
はじめまして、もるふぉ@コードをかかないAIエンジニアです。
エンジニアをやりながら、今はほぼコードを書かない開発スタイルに移行しました。
「書けないから書かない」じゃなくて、「書けるから書かなくていい」という話です。
実案件ベースで気づいたことだけ書いています。
Claude Codeを毎日使い込んでいる人なら、こんな経験ありませんか?
「あれ、Claudeが前に覚えたはずのこと忘れてる」「なんか古い情報に引っ張られて、逆にトンチンカンなこと言い出した」。
Auto Memoryでセッション間の記憶が改善されたのは確かです。 でも、使えば使うほど新しい問題が見えてくるんですよね。
2026年3月24日、Claude Codeの /memory メニュー内で「Auto Dream」という新機能が発見されました。
AIがセッションの合間にメモリを自動で整理・統合する、いわば人間のREM睡眠のような機能です。
これ、地味にすごいんですよ。 「メモを取る」だけだったClaude Codeに、「メモを整理する」能力が加わったんです。 長期利用でメモリがゴミだらけになる問題、これで根本から変わります。
Auto Dreamが生まれた背景
Auto Memoryだけでは何が問題だったのか
Claude Codeにはすでに「Auto Memory」という機能がありますよね。 セッション中にClaudeが自動でメモを取って、ビルドコマンドやデバッグパターン、アーキテクチャの決定事項なんかを記録してくれる便利なやつです。
ところが、Auto Memoryには根本的な弱点があります。 「フィルタリングなしで何でも記録する」んです。 セッション中に有益だった情報も、一時的なデバッグメモも、全部同じ粒度で保存されてしまう。
想像してみてください。 ノートを取り続けるだけで、一度も見返さない人のノート。 それがAuto Memoryの実態です。
20セッション以上でメモリが「ゴミ箱」になる問題
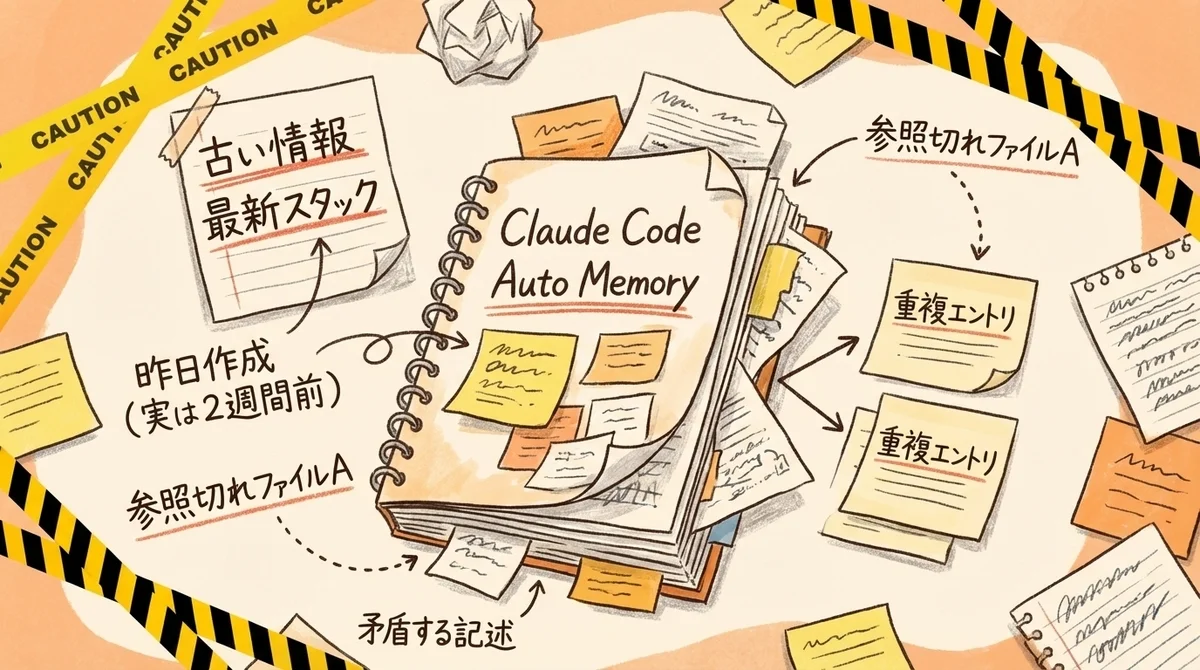
20セッション、30セッションと使い続けると、メモリファイルの中身は地獄絵図になります。 具体的にはこんな問題が起きるんです。
- 矛盾するエントリ: ExpressからFastifyに移行したのに「APIはExpressを使用」という古い記述が残っている
- 意味を失った相対日付: 「昨日Redisを使うことにした」が2週間前の話になっている
- 存在しないファイルへの参照: リファクタリングで削除したファイルのデバッグノートがいつまでも残る
- 重複エントリ: 3つのセッションで同じビルドの癖が別々に記録されている
「あるある」って思いましたよね? つまり、Auto Memoryは「メモを取る」のは得意だけど、「メモを整理する」仕組みがなかったんです。
ここが面白いところなんですが、Anthropicのエンジニアたちは「書くときにフィルタリングする(write-time filtering)」ではなく、「定期的にまとめて整理する(periodic consolidation)」というアプローチを選びました。 技術的には後者の方が実装が容易だったという背景もあります。 こうして生まれたのが、Auto Dreamという新しいメモリ統合機能です。
さて、ここからが本題です。 この機能、中身がめちゃくちゃよくできてるんですよ。
Auto Dreamの仕組み:4フェーズで何が起きるのか
この機能はバックグラウンドで動くサブエージェントとして実装されています。 システムプロンプトには次のように記述されています。
You are performing a dream — a reflective pass over your memory files. Synthesize what you've learned recently into durable, well-organized memories so that future sessions can orient quickly.
「dreamを実行している。 メモリファイルに対する振り返りのパスだ。 最近学んだことを、耐久性のある整理されたメモリに統合せよ」という指示です。
つまり、AIに「寝てる間に記憶を整理しろ」と言っているわけです。 人間の脳がやっていることを、プロンプトで再現しようとしている。 この発想、ワクワクしませんか?
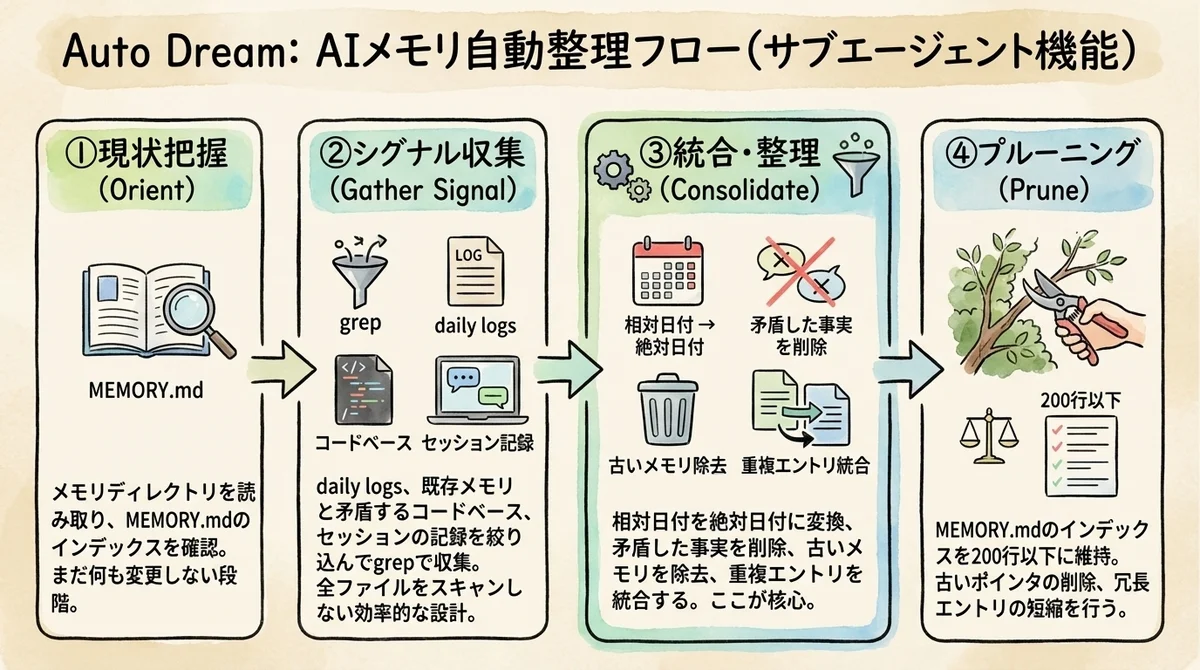
この処理は4つのフェーズで構成されています。
フェーズ1 - Orient(現状把握)
まず現在のメモリディレクトリを読み取ります。 MEMORY.mdを開いてインデックスを確認し、トピックファイルのリストをスキャンします。 assistant-modeのサブディレクトリ(logs/sessions)もチェックします。
ここではまだ何も変更しません。 人間の睡眠に例えるなら、寝入りばなに「今日は何があったっけ」と一日を振り返る段階です。
フェーズ2 - Gather Signal(シグナル収集)
次に、更新すべき情報のシグナルを集めます。 ここがよくできているんですが、全データを読み込むのではなく、ターゲットを絞ったgrepで効率的に情報を収集するんです。
優先順位は以下の通りです。
- daily logs: append-onlyのストリームから最新の変更を拾う
- 既存メモリと矛盾する現行コードベース: コードの実態とメモリの記述にズレがないかチェック
- セッショントランスクリプトの選択的grep: 必要に応じて過去のセッション記録を参照
全ファイルをフルスキャンしない設計は、トークン消費を抑えるうえで重要なポイントです。 「必要なものだけ見に行く」という効率重視の設計、エンジニアとしてはグッときますよね。
フェーズ3 - Consolidate(統合・矛盾解消)
ここがAuto Dream処理の核心部分です。 収集したシグナルをもとに、メモリを実際に書き換えます。
具体的に何が起きるかというと、こうです。
- 相対日付を絶対日付に変換: 「昨日Redisを使うことにした」→「2026-03-15にRedisを使うことにした」
- 矛盾した事実を削除: ExpressからFastifyに切り替えた後、「APIはExpressを使用」というエントリを削除
- 古いメモリを削除: リファクタリングで削除されたファイルに関するデバッグノートを除去
- 重複エントリを統合: 3つのセッションで同じビルドの癖が記録されていたら1つのエントリに集約
これ、自分でやろうとしたら相当面倒ですよね。 「ノートの棚卸し」をAIが勝手にやってくれる。 地味ですけど、長期利用における品質の差はここで決まります。
フェーズ4 - Prune(プルーニングとインデックス更新)
最後に、MEMORY.mdのインデックスを200行以下に維持します。 200行という上限は、Claude Codeがスタートアップ時にロードするインデックスのサイズ制限に由来しています。
各エントリは1行で表現されます。
- [Title](file.md) — one-line hook古いポインタの削除、冗長なエントリの短縮、新しいエントリの追加が行われ、インデックスが常にコンパクトに保たれます。 次のセッションが素早く立ち上がれるよう、インデックスが最適化されるわけです。
4フェーズの構造を理解したところで、この機能がメモリ全体のどの位置に収まるのかを整理していきましょう。
Claude Codeの4層メモリアーキテクチャを整理する
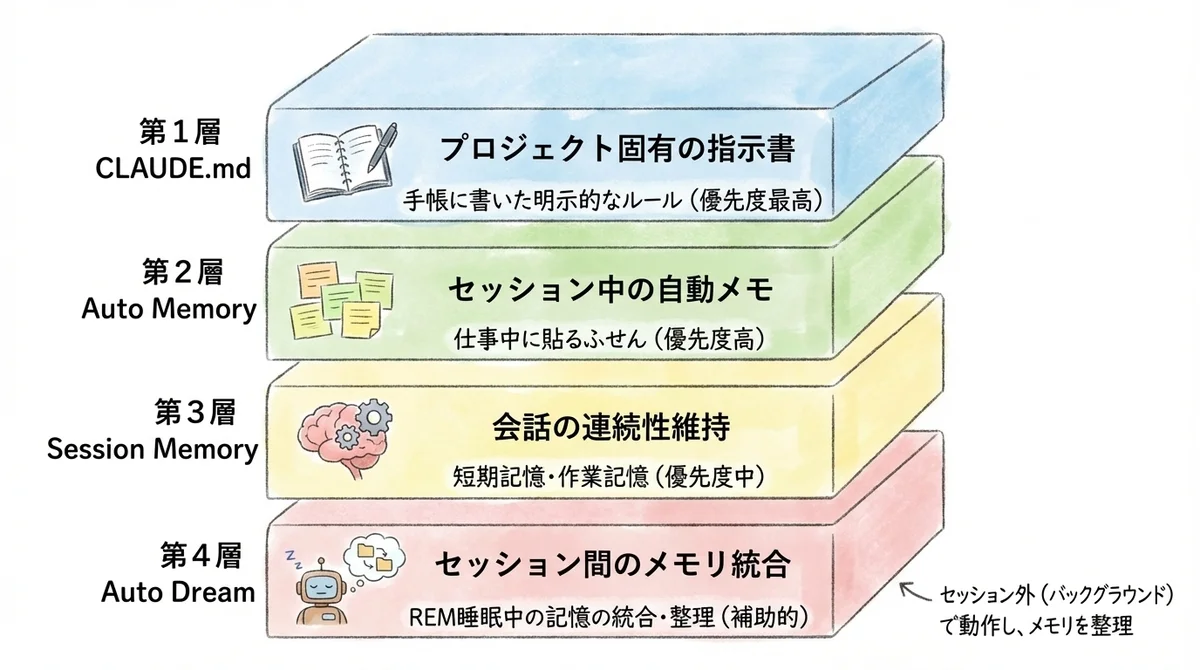
Auto Dreamの登場で、Claude Codeのメモリは明確な4層構造として整理できるようになりました。 これ、全体像がわかるとAuto Dreamのすごさがもっとよく見えてきます。
CLAUDE.md / Auto Memory / Session Memory / Auto Dream
身近なもので例えると、こんなイメージです。
- CLAUDE.md = 手帳に書いた明示的なルール
- Auto Memory = 仕事中に貼るふせん
- Session Memory = 短期記憶(作業記憶)
- Auto Dream = REM睡眠中の記憶の統合・整理
ここ、ちょっと注目してください。 この第4層だけが「セッション外」で動作するんです。 ユーザーがClaude Codeを使っていない間に、バックグラウンドでメモリを整理する。 まさに、人間が寝ている間に脳が記憶を定着させるのと同じ構造です。
4層すべてを有効にした時に何が変わるか
これまでは、セッションを重ねるほどAuto Memoryが肥大化して、Claudeの応答品質が徐々に劣化するという問題がありました。 「使えば使うほど賢くなる」はずが、「使えば使うほどメモリが散らかる」という皮肉な状態だったわけです。
Auto Dreamが加わることで、このサイクルが変わります。
- ユーザーがCLAUDE.mdに基本方針を書く
- セッション中にAuto Memoryが具体的な学びを記録する
- Session Memoryが会話の文脈を保持する
- セッション終了後にバックグラウンドでメモリが統合・整理される
- 次のセッションでClaudeが整理済みのメモリを読み込み、より正確な文脈で作業を開始する
「メモを取る(Auto Memory)」と「メモを整理する(Auto Dream)」が分離されたことで、長期間にわたってメモリの品質を維持できる設計になりました。 これは単なる機能追加ではなく、Claude Codeのメモリ管理に対するアーキテクチャレベルの改善です。
では、この設計思想はどこから来たのか。 理論的背景を掘り下げると、かなり興味深い論文との接点が見えてきます。
Auto Dreamの理論的背景:Sleep-time Compute論文との関係

UC Berkeley + Letta「Sleep-time Compute」論文とは
Auto Dreamの設計思想を理解するうえで、一つの論文が参考になります。 UC BerkeleyとLetta(旧MemGPT)チームが2025年4月に発表した「Sleep-time Compute」(arXiv:2504.13171)です。
この論文の主張はシンプルです。 LLMがアイドル時間に事前計算を行うことで、テスト時の計算量を5倍削減し、精度を最大18%向上させたという結果を報告しています。 「使われていない時間にこそ、モデルに仕事をさせるべきだ」という提案です。
これ、考えてみるとすごい発想ですよね。 人間だって、寝ている間に脳が勝手に情報を整理してくれる。 AIにも同じことをやらせよう、と。
論文の主張とAuto Dreamの実装の「正確な違い」
ここは多くの英語記事が曖昧にしている部分なので、正確に整理しておきます。
論文は「次にユーザーが何を聞くか」を予測して事前に計算しておくアプローチです。 一方、Auto Dreamは「過去に蓄積されたメモリのノイズを取り除く」アプローチです。
方向は真逆ですが、「アイドル時間を活用してエージェントの性能を維持・向上させる」という設計哲学は共通しています。 Auto Dreamが論文の「直接的な実装」だと言うのは言い過ぎですが、同じ思想の流れにあるのは間違いありません。 この違いを正確に理解しておくと、技術的な位置づけがクリアになります。
さて、理論はここまでにして、いよいよ実際の使い方です。
Auto Dreamを確認・実行する方法

「で、結局どうやって使うの?」という声が聞こえてきそうなので、具体的な手順を見ていきましょう。
/memoryメニューでの確認方法
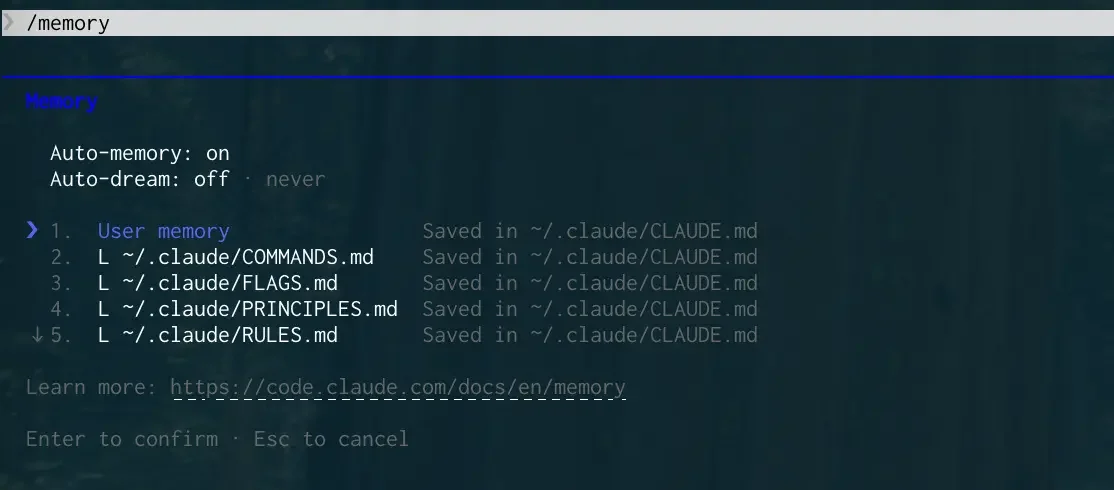
Claude Codeで /memory コマンドを実行すると、メモリ管理メニューが表示されます。
ここで「Auto-dream: on」という表示があれば、Auto Dreamが有効になっています。
/memoryただし注意点があります。 2026年3月25日時点では、この機能はサーバーサイドのフィーチャーフラグで制御されていて、多くのユーザーではまだ有効化できません。 「表示がないんだけど!」と焦る必要はありません。 あなたの環境が壊れているわけではないので安心してください。
/dreamコマンドで手動実行する
機能が有効な環境では、/dream コマンドで手動実行が可能です。
/dream実行すると、前述の4フェーズがバックグラウンドで走り、メモリの統合・整理が行われます。
ここで驚きの数字をひとつ。 ある開発者の報告では、913セッション分のメモリを9分以内に統合したそうです。 913セッション分ですよ。 それが9分。 バックグラウンド処理としては十分すぎる速度です。
自動実行の条件(24時間+5セッション)
「毎回手動で実行するのは面倒だな」と思いましたよね。 安心してください、自動実行の仕組みがあります。
自動実行にはデュアルゲート条件があります。
- 前回のdreamから24時間以上経過していること
- その間に5セッション以上のアクティビティがあること
両方の条件を満たした場合にのみ、自動でトリガーされます。 つまり、1日1回程度のペースで、十分なデータが溜まった時だけ実行される設計です。 頻繁すぎる実行によるトークンの無駄遣いと、長期間放置によるメモリの劣化の、ちょうどよいバランスを取っています。
ただし、夢ばかり見ていられないのが現実です。 現時点での課題も正直にお伝えしておきます。
現在の課題と今後の展望
Auto Dreamの可能性は大きいですが、課題も明確に指摘されています。 ここは公平に見ておきましょう。
GitHub Issue #38493が指摘する3つのギャップ
GitHub Issue #38493では、Auto Dreamに関する3つのギャップが報告されています。
- Identity(命名の正確性): メモリの命名やカテゴライズが不正確になる可能性があります。 Dreamプロセスがファイル名やタイトルを自動生成する際、内容と一致しない名前がつく場合があるんです。
- Accuracy(事実の検証): 事実が検証されないまま記録・統合されるリスクがあります。 Auto Dreamは既存のメモリを整理しますが、その内容が正しいかどうかを外部ソースと照合する仕組みはありません。
- Transparency(監査可能性): dreamプロセスで何が変更されたのかを追跡するのが困難です。 バックグラウンドでメモリが書き換えられた結果、重要な情報が失われていないかを確認する手段が現時点では限られています。
また、トークン消費量の懸念もコミュニティで議論されています。 バックグラウンドでサブエージェントを走らせる以上、当然ながらAPIトークンを消費します。 このコストをどう吸収するかは、Anthropicにとって重要なビジネス判断になるでしょう。
ロールアウト状況と一般提供の見通し
2026年3月25日時点で、Auto Dreamはサーバーサイドのフィーチャーフラグで制御されています。 一般ユーザーへのロールアウト時期は公式にアナウンスされていません。
ただし、Auto Memoryが2026年2月のv2.1.32で一般提供された流れを考えると、Auto Dreamも数週間から数ヶ月以内に段階的にロールアウトされる可能性は十分にあります。
/memory メニューを定期的にチェックしておくのがおすすめです。
まとめ:Auto DreamはAIエージェントの「記憶」をどう変えるか
Claude Code Auto Dreamは、Auto Memoryの「メモを取る」機能に「メモを整理する」機能を加えた、メモリ管理アーキテクチャの重要なピースです。
この記事のポイントを振り返ります。
- Auto Memoryだけではセッションが増えるほどメモリが散らかる問題があった
- Auto Dreamは4フェーズ(Orient → Gather Signal → Consolidate → Prune)でメモリを自動統合する
- Claude Codeのメモリは4層構造(CLAUDE.md / Auto Memory / Session Memory / Auto Dream)として整理できる
- Sleep-time Compute論文と設計哲学を共有するが、直接的な実装ではない
- 現時点ではフィーチャーフラグ制御で、一般提供は未定
Auto Dreamが示しているのは、AIエージェントの「記憶」が単なるログの蓄積から、能動的な統合・整理へと進化しているという方向性です。 人間がREM睡眠で記憶を整理するように、AIも「眠る」時間が必要になる。 この発想の転換は、Claude Codeに限らず、今後のAIエージェント開発全般に影響を与えるでしょう。
まずは /memory コマンドを実行して、あなたの環境でAuto Dreamが有効になっているか確認してみてください。
コマンド一つで確認できます。
有効であれば /dream で手動実行を試してみるのも面白いですよ。
913セッション分のメモリが数分で整理される様子は、AIの「睡眠」を目の当たりにする感覚です。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます