
こんにちは。もるふぉです。
Claude 金融エージェント10個の発表、見ましたか?
「業務エージェントを作りたいんだけど、設計の指針が何もない」——そう感じたことはありませんか。
業務システムにAIを組み込もうとして、「どこから手を付ければいいのか」「どう設計すれば再利用できるのか」が分からなくて、結局PoC止まりで終わる。そんな経験、自分も何度かしてきました。
Anthropicが2026年5月5日に出してきたこの10個には、まさにその問いへの答えが詰まってます。
しかも、これは単なる金融特化ニュースではありません。中を覗くと「業務エージェントを設計するときの標準テンプレ」が見えてくるんですよ。Skills・Connectors・Subagentsという3層構造で、自社ドメインにそのまま横展開できる設計パターンです。
この記事では、10個のテンプレートの中身と、KYCスクリーナーのJSON出力スキーマ、2つのデプロイ方式の比較、そして自社で同じ設計を組むときのチェックリストまで、技術視点で読み解いていきます。
読み終えたとき「あ、それなら自分のドメインでも作れる」と思えるはずです。
Anthropicが2026年5月5日に発表したClaude 金融エージェントとは
まずは何が出たのかを整理します。
Anthropicは2026年5月5日に、金融サービス向けのClaude 金融エージェント10個を「ready-to-run」テンプレートとして公開しました。
GitHub上のfinancial services marketplaceで配布されており、Claudeの全有料プランで使える形です。裏で動くモデルはClaude Opus 4.7。Vals AIのFinance Agent benchmarkで64.37%というスコアを出してます。この数字は後ほど詳しく解説しますが、「人間レビュー前提」の設計思想を理解する鍵なのでぜひ覚えておいてください。
10個の内訳——Research系5個とOperations系5個
10個のテンプレートは、用途別に2グループに分かれてます。
Research & Client Coverage(リサーチ・クライアント対応)系は5個。
Pitch builder: 投資銀行のピッチ資料を作るエージェントMeeting preparer: クライアントミーティングの事前準備Earnings reviewer: 決算レビューModel builder: 財務モデル構築Market researcher: マーケットリサーチ
Finance & Operations(経理・オペレーション)系も5個。
Valuation reviewer: バリュエーションのレビューGeneral ledger reconciler: 総勘定元帳の照合Month-end closer: 月次決算Statement auditor: 財務諸表監査KYC screener: 顧客審査(後で詳しく解剖します)
並べてみると分かるんですが、片方は「アナリストの作業を加速させる」系、もう片方は「経理オペレーションの定型業務を自動化する」系です。
業務システムで言うと、フロントオフィスとバックオフィスの分け方そのままなんですよ。自社業務に置き換えるなら、「営業支援系」と「事務処理系」みたいに用途を切り分ける発想で読むと整理しやすいです。
「ready-to-run」の意味——Skills・Connectorsを設定して自社業務に合わせる
「ready-to-run」と聞くと「すぐ動くんでしょ」と思いがちですが、ここは慎重に読んだほうがいいです。
実態は「骨組みは完成している、ただし自社のデータ接続とポリシー調整は必須」というレベル感です。Skills(業務手順)とSubagents(並列ワーカー)の構造はテンプレートとして提供されますが、Connectors(外部データへの接続)は自社のデータソースに合わせて設定する必要があります。
たとえばPitch builderなら、ターゲット企業リストを渡すと、comps model(比較企業モデル)をExcelで作り、pitchbookをPowerPointに、cover noteをWord(またはOutlook——Outlookアドインは近日公開予定)に下書きするまでカバーします。ただし「どのデータベースから比較企業を引っ張るか」「どのテンプレで資料を作るか」は社内ルールに合わせて設定する形です。
ここがまさに、エージェント設計の核心部分です。「テンプレートを使う=設定不要」ではなく、「テンプレートを使う=設計判断の8割が省略できる」と理解するのが正しいんですよ。
では、この10個を支えている設計の骨格はどうなっているのか。次のセクションが本題です。
3層アーキテクチャ(Skills・Connectors・Subagents)の設計思想
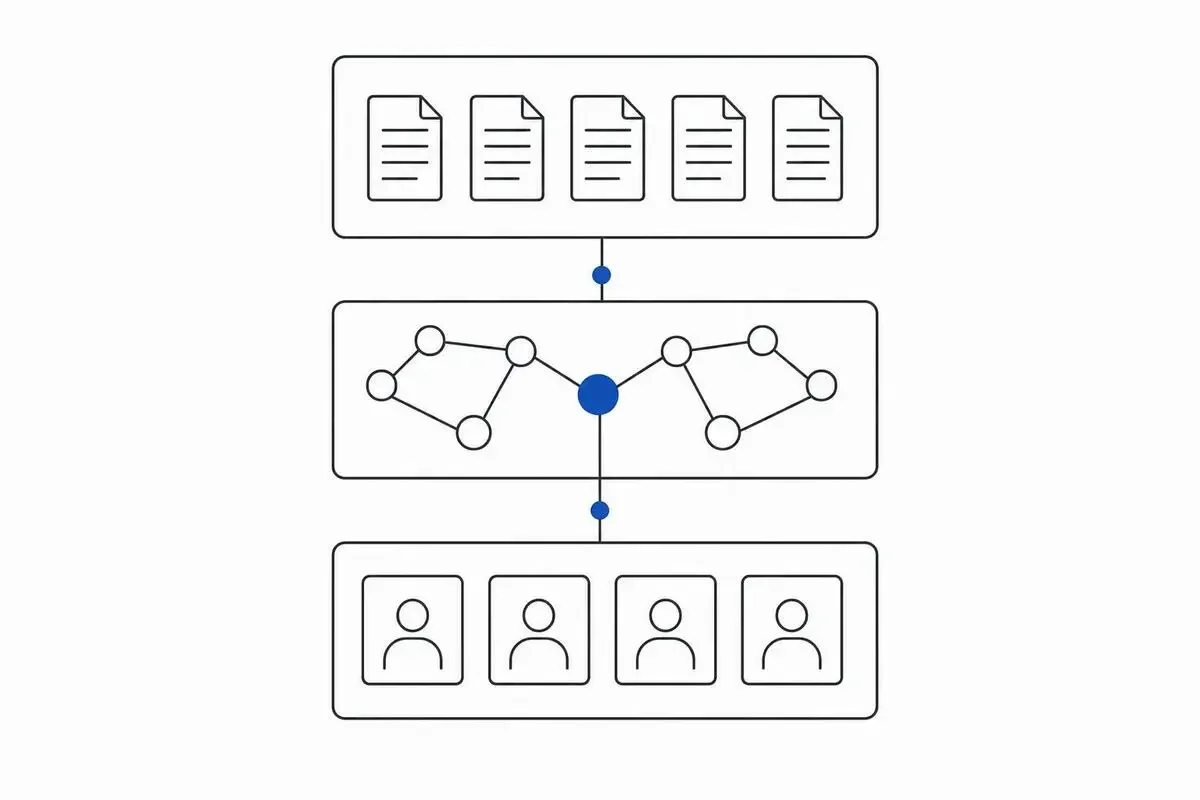
ここからが本題です。10個のテンプレートに共通している3層アーキテクチャを見ていきます。
最初に要約だけ書いておくと、こうなります。
- Skills: Markdownを中核とした業務手順書パッケージ。エージェントの「脳」にあたる
- Connectors: 外部データへのガバナンス付きアクセス層。エージェントの「手足」
- Subagents: コンテキスト分離された並列ワーカー。エージェントの「分身」
料理に例えるなら、Skillsはレシピ、Connectorsは食材調達ルート、Subagentsは厨房の各担当(前菜担当・メイン担当・デザート担当)という感じです。
Skills——Markdownの業務手順書がそのままエージェントの脳になる
ここ、自分が一番「おっ」と思った部分です。
AnthropicのSkillsは、専用のDSLでもJSONでもなくて、SKILL.mdというMarkdownファイルを中核とする構造になってます。
エージェントが何かタスクを実行するとき、このMarkdownを読んで手順通りに動きます。Markdownの指示書が軸になっていますが、必要に応じて実行スクリプトや参照ファイルも同梱できるディレクトリ構造なので、複雑な業務にも対応できるんですよ。
何が嬉しいかというと、社内に既にある業務マニュアルやRunbookを、ほぼそのままSkillsのベースとして使えるんです。
新しい記法を覚える必要がない。エンジニアじゃない業務担当者がメンテナンスできる。バージョン管理もGit上で普通に回せる。
業務システム開発をやってる人ならピンとくると思いますが、これは「ドキュメント=コード」というアプローチです。Railsアプリで言うと、app/services/配下にビジネスロジックを書く代わりに、docs/skills/配下にMarkdownを置く感覚です。サービスクラスの仕様書がそのまま実行可能になる、みたいなイメージですね。
横展開のヒントを1つ書いておきます。自社でエージェントを作るなら、まず「既存の業務マニュアル」を棚卸しして、Markdownに整形するところから始めると速いです。新しくゼロから作る必要はありません。
Connectors——外部データへのガバナンス付きアクセス設計
Connectorsは外部データへのアクセス層です。
今回の発表では、8社のデータコネクター(Dun & Bradstreet, Fiscal AI, Financial Modeling Prep, Guidepoint, IBISWorld, SS&C IntraLinks, Third Bridge, Verisk)が新規追加され、加えてMoody'sのMCPサーバーも統合されました。
ここで重要なのは「ガバナンス付き」という点です。エージェントが好き勝手にデータを取りにいくのではなく、許可されたデータソースに対して、許可された権限で、ログを残しながらアクセスする仕組みになってます。

業務システムのエンジニアからすると、これは「APIゲートウェイ+IAM+監査ログ」を1つにまとめた設計に近いです。
自社で同じ設計をするなら、データソースごとに「読み取り専用」「特定テーブルのみ」「監査ログ必須」といった粒度でアクセス制御を設計するのが定石です。
Subagents——コンテキスト分離と並列処理で品質を上げる仕組み
Subagentsは、メインのエージェントが「下請け」として呼び出す並列ワーカーです。それぞれが独立したコンテキストウィンドウを持っていて、特定タスクに集中できます。
なぜコンテキスト分離が大事かというと、コンテキストウィンドウが膨れすぎると、AIの判断品質が落ちるからです。1つのエージェントに「市場リサーチ」「比較企業選定」「資料作成」を全部やらせると、どこかで情報が混線します。Subagentsで分割すれば、それぞれが必要な情報だけに集中できる。
これも業務システム開発で言うと、Sidekiqジョブを役割別に分割するのと似た発想です。「メールを送るジョブ」「画像を処理するジョブ」「集計するジョブ」を分けるのと同じで、エージェントも「リサーチ担当」「資料生成担当」「レビュー担当」と分けたほうが、デバッグもチューニングもしやすいんですよ。
SaaS開発で言い換えると、マルチテナント処理を非同期ジョブで分散させるあのアーキテクチャと本質的には同じです。処理ごとに責任範囲を切る、という発想ですね。
横展開ヒント: Subagentsは並列実行が基本なので、依存関係のないタスクほど分割しやすいです。逆に「Aの結果を見てBを判断する」みたいな逐次処理が多い業務は、Subagents化のメリットが薄いです。最初に並列性を見極めるのが設計のキモです。
3層の構造が分かったところで、次は「審査系タスク」の設計パターンに踏み込みます。ここからが個人的に一番面白いところです。
KYCスクリーナーを解剖する——審査系タスクの設計パターン
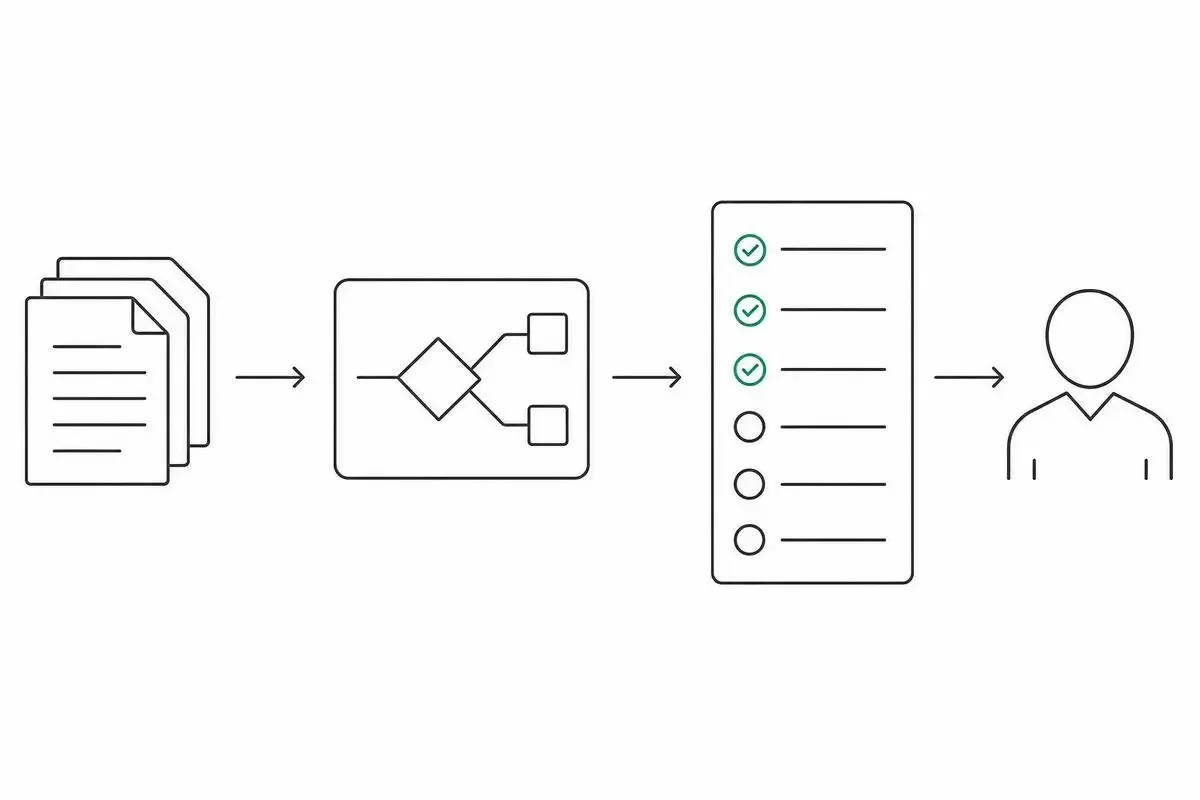
ここが個人的に一番熱いセクションです。
10個のテンプレートの中で、KYC screenerだけは設計の「型」がそのまま他ドメインに転用できるんですよ。金融の話じゃなくて、「審査」が絡む業務全般の話になります。
JSON出力スキーマ(risk_rating / disposition / rule_outcomes)
KYC screenerが出力するのは、自然言語の文章ではなくて、構造化されたJSONです。ざっくりこんな形です。
{
"risk_rating": "medium",
"disposition": "request-docs",
"missing_documents": [
"proof_of_address",
"beneficial_owner_declaration"
],
"escalation_reasons": [
"rule 4.2: confirmed PEP",
"high-risk jurisdiction"
],
"rule_outcomes": [
{ "rule_id": "sanctions_check", "outcome": "clear", "evidence": "OFAC list checked at 2026-05-05T10:30Z, no match" },
{ "rule_id": "pep_check", "outcome": "match", "evidence": "matched against EU sanctions database, see ref-12345" },
{ "rule_id": "adverse_media", "outcome": "clear", "evidence": "Refinitiv World-Check, 0 results" }
]
}5つのフィールドの意味はこうです。
risk_rating: low / medium / high の3段階リスクスコアdisposition: 推奨アクション(clear / request-docs / escalate-EDD / decline-recommend)missing_documents: 不足書類のリストescalation_reasons: エスカレーション理由rule_outcomes: 個別チェック項目の結果(rule_id/outcome/evidenceの3つ組)
ここ、ちょっと注目してください。
このスキーマ、よく見ると審査系・チェック系タスク全般に使える普遍的なパターンなんですよ。金融KYCに限らず、「申請を受け取って、ルールに照らして、判定を出す」という業務であれば、ほぼそのまま使い回せます。ここだけでも持ち帰る価値があります。
「人間がレビューする前提」の設計思想——64.37%という数字をどう読むか
冒頭で触れたVals AIベンチマークの64.37%。これ、単独で見ると「正解率64%って低くない?」と思うかもしれませんが、設計思想を理解すると見方が変わります。
Anthropicは明確に「人間がレビューする前提」でこのテンプレートを設計してます。
エージェントは「初稿を作る」「データを集める」「候補をリストアップする」までが仕事で、最終判断は人間がやる。だから出力がJSONなんです。人間が一目で「ここは妥当」「ここは確認必要」と判断できる構造化データのほうが、レビュー効率が圧倒的に高いんですよ。
これはビジネスエージェント設計の基本姿勢として覚えておいたほうがいいです。「AIに全部任せる」のではなく「AIが叩き台を作って人間が判断する」という前提で出力を設計すると、品質要件が現実的なラインに収まります。
金融KYC以外(採用審査・与信・ライセンス確認)への横展開
このJSON出力スキーマ、金融以外でも使えます。具体例をいくつか挙げます。
採用書類審査エージェント。
{
"risk_rating": "low",
"disposition": "advance-to-interview",
"missing_documents": ["portfolio_url"],
"escalation_reasons": [],
"rule_outcomes": [
{ "rule_id": "skill_match", "outcome": "match", "evidence": "Required skills confirmed in resume and GitHub profile" },
{ "rule_id": "experience_check", "outcome": "clear", "evidence": "5 years relevant experience verified" }
]
}中小企業向けの与信審査エージェント。
{
"risk_rating": "high",
"disposition": "escalate-EDD",
"missing_documents": ["latest_financial_statement"],
"escalation_reasons": ["debt_to_equity_ratio_exceeded"],
"rule_outcomes": [
{ "rule_id": "credit_score_check", "outcome": "match", "evidence": "Credit score 520, below threshold of 600" },
{ "rule_id": "industry_risk", "outcome": "high", "evidence": "SIC code 5812 classified as high-risk sector" }
]
}業務システム開発をしているエンジニアなら、自社の「申請受付→チェック→承認」というワークフローのどこかに、このパターンを当てはめられる場面が必ずあるはずです。SaaSであれば、利用申込み審査、加盟店審査、契約書チェックあたりが王道ですね。
設計のコツは、rule_outcomesのrule_id名を業務言語にしておくことです。エンジニアの内部用語ではなく、業務担当が読んでわかる名前にしておくと、レビュー時のコミュニケーションコストが激減します。
JSON設計の話が分かったところで、次はデプロイの選択肢を整理します。「どう動かすか」で開発コストが全然変わるので、ここも重要です。
2つのデプロイ経路——Cowork/Claude CodeプラグインとManaged Agents Cookbookの比較
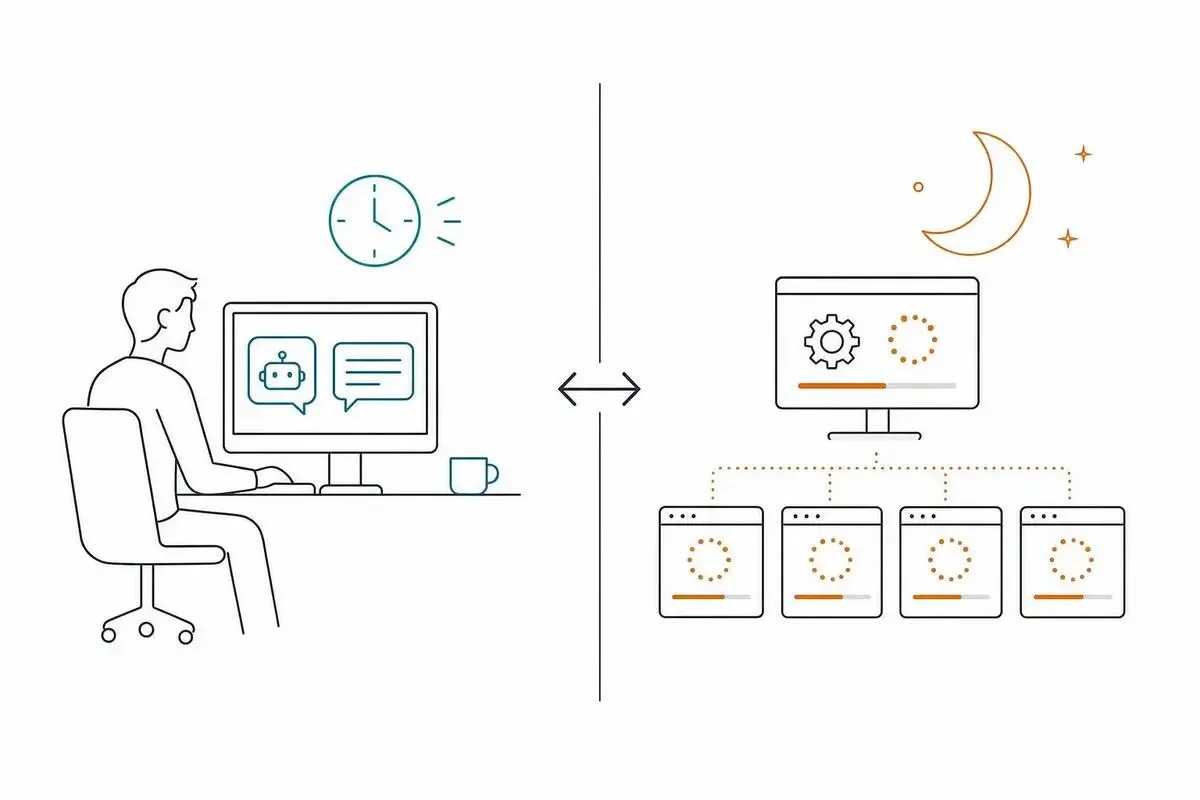
これ、実は業務の性質ひとつで答えが変わります。
10個のテンプレートには、2つのデプロイ方法が用意されてます。「人間と並走する形」と「自律で動かす形」のどちらを選ぶか、見ていきましょう。
アナリスト並走型(Cowork/Claude Code)——人間がレビューしながら使う形
1つ目は、ClaudeのCoworkまたはClaude Codeのプラグインとしてデプロイする形です。Claudeの全有料プランで使えます。

これは「アナリストが業務をしながら、必要なときにエージェントを呼び出す」スタイルです。たとえばPitch builderなら、アナリストが「この企業のピッチ資料を作って」と指示し、出力をその場でレビューして、修正を指示しながら仕上げていく。
人間がリアルタイムでレビューするので、品質保証が強いです。一方で、人間の時間が必要なので、スケールに限界があります。
自律運用型(Managed Agents Cookbook)——長時間バックグラウンド実行
2つ目は、Managed Agents経由でデプロイする形です。Cookbookと呼ばれるコード集(パブリックベータ)が公開されており、これを使うと業務フローをバックグラウンドで自律実行できます。
この形は、夜間バッチや大量処理に向いてます。たとえばGeneral ledger reconcilerを夜間に走らせて、朝には例外項目だけ人間がレビューする、といった運用が可能です。
ただし、自律実行する分、エラー処理や監視を自分で組み込む必要があります。失敗したときに誰が気づくか、どう復旧するかを設計しておかないと、サイレント障害が起きやすいです。
コスト・レイテンシ・人間介在度の3軸で選ぶ
2つの方式の使い分けを表にまとめます。
選ぶ基準はシンプルで、「業務担当が常時レビューできる量か?」を最初に問うのがいいです。1日10件程度ならCowork/Claude Codeプラグイン、1日1000件を超えるならManaged Agents Cookbook、という肌感覚です。
実務では両方を組み合わせるのもアリです。日中はCowork経由でアナリストが使い、夜間はManaged Agentsでバッチ処理する、みたいな形ですね。
デプロイ方式が決まったら、次はConnectors層を具体的に設計する話です。エージェントの「賢さ」はデータアクセスで決まる、という話をします。
データコネクターとMCPエコシステムの実力——Connectors層を支える仕組み
ここでは、Claude 金融エージェントの裏側を支えているConnectors(データ接続層)の話をします。エージェントの賢さは、結局のところ「どんなデータにアクセスできるか」で決まるからです。
8社の新コネクター——どんなデータにアクセスできるか
今回新たに統合された8社のデータコネクターは、それぞれ得意領域が違います。
注目すべきは、Bloomberg/Refinitivみたいな「総合データプロバイダ」だけでなく、ニッチな専門データソース(GuidepointやThird Bridge)も含まれている点です。「1つの大きなデータ源より、複数の専門データ源を組み合わせるほうが強い」という設計思想の表れだと思います。
Moody's MCPの意味——6億以上の企業のクレジット情報・リスクデータをリアルタイム参照
Moody'sのMCPサーバー統合は、地味ですが破壊力あります。
MCP(Model Context Protocol)経由で、Moody'sが持つ6億以上の公開・非公開企業のクレジット情報やリスクデータをリアルタイムで参照できるようになりました。
何が嬉しいかというと、与信判断やKYCのワークフローで、最新のクレジット情報を直接エージェントが引っ張れることです。今までは人間がMoody'sのサイトで調べてエージェントに伝える、という回り道が必要でしたが、MCP経由で直接アクセスできるようになりました。
横展開のヒントとして、自社にも「業務担当が日常的に参照しているデータソース」が必ずあるはずです。社内DB、SaaS、外部API、Excelシートなど。これらをMCP化してエージェントから参照可能にすると、業務エージェントの実用度が一気に上がります。
自社でコネクターを作る場合の設計ヒント
自社データへのコネクターを作るときは、3つのポイントを押さえると失敗しにくいです。
1つ目は、読み取り専用から始めることです。書き込み権限を最初から渡すと事故ります。最初は「データを取ってくるだけ」のコネクターでエージェントを慣らして、安定したら段階的に書き込み権限を追加する流れが安全です。
2つ目は、ログを徹底することです。エージェントが「いつ・どのデータに・なぜアクセスしたか」を全部記録しておく。後でデバッグするときも、監査対応するときも、ログがないと地獄を見ます。業務システムでよくある「誰が何を変更したか分からない」問題と同じで、最初からログ設計を組み込むのがコツです。
3つ目は、レート制限とフォールバック設計です。エージェントは人間より高速にAPIを叩きます。レート制限に引っかかったとき、どう振る舞うかを決めておく必要があります。リトライ、キャッシュ、代替データソースへのフォールバックなど、業務継続性を担保する仕組みを最初から入れておきましょう。
設計ヒントが揃ったところで、いよいよ最後のセクションです。ここまでの知識を使って、明日から実際に動けるチェックリストに落とし込みます。
自社ドメインで設計するときのチェックリスト——Skills・Connectors・Subagentsで考える
ここまで読んでくれた方なら、もう自社で業務エージェントを設計する素地ができているはずです。
「でも、実際どこから始めればいいの?」という問いに答える形で、明日から試せるチェックリストをまとめます。難しく考えなくて大丈夫です。まず1つ動かしてみるところから始めればいいです。
Skillsに書くべき「業務手順書」の5要件
Skills(Markdown業務手順書)を書くとき、最低限押さえるべき5要件はこれです。
- 目的の明示: 「このSkillは何をするためのものか」を1文で書く
- 入力の定義: 何を渡されたら動くのか(必須・オプション)
- 手順の具体化: ステップごとに「やること」と「やらないこと」を明記
- 出力フォーマット: JSON / Markdown / 表形式など、構造を決めておく
- エスカレーション条件: 「こうなったら人間に渡す」という分岐を書く
5番目のエスカレーション条件が抜けてるSkillsをよく見ますが、ここが一番大事です。AIが迷ったときに「人間に投げる」という選択肢を必ず用意しておかないと、無理に判断して品質が落ちます。最初に「人間に渡す条件」を決めておくだけで、エージェントの挙動が格段に安定します。
Connectors設計——必要最小限のデータアクセス権限を意識する
Connectors(外部データ接続)の設計では、最小権限の原則を必ず守ってください。エージェントに渡す権限は、業務に必要な最小限だけ。社内のDBを丸ごと読めるようにするのは事故のもとです。
具体的には、業務単位でデータビュー(読み取り専用のSQL ViewやAPI ラッパー)を作って、エージェントはそれだけにアクセスする形がおすすめです。後から権限を絞るのは大変なので、最初から狭く設計するほうが楽です。
Subagents分割の判断基準——コンテキストウィンドウと並列性を軸に
Subagents(並列ワーカー)の分割は、2つの軸で判断します。
1つ目はコンテキストウィンドウです。1つのエージェントに渡す情報量が膨らみそうなら、Subagentsで分割してコンテキストを細切れにする。たとえば「100社分の財務データを分析する」なら、1社ずつSubagentsに振り分けて並列実行するイメージです。
2つ目は並列性です。タスク間に依存関係がなければ、Subagentsで並列化したほうが速い。逆に「Aの結果を見てBを判断する」みたいな逐次タスクは無理に分割しないほうがいいです。
設計でつまずきやすいのが、この「分けすぎ問題」です。Subagentsを増やすほどデバッグが大変になるので、迷ったら最初は1つのエージェントで作って、必要になってから分割する形がおすすめです。
人間レビュー設計——どの出力を人間が確認するか決める
最後に、人間レビューの設計です。これを最初に決めないと、運用が始まってから「結局全部レビューしてる」状態になります。
判断軸はシンプルで、「失敗したときの影響度」と「AI判定の信頼度」の2軸です。
- 影響度高×信頼度低: 必ず人間レビュー(例: 大口顧客のKYC、金額の大きい契約)
- 影響度高×信頼度高: サンプリングレビュー(例: 中堅顧客のKYC)
- 影響度低×信頼度高: 自動承認(例: 定型書類の不足チェック)
- 影響度低×信頼度低: 例外検出時のみレビュー
業務開始前にこの4象限を業務担当と握っておくと、運用負荷が劇的に下がります。
4象限を書き出すだけなら15分もかからないので、エージェント設計の最初の一歩としてここから始めるのがおすすめです。
まとめ——Claude 金融エージェントが示す「業務エージェント標準化」の方向性
ここまで、Anthropicが2026年5月5日に発表したClaude 金融エージェント10個を、技術視点で解剖してきました。
最後に押さえておきたいのは、これは「金融特化のニュース」ではなく、「業務エージェント標準化の方向性が見えた発表」だということです。
3層アーキテクチャ(Skills・Connectors・Subagents)は、ドメインに依存しない設計パターンです。Skillsは社内マニュアルから流用できる、Connectorsは最小権限で設計する、Subagentsは並列性で分割する——この設計指針は、金融以外のあらゆる業務に当てはまります。
KYCスクリーナーのJSON出力スキーマも、審査系・チェック系タスクの普遍的な型として使えます。risk_rating / disposition / rule_outcomesという構造は、採用審査でも与信でも、ライセンス確認でも応用できる。
そしてデプロイ方式も、人間並走型と自律運用型の2系統が用意されているので、業務の性質に合わせて選べばいい。1日10件ならCowork、1000件超えるならManaged Agents、というシンプルな判断軸です。
業務エージェントを作りたいけど何から手を付ければいいかわからなかった人、既存の業務システムにAIを組み込みたいけど設計指針がなかった人、今回の10個のテンプレートは確実に「設計の標準テンプレ」になります。
まず明日やることは1つだけです。社内の業務マニュアルを1枚引っ張り出してきて、Markdownに整形する。それだけでいい。それがSkillsの第一歩になります。コピペでOKです。
次の一手として自分は、複数のエージェントをSubagentsで束ねるパターンを実案件で試してます。手応えが出てきたらまた書きますね。
それでは、よい設計を。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 3
- 0
-
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
AI脱社畜
- 2
- 0
-
- 2
- 0
-
- 2
- 0
-
- 1
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0


















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます