こんにちは。
もるふぉです。
「Realtime APIって聞いたことあるけど、ちゃんと触ったことはない」「pipecatやLiveKitとの違いがよく分からない」──そういう状態のまま、なんとなく後回しにしてませんか?
僕も似たような感じだったんですが、あるツイートをきっかけに、ちゃんと向き合ってみる時期が来たなと思いました。
きっかけはこのツイートでした。
OpenAI Devs が「Hi Chappy 👋」と話しかけるだけで、画面の中のキャラクターが動いて、テーマが変わって、ちょっとした会話が成立する短いデモです。
派手な見た目ではないんですが、エンジニア目線で見ると地味にすごい。
何がすごいかというと、ボタンも、キーボードショートカットも、コマンドパレットも介さずに、声でアプリの状態(state)が直接書き換わっていることです。
しかも続編のツイートで「自分で試してみたい?オープンソースのリポジトリ用意したよ」と来ました。
それが realtime-voice-component というリポジトリで、gpt-realtime-1.5 を使ってブラウザ上で音声UIを組むためのリファレンス実装です。
この記事では、X投稿のデモをきっかけに、gpt-realtime-1.5 というモデルが何を変えたのか、realtime-voice-component がどういう設計思想で組まれているのか、実装の核心はどこか、そして「いま本番で使えるのか」までを、現役エンジニアの視点で読み解いていきます。
「Hi Chappy 👋」──OpenAIが投げてきた、声でUIを動かすデモ
まずデモの体験をテキストで再現すると、こんな感じです。
ユーザーがマイクに「Hi Chappy」と話しかける。
画面の中央にいるキャラクター(Chappy)が表情を変えて返事をする。
「ダークモードに切り替えて」と言うと、画面のテーマがするっと暗くなる。
「もう少し明るくして」と言うと、明るさが調整される。
「左側にメニューを出して」とか、「ヒント表示して」と言うと、UIの状態が連動して変わる。
これだけ書くと「いやSiriやAlexaも昔からやってるじゃん」と思うかもしれません。
でも、よく見ると違うんですよ。
スマートスピーカー系の音声操作って、基本は 「音声コマンド → デバイス機能の呼び出し」 という1対1のマッピングです。
電気を消す、音楽を鳴らす、タイマーをセットする。
事前に決められたインテント(意図)に音声を分類して、対応するハンドラを呼ぶ。
ところが Chappy デモでやっていることは、Web アプリの内部状態を、自然言語ベースでそのまま書き換えることです。
「ダークモード」も「左メニュー」も「ヒント表示」も、Webアプリ側の React state を、AIが「いまこれを変えるべきだ」と判断してツールとして呼び出す形になってます。
僕がこのデモを見て一番アツいと思ったのは、「ユーザーが何を言うか分からないアプリ」のUIを、声で操作できるようになったということです。
これまでの音声操作は「事前に登録した発話」に強かったんですが、今回は「ユーザーが普段アプリで触る全機能」を音声から呼べる構造になっています。
つまり、既存の React アプリに「声の入口」を後付けできる、ということです。これが何を意味するか、設計の話に降りていきましょう。
gpt-realtime-1.5は何が変わったのか
realtime-voice-component の中身に入る前に、土台となっている gpt-realtime-1.5 を整理しておきます。
ここを押さえないと、「なぜいまこの設計が成立するのか」が分からないんですよ。
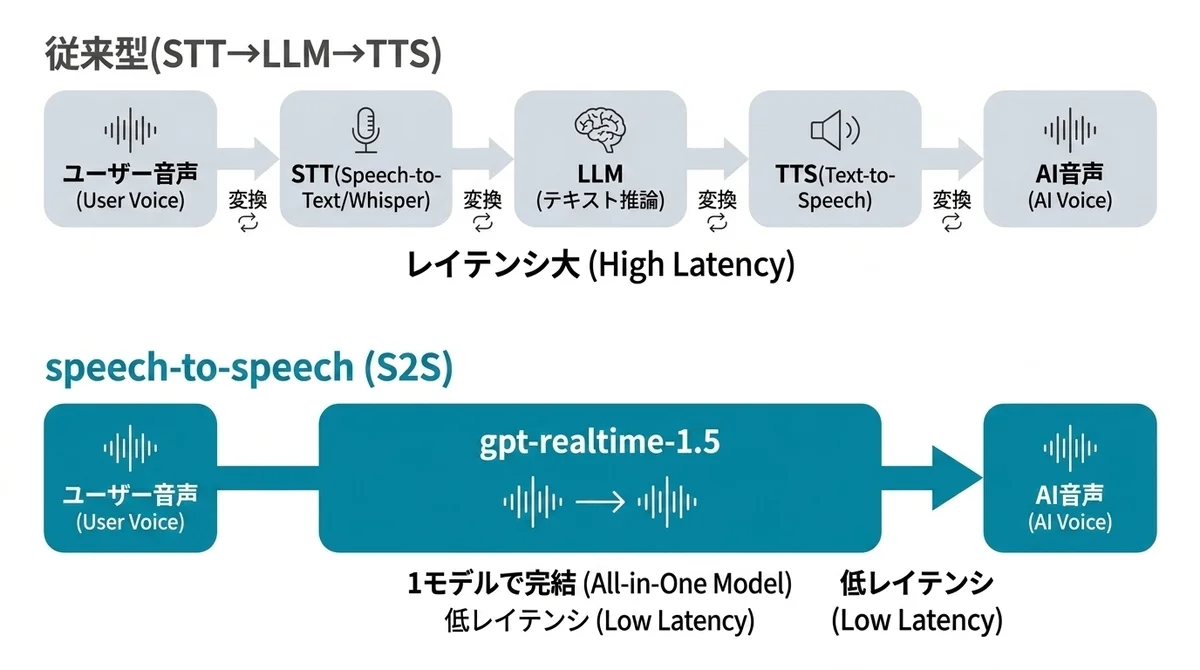
STT→LLM→TTSを捨てた「speech-to-speech」のアーキテクチャ
従来の音声AIは、ほとんどが3層パイプラインでした。
ユーザーの音声を Whisper などで文字起こし(STT)して、テキストを LLM に渡して、出てきたテキストを TTS で音声に戻す。
この構成は枯れていて作りやすい反面、レイテンシが大きい、文字起こしで失われるニュアンスがある、トーンや感情がモデル間で寸断される、という弱点がありました。
gpt-realtime 系列はここを捨てて、音声 → 音声を1モデルで完結させる speech-to-speech(S2S)アーキテクチャを採用しています。
ざっくり言うと、こういう流れです。
flowchart LR
A[ブラウザ<br/>マイク・スピーカー] -- WebRTC<br/>音声+DataChannel --> B[/session<br/>自前サーバー/]
B -- ephemeral token<br/>SDP --> C[OpenAI Realtime API<br/>gpt-realtime-1.5]
C -- 音声+ツール呼び出しイベント --> A
A -- ツール実行・state更新 --> A途中にテキスト変換が挟まらないので、応答までの遅延がぐっと縮みます。
公式が出しているガイドや、僕が触ってみた感覚だと、ターン全体で250〜500msくらい。
人間同士の会話に近い「割り込み可能な」レベルになっています。
ちなみにこのモデル、gpt-realtime-1.5 という名前が示す通り、gpt-realtime の改良版です。
公式の発表では Big Bench Audio(音声推論)で約5%、英数字の書き起こし精度で約10%(+10.23%)改善、ツール呼び出しの信頼性向上といった改善が報告されていて、特にツール呼び出しの安定化が今回の realtime-voice-component 設計と深く関係しています。
ツール呼び出しの信頼性と多言語対応の改善点
エージェント系の機能で一番ストレスが溜まるのって、「呼んでほしいタイミングで呼んでくれない」「呼ばないでほしいタイミングで呼んでしまう」というツール呼び出しの不安定さなんですよ。
正直、gpt-realtime の初期バージョンは、ツールを定義しても会話の流れによって呼んだり呼ばなかったりが結構ありました。
gpt-realtime-1.5 でここが大きく改善されています。
具体的には、
- ツール定義に書いた
descriptionをちゃんと読みに行くようになった - 引数の型をスキーマ通りに整形してくる確率が上がった
- 1ターン内で複数ツールを連続呼び出ししても落ちにくくなった
呼び出しが信頼できるからこそ、UI の状態を声で書き換えるという発想が成立するわけです。
それに加えて、多言語対応が地味に効いていて、日本語と英語を混ぜた発話(いわゆる Code-switching)でも、ツール呼び出しの精度がほとんど落ちません。
日本語UIを持つ国内プロダクトで使う場合、ここはかなり重要なポイントになります。
ツール呼び出しの信頼性と多言語対応が揃ったことで、「声でUIを動かす」というユースケースの実用度が大きく押し上げられた、ということです。次はその設計思想の話に入ります。
realtime-voice-componentが提案する「app-owned state」という設計思想
ここからが本題です。
realtime-voice-component がなぜ普通の「ボイスエージェントSDK」と違うのか、設計思想を読み解いていきます。
ツールはUIへの薄いインターフェースに過ぎない
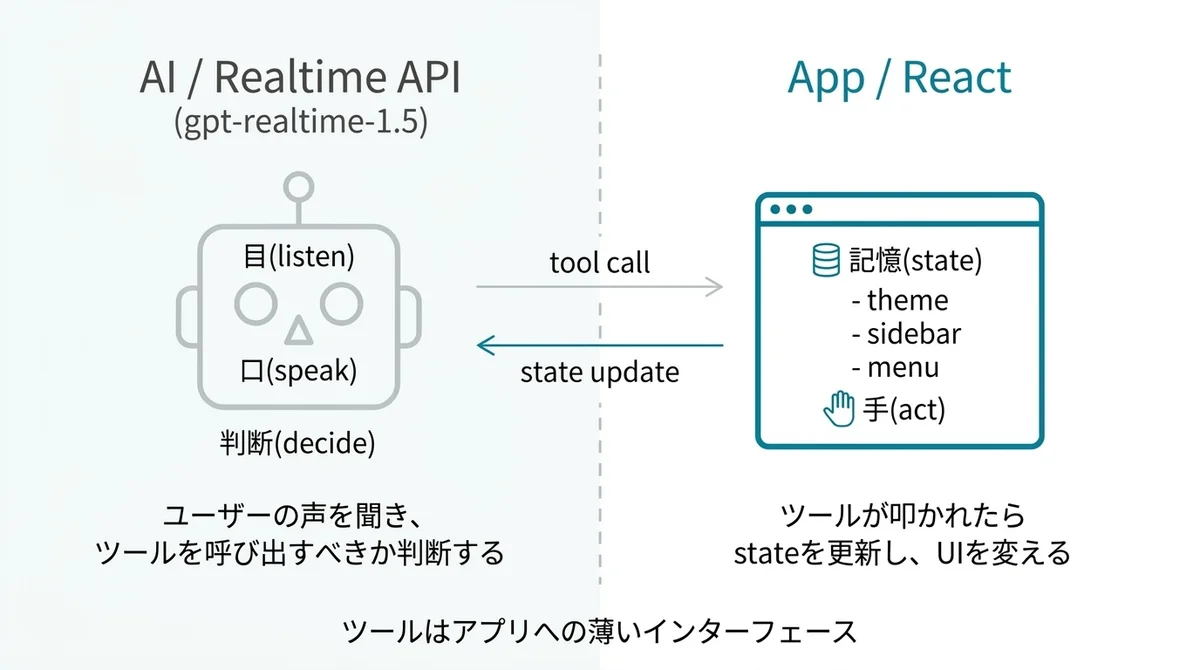
このリポジトリのコードを読んで僕が一番「おっ」と思ったのは、「ツールはアプリへの薄いインターフェースであり、状態(state)はあくまでアプリが持つ」 という分離が徹底されていることです。
いわば、AIは「指示を出す人」であって、「手を動かすのはアプリ側のコード」という構造です。
Reactをやってきたエンジニアならすぐにピンとくる Controlled Component パターンに近い考え方なんですよ。
たとえば、AIエージェント系のフレームワークだと「Agent内部に会話履歴・状態・タスクキューを全部持たせる」という設計が結構多くて、その結果アプリ側のstateとAgent内部のstateで二重管理になりがちでした。
realtime-voice-component はそこを逆向きに割り切っています。
- アプリのstate(テーマ、サイドバー開閉、入力中のテキスト、何でも)はアプリが持つ
- Realtime API は「いまこのツールを呼ぶべき」と判断して関数を叩くだけ
- ツールの中身は「アプリのstateを変えるロジック」のラッパー
つまりAI側は 「目」と「口」と「判断」 を持っているだけで、「手」と「記憶」はアプリ側にある という構造です。
この設計の何が嬉しいかというと、
- AIが暴れても、影響範囲はツールが提供する操作だけに閉じる
- 既存のReactアプリにあとから音声レイヤーを足せる(state は触らずに済む)
- テストが書きやすい(ツール関数は普通の純粋関数として単体テストできる)
特に最後のテスタビリティは、僕がClaude Codeで開発するときに最重視している軸です。
「AIが触るインターフェース」と「アプリのコアロジック」が綺麗に分離されているコードは、後から仕様が変わっても安全に壊せます。
なぜZod・WebRTC・GhostCursorが同梱されているのか
このリポジトリ、依存関係を眺めると zod ・ WebRTC 周辺ユーティリティ・ GhostCursor という3点セットが入っていて、最初は「なんでこれが?」と思ったんですが、設計思想を踏まえると全部理由がはっきりします。
- Zod: ツール定義のスキーマを TypeScript の型と JSON Schema の両方に変換するために使う。AIに渡すスキーマと、TSコード上の型が二重定義にならない
- WebRTC: WebSocketではなく WebRTC を使う。その理由は次のセクションで詳しく書きます
- GhostCursor: 「AIが今どこを操作しているか」をユーザーに視覚的に見せるためのカーソル。声だけだと「AIがいま何をやろうとしているのか」が見えにくいので、UI上に薄いカーソルを出す。これUX的にめちゃくちゃ重要
GhostCursor の同梱は、最初「おまけかな」と思ったんですが、実際にデモを動かすと「あ、これ無いと不安だ」と気づきます。
声でアプリを動かすと、ユーザーは「ちゃんと聞こえてる?」「いま何してる?」と分からなくなる瞬間がある。
そこに薄いカーソルが「ここをクリックしようとしてますよ」と出ると、安心感が全然違うんですよ。
OpenAI が「リファレンス実装」として出している意味は、コードだけじゃなくこういう UX の作法ごと 提示しているところにあります。
設計思想が分かったところで、次は実装の核心に入ります。「APIキーをブラウザに置いてもいいのか?」という最初の壁の話です。
実装の核心──WebRTCとephemeral tokenで組むOpenAI Realtime APIの接続設計
さて、ここから実装の話に降りていきます。
ブラウザにAPIキーを置かないSDPプロキシ
OpenAI Realtime API をブラウザから叩くときに最初にぶつかる壁が、「APIキーをブラウザに置いていいのか?」 問題です。
答えは当然「ダメ」です。
OpenAI の API キーは課金が直結しているので、フロントエンドのバンドルに含めた瞬間、誰かに発見されたら破産コースになりかねません。
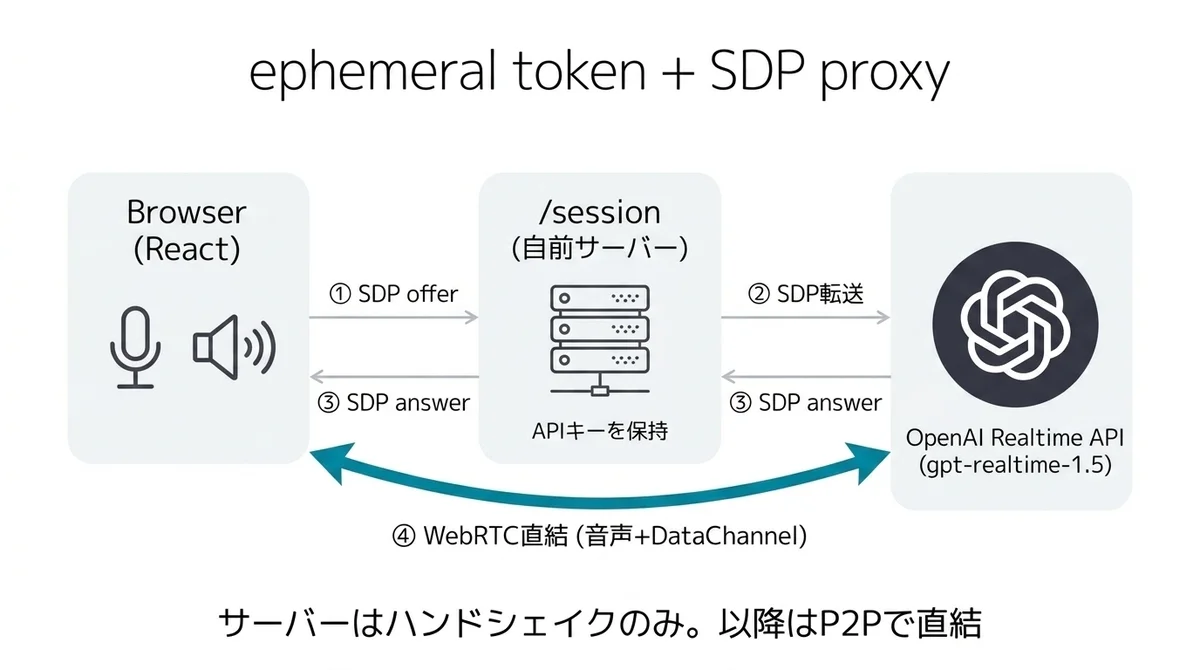
そこで realtime-voice-component が採用しているのが、ephemeral token + SDPプロキシ パターンです。
具体的には、自前のバックエンドに /session エンドポイントを立てて、
- ブラウザから WebRTC の SDP(Session Description Protocol)を
/sessionに POST する - サーバー側が APIキー(永続トークン)を使って OpenAI Realtime API に SDP を転送する
- OpenAI から返ってきた SDP(answer)をブラウザに返す
- それ以降はブラウザと OpenAI が直接 WebRTC で繋がる
最低限の /session エンドポイントを TypeScript(Express風)で書くとこんな感じです。
import express from "express";
import fetch from "node-fetch";
const app = express();
app.use(express.text({ type: "application/sdp" }));
const OPENAI_API_KEY = process.env.OPENAI_API_KEY!;
const REALTIME_MODEL = "gpt-realtime-1.5";
app.post("/session", async (req, res) => {
const sdp = req.body as string;
const upstream = await fetch(
`https://api.openai.com/v1/realtime?model=${REALTIME_MODEL}`,
{
method: "POST",
headers: {
Authorization: `Bearer ${OPENAI_API_KEY}`,
"Content-Type": "application/sdp",
},
body: sdp,
},
);
if (!upstream.ok) {
res.status(upstream.status).send(await upstream.text());
return;
}
res.set("Content-Type", "application/sdp");
res.send(await upstream.text());
});
app.listen(3000, () => console.log("session proxy on :3000"));ポイントは3つあります。
- ブラウザは
OPENAI_API_KEYを一切知らない。サーバーだけが持つ - やり取りしているのは SDP(接続情報)だけで、アプリのビジネスロジックは介在しない
- 一度繋がったあとの音声・ツールイベントは、ブラウザと OpenAI が直接 WebRTC で送受信する(自前サーバーを通らない)
3つ目が地味に効きます。
会話のたびに自前サーバーを経由していたら、レイテンシも帯域も自前サーバーで負担することになりますが、SDPプロキシ方式ならハンドシェイクだけで済むので、サーバー側はほぼスケール不要です。
「ハンドシェイク専用の薄いプロキシ」と考えると分かりやすいです。自前サーバーは玄関だけ担当して、あとはブラウザと OpenAI が直接会話する、というイメージです。
詳しくは公式のRealtime APIガイドに書いてあるので、本番で組むときは一読しておきましょう。
WebSocketではなくWebRTCを選ぶ理由
ここで「なんで WebSocket じゃなくて WebRTC なの?」という疑問が出てきます。
実際、初期の Realtime API のチュートリアルは WebSocket ベースのものが多くて、僕も最初は「WebSocketで十分なのでは?」と思っていました。
ところが、ブラウザでガッツリ音声UIを組むなら、realtime-voice-component が選んだ通り WebRTC のほうが圧倒的に向いてます。
理由をざっくり整理するとこうです。
特に エコー・ノイズ抑制 はブラウザ標準で効いてくれるので、自分でDSP(信号処理)を書かなくていい。
WebSocket実装だと、ここだけで結構な工数が必要になります。
それに加えて、WebRTC の DataChannel を使えば、音声ストリームとは別の経路でツール呼び出しイベントやテキスト指示を流せるので、音声と制御信号を綺麗に分離できます。
realtime-voice-component は、
MediaStream: ブラウザのマイク音声を OpenAI に送る・OpenAI からの音声を再生するDataChannel: ツール呼び出し・session設定・割り込みイベントなどを送受信する
という綺麗な役割分担になっていて、これを自前で組み直す気にはならないくらいの完成度です。
tool定義の作法──gpt-realtime-1.5のvoice agentに「アプリ実体を呼ぶ薄いラッパー」を書く
設計思想と接続経路が分かったところで、いよいよツール定義の話に入ります。
ここは「ちょっと注目してほしい」ポイントが3つあるので、丁寧に解説します。
voiceAdapterパターンで状態をrefから読む
realtime-voice-component のツール定義は、defineVoiceTool という薄いヘルパーで書きます。
ポイントは、ツールは引数を受け取って state を変えるだけの関数で、state そのものを保持しない ということです。
最小サンプルはこんな感じです。
import { z } from "zod";
import { defineVoiceTool } from "realtime-voice-component";
// アプリのstateを操作するadapter(refから読み書き)
type Theme = "light" | "dark";
interface AppAdapter {
setTheme: (t: Theme) => void;
getScreenState: () => { theme: Theme; sidebarOpen: boolean };
}
export function buildVoiceTools(adapter: AppAdapter) {
const setTheme = defineVoiceTool({
name: "set_theme",
description: "Set the application theme to light or dark.",
parameters: z.object({
theme: z.enum(["light", "dark"]).describe("Target theme"),
}),
execute: async ({ theme }) => {
adapter.setTheme(theme);
return { ok: true, theme };
},
});
const getScreenState = defineVoiceTool({
name: "get_screen_state",
description: "Return the current UI state to the assistant.",
parameters: z.object({}),
execute: async () => adapter.getScreenState(),
});
return [setTheme, getScreenState];
}注目してほしいのが3つあります。
1つ目、adapter を引数で受け取っていることです。
ツール本体は state そのものに触らず、adapter 経由で操作する。
これにより、テストでは adapter をモックに差し替えて「set_theme が呼ばれたら setTheme が dark で呼ばれること」を単体テストできます。
2つ目、outputMode の話です。
get_screen_state のような「アシスタントに画面状態を教えるだけ」のツールを使うときは、セッション全体で outputMode: "tool-only" を設定しておくのが安全です。
これは ツール側ではなく、コントローラを生成する createVoiceControlController のオプションとして指定 します(後述のサンプル参照)。
tool-only を有効にしておくと、アシスタントは音声で長々と返事をせず「ツールを呼ぶ → 結果を内部で消化する」だけで動きます。
逆にこれを忘れると、AIが画面状態を声でくどくど読み上げるパターンに入りやすく、UXが壊れます。
地味だけど超大事なオプションなので忘れないでください。
3つ目、description と parameters の説明文です。
gpt-realtime-1.5 はツール呼び出しの信頼性が上がったとはいえ、description の質で精度がはっきり変わります。
「Set the theme」だけより「Set the application theme to light or dark.」のように、いつ呼ぶか・何を受け取るか を明示したほうが、誤呼び出しが減ります。
React Strict Modeとconfigure再実行の落とし穴
ここで失敗談を1つ。
僕がこのリポジトリの demo を React の Strict Mode 下で動かしてみたとき、最初コントローラが「死んでる」状態になって全然反応しなかったんですよ。
原因は、Strict Mode 下では useEffect が2回呼ばれて、最初の cleanup でコントローラが destroy される ためでした。
createVoiceControlController を useEffect の中で毎回作っていると、Strict Mode の二重実行で「作る → destroy → 作る」となるんですが、配線するイベントの順序を間違えていると2回目のcontrollerが正しく動かない。
realtime-voice-component 公式の最小構成はこういう書き方をしています。
import { useEffect, useMemo, useRef } from "react";
import {
createVoiceControlController,
VoiceControlWidget,
useVoiceControl,
} from "realtime-voice-component";
import "realtime-voice-component/styles.css";
import { buildVoiceTools } from "./tools";
export function VoicePanel() {
// adapterは1回だけ作る(refで安定させる)
const adapterRef = useRef({
setTheme: (t: "light" | "dark") => document.documentElement.setAttribute("data-theme", t),
getScreenState: () => ({
theme: (document.documentElement.getAttribute("data-theme") as "light" | "dark") ?? "light",
sidebarOpen: false,
}),
});
const tools = useMemo(() => buildVoiceTools(adapterRef.current), []);
const controller = useMemo(
() =>
createVoiceControlController({
activationMode: "vad",
auth: { sessionEndpoint: "/session" },
instructions:
"Use the provided tools to control the current screen. Prefer tools over free-form responses.",
outputMode: "tool-only",
tools,
}),
[tools],
);
useEffect(() => {
return () => controller.dispose();
}, [controller]);
// 接続状態やアクティビティを描画する必要がある場合のみ呼ぶ
const { connected, activity } = useVoiceControl(controller);
return (
<div>
<p>{connected ? `🎙 接続中(${activity})` : "切断"}</p>
<VoiceControlWidget controller={controller} snapToCorners />
</div>
);
}ポイントは、
adapterはuseRefで固定する(毎レンダー作り直さない)toolsはuseMemoで固定する(依存が変わらない限り作り直さない)controllerもuseMemoで固定して、cleanup 時にdisposeを呼ぶactivationMode: "vad"でユーザーの発話開始をブラウザ側で検知。auth.sessionEndpointで先ほどの/sessionを渡すoutputMode: "tool-only"で「アシスタントは音声で返事せず、ツール呼び出しに徹する」モードに。Chappyデモのような「画面が動くだけ」のUIに合うuseVoiceControl(controller)はconnectedやactivityを描画したいときだけ呼ぶ。VoiceControlWidget自体は内部でcontrollerに紐づくので、表示だけなら呼ばなくてもよい
この controller の所有権をどこに置くかを間違えると、Strict Mode 下で「生きていないコントローラ」をWidgetが参照して無音になることがあります。
特に複数画面で controller を共有したい場合は、Reactツリーの上位(プロバイダ)で生成して dispose も同じ層で呼ぶ、というルールを徹底してください。
それと、server_vad を使った割り込み挙動の話。
outputMode: "tool-only" セッションでは、ライブラリ既定で interruptResponse: false になっています。
これは「テキストやツール呼び出しが進行中の応答を、新しい発話で打ち切らない」という設定で、UIが音声を再生しないユースケースでは正しい挙動です。
逆に outputMode を変えてユーザーに音声を返す設計にする場合、audio.input.turnDetection 経由で interruptResponse: true を明示的に上書きしないと、AIの発話を割り込めません。
僕は最初、outputMode を切り替えたのにこの設定の存在を知らず、AIがずっとしゃべり続けて「あれ、止まらない」とハマりました。
既定値を変えたら、turnDetection の設定も合わせて見直すのが鉄則です。
似たフレームワークとの使い分け(pipecat / LiveKit / openai-agents-js)
「voice agent 系のフレームワーク、もう色々あるけど、結局どれを使えばいいの?」というのは、エンジニアからよく聞かれる質問です。
ざっくり整理するとこんな感じです。
realtime-voice-componentgpt-realtime-1.5の活用僕の結論としては、
- ブラウザのReactアプリに「音声で操作する」を後乗せしたい →
realtime-voice-component - サーバーサイドで黙々と動くAIエージェントが欲しい →
openai-agents-js - 電話・コールセンター・SIPトランクと組み合わせたい → Pipecat / LiveKit Agents
この使い分けが2026年4月時点のベース感覚です。
「どれを選ぶか」の起点は、「Web UIのstateを声で動かしたいか」という1点 だと思っています。
realtime-voice-component を選ぶ理由はここが出発点であるかどうかで決まります。
逆に「電話越しに長時間アシスタントしたい」「複数のSTT/TTSプロバイダを切り替えたい」みたいな要件があるなら、Pipecat / LiveKit Agents のほうが圧倒的に向いていますし、そもそも gpt-realtime-1.5 を選ばない選択肢も出てきます。
コスト・落とし穴・realtime-voice-componentは本番で使えるのか
設計と実装が分かったところで、最後に必ず気になるコストと現実的な落とし穴の話をします。
「で、実際のところ使えるの?」という問いへの正直な回答です。
音声トークンはテキストの約20倍。1分あたりいくらかかるか
gpt-realtime-1.5 の価格は、現時点でだいたいこんなレンジです。
- 音声入力: $32 / 1M tokens
- 音声出力: $64 / 1M tokens
これだけ見るとピンと来ないので、概算してみます。
OpenAI の公式ガイダンスでは、Realtime API の音声トークン消費レートは 入力で1トークン/100ms(=10トークン/秒)、出力で1トークン/50ms(=20トークン/秒) と明記されています。
5分(300秒)の会話で、ユーザーとAIが半々にしゃべると仮定すると、
- 入力(ユーザー音声): 150秒 × 10 tokens/秒 = 1,500 tokens
- 出力(AI音声): 150秒 × 20 tokens/秒 = 3,000 tokens
これを単価に当てはめると、
- 入力料金: 1,500 / 1,000,000 × $32 = 約 $0.048
- 出力料金: 3,000 / 1,000,000 × $64 = 約 $0.192
- 5分の会話 ≒ $0.24(およそ35円前後)
1分あたりだと約 $0.05(7〜8円)です。
安く見えますが、テキスト推論(gpt-4oで入力 $2.50 / M、出力 $10 / M)と比べると、音声入力は約13倍、音声出力は約6倍のトークン単価になります。
しかも音声は「無音区間にも課金される」ので、思っているより金額が膨らみやすい料金体系です。
「常時マイクON」みたいな使い方をすると、ユーザー1人当たり1日で数百円というレベルにすぐ届くので、料金設計と合わせて考えないとビジネスとして詰みます。
実装時には、
- 「ホットワード(Wake Word)で起動して、用件が終わったら切る」
- 「30秒〜1分の無音で自動切断する」
- 「セッションの上限時間を決めてリトライにする」
といったコスト制御を最初から組み込んでおくのが現実解です。
なお、ここで挙げた金額はあくまで概算なので、本番で使うときは必ずOpenAIのAPIプロバイダ公式の試算ツール(Pricing ページ・Tokenizerなど)で再確認してください。
「npm未公開のリファレンス実装」という現状をどう捉えるか
realtime-voice-component は2026年4月時点で npm 未公開 で、リポジトリを git clone して自分のプロジェクトに組み込む形になります。
ライセンスは Apache-2.0 なので商用利用も改変も問題ないんですが、
- npm でバージョン管理されないので、フォークして取り込む形になる
- 破壊的変更があったときに追従コストがかかる
- 公式が「リファレンス実装」と言っている通り、本番運用での保証はOpenAI側にない
このあたりを踏まえると、現時点でのスタンスは 「設計のお手本として読み込む」「コア部分はフォークしてプロジェクトに同梱する」 が現実的です。
「これを直接npmで入れて本番投入」みたいな使い方は、まだ早いですね。
ただ、今後 openai-agents-js 側に統合される可能性もあるので、コミット履歴を継続的にウォッチしておく価値はあります。
まとめ──いつrealtime-voice-componentを選ぶか
長くなったのでまとめます。
gpt-realtime-1.5 と realtime-voice-component の組み合わせが刺さる対象は、僕の感覚だと次のような条件です。
- React で作っているWebアプリがある
- そのアプリの内部stateを、声で操作できると体験が変わる
- 音声時間が短時間(数分単位)で、コストが許容範囲
/sessionエンドポイントを置けるバックエンドがある
逆に、これらが当てはまらないなら無理に飛びつかなくていい、というのも含めての結論です。
realtime-voice-component の本当の価値は、「コードのサンプル」より「設計の作法」を提示している ところにあると個人的には思っています。
- ツールはアプリへの薄いインターフェース
- stateはアプリ側で管理する
- ephemeral token / SDPプロキシで APIキーを守る
- WebRTC でブラウザ標準のオーディオ機能を活かす
outputMode: "tool-only"で読み上げを制御する
このあたりの作法は、自分で voice agent を組むときにも、別のフレームワークを選ぶときにも、共通して通用します。
最初の一歩として一番おすすめなのは、リポジトリの demo/ フォルダを git clone して、/session だけ自分の環境に立てて動かしてみること、です。
コードを読むのと、自分のアプリのstateが実際に声で動く瞬間を体験するのとでは、理解の深さが全然違います。
Chappy デモのように、声を出したら画面が変わる瞬間に、ぜひ自分の手で出会ってみてください。
「次のUIは、もしかしたらマウスじゃないかもしれない」と思える瞬間が、そこにあります。
ではまた次回。
もるふぉでした。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 3
- 0
-
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
AI脱社畜
- 2
- 0
-
- 2
- 0
-
- 2
- 0
-
- 1
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0


















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます