
こんにちは。
仕様書を書かないPM@カイです。
AimanaVo(エーアイマナボ)でAIとプロダクトマネジメントの記事を連載しています。
「ChatGPTもCopilotもClaudeも社内に入れた。なのに、半年後の今、うちのAIは半年前より賢くなってるんだろうか」——そう問われて即答できる人は、まだほとんどいないと思います。
「活用しています」と言える状態にはなった。
でも、それが競争優位につながっているかと聞かれると急に自信がなくなる。
このモヤモヤの正体を、Satya Nadellaさん(X)が2026年6月15日の長文投稿でくっきり言語化してくれました。
結論から言うと、AIが「使われているだけ」の状態と「賢くなっている」状態の間には、学習ループという巨大な分かれ道があります。
その正体と、明日から動ける具体策まで、現場の感覚に翻訳します。
あなたの会社の社内AIは、今日より明日「賢く」なっていますか?
「導入しました」を成果報告にしている限り、AIはずっと外部リソースのままです。
社員が使っている、稟議が通った、月額契約を結んだ。
ここまでは多くの会社が到達しています。
でも、半年前のAIと今のAIで、自社の業務に対する「賢さ」が変わったかと聞かれて即答できる会社は、ほとんど見たことがありません。
ここで言う「賢さ」は、モデル自体のベンチマークスコアではありません。
自社の文脈、自社の顧客、自社の業務プロセスに対する適応度です。
この観点で見ると、ほとんどの企業のAIは導入初日からほぼ進化していません。
使っているだけの状態と、育てている状態の差は、ここから先で爆発的に広がります。
その「育て方」の設計図を、Nadellaさんが書いてくれました。
Satya Nadellaが指摘した「本当の問い」
「最良モデルを選ぶこと」ではなく「学習ループを持つこと」
多くの会社が今、「ChatGPTかClaudeかGeminiか」「Copilotか自社RAGか」というモデル選びに時間を使っています。
Nadellaさんの主張は、ここに鋭くナイフを入れます。
真の機会はモデル選びではなく、そのモデルの上に学習ループを組むことだと。
モデルは差し替えが効きます。
半年後には今より強い汎用モデルが出ているでしょう。
でも、自社の業務トレースから蓄積された評価データと、社内ナレッジが取り込まれた知識ベースは、差し替えられません。
つまり、モデル選びに注いだ時間は半年で陳腐化するけれど、学習ループを組んだ時間は複利になる、ということです。
タスクは外注できる。でも学習は外注できない
「議事録の要約」「営業メールのドラフト」のようなタスクは、外部AIに任せられます。
一方、自社の文脈を踏まえた判断基準、顧客との過去のやり取りから学んだコツ、ベテラン社員が体得している暗黙知。
これらをAIに教え込むプロセスを外注すると、価値の核がそのまま外に流れます。
タスクの結果だけ受け取って、学習の蓄積を捨てている会社が今とても多い。
これが「AIを入れたのに、なぜか差がつかない」の正体です。
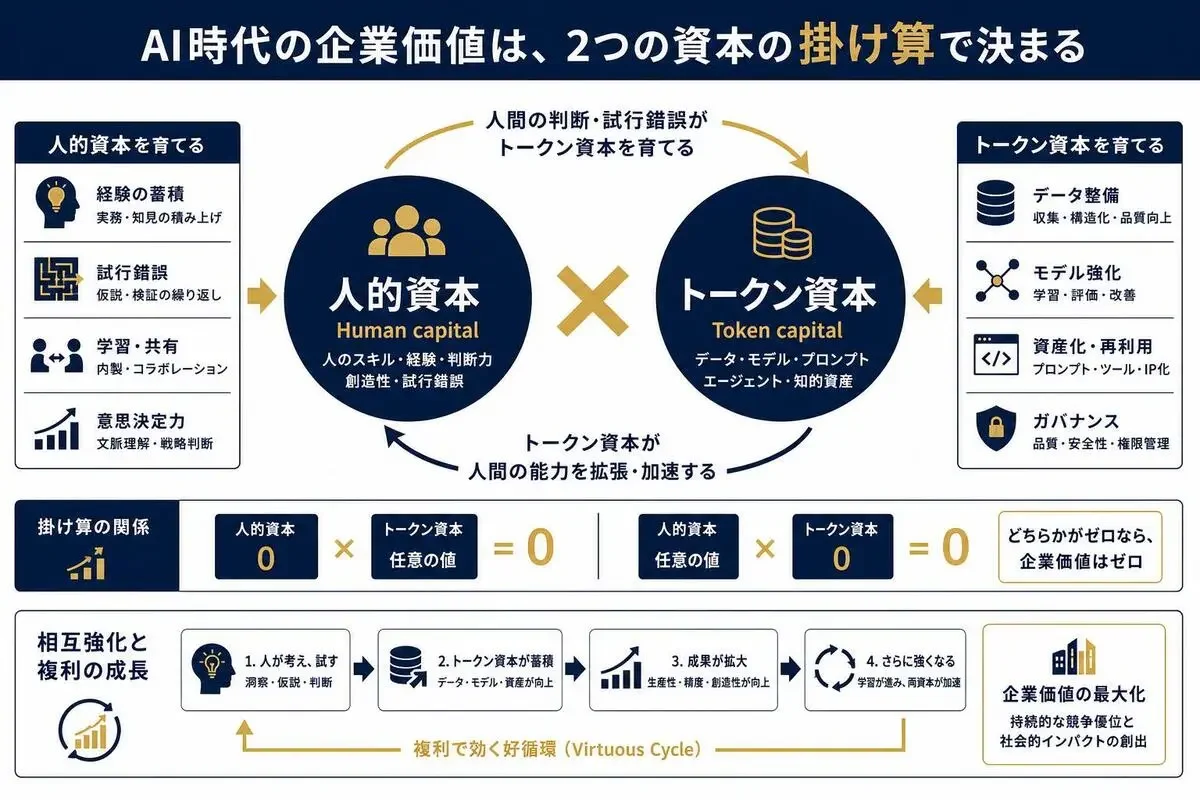
人的資本とトークン資本(Human capital × Token capital)を同時に育てる
では、差がつく会社とつかない会社の違いをどう設計するか。
Nadellaさんはその構造を「Human capital × Token capital」という枠組みで示しました。
人的資本と、企業が所有するAI能力(トークン資本)の掛け算で企業価値が決まる、という見方です。
ここが核心で、掛け算という点が効いてくる。
どちらかがゼロになると、全体がゼロになる。
トークン資本が伸びても人的資本の価値は下がらない、むしろ上がる。
この非対称性が肝になります。
人間が賢くなるほど、AIも賢くなる。その逆も成り立つ
人間が目標を設定し、領域を横断して点をつなぎ、関係を築き、重要なパターンを認識する。
この「人間のエージェンシー」こそが、トークン資本を育てるドライバーだとNadellaさんは書いています。
丁寧なOJTを積んだ新人が組織の財産になるように、AIも同じです。
人間の判断と試行錯誤をインプットし続けなければ、AIはいつまでも赴任初日のままです。
裏返すと、「AIに丸投げ→出てきた結果を使うだけ→学習なし」のパターンは、人的資本とトークン資本の両方を同時に止めています。
使えば使うほど差がつく、という本来の勝ち方と真逆の使い方です。
AI活用が伸び悩む根本的な理由
AIを入れたのに業務が変わらない原因は、ほぼ一点に絞られます。
人間が出した判断と、AIが出した結果の差分が、どこにも蓄積されていないことです。
ベテラン社員が「この提案文、ここが顧客の本音をついてない」と直した修正履歴。
営業が「このメール、相手の業界だとこの表現は刺さらない」と書き換えた赤入れ。
これらが日々消費されて、データとして残っていない。
学習ループの欠如とは、この差分の取り逃しです。
毎日金を掘り当てているのに、砂ごと川に流している状態です。
自社に「学習ループ」を作るとはどういうことか
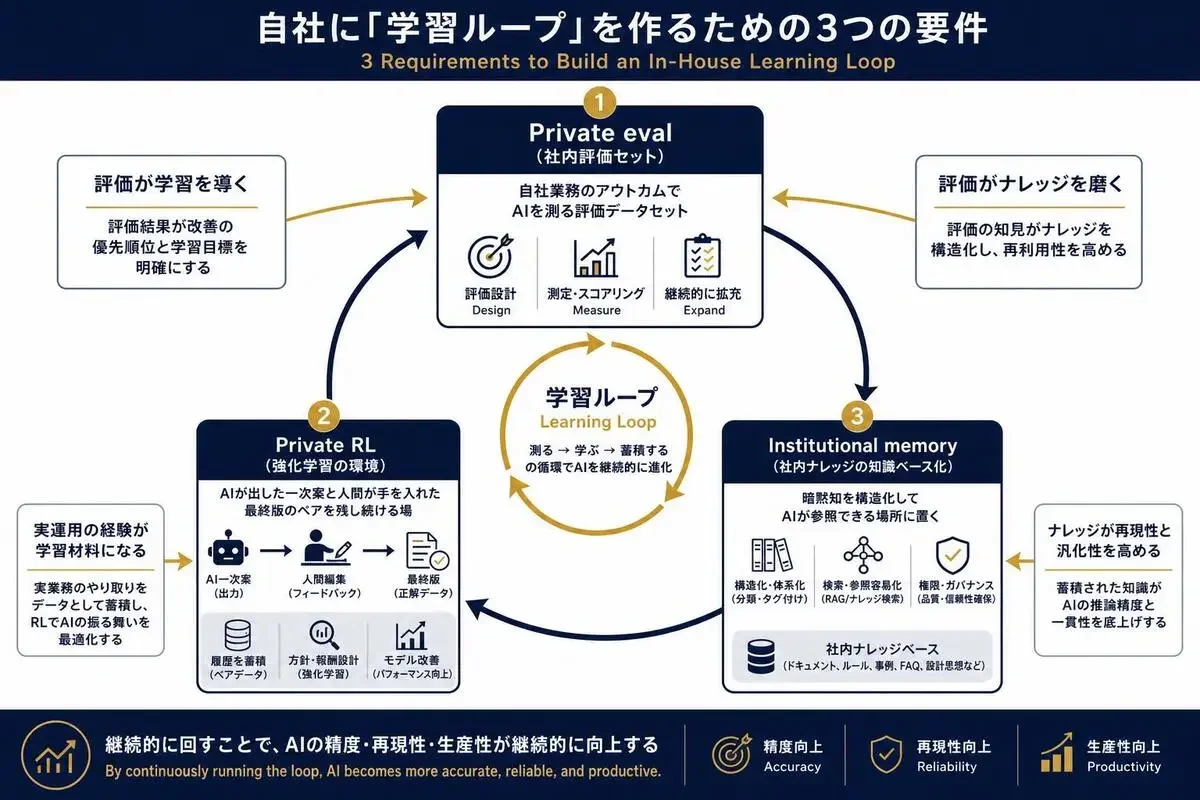
Nadellaさんは新アーキテクチャの3要件として、Private evals、Private RL environments、Institutional memoryの3つを挙げています。
日本の現場の言葉に翻訳します。
Private eval(社内評価セット)を整備する
Private evalとは、外部ベンチマークではなく、自社のビジネス上意味のあるアウトカムでAIの良し悪しを測る評価データセットです。
カスタマーサポートなら、「過去1年で対応の難しかった問い合わせ50件」をピックアップして、各ケースに「ベテランオペレーターが書いた理想回答」をペアで保存する。
新しいモデルが出るたびにこの50件を流して比較する。
これだけで、自社にとっての賢さを測れます。
汎用ベンチでGPT-5よりClaudeが上、みたいな話は自社業務とほとんど関係ありません。
自社の50件で勝つかどうかが、唯一意味のある指標です。
強化学習の環境を自社プロセスに埋め込む
Private RL environmentは、社内の実トレースからモデルが強くなれる強化学習の場、という概念です。
難しく考えすぎる必要はありません。
実務的にやるべきは、「AIが出した一次案」と「人間が手を入れた最終版」をペアで残し続けることだけ。
営業メール、PRD、議事録、提案資料。
あらゆる業務で、この差分がそのまま教師データになります。
将来このペアデータを使ってファインチューニングするのか、プロンプトを改善するのか、エージェントの行動方針を更新するのかは後で決められます。
今やるべきは、差分を捨てずに残す仕組みを作っておくことだけです。
社内ナレッジをAIに読み込ませ続ける仕組みを作る
Institutional memory(機関の記憶)を、検索可能な知識ベースとしてAIに渡し続ける。
これが3つ目の要件です。
過去の障害対応の記録、失注理由のメモ、ベテランの判断履歴、製品の細かい仕様の経緯。
文書にすらなっていない暗黙知を、Slackや議事録から拾い上げて構造化し、AIが参照できる場所に置く。
1回やって終わりではなく、日々更新し続ける運用設計が必要です。
地味ですが、ここをサボると、いくら強いモデルを使っても出力は薄っぺらいままです。
「賢いAIを選ぶ」から「自社でAIを育てる」へ
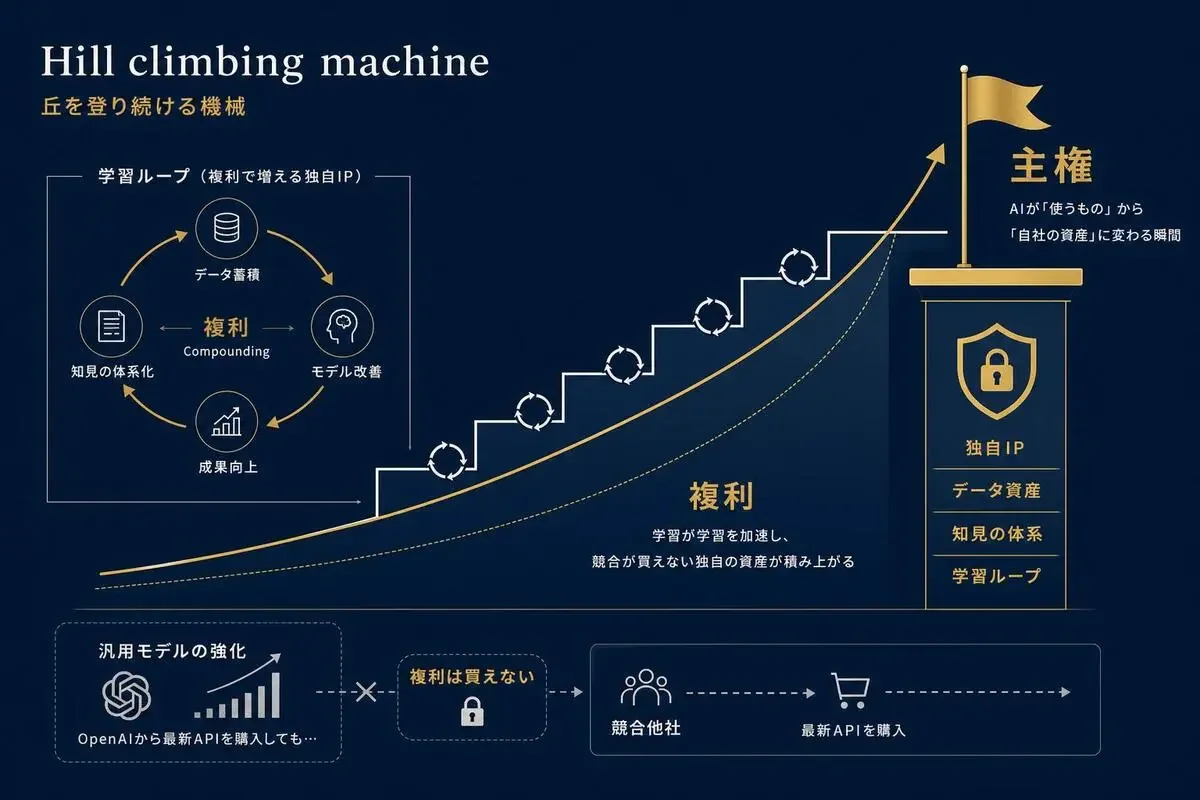
3要件を回し続けると、やがて会社のAIに人格のようなものが宿り始めます。
Nadellaさんはその状態をhill climbing machine(丘を登り続ける機械)と呼んでいます。
改善されたワークフローがより良い訓練シグナルを生み、それがまた業務改善を加速する。
複利で増える独自IPです。
汎用モデルがどれだけ強くなっても、競合がOpenAIから最新APIを買ってきても、この複利は買えません。
Nadellaさんはこれを新時代の主権テストと呼んでいます。
主権テストとは、こういうことです。
明日、今使っているAIのAPIが突然使えなくなったとしましょう。
別のモデルに乗り換えたとき、自社の学習システム側に何が残っていますか。
評価セット、差分データ、知識ベース——これらがあれば、次のモデルでも同じ「賢さ」を出発点にできます。
何も残っていなければ、乗り換えのたびに初日からやり直しです。
ジェネラリストモデルを差し替えても、自社の学習システム側にベテラン社員相当の知見が残っているか。
そこで初めて、AIが「使うもの」から「自社の資産」に変わります。
明日からできる、AI活用の効果測定と成果を積み上げる3つのアクション
3つ全部やる必要はありません。
1つだけ選んで、今週中に始めれば十分です。
自社の評価セットを1つ作る
特定の業務を1つ選び、「ベテラン社員が見て上手いと判断した過去のアウトプット」を10〜20件集めます。
それぞれに「なぜこれが良かったのか」を1〜2行で添える。
これだけで、汎用ベンチマークでは絶対に測れない自社にとっての賢さを測る軸ができます。
難易度は高くない。
今日の午後から始められます。
AI活用ログを取り始める
「AIに何を頼んだか」「出てきた結果」「人間がどう修正したか」を、業務単位でテンプレ化して残す運用に変えます。
Notion、Slackチャンネル、スプレッドシート、何でも構いません。
3ヶ月分溜まれば、それはもう立派な強化学習データセットの素材です。
始めるコストはほぼゼロ。
溜め始めるだけでいい。
「使った回数」より「何が変わったか」を記録する
社内のAI活用報告を、利用回数や時間削減ではなく「何が変わったか(WHAT changed)」で書く運用に変えます。
提案書の質が上がった、初回返信までの時間が短くなった、顧客の離脱が減った。
アウトカム側の変化を追いかける文化に変わると、AI活用は一気に「資本を育てる活動」になります。
会社のAIが今日より明日賢くなる仕組みを持つ。
それだけで、汎用モデルの進化に振り回されない強さが手に入ります。
3つのアクションのうち、1つだけ始めてみてください。
半年後に振り返ったとき、景色は変わっています。
変わっていなければ、学習ループのどこかに穴があります。
- 1
- 0

元メガベンチャーのプロダクトマネージャー。 PRD、ユーザーインタビュー分析、競合調査、ロードマップ策定などPM業務の8割をAIと一緒にやっています。 「AIに任せる判断力」は、現場で泥臭くやってきたPMだからこそ。PM × AI の実践ノウハウを発信中。

こちらもおすすめ
-
 AI集客@ルイ
AI集客@ルイ
- 1
- 0
-
AI脱社畜
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 2
- 0
-
- 5
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
AI集客@ルイ
- 2
- 0
-
AI経営者の参謀@ひで
- 29
- 1
-
コードを読まないAIエンジニア
- 2
- 0
-
AI経営者の参謀@ひで
- 4
- 0
-
- 1
- 1
-
- 6
- 0
-
- 13
- 3
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
KAWAI
- 1
- 0
-
- 2
- 1
-
- 26
- 2
-
- 4
- 0
-
- 6
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます