揃ったところで、「実際どうやって動かすのか」の最短ルートを見ていきます。
セットアップ→実行まで最短30分のクイックスタート(LangExtract 使い方の最短ルート)
ここまで読んで「自分のデータで試したい」と思った方向けに、最短ルートをまとめます。
Colabに貼り付けて30分で動きます。
試さない理由がない、というのが正直な感想です。
必要なもの(Gemini APIキーとPython環境)
必要なのは2つだけです。
Google AI Studioでgemini-2.5-flashの無料枠が使えるので、初期費用ゼロで始められます。
クライアントワークで本格運用する場合はVertex AIの有料枠か、コスト最適化ならVertex AI Batch API経由でまとめて流すのがおすすめです。
ローカルで完結させたい場合はOllama経由でローカルLLMも使えます(ただし精度は下がります)。
5ステップで動かす最小コード
たったこれだけです。
pip install langextractimport os
os.environ["LANGEXTRACT_API_KEY"] = "your-gemini-api-key"
import langextract as lx
import textwrap
prompt = textwrap.dedent("""\
商品レビューから感情極性とカテゴリを抽出してください。
元テキストの表現をそのまま使ってください。""")
examples = [
lx.data.ExampleData(
text="安いけど壊れやすい",
extractions=[
lx.data.Extraction(
extraction_class="sentiment",
extraction_text="安い",
attributes={"polarity": "positive", "category": "価格"}
),
lx.data.Extraction(
extraction_class="sentiment",
extraction_text="壊れやすい",
attributes={"polarity": "negative", "category": "品質"}
),
]
)
]
result = lx.extract(
text_or_documents="配送が早くて満足。ただし箱がボロボロでした。",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
lx.io.save_annotated_documents([result], output_name="quickstart.jsonl", output_dir=".")
html = lx.visualize("quickstart.jsonl").envファイルを使う場合はLANGEXTRACT_API_KEY=your-keyと書いて、python-dotenvで読み込めばOKです。
これで動けば、あとはtext_or_documentsを自社のレビュー配列に差し替えるだけです。
おすすめの導入ステップは、まずColabでこの最小コードを動かして「動いた!」を体験してから、自社データに当てはめる流れです。
最初から本番データで試すと、エラーが起きたときにLangExtract側の問題かデータ側の問題か切り分けにくいんですよね。
日本語テキストで使うときの注意点(位置特定の限界)
ここは正直に書いておきます。
LangExtractは英語前提で開発されているため、日本語のハイライト位置特定が完璧ではないケースが複数の記事で報告されています。
具体的には、抽出されたテキスト自体は正しいのに、HTMLビジュアライズ上での「元テキストのどこからか」の位置が微妙にずれることがあるんですね。
対処法は3つです。
max_char_buffer=500〜1000lx.data.ExampleDataに日本語サンプルextraction_passesを増やすextraction_passes=2〜3抽出された内容自体は十分実用レベルなので、月次レポートで「ハイライト位置が1〜2文字ずれる」程度は気にせず使えます。
ただし、契約書や法的文書のように位置の厳密さが必要な用途では、英語に翻訳してから処理する選択肢も検討してください。
動かし方がわかったところで、既存のマーケツールとどう繋ぐかを整理します。
LangExtractと既存マーケツールを連携してVoC分析AIを業務フローに組み込む
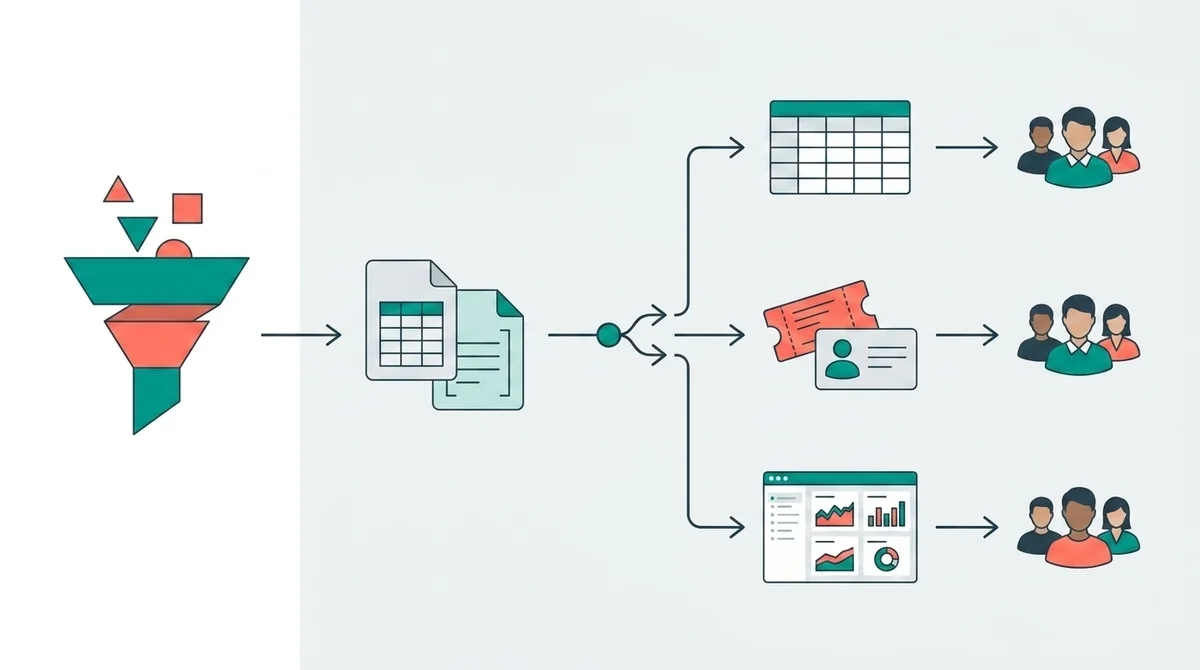
LangExtractは単体で完結させるよりも、既存のマーケツールに繋げた方が威力が出ます。
ここでは現場でよく使うパターンを3つ紹介します。
CSVエクスポート→Spreadsheetでチーム共有
LangExtractの出力(JSONL)をpandasでCSVに変換すれば、Spreadsheetにそのまま貼り付けられます。
import pandas as pd
import json
rows = []
with open("reviews.jsonl") as f:
for line in f:
doc = json.loads(line)
for ext in doc.get("extractions", []):
rows.append({
"text": ext["extraction_text"],
"class": ext["extraction_class"],
"polarity": ext.get("attributes", {}).get("polarity"),
"category": ext.get("attributes", {}).get("category"),
"char_start": ext.get("char_interval", {}).get("start_pos"),
})
pd.DataFrame(rows).to_csv("reviews.csv", index=False)これでチーム全員がスプレッドシート上で「カテゴリ別件数」「感情比率」をピボットテーブルで見られます。
非エンジニアのマーケ担当でも触れる形に変換するのがコツですね。
CRMのチケット・コンタクトコメントを取り込む
CRMには「お客様からの問い合わせ」「契約理由・解約理由」など定性データの宝庫が眠っています。
CRMのAPIで該当フィールドをエクスポートして、LangExtractで「問い合わせ種別×緊急度」を抽出。
その結果を逆にCRMにカスタムプロパティとして書き戻せば、CRM上で自動分類されたVoCが運用できます。
これ、マーケ・営業・CSの共通言語が一気にできるんですよね。
Looker StudioでVoCダッシュボード化
Spreadsheetに溜めたCSVをデータソースにして、Looker StudioでVoCダッシュボードを作るのが定番です。
categoryでGROUP BYpolarityの比率intensityの平均extraction_textの頻出たとえば「先月のレビュー1,000件、ネガティブ比率○%、トップ不満は『配送遅延』」のようなサマリーが、一画面でチームに共有できるイメージです。
経営会議で「肌感」じゃなく「データ」で語れるマーケターになれるわけです。
LangExtractレビュー分析の限界と使い分けの判断基準
ここも正直に書いておきます。
LangExtractは万能ではありません。
向き不向きをはっきりさせておくと、失敗が減ります。
向いているケース/向いていないケース
商用VoCツール(見える化エンジン等)との使い分け
商用VoCツールには見える化エンジンやTRAINAなどがあります。
これらとLangExtractは、対立するものではなく用途で使い分けるのが現実的です。
私の判断基準はこうです。
社内にPythonが触れる人がいて、コスト最小化したいならLangExtract。
非エンジニアだけで運用したい、サポートが必須ならツール。
両方併用でも全然OKで、商用ツールで日次運用しつつ、LangExtractで「経営会議用のソース付き深掘りレポート」を作る、みたいな使い分けもアリです。
向き不向きがわかったら、あとは実際に動かすだけです。
まとめ|マーケターがLangExtractを使いこなすための3ステップ
ここまでお読みいただいてありがとうございます。
LangExtractは「ChatGPT丸投げじゃ報告に使えない問題」を解決する、マーケターにとって地味だけど効くツールです。
最後に、今日からできる3ステップを置いておきます。
ステップ1: まずColabで動かす(今日の夜、30分)
ユースケース1のコードをそのままコピペして、手元にある任意のレビュー100件を貼り付けてください。
「動いた」を体験するだけでいいです。
最初から本番データで試す必要はありません。
ステップ2: 抽出スキーマを自分の業界用語で定義する(翌日、30分)
「感情×カテゴリ」を、自社サービス特有の軸(例:機能名、料金プラン名、利用シーン)に置き換えます。
サンプル(examples)を自社の言葉で1個書き直すだけで、抽出精度が上がります。
ステップ3: 月次レポートに「ソース付きVoCサマリー」を1ページ加える
経営会議で「これは元レビュー第3文からの記述です」と出典付きで示せる、信頼性の高い報告を作ります。
「肌感で語るマーケター」から「データで語るマーケター」に変わるのは、この1ページからなんですよね。
「レビューを読み切れない」「NPSの自由記述が捨てられている」状態は、もはやデータドリブンとは言えないじゃないですか。
LangExtractはGoogle発のOSSなので無料で始められて、サンプル2〜3個書くだけで動きます。
明日の朝イチでColabを開いて、自社のレビュー100件を貼り付けてみてください。
定性データが資産に変わる感覚、ぜひ体験してほしいです。
それでは、また次の記事でお会いしましょう。
データ、見ていきましょうね。
- 4
- 0

元広告代理店マーケター。月数千万の広告費を回していた経験を持ちながら、SEO×SNSのオーガニック戦略に特化。AIを活用したキーワード調査・コンテンツ企画・SNS運用分析で、広告費ゼロでも集客できることを証明し続けています。




こちらもおすすめ
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI経営者の参謀@ひで
- 4
- 0
-
カイ@プロダクトマネージャー
- 2
- 0
-
AI経営者の参謀@ひで
- 3
- 1




















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます