こんにちは。もるふぉです。
Claude Codeで開発をしていて、こんな経験はないでしょうか。
ある公式ドキュメントのURLを WebFetch で読ませて、「この記事の手順に従って実装して」と指示する。
返ってきたコードは、それっぽい。
でもなぜか、ドキュメントに書かれているはずのオプションが抜けていたり、似たような旧APIの書き方になっていたりする。
「LLMの気まぐれ?」と思いながら再実行すると、今度は正しい実装が返ってくる。
同じ指示なのに、結果が毎回微妙にズレる。
これ、LLMの問題じゃないんですよね。
ターミナルには「Received 204.4KB」と出ている。
ちゃんとページは取得できているはずなのに、なぜか核心の情報が落ちている。
この違和感の正体について、sherryさんがZennにとても良い記事を書いてくれていました。

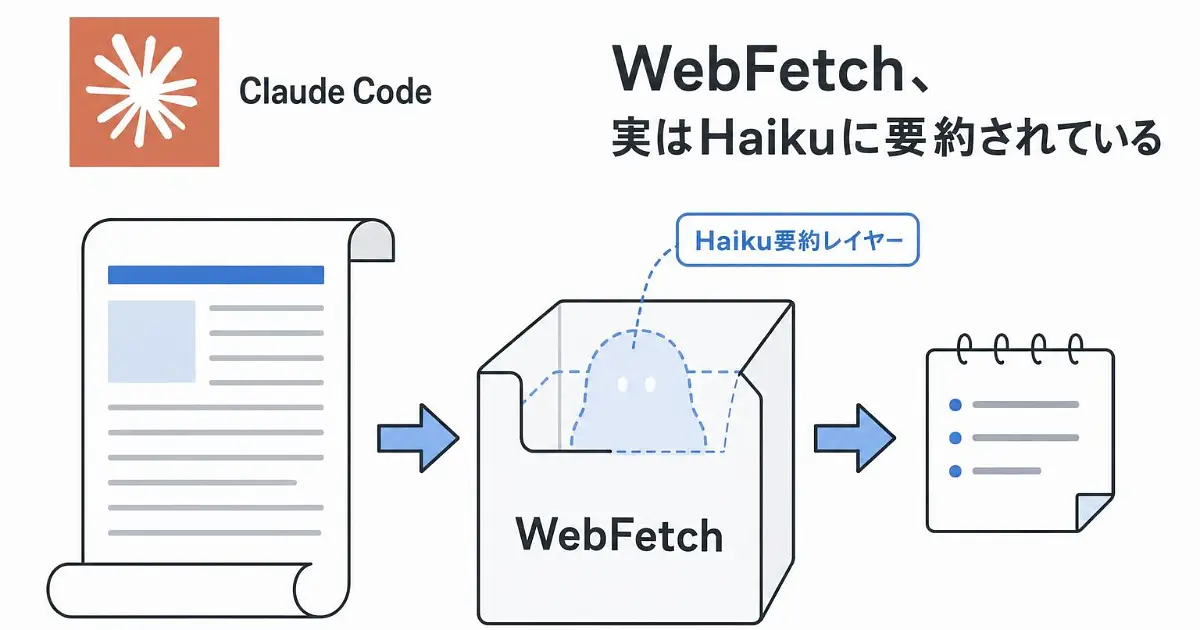
結論を先に言うと、WebFetch は内部でHaikuに要約させてから上位モデル(Sonnet/Opus)に渡しているケースがあるんですね。
sherryさんの記事は仕組みの解明として完璧なので、本記事では「実案件でどう設計を変えるか」のフェーズにフォーカスします。
実務でハマる場面と、CLAUDE.md で制御する設計パターンまで踏み込んで書きます。
検証時バージョンはClaude Code v2.1.126を前提としています。
Claude Code WebFetch の実態 — Haiku要約が入るとはどういうことか
まず仕組みの確認です。
ここはsherryさんの記事と前提を揃えるために、必要最小限で整理します。
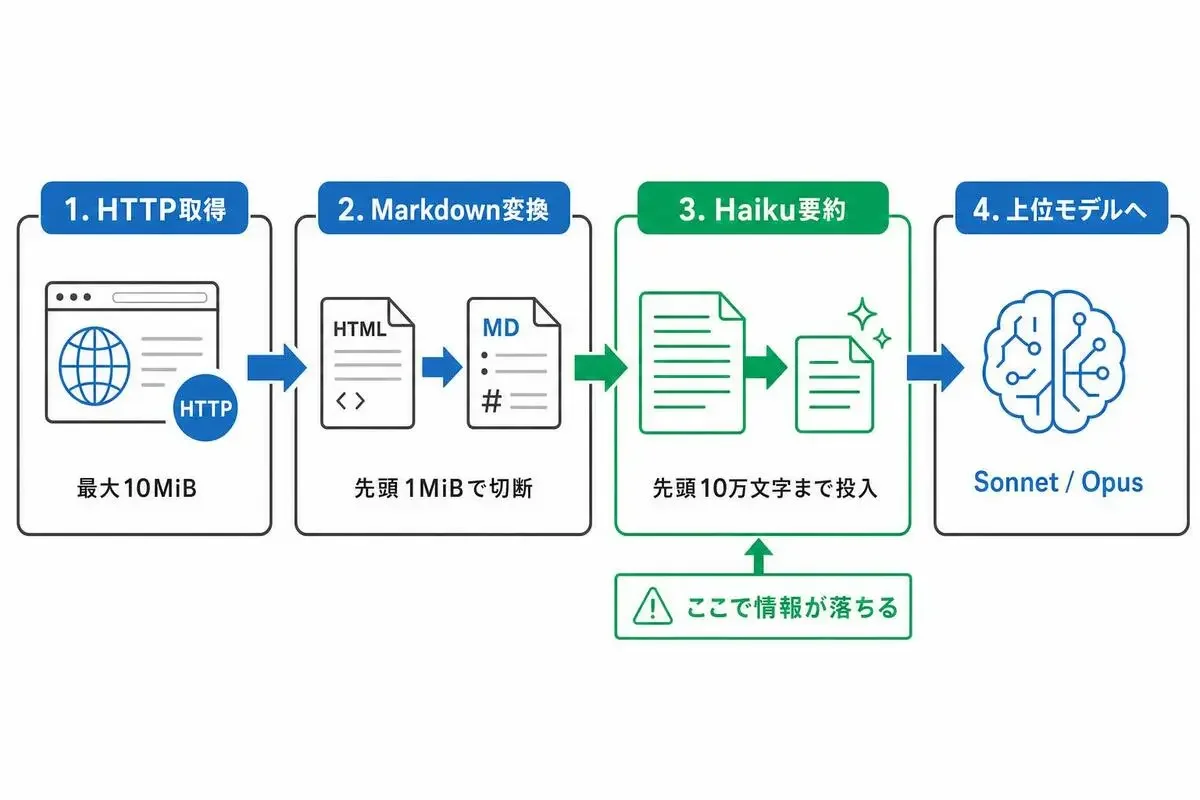
WebFetch ツールの内部処理は、ざっくりこんなパイプラインになっています。
- HTTPでページを取得(最大10MiB)
- HTMLをMarkdownに変換(先頭1MiBで切断)
- Haikuで要約(先頭10万文字まで投入)
- 上位モデル(Sonnet/Opus)には要約結果が渡る
つまり、ユーザーから見えているのは「ページを取った」という事実だけで、上位モデルが見ているのは「Haikuが書いた数百文字〜数千文字の要約」だったりする、ということなんですよ。
料理に例えるなら、「素材から料理してね」と頼んだのに、間に挟まったアルバイトが「えーと、トマトとタマネギ入ってます」とメモだけ渡してくるイメージです。
メインシェフ(Opus/Sonnet)はそのメモだけを頼りに料理を作る。
そりゃ味がブレるよね、という話です。
そして、この要約処理をバイパスする条件が3つあります。
この3つをすべて同時に満たした場合だけ、Markdown化された原文相当のテキストがそのまま上位モデルに渡ります。
Content-Type が text/markdownここで大事なのは、この3つは「AND」だということです。
3つを同時に満たした場合だけ、Haiku要約が入りません。
逆に言えば、1つでも欠けると、上位モデルが見ているのは要約だけ、ということになります。
ここを知らないまま WebFetch を使い続けると、設計のレベルで穴が開きます。
次で「どんな穴が開くか」を具体的に見ていきますが、その前にverboseログで自分の環境を確認する方法を押さえておきましょう。
verboseログで実際に何が渡っているか確認する
「自分が見ている結果は要約なのか原文なのか」を判定するには、/config でverboseモードを有効にするのが一番早いです。
Claude Codeを起動した状態で /config を打つと、設定タブが開きます。
ここでverbose modeをonにしておくと、WebFetch 実行時にHaiku要約が走ったかどうかがログに出るようになります。
CLI起動時に --verbose フラグを付けても同じ効果です。
claude --verboseverboseで出てくるログを眺めていると、たとえば「ある公式ドキュメントは要約されない(信頼ドメインなので素通し)」「あるブログ記事は要約される」みたいな差がはっきり見えてきます。
私の感覚で言うと、これは1回でいいから自分のチームで /config を開く時間を作るべきです。
「Claude Codeが何を見ているか」を1度も自分の目で確認したことがない状態でCLAUDE.mdを書いても、それはただの願望リストになりがちなんですよね。
verboseログを1時間眺めるだけで、自分が頭の中に持っていた WebFetch の挙動モデルが結構ズレていることに気づきます。
バイパスされる3条件と、実務で使えるドメインリスト
信頼ドメインとして登録されているのは、エンジニアがよく参照する公式系のドメインがメインです。
実務でよく出てくる代表例を挙げると、こんな感じです。
sherryさんの記事に名前が挙がっているもの+信頼リストとして他の検証記事で確認できるものをまとめました。完全なリストは公開されておらず、80件強のうち代表例として参照してください。
docs.python.orgdeveloper.mozilla.orgreact.devkubernetes.iodocs.aws.amazon.comcloud.google.comlearn.microsoft.comnodejs.orggo.dev / pkg.go.devdoc.rust-lang.orgここに載っているドメインは、ほかの2条件(Content-Type: text/markdown と10万文字以下)が揃ったときにバイパスが効きやすい立場にあります。
ただ、HTMLで返してくるドキュメントも多いので、信頼ドメインだから無条件にOKというわけではないんですよね。
verboseで実際に要約が入っていないか確認しておくのが安全です。
問題は、信頼ドメインリストに載っていないところを引いたときです。
たとえば企業の技術ブログ、Qiitaやnoteの個別記事、ニッチなOSSの公式サイトなど。
ここは要約バリバリ入ります。
実務での運用としては、自分がよく参照するドメインがリストに入っているかどうかを把握しておくと、WebFetch の挙動が予測可能になります。
「このドメインは信頼ドメインだから原文取れる、こっちのドメインは要約されるから対策が要る」という二分法で頭を整理しておくのが現実的です。
「Received 204.4KB」表示と実際の情報量のギャップ
ここが一番見落とされがちなポイントです。
WebFetch 実行時にコンソールに表示される「Received 204.4KB」みたいなサイズは、HTTPで取得した生データのサイズなんですよ。
これは「Claude Codeのプロセスがそのバイト数を受け取った」という事実でしかなく、「上位モデルにそのバイト数の情報が届いた」という意味ではありません。
200KB取得したけれど、最終的にOpusに届いたのは「800文字の要約」、というのが普通に起こります。
厄介なのは、この表示が「ちゃんと取れた」という安心感を生むことです。
「Received 204.4KB」を見ると、人間は反射的に「ページは読めた」と思ってしまう。
でも実際は、Haikuの解釈フィルターが間に1段入っていて、上位モデルは要約しか見ていない。
この「人間が見ている表示」と「上位モデルが見ている入力」のギャップが、次で話す「再現性のないバグ」の温床になります。
正直、これは知っておかないとまずいやつです。
WebFetch 依存で壊れやすい設計パターン
ここからが本題です。
「Haiku要約が入る」という事実を知った後、自分の設計のどこが壊れやすくなるのか。
WebFetch 依存で壊れやすい設計パターンは大きく3つに分類できます。
Haikuの要約が「再現性のないバグ」を生む場面
最初にして最大の問題は、これです。
Haikuの要約は、temperature の設定や入力の細かな違いによって、実行のたびに微妙に異なるテキストが返ることがあります。
LLMの出力には統計的なゆらぎがあるので、同じURLを WebFetch した結果でも、含まれる情報の精粗が揺れるんですよ。
「再現しないバグ」ほど厄介なものはありません。
これが地味に怖いんですよ。
たとえばこういう場面が起きやすいです。
仕様書のURLを WebFetch させて、「この仕様の通りにバリデーションを実装して」と指示するタスクを考えてみます。
Haikuの要約処理では、たとえば「最大値の単位がkで省略可能」のような注釈をうまく拾えないケースがあります。
その結果、1回目の実行では「最小値0、最大値1000」とちゃんと実装される。
同じ指示でも、要約のゆらぎ次第で「最小値0、最大値100」のような実装になることがある。
ベテランほど、この種の「微妙にズレた挙動」を再現させる工数を読んでバジェットに乗せてきたはずなんですよ。
でも、AI駆動開発における「微妙なズレ」は、人間の見落としではなく WebFetch という具体的な構造的バグから来ているケースがある。
これに気づかないと、「またLLMの気まぐれかな」で済ませて深掘りしないままになります。
ここが落とし穴です。
「LLMがよくわからない動きをする」と感じたとき、まず疑うべきは上位モデルの知能ではなく、その上位モデルに何が入力されているか、なんですよね。
ドキュメント参照タスクでの失敗パターン
もう1つよく出るのが、ドキュメント参照タスクでの失敗です。
具体的には、こういうパターンが頻発します。
ロングなREADMEを WebFetch で読ませる場面。
10万文字を超えると、Markdown化後に切断されます。
ライブラリのREADMEで、「インストール手順」「基本的な使い方」「APIリファレンス」「FAQ」「移行ガイド」と続く構成だと、後半の移行ガイドあたりは入力に届かないことがあります。
「この移行ガイドの通りに、v1からv2にアップグレードして」と指示すると、Claude Codeは「移行ガイドの該当箇所」を読めていないまま作業を始めて、それっぽいけど誤った変更を加えるみたいなことになる。
新旧バージョンが混在しているドキュメントの参照。
公式ドキュメントが新旧両バージョンの記述を含んでいると、Haikuの要約は「両方の特徴を平均化した」みたいなテキストを返すことがあります。
「v3の使い方を教えて」と頼んだのに、要約のなかでv2の書き方が混ざってきて、結果として動かないコードを生成する、というやつですね。
サンプルコードがコメントアウトされた古いドキュメント。
Haikuはコメントアウト記号を厳密にトークン単位で保持しないことがあるので、「コメントアウトされていた古いコード例」が、要約の中で生きているコードのように扱われることがあります。
これらは全部、上位モデル(Opus/Sonnet)の知能の問題ではなく、入力段階で情報が変質しているという「ツール特性の問題」です。
エンジニアの仕事は、この種の問題を「LLMの限界」ではなく「ツールの設計上の特性」として切り分けることなんですよね。
なぜ「テスト駆動AI開発」の視点が必要になるか
ここでテスト駆動AI開発の話に繋がります。
自分は普段、Claude Codeに実装を任せるときは、必ずテストを先に書かせます。
「機能Xを実装して、その後テストも書いて」ではなく、「テストを先に書いて、それが通る実装を書いて」の順です。
これは設計の信念というより、WebFetch のような不確定要素のあるツールを使う場合の防衛策として効くんですよ。
テストが先にあれば、要約のゆらぎで実装が微妙にズレても、テストが落ちることでズレが顕在化します。
逆に、テストなしで「ドキュメントを読んで実装して」だけを任せると、ゆらぎが生んだ微妙なズレが何回もリリースされて、「バグなのか仕様変更なのかも分からない」状態が積み上がっていきます。
経験則的にもテスト駆動でやらないとAIは普通に暴走します。
要約のゆらぎとテストのなさが組み合わさったときに、コードベースが何のテストにも守られないまま「微妙にズレた仕様」を取り込み続けることになる。
これは、感覚で言うと、結構ホラーです。
WebFetch 依存のタスクほど、テストの網が要る、というのが自分の結論です。
では「壊れやすい設計を知った上で、具体的に何をするか」——次が実践編です。
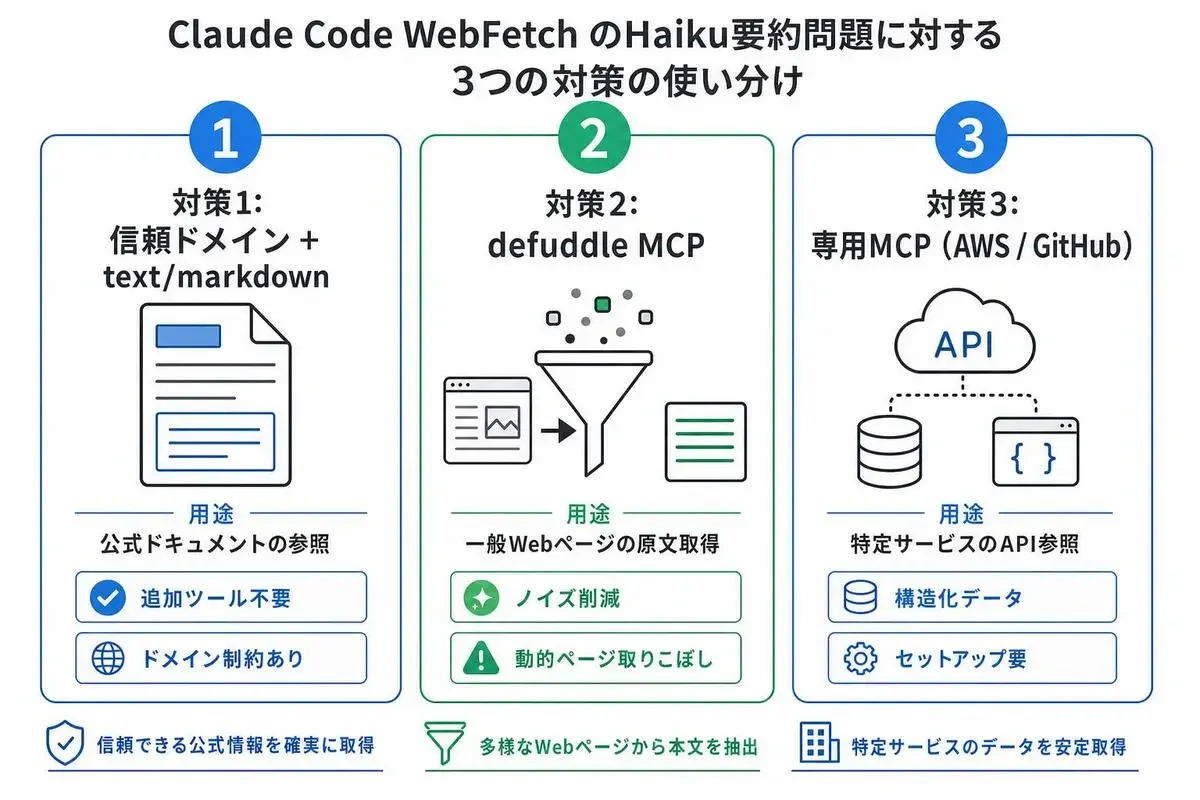
原文取得のための3つの対策 — WebFetch を使い続けるか、替えるか
ここまでで「WebFetch には構造的な制約がある」という前提を共有しました。
次に「では何をするか」の話に入ります。
対策は大きく3つに分けられます。
それぞれメリット・デメリットがあるので、案件の性質に応じて使い分けるのが現実的です。
対策1: 信頼ドメイン + text/markdown を活用する
一番手軽なのが、WebFetch を「Haikuバイパスが効く形で使う」という方針です。
具体的には2つのアプローチがあります。
1つ目は、信頼ドメインに含まれているURLだけを WebFetch させること。
公式ドキュメントが信頼ドメインに入っているなら、URLを直接渡すのが一番安心です。
2つ目は、自分でホストしているドキュメントを Content-Type: text/markdown で配信すること。
社内ドキュメントをConfluenceで管理している場合は厳しいですが、たとえばGitHub PagesやS3で .md ファイルを直接配信するパターンであれば、Content-Typeを text/markdown に設定するだけでバイパスが効きます。
メリットとしては、追加のツール導入なしで原文がそのまま渡せること。
デメリットは、対象ドメインに制約があることと、Content-Type を制御できないサイトでは使えないことです。
実務では、この対策1で対応できる範囲を最初にきっちり仕分けるのが大事です。
「公式ドキュメントは対策1で素通し、それ以外は対策2か3」という二段構えにすると、判断がシンプルになります。
これ、CLAUDE.md に5行足すだけで運用できます。
対策2: defuddle MCP で原文をそのまま渡す
信頼ドメインに入っていないサイトの原文を取得したい場合、defuddle を経由させるのが定石です。
defuddleは、Webページのメインコンテンツを抽出してMarkdown化するツールです。
サイドバーや広告、フッター、コメント欄などのノイズを削ってくれるので、純粋な記事本文だけを取り出せます。
これをMCP化して使う、というのが対策2です。
defuddleが返すのはMarkdown形式のクリーンなテキストなので、上位モデルに渡したときに「ノイズが少ない原文」として扱われます。
ここでポイントなのが、defuddle MCP経由で取得したテキストは、WebFetch のHaiku要約パスを通らないということです。
MCP経由なので、Claude Codeから見れば「Toolが返したテキスト」であり、HTML→Markdown変換のパイプラインに入りません。
メリット: 信頼ドメイン外のサイトの原文がそのまま使える。
デメリット: defuddleの抽出が完璧ではないサイトもある。極端に複雑な構造のページや、JavaScriptで描画される動的コンテンツの一部は取りこぼしがある。
実案件では、定型的に参照するドキュメントが信頼ドメイン外にある場合、対策2を仕込んでおくのが効きます。
たとえば自社の技術ブログをClaude Codeに参照させたい場合、WebFetch だと要約されてしまうので、defuddle MCPに乗せ替える、というのは普通にあります。
設定自体は30分もあれば完了するので、「信頼ドメイン外のサイトを頻繁に参照する」プロジェクトなら最初に入れておくのが得策です。
対策3: AWS MCP / GitHub MCP を使い分ける
特定ドメインのドキュメントが頻繁に必要な場合、その分野の専用MCPを使うのが筋がいいです。
AWSの場合、awslabs/mcpが公式のMCPサーバー集を出していて、Documentation MCP Server / API MCP Server / Knowledge MCP Serverといったサーバーが用意されています。
GitHubの場合も、公式が github-mcp-server を出しています。
専用MCPの何が嬉しいかというと、APIレベルで検索・取得ができることです。
WebFetch でAWSのドキュメントを開いて要約される、というルートではなく、ドキュメントAPIに対して「このサービスのこのオプションについて教えて」とクエリを投げられる。
返ってくるのは構造化されたAPIレスポンスなので、Haiku要約は介在しません。
GitHub MCPも同じで、Issue、PR、コードを直接APIで取りに行けるので、WebFetch でissueページを開いて要約される、みたいな経路を回避できます。
メリット: APIレベルで構造化された情報が取れる。検索・取得の精度が高い。
デメリット: セットアップが必要。MCPサーバーごとに認証やトークン管理が増える。
使い分けの指針としては、こんな感じで整理しておくと運用しやすいです。
WebFetch 直接.md ドキュメントtext/markdown 配信万能な選択肢はないので、案件ごとにこの表を見て決めるのがおすすめです。
この3つの対策を CLAUDE.md に明文化しておくのが次のステップです。
CLAUDE.md でWebFetch依存を明示的に制御する設計パターン
CLAUDE.md を使って「WebFetch に何を期待してよいか・いけないか」を明文化する話をします。
CLAUDE.md はClaude Codeに対するプロジェクト固有の指示書ですが、これを「ツール依存の制御」の観点で書くと、要約問題に対する強力な防衛線になります。
どのタスクにWebFetchを使ってよいか・使ってはいけないか
まず、WebFetch に対するメンタルモデルを CLAUDE.md で明文化します。
「WebFetch は信頼ドメイン以外では要約が入る可能性がある。だからこういうタスクでは使うな、こういうタスクでは使ってよい」というルールを書く。
ここを言語化しないままClaude Codeに作業を任せると、WebFetch の特性を考慮しないツール選択をされて、結果としてバグを引き込むことになります。
具体的なルールの粒度としては、こんな感じです。
- 信頼ドメインのドキュメントなら
WebFetch直接でOK - それ以外のドキュメント参照は対策2か3を優先
- ロングなドキュメントを読ませる前は、目次から該当セクションを特定する
- 仕様書の参照には必ず元URLを
verboseで確認した上で実装する
このルールが CLAUDE.md にあるかないかで、Claude Codeが取る行動がかなり変わります。
CLAUDE.md設定の実例(コピペ用)
実際に自分が使っている CLAUDE.md 設定の抜粋を貼ります。
そのままコピペして使えるレベルにしてあるので、自分のプロジェクトに合わせて調整してください。
## URL読み取り・WebFetchの取り扱いルール
`WebFetch` は内部でHaiku要約が走るケースがあり、信頼ドメイン外のページでは
原文が上位モデルに届かないことがある。これを前提にツールを選択する。
### WebFetchで直接読んでよい場合(下記3条件をすべて同時に満たすとき)
1. ドメインが以下のいずれかに該当する(信頼ドメイン例)
- `docs.python.org` / `developer.mozilla.org` / `react.dev`
- `docs.aws.amazon.com` / `cloud.google.com` / `learn.microsoft.com`
- `nodejs.org` / `kubernetes.io` / `go.dev` / `pkg.go.dev` / `doc.rust-lang.org`
2. レスポンスの `Content-Type` が `text/markdown`
3. Markdown化後のサイズが10万文字以下と推定できる
※ 3条件のうち1つでも欠ければ、信頼ドメインであってもHaiku要約が入る。
### WebFetchで直接読んではいけない場合
- 上記の信頼ドメインに該当しない一般Webページ
- ブログ・技術記事サイト(要約による意図ズレが起きやすいため)
- ロングなREADME(10万文字超で末尾切断のリスクがある)
### 代替ツールの選択
- 一般Webページ → defuddle MCP を使う
- AWSドキュメント → AWS Documentation MCP Server を使う
- GitHub Issue / PR / コード → GitHub MCP を使う
### 検証ルール
- `WebFetch` を使ったタスクで挙動が怪しい場合、必ず `/config` のverbose modeで
Haiku要約が走ったか確認すること
- 仕様書ベースの実装は、テストを先に書いてから実装する
- 実装後、verboseログを根拠に「要約が入っていないこと」を確認するこれを CLAUDE.md に貼っておくと、Claude Code自身が「このタスクでは WebFetch を直接使うべきか、defuddle MCPに切り替えるべきか」を判断するときの指針として参照してくれます。
ここで大事なのは、ルールを書くときに「条件」と「代替手段」をセットで書くことです。
「WebFetch を使うな」だけだと、Claude Codeは別の不適切なツールに走ることがある。
「使うな、その代わりこれを使え」までセットで書いておくのが、md制御の基本です。
Verboseログを読む習慣をチームに定着させる方法
CLAUDE.md のルールを書いただけでは、人間側の運用が追いつかないことがあります。
特にチーム開発でClaude Codeを使っている場合、「verboseログを読む文化」がないと、いつの間にか要約された結果に頼った実装が混入していきます。
定着させるための実務的なテクニックを3つ挙げます。
1つ目は、PRレビューで「このタスクは WebFetch 使ってる? verboseで確認した?」を聞く文化にすることです。
最初の数回は鬱陶しいかもしれませんが、3週間もすれば全員の標準動作になります。
2つ目は、ふりかえりにチェックポイントとして入れることです。
「今週の WebFetch 経由のタスクでverbose確認したか」をスプリントレビューの軽いチェック項目に入れる。
これで「やってない」が可視化されるので、自然と確認するようになります。
3つ目は、CLAUDE.md の中に「verbose確認をしていないPRはマージしない」のような運用ルールを書き込んでおくことです。
ルールが CLAUDE.md にあると、Claude Code自身がPR説明文に「verbose確認: ◯◯」のような項目を入れるようになります。
これは結果的に、人間のレビュアーにも「verbose確認した?」を意識させる効果がある。
地味ですが、こういう仕組みづくりがツール信頼性のベースラインを作ります。
まとめ — WebFetch の特性を前提にした「ツール信頼性設計」
ここまでの話を「ツール信頼性設計」という言葉で一旦まとめます。
「ツール信頼性設計」——これが、今回伝えたかった一番の概念です。
Claude Code WebFetch のHaiku要約問題が示しているのは「Claude Codeの各ツールが内部で何をしているかを知らないと、設計のレベルで穴が開く」という事実です。
これは WebFetch だけの話ではなくて、Bash、Grep、Read、Edit、それぞれのツールに固有の制約や挙動があります。
WebFetch の問題に気づいたなら、次は「自分が依存している他のツールも同じ視点で見直す」というアクションに繋げるべきです。
たとえば、Read ツールの読み込み上限はどこにあるか。
Grep のデフォルトのhead_limitは何件か。
それを超えた場合、Claude Codeはどう振る舞うか。
これらは全部、WebFetch のHaiku要約と同じ「人間が見ている結果と、上位モデルが見ている入力のギャップ」を生む可能性のある場所です。
ツール信頼性設計の本質は、こういう「ツール固有の制約」を前提にして、設計とCLAUDE.mdを書くことです。
万能な道具は存在しない、という前提を持って、ツールごとに使い方の作法を決めていく。
これがAI駆動開発における設計の中核だと自分は思っています。
最後に、明日からできる最初の一歩を3つだけ挙げます。
1つ目は、Claude Codeで /config を開いて、verbose modeを有効にすることです。
これは1分でできます。
その上で、自分が普段やっているタスクを1つ動かして、verboseログを眺めてみる。
「自分が WebFetch で読んでいると思っていたページが、実は要約されていた」みたいな発見が必ず1個は出てきます。
2つ目は、本記事の CLAUDE.md 設定例を自分のプロジェクトに貼ることです。
5行から30行追加するだけで、Claude Codeのツール選択がかなり変わります。
3つ目は、WebFetch 以外のツール(Bash、Grep、Read、Edit)について「このツールが返しているのは、本当に上位モデルが見ている内容と一致しているか」を一度疑ってみることです。
ツール信頼性設計は、WebFetch から始まりますが、ここで終わるものではない、ということなんですよね。
この3つ、どれも今日中にできます。
sherryさんの記事のおかげで、WebFetch の内部実態が一気に可視化されました。
ここから先、実案件でどう設計に反映させるかは、エンジニアそれぞれの腕の見せどころだと思います。
自分も引き続き実案件のなかで CLAUDE.md のテンプレを磨いていきます。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます