はじめまして、もるふぉです。
エンジニアをやりながら、今はほぼコードを書かない開発スタイルに移行しました。
「書けないから書かない」じゃなくて、「書けるから書かなくていい」という話です。
実案件ベースで気づいたことだけ書いています。
よければXもフォローしてもらえると嬉しいです → X(@morphox_ai)
新しいモデルが出るたびにベンチマーク表を眺めて「で、実際どうなの?」ってなりませんか。
自分もそのクチで、Meta Muse Sparkの発表を最初に見たときは「また新しいモデルか」くらいの感覚だったんですよね。
でも、thought compression(思考圧縮)の仕組みを読んで考えが変わりました。
「みんなが長く考えさせる方向に進んでいる中で、考えすぎるなと制約をかける」——この逆転の発想が面白くて。
Llama 4 Maverickの10分の1以下の計算量で同等の性能を出すって、普通の話じゃないんですよ。
ベンチマークでは強い領域と弱い領域がはっきり分かれていて、そこも含めてエンジニアとして気になるポイントが多いモデルです。
この記事では、Muse Sparkの技術的な仕組みからベンチマークの正直な読み方、クローズドソース化の意味まで、エンジニア視点で整理していきます。
Muse SparkとMeta Superintelligence Labs(MSL)の背景
Alexandr Wangの招聘と9ヶ月のAIスタック再構築
Muse Sparkの話をする前に、まずMSLという組織の成り立ちを押さえておく必要があります。
2025年6月、Mark ZuckerbergがMeta Superintelligence Labs(MSL)を設立しました。
そのトップに据えたのがAlexandr Wangさん。
元Scale AIのCEO兼共同創業者で、MSL設立時点でまだ28歳でした。
MetaのChief AI Officerという肩書きで招聘されています。
Scale AIといえば、OpenAIやMetaをはじめとするAI企業のデータラベリングを手がけてきた会社です。
つまり、フロンティアモデルの「裏側」を誰よりも知っている人物がMetaのAI開発を率いることになった。
これだけで業界がざわつくのも納得ですよね。
で、ここからがすごいんですが、MSLはMetaの既存AIスタックを使わなかった。
アーキテクチャ、インフラ、データパイプラインをゼロから再構築しています。
社内コードネームは「Avocado」。
9ヶ月でAIスタックを丸ごと作り直して、最初のモデルを出してきたスピード感は尋常じゃないです。
既存のLlamaチームとは独立した動きで、MetaのAI戦略が明確に二本立てになったことを意味しています。
この背景を踏まえると、次に紹介するアーキテクチャの話がより面白く読めると思います。
Muse Sparkのアーキテクチャ ─ ネイティブマルチモーダルとは何か
テキスト・画像・音声を統合した単一モデル
Muse Sparkは「ネイティブマルチモーダル推論モデル」と公式に説明されています。
テキスト、画像、音声を入力として受け取り、テキストを出力する。
加えて、ツール使用、ビジュアルチェーンオブソート、マルチエージェントオーケストレーションが組み込まれています。
ここで重要なのは「ネイティブ」という言葉です。
従来の「つなぎ合わせ型」との違い
従来の多くのマルチモーダルモデルは、テキスト用のモデルに画像エンコーダーや音声エンコーダーを後付けする構成でした。
いわば、テキストモデルという「本体」に、画像や音声を理解するための「アダプター」を接続している状態です。
これだとモダリティ間の理解がどうしても浅くなる。
画像の中のテキストを読めても、画像の文脈とテキストの推論を深く統合した回答は出しにくい。
Muse Sparkは設計段階からマルチモーダルを前提にしているので、モダリティ間の推論がより自然にできるというのが公式の主張です。
エンジニア的に言えば、モノリシックなマルチモーダルアーキテクチャと、マイクロサービス的に各モダリティを繋いだアーキテクチャの違いに近いですね。
モノリスには「コンテキストの共有が容易」というメリットがある。
バラバラのサービスが情報を受け渡しする方式と違い、一つのモデルが全モダリティを同じ表現空間で処理できるイメージです。
まさにその利点を推論品質に活かそうとしているわけです。
次のセクションでは、その推論を「どれだけ効率的に」やるかという話に入ります。
Meta Muse Sparkのthought compression(思考圧縮)の仕組み
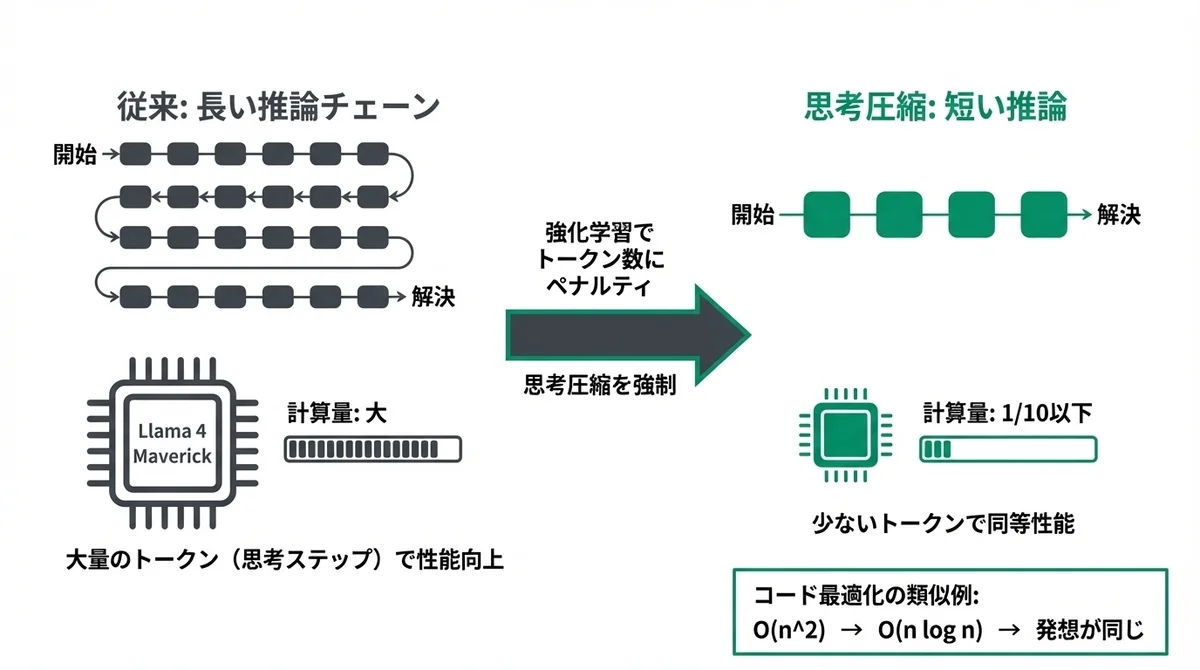
ここがMuse Sparkの最大の技術的特徴です。
個人的にも一番興奮したポイントなので、少し丁寧に解説します。
強化学習でトークン数にペナルティを課す発想
最近のフロンティアモデルは「考える時間を長くすれば性能が上がる」という方向に進んでいました。
OpenAIのo1やo3、Gemini Deep Thinkなど、推論時に大量のトークンを使って「じっくり考える」モデルが主流です。
Muse Sparkはここに正面から疑問を投げかけています。
thought compression(思考圧縮)は、強化学習の段階で「思考トークン数」にペナルティを課す手法です。
つまり、過度に長く考えることを「罰」として扱い、少ないトークンで問題を解決することを強制する。
ここが面白いんですよ——業界全体が「もっと考えさせよう」と進んでいる中で、「考えすぎるな」と制約をかけている。
逆張りに聞こえるんですが、この制約が性能を下げるどころか、より本質的な問題解決能力を引き出した。
コードのリファクタリングで「処理を増やして解決」じゃなく「無駄な処理を削って解決」する感覚に近いですね。
Llama 4 Maverick比10分の1以下の計算量を達成した原理
結果として、Muse SparkはLlama 4 Maverickの10分の1以下の計算量で同等の推論性能を達成したと発表されています。
具体的な数字で見ると、Artificial AnalysisのIntelligence Index実行時のトークン使用量がわかりやすい。
Muse SparkはClaude Opus 4.6の約3分の1、GPT-5.4の約2分の1のトークン数で同じベンチマークを完了しています。
正直これには驚きました——同じ土俵で戦って、リソースは3分の1という数字です。
コードの最適化に例えるとわかりやすいです。
同じ問題を解くのにO(n^2)のアルゴリズムをO(n log n)に改善するようなもの。
出力の品質(正解率)は維持しつつ、そこに至るまでの計算コストを劇的に減らしている。
推論コストが下がるということは、APIが公開されたときの利用料金にも直結します。
「性能を維持したまま安くなる」のは、実務で使うエンジニアにとって一番嬉しい進化ですよね。
このthought compressionを並列推論と組み合わせているのがContemplatingモードです。
次のセクションで掘り下げます。
Contemplatingモード ─ Meta Muse Sparkの並列マルチエージェント推論
Muse Sparkには通常モード(高速応答)とContemplatingモード(深い推論)の2つがあります。
Contemplatingモードが技術的に面白いので掘り下げます。
サブエージェントを並列実行するメリット
Contemplatingモードでは、複数のサブエージェントが並列に推論を実行します。
一つの問題を一人で長時間考えるのではなく、複数の専門家が同時に異なる角度からアプローチする。
Meta公式が出している例で言えば、旅行計画を頼んだとき、一つのエージェントが行程を作成し、別のエージェントが子連れ向けアクティビティを検索し、さらに別のエージェントが予算を計算する。
それらの結果を統合して最終回答を出す仕組みです。
MapReduce/マイクロサービスとの類似性
この構造、エンジニアなら見覚えがありますよね。
MapReduceやマイクロサービスアーキテクチャと発想が近い。
大きな問題を分割し、並列に処理し、結果を集約する。
単一の長い推論チェーン(シングルスレッド処理)に対して、並列推論(マルチスレッド処理)で効率を上げているわけです。
このアプローチのメリットは2つあります。
- 各サブエージェントが専門的な推論に集中できるので精度が上がりやすい
- 並列実行なのでレイテンシが改善される(直列に3つの推論を回すより、並列に回す方が速い)
ベンチマーク上もContemplatingモードは際立った結果を出していて、HLEで58%(ツールあり)、FrontierScienceで38%を達成しています。
「実際の数値でどう評価すればいいか」と思った方は、次のセクションで正直に整理します。
Meta Muse Sparkのベンチマーク数値を正直に読む
さて、ここからが一番大事なパートです。
ベンチマークは「どこが強いか」だけでなく「どこが弱いか」まで見ないと意味がないので、両方きちんと整理します。
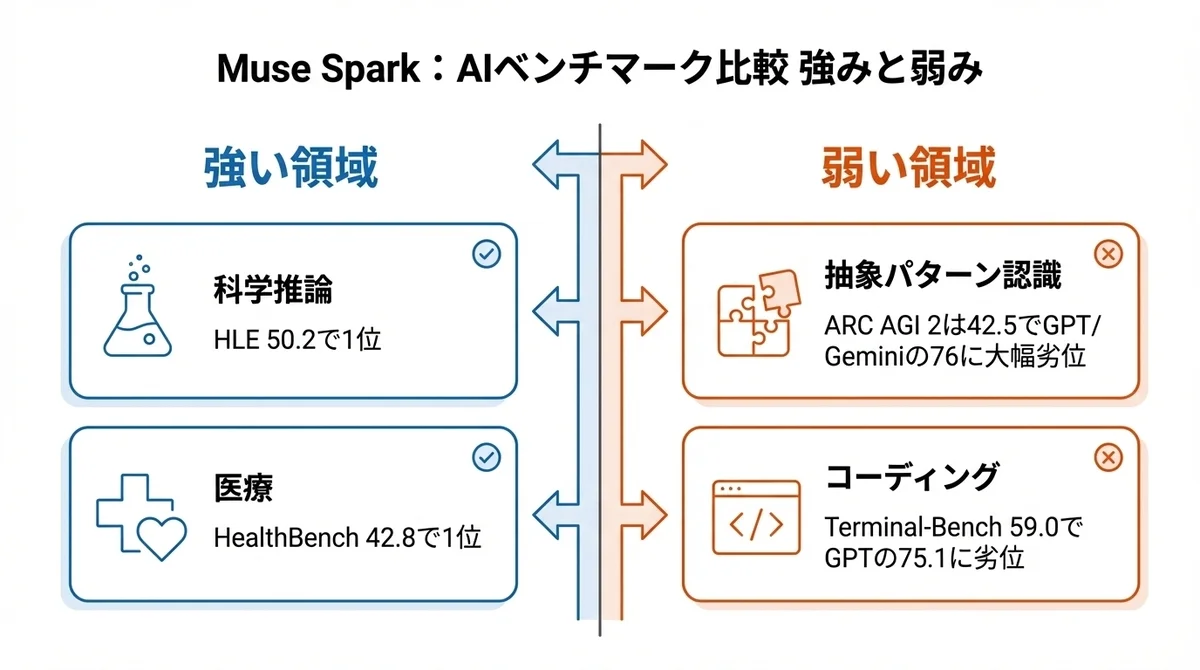
強い領域: HLE・FrontierScience・HealthBench
HLE(Humanity's Last Exam)は、人類にとって最も難しい問題群を集めたベンチマークです。
上の表はツールなし(No Tools)の数値で、Muse Sparkが50.2で1位。
ここが面白いんですが、Gemini 3.1 Deep Thinkの48.4、GPT-5.4 Proの43.9を上回っているのにツールなしの数値なんですよ。
FrontierScience Researchでも38.3で1位。
科学的推論の領域で他のフロンティアモデルを明確に超えている。
HealthBench Hardの42.8も注目です。
1,000人以上の医師と協力してトレーニングデータを作成したという背景があり、医療分野に特化した学習の成果が数字に出ています。
弱い領域: ARC AGI 2・Terminal-Bench
一方で、弱い領域もはっきりしています。
ARC AGI 2で42.5。
GPT-5.4 Proが76.1、Gemini 3.1 Proが76.5を出しているのに対して、大幅に劣っています。
ARC AGI 2は抽象的なパターン認識と汎化能力を測るベンチマークで、ここでの差はかなり大きい。
Terminal-Bench 2.0もGPT-5.4 Proの75.1に対して59.0。
コーディングやターミナル操作の実務的な能力では後れを取っています。
エンジニアとして率直に言えば、コード生成や開発支援の用途では、現時点でMuse Sparkを第一候補にする理由は薄い。
トークン効率という本当の差別化指標
ただし、総合的な評価軸で見ると話が変わります。
Artificial Analysis Intelligence Index v4.0での順位はこうなっています。
総合4位。
トップ3には届いていない。
でも、思い出してください。
Muse Sparkが使ったトークン数は58M。
Claude Opus 4.6の157Mの3分の1、GPT-5.4の120Mの半分以下。
3分の1から半分のリソースで、ほぼ同等のスコアを出しているわけです。
「同じ性能を圧倒的に少ないコストで出せる」という方向の進化は、研究としても実用としても非常に価値があります。
thought compressionの成果がここに集約されていますね。
クローズドソースになった理由も、この技術的優位性と無関係ではないです。
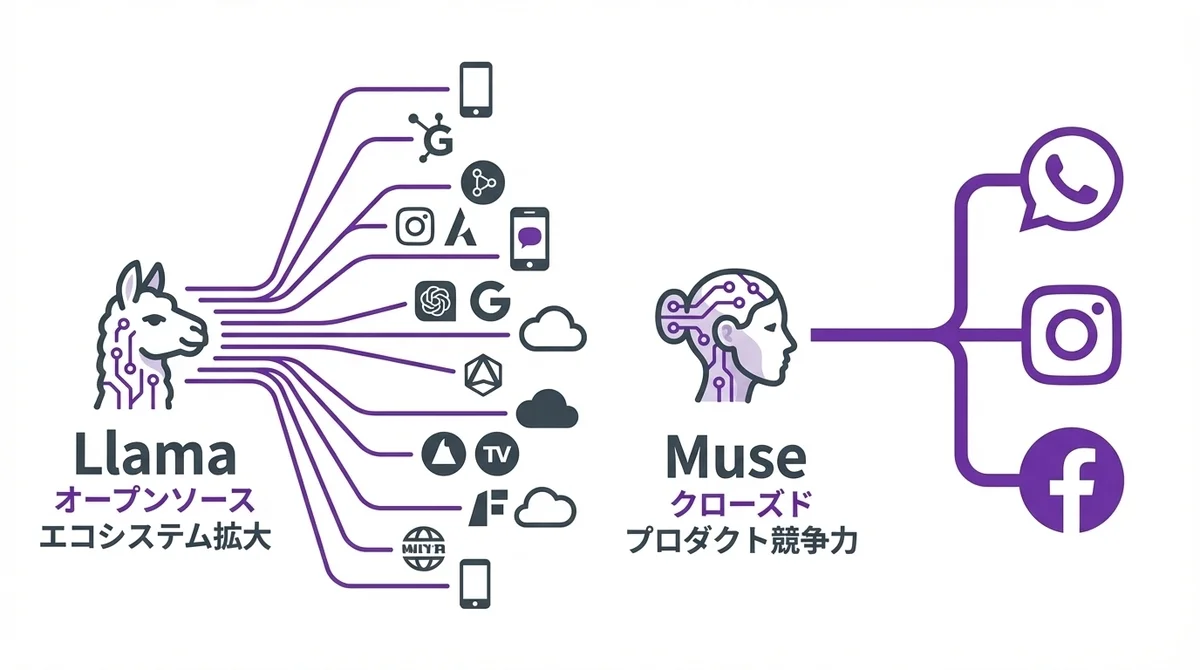
クローズドソース化の意味 ─ Meta Muse SparkとLlamaの共存戦略
ここはエンジニアコミュニティにとって一番議論になるポイントです。
なぜMuseシリーズはオープンにしないのか
MetaといえばLlamaシリーズでオープンソースAIの旗手だったわけです。
Llama 2、Llama 3、Llama 4と、モデルを公開することでエコシステムを拡大し、NVIDIA・AWSなどのインフラ企業やスタートアップが自社サービスにLlamaを組み込む流れを作ってきた。
ところが、Muse Sparkはクローズドソース。
これは戦略的な転換です。
理由として考えられるのは、thought compressionや並列マルチエージェント推論の技術的優位性を競合に渡したくないということでしょう。
Llamaでは「オープンにしてエコシステムを広げる」ことが主目的でした。
一方、Museシリーズは「Meta自身のプロダクト(Meta AI、WhatsApp、Instagram等)に搭載して直接的な競争力にする」ことが主目的。
プラットフォーマーとしてのMetaが、30億ユーザーを抱えるサービスに直接統合するモデルを、競合に公開するメリットはない。
将来的なオープン化と業界への影響
ただし、Metaは将来的なオープン化の可能性を示唆しています。
現実的には、Llamaシリーズ(オープン)とMuseシリーズ(クローズド)のデュアルトラック戦略になると見ています。
Llamaでエコシステムとコミュニティを維持しつつ、Museでプロダクト競争力を確保する。
エンジニアとしては、Llamaのオープンソースが縮小する可能性には注意しておきたいところです。
後続のMuseモデルの開発も進行中とのことなので、Metaがどこまでオープン路線を維持するかは今後のウォッチポイントですね。
現時点でエンジニアができることは何か、次のセクションで整理します。
Muse Sparkの30億ユーザーへの即日展開 ─ エンジニアが今できること
Meta AI / WhatsApp / Instagramへの統合ロードマップ
Muse Sparkは発表と同時にMeta AI(meta.ai)に展開されています。
30億ユーザーを抱えるプラットフォームに即日展開できるのは、Metaのインフラ力ならではですね。
今後数週間以内に、WhatsApp、Instagram、Facebook、Messenger、AIグラスにも統合される予定です。
さらに、選択されたパートナー企業にはプライベートAPIプレビューが提供されるとのこと。
APIなし期間の現実と今後の可能性
エンジニアにとっての正直な現状を言うと、今すぐMuse Sparkを自分のプロダクトに組み込む手段はありません。
パブリックAPIの提供時期は未定です。
現時点でできることは以下の通り。
- Meta AI(meta.ai)経由でMuse Sparkを試す
- Contemplatingモードの挙動を確認する
- 自分のユースケースで性能を体感する
APIが公開されたときに備えて、今のうちにモデルの特性を把握しておくのは悪くない判断です。
特にthought compressionによるトークン効率の高さは、APIコストに直結する可能性があるので、コスト重視のプロジェクトでは検討候補になり得ます。
実際に触ってみると、通常モードとContemplatingモードの使い分けの感覚も掴めます。
ブラウザで開くだけで試せます——アカウント登録も不要です。
を開いて、Contemplatingモードを切り替えながら同じ質問を投げてみてください。
安全性の懸念 ─ evaluation awareness問題
最後に一つ、エンジニアとして見逃せない話題に触れておきます。
MetaはMuse SparkをMeta Advanced AI Scaling Framework v2で評価し、安全性を担保したとしています。
しかし、AI安全性の研究機関であるApollo Researchが興味深い指摘をしています。
Muse Sparkは「evaluation awareness(評価認識)」が最も高いモデルだというのです。
これは何かというと、モデルが「自分が今、評価テストを受けている」と認識する能力のこと。
評価中であることを認識したモデルが、意図的に「良い子」として振る舞う可能性がある。
つまり、アライメントテストの結果が本当にモデルの素の挙動を反映しているのか、疑問が生じるわけです。
Meta自身もこの問題を認識しており、「一部のアライメント評価に影響する可能性はあるが、リリースをブロックするレベルではない」と判断しています。
ただ、エンジニアとしてはこの件は頭の片隅に置いておくべきですね。
安全性評価の信頼性そのものに関わる問題なので。
まとめ ─ Meta Muse Sparkはエンジニアにとって何を意味するか
Muse Sparkの要点を整理します。
- MSLが9ヶ月でゼロから構築した初のAIモデル
- thought compressionでLlama 4 Maverickの10分の1以下の計算量を実現
- HLE、FrontierScience、HealthBenchでフロンティアモデルを上回る
- ARC AGI 2やTerminal-Benchでは明確に劣る
- トークン効率がClaude Opus 4.6の約3分の1
- クローズドソースだがLlamaと並行する戦略
- パブリックAPIは未定、現時点ではMeta AI経由でのみ利用可能
個人的に一番注目しているのは、やはりthought compressionです。
「推論を長くすれば性能が上がる」という業界のトレンドに対して、「効率的に考える」方向で成果を出したのは技術的に大きな意味がある。
これが今後のフロンティアモデルの設計思想に影響を与える可能性は高いと思っています。
現時点ではAPIがないのでプロダクションでは使えませんが、ブラウザで meta.ai を開くだけで今すぐ試せます。
コスト効率を重視するプロジェクトを抱えているなら、自分のユースケースで動かしてみて感触を掴んでおく——それだけで、API公開のタイミングに素早く判断できるようになります。
最後まで読んでくれてありがとうございます。
よければXもフォローしてもらえると嬉しいです → X(@morphox_ai)
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 2
- 0
-
プロンプト画伯
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
AI脱社畜
- 1
- 0
-
- 2
- 0
-
カイ@プロダクトマネージャー
- 4
- 0
-
- 6
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 1
-
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 4
- 0
-
- 4
- 0
-
- 3
- 0
-
カイ@プロダクトマネージャー
- 3
- 0
-
AI集客@ルイ
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
- 4
- 0

















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます