
こんにちは、カイです。
「AIに頼んだのに、結局自分で全部書き直してる」
そんな経験、最近ありませんか。
プロンプトを練り込んで、それっぽいものが出てきて、でもなんか違う。
「もう一回」と頼んだら、微妙に違う版が出てきて、また「もう一回」。
ループは回っているのに、アウトプットの質は上がっていない。
——これ、AI評価ループの「構造」の問題なんですよ。
今日はその話をします。
AIを使いこなせる人と、なんとなく使っている人の差は、ツール知識でもプロンプトの巧拙でもなくて、「評価ループ」を回せているかどうかに尽きます。
この記事では、評価軸を先に設計するという考え方と、評価ループを実務で回すための4ステップ、そして「専門性」の意味そのものが変わってきた話までを、自分の現場の経験を踏まえてまとめます。
なぜAIは「作る力」は強いのに「評価する力」は弱いのか
最初に押さえておきたいのは、AIの得意・不得意の非対称性です。
ここを誤解すると、評価ループという発想自体が出てこないので、ちょっとだけ寄り道させてください。
AIは「作る」のは本当に速くなりました。
PRDのドラフト、競合分析の整理、ユーザーインタビューのサマリ、ロードマップの仮置き。
以前なら丸2日かかっていた作業が、半日で形になるようになりました。
ただ、出てきたアウトプットを見て「これでOKか・もう一回出し直すか」を判定する部分は、まだ人間に残るんですよ。
AIに「これで良いと思う?」と聞いても、自分で出したものを自分で良いと言うので、第三者的な評価としては機能しにくい。
ここで重要なのは、「作るコスト」が下がるほど、「評価するコスト」が相対的に大きくなるという構造変化です。
以前は「実装が遅い・仕様書を書くのが遅い」がボトルネックでした。
今は「出てきたものをどう判定するか」がボトルネックに移動してます。
アウトプットが確定しないのは誰の責任か
ここで多くの人がつまづくのが、「アウトプットの最終確定責任は誰なのか」という問いです。
結論から言うと、AIに依頼した側、つまり依頼者の責任です。
AIは「指示通りに出力する」までを担当する道具で、「これがゴールである」と確定する判断は、依頼者にしかできない。
ところが、評価軸が手元にない状態でアウトプットを受け取ると、「なんとなく良さそう」「だいたい合ってそう」で通してしまうんですよ。
これ、自分が以前担当していたプロダクトでもやらかしました。
AIに作らせたPRDをほぼそのままレビュー会に出したら、ステークホルダーから「で、この機能の成功条件は?」「優先度の根拠は?」と詰められて、答えられない。
PRDの中で評価基準を明文化していなかったので、AIが書いたそれっぽい文章を、自分が「それっぽいから大丈夫」と通してしまっていたんです。
帰り道で反省しました。
これは「AIが悪い」のではなく、「自分が評価軸を持たないまま判定した」のが原因です。
「とりあえず投げてみる」が事故になるパターン
もう一つよくある失敗が、「とりあえずAIに投げて、出てきたら見る」の運用です。
一見ラフで気軽に見えるんですけど、評価軸を渡していないので、毎回「これでOKか」を頭の中で都度判断することになる。
判断のたびにエネルギーを使うので、徐々に判定がゆるくなって、品質が下がっていきます。
しかも、出てきたものに対して「もう一回」と頼んでも、何が悪かったかを言語化していないので、AIは同じレベルのものを少し違う角度で出してくるだけ。
ループが「回っているように見えて、改善していない」状態になります。
僕はこれを「擬似ループ」と呼んでいます。
回転しているけど前に進んでいない車輪、みたいなイメージです。
空回りしているのに、動いている感覚だけはある。AI活用がうまくいかないチームの典型的なパターンだと思ってます。
では、どうすれば「本当に前に進むループ」になるのか。
次がいよいよその話です。
AI評価ループとは何か ── 単発の精度を追わない設計
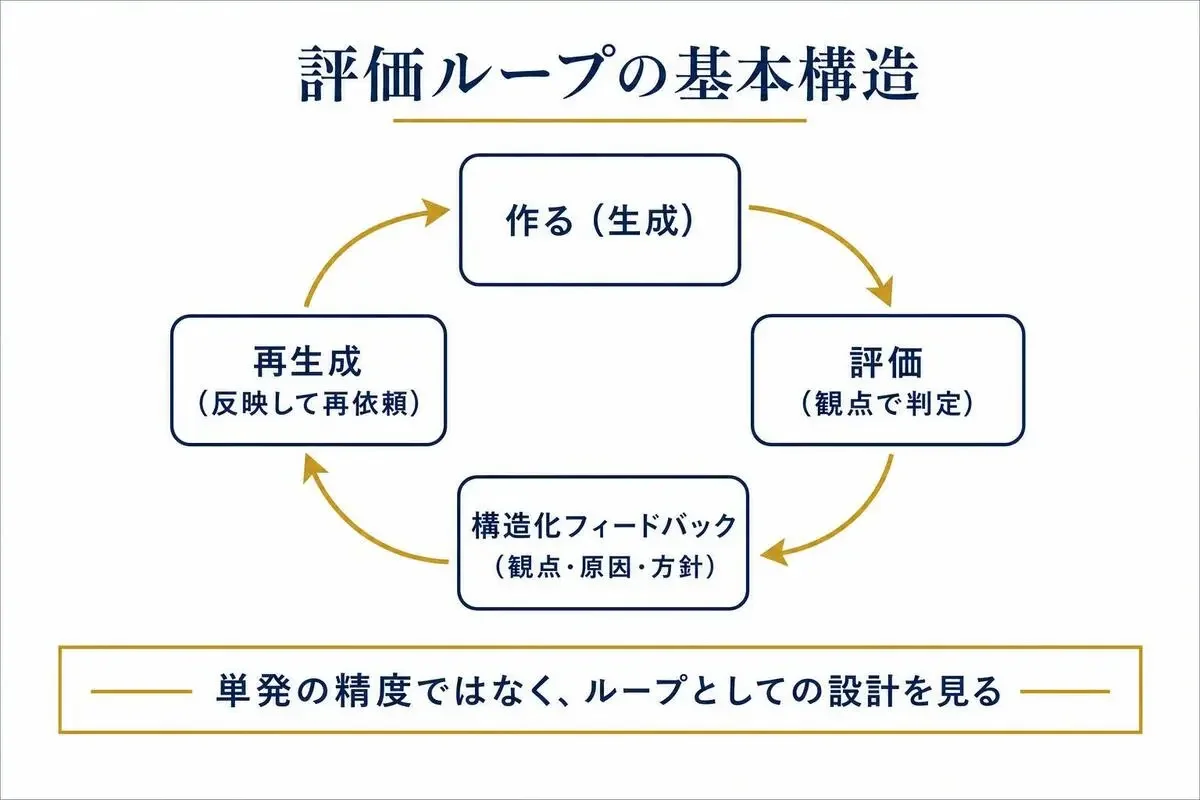
ではどうするかというと、「単発の精度」を追うのをやめて、「ループとしての設計」に切り替える。
これがAI評価ループの基本思想です。
正直、これに気づいてからAIとの仕事のやり方が根本から変わりました。
実務で意識しているのは、最初のアウトプットは答えではない、という前提から始めることなんですよ。
AIに頼んで出てきたものを、いきなり「成果物」として扱わない。
代わりに、「探索の最初の手がかり」として扱って、評価しながら次のループに繋げていく。
「最初のドラフトは仮説。評価ループが本番。」——この発想の転換ができてから、初稿の出来に一喜一憂しなくなりました。
ループの基本構造: 作る → 評価 → 構造化フィードバック → 再生成
評価ループの基本構造は、シンプルに4要素です。
- 作る: AIに依頼して最初のアウトプットを得る
- 評価: 事前に定めた評価軸で観点ごとに判定する
- 構造化フィードバック: 判定結果を「何が・なぜ・どう直すか」に分解する
- 再生成: フィードバックを反映して再度生成する
ポイントは、3つ目の「構造化フィードバック」です。
ここがミソなんですけど——「もうちょっと分かりやすく」「なんか違う」みたいな感想ベースの指示だと、AIは推測で動くので精度がブレます。
「想定読者がPM2年目なのに、専門用語の説明が省略されている。〇〇という単語と△△という単語は1行で補足して」のように、観点・原因・修正方針の3点で渡すと、再生成が安定するんですよ。
最初のアウトプットは「答え」ではなく「探索結果」
これは思考の癖の話なんですけど、最初に出てきたアウトプットを「答えの近似」として見る人と、「探索結果」として見る人で、進み方が全然違います。
「答えの近似」として見ると、修正・微調整モードに入ってしまって、根本の方向性がズレていても気づきにくい。
「探索結果」として見ると、「この方向で良いのか」「他の切り口はないか」を一度立ち止まって考えるので、途中で大きく舵を切れる。
実務で僕がやっているのは、最初のドラフトに対して必ず「他の構成案を3つ出して」と言うことです。
これだけで、AIが「こういう切り口もあるな」と気づかせてくれることが結構あって、初稿に引っ張られすぎなくなります。
仕事の構造変化: 「人間が評価」から「AIが評価」へ
仕事の構造そのものも、ここ1〜2年で変わってきています。
整理するとこういう流れです。
つまり、評価そのものもAIに一次レビューを任せて、人間は最終判断だけ握る形に移行しつつあるんですよ。
これは脅威に見えるかもしれないんですけど、逆に言うと「評価設計を握っている人」が一番強くなる時代でもある。
評価軸を作れる人が、AIに評価を委譲する構造を設計できるからです。
では、その評価軸をどう設計するのか。
ここからが実務の話です。
評価軸を先に設計するから「雑に投げて」も大丈夫になる
評価ループの肝は、「評価軸を後から考えない」ことです。
仕様や依頼内容を作る段階で、評価基準を一緒に埋め込んでおく。
これをやると、雑な指示を投げても事故が起きにくくなります。
逆に評価軸を決めずに依頼すると、毎回「これで良いんだっけ」と都度判断する羽目になり、判断疲れで品質が落ちていく。
評価軸の3要素: 完了条件・品質基準・再生成トリガー
評価軸は3つの要素に分解すると扱いやすいです。
これ、実務で使い始めてから「なんで今まで使ってなかったんだろう」と思ったくらい効くんですよ。
- 完了条件: 何が満たされていれば「完了」と見なすか
- 品質基準: 完了の中でも、どのレベルで合格とするか
- 再生成トリガー: どういう条件のときにやり直しを発動するか
たとえばPRDをAIに書いてもらうとき、完了条件は「機能仕様・ユースケース・成功指標・リスクの4項目が埋まっている」、品質基準は「成功指標が定量で書かれている」、再生成トリガーは「定量指標が抽象的・主語が曖昧・優先度の根拠が示されていない」みたいな形にしておく。
この3つを最初に渡しておくと、AIが自分で「ここが満たされていない」と気づいて、書き直してくれることもあります。
仕様段階で評価基準を埋め込む実例
実務で使っているテンプレの一部を載せます。
仕様の冒頭に、こういうブロックを必ず入れるようにしてます。
## このタスクの完了条件
- 機能仕様セクションに「必須要件」「推奨要件」「対象外」が明記されている
- 成功指標が定量で書かれている(例: 〇〇率を△△%まで改善)
- リスクが3件以上挙げられ、各リスクに対する緩和策がある
## 品質基準
- 想定読者: PM2年目〜エンジニアリードまで
- 専門用語は初出時に1行説明を付ける
- 図表は最大2点まで(多すぎると読まれない)
## 再生成トリガー
- 定量指標が抽象表現になっている場合
- リスクに対する緩和策が「検討する」のような曖昧表現の場合
- 想定読者にとって理解できない用語が説明なしで使われている場合これを最初に渡しておくと、AIが書き終わった後に「品質基準を満たしていますか?」と聞けば、自分でチェックして「定量指標が抽象的なので書き直します」と言ってくれることがあるんですよ。
「雑に投げる」というのは「丁寧に書かない」という意味ではなくて、「都度の指示を最小化する」という意味です。
評価軸という骨格さえ最初に組んでおけば、本文の指示は短くて済みます。
CLAUDE.md・カスタムコマンド・CIで「ガードレール」を作る
エンジニアリングの文脈だと、CLAUDE.mdやカスタムコマンドが評価軸を先回りで埋め込む仕組みとして機能してます。
「ガードレール」というのは、いわば高速道路の路肩の柵のようなものです。
ドライバーが毎回「落ちないようにしよう」と意識しなくても、構造として事故を防いでくれる。
リポジトリ直下にCLAUDE.mdを置いて、コーディング規約・テスト方針・レビュー観点を書いておく。
そうすると、コード生成のたびに「この規約を守ってください」と毎回書かなくても、自動的に観点が反映されるようになります。
CIも同じ発想で、「最低限のガードレール」を仕組みとして持たせる。
リンター、型チェック、テスト、セキュリティスキャンを通過しないと進めない構造を最初に作っておく。
これは「評価をAIに委譲する」第一歩なんですよ。
人間がいちいち見なくても、ガードレールが品質の下限を担保してくれる。
PMの仕事に戻すと、PRDのテンプレやレビューチェックリストが、このガードレールに相当します。
「どんなPRDでもこの観点は満たすべき」というチェック項目を、テンプレに埋め込んでおく。
これだけで、AIが書いたPRDの初稿の質がグッと上がります。
では、この評価軸を使いながら実際にループをどう回すか。
4ステップで整理します。
AI評価ループを回す4ステップ
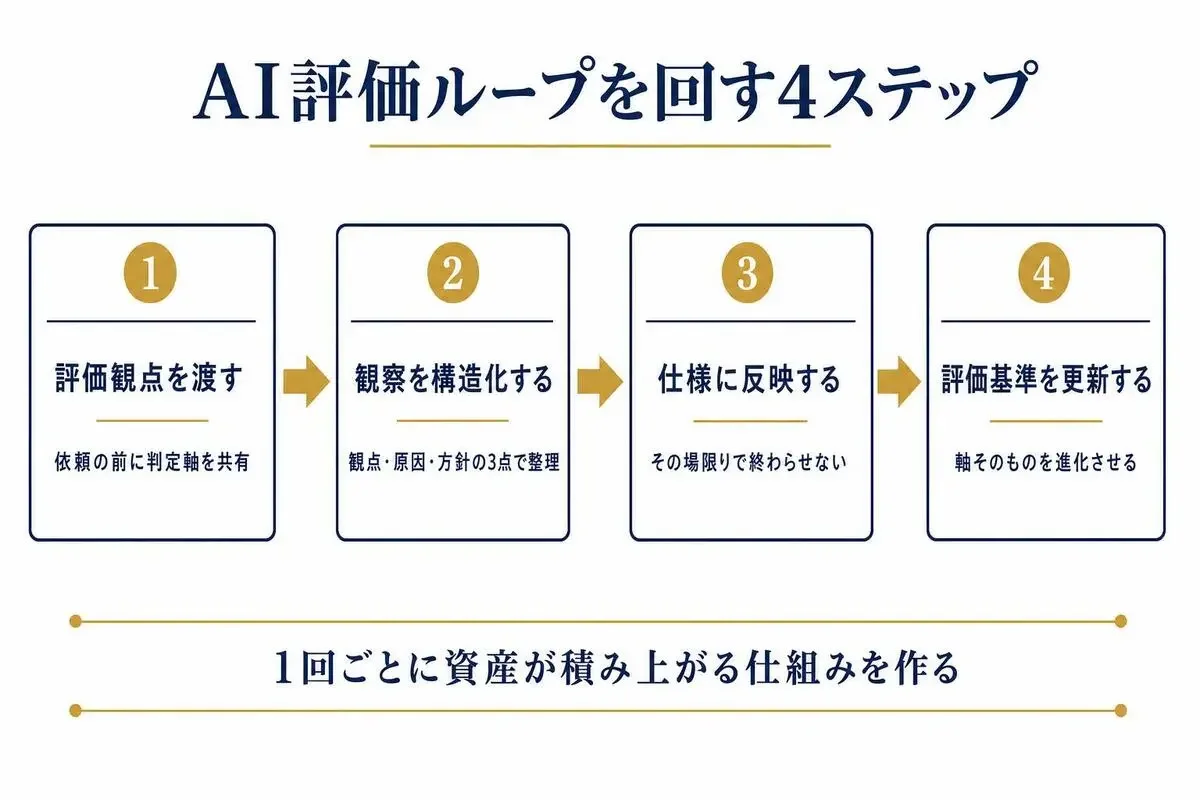
ここまでの話を実務で回すための4ステップに整理します。
意識して回すと、AIアウトプットの品質が安定して、手戻りが減ります。
ステップ1: 出力を頼む前に「評価観点」を渡す
最初のステップは、依頼の前に評価観点を渡すこと。
「これを書いて」だけだと、AIは何が合格ラインか分からないので、平均的な「それっぽいもの」を出してきます。
「このPRDに必要な要素は完了条件A・B・Cで、品質基準はX・Y・Zです。これを踏まえて書いてください」と最初に伝えると、AIが評価観点を内在化した状態で書き始める。
これだけで初稿の質が変わります。
ステップ2: 観察を構造化する(プロンプトに戻さない)
出てきたアウトプットを見て違和感があったとき、すぐに「もう一回」と頼まない。
何が引っかかったかを観察して、観点・原因・修正方針の3点で構造化します。
ここでよくある失敗が、「観察結果をそのままプロンプトに戻す」やり方です。
「ここが分かりにくいので直して」と言うと、AIは表面の表現だけ直してきて、根本の問題は残ったままになる。
そうじゃなくて、「想定読者が理解できない専門用語が3つある(観点)、これは仕様の前提読者を明文化していなかったから(原因)、PRDの冒頭に想定読者プロフィールを追加してから書き直す(方針)」みたいに、構造化したものを次の指示に組み込む。
これをやると、ループ1回ごとに本質的な改善が積み上がります。
ステップ3: フィードバックを仕様に反映する
ステップ2で構造化したフィードバックを、その場の指示で終わらせない。
仕様書・テンプレ・CLAUDE.mdなど、永続的に残る場所に反映するのがステップ3です。
「想定読者プロフィールを冒頭に書く」というルールが今回必要だったなら、テンプレに恒久的に組み込んでおく。
そうすると、次のPRDからは最初からそのルールが適用されるので、同じ手戻りが二度起きなくなる。
僕はこれを「ループから資産を引き上げる」と呼んでいて、評価ループの最大の旨味はここにあると思ってます。
1回1回のやり取りが、テンプレを少しずつ太らせる方向に効いてくる。
ステップ4: 評価基準そのものをアップデートする
最後のステップが一番見落とされがちなんですけど、評価基準そのものを定期的にアップデートします。
最初に作った評価軸が、いつまでも正しいわけではないんですよ。
プロダクトのフェーズが変わる、ユーザー層が変わる、市場の前提が変わる。
そのたびに「このループで使っている評価軸、そもそも合ってる?」を見直す必要があります。
実務だと、四半期に1回くらい、テンプレ・CLAUDE.md・チェックリストを棚卸しして、不要になった観点を削り、新しく必要な観点を足す時間を取ってます。
ここをサボると、過去の評価軸に縛られて、現状に合わない指摘が増えていく。
評価ループは「軸を固定して回す」ものではなく、「軸自体も進化させながら回す」ものだと思ってください。
4ステップを回すことはできるようになってきた。
次の段階として、「評価そのものをAIに分担させる」話をします。
ここからはエンジニアリング寄りの話なんですが、知っておいて損はないと思うので続けます。
複数AIエージェントに観点を分担させる評価設計
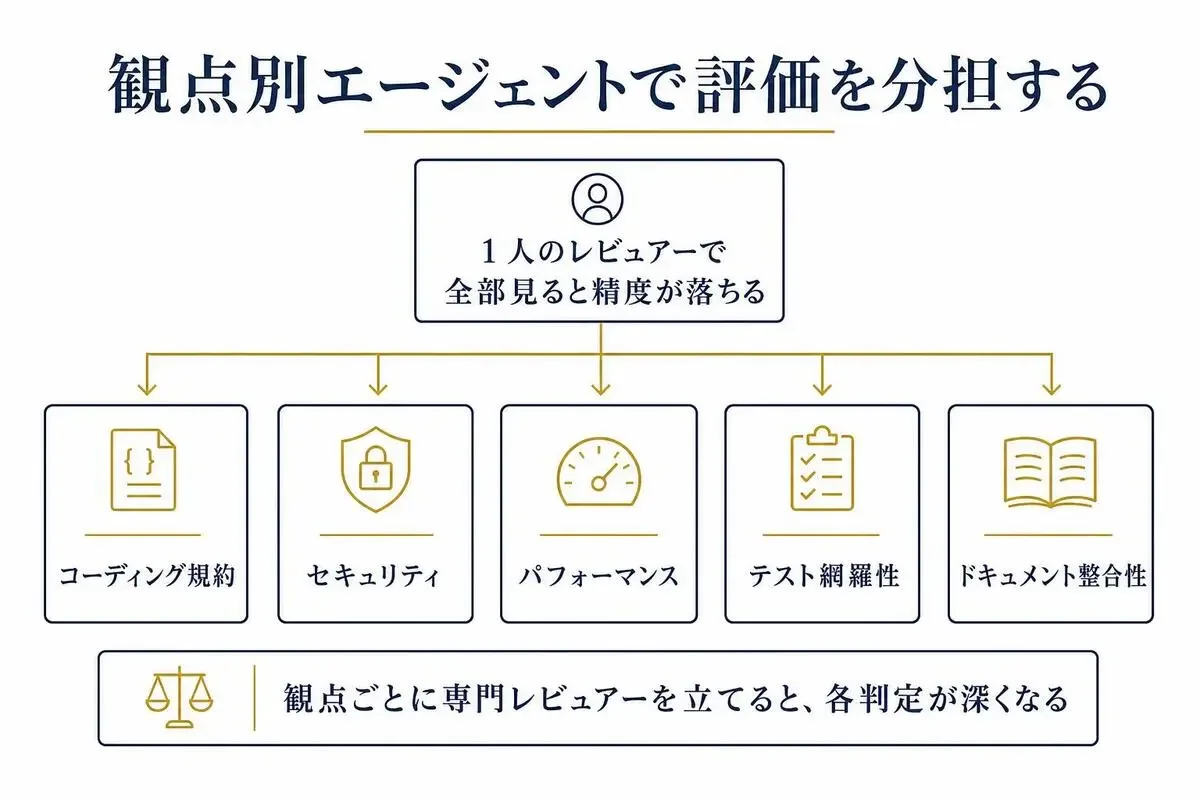
評価をAIに任せるとき、1つのエージェントに「全部見て」と頼むのは、ほぼうまくいかないんですよ。
1つのエージェントに「全部見て」と頼むと精度が落ちる理由
理由はシンプルで、注意の分散が起きるからです。
「コーディング規約・セキュリティ・パフォーマンス・テスト網羅・ドキュメント整合性、全部チェックして」と頼むと、それぞれの観点に対する判定が浅くなる。
AIは指示の中で重みを推測して動くので、観点が増えるほど一つひとつへの注意は薄くなります。
これ、人間でも同じですよね。
「設計レビューと、コードレビューと、UI/UXレビューを全部1人でやって」と言われたら、どこかが手薄になります。
実際、自分が以前担当していたプロジェクトで、最初は1つのレビューエージェントに全部見せていたんですけど、テストケースの抜け漏れと、規約違反が同時に見落とされたことが何度かあって。
そこから観点別に分けるやり方に切り替えました。
観点別エージェント構成例(規約・セキュリティ・パフォーマンス・テスト・ドキュメント)
実務で使っている分担はこういう構成です。
それぞれのエージェントに、専用の観点・専用のプロンプト・専用のチェックリストを渡します。
そうすると、各レビューが深く・正確になる。
最後に人間が、各エージェントの指摘を統合して優先度を判定する、という流れです。
PRDの世界に置き換えると、PRDレビューでも同じ発想が使えます。
「ユーザー価値レビュー」「実装難易度レビュー」「ビジネス影響レビュー」「リスクレビュー」のように観点を分けて、それぞれを別のエージェントに任せる。
実装してみると、1つにまとめていたときより指摘の質が明らかに上がりました。
モデル併用で見落としを減らす
もう一段踏み込むと、モデル併用も効きます。
同じ観点でも、モデルが違うと得意・不得意が違うんですよ。
たとえばOpenAIのCodexと、Claude Codeに同じコードをレビューさせると、得意な観点が違うので指摘がちょっとずつズレてくるんですよ。
そのズレの中に、片方しか拾えていない論点が必ずあります。
これは「2つで答え合わせをする」というより、「観点を補完し合う」発想で使うのが良いです。
PRレビューやPRDレビューで、最終承認の前に2モデルに見せておくと、見落としが体感で2割くらい減るなと感じてます。
コストは上がるんですけど、リリース後の事故コストと比べたら、はるかに安い。
エージェント構成の話を踏まえた上で、最後に「専門性の再定義」の話をします。
AI評価ループを回せる人間が強い、というのはスキルの話だけじゃないと思っていて。
「評価する専門性」がAI時代に求められる理由
最後に、ここまでの話を踏まえて、「専門性」の意味そのものが変わってきている話をして締めます。
これは僕が最近強く感じていて、キャリア観にも影響する話です。
「作る専門性」と「評価する専門性」を分けて考える
これまで、専門性 = 作る能力、と暗黙に思われていました。
コードが書ける、デザインが描ける、文章が書ける。
でも、「作る」のコストが下がる中で、「作る能力」だけでは差別化が効きにくくなってます。
代わりに価値が出てくるのが、「評価する専門性」です。
具体的には、以下のような能力です。
- どういう観点で見れば良し悪しが判定できるか、その観点リストを持っている
- 観点ごとに合格・不合格の基準を言語化できる
- 観点同士のトレードオフを把握していて、優先順位をつけられる
- 失敗パターンを大量に知っていて、危険な兆候を素早く嗅ぎ取れる
これらは「作る」とは別軸の能力で、現場経験が長い人ほど自然に蓄積されています。
ただ、多くの人がそれを言語化していないので、AIに移植できていない。
評価軸を言語化してテンプレ化することは、自分の中の暗黙知をAIに渡すことそのものなんですよ。
コードが書けなくても、テストケースを設計できる人は強い
ここから先は希望のある話です。
コードが書けなくても、「このシステムだったら、こういうテストケースが必要だよね」を設計できる人は、今後すごく強くなります。
実装はAIに任せて、テスト観点は人間が握る。
これだけでも、品質責任の大きな軸を担えるようになります。
デザインも同じで、図を自分で描けなくても、「ユーザーがこの画面でつまづくのは、ここに導線がないからだ」と判断できる人は、AIにデザイン案を出させて評価する役割で価値が出ます。
文章も同じで、「この文章は読者に届くか・届かないか」を判断できる人は、AIに書かせて評価する役割で十分強い。
つまり、「作る」を持っていなくても、「評価する」を持っていれば成果が出る時代が来てます。
これ、5年前なら考えられなかったキャリアパスです。
専門性を「作る能力」だけで測るのではなく、「判定の構造を持っているか」で測る。
その視点に切り替えられた人から、AI時代の波に乗っていけるんじゃないかなと思ってます。
まとめ: 評価ループを設計できる人が、AI時代の品質を握る
長くなったので、最後にざっとまとめます。
- AIは「作る力」は強いが「評価する力」は弱く、最終確定責任は依頼者にある
- 評価軸がないまま「とりあえず投げる」は、判断疲れで品質が落ちる擬似ループになる
- 評価ループの基本は「作る → 評価 → 構造化フィードバック → 再生成」
- 評価軸の3要素は「完了条件・品質基準・再生成トリガー」。これを仕様段階で埋め込む
- ループを回す4ステップは「観点を先に渡す・観察を構造化する・仕様に反映する・評価基準もアップデートする」
- 1つのエージェントに全部見せず、観点別に分担させると精度が上がる
- モデル併用で見落としが減る
- 専門性の定義は「作る能力」から「判定の構造を持っていること」へシフトしている
AIにアウトプットを任せられるようになった今、価値の源泉は「何を作るか」ではなく、「何をもって完成とするか」を決められることに移りました。
評価軸を持って、ループとして運用できる人が、AI時代の品質を握ります。
明日からできるアクションを1つだけ。
次にAIに何かを頼むとき、依頼文の末尾にこの3行を足してみてください。
完了条件:
品質基準:
再生成トリガー: 中身はざっくりで構いません。
「完了条件: 必要な項目が全部埋まっている」くらいでも、渡すのと渡さないのでは初稿の質が変わります。
一度体感してみると、「あ、これが評価ループか」と分かるはずです。
ループは、最初の1回を回すところから始まります。
- 3
- 0

元メガベンチャーのプロダクトマネージャー。 PRD、ユーザーインタビュー分析、競合調査、ロードマップ策定などPM業務の8割をAIと一緒にやっています。 「AIに任せる判断力」は、現場で泥臭くやってきたPMだからこそ。PM × AI の実践ノウハウを発信中。

こちらもおすすめ
-
コードを読まないAIエンジニア
- 3
- 0
-
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0

















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます