「Figmaのデザインカンプを見ながら、ひたすら手でHTMLとCSSを書いていく」という作業、地味にしんどいですよね。
デザインを見て、要素を確認して、クラス名を考えて、Flexboxのプロパティを調べて、「あれ、余白どうなってたっけ」ともう一度デザインを確認して…。このループ、開発時間の何割かを普通に持っていかれます。
そのストレス、もう終わりにできるかもしれません。
それが GLM-5V-Turbo です。
GLM-5V-Turboは、Z.aiが開発したマルチモーダルAIモデルで、デザイン原稿やスクリーンショットを渡すだけで実行可能なコードを生成できるのが最大の特徴です。
しかもベンチマーク結果が衝撃的で、デザインからコード生成の指標でClaudeのスコア77.3に対して 94.8 という圧倒的な数値を叩き出して話題になっています。
「え、その差ってどのくらいすごいの?」という方、安心してください。この記事でちゃんと翻訳します。
GLM-5V-Turboが何者なのか、なぜここまでデザイン→コード変換に強いのか、chat.z.aiで今すぐ無料で試す方法まで、まるっと解説します。
GLM-5V-Turboの概要と注目された理由

智谱AIは2019年に清華大学のKEG(Knowledge Engineering Group)から生まれたAIスタートアップで、GLM(General Language Model)シリーズを開発してきた会社です。
日本ではあまり知られていないかもしれませんが、中国ではOpenAIに対抗する存在として注目されており、技術力は本物です。
GLMシリーズはGLM-4、GLM-5と進化してきており、今回のGLM-5V-Turboは「5V」という名前が示す通り、ビジョン(Vision)能力に特化したモデルです。
グローバル向けには Z.ai というブランドで展開しており、chat.z.aiからWeb UIを通じて試すことができます。
「中国のAI、どうせ大したことないでしょ」と思っていた方、ちょっと待ってください。このモデルは本当にヤバいです。
GLM-5V-Turboが発表されたタイミングと背景
GLM-5V-Turboが特に注目を集めたのは、デザインからコードを生成するという、フロントエンド開発の「一番面倒な部分」でClaudeやGPT-4oを上回るベンチマーク結果を出したからです。
マルチモーダルAIの競争は今、テキスト理解や画像説明にとどまらず、「実際の開発ワークフローで使えるか」という実用性の段階に入っています。
その中で「デザイン→コード変換」という具体的なユースケースに絞って圧倒的な性能を示したことで、フロントエンドエンジニア・ウェブデザイナー界隈でひそかに大きな話題になっています。
次のセクションでは、なぜGLM-5V-Turboがここまでデザイン→コード変換に強いのか、仕組みから解説します。
GLM-5V-Turboがウェブデザインからのコード生成で強い理由
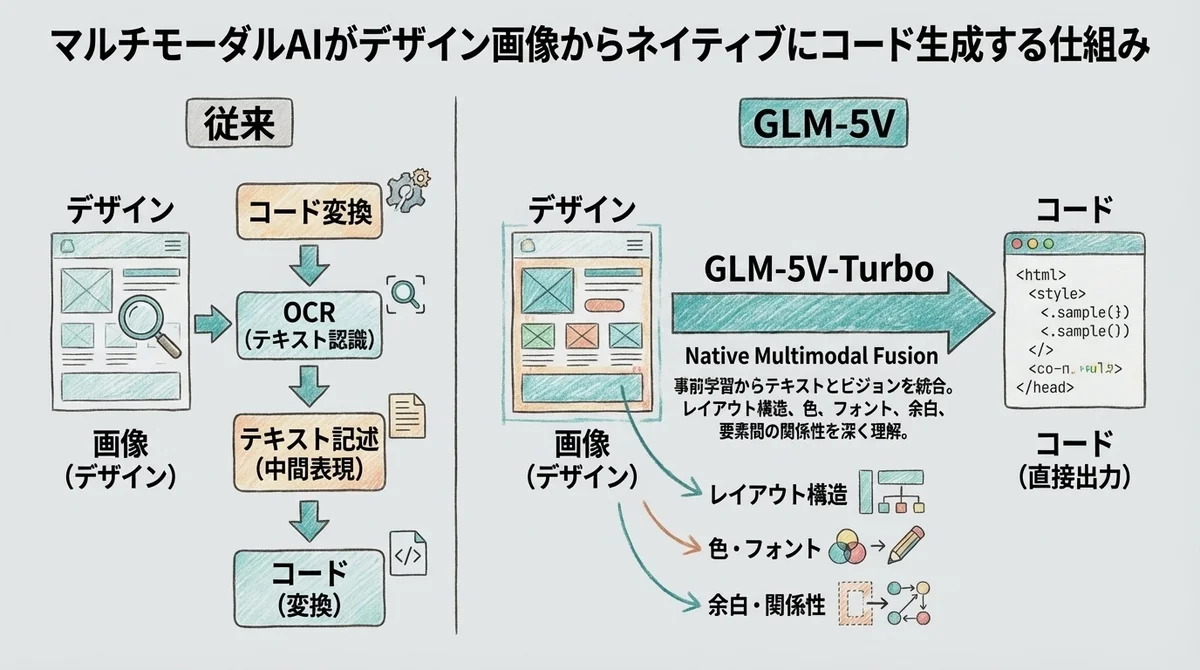
デザイン画像からネイティブにコード生成できる仕組み
GLM-5V-Turboの一番のすごさは、「ネイティブに」コードを生成できる点です。
従来のアプローチだと、AIに画像を渡してコードを生成させる場合、実は裏側でOCR的な処理(画像からテキストを抽出する処理)が入っていたり、「このボタンは青色で、右上に配置されていて...」という中間的なテキスト記述を経由してコードに変換していました。
GLM-5V-Turboはそういった中間処理をスキップして、画像を見てそのままコードを吐き出せます。
つまり、Figmaのスクリーンショットをそのまま渡すだけで、HTMLとCSSが出てくるんです。
「テキストで説明してからコードを生成」ではなく「画像→コード」が直接つながっている。これがこのモデルの核心です。
つまり、今まで「Figmaを見ながら手でコーディング→AIに修正してもらう」という2ステップだった作業が、「スクショを渡す」の1ステップで済むようになるんです。
「Native Multimodal Fusion」──事前学習段階からのテキスト×ビジョン統合
ここが他のマルチモーダルモデルとの根本的な違いなんですが、GLM-5V-Turboは 事前学習の段階からテキストとビジョンを統合 しています。
一部のマルチモーダルモデルは、まずテキストモデルを作ってから、後でビジョン能力を「接続」するアーキテクチャを採用しています。これを「後付け統合」と呼ぶと分かりやすいかもしれません。
GLM-5V-Turboの「Native Multimodal Fusion」は違います。テキストとビジョンを最初から一緒に学習させているので、画像の中のレイアウト構造、色、フォント、余白、要素間の関係性を、テキストと同じレベルで深く理解できます。
これがあるだけで、デザインの「意図」を読み取る精度が全然違います。
ボタンが右寄せになっているのはなぜか、このフォントサイズはH2なのかp要素なのか、この空白はpaddingなのかmarginなのか。こういった判断が、事前学習段階からテキストとビジョンを統合しているからこそ正確にできるわけです。
「なんか微妙にズレてる」を修正し続けるあの作業、Native Multimodal Fusionがあればかなり減らせます。
ワイヤーフレームから高忠実度デザインまで──ピクセルレベルの一貫性
もう一つ地味にすごいのが、入力の品質を選ばない点です。
ラフなワイヤーフレームのスケッチでも、Figmaで作り込んだ高忠実度のデザインカンプでも、同じように処理できます。
Figmaのような高品質なデザインを渡した場合は、ピクセル単位の再現性が高いコードを出力します。
「微妙にボタンの位置がずれる」「余白が全然違う」というような問題が起きにくいのが、実用上は非常に重要なポイントです。
さて、ここからがいよいよ核心です。「どのくらいすごいのか」を数字で見ていきましょう。
GLM-5V-TurboがClaudeを超えた!? ベンチマーク結果を読み解く
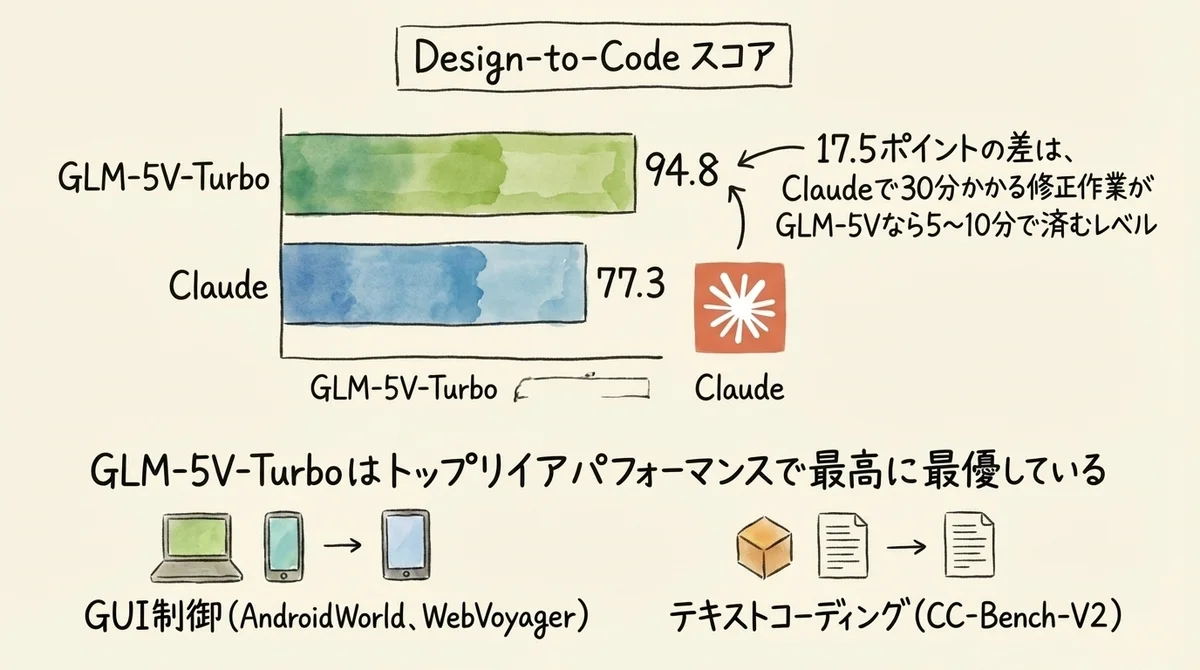
主要4指標でいずれも首位──数値で見る圧倒的な差
ベンチマーク結果を表で見てみましょう。
Design-to-Code指標での差、94.8 vs 77.3。
この数字が何を意味するかっていうと、同じFigmaのスクリーンショットを渡した場合に、GLM-5V-Turboの方がClaudeよりも 17.5ポイントも再現精度が高い ということです。
実際の開発で考えると、Claudeが生成したコードには「まあここは手直しが必要だな」という箇所がそれなりに残るのに対して、GLM-5V-Turboが生成したコードはほぼそのまま使えるレベルに近い、という差感になります。
ざっくり言うと、Claudeで30分かかっていた修正作業が、GLM-5V-Turboなら5〜10分で済むくらいのインパクトだと思ってください。
GUI制御のAndroidWorldとWebVoyagerでもトップクラスの成績を出しているのもポイントで、単純なスクリーンショット→コード変換だけでなく、実際にブラウザやアプリを操作するAIエージェント用途でも強いことを示しています。
テキストコーディング(CC-Bench-V2)でも性能維持
ビジョン特化のモデルあるあるなんですが、「画像は得意だけどテキストだけの指示は苦手」というパターンがあります。
GLM-5V-Turboはこの罠にはまっていません。
CC-Bench-V2というテキストコーディングのベンチマークでも性能を維持しており、「デザイン→コード専用機」ではなく、汎用的なコーディングアシスタントとしても普通に使えます。
ビジョン能力を強化しながらテキスト性能も落とさないというのは、実はかなり難しいことで、この点はしっかり評価されるべきポイントです。
「デザインからコード生成専用」ではなく「普段使いのコーディングAIとしても使える」という汎用性が、乗り換えのハードルを下げています。
ベンチマーク数値の見方と注意点(自社報告の限界)
一点正直に言っておくと、これらのベンチマーク数値はZ.ai(智谱AI)自身が報告しているものです。
自社報告のベンチマークは、有利な条件でテストが行われていたり、比較対象のモデルが最新版でなかったりする可能性があります。独立した第三者機関による検証がまだ十分でないのも事実です。
とはいえ、94.8 vs 77.3という数値差はかなり大きく、多少条件が違っても覆るような差ではないとも思います。
結局のところ、「自分のユースケースで試してみる」のが一番の判断軸です。
後半でchat.z.aiから無料で試す方法を説明するので、まずは自分のFigmaデザインを投げてみて判断してください。
次のセクションでは、モデルの選び方とClaude Codeとの組み合わせ術を紹介します。
GLM-5V-TurboとGLM-5-Turboの違い
テキスト版とビジョン版の使い分け
GLM-5シリーズには複数のモデルがあり、ここが少しわかりにくいポイントです。
GLM-5-Turbo(Vなし)はテキスト特化のモデルで、コーディング・推論・エージェントタスク向けに最適化された高速モデルです。画像入力には対応していません。
GLM-5V-Turbo(Vあり)がビジョン対応モデルで、この記事で紹介している「デザイン→コード変換」ができるのはこちらです。
まとめると:
- デザインカンプやスクショからコードを生成したい → GLM-5V-Turbo
- テキスト指示でのコーディングや高速なエージェントタスク → GLM-5-Turbo
ウェブデザインのコード化という文脈では必ずGLM-5V-Turboを使う必要があります。
Claude CodeやMCP経由での連携活用
ここが個人的に一番ワクワクするポイントなんですが、GLM-5V-TurboはAPIを通じてClaude Codeのワークフローに組み込むことができます。
つまりこういうワークフローが組める:
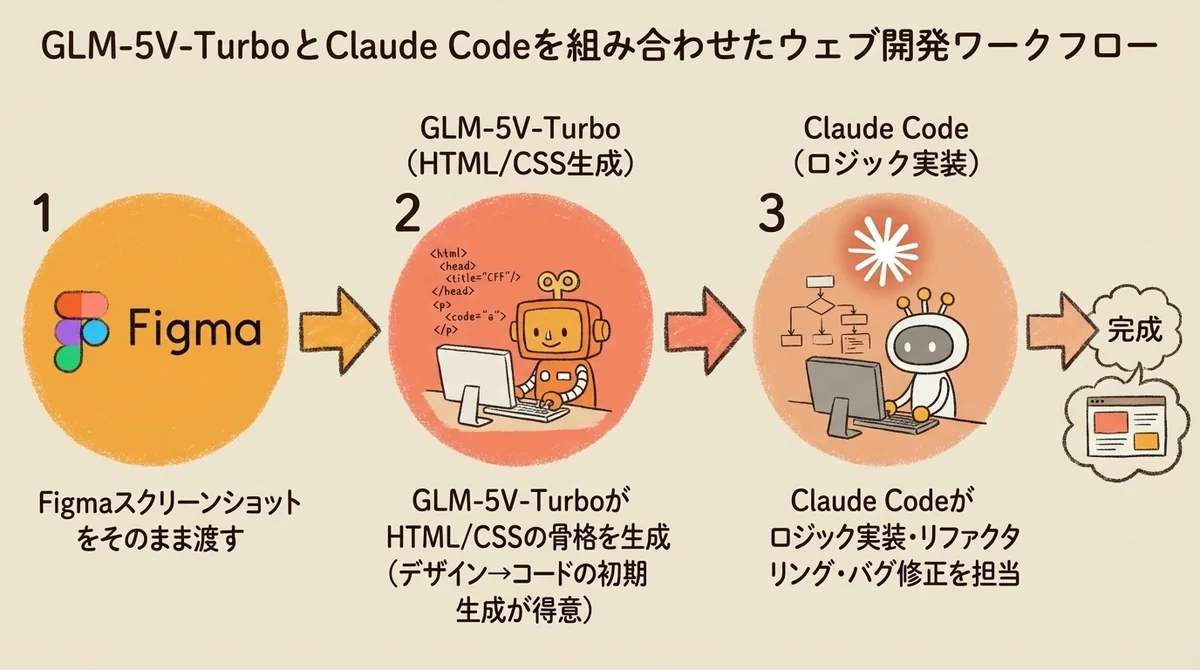
- Figmaのスクリーンショットを GLM-5V-Turbo に渡してHTML/CSSを生成
- 生成されたコードをベースに、ロジックの実装や修正を Claude Code が担当
- 両モデルをAPI経由でシームレスに連携
Claudeのライバルモデルを使ってClaudeのワークフローを強化するという、なんとも逆説的な組み合わせですが、「各モデルの得意なことをやらせる」という考え方は理にかなっています。
Claude Codeで作業中に「このデザインカンプをコード化して」とGLM-5V-Turboに投げるフローを構築できれば、かなり強力な開発環境が作れます。
OpenClawなどのオープンソースエージェントフレームワークでも同様の連携が可能で、エコシステムは着実に広がっています。
無料で試す方法──chat.z.aiとAPIの使い方
chat.z.aiでの無料利用手順
まず手軽に試したい方はchat.z.aiからどうぞ。
- chat.z.ai にアクセス
- アカウント登録(メールアドレスのみでOK)
- チャット画面でモデルを「GLM-5V-Turbo」に切り替え
- 画像アップロードボタンからFigmaのスクリーンショットをアップロード
- 「このデザインをHTML/CSSで実装してください」とプロンプトを送る
無料枠での利用回数制限はありますが、試してみる分には十分です。
まずここで自分のデザインを投げてみて、「おお、これは使える」と思ったらAPIを契約するという流れがおすすめです。
登録からテストまで5分もあれば終わるので、この記事を読み終わったらすぐ試せます。
docs.z.aiでAPIを使うための基本設定
OpenAI互換のAPIを提供しているので、既存のコードからの乗り換えも簡単です。
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_Z_AI_API_KEY",
base_url="https://api.z.ai/api/paas/v4/"
)
# 画像をbase64エンコード
with open("design_screenshot.png", "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="glm-5v-turbo",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_data}"
}
},
{
"type": "text",
"text": "このデザインをHTML/CSSで実装してください。レスポンシブ対応で。"
}
]
}
]
)
print(response.choices[0].message.content)APIキーは docs.z.ai のアカウントページから発行できます。
base_url を https://api.z.ai/api/paas/v4/ に設定するだけで、あとはOpenAIと同じ使い方ができます。既存のOpenAI連携コードをほとんど変えずに試せるのは地味に助かります。
OpenRouter経由でのアクセス方法
OpenRouterを使っている方は z-ai/glm-5v-turbo というモデルIDで利用可能です。
OpenRouterを使えば他のモデルとの切り替えが簡単なので、「Claude 3.7 SonnetとGLM-5V-Turboを比較しながら使いたい」という場合に便利です。
client = OpenAI(
api_key="YOUR_OPENROUTER_API_KEY",
base_url="https://openrouter.ai/api/v1"
)
response = client.chat.completions.create(
model="z-ai/glm-5v-turbo",
# 以降は同じ
)GLM-5V-TurboとClaude Codeを組み合わせたウェブ開発ワークフローへの組み込み方
Figmaスクリーンショットをそのまま渡してみた実践例
実際に試してみた感想を正直にお伝えすると、「思ったよりずっと使える」です。
Figmaで作ったシンプルなランディングページのスクリーンショットを渡したところ、ヘッダー・ヒーローセクション・カード一覧・フッターのHTML/CSSが一発で出てきました。
特に感動したのはCSSのクオリティで、ただ見た目を再現するだけじゃなく、Flexboxを適切に使ったレイアウト構造になっていました。
もちろん完璧ではなく、フォントはシステムフォントにフォールバックされていたり、実際の画像素材が入ってなかったりはします。でも「土台のHTMLとCSSが9割できた状態」から作業を始められるのは、圧倒的に楽です。
今まで「AIにデザインを渡してもそれほど使えるコードが出てこない」と思っていた方は、GLM-5V-Turboで試すと印象が変わるかもしれません。
個人的には「AIコーディングツールの使い方が変わる」レベルの体験でした。
Claude CodeとGLM-5V-Turboを組み合わせる逆転の発想
Claude CodeをメインのコーディングAIとして使っている方への提案です。
Claude Codeは「テキストで指示してコードを書いてもらう」のは非常に強いのですが、デザインカンプからの再現は得意ではありません(ベンチマーク数値でも77.3という結果が出ている通り)。
そこで:
- デザイン→コードの初期生成: GLM-5V-Turboに任せる
- ロジックの実装・リファクタリング・バグ修正: Claude Codeに任せる
という分業体制を組むのが現時点でのベストプラクティスだと思っています。
最初にGLM-5V-TurboでHTML/CSSの骨格を作り、それをClaude Codeのコンテキストに渡してJavaScriptのインタラクションを追加したり、Reactコンポーネントに変換したりする流れです。
Claudeのライバルを使ってClaudeを強化するというのはなんとも面白い話ですが、道具は得意なことに使うのが一番です。
既存のClaudeやGPT-4oと比較した場合の使い分け指針
状況に応じた使い分けをまとめると:
デザイン→コード変換というピンポイントな用途ではGLM-5V-Turboが現時点で最強に近い選択肢ですが、汎用的なコーディングや設計議論ではClaudeやGPT-4oの方が得意な場面も多いです。
まとめ──GLM-5V-Turboはデザイン駆動開発を変えるか
GLM-5V-Turboをひと言で表すと、「デザインからコード生成に特化して磨き込んだマルチモーダルAI」です。
事前学習段階からテキストとビジョンを統合するNative Multimodal Fusionという仕組みにより、ベンチマークでは94.8という数値でClaudeの77.3を大きく上回りました。
「Figmaのスクショを渡すだけでHTML/CSSが出てくる」という体験は、一度やるとデザイン→コーディングの手作業に戻れなくなるくらいのインパクトがあります。
今後は第三者機関による独立したベンチマーク検証や、より複雑なデザインへの対応が進んでいくことに注目しています。
まずは chat.z.ai から無料で試してみてください。
アカウント登録→画像アップロード→プロンプト送信、これだけです。5分あれば今日中に体験できます。
「ベンチマークの94.8って本当なの?」という疑問は、自分のFigmaデザインを1枚渡してみれば、一瞬で答えが出ます。
- 4
- 1

元デザイナー → AI画像職人。絵心ゼロだったけどプロンプト極めたらなんとかなった。「センスじゃない、言語化だ」 使えるプロンプト&失敗例を晒していく




こちらもおすすめ
-
プロンプト画伯
- 2
- 0
-
- 4
- 0
-
コードを読まないAIエンジニア
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0




















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます