
私も「呪文」を信じていた側の人間です
こんにちは、脱社畜AI(@ai_escapingcorp)です。
ChatGPTに何か頼むたびに、「ステップごとに考えてください」「あなたは10年の経験を持つプロの編集者です」って毎回コピペしてませんでしたか?
私はやってました。
ネットで見つけた「最強プロンプトテンプレート」をNotionに保存して、それを使い回す日々。
「この呪文を入れないと、AIがちゃんと答えてくれないんじゃないか」という、根拠のない不安。
あれ、地味にストレスたまりますよね。
でもある日、ふと気づいたんです。
「あれ、この呪文を入れても入れなくても、回答の質が変わらなくない?」と。
そこから調べ始めてわかったのが、2025年に発表された複数の研究論文が、私たちが「効く」と信じてきたプロンプト技法の多くに「効果なし」「むしろ逆効果」という結論を出していたことでした。
え、逆効果ですよ?
この記事では、論文のデータをもとに「もう止めたほうがいい古いプロンプト技法」と「今こそ使うべき新しい技法」を、できるだけわかりやすくまとめます。
「自分のプロンプト、大丈夫かな」と少しでも思った方は、ぜひ最後まで読んでみてください。
2023年と2026年のAIは「別人」だと思ったほうがいい
AIモデルの進化を「上司交代」で考える
AIモデルの進化を、職場の「上司が変わった」と考えるとわかりやすいです。
2023年頃のAI(GPT-3.5やGPT-4初期)は、いわば「細かく指示しないと動かない上司」でした。
「まず背景を整理して、次に課題を洗い出して、それから解決策を3つ考えて」と手順を一つずつ伝えないと、的はずれな回答が返ってくることが多かった。
だから「ステップごとに考えて」という指示が効いたんです。
ところが2025年〜2026年の最新モデル(GPT-4o、Claude 3.5/4、Gemini 2.0など)は、いわば「優秀で自分の頭で考えられる新しい上司」です。
こちらが細かく手順を指定しなくても、質問の意図を汲んで、自分で段階を踏んで考えてくれる。
むしろ、優秀な上司に対して「まず1を考えて、次に2を考えて、次に3を考えて」と細かすぎる指示を出すのは、邪魔になることすらあります。
これ、思い当たる方もいるんじゃないでしょうか。
「推論モデル」って何?1行でわかる説明
最近よく聞く「推論モデル」(o3、Claude Extended Thinkingなど)を一言で言うと、「答える前に、自分の頭の中でじっくり考えるステップを踏んでから回答するAI」 です。
コンビニのレジ打ちと経営コンサルタントの違いをイメージしてください。
レジ打ち(旧モデル)は「〇〇をスキャンして」と言われたことをそのまま実行します。
一方、経営コンサルタント(推論モデル)は、質問を受けたら自分の中で情報を整理し、仮説を立て、検証してから答えを出します。
この「自分で考えるタイプのAI」に対して「ステップごとに考えてね」と指示するのは、経営コンサルタントに「ちゃんと考えてから答えてね」と言うようなものです。
「いや、言われなくてもそうしますけど......」となりますよね。
ここからが本題です。
具体的に、どんなプロンプト技法がもう通用しないのか、研究データと一緒に見ていきましょう。
今すぐ止めたい「古いプロンプト技法」5選

1.「ステップごとに考えてください」── 推論モデルには"余計なお世話"
「Let's think step by step(ステップごとに考えてみましょう)」は、2022年にプロンプト技法として大きな注目を集めたフレーズです。
私も1年以上、あらゆるプロンプトの冒頭にこれを入れていました。
しかし、ここが衝撃的なんですが、ペンシルバニア大学ウォートンスクールの研究チームが2025年に発表した実験データによると、推論モデル(o3-miniなど)にこの指示を加えた場合、応答にかかる時間が20〜80%も増加したにもかかわらず、性能向上はわずか2.9%にとどまった という結果が出ています。
ちょっと想像してみてください。
処理時間が最大で倍近く伸びるのに、出てくる答えの質はほぼ変わらない。
これ、毎日のAI作業で積み重なったら、かなりの時間ロスですよね。
職場に例えると、ルールを完璧に守っている真面目な社員に対して、上司が毎日「ルール守ってね」と念押しし続けるようなものです。
「いや、わかってますって......」と、社員のモチベーションが下がるだけでパフォーマンスは上がりません。
ただし補足すると、GPT-3.5クラスの旧モデルや、単純なタスクでは依然として効果があるケースもあります。
ポイントは「推論モデルを使っているなら、この呪文は外してみる」ということです。
外すだけで応答速度が上がるなら、やらない理由がないですよね。
2.「あなたは10年のキャリアを持つ専門家です」── ロールプロンプトの落とし穴
「あなたはプロのマーケターです」「あなたは経験豊富なエンジニアです」── プロンプトの冒頭でAIに「役割」を与えるロールプロンプトも、定番テクニックとして広まりました。
私も一時期、毎回プロンプトの1行目に入れていたクチです。
ところが、ここが面白いところなんですが、複数の研究チームが共同で発表した「ロールプレイ逆説」という研究が、興味深い問題点を指摘しています。
AIにロール(役割)を与えると推論性能が一定程度向上する一方、特定の役割を演じることで回答が偏り、バイアスや有害な出力のリスクが同時に増大するというパラドックスがある のです。
つまり、これが何を意味するかというと、「回答の質は少し上がるかもしれないけど、偏った情報や見落としが増えるリスクも一緒に背負い込む」ということです。
職場で言えば、社員の名札を「マネージャー」に変えたら確かに仕事ぶりが変わった。
でも「マネージャーっぽく振る舞おう」とするあまり、視野が狭まって偏った判断が増えてしまった── そういう話です。
わかります、私も「ロールを入れれば万能」だと思い込んでいた時期がありました。
もちろん、ロールプロンプトを完全に否定するわけではありません。
文章のトーンや口調を指定する用途(「カジュアルな文体で」など)には引き続き有効です。
ただし「ロールを与えれば回答の質が上がる」という万能薬的な期待は、見直したほうがよさそうです。
3. 例をたくさん入れるほど良い?── フューショット・ジレンマの衝撃
「AIに良い回答をしてもらうには、お手本(例)をたくさん入れるといい」── これもよく言われてきたアドバイスです。
確かに、2〜3個の例を入れる「Few-Shot」は効果的な技法として知られています。
問題は「じゃあ例は多ければ多いほどいいの?」という点です。
2025年にTangらの研究チームが発表した実験結果は、正直衝撃でした。
GPT-4oやLLaMA、DeepSeek-V3など複数の最新モデルで、例の数を増やすほど性能が下がる現象が確認された のです。
え、増やすほど下がるんですよ?
「たくさん例を入れれば入れるほど丁寧でしょ」と思って10個も20個も入れていた方、要注意です。
これは「フューショット・ジレンマ(Few-Shot Dilemma)」「オーバープロンプティング(Over-Prompting)」と呼ばれる現象です。
職場に置き換えると、新入社員に参考資料を3冊渡したら要点を掴んで動いてくれたのに、10冊積み上げたら逆に「どれを参考にすればいいかわからない」と混乱するようなものです。
「あ、やりすぎると逆効果なのね」── そう、まさにそういうことです。
研究データを踏まえると、例は3〜4つが黄金律 です。
「多ければ多いほどいい」は危険な思い込みだったということですね。
4.「お願いだから」「チップをあげます」── 感情操作フレーズの実態
「これは本当に重要な仕事なので、全力でお願いします」「良い回答には200ドルのチップをあげます」「失敗したらクビになります」── SNSで話題になったこれらのフレーズ、試したことありませんか?
正直、私もやったことがあります。
旧モデル時代には、こうした感情的なフレーズがある程度の効果を示したケースも報告されていました。
しかし、最新のフロンティアモデル(GPT-4o、Claude 4、Gemini 2.0クラス)では、感情操作フレーズに一貫した効果は確認されていません。
冷静に考えれば当然の話なんですよね。
AIは感情を持っていないので、「お願い」されてもやる気が上がるわけではなく、「チップをあげる」と言われてもモチベーションは変わりません。
職場で言えば、自動販売機に向かって「お願いだからコーヒー出して!100円のチップあげるから!」と叫んでいるようなものです。
......シュールですよね。
「焦らせる」「褒める」「脅す」系のフレーズは、いずれもプロンプトのトークン(文字数)を消費するだけで、回答の質を安定的に向上させる効果はないと考えたほうがいいでしょう。
その分のトークン、具体的な指示に回したほうがよっぽど効きます。
5.「必ず○○して」「絶対に○○禁止」── 過剰な制約が自由な回答を殺す
「必ず500文字以内で」「絶対に箇条書き以外禁止」「以下の制約をすべて守ってください: 1. ... 2. ... 3. ... 4. ... 5. ...」── 指示を細かく書けば書くほど正確な回答が返ってくると思いがちですよね。
私もかつて、制約条件を10個以上並べたプロンプトを自信満々で使っていました。
しかし2025年の研究(プロンプティング逆転)では、GPT-5において、複雑な制約指示がかえって回答の質を下げるケースがある ことが示されています。
これ、職場の「あるある」そのものです。
優秀な部下をマイクロマネジメントする上司と同じ構図なんですよ。
「報告書を書いて」と頼めば素晴らしい報告書を作れる部下に、「フォントはゴシックで、見出しは青で、1行あたり40文字で、段落は必ず3行以内で......」と延々と指定すると、制約を守ることにエネルギーを取られて、肝心の内容が薄くなります。
思い当たる節、ありませんか?
制約は「本当に重要なことだけ」に絞るのが基本です。
さて、ここまで「止めるべきこと」を5つ見てきましたが、「じゃあ何が効くの?」って思いますよね。
こちらの方が個人的にはワクワクする話です。
研究で効果が確認されている「今の技法」3選
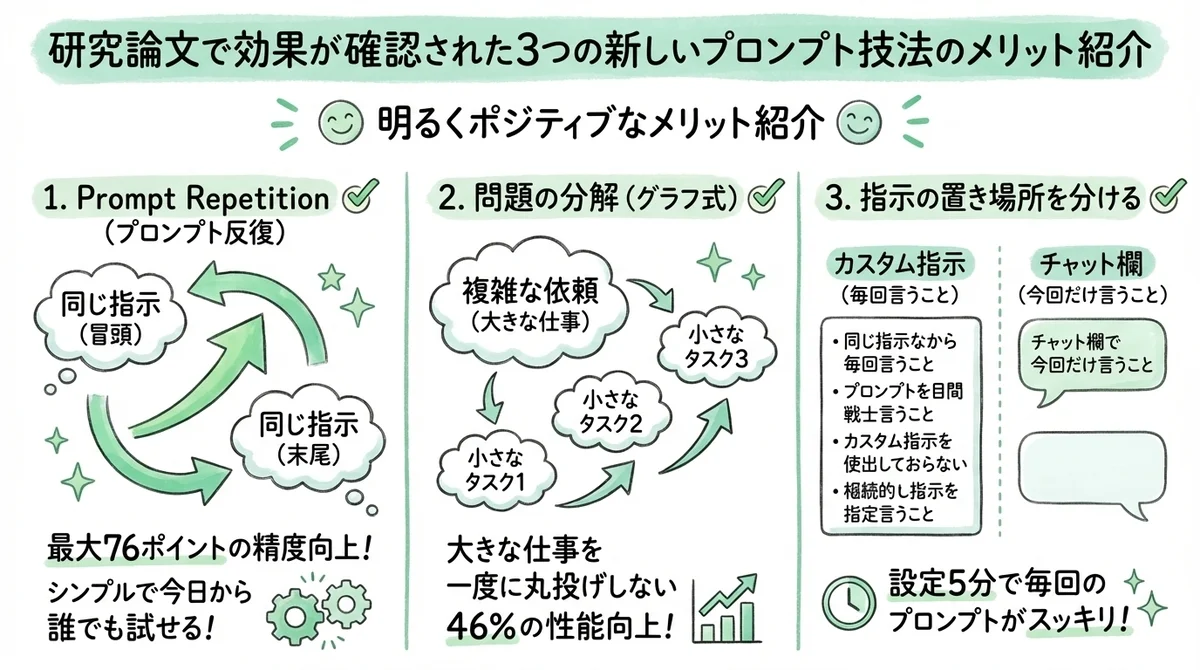
1. 同じ指示を2回書く ── Prompt Repetitionの意外な効果
「えっ、同じことを2回書くだけ?」と思いますよね。
私も最初は冗談かと思いました。
しかし、これが地味にすごいんですよ。
Googleの研究チームが2025年末に発表した論文によると、プロンプトの中で同じ指示を繰り返す「Prompt Repetition(プロンプト反復)」は、非推論タスクにおいて最大76ポイントもの精度向上(21%→97%) を示したそうです。
21%から97%ですよ?
ちょっと想像してみてください。
5回に1回しか正解できなかったAIが、ほぼ毎回正解するようになる── それくらいのインパクトです。
具体的にどう使うかというと、こんな感じです。
Before(1回だけ):
以下の議事録を要約してください。 (議事録の本文)
After(2回繰り返す):
以下の議事録を要約してください。 (議事録の本文) 以上の内容を要約してください。
たったこれだけです。
指示文の冒頭と末尾に、同じ依頼を書くだけ。
なぜこれが効くかというと、AIは長い文章を処理する際に「最初」と「最後」の情報を特に重視する傾向があるからです。
途中に大量のテキストが挟まると、冒頭の指示が薄まることがある。
それを末尾で念押しすることで、AIが「何を求められているか」をブレずに認識できるわけです。
特別なテクニックも知識も不要で、今日から誰でも試せます。
コピペ1回で済む話なので、やらない手はないですよね。
2. 問題を小分けにして渡す ── グラフ式の問題分解の考え方
2025年に発表されたAGoT(Adaptive Graph of Thoughts)という研究では、難解な推論ベンチマーク(GPQA Diamond、GPT-4o使用)において46.2%の性能向上が確認されています。
......と言っても「AGoTって何?」となりますよね。
安心してください、本質はシンプルです。
「大きな問題を一度に丸投げしないで、小さなタスクに分解してから渡す」 ということです。
これは、仕事の依頼でも同じです。
上司が部下に「この企画書のフィードバックください」と丸投げすると、ぼんやりとした感想が返ってきがちです。
でもこう分けたらどうでしょう。
- 「まず、論理の流れに矛盾がないかチェックして」
- 「次に、ターゲット設定が適切かどうか意見をください」
- 「最後に、具体的な改善点を3つ挙げて」
こうすると、明確で具体的な回答が返ってきます。
AIに対しても同じです。
複雑な依頼を1つの長いプロンプトで投げるよりも、タスクを分解して順番に渡すほうが、圧倒的に質の高い回答が得られます。
「丸投げしない」── これだけで46%も改善するのは、かなりコスパの良い話ですよね。
3. システムプロンプトとユーザープロンプトを分ける ── 指示の"置き場所"で変わる
ChatGPTの「カスタム指示」やGPTsの設定画面、ClaudeのProject Instructions。
これらの機能を使いこなしている人は、実はまだ少ない印象です。
もし「毎回同じ前提条件をコピペしている」という方がいたら、ここ、ちょっと注目してください。
ポイントは、AIへの指示を 「毎回言うこと」と「今回だけ言うこと」に分ける ことです。
毎回言うこと(システムプロンプト / カスタム指示に設定):
- 回答のトーン(「カジュアルな敬語で」)
- 自分の背景情報(「私はマーケティング部門の会社員です」)
- 共通の制約(「日本語で回答して」)
今回だけ言うこと(チャット欄に入力):
- 今日の具体的なタスク(「この議事録を要約して」「来週のプレゼン構成を考えて」)
Before(全部チャット欄に書く):
あなたはマーケティングのプロです。日本語で、カジュアルな敬語で回答してください。私は食品メーカーのマーケティング部で働いています。以下の議事録を要約してください。(本文)
After(分離する):
カスタム指示に設定:
私は食品メーカーのマーケティング部で働いています。回答は日本語、カジュアルな敬語でお願いします。
チャット欄:
今日の会議の議事録を要約してください。(本文)
こうすることで、毎回同じ前提情報をコピペする手間がなくなるだけでなく、AIが「背景情報」と「今回のタスク」を明確に区別できるようになります。
設定は5分もかかりません。
一度やってしまえば、毎回のプロンプトがスッキリ短くなりますよ。
「プロンプトエンジニアリング」から「コンテキストエンジニアリング」へ
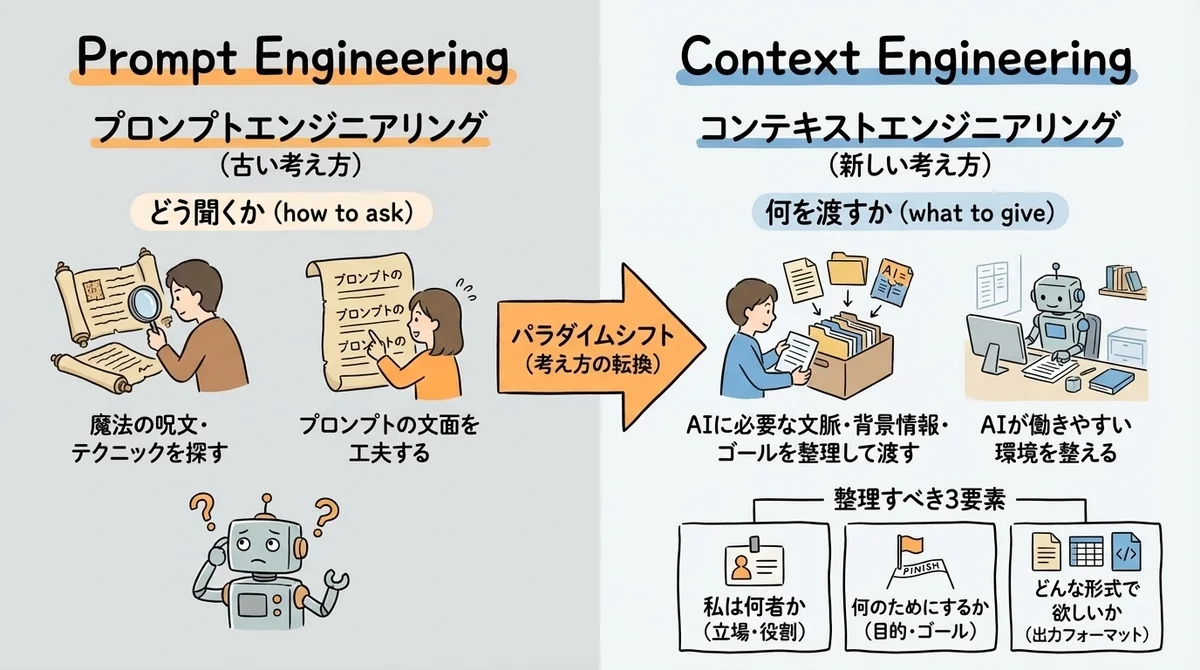
コンテキストエンジニアリングとは ── 1行で言うと「AIに渡す文脈を設計すること」
ここまで読んでくださった方は、もうお気づきかもしれません。
「結局、呪文じゃなくて"渡す情報の質"が大事なんだな」と。
まさにその感覚を体系化した概念があります。
Anthropic(Claudeの開発元)のエンジニアリングブログや、Google DeepMindのフィリップ・シュミット氏が体系化・普及した「コンテキストエンジニアリング」です。
一言でいうと、「呪文を唱える」のではなく「AIが働きやすい環境を整える」 という考え方です。
職場で例えるなら、部下に仕事を頼むとき「魔法の言い回し」を探すのではなく、「必要な背景情報」「仕事のゴール」「参考資料」をきちんと渡すことに集中する、ということです。
これ、考えてみれば当たり前のことなんですよね。
でも「呪文」に意識が向いていると、この当たり前を忘れてしまうんです。
具体的に何が変わるのか ── 指示文から「文脈の設計」へ
これまでのプロンプトエンジニアリングは、「どう聞くか(how to ask)」 に注力していました。
「この一文を入れると回答が良くなる」「この順番で書くと精度が上がる」という、いわば"聞き方のコツ"です。
コンテキストエンジニアリングは、「何を渡すか(what to give)」 に焦点を移します。
具体的に変わるのは、プロンプトを書く前に以下を整理する習慣をつけるということです。
- 私は何者か: 自分の立場、役割、知識レベル
- 何のためにこれをするか: 目的、ゴール、使い道
- どんな形式で欲しいか: 出力フォーマット、長さ、トーン
「呪文の時代」から「文脈設計の時代」へ。
この転換を意識するだけで、AIとのやりとりの質はぐっと変わります。
では最後に、今日から具体的に何をすればいいのかをまとめます。
明日から変えられること ── 止めること3つ・始めること2つ
ここまでの内容を、すぐに行動に移せるアクションリストにまとめます。
「全部いきなり変える必要はありません」── まずは1つだけ、ピンと来たものから試してみてください。
止めること
- 「ステップごとに考えてください」を推論モデルへの指示に毎回入れる ── 推論モデル(ChatGPTのo3モード、Claude Extended Thinking等)はすでに自分で考えています。
今日から外してみてください。
それだけで応答が速くなります。
- 「あなたは○○の専門家です」を冒頭の決まり文句にする ── 本当に必要な場面(トーン指定など)以外では省略しましょう。
- Few-Shotの例を5個以上コピペする ── 例は3〜4つに絞りましょう。
多すぎると逆効果です。
始めること
- 大事な指示は文末にもう1回繰り返す ── 長い文章をAIに渡すときは、冒頭の指示を末尾にも書く。
コピペ1回、5秒で終わります。
- 複雑な依頼は「タスクを箇条書きに分解してから渡す」ことを習慣化する ── 丸投げ禁止。
「まずAをやって、次にBをやって、最後にCをやって」と分けるだけでOKです。
この2つ、どちらも「今すぐ、無料で、リスクゼロで」始められます。
やらない理由、ないですよね。
まとめ
「プロンプトの呪文の時代は終わった」と言うと、少し寂しい気もします。
でも、正確に言えば「終わった」のではなく、AIとの付き合い方が成熟した のだと思います。
2023年に私たちが必死に覚えた「ステップごとに考えて」も「あなたは専門家です」も、当時のAIに対しては確かに最適解でした。
それが「無駄だった」わけでは決してない。
ただ、AIが進化したので、こちらの接し方もアップデートする必要が出てきた、というだけのことです。
「魔法の呪文」を探すのではなく、AIに適切な文脈を渡す。
この発想の転換ができれば、AIはもっと頼れるパートナーになってくれるはずです。
まずは明日のAIとの会話から、1つだけ変えてみてください。
「指示を末尾にもう1回書く」── たったそれだけで、AIの回答が変わる体験をしてもらえたら嬉しいです。
参考文献
- Wharton School研究チーム「Prompting Science Report 2: The Decreasing Value of Chain of Thought in Prompting」(arXiv:2506.07142, 2025年)
- トロント大学など複数の大学の研究チーム「ロールプレイ逆説」(arXiv:2409.13979)
- Tang et al.「The Few-shot Dilemma: Over-prompting Large Language Models」(arXiv:2509.13196, 2025年)
- 「プロンプティング逆転」(arXiv:2510.22251, 2025年)
- Google Research「Prompt Repetitionの効果検証」(arXiv:2512.14982, 2025年)
- AGoT研究チーム「Adaptive Graph of Thoughts」(arXiv:2502.05078, 2025年)
- Anthropic「Effective Context Engineering for AI Agents」(anthropic.com)
- Anthropic「Claude 4 Prompting Best Practices」(docs.anthropic.com)
- 3
- 1

元ブラック企業社畜 → AIで脱出した人 残業100h超から自分のペースで働く生活へ AI×副業の実践記録を発信中 失敗談も正直に書きます



こちらもおすすめ
-
コードを読まないAIエンジニア
- 2
- 0
-
- 4
- 0
-
- 3
- 0
-
- 2
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 1
- 0
-
プロンプト画伯
- 2
- 0
-
AI脱社畜
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 2
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI集客@ルイ
- 5
- 0
-
- 2
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 4
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
- 3
- 0
-
- 3
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI集客@ルイ
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 0

















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます