
はじめまして、もるふぉ@コードをかかないAIエンジニアです。
エンジニアをやりながら、今はほぼコードを書かない開発スタイルに移行しました。
「書けないから書かない」じゃなくて、「書けるから書かなくていい」という話です。
実案件ベースで気づいたことだけ書いています。
「マルチエージェントにすれば、もっと賢くなるはず」──AIエージェントの設計でそう考えたことはありませんか。 エージェントを増やした結果、むしろ性能が落ちた。 そんな事例が、Google Research・MIT Media Lab・Anthropic・Cognition AIの研究から相次いで報告されています。
この記事では、3つの最新研究を横断的に読み解きながら、「エージェントの数ではなく設計の質がすべてを決める」という業界の新しいコンセンサスを、データとともに解説します。
「エージェントを増やせば賢くなる」という通説
なぜこの誤解が広まったのか
「人間のチームだって、人数が増えれば仕事は早く終わる」。 マルチエージェントへの期待は、この直感に支えられています。
実際、2024年から2025年にかけて「マルチエージェントフレームワーク」を謳うOSSやプロダクトが続々と登場しました。 CrewAI、AutoGen、LangGraphなど、エージェントを複数並べてタスクを分担させる仕組みが次々に公開され、「エージェントは増やすほど賢くなる」というイメージが広まりました。
しかし、これは「ブレインストーミングは人数が多いほどアイデアが出る」と思い込むのと同じ種類の誤解です。 実際のブレインストーミング研究では、人数が増えると社会的手抜きや同調圧力が発生し、一人で考えたほうがアイデアの質も量も高いことが知られています。 AIエージェントにも、似たような「数の罠」があったのです。
実際のプロダクトで起きていること
あなたも、こんな経験をしたことはないでしょうか。
「とりあえずエージェントを分割してみたら、なぜか出力がバラバラになった」「並列で動かしたはずなのに、最終結果がちぐはぐで使い物にならなかった」──マルチエージェント構成を採用したプロダクトでは、こうした問題が繰り返し報告されています。
具体的には、次のようなパターンです。
- エージェントAが決めた方針を、エージェントBが知らずに上書きする
- 各エージェントが独立して動いた結果、最終出力の整合性が崩壊する
- エラーが1つのエージェントで発生すると、後続のエージェントに波及して被害が拡大する
- 「どのエージェントが何を決めたのか」が追跡できず、デバッグに何時間もかかる
「エージェントを増やしたのに、なぜか品質が下がった」。 この現象の根本原因を、3つの研究機関が異なる角度から明らかにしています。 そして、その結論は驚くほど一致していました。
3つの研究機関が出した「逆の結論」
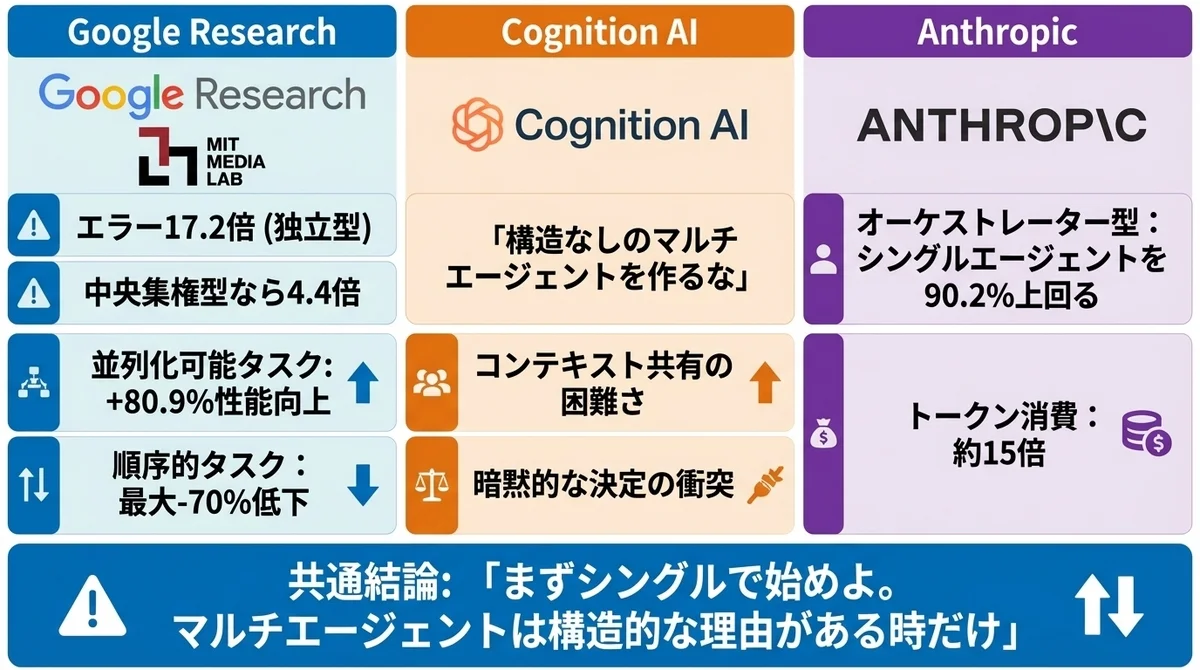
Google Research × MIT Media Lab:独立型マルチエージェントはエラーが17.2倍に増幅する
Google ResearchとMIT Media Labの共同研究チームは、論文「Towards a Science of Scaling Agent Systems」で、180ものエージェント構成を体系的に評価し、初の定量的なスケーリング原則を導出しました。
結果は衝撃的です。
- 並列化可能なタスク(金融分析など):中央集権型マルチエージェントで+80.9%の性能向上
- 順序的なタスク(PlanCraftなど):マルチエージェントで最大-70%のパフォーマンス低下(39〜70%の範囲)
特に注目すべきは、エラー増幅の差です。
独立型、つまり各エージェントがバラバラに動く構成では、エラーが17.2倍にも増幅されます。 一方、中央のオーケストレーターが結果を集約する中央集権型(Centralized)では4.4倍に抑えられます。
これが地味にすごいんですよ。 「エラーが4倍になるのを良しとする設計か、17倍になるのを許容する設計か」──この差は、プロダクトの信頼性に直結します。
さらにGoogleらは5つのアーキテクチャ(シングルエージェント、独立型、中央集権型、分散型、ハイブリッド)を評価し、予測モデルを構築。 このモデルは87%の未知タスクで最適なアーキテクチャを特定できたと報告しています。
つまり、「マルチエージェントが有効かどうかはタスク次第」であり、闇雲にエージェントを増やすのは逆効果だということです。 そして、タスクの性質を分析すれば、事前に最適な構成を高い確率で判断できる──これは設計者にとって、非常に心強い知見です。
Cognition AI:構造なしのマルチエージェントを作るな
Devin(AIソフトウェアエンジニア)を開発するCognition AIは、ブログ「Don't Build Multi-Agents」で、さらに踏み込んだ主張をしています。
彼らの核心的な問題提起は、コンテキスト共有の困難さです。
想像してみてください。 Flappy Birdのクローンを作るタスクがあります。 「背景担当エージェント」と「鳥担当エージェント」を別々に動かしたとしましょう。 背景担当は雰囲気に合わせてスーパーマリオ風のレンガ模様の背景を作成し、鳥担当はモダンなフラットデザインで鳥のスプライトを作成する。 それぞれ、担当範囲では完璧な仕事をしています。 ところが、いざ統合してみると──まったくスタイルが噛み合わず、見た目がちぐはぐに破綻してしまう。
「え、それだけで崩壊するの?」って思いますよね。 でも、これが現実なんです。
人間のチームなら「隣の席の同僚に聞く」で解決できることが、エージェント間では構造的に共有できません。 各エージェントは自分のコンテキストウィンドウの中でしか判断できないため、他のエージェントが何を決めたかを知る手段がないのです。 Cognition AIはこれを「暗黙的な決定の衝突」と呼んでいます。
Cognition AIの推奨はシンプルです。
- 最高推奨: シングルスレッド線形エージェント
- 長期タスク向け: 圧縮メモリ機構を搭載したシングルエージェント
実際、Claude Codeも当初はシングルスレッド設計でスタートしました(なお、これはCognition AIのブログが執筆された時点の話であり、Claude Codeはその後Task toolによる並列実行を導入しています)。 それほどシングルスレッドの信頼性が、現場でも評価されていたということです。
Anthropic:オーケストレーター型なら90.2%上回れる(ただしトークン15倍)
意外だったのが、マルチエージェントの旗手とも言えるAnthropicの立場です。 彼らは決してマルチエージェントを全否定せず、条件付きで有効な設計パターンを2つの記事で丁寧に整理しています。
「Building Effective Agents」では、シンプルなパターンから始めて必要に応じて複雑化すべきという原則と、5つのワークフローパターンを整理しています。
- Prompt Chaining - タスクを連鎖的に処理
- Routing - 入力に応じて適切な処理に振り分け
- Parallelization - 独立タスクを並列実行
- Orchestrator-Workers - 中央が指揮し、サブエージェントが実行
- Evaluator-Optimizer - 生成と評価を繰り返し改善
さらに「How we built our multi-agent research system」では、Claude Opus 4をリードエージェント、Claude Sonnet 4をサブエージェントとしたマルチエージェント研究システムが、シングルエージェントのClaude Opus 4を内部評価で90.2%上回ったと報告しています。
ただし、代償があります。 トークン消費は約15倍です。
つまり、「90%良くなるけど、コストは15倍かかる」。 このトレードオフを理解した上で採用するかどうかが、設計者の腕の見せどころです。
Anthropicの推奨は明確です。 最適化された単一LLM呼び出しから開始し、必要に応じて複雑化する。
3つの研究機関がそれぞれ違う文脈・違う方法で検証して、同じ結論に至っている──この一致は、単なる偶然ではないと思います。
Anthropicが定義するOrchestrator-Workers型の実装をClaude Codeのスキル設計で実現する方法については、Claude Code スキル設計の失敗しない4パターン|SKILL.mdの書き方から呼び出し制御までで詳しく解説しています。
なぜマルチエージェントはエラーを増幅するのか
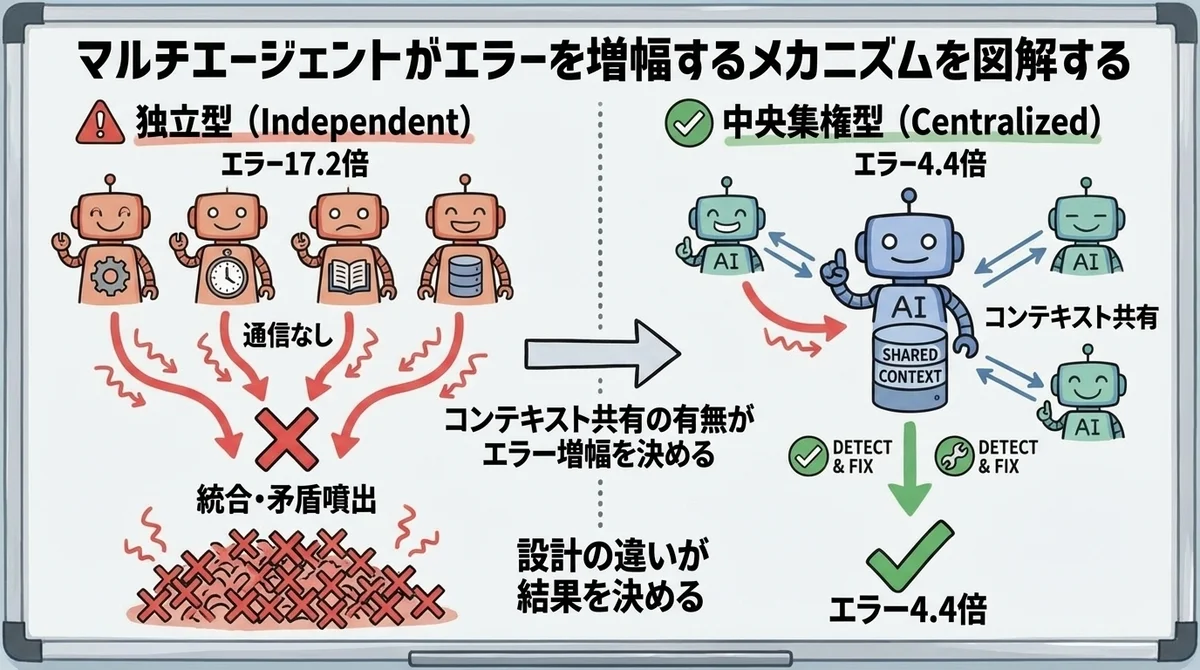
3つの研究が異なる角度から同じ結論に至っている背景には、構造的な理由があります。
コンテキスト非共有がもたらす「知識の断絶」
マルチエージェントでエラーが増幅する最大の原因は、コンテキストの非共有です。
人間のチーム開発を想像してください。 デザイナーとエンジニアが別々に作業しても、Slackで「こっちは青ベースでいくね」と一言共有すれば済みます。 しかしAIエージェント間には、この「Slack」に相当するものがありません。
各エージェントは自分のコンテキストウィンドウの中だけで意思決定します。 エージェントAが「背景は暗い色調」と決め、エージェントBが「UIは明るいトーン」と決める。 どちらも単体では合理的な判断ですが、統合すると破綻する。 Cognition AIが指摘した「暗黙的な決定の衝突」が、ここで発生します。
エラー伝播のメカニズム:独立型 vs 中央集権型
Google Researchらのデータが、エラー伝播の構造を明確にしています。
独立型(各エージェントが独立して出力)では、あるエージェントのエラーが他のエージェントに検知されないまま最終出力に含まれます。 しかも、各エージェントが独自にエラーを生む可能性があるため、エラーは「加算」ではなく「乗算」的に増えます。 結果として17.2倍のエラー増幅が発生します。
中央集権型(中央のオーケストレーターが結果を統合)では、オーケストレーターがフィルターの役割を果たします。 サブエージェントの出力を統合する段階で、矛盾や明らかなエラーを検出・修正できます。 それでも4.4倍のエラー増幅は残りますが、独立型と比べれば大幅に制御可能です。
タスク特性による分岐:読み込み vs 書き込み
ここで重要なのは、「すべてのマルチエージェントが悪い」わけではないということです。
Google Researchらの結果を見ると、タスクの性質によって効果がまったく異なります。
読み込み型タスク(情報収集・分析・比較)は並列化との相性が良好です。 金融分析のように、各エージェントが異なるデータソースを独立して分析し、最後に結果を集約するタスクでは+80.9%の性能向上が見られました。 エージェント間で「何かを一緒に作る」必要がないため、コンテキスト非共有の問題が顕在化しにくいのです。
書き込み型タスク(コード生成・文書作成・クリエイティブ制作)は順序的な依存関係が強く、最大-70%のパフォーマンス低下が起きました。 あるエージェントの出力が次のエージェントの入力になるため、前段のエラーや方針のズレが後段に累積するのです。
この「読み込み vs 書き込み」の分類は、マルチエージェントを検討する際の最も実用的な判断軸になります。 次のセクションでは、この軸をもとに「どのタイミングで移行すべきか」を整理します。
「まずシングルエージェントで始めよ」がAIエージェント設計の業界結論になった理由
シングルエージェントで解決できる問題の範囲
「シングルエージェントでは限界があるのでは?」と思うかもしれません。 しかし、現在のLLMの能力を考えると、シングルエージェントで対応できる範囲は想像以上に広いです。
Anthropicが述べているように、成功するエージェント実装は「最適化された単一LLM呼び出し」から始まります。 Prompt ChainingやRoutingといったパターンは、すべてシングルエージェントの枠組みで実現可能です。
コード生成、文書作成、データ分析、カスタマーサポート──これらのタスクの大半は、適切にプロンプトを設計したシングルエージェントで十分な品質が得られます。 Cognition AIのDevinも、シングルスレッド設計で複雑なソフトウェアエンジニアリングタスクをこなしています。
まずシングルエージェントで始め、使いながらスキルを自動改善していく仕組みについては、Claude CodeのSKILL.mdが自動で改善される「Learnings Loop」とは?が参考になります。
マルチエージェントに移行すべき「構造的な理由」とは
では、どんなときにマルチエージェントを検討すべきなのか。 3つの研究を総合すると、以下の「構造的な理由」がある場合に限られます。
- タスクが本質的に並列化可能:各サブタスクが独立しており、他のエージェントの出力に依存しない(例:複数データソースの並列分析)
- 単一コンテキストウィンドウに収まらない:処理すべき情報量が1つのエージェントのコンテキスト長を超える
- 異なる専門性が必要:コード生成とセキュリティ監査のように、根本的に異なるプロンプト設計が求められる
- 中央のオーケストレーターを置ける:独立型ではなく、中央集権型またはオーケストレーター型の設計が可能
逆に言えば、「なんとなく速くなりそう」「エージェントが多いほうが賢そう」という理由では移行すべきではありません。
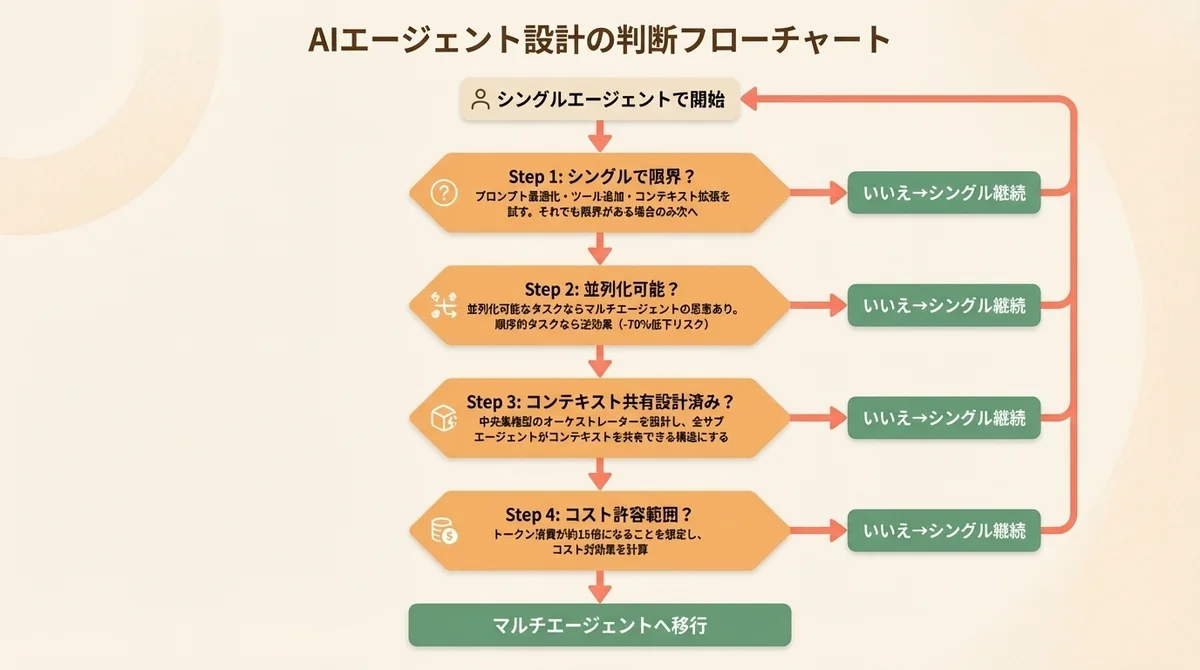
判断フローチャート:どのタイミングでマルチエージェント移行を検討するか
以下の順番でチェックしてください。
ステップ1: シングルエージェントで試したか? → No → まずシングルエージェントでPoCを作る
ステップ2: シングルエージェントの限界に達したか? → No → プロンプト最適化やPrompt Chainingで改善を試みる
ステップ3: 限界の原因は「構造的」か? → コンテキスト長の制約、並列化の必要性、異なる専門性の要件 → マルチエージェントを検討 → プロンプトの質、モデルの能力 → モデル変更やプロンプト改善で対応
ステップ4: オーケストレーター型で設計できるか? → Yes → Orchestrator-Workers型を採用(独立型は避ける) → No → 中央集権型(Centralized)を検討
このフローの核心は、「マルチエージェントは最初の選択肢ではなく、最後の手段」だということです。
Anthropicのオーケストレーター型が示す「正しいマルチエージェント設計」
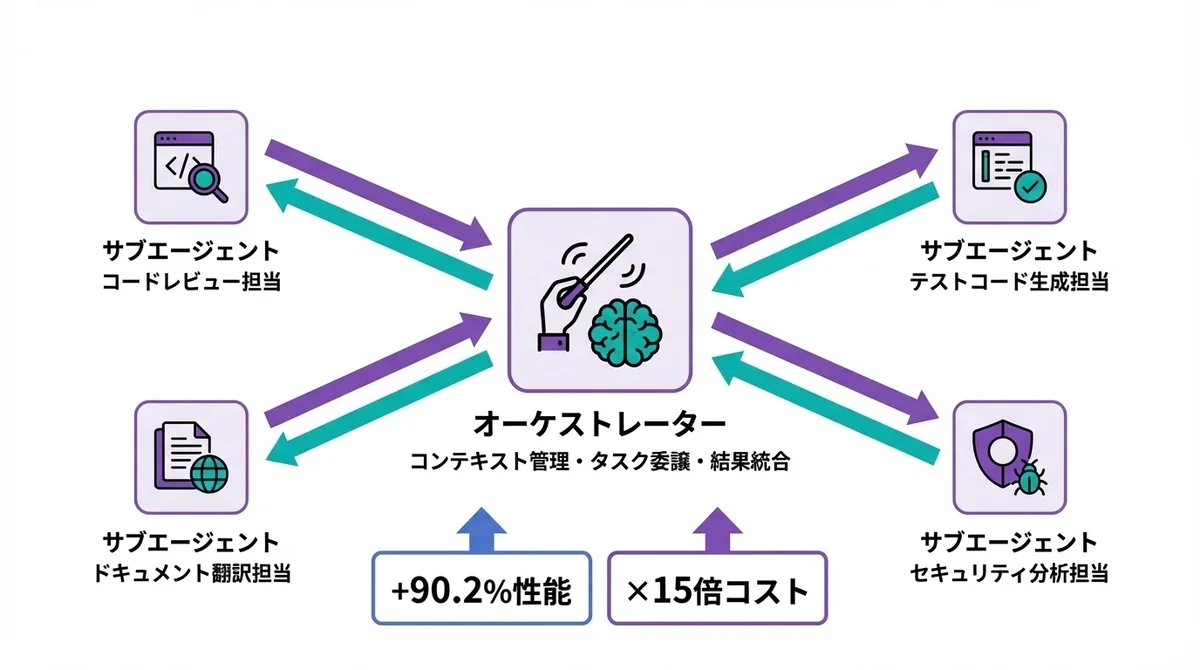
オーケストレーターとサブエージェントの役割分担
マルチエージェントが必要になった場合、AnthropicのOrchestrator-Workers型が最も有効な設計パターンです。
この型の特徴は、明確な役割分担にあります。
オーケストレーター(司令塔)の役割:
- タスク全体の分解と計画策定
- サブエージェントへのタスク割り当て
- サブエージェントの出力の統合と品質チェック
- コンテキストの一元管理
サブエージェント(実行者)の役割:
- 割り当てられた特定タスクの実行
- 結果をオーケストレーターに報告
- 自分の担当範囲に集中
これは、優秀なプロジェクトマネージャーとスペシャリストチームの関係に似ています。 PMが全体の整合性を担保しながら、各メンバーは自分の専門領域に集中する。 「暗黙的な決定の衝突」は、PMが防いでくれるわけです。
90.2%の性能向上はどこから生まれたのか
オーケストレーター型がシングルエージェントを90.2%上回れた理由は、独立型マルチエージェントの弱点を構造的に克服しているからです。
- コンテキストの一元管理: オーケストレーターが全体の文脈を保持するため、サブエージェント間の「知識の断絶」が発生しない
- 品質フィルタリング: サブエージェントの出力をオーケストレーターが検証するため、エラーが最終出力に混入しにくい
- 動的なタスク分解: 固定的な分担ではなく、進行状況に応じてタスクを動的に再割り当てできる
独立型がエラー17.2倍だったのに対し、オーケストレーター型では中央の制御がエラー増幅を大幅に抑制します。 中央集権型の4.4倍よりもさらに低い増幅率に抑えられるのは、事前のタスク分解と事後の品質検証の両方が機能するためです。
なお、90.2%という数値はAnthropicの内部評価に基づくものであり、公開ベンチマークではありません。 実際の効果はタスクやシステム構成によって異なります。
トークンコストとのトレードオフ計算
ここで現実的な話をしましょう。 90.2%の性能向上は魅力的ですが、トークン消費が約15倍になるという代償を無視できません。
具体的な数字で考えてみます。
性能が約2倍になる代わりに、コストは15倍。 「性能あたりのコスト効率」で見ると、シングルエージェントのほうが圧倒的に効率的です。
たとえば月間1万リクエストのサービスで考えてみましょう。 シングルエージェントで月$1,000かかっているシステムをオーケストレーター型に切り替えると、コストは$15,000になります。 性能は向上しますが、その向上分がランニングコストの14,000ドル増加を正当化できるかどうか──これが設計者に問われる判断です。
では、いつオーケストレーター型のコストが正当化されるのか。
- 品質が最優先のタスク: 性能90.2%向上の価値がコスト15倍を上回るケース(例:重要なコード生成、法的文書の作成)
- エラーコストが極めて高いタスク: エラーが発生した場合の損失がトークンコストを大幅に超えるケース
- 大規模な並列分析: 金融分析のように、並列化による性能向上がコストを正当化するケース
逆に、定型的なタスクや試行錯誤が許される場面では、シングルエージェントで十分です。 「性能とコストのどちらを優先するか」──この判断が、エージェント設計の最も重要な意思決定ポイントになります。
まとめ:エージェントの数ではなく設計の質がすべてを決める
3つの研究が示す結論は、驚くほど一致しています。
この3つから導かれるAIエージェント設計の原則は、次の3点に集約されます。
- まずシングルエージェントで始める: 最適化された単一エージェントの性能を最大限引き出してから、次を考える
- マルチエージェントは構造的な理由がある場合のみ: 「なんとなく」ではなく、タスクの並列性・コンテキスト長の制約・専門性の分離といった明確な根拠が必要
- やるなら中央集権型またはオーケストレーター型: 独立型マルチエージェントは最悪の選択肢。中央制御を必ず置く
「エージェントを増やせば賢くなる」時代は終わりました。 これからは「正しい設計で、最小限のエージェントから最大限の成果を引き出す」時代です。
あなたの次のAIプロダクトの設計で、まず問うべき質問はこうです。 「このタスクは、本当にマルチエージェントが必要か?」
よくある質問
Q: マルチエージェントとシングルエージェントはどちらを選ぶべきですか?
タスクの性質によります。並列化可能なタスク(各サブタスクが独立している場合)や、単一コンテキストウィンドウに収まらない大量情報処理には中央集権型のマルチエージェントが有効です。それ以外の大多数のタスクは、最適化されたシングルエージェントで十分な品質が得られます。Google Research・Cognition AI・Anthropicの三者が「まずシングルエージェントで始める」ことを推奨しています。
Q: マルチエージェントでエラーが増幅する仕組みはなぜですか?
主な原因はコンテキストの非共有です。各エージェントは自分のコンテキストウィンドウ内でのみ判断するため、他のエージェントの決定を知ることができません。独立型では各エージェントがそれぞれエラーを生む可能性があり、エラーは加算ではなく乗算的に増えます。Google Researchの研究では、独立型マルチエージェントで最大17.2倍のエラー増幅が確認されています。
Q: Anthropicのオーケストレーター型は具体的にどんな設計ですか?
中央のオーケストレーターが全体の文脈管理・タスク分解・品質チェックを担い、サブエージェントが割り当てられたタスクの実行に集中する構成です。Anthropicの内部評価では、シングルエージェントを90.2%上回る性能が報告されています。ただしトークン消費は約15倍になるため、コストと品質のトレードオフを考慮した上での採用を推奨します。
Q: マルチエージェントに移行すべきタイミングはどう判断しますか?
以下の4条件を確認してください。(1)タスクが本質的に並列化可能か、(2)処理すべき情報量が単一コンテキストウィンドウを超えるか、(3)根本的に異なる専門性が必要か、(4)中央のオーケストレーターを設置できるか。4つのうち複数が当てはまる場合のみマルチエージェントを検討し、それ以外はシングルエージェントの最適化を優先してください。
よければXもフォローしてもらえると嬉しいです → X(@morphox_ai)
- 1
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます