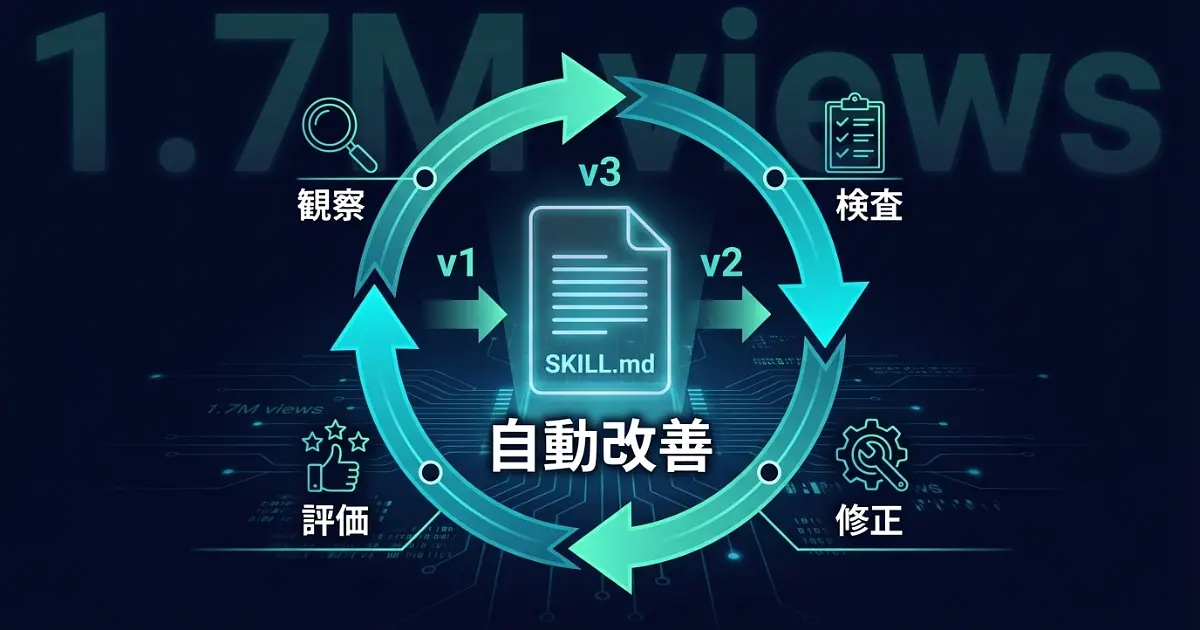
SKILL.md自動改善ブームの背景
SKILL.mdを一度書いて、そのまま放置していませんか?
正直なところ、これ、かなり多くの人がハマっているパターンだと思います。
スキルファイルを丁寧に書いたときは「これで完璧だ!」って思えるんですよね。
でも1週間、2週間と経つうちに、なんとなく出力の精度が落ちてくる。
どこが悪いのかもわからない。
直そうにも、どこから手をつければいいのか見当がつかない。
この「静的なスキルファイル問題」に正面から切り込んだ投稿が、2026年3月に爆発的にバズりました。
この記事では、SKILL.mdを「生きたコンポーネント」に変える自動改善ループの仕組みと、今日から試せる具体的なステップを紹介します。
Vasilije (@tricalt) の投稿が示したもの
2026年3月13日、Vasilije(@tricalt)がXに投稿した「Self improving skills for agents」が爆発的に拡散しました。
79件の返信、450リポスト、3,483いいね、11,443ブックマーク、そして170万回を超える表示数(2026年3月13日時点)。
AIエージェント界隈でここまでの反響は、正直かなり異例です。
彼の主張はシンプルでした。
"not just agents with skills, but agents with skills that can improve over time" (スキルを持つエージェントではなく、スキルが時間とともに改善するエージェントを)
つまり、スキルが自分で自分を改善する。
この一文に「それだ!」と膝を打った人が、170万人分いたということですね。
従来のスキル運用は、次の3ステップで完結していました。
- プロンプトを書く
- フォルダに保存する
- 必要なときに呼び出す
「デモでは動くけど、実運用では壁にぶつかる」——これがVasilijeの問題提起です。
なぜ今、スキルの「自動改善」が注目されているのか
背景にあるのは、AIエージェントの利用が「お試し」から「業務の中核」へ移行しつつあるという現実です。
スキルを本番運用すると、こんな問題が起きます。
どれか一つは身に覚えがありませんか?
- 特定のスキルが選ばれすぎる——汎用的なスキルが優先され、専門スキルが埋もれる
- 見た目は成功しているが、実際は失敗している——出力フォーマットが崩れている、条件分岐が効いていないなど
- 環境変更でツール呼び出しが壊れる——APIのバージョンアップ、外部サービスの仕様変更に追従できない
- 個別の指示が機能しなくなる——コンテキストが増えるにつれて、初期に書いた指示の優先度が下がる
特に厄介なのは2つ目です。
一見うまく動いているように見えるから、問題に気づくのが遅れるんですよね。
気づいたときには、いつから壊れていたのかすら追えなくなっている。
Vasilijeはこれを「Skills are usually static, while the environment around them is not!」と表現しました。
スキルは静的なのに、周囲の環境は動き続けている。
このギャップが、自動改善ループへの関心を一気に高めました。
では、具体的にどんなアプローチがあるのか。
次のセクションで、SKILL.mdの基本から振り返っていきましょう。
SKILL.mdとは何か——静的プロンプトの限界
SKILL.mdの基本構造
SKILL.mdとは、AIエージェントに特定のタスクを実行させるための「指示書ファイル」です。
Claude CodeやCursorなどのAIコーディングエージェントで広く使われています。
基本的な構造は次のようになります。
# SNS投稿の下書き作成
## 概要
与えられたテーマからX(Twitter)向けの投稿文を作成する。
## 手順
1. テーマのキーワードを抽出する
2. ターゲット読者の関心ポイントを特定する
3. 140文字以内で要点を伝える文章を作成する
4. ハッシュタグを3つ付与する
## 制約条件
- 絵文字は最大2個まで
- URLは短縮リンクを使用
- 投稿時間帯に応じてトーンを調整するシンプルなMarkdownファイルです。
これをプロジェクトの.claude/skills/ディレクトリに置けば、エージェントが自動的に読み込んで実行してくれます。
静的ファイルの3つの問題点
この仕組み、直感的で分かりやすいんですよね。
でも、運用を続けると3つの壁にぶつかります。
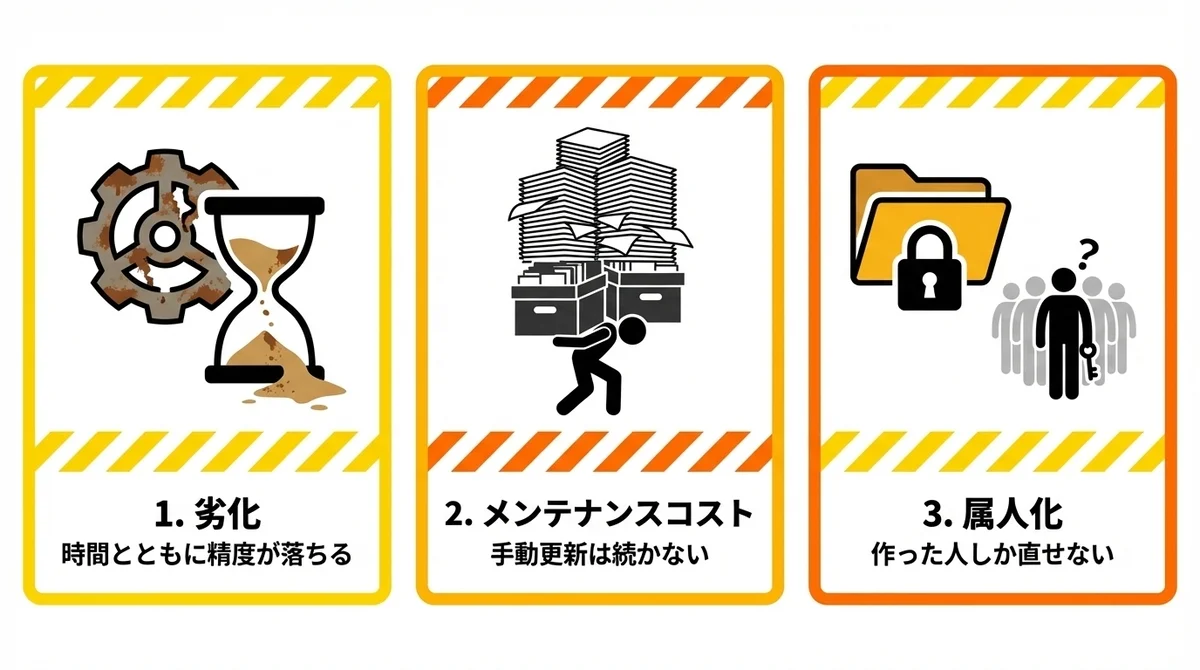
1. 劣化——時間とともにスキルの精度が落ちる
作成時点では完璧だったスキルでも、外部環境の変化で精度が落ちていきます。
「X向けの投稿を作成する」というスキルは、アルゴリズム変更やトレンドの移り変わりによって、数週間で効果が薄れることがあります。
ソフトウェアエンジニアなら馴染みのある感覚ではないでしょうか。
依存ライブラリが更新されて、気づいたらテストが落ちている——あれと同じことがスキルにも起きるんです。
2. メンテナンスコスト——手動更新は続かない
スキルが10個、20個と増えると、どのスキルが劣化しているかを人間が把握するのはかなり困難です。
「先月作ったあのスキル、最近なんか微妙だな」と感じても、原因の特定と修正には時間がかかります。
そして正直なところ、この手の地味なメンテナンスって後回しになりがちですよね。
緊急性がないから、ずるずると放置してしまう。
3. 属人化——作った人しかメンテできない
スキルの設計意図やチューニングの経緯がドキュメント化されていないと、作成者以外がメンテナンスできません。
チームでの運用では深刻なボトルネックになります。
これらの問題に対して、業界では3つのアプローチが提案されています。
3つの「スキル自動改善」アプローチを比較する
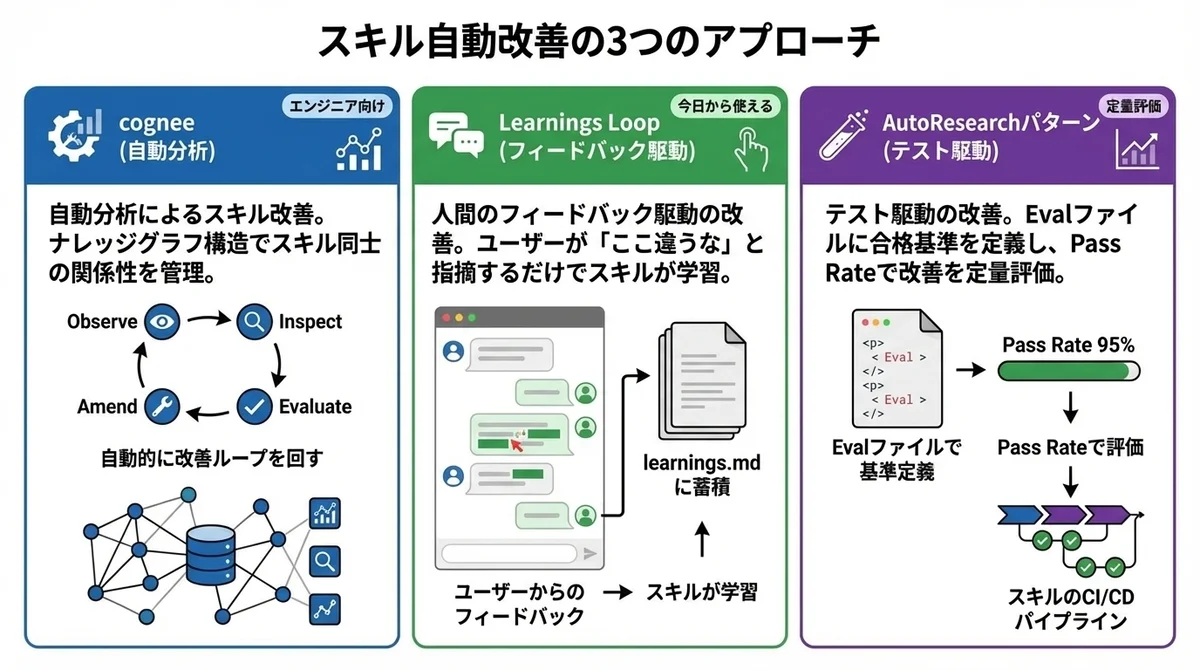
2026年3月時点で注目されている自動改善の仕組みを、3つ紹介します。
それぞれアプローチが異なるので、用途に応じて選べるのが嬉しいポイントです。
cognee のスキル自動改善機能(Observe→Inspect→Amend→Evaluate ループ)
Vasilijeの投稿で紹介されたのが、cognee(Pythonライブラリ。
スキル自動改善機能はコミュニティで「cognee-skills」とも呼ばれます)による自動改善ループです。
これが何が面白いかというと、スキルをナレッジグラフ構造で管理する点にあります。
単なるテキストファイルではなく、スキル同士の関係性やセマンティックな意味づけを持たせるんです。
これにより、「どのスキルが、どの文脈で、どう使われたか」を構造的に追跡できます。
いわばスキルの依存関係をグラフDBで管理するようなものです。
コードの依存関係をパッケージマネージャが管理するように、スキルの関係性をナレッジグラフが管理する——こう考えると、エンジニアの方にはイメージしやすいのではないでしょうか。
改善ループは4ステップで回ります。
- Observe(観察)——スキルの実行結果を記録します。
何を試みたか、どのスキルが選ばれたか、成功/失敗、エラー内容、ユーザーフィードバックをすべて蓄積 2. Inspect(検査)——蓄積された失敗データからパターンを分析します。
「このスキルは特定の条件下で繰り返し失敗している」といった知見を抽出
3. Amend(修正)——.amendify()メソッドでエビデンスに基づいた修正案を生成します。
トリガー条件の調整、ステップの並べ替え、出力形式の変更など 4. Evaluate(評価)——修正版を検証し、改善が確認できたら新バージョンに昇格させます。
問題があればロールバック可能
Vasilijeが強調したのは、最後のEvaluateステップの重要性です。
「信頼できるのは検証を経た改善のみ」——無検証で自動修正を反映するのは危険だという立場ですね。
Claude Code の Learnings Loop(フィードバック駆動の改善パターン)
Claude Codeのスキル・メモリシステムを活用した「Learnings Loop」は、実践者の間で広まっているフィードバック駆動の改善パターンです(Anthropicの公式機能名ではなく、MindStudioのブログなどコミュニティで提唱されているベストプラクティス)。
仕組みは5ステップで構成されます。
- スキル実行——エージェントがSKILL.mdに基づいてタスクを実行する
- フィードバック提供——ユーザーが「日付はYYYY-MM-DD形式にして」「見出しレベルはH2から始めて」など具体的な指摘を行う
- 指示書更新——エージェントがフィードバックを受けてSKILL.mdやlearnings.mdを書き換える
- 即座に反映——次回のスキル実行から、更新された指示が適用される
- 累積改善——フィードバックが蓄積され、スキルが段階的に精度を上げていく
ここが面白いところなんですが、cogneeとの大きな違いは人間のフィードバックを起点とする点です。
自動分析ではなく、ユーザーの具体的な指摘がトリガーになります。
つまり、普段の作業で「ここ違うな」と思ったことを伝えるだけで、スキルが勝手に賢くなっていくんです。
特別なセットアップは不要で、日常のワークフローの延長線上で改善が回る。
これがあるだけで、スキル運用の体験が激変します。
効果的なフィードバックのポイントは3つあります。
- 具体的に指摘する——「もっと良くして」ではなく「日付はYYYY-MM-DD形式で統一して」
- 条件を明示する——「技術記事の場合はコードブロックを必ず含める」
- 優先度を伝える——「フォーマットより内容の正確性を優先して」
この仕組みは、文脈内学習(セッション終了で消える)やファインチューニング(モデル再学習が必要)とは根本的に異なります。
ユーザーのフィードバックを受けてスキルの指示書が更新されると、次のセッションにも改善が引き継がれるんです。
AutoResearch パターン——eval基準でエージェントに改善させる
Andrej KarpathyのAutoResearchは、本来はML実験を自動化するツールです(「AI agents running research on single-GPU nanochat training automatically」)。
しかしコミュニティがこのeval駆動のアプローチをスキル改善に応用し、テスト駆動の改善パターンとして広まっています。
エンジニアの方なら、このアプローチは直感的に理解しやすいはずです。
要するに「スキルにもテストを書こう」ということですから。
中核にあるのは3つのコンポーネントです。
- Evalファイル——スキルの合格基準を定義するテストケース
- Pass Rate追跡——現在の合格率を数値で管理する
- 改善ループ——不合格のケースを分析し、スキルを自動修正する
ループの流れはこうなります。
Eval実行 → 合格率計算 → 失敗分析 → プロンプト候補生成 → 再テスト → 最良候補を選択いわばスキルのCI/CDパイプラインのようなものです。
コードにテストを書いてCIで回すように、スキルにもEvalを書いてPass Rateで回す。
Red→Green→Refactorのサイクルが、スキル改善にもそのまま適用されるわけですね。
このパターンをスキル改善に応用する場合、Evalファイルは次のような形式が考えられます(AutoResearch本体のevalは単一の数値メトリクスであり、以下はコミュニティでの応用例)。
{
"test_cases": [
{
"input": "ReactのuseEffectについて解説して",
"expected_behavior": "クリーンアップ関数の説明を含む",
"pass_criteria": "useEffectの第2引数(依存配列)に言及している"
},
{
"input": "Python の型ヒントについて教えて",
"expected_behavior": "typing モジュールの具体例を含む",
"pass_criteria": "Union, Optional, List のいずれかが登場する"
}
]
}このパターンの強みは、改善を定量的に評価できる点です。
「合格率が70%から85%に上がった」——この一文で、改善が本物かどうかを誰でも判断できます。
「なんとなく良くなった気がする」ではなく、数字で語れるのは本当に大きいですよね。
オーバーナイト自動化も可能ですが、本番適用前に人間のレビューゲートを挟むのがコミュニティのベストプラクティスとされています。
3つのアプローチの比較
最も手軽に始められるのはLearnings Loopパターンです。
すでにClaude Codeを使っているなら、追加のセットアップなしで今日から試せます。
一方、チームで複数のスキルを本格運用するなら、cogneeの構造的な管理やAutoResearchパターンの定量評価が威力を発揮します。
では次のセクションで、これらに共通する自動改善ループの仕組みを、もう少し詳しく見ていきましょう。
自動改善ループの仕組みを図解する
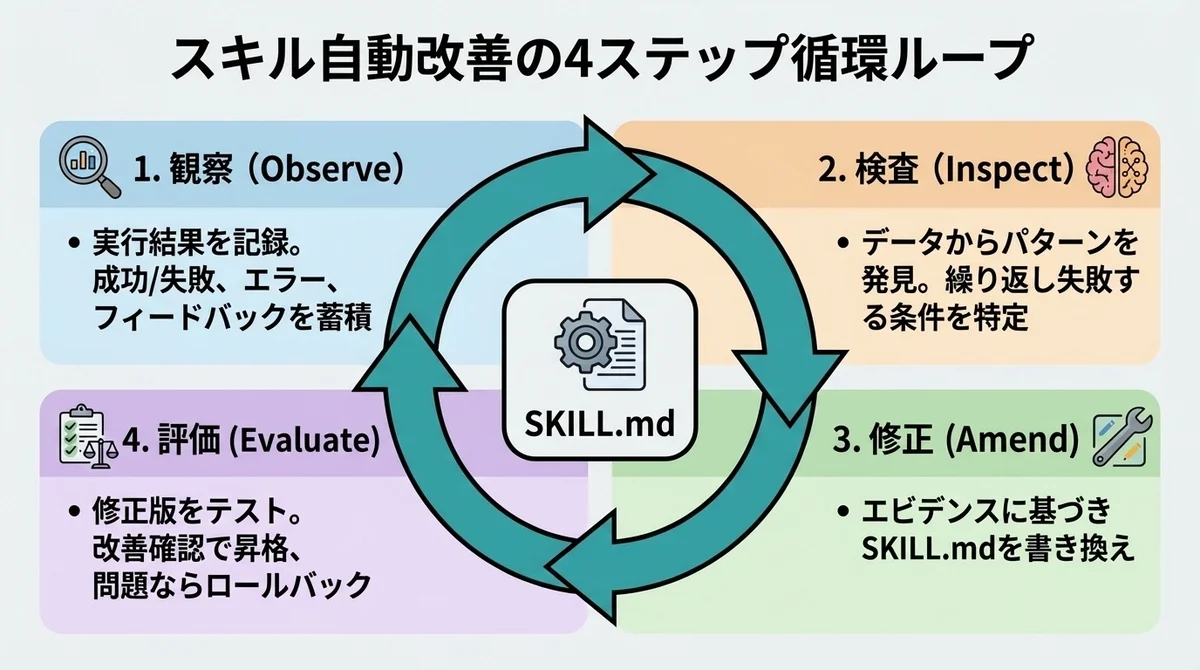
3つのアプローチに共通するのは、Observe → Inspect → Amend → Evaluate という4つのフェーズです。
cogneeの用語をベースに、それぞれ解説していきます。
一つずつ見ていくと、「なるほど、こうやってスキルが賢くなっていくのか」という全体像が掴めるはずです。
Observe(観察)——スキルの実行結果を記録する
最初のステップは「記録」です。
スキルが実行されるたびに、以下の情報を蓄積します。
- 何を試みたか——ユーザーのリクエスト内容
- どのスキルが選ばれたか——複数スキルがある場合、選択の根拠
- 成功したか、失敗したか——期待通りの出力が得られたか
- エラーの内容——失敗した場合の具体的なエラー情報
- ユーザーのフィードバック——「ここが違う」「こうしてほしかった」という指摘
この記録がなければ、改善のしようがありません。
当たり前のようですが、ここを省略しているケースは意外と多いんですよね。
Learnings Loopパターンでは、ユーザーのフィードバックがこのObserveに相当します。
AutoResearchパターンではEvalの実行結果が記録されます。
Inspect(検査)——失敗パターンを分析する
蓄積されたデータから、パターンを見つけ出すフェーズです。
たとえば、SNS投稿スキルのObserve記録から次のようなパターンが浮かび上がるかもしれません。
- 「技術的なテーマのとき、文字数が140文字を大幅に超える」(頻度: 5回/10回)
- 「ハッシュタグが日本語圏で使われていないタグになる」(頻度: 3回/10回)
- 「朝の投稿なのに、夜のトーンで書いている」(頻度: 2回/10回)
ここで重要なのは、個々のエラーではなく「パターン」を見つけることです。
1回の失敗は偶然かもしれませんが、同じ条件で5回失敗しているなら、それはスキルの構造的な問題ですよね。
cogneeはナレッジグラフで構造的にこの分析を行います。
Learnings Loopパターンでは、ユーザーのフィードバックが直接このパターンを教えてくれます。
Amend(修正)——エビデンスに基づいてSKILL.mdを書き換える
Inspectで特定されたパターンに基づいて、スキルの修正案を生成します。
修正の種類は大きく4つあります。
- トリガー条件の調整——「技術テーマの場合は280文字まで許容する」
- 条件分岐の追加——「投稿時間が6:00-9:00の場合、朝向けのトーンを使用する」
- ステップの並べ替え——「ハッシュタグ生成を先に行い、文字数をその後で調整する」
- 出力形式の変更——「日本語のハッシュタグを優先し、英語は補助的に使う」
cogneeの.amendify()メソッドは、これらの修正案をエビデンス(Inspectの分析結果)とセットで提示してくれます。
「なぜこの修正が必要か」が明示されるため、人間が判断しやすいんですよね。
ここが地味にすごいところで、修正案だけでなく「根拠」が付いてくるんです。
コードレビューで「なぜこの変更が必要なのか」をPRの説明に書くのと同じ発想ですね。
Evaluate(評価)——改善を確認して新バージョンへ昇格
修正案を実際にテストし、改善を確認するフェーズです。
ここが最も重要なステップです。
Vasilijeが繰り返し強調したのも、まさにこの点でした。
信頼できるのは、検証を経た改善のみ
修正版のスキルでタスクを実行し、以前よりも良い結果が出ることを確認します。
確認できたら新バージョンに昇格させ、問題があればロールバックします。
AutoResearchパターンでは、このEvaluateが特に強力です。
Evalファイルに定義した合格基準に対して、修正前と修正後のPass Rateを比較できます。
「合格率70% → 85%」のように、改善を数値で証明できるのは心強いですよね。
この4ステップが繰り返されることで、Vasilijeの言葉を借りれば「スキルは静的なプロンプトファイルではなく、進化するコンポーネントのように振る舞い始める」わけです。
放っておいてもスキルの精度が上がっていく。
手動で一つずつ直していたあの面倒な作業が、仕組みとして自動化される。
これがこのループの本質です。
自動改善ループを組み込む具体的なステップ
ここからは、Claude Codeで今日から試せる実践的な手順を紹介します。
Learnings Loopパターンをベースに、3ステップで自動改善の仕組みを組み込んでいきましょう。
どれも5分以内にできる作業なので、記事を読みながらでも試せますよ。
ステップ1: learnings.mdファイルを用意する
まず、フィードバックを蓄積するファイルを作成します。
# Learnings
## SNS投稿スキル
- 技術テーマの投稿は280文字まで許容する(140文字では情報が不足する)
- ハッシュタグは日本語タグを優先する(#AI活用 > #AIUsage)
- 朝の投稿(6:00-9:00)は「おはようございます」で始めるとエンゲージメントが高い
## コードレビュースキル
- セキュリティ関連の指摘は最優先で表示する
- 「なぜ問題なのか」の説明を必ず添えるこのファイルをプロジェクトの.claude/ディレクトリに配置します。
エージェントは次回のスキル実行時にこのファイルを参照し、蓄積された学びを反映してくれます。
やっていることはシンプルですが、これが「スキルの記憶装置」になるんです。
セッションが終わっても消えない、永続的な学びの蓄積先ですね。
ステップ2: SKILL.mdにフィードバック記録の指示を追加する
既存のSKILL.mdに、自動改善のための指示を追記します。
# SNS投稿の下書き作成
## 概要
与えられたテーマからX(Twitter)向けの投稿文を作成する。
## 手順
1. テーマのキーワードを抽出する
2. ターゲット読者の関心ポイントを特定する
3. 140文字以内で要点を伝える文章を作成する
4. ハッシュタグを3つ付与する
## 制約条件
- 絵文字は最大2個まで
- URLは短縮リンクを使用
- 投稿時間帯に応じてトーンを調整する
## 改善ルール
- ユーザーからフィードバックを受けた場合、learnings.md に記録する
- 同じ指摘が2回以上あった場合、このスキルの該当箇所を直接修正する
- 修正時は変更理由をコメントで残すポイントは末尾の「改善ルール」セクションです。
「え、たった3行?」って思いますよね。
でも、この3行の追記でエージェントの振る舞いが大きく変わります。
フィードバックを受けたら記録する、繰り返し指摘されたら自分で直す——この行動指針が明示されることで、スキルが「自己改善するコンポーネント」に変わり始めるんです。
ステップ3: フィードバックを意識的に提供する
自動改善ループの燃料は、ユーザーのフィードバックです。
スキルの実行結果に対して、意識的にフィードバックを与えていきましょう。
効果的なフィードバックの例を挙げます。
良いフィードバック(具体的):
- 「日付の表記はYYYY年MM月DD日で統一して」
- 「技術記事のタイトルには【】を使わないで」
- 「APIのレスポンス例は実際のJSONを使って」
改善しにくいフィードバック(抽象的):
- 「もっと良くして」
- 「なんか違う」
- 「前のほうが良かった」
具体的で、条件付きで、再現可能なフィードバックほど、スキルの改善精度が上がります。
コードレビューのコメントと同じですね。
「ここがダメ」ではなく「この条件のときにこう動いてほしい」と伝えるのがコツです。
3ステップをまとめるとこうなります。
- learnings.md を作成して、フィードバックの蓄積先を用意する
- SKILL.md に「改善ルール」を追記して、エージェントの改善行動を定義する
- 日々のフィードバック を具体的に提供して、改善ループを回す
Addy Osmaniが紹介しているCarsonのループ実装では、Gitコミット履歴、進捗ログ(progress.txt)、タスク状態ファイル(prd.json)、AGENTS.mdという4つのチャネルで学びを永続化する仕組みが示されています。
セッションが終わっても次のセッションに改善が引き継がれる点が、文脈内学習との決定的な違いです。
まとめ——スキルは「作るもの」から「育てるもの」へ
Vasilijeの投稿が170万インプレッションを超えた理由は、多くのAIエージェントユーザーが同じ課題を感じていたからです。
「スキルは作って終わりではない。
育て続けなければならない」——この認識が、2026年のAIエージェント運用における新しい常識になりつつあります。
本記事で紹介した3つのアプローチを整理するとこうなります。
- cognee——構造的なグラフ管理と自動分析で、エンジニア向けの本格的な自動改善
- Learnings Loopパターン——Claude Codeのスキルシステムで今日から始められるフィードバック駆動の改善
- AutoResearchパターン——テスト駆動で改善を定量評価できる、品質にこだわるチーム向け
今すぐできる最初の一歩
最もハードルが低いのは、Learnings Loopパターンから始めることです。
- 自分のプロジェクトに
learnings.mdを1つ作る - 既存のSKILL.mdに「改善ルール」セクションを追記する
- 次にスキルを使ったとき、結果に対して具体的なフィードバックを1つ伝える
たったこれだけで、スキルは「静的なプロンプトファイル」から「自分と一緒に成長するコンポーネント」に変わり始めます。
一度この仕組みが回り始めると、使えば使うほどスキルが賢くなっていくんですよ。
手動でSKILL.mdを書き直していた頃には、もう戻れなくなるはずです。
Claude CodeのSKILL.mdをはじめて作成する方は、まずスキルの基本設計から学ぶと理解が深まります。
また、AIエージェントを業務で継続的に活用したい方には、AIツールの選び方や使い倒し方をまとめた記事も参考にしてみてください。
よくある質問
Q. SKILL.mdの自動改善はClaude Codeの公式機能ですか?
Learnings LoopはAnthropicが公式に「Learnings Loop」と命名した機能ではなく、コミュニティの実践者が提唱しているベストプラクティスです。
Claude Codeのスキル・メモリシステムを活用した運用パターンとして広まっています。
cognee-skillsとAutoResearchパターンも同様に、公式機能ではなくサードパーティ・コミュニティのアプローチです。
Q. 非エンジニアでも自動改善ループを導入できますか?
Learnings Loopパターンは、Markdownファイルの編集とフィードバックの提供だけで始められます。
Pythonのコーディングや専用ライブラリの導入は不要です。
cogneeやAutoResearchパターンはエンジニア向けですが、Learnings Loopパターンであれば非エンジニアでも今日から試せますよ。
Q. スキルの自動改善によって、意図しない変更が加えられるリスクはありますか?
Vasilijeが強調したとおり、Evaluate(評価)ステップで検証を経てから新バージョンに昇格させることが重要です。
Learnings Loopパターンでも、フィードバックに基づく修正はエージェントが提案し、人間が確認してから反映する運用をおすすめします。
自動改善はあくまで「提案」であり、最終判断は人間が行う設計にすることでリスクを抑えられます。
関連リソース
- cognee(スキル自動改善機能を持つPythonライブラリ): https://github.com/topoteretes/cognee
- Claude Code公式ドキュメント(スキル): https://code.claude.com/docs/ja/skills
- Addy Osmani「Self-Improving Coding Agents」: https://addyosmani.com/blog/self-improving-agents/
- Andrej Karpathy AutoResearch: https://github.com/karpathy/autoresearch
- 1
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます