
こんにちは。ひでです。
スタートアップ経営の現場で、AIを「参謀」として使い倒している人間の視点で記事を書いています。
「AIユニコーン解体新書」シリーズ、第5弾です。
第1弾(Anthropic)では「安全性を盾に防衛壁を作った兄妹」
第2弾(Perplexity)では「Google検索を真正面から再発明した男」
第3弾(Cognition)では「人材密度を最大の堀にした集団」
第4弾(ElevenLabs)では「個人的怒りを1.6兆円TAMに変換した男」
第5弾(DeepSeek)では「副業+自己資金+オープンソースで巨人を揺らした男」←この記事
第6弾(Sakana AI)では「東京×3人組×逆張りで日本最速ユニコーンになった集団」
第7弾(Suno)では「訴訟を抱えたまま高成長を続ける経営胆力」
第8弾(Figure AI)では「BMW工場に人型ロボットを送り込んだ男の戦略」
今回、シリーズ最大の異色作です。
主役は、中国・浙江省杭州、クオンツヘッジファンドの創業者、そしてAIを「副業」で作った男——梁文鋒(リャン・ウェンフォン)さんです。
会社の名前はDeepSeek(ディープシーク)。生成AIの会社です。
この会社、ちょっと信じられない数字を持っています。
2025年末まで外部資本ゼロ。VCゼロ。自己資金100%。
評価額の話をしようとすると、いきなり前提が崩れます。なぜなら、少なくとも2025年末まで外部投資を一切受けていないので、そもそも「評価額」という概念が成立しなかったからです。
それなのに、世界の株式市場を一晩で揺らした。
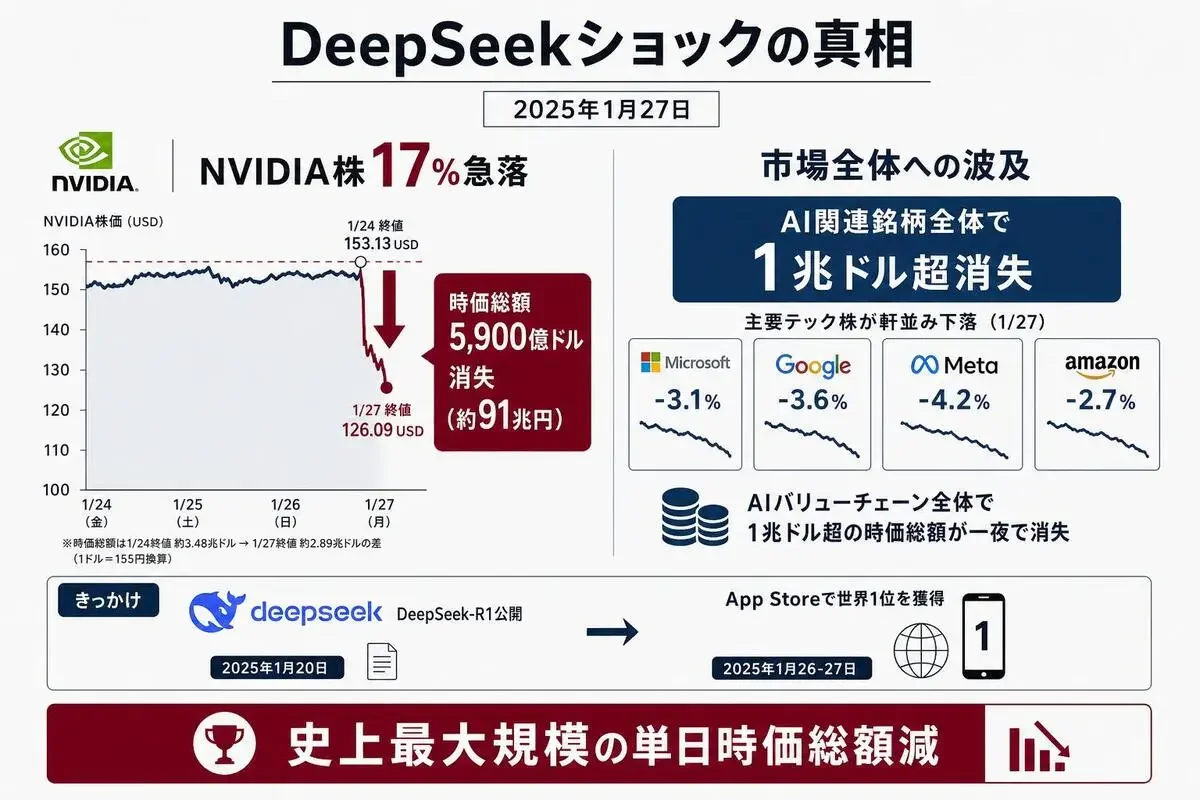
2025年1月27日、DeepSeekが公開した1本のオープンソースモデルが、NVIDIAの時価総額を1日で約5,900億ドル(約91兆円、当時のドル円レートで約92兆円)消し飛ばしました(Bloomberg他複数報道)。
個別企業の単日時価総額減少として、史上最大規模です。
しかも、それを起こした会社は、杭州のヘッジファンドが副業で作ったAIでした。
僕はこのニュースを最初に聞いたとき、「これ、経営学の教科書を書き換える事件だぞ」と感じました。
なぜなら、これまで僕たちが信じてきた「スタートアップの常識」——巨額調達、シリコンバレー一極集中、最先端GPUの大量保有、研究者中心の組織——その全部を否定して、巨人を揺らしているからです。
このシリーズで一貫してやっているのは、「会社」ではなく「人(創業者)」を主役にした分解です。
技術論じゃありません。やるのは戦略論と意思決定論。経営者として持ち帰れる学びにフォーカスします。
それでは始めます。
DeepSeekが一晩でNVIDIA株を約91兆円消した事件の重さ
「なんで自分の業界と関係ない中国のAI企業の話を聞かないといけないんだ」——最初にそう感じた経営者の方、正直だと思います。
でも、この事件を「中国のAIの話」として片付けると、本質を見誤ります。
これは「スタートアップ経営の前提が、たった1本のモデルで崩れた日」の話です。
2025年1月27日、米国の株式市場が開く前から異変が起きていました。
前週末、中国の小さなAI企業が公開したDeepSeek-R1というオープンソースモデルが、AppleのApp Storeで無料アプリ1位を獲得。ChatGPTを抜き去りました。
そして月曜日、市場が開いた瞬間、NVIDIA株が暴落します。
その日の終値で、NVIDIAの時価総額は約5,900億ドル(約91兆円、2026年5月末時点の約155円換算)が消失しました(Bloomberg、CNBC他複数報道)。
個別企業の単日時価総額減少として、史上最大規模です。
この数字、感覚的に掴みにくいですよね。
だから、誰でも知ってる会社と並べてみます。
- 任天堂の時価総額: 約9〜10兆円前後
- ソニーグループの時価総額: 約25兆円前後
- トヨタ自動車の時価総額: 約45兆円前後
- NVIDIAが1日で消した時価総額: 約91兆円
これって、トヨタ2社分です。任天堂なら約9社分。
「1日で消えた金額」が「トヨタを2社まるごと買える額」——これが「DeepSeekショック」の規模感です。
しかも、影響はNVIDIAだけじゃありませんでした。
ブロードコム、ARM、TSMC、Alphabet、Microsoft——AI関連銘柄が連鎖暴落。米国株式市場全体で1兆ドル(約155兆円)超が消えたと試算されています(複数報道)。
つまり、日本の国家予算(年間約100兆円)をゆうに超える資産が、たった1日で消えたということです。
ここが本当にすごいんですよ。
これを起こした会社は、社員数約150人前後、創業から1年半、2025年末まで外部投資ゼロ。中国・浙江省杭州にある「幻方量化(High-Flyer)」というクオンツヘッジファンドが、副業として作ったAI企業——DeepSeekです。
シリーズ前作で扱ったAnthropicは数千億円規模の調達。Perplexityは評価額3.3兆円。CognitionはIOI金メダリスト集団。ElevenLabsは創業4年で1.6兆円。
どれも「資本」「人材」「タイミング」のどれかで圧倒的な強みを持っていました。
DeepSeekは違います。そのどれも持っていない。
VCも入っていない。シリコンバレーにもいない。世界トップクラスの研究者で固めているわけでもない。最新の米国製GPUは輸出規制で手に入らない。
それでも、世界最大のテック企業の時価総額を1日で約91兆円消した。
「で、この会社を作った人間はいったい何者なんだ」——経営者なら必ずそこが気になりますよね。
会社って結局、創業者で全部決まる。事業計画書を読むより、創業者のバックグラウンドを5分調べる方が、その会社の未来は読めると思っていて。
主役の梁文鋒さんがどんな人なのか、ここから掘り下げます。
梁文鋒(リャン・ウェンフォン)とは何者か|DeepSeek創業者の素顔
「シリコンバレー出身じゃないと、世界は変えられない」——経営者なら一度はそう思ったことがあるんじゃないですか。
僕も1社目の頃、そう思っていました。
梁文鋒さんは、その思い込みを根こそぎひっくり返す人物です。
「DeepSeekって、中国のAI会社でしょ?」——名前は知っていても、創業者を知らない経営者の方が大半だと思います。
ここで経営者として正直に言わせてください。DeepSeekを「中国の脅威」とか「OpenAIキラー」で片付けると、本質を見誤ります。
DeepSeekを語る上で絶対に外せないのが、創業者でCEOの梁文鋒(リャン・ウェンフォン、Liang Wenfeng)さんです。
経歴をざっくり時系列で並べると、こんな感じです。
- 1985年、中国・広東省湛江市の小学校教師の家庭に生まれる(浙江省ではない。出身地と本社所在地が違うので注意)
- 地元の高校で「状元」(学年トップ)として浙江大学に進学
- 浙江大学(中国トップ大学の一つ)で情報通信工学を学ぶ
- 修士課程でも浙江大学に在籍、AIを使った金融取引を研究
- 2008年頃から、大学院時代に仲間と共に金融×AIの研究を開始
- 2015〜2016年頃、幻方量化(High-Flyer)を共同創業(クオンツヘッジファンド。前身法人の設立は2015年、現在の社名での法人登記は2016年2月)
- 2023年7月(一部報道では5月)、DeepSeekを設立
ここ、経営者として注目してほしいんですが、梁文鋒さんのキャリアは最初から最後まで「AI×金融」なんです。
研究者として論文を書いてきたわけでもない。シリコンバレーで修行したわけでもない。アメリカの大学を出たわけでもない。
地方都市出身、中国国内の大学だけで学び、ヘッジファンドを共同創業して、その延長線上でAI企業を作った——という、完全に中国国内完結型のキャリアです。
サム・アルトマンさんのようにシリコンバレーの中心にいたわけでもない。ダリオ・アモデイさんのようにOpenAIで研究の最先端を見てきたわけでもない。
それでも、世界の株式市場を揺らせる会社を作った。
ここが、シリーズの過去4作と決定的に違うところです。
広東省湛江の小学校教師の息子から「状元」へ
梁文鋒さんのバックグラウンドで、僕が経営者として一番グッときたのが、「広東省湛江市出身」というポイントです。
湛江って、日本人にはあまり馴染みがないと思うんですが、広東省南部の港町です。中国でいうと「シリコンバレー」じゃなく「地方都市」の位置付け。北京、上海、深センのような大都市とは違います。
そんな地方都市の、小学校教師の家庭に生まれた少年が、地元の高校で「状元」(学年トップ)になり、中国トップ大学の一つである浙江大学に進学した。
これ、日本で例えると、地方の公立高校から東京大学にトップ合格するレベルです。中国の受験戦争を考えると、東大よりさらに厳しい競争を勝ち抜いている。
経営者として注目してほしいのは、「地方出身者の起業」という構図です。
中国のテック企業の多くは、北京、上海、深センといった大都市発です。創業者の多くがエリート都市出身、欧米留学経験あり、海外VCとのコネクションを持つ。
梁文鋒さんは違う。地方出身、国内大学、国内ヘッジファンド出身という、中国国内完結型のバックグラウンドで、世界を揺らした。
これ、日本の地方出身の経営者の方に、めちゃくちゃ刺さるストーリーじゃないですか。
「シリコンバレーに行かないと」「アメリカで修士を取らないと」「海外VCとのネットワークを作らないと」——僕も1社目の頃、そう思っていました。
でも梁文鋒さんは、その「グローバルキャリア神話」を完全に否定している。地元の大学で、地元の仲間と、地元の問題(中国市場での金融取引)から始めて、世界トップに到達できるということを証明している。
ヘッジファンド「幻方量化」を共同創業した経歴
梁文鋒さんのキャリアで、DeepSeekを理解する上で絶対に外せないのが、幻方量化(High-Flyer)の創業です。
幻方量化は2015〜2016年頃に創業された、中国でトップクラスのクオンツヘッジファンド。「クオンツ」というのは、数学・統計・AIを使って金融市場の取引を自動化する手法のことです。
幻方量化の数字を見ると、その規模が分かります。
- 運用資産:約700億元(約1兆4,000億円、2026年1月報道時点、1元=20円換算)
- 2025年の収益率:56.6%(業界2位)
- 中国国内のクオンツヘッジファンドで上位
「年間収益率56.6%」——これ、ちょっと意味を翻訳させてください。
日本の銀行預金が0.001%、株式市場のインデックス投資が年平均7%程度。その中で56.6%というのは、いわばプロ野球で打率5割を叩き出すレベルの異常な数字です。
幻方量化は、AIを使って金融取引で勝ち続けてきた会社なんですよ。
ここで経営者として読み解いてほしいのは、「DeepSeekの研究費は、幻方量化の収益で完全に賄える」という構造です。
運用資産1兆4,000億円、年間収益率56.6%。つまり、収益額だけで年間数千億円規模になります。
DeepSeekの年間運営費は、推定で数億〜数十億円程度。幻方量化の収益のごく一部で、十分に賄える。
これが、DeepSeekが2025年末まで外部投資を1円も受けずに世界トップクラスのAI企業として運営できた理由です。
「AIは副業」という稀有な立場
ここから、シリーズ過去4作と完全に違う話に入ります。
梁文鋒さんにとって、AIは副業なんですよ。
本業は何かというと、幻方量化のクオンツヘッジファンド。AIで金融取引をする会社です。
DeepSeekは、その本業から「派生」して生まれた会社。本業の収益をAI研究に投資して、副産物として生成AIモデルが出来上がった——そういう構造なんです。
これ、シリコンバレーの常識から見ると、完全に「あり得ない」構図です。
普通、AIユニコーンは「AI一本」で勝負します。サム・アルトマンさんも、ダリオ・アモデイさんも、アラビンド・スリニバスさんも、スコット・ウーさんも、マティ・スタニシェフスキーさんも、全員「AI企業のCEO」が本業です。
梁文鋒さんは違う。ヘッジファンドCEOが本業で、AI企業はおまけ。
しかも、その「おまけ」が、世界の株式市場を揺らした。
経営者として、この発想は震えませんか?
僕は1社目を立ち上げたとき、「事業は1本に絞れ」と何人ものメンターに言われました。リソースが分散すると、どっちも中途半端になる、と。
確かに、それは正しいアドバイスです。多くのスタートアップは、本業1本でも回らないんですから、副業まで持ったら確実に潰れる。
でも、梁文鋒さんは違う条件を持っていた。本業(幻方量化)が、すでにケタ違いのキャッシュフローを生んでいる。だから、副業(DeepSeek)に投資し続けられる。
これ、シリーズ前作のElevenLabsで「個人的怒りを事業に変換する」と書いた話と、構造が似ています。違いは、梁文鋒さんは「自社のキャッシュフロー」を、別事業の起爆剤に変換したことです。
人物像が見えてきたところで、本題に入ります。「で、なぜヘッジファンドの男がAI企業を作ろうとしたのか」——ここが、DeepSeekの本質に直結する問いです。
梁文鋒がDeepSeekを作った理由|ヘッジファンドからAIへの決断
「なぜ、うまくいっている事業を持っている人が、わざわざ別の領域でリスクを取るんだ」——経営者なら必ずこの問いが浮かぶはずです。
僕も最初は疑問でした。
ヘッジファンドで年間数千億円の収益を出せているなら、そのまま金融で稼げばいい。なぜ生成AIという未知の領域に踏み込む必要があるのか、と。
「クオンツヘッジファンドの創業者が、なぜ生成AIを作ろうとしたのか」——この問いに答えられるかどうかが、DeepSeekの本質を理解できるかの分かれ目です。
結論から言うと、「中国独自の基盤モデルを作る使命感」と、「制限される前にGPUを大量調達するチャンスを見逃さなかった先読み」の2つです。
米国輸出規制の前に仕込んだH800を2,000枚超——「制限前調達」の先読み
ヘッジファンドの男がAI企業を作る——この決断の背景に、地政学的な先読みがあります。
2022年10月、米国は中国向けに最先端半導体(特にNVIDIAのA100、H100など)の輸出規制を発表しました。
これにより、中国企業は最新のAI訓練用GPUを買えなくなります。AI開発に必須の「基礎体力」が削がれる事態でした。
ところが、幻方量化は規制の前に、すでに大量のGPUを保有していたんです。
なぜか。
幻方量化はクオンツヘッジファンドとして、金融取引の高速計算のためにGPUを大量に必要としていたからです。AI研究のためじゃなく、本業のためにGPUを買い続けていた。
その量、推定で1万枚前後(アナリスト推定値)。
しかも、DeepSeek-V3の訓練に使われたH800(米国向けH100の中国向け廉価版)が2,048枚(DeepSeek公式技術レポート)。
これ、何を意味するか分かりますか?
経営者として翻訳すると、「本業の必要性で買ったインフラが、副業の必殺武器になった」ということです。
いわば、鍛冶屋が鉄を大量に仕入れていたら、戦争が始まって武器商人になれた——みたいな構図です。
シリーズ前作のCognition記事で「IOI金メダリスト集団」が最大の堀になっていると書きました。DeepSeekにとっての堀は、「規制前に合法的に調達したGPUの蓄積」なんですよ。
中国の他のAI企業は、規制以降にGPUを買えなくなって苦しんでいる。DeepSeekだけが、規制前の在庫で世界トップクラスのモデルを訓練できる。
これ、「たまたまラッキーだった」のレベルじゃないんです。梁文鋒さんは、規制の動きを察知していた可能性が高い。
なぜなら、2022年の規制発表前から、幻方量化は数千枚規模のNVIDIA GPUを買い続けていたという報道があるからです(複数報道)。
「将来、AIが規制対象になる可能性が高い。今のうちに、合法的に買えるだけ買っておく」——この判断が、結果としてDeepSeekの世界進出を可能にした。
経営者として、この「規制が来る前に動く」という先読み力は、めちゃくちゃ勉強になります。
「自己資金100%」で運営する哲学——2025年末までの軌跡
「VC調達しない経営って、そんなに正解なの?」——スタートアップ界隈だと、あまり語られない問いです。
梁文鋒さんの経営哲学で、シリーズ過去4作と最も違うのが、「外部投資ゼロ・自己資金100%」の運営スタイルでした。
DeepSeekは2023年の創業から2025年末まで、一度もベンチャーキャピタル(VC)の投資を受けずに運営してきました。
※2026年に入り、中国の国家集積回路産業投資基金(国家大基金)主導の初回外部融資交渉が進行中との報道があります(評価額約450億ドル規模)。ただし2025年末までの「自己資金だけで世界と戦った」という事実は変わりません。
この「VC資金なしで世界トップクラスのAI企業を作った」という事実は、AI業界の常識から見ると、完全に異常です。
AnthropicはGoogle、Amazonから累計約160億ドル超を調達(2026年5月時点の主要報道)。OpenAIはMicrosoftから100億ドル超。Perplexityも数十億ドル規模を調達済み。
DeepSeekは0円。すべて、幻方量化の自己資金で運営してきた。
なぜ梁文鋒さんは外部投資を拒んできたのか。
中国メディア36氪(36Kr)のインタビューで、梁文鋒さん自身がこう語っています。
「お金は問題ではない。問題はチップ(GPU)だ」
これ、すごく大事な発言なんです。
翻訳すると、梁文鋒さんにとっての制約はキャッシュじゃない。GPU調達の物理的制約だけ。
VCから100億円もらっても、その金でGPUが買えないなら意味がない。むしろ、VCから資金を受け入れると、彼らの意向に経営判断を縛られる。
「意思決定の自由を、お金で売り渡したくない」——これが梁文鋒さんの哲学です。
経営者として、これは超重要な視点なんですよ。
僕も1社目で資金調達をしたとき、痛感したことがあります。
VCから出資を受けると、その瞬間から「投資家への説明責任」が発生する。3ヶ月ごとの進捗報告、KPIの達成、次のラウンドの準備——本業の意思決定に、投資家の意向が常に影を落とすようになる。
これが、ある時期から「経営のスピードが落ちる」原因になる。意思決定するたびに、「VCが何と言うか」を考えてしまう。
梁文鋒さんは、最初からこの罠を回避した。自己資金で運営して、外部の意向に縛られない経営判断をしている。だから、コストを度外視した研究投資ができる。短期収益を急がない設計ができる。
シリーズ前作のCognition記事で「採用基準を妥協しない自由」を書きましたが、DeepSeekは別ベクトルで「経営判断を妥協しない自由」を獲得している。
「中国独自の基盤モデル」を作る使命感
最後に、梁文鋒さんの起業動機で重要なのが、「中国独自の基盤モデル」を作る使命感です。
2023年当時、中国のAI企業の多くは、OpenAIのモデルをラッピングしたり、追随する形でモデルを作っていました。「中国版ChatGPT」「中国版GPT-4」と謳う製品が乱立していた。
梁文鋒さんは、この風潮に違和感を持っていました。
36氪のインタビューでこう語っています(要約)。
「中国のAIが世界に追随する立場から抜け出すには、基礎研究で勝負するしかない。応用だけでは、永遠に追随者で終わる」
これ、経営者として震える発言です。
普通、ヘッジファンド出身者なら「短期収益が見込めるBtoBサービスをやる」と判断します。基礎研究は、収益化までの時間が長すぎて、経営判断としてリスクが高い。
でも梁文鋒さんは、「基礎研究で世界に追いつく」という長期視点を選んだ。
これができたのは、外部投資を受けていないからです。VCがいたら、「3年で黒字化しろ」「収益見通しを出せ」というプレッシャーで、基礎研究の長期投資は通らない。
自己資金100%だから、3年、5年、10年の長期視点で意思決定できる。
これ、シリーズ前作のAnthropic記事で「Constitutional AIという基礎研究で防衛壁を作った」と書いた話と、構造は似ています。違いは、Anthropicは投資家を説得して長期研究を実現したのに対し、DeepSeekは投資家不在で長期研究を実現したことです。
起業動機と先読みが見えたところで、いよいよプロダクトの中身です。ここからが、正直一番面白いんですよ。「DeepSeekって結局、何ができるの?」「なぜ安いの?」——経営者として一番気になるはずです。
DeepSeek V3とR1の正体|「OpenAIの1/10コスト」の真実
「うちはAI使うにしても、まあOpenAIでいいかな」——そう思っていた経営者の方、ちょっと待ってください。
この章を読んだら、その判断が変わるかもしれません。
「DeepSeekって、ChatGPTより安いんでしょ?」——経営者の方からよく聞かれます。
半分合ってます。でも、それだけだと「すごさ」が伝わらない。
結論から行きます。
訓練コスト約557万ドルの真実——「公式論文記載の数値」の意味
DeepSeekで最も衝撃的な数字が、訓練コスト約557万ドル(約8.6億円、1ドル155円換算)です。
GPT-4の訓練コストが推定100億ドル超(諸説あり)と言われている中で、約1/2,000の費用で、ほぼ同等性能のモデルを作った——これがDeepSeekショックの引き金になった数字です。
つまり、「同じ料理を、食材費が2,000分の1で作った」みたいな話です。
ただし、ここで経営者として正確に理解してほしいことがあります。
この約557万ドルという数字は、DeepSeek-V3の「GPU前訓練費用のみ」なんです(DeepSeek公式技術レポート)。
具体的には、
- H800(中国向けGPU)を2,048枚使用
- 訓練期間:約2ヶ月
- GPU時間ベースのレンタル換算で約557万ドル
これだけです。
実際にDeepSeekを運営するには、これ以外に以下のコストがかかっています。
- GPU本体の購入費用(規制前に保有していた在庫)
- 研究者・エンジニアの人件費
- データセンターの運営費
- R&Dの試行錯誤コスト
- 過去のモデル(V1、V2、V2.5など)の開発費
これらを全部足すと、DeepSeek全体のインフラ・R&Dコストは累計で13億ドル超との試算もあります(SemiAnalysis報告)。
つまり、「557万ドルでChatGPT並みのAIを作った」という見出しは、技術的には正しいけれども、ビジネス全体のコストを反映していない。
ここを正確に理解した上で、経営者として注目してほしいのは、それでも「OpenAIの研究コストよりケタ違いに安い」という事実です。
OpenAIの2024年の研究開発費は推定数十億ドル規模、Anthropicも年間数十億ドル規模。DeepSeekは数十分の1の予算で、ベンチマークでOpenAIに迫る成果を出している。
経営者として翻訳すると、「予算がOpenAIの数十分の1でも、技術選択次第で同等の性能を出せる」ということです。
「なぜ安いか」の構造——MoE・MLA・FP8量子化という工夫
「DeepSeekはなぜそんなに安く作れたのか」——これ、技術論を抜きにして経営者向けに翻訳します。
DeepSeekは、大きく3つの技術的工夫でコストを下げました。
工夫1:MoE(Mixture of Experts)アーキテクチャ
これは、「全部のパラメーターを毎回使うんじゃなく、必要な専門家(Expert)だけを起動する」という仕組みです。
料理に例えると、和食・中華・洋食・フレンチ・イタリアン全部のシェフが厨房にいるけど、和食の注文が来たときは和食シェフだけが動く——みたいなイメージ。
これにより、モデル全体のサイズは大きくても、実際の計算コストは小さく抑えられる。
工夫2:MLA(Multi-head Latent Attention)
これは、「過去の会話履歴を圧縮して効率的に扱う」という仕組みです。長い会話でも、メモリ使用量を大幅に削減できる。
工夫3:FP8量子化
これは、「通常16ビットで表現する数値を、8ビットで表現する」というテクニック。データサイズが半分になるので、計算速度と省メモリの両方を実現できる。
これら3つを組み合わせることで、DeepSeekは「性能を維持しながら、計算コストを大幅に削減」した。
これ、経営者として何を意味するか。
「制約があるから、効率化のイノベーションが生まれた」ということなんです。
DeepSeekには、最新のH100が使えないという制約があった。だから、限られた性能のH800で最大の効果を出すために、技術的な工夫を積み重ねた。
逆に、潤沢にH100を持っているOpenAIやAnthropicは、効率化への切迫感がない。だから、「とにかく規模を大きくして殴る」アプローチに振りやすい。
シリーズ前作のElevenLabs記事で「個人的怒りが事業の起爆剤になる」と書きました。DeepSeekは、「制約が技術革新の起爆剤になる」ことを証明している。
経営者として、これは超勉強になる発想なんですよ。
「リソースが足りない」「予算がない」「人手が足りない」——これらの制約は、普通は経営者にとって悩みのタネです。
でも、制約があるからこそ、効率化の工夫が生まれる。制約がない競合より、結果として強くなれる。
「制約は敵じゃない。設計条件だ」——梁文鋒さんから僕が一番盗みたい思考です。
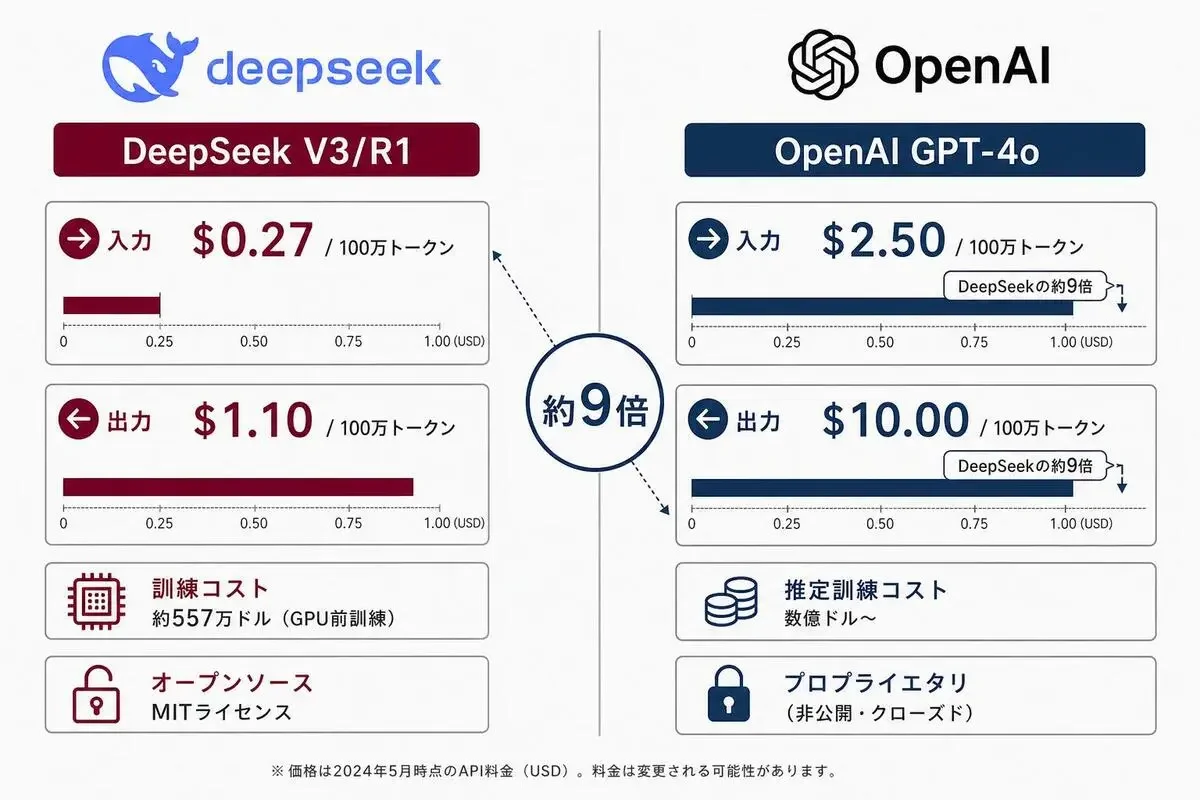
API料金がOpenAIの約9〜36倍という事業構造
ビジネスモデルの話に行きます。
DeepSeekの料金体系は、OpenAIと比べて圧倒的に安いです。
具体的な数字を見ると(2026年5月時点、DeepSeek公式サイト)、
- DeepSeek-V3:入力100万トークンあたり0.27ドル(約42円)、出力1.10ドル(約170円)
- DeepSeek-R1:入力100万トークンあたり0.55ドル(約85円)、出力2.19ドル(約340円)
これに対し、
- OpenAI GPT-4o:入力100万トークンあたり2.50ドル(約390円)、出力10.00ドル(約1,550円)(2026年5月時点 OpenAI公式)
- OpenAI o1:入力100万トークンあたり15ドル(約2,325円)、出力60ドル(約9,300円)
DeepSeekは、OpenAI GPT-4oに対して入力で約9倍、出力で約9倍安い料金で、同等のベンチマーク性能を提供しています。o1と比較すると最大30倍以上の差があります。
これ、経営者として翻訳すると、
「AI APIで月100万円使っていた会社が、DeepSeekに切り替えると月10〜30万円で済む」
という話です。
しかも、この価格は「セール」じゃありません。通常料金です。
なぜDeepSeekはこんな安値で出せるのか。
理由は2つ。
理由1:訓練コストが安い
前述の通り、MoE・MLA・FP8量子化で計算コストを抑えている。推論時の計算コストも低いので、安く提供できる。
理由2:「収益化を急がない」哲学
DeepSeekは外部投資を受けていないので、VCに「早く黒字化しろ」と言われない。だから、利益率を犠牲にしてでも、市場シェアを取りに行ける。
「安く提供して、まず使ってもらう。収益化は後で考える」——これが、自己資金100%だからこそできる戦略なんです。
シリーズ前作のCognition記事で「Devinの単価が高い理由」を書きました。DeepSeekは正反対の戦略で、「単価を圧倒的に下げて、市場を一気に取りに行く」戦略を選んでいる。
MITライセンスでオープンソース——戦略の中核
DeepSeekで、もう一つ経営者として絶対に押さえてほしいのが、MITライセンスでのオープンソース化です。
DeepSeek-V3もR1も、モデルの重み(weights)が完全に公開されているんですよ。MITライセンスというのは、「商用利用OK、改変OK、再配布OK」という、ほぼ制約のないオープンライセンスです。
これ、AI業界の常識から見ると、めちゃくちゃ異常です。
OpenAIのGPT-4も、AnthropicのClaudeも、Googleのモデルも、全部クローズドソース。モデルの中身は社外秘で、APIを通じてしか使えない。
DeepSeekは違う。自社の最強モデルを、全部タダで公開している。
「なんでそんなアホみたいな戦略を取るんだ」と思いますよね。
でも、これが梁文鋒さんの戦略の核心なんです。
オープンソース化することで、何が起きるか。
- 世界中の開発者がDeepSeekモデルを使い始める
- 派生モデル(fine-tuning版)が大量に生まれる
- DeepSeekの「技術スタンダード」が業界に広がる
- 結果として、DeepSeekがAI業界の「インフラ」になる
これ、Linuxがクラウドサーバーの90%以上を占めているのと同じ構造なんですよ。
Linuxは無料で配布されたから、世界中のサーバーで使われるようになった。結果として、Red Hatのような周辺サービス会社が大儲けする構造ができた。
DeepSeekも同じ構造を狙っている。モデル本体は無料で配布して、API利用や派生サービスで収益化する。
経営者として、この「無料で配布して、市場のスタンダードを取りに行く」戦略は、めちゃくちゃ強い。
なぜなら、競合(OpenAI、Anthropic)が真似できないからです。彼らはVCからの投資を回収する必要があるので、有料モデルを手放せない。
DeepSeekは外部投資がないから、無料化できる。外部投資を取らなかったからこそ、オープンソース化という最強の戦略が選べたわけです。
プロダクトの中身が見えたところで、ここからが経営者として本当に面白い話になります。梁文鋒さんの戦略——「コスト破壊×制約活用×オープンソース」の3点セットを、経営戦略として丸ごと解剖します。
梁文鋒の戦略|「コスト破壊×制約活用×オープンソース」で巨人を揺らす
「DeepSeekって戦略が面白いらしいけど、うちと規模が違いすぎて参考にならないかな」——そう感じた経営者の方、この章を最後まで読んでから判断してください。
規模は関係ありません。発想の構造が、そのまま自社の戦略に使えます。
「DeepSeekは安いし、オープンソースだし、すごいね」で終わらせないために、経営戦略として分解します。
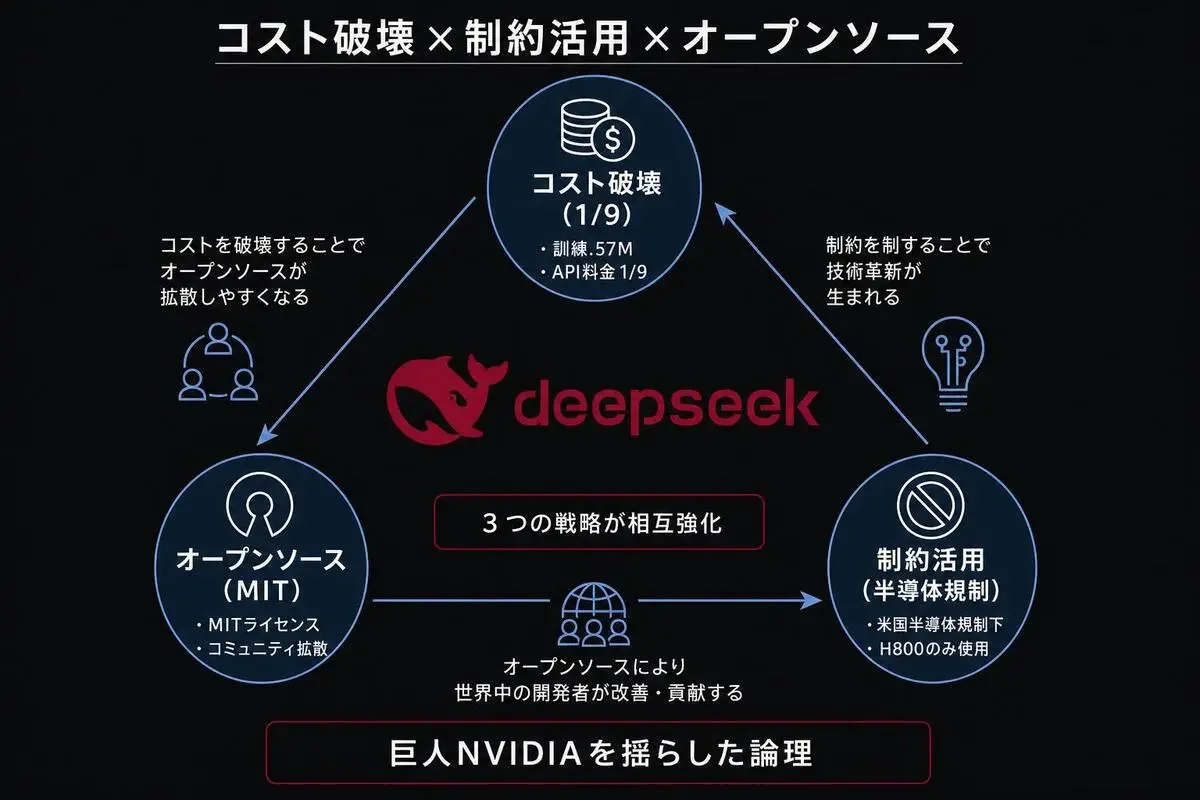
梁文鋒さんがやっているのは、シンプルに言うと3つの戦略の組み合わせです。
- 戦略1:コスト破壊(OpenAIの1/9〜1/30以上の料金)
- 戦略2:制約活用(H100が使えないことを技術革新の起爆剤に)
- 戦略3:オープンソース(MITライセンスで全公開)
この3つが有機的に組み合わさっていることが、DeepSeekの本当の強さです。
BMCで読み解くDeepSeekのビジネスモデル
ビジネスモデルキャンバス(BMC)で整理すると、DeepSeekの戦略の妙が見えてきます。
ここで一番見てほしいのが、「収益源」と「主要パートナー」の関係です。
普通のスタートアップは、外部投資家が「主要パートナー」に入ります。DeepSeekは違う。幻方量化(親会社)だけがパートナー。
これが意味することは、DeepSeekは、収益を急ぐ必要がないということです。
幻方量化のヘッジファンドが年間数千億円規模のキャッシュフローを生んでいる。その一部がDeepSeekの研究費に回ってくる。だから、API利用料が安くても、研究を続けられる。
経営者として読み解いてほしいのは、「事業の収益化スピードと、研究開発の長期視点のバランス」です。
普通のスタートアップは、3年以内に黒字化しないと潰れます。だから、短期収益化を急ぐ。
DeepSeekは、親会社のキャッシュフローが研究開発を支えるので、5年、10年の長期視点で意思決定できる。
これ、日本の老舗大企業に近い構造なんですよ。トヨタのR&D部門が、本業(自動車販売)のキャッシュフローで支えられて、長期視点で研究できるのと同じ構造です。
DeepSeekは、「スタートアップの機動性」と「大企業の長期視点」を両立している。これが、競合(OpenAI、Anthropic)にとって最も脅威的な特徴です。
制約を逆手に取るイノベーション——半導体規制が生んだ「効率化の強制」
戦略の核として、もう一つ深掘りしたいのが、「制約活用」です。
米国の半導体輸出規制で、中国企業は最新のH100が使えない。これは、AI開発における「物理的なハンディキャップ」です。
普通の経営者なら、この制約に対して「不利だ」「不公平だ」と嘆くか、規制の抜け道を探すか、撤退するかのどれかでしょう。
梁文鋒さんは違いました。制約を「設計条件」として受け入れ、それを前提に最適化した。
具体的には、
- H800(H100の中国向け廉価版)でも訓練できるアーキテクチャを設計
- メモリ効率を上げるためにMLA技術を開発
- 計算量を減らすためにMoEアーキテクチャを採用
- データ量を削減するためにFP8量子化を導入
これら全部、「H100が使えない」という制約があったから生まれた技術なんです。
逆に、H100を潤沢に持っているOpenAIやAnthropicは、こうした効率化への切迫感がない。「とにかく規模を大きくして殴る」アプローチで来ている。
結果として、DeepSeekは「1/9以下のコストで、同等性能」を実現した。
これ、経営者として超重要な発想なんですよ。
「制約は、イノベーションの母」——よく言われる言葉ですが、DeepSeekはこれを実証した。
応用例を考えると、
- 「予算が足りない」→ クラウドコスト最適化のイノベーション
- 「人手が足りない」→ AI自動化のイノベーション
- 「時間が足りない」→ プロセス効率化のイノベーション
- 「市場が小さい」→ ニッチ特化のイノベーション
中小企業・スタートアップが大企業に勝てるのは、「制約があるから工夫せざるを得ない」という構造があるからです。
梁文鋒さんを見て、自社の制約を「設計条件」として捉え直してみてください。
オープンソースは防衛ではなく攻め——エコシステム構築こそが真の競争優位
最後に、戦略の核として「オープンソース」の意味を、経営者向けに掘り下げます。
普通、オープンソースは「コミュニティ貢献」「社会的善行」として語られます。
でも、梁文鋒さんのオープンソース戦略は、完全に攻めの経営判断なんですよ。
オープンソース化することで、何が起きるか。
効果1:競合のAPI事業を陳腐化させる
OpenAIのGPT-4が月100万円かかるなら、DeepSeekを無料でダウンロードしてセルフホストすれば、月数万円で同等性能が得られる。これにより、OpenAIの「API課金モデル」が成立しにくくなる。
効果2:開発者コミュニティが自社の技術スタンダードを広める
世界中の開発者がDeepSeekを使ってfine-tuningし、派生モデルを作る。その派生モデルがHugging Faceなどに公開され、DeepSeekの技術スタンダードが業界全体に広がる。
効果3:エンタープライズ採用の障壁を下げる
「クローズドソースのOpenAIは情報漏洩が心配」「自社データを送るのに抵抗がある」という大企業が、オープンソースのDeepSeekを自社サーバーで動かせる。これにより、コンプライアンスが厳しい業界(金融、医療、政府)への浸透が一気に進む。
効果4:競合の優秀な研究者を引き寄せる
研究者は「自分の成果が世界に公開される」ことを好む。クローズドソースの会社では論文も出せないが、オープンソースのDeepSeekでは自由に研究できる。結果として、優秀な研究者が集まる。
これ、めちゃくちゃ巧妙なんですよ。
オープンソース化は、短期的には収益を放棄する選択です。でも、長期的には市場の支配権を取れる戦略です。
ただし、これができるのは「外部投資を受けていない」会社だけです。VCが入っていたら、「収益機会を捨てるな」と反対される。
外部投資ゼロという出発点が、オープンソースという最強戦略を可能にした——これがDeepSeekの構造的優位性です。
シリーズ前作で扱った4社(Anthropic、Perplexity、Cognition、ElevenLabs)は、全部クローズドソースのモデルか製品を持っています。VCから巨額調達しているから、収益化を急ぐ必要があるからです。
DeepSeekだけが、自己資金100%という出発点があったからこそ、オープンソースで攻めの経営ができている。
戦略の全体像が見えたところで、いよいよあの事件の核心に踏み込みます。なぜ、たった1本のオープンソースモデルが、NVIDIA株を一晩で約91兆円消したのか——その因果を丸ごと分解します。
一晩でNVIDIA株91兆円消失|DeepSeekショックの真相
「株式市場の話は経営者には関係ない」——そう思った方、ちょっと待ってください。
この事件は株価の話じゃありません。自分の業界の「前提」が一夜にして崩れるという、経営者全員に刺さるリスクの話です。
「DeepSeekショック」——この事件、経営者として絶対に深く理解しておくべき出来事です。
なぜなら、これは「AIインフラ業界全体の前提が、たった1本のモデルで揺らいだ」歴史的な事例だからです。
時系列で振り返ります。
2025年1月20日〜27日——DeepSeek-R1公開から株式市場崩壊までの1週間
- 2025年1月20日:DeepSeek-R1(推論特化型モデル)が公開、MITライセンスでオープンソース化
- 1月20日〜24日:開発者コミュニティで急速に話題に。「OpenAI o1と同等性能、しかも無料」と評判が広がる
- 1月26日〜27日:DeepSeekのアプリが米国App Store無料アプリ1位を獲得、ChatGPTを抜き去る
- 1月27日(月曜):米国株式市場が開いた瞬間、NVIDIA株が暴落
この数日間で、世界の認識が一気に変わったんです。
「AIモデルの開発に、これまで言われてきたような巨額のGPU投資は必要ないかもしれない」と。
これがNVIDIA株暴落の引き金です。
「AIインフラ過剰投資論」の台頭——GPU需要前提が崩れた瞬間
経営者として、なぜNVIDIA株が暴落したかを、構造的に理解しておく必要があります。
NVIDIAの株価は、「AI企業がGPUを大量に買い続ける」という前提で成り立っていました。
具体的には、
- OpenAI、Anthropic、Google、Microsoft、Meta などの大手AI企業が、毎年数兆円規模のGPUを購入
- AI市場が拡大するほど、GPU需要も拡大
- NVIDIAの売上は、AI市場の成長と完全にリンクしている
この前提があるから、NVIDIAの時価総額は3兆ドル超まで膨らんだ。
DeepSeekは、この前提を真正面から否定しました。
- 「H800という旧型GPUでも、最先端モデルが作れる」
- 「MoE・MLA・FP8で、計算コストを大幅に削減できる」
- 「557万ドルでGPT-4並みのモデルが作れる」
つまり、「これまでAI企業が買っていた最新GPUは、本当に必要だったのか?」という疑問が、市場全体に広がった。
「もしDeepSeekの手法が広まれば、AI企業はもっと少ないGPUで済むかもしれない」「NVIDIAの今後のGPU売上見通しが、過大評価されているかもしれない」——投資家がそう考えた瞬間、株価が暴落した。
これ、経営者として超重要な視点なんですよ。
「市場の前提を覆す技術が公開された瞬間、その前提に乗っていた企業の評価が一気に崩れる」——これがDeepSeekショックの本質です。
シリーズ前作のPerplexity記事で「Googleの広告モデルが陳腐化する可能性」を書きました。DeepSeekは、NVIDIAのGPU販売モデルが陳腐化する可能性を、世界に示してしまった。
NVIDIAだけじゃない——ブロードコム・ARM・Alphabetまで連鎖した理由
DeepSeekショックは、NVIDIAだけじゃありませんでした。AI関連銘柄が広く連鎖暴落しました。
具体的には、
- NVIDIA:1日で約5,900億ドル(約91兆円)の時価総額消失
- ブロードコム(半導体):1日で約2,500億ドル超下落
- TSMC(半導体製造):大幅下落
- ARM(チップ設計):大幅下落
- Alphabet(Google親会社):大幅下落
- Microsoft、Meta:大幅下落
合計で、米国株式市場全体から1兆ドル超(約155兆円)が消失したと試算されています。
なぜここまで広く影響したか。
理由は、「AIインフラ業界全体の収益見通しが、一気に下方修正された」からです。
- GPU需要が減れば、GPU設計のARMも売上減
- GPU生産量が減れば、半導体製造のTSMCも売上減
- AIインフラ投資が減れば、データセンター需要も減
- AIモデルが安く作れるなら、Alphabet・MicrosoftのAIサービス料金も下がる
- 結果として、AI企業全体の収益見通しが下方修正
これが、わずか1本のオープンソースモデルが起こした「ドミノ倒し」です。
経営者として、これは超勉強になる視点なんですよ。
「業界の前提を覆す技術が出ると、その業界のサプライチェーン全体が一気に評価変動する」——これ、AI業界に限らず、全ての業界で起きうる現象です。
ジェンスン・フアンさん(NVIDIA CEO)も、後にこのDeepSeekショックについてコメントしています。「DeepSeekは素晴らしい技術で、世界中の開発者にとって良いニュースだ」と公式にはポジティブに反応していますが、市場の評価は別物でした。
米国テック巨人の「AI戦略見直し」が始まった
DeepSeekショックは、株価の話だけで終わりませんでした。
米国のテック巨人各社が、自社のAI戦略を全面的に見直す契機になりました。
具体的には、
- Microsoft:AzureでDeepSeekモデルをホスト開始(2025年2月発表)
- AWS:BedrockでDeepSeekモデルを利用可能に
- Meta:自社のLlamaモデルの開発方針見直しを発表
- Google:オープンソース戦略の強化を検討
「もう、自社でクローズドソースのモデルを作り続けても勝てないかもしれない」——この危機感が、テック巨人を動かした。
これ、経営者として震えませんか?
中国・杭州のヘッジファンド副業AI企業が、シリコンバレーの巨人たちの戦略を、たった1本のオープンソースモデルで動かしてしまった。
シリーズ前作のCognition記事で「巨人が組織DNA的に追いつけない領域に陣を構える」と書きました。DeepSeekは、巨人を「自社の戦略の根本」から揺さぶったんです。
DeepSeekショックの全貌が見えたところで、最後に経営者として一番大事なパートに入ります。「で、あなたの会社で何ができるか」——これがこの記事の本丸です。
DeepSeekから経営者が学ぶ3つのこと
「すごいのは分かった。でも、うちの会社に関係あるの?」——それが正直なところだと思います。
関係あります。めちゃくちゃ。
「DeepSeekすごいね」で終わらせないために、自分の会社の意思決定に持ち帰れる学びを3つに整理しました。
経営者同士の飲み会だったら、ビール片手に話す内容です。難しく考えないでください。
示唆1:「制約は設計条件」と捉え直すと、競合より強くなれる
梁文鋒さんが世界を揺らせた最大の理由は、「制約を設計条件として受け入れた」ことです。
米国の半導体規制で、最新GPUが使えない。普通の経営者なら「不利だ」「不公平だ」と嘆く。
梁文鋒さんは違った。「H100が使えないなら、H800で最大の効果を出す方法を考える」と発想を切り替えた。
結果として、MoE・MLA・FP8量子化という効率化技術が生まれ、コスト約1/9で同等性能を実現した。
経営者として持ち帰ってほしいのは、「自社の制約を、競争優位の源泉として再定義する」発想です。
僕の1社目では、創業期に「人手が足りない」「予算がない」「時間がない」を、ずっと「悩み」として捉えていました。
でも振り返ると、それらの制約があったから、業務効率化のイノベーションが生まれた。SaaS導入のスピードが速くなった。アウトソースの判断が的確になった。
逆に、シリーズBで資金調達して「リソースに余裕ができた」瞬間から、組織が緩んで意思決定が遅くなった経験があります。
制約があるうちが、一番強い——これ、スタートアップ経営の真理だと思っています。
応用例を考えると、
- 「広告予算が足りない」→ オーガニックSEO・PRに振り切る → 結果として持続可能な集客基盤ができる
- 「エンジニアが採用できない」→ ノーコードツール・AIで業務を回す → 結果として固定費が下がる
- 「営業人員が足りない」→ プロダクトの自助力(マニュアル不要のUX)を磨く → 結果としてPLG(プロダクト主導成長)が実現
- 「市場が小さい」→ ニッチに特化して圧倒的シェアを取る → 結果として参入障壁が高くなる
あなたの会社の「制約」を、一度書き出してみてください。 それを「悩み」じゃなく「設計条件」として捉え直したら、どんな戦略が描けるか。
これ、めちゃくちゃ刺激的な思考実験です。
示唆2:オープンソースは「収益放棄」ではなく「市場支配」の戦略
2つ目の示唆は、もっと事業設計レベルの話です。
梁文鋒さんがDeepSeekで証明したのは、「無料で配布することが、最大の収益化につながる」という逆説です。
普通の経営者なら、「自社の最強プロダクトを無料公開するなんて、収益を捨てる狂気だ」と判断する。
でも梁文鋒さんは、オープンソース化することで、市場のスタンダードを取りに行った。
なぜこれが強いかというと、「市場のスタンダードを握った会社が、長期的に最大の収益を得る」からです。
Linuxは無料で配布されたから、世界のサーバーの90%以上で使われている。結果として、Red HatやUbuntu(Canonical社)のような周辺サービス会社が大儲けする構造ができた。
Androidも無料で配布されたから、世界のスマホの70%以上で使われている。結果として、Googleが広告収益で大儲けする構造ができた。
DeepSeekも同じ構造を狙っている。モデル本体を無料で配布して、API利用、エンタープライズサポート、カスタマイズサービスで収益化する。
経営者として持ち帰ってほしいのは、「自社の何を無料化すれば、市場のスタンダードを取れるか」という発想です。
応用例を考えると、
- 自社のコアプロダクトの「ベーシック版」を無料化 → 有料の「プロ版」「エンタープライズ版」で収益化
- 自社のノウハウを書籍・ブログで無料公開 → コンサルティング・研修で収益化
- 自社のソフトウェアをOSS化 → サポート契約・カスタマイズで収益化
- 自社のデータをAPIで無料提供 → 大量利用時のEnterprise契約で収益化
中小企業・スタートアップで「無料化なんて、収益を捨てる狂気だ」と思っている経営者の方、オープンソースは「収益放棄」じゃなく「市場支配の投資」だという視点で見直してみてください。
シリーズ前作のCognition記事で「『役割』を売ると単価がケタ違いになる」と書きました。DeepSeekは、「無料化することで、業界のスタンダードを握る」ことを証明している。
どちらも、「売っているものの単位」「収益化のタイミング」を再発明するという意味で、共通の発想です。
示唆3:本業のキャッシュフローは、副業スタートアップの最強の武器になる
3つ目は、経営の哲学レベルの話です。
DeepSeekの最大の特徴は、「副業で作られた」ことです。
梁文鋒さんの本業はヘッジファンド経営。AIは副産物。それでも、世界の株式市場を揺らせる会社になった。
これ、経営者として超重要なメッセージなんですよ。
「1つの事業を本業として持ち、そのキャッシュフローで別の事業に投資する」——これ、AI時代のスタートアップ経営の新しい型かもしれません。
これまで20年間、スタートアップの常識は「1つの事業に全リソースを集中させる」でした。VCも「1点突破」を求める。
でも、AIが事業領域を越境させる時代になって、状況が変わってきています。
- 製造業の会社が、自社の生産データを使ってAI事業を始める
- 小売業の会社が、自社の顧客データを使ってAIマーケ事業を始める
- 金融業の会社が、自社の取引データを使ってAI投資事業を始める
- 医療機関が、自社の診療データを使ってAI診断事業を始める
これら全部、「本業のキャッシュフローと、本業で蓄積したデータを、AI事業の起爆剤にする」モデルです。
DeepSeekがやったことを、自社で再現するには、以下のステップが考えられます。
- 自社の本業で安定したキャッシュフローを作る
- 本業の延長線上にあるAI事業を、副業として小さく始める
- VC調達せず、本業のキャッシュフローで研究開発を続ける
- 短期収益化を急がず、技術的優位性に集中する
- ある段階で、その副業が本業を超える規模に成長する
これ、日本の中堅・中小企業にとって、めちゃくちゃ現実的な戦略なんですよ。
日本には、自社で長年蓄積してきたドメイン知識・顧客データを持つ会社がたくさんあります。
それを「本業のオマケ」のままにしておくのか、「DeepSeek式の副業AI企業」として育てるのか。
あなたの会社、本業のキャッシュフローを「副業AI事業」に投資する設計、できていますか?
これ、できるかどうかが、今後10年の経営判断を決めます。
シリーズ前作のElevenLabs記事で「個人的怒りを事業にする」と書きました。DeepSeekは、「本業のキャッシュフローを別事業の起爆剤にする」という、また別のスタートアップ起源を示している。
スタートアップの作り方は、もはや「シリコンバレー型のVC調達一択」じゃない。多様な起業の型が、AIによって解放されつつあります。
で、意思決定は?
ここまで読んでくださった経営者の方に、最後に問いを置かせてください。
あなたの会社の「制約」を、「悩み」じゃなく「設計条件」として書き出せますか? それを起点に、競合より強くなれる戦略を描けますか?
あなたの会社が「無料化」できる資産は何ですか? それを無料化することで、業界のスタンダードを取りに行く設計はできますか?
あなたの会社の本業のキャッシュフローを、「副業AI事業」に投資する設計はありますか? それとも、本業1本に絞ったままですか?
梁文鋒さんがやったことを「すごい話」で終わらせないために、この3つを経営の意思決定に持ち帰ってほしいんです。
DeepSeekの次へ|AIユニコーン解体新書 次回予告
ここまでお付き合いありがとうございました。
「AIユニコーン解体新書」シリーズ、これまでに5社見てきました。
- 第1弾:Anthropic(アモデイ兄妹)——「安全性で防衛壁を作る戦略」
- 第2弾:Perplexity(アラビンド・スリニバスさん)——「巨人の本丸を真正面から再発明する戦略」
- 第3弾:Cognition(スコット・ウーさん)——「人材密度を最大の堀にする戦略」
- 第4弾:ElevenLabs(マティ・スタニシェフスキーさん)——「個人的怒りを1.6兆円TAMに変換する戦略」
- 第5弾:DeepSeek(梁文鋒さん)——「副業+自己資金+オープンソースで巨人を揺らす戦略」
5社とも戦略のベクトルが違いますが、共通点があります。「巨人が組織DNA的に追いつけない領域に最初に陣を構える」ことです。
そして今回、DeepSeekで新しく加わった視点は、「シリコンバレーの常識(巨額VC調達、最先端GPU、エリート研究者)を全部否定しても、世界を揺らせる」ということです。
これ、日本の経営者にとって、めちゃくちゃ重要なメッセージなんですよ。
「日本からAIユニコーンが出るか」という議論がよくありますが、DeepSeekを見ると「型は1つじゃない」ということが分かります。
VC調達せずに、本業のキャッシュフローで研究開発を続ける——これは、日本の中堅・中小企業が一番得意な経営スタイルです。むしろ、シリコンバレー型より日本企業の方が向いているかもしれません。
次回は、AI×研究という別ベクトルで世界を変えようとしている、Sakana AI(サカナAI)の共同創業者デビッド・ハさんを解剖する予定です。
「Google Brainの元研究者が、なぜ東京で会社を立ち上げたのか」を、経営者目線で深掘りします。
このシリーズは「AIユニコーン解体新書」タグでまとめていきます。気になる方はぜひ追いかけてください。
経営の意思決定にAIを活用する具体的なテクニックや、スタートアップ向けのAI戦略については、私が連載しているAimanaVoで他にも記事を書いています。よかったらプロフィールから他の記事も覗いてみてください。
それでは、また次回。
- 1
- 0

元大手コンサル→スタートアップCEO。AIを経営の参謀として活用し、競合調査・市場分析・事業計画のドラフトをAIに任せて意思決定に集中するスタイル。2社目立ち上げ中。経営者目線でAI導入のリアルを発信します。




こちらもおすすめ
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 7
- 0
-
AI経営者の参謀@ひで
- 8
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 4
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI集客@ルイ
- 3
- 0
-
AI経営者の参謀@ひで
- 4
- 0
-
AI経営者の参謀@ひで
- 4
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI経営者の参謀@ひで
- 1
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI集客@ルイ
- 3
- 0

















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます