コードを書かないAIエンジニア@もるふぉです。
シニアソフトウェアエンジニアとして10年以上開発をしてきましたが、今はClaude Codeを使って「コードを書かない開発スタイル」を実践しています。
Google Magikaを知っていますか?ファイル偽装を99%の精度で見破る、Google製のAIファイル検出ツールです。
ファイルアップロードの実装、拡張子チェックとMIMEタイプ確認だけでセキュリティ担保してませんか?
.pdfに見せかけた実行ファイルが普通にすり抜けてきますよ、それ。
今回紹介するGoogle Magikaは、Googleが「週に数千億ファイル」の処理に使ってきたAIベースのファイル検出ツールです。
それが無料・オープンソースで公開されていて、しかもpip install magika
200種類以上のファイルタイプを99%の精度で識別して、拡張子偽装を見破ります。
Rustで完全に書き直されたMagika 1.0が2025年11月にリリースされていて、1ファイルあたり5ms以内、1,000ファイル/秒の処理速度が出ます。
きっかけはこのポスト。
Guillermo Casausさん(@_guillecasaus)が紹介していたんですが、「Googleが内部ツールの中でも最も強力なものの1つを公開した」というフレーズが刺さりました。
実際に調べてみたら、想像以上に実用的だったので、技術的な仕組みから実装方法まで深掘りしていきます。
Google Magikaとは何か——ファイル偽装を見破るためにGoogleが作ったAIツール
ファイル識別の難しさ:拡張子は信頼できない
これ、地味に「あるある」な話なんですよ。
拡張子は単なるラベルにすぎません。
.jpgと名付けられたファイルが実はPythonスクリプトだった、.pdfに見せかけた実行ファイルだった——こういうケースは攻撃者にとって初歩的なテクニックです。
MIMEタイプも同様で、HTTPリクエストのContent-Typeヘッダーはクライアントが自由に設定できます。
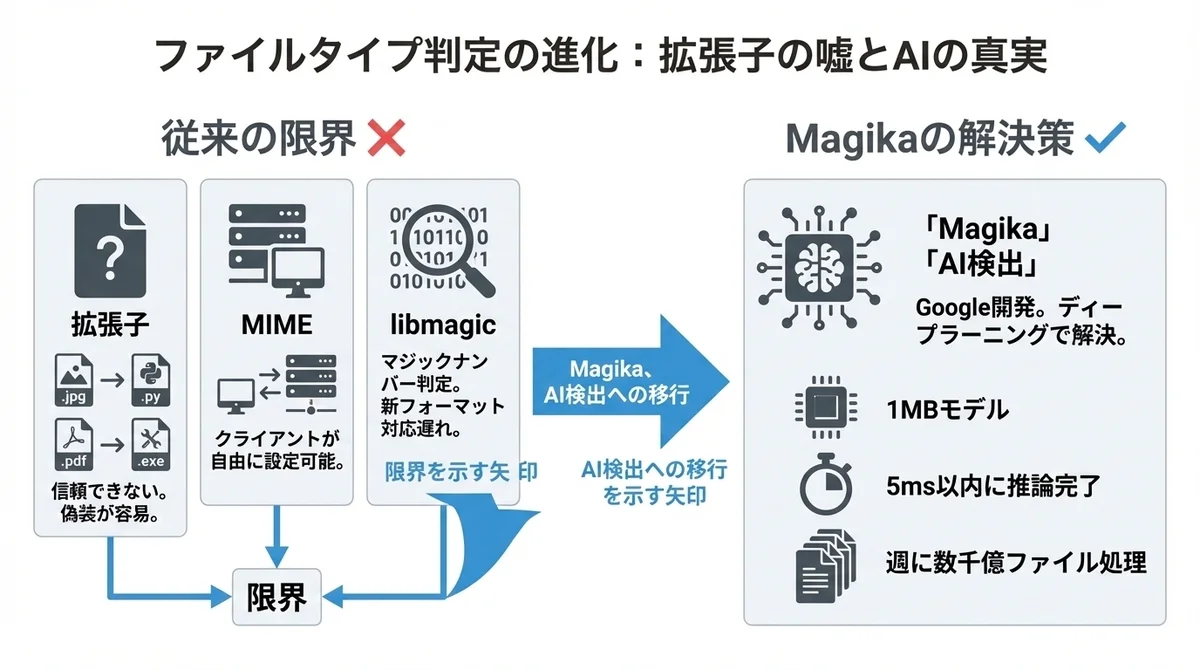
「じゃあlibmagicでマジックナンバーを見ればいい」という話になるんですが、それにも問題があります。
従来のツールであるlibmagic(fileコマンドの内部ライブラリ)は、ファイルの先頭数バイトにあるマジックナンバーを手書きのルールで照合して判定しています。
長年使われてきた実績はあるんですが、新しいファイルフォーマットへの対応が遅い、似たようなフォーマット(JSONとJSONL、CとC++など)の区別が苦手、そして意図的に偽装されたファイルに対して脆弱という問題があります。
「先頭のマジックナンバーだけ書き換えれば騙せる」ということですね。
MagikaがGoogleで解いた問題
Googleは、Gmail、Google Drive、Safe Browsingなどのサービスで、アップロードされるファイルを適切なセキュリティスキャナーやコンテンツポリシーチェッカーに振り分ける必要があります。
その規模が、週に数千億ファイル。
この規模で手書きルールベースのファイル判定を運用すると、メンテナンスコストが膨大になります。
ルールを追加するたびに既存の判定に影響が出ないかテストしなければならないし、新しいファイル形式が登場するたびに専門家がルールを書かなければならない。
Magikaは、この「手書きルールの限界」をディープラーニングで解決したツールです。
人間がルールを書く代わりに、約1億サンプル規模の大規模データセットでモデルを訓練し、ファイルのバイト列パターンから自動的にコンテンツタイプを推論するようにしました。
何が嬉しいかっていうと、新しいファイル形式への対応がルール追加ではなく再学習で済むことです。
しかもモデルのサイズはわずか1MB程度で、CPU1コアで5ms以内に推論が完了します。
1MBのモデルがGoogleスケールの問題を解いてるって、ちょっと痺れませんか?
2024年OSS化から2025年Magika 1.0へのアップデート経緯
Magikaの歴史を簡単に整理しておきます。
- 2024年2月: Googleが初期バージョンをオープンソースとしてリリース。
Pythonベースで、約100種類のコンテンツタイプに対応していました。
- 2024年9月: 学術論文「Magika: AI-Powered Content-Type Detection」がarXivに公開。
- 2025年11月: Magika 1.0が正式リリース。
Rustで完全に書き直され、対応コンテンツタイプが200種類以上に倍増しています。
1.0では、Geminiを活用して合成トレーニングデータを生成するという手法も取り入れています。
珍しいファイル形式やレガシーフォーマットは実データが少ないため、既存のコードや構造化ファイルをGeminiで別フォーマットに変換して学習データを増やしたそうです。
「AIでAIを強化する」というGoogle流のアプローチですね。
で、「実際どう使うの?」という話を先に見ていきましょう。
Google Magika実装ガイド——ファイル偽装を防ぐインストールから実務活用まで
インストール(pip / cargo / npm)
インストールは本当に簡単です。
言語に応じて3つの方法があるので、用途に合わせて選んでください。
Pythonの場合(pip)
pip install magikaPython 3.8以上が必要です。
最新のリリース候補を試したい場合は以下のコマンドを使います。
pip install --pre magikaRustの場合(cargo)
crates.io経由でインストールするのが公式推奨の安定版です。
cargo install --locked magika-cliGitHubのリポジトリから最新の開発版を直接インストールしたい場合は以下を使います。
cargo install --locked --git=https://github.com/google/magika.git magika-cliJavaScriptの場合(npm)
npm install magikaCLIとして使う場合はグローバルインストールします。
npm install -g magikaJavaScript版はブラウザでも動作するため、クライアントサイドでのファイル判定にも使えます。
CLIの基本的な使い方
インストールしたら、まずCLIで試してみてください。
こんなアウトプットが出ます。
単一ファイルの判定
$ magika suspicious_file.pdf
suspicious_file.pdf: Python source (code)拡張子は.pdfなのに、中身はPythonソースコードだと見抜いています。
これがMagikaの真価です。
ディレクトリの再帰スキャン
$ magika -r ./uploads/
uploads/report.pdf: PDF document (document)
uploads/image.jpg: JPEG image (image)
uploads/sneaky.png: ELF executable (executable)-rオプションでディレクトリ内のファイルを再帰的にスキャンできます。
3番目のファイル、拡張子は.pngですが中身はELF実行ファイルだと判定されています。
これが本番環境のアップロードフォルダに混じっていたら、ちょっと背筋が凍りますよね。
便利なオプション
# JSON形式で出力(プログラムからパースしやすい)
$ magika --json suspicious_file.pdf
# MIME type形式で出力
$ magika -i suspicious_file.pdf
# 信頼度スコアも表示
$ magika -s suspicious_file.pdf--jsonオプションはパイプライン処理に組み込むときに重宝します。
Python APIでファイルアップロードのバリデーションを強化する
CLIで試せたら、次はアプリケーションへの組み込みです。
pip install magikaしたらそのまま使えて、既存コードへの追加もほぼコピペでいけます。
ファイルアップロード機能のセキュリティ強化に使う例を書いてみます。
基本的な使い方
from magika import Magika
m = Magika()
# ファイルパスから判定
result = m.identify_path("./uploads/user_file.pdf")
print(result.output.label) # 例: "pdf"
print(result.output.score) # 例: 0.99
# バイト列から判定
with open("./uploads/user_file.pdf", "rb") as f:
data = f.read()
result = m.identify_bytes(data)
print(result.output.label)ファイルアップロードのバリデーション実装例
from magika import Magika
from pathlib import Path
# 許可するコンテンツタイプのホワイトリスト
ALLOWED_TYPES = {"pdf", "jpeg", "png", "gif", "docx", "xlsx"}
magika = Magika()
def validate_upload(file_path: str, expected_extension: str) -> dict:
"""
アップロードされたファイルの真のコンテンツタイプを検証する。
拡張子との不一致を検出して偽装ファイルをブロックする。
"""
result = magika.identify_path(Path(file_path))
detected_type = result.output.label
confidence = result.output.score
# 許可リストに含まれないタイプはブロック
if detected_type not in ALLOWED_TYPES:
return {
"allowed": False,
"reason": f"検出されたタイプ '{detected_type}' は許可されていません",
"detected_type": detected_type,
"confidence": confidence,
}
# 拡張子と検出結果の不一致をチェック
ext = expected_extension.lstrip(".").lower()
if ext == "jpg":
ext = "jpeg"
if detected_type != ext:
return {
"allowed": False,
"reason": f"拡張子 '.{ext}' と実際のタイプ '{detected_type}' が不一致",
"detected_type": detected_type,
"confidence": confidence,
}
return {
"allowed": True,
"detected_type": detected_type,
"confidence": confidence,
}
# 使用例
result = validate_upload("./uploads/report.pdf", ".pdf")
if not result["allowed"]:
print(f"ブロック: {result['reason']}")
else:
print(f"OK: {result['detected_type']} (信頼度: {result['confidence']:.2f})")大きなファイルを扱う場合はidentify_pathを使うのがおすすめです。
identify_bytesはファイル全体をメモリに読み込みますが、identify_pathは内部でseekを使って必要な3領域(先頭・中間・末尾の各512バイト)だけを読み取るので、メモリ効率が良いです。
「なぜ3領域なの?」というのが次の話です。
Magikaの技術的な仕組み——ファイル偽装を見破るAIの中身
ディープラーニングモデルが見ているもの(ファイル先頭・中間・末尾512バイト)
ここ、設計が面白いんですよ。
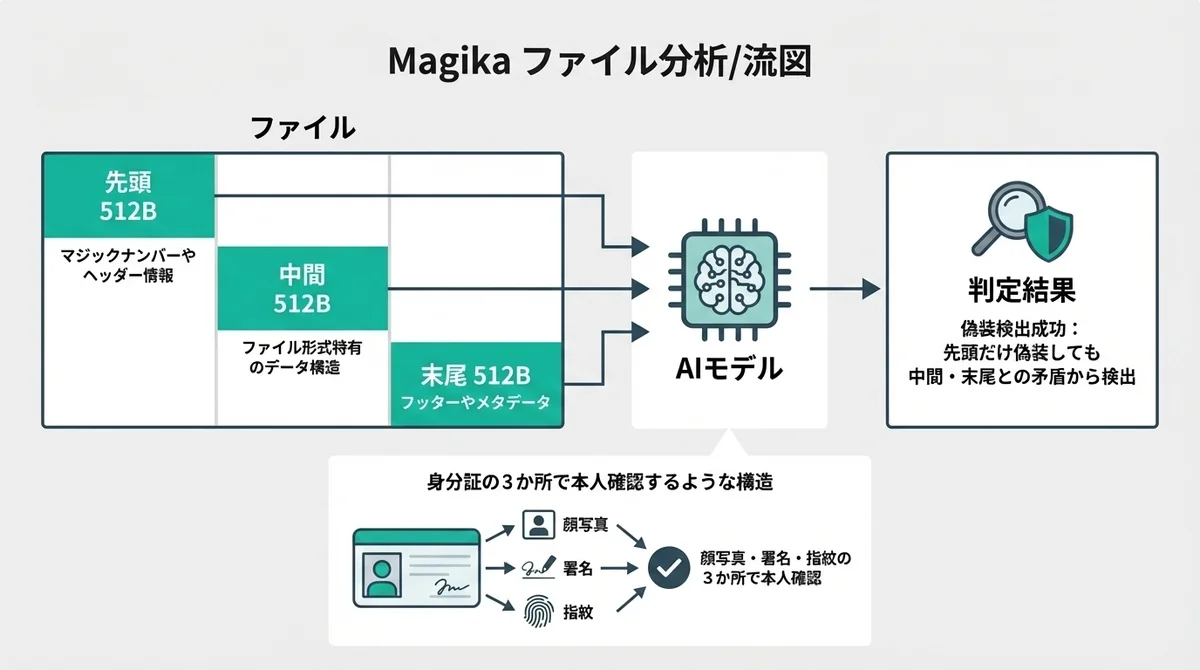
Magikaのモデルが入力として受け取るのは、ファイルの3つの領域から取得した合計1,536バイトです。
各バイトは0〜255の整数としてエンコードされます。
ファイルが小さい場合は、特殊文字(整数256)でパディングされます。
また、前処理として先頭と末尾の空白文字がストリップされるのもポイントです。
なぜこの3点なのかというと、ファイルの先頭にはマジックナンバーやヘッダー情報があり、末尾にはフッターやメタデータがあり、中間部分にはそのファイル形式特有のデータ構造があります。
この3点を組み合わせることで何が嬉しいかっていうと、先頭のマジックナンバーだけを偽装しても、中間・末尾のデータパターンとの矛盾から偽装を検出できるんです。
いわば「身分証の顔写真・署名・指紋の3か所で本人確認する」みたいな構造ですね。
しかも、ファイル全体を読み込む必要がないので、巨大なファイルでも高速に処理できます。
99%精度の実態——libmagicとの比較
「99%の精度」と聞くと少し眉唾に感じるかもしれません。
これは100万件以上のテストセットに対する平均精度・再現率の数字です。
具体的にlibmagicとどう違うのか、Google Research公開のデータから比較してみます。
libmagicの「数千種類対応」は一見有利に見えますが、対応しているだけで精度が出ないケースが多いです。
Magikaはカバー範囲を200種類に絞りつつ、そのすべてで高精度を実現しているのが特徴ですね。
「それにしても1MBのモデルでそこまでできるの?」と思うんですが、Rustへの書き直しでさらに速くなっています。
Rust再構築がもたらした性能向上
Magika 1.0の最大の変更は、Rustでのフルリライトです。
初期バージョンはPythonで実装されていましたが、1.0でRustに移行したことで以下の改善が実現しています。
- M4 MacBook Proで約1,000ファイル/秒の処理速度
- マルチコアで数千ファイル/秒にスケール
内部的には、モデル推論にONNX Runtime、非同期並列処理にTokioを使っています。
Rustの所有権システムによるメモリ安全性と、ONNX Runtimeの高速推論の組み合わせは理にかなっていますね。
Python版が悪かったわけではないんですが、Googleが「週数千億ファイル」を処理する環境では、このレベルのパフォーマンスが求められるということです。
「じゃあ実際に使うときに何に気をつければいいか」という話をしておきます。
セキュリティエンジニアが知るべきGoogle Magikaの得意と限界
得意なケース・苦手なケース
Magikaの導入を検討するなら、得意・不得意を正確に把握しておく必要があります。
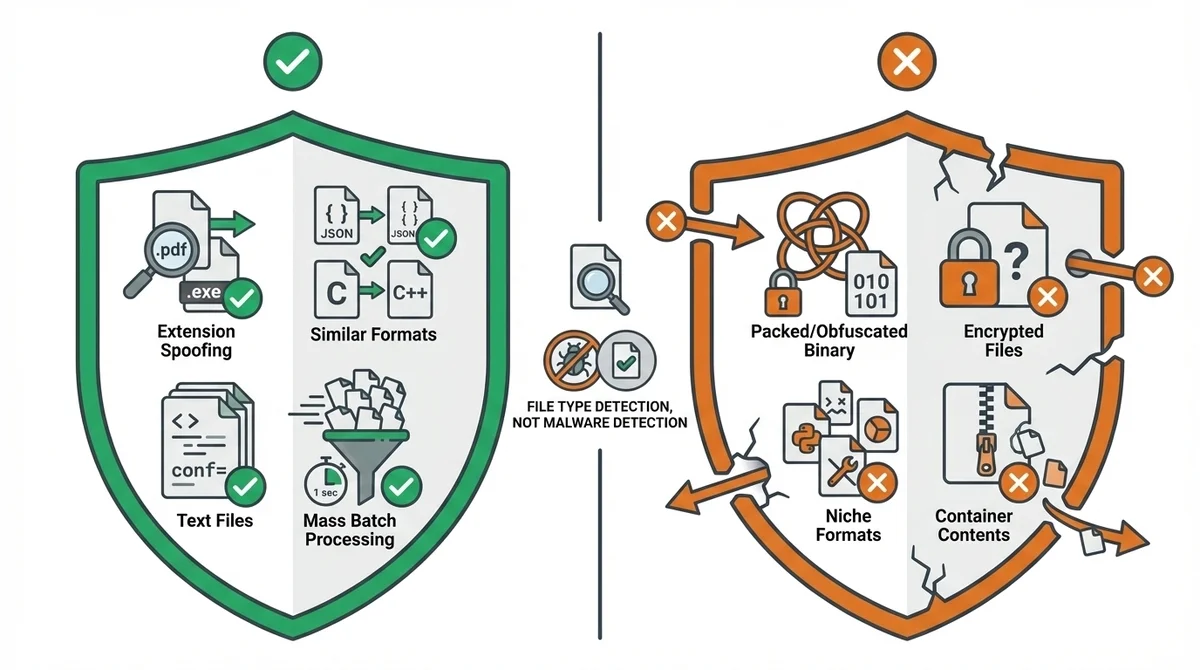
得意なケース
- 拡張子が偽装されたファイルの検出(
.pdfに見せかけた実行ファイル等) - 類似フォーマットの区別(JSON vs JSONL、TSV vs CSV、C vs C++、JavaScript vs TypeScript)
- テキストベースのファイルの判定(ソースコード、設定ファイル、マークアップ等)
- 大量ファイルのバッチ処理(数千ファイル/秒のスループット)
苦手なケース
- パッキング・難読化されたバイナリの内部構造の特定
- 暗号化されたファイルの元のコンテンツタイプの推定
- 対応していないニッチなファイル形式(200種類の範囲外)
- コンテナフォーマット内の個別ファイル判定(ZIPの中身など)
ここは誤解してほしくないんですが、Magikaは「このファイルは何のタイプか」を判定するツールであって、「このファイルはマルウェアか」を判定するツールではないです。
ファイルタイプ判定はセキュリティの第一防衛線であり、それ単体で完結するものではありません。
UPXパッキング済みマルウェアへの限界
具体的な限界の話をしておくと、Security Blue Teamの分析レポートが参考になります。
UPX(Ultimate Packer for eXecutables)でパッキングされたArdamaxマルウェアをMagikaに掛けた結果、「PE」(Windows実行ファイル)とだけ判定されました。
一方、従来のlibmagic(fileコマンド)は「UPX compressed」と判定し、パッキングされている事実を検出できていました。
これは重要な知見です。
libmagicには「UPXパッキングを検出するルール」が明示的に書かれているため、この特定のケースでは有利に働きます。
MagikaのAIモデルはパッキング手法の識別を学習していないため、パッキングされたバイナリを単なる実行ファイルとして分類してしまいます。
つまり、Magikaとlibmagicはどちらかをもう一方で完全に置き換えるものではなく、併用が現実的ということです。
VirusTotal連携という選択肢
MagikaはVirusTotalとabuse.chに統合されています。
VirusTotalでは、すべての提出ファイルがMagikaで処理され、各ファイルの「Details」タブで結果を確認できます。
Magikaのファイルタイプ判定が、VirusTotalのCode Insight機能(生成AIによるコード分析)のプレフィルターとして機能しているんですね。
たとえば、MagikaがPowerShellスクリプトだと正確に検出すれば、VirusTotalはそのファイルに対してPowerShell専用の分析を走らせることができます。
実務での活用を考えるなら、以下のような多層防御が現実的です。
- 第1層: Magika — ファイルタイプの真偽判定(ミリ秒単位)
- 第2層: VirusTotal API — マルウェアスキャン(秒単位)
- 第3層: サンドボックス実行 — 動的解析(分単位)
すべてのファイルにフルスキャンを掛けるのは現実的ではないですが、Magikaで怪しいファイルをフィルタリングしてからVirusTotalに投げる、という構成なら運用コストを抑えられます。
限界を踏まえたうえで、「なぜGoogleはここまで思い切ってルールベースを捨てたのか」というところを考えてみます。
ルールベースをAIに置き換える——Google Magikaから学ぶマルウェア検出の判断軸
Googleがhandcrafted rulesを捨てた理由
ここからは少し視座を上げて、「なぜGoogleはルールベースからAIに移行したのか」を考えてみます。
これはMagikaに限らず、自分たちのサービスにも応用できる考え方です。
従来のlibmagicは、専門家が手書きしたルール(handcrafted rules)の集合体です。
このアプローチには根本的な限界があります。
- スケーラビリティの問題: ルールが増えるほど相互干渉のリスクが増す
- メンテナンスコスト: 新フォーマット対応のたびに専門家の手作業が必要
- 精度の天井: テキストベースの類似フォーマットの区別が構造的に困難
- 偽装耐性の低さ: ルールのパターンが既知なので、回避が容易
Googleがこれを捨ててディープラーニングに移行した判断軸は、「ルールのメンテナンスコストがモデル再学習コストを上回ったとき」だったと推測できます。
大規模データセットで学習させたモデルは、人間が書けるルール数を遥かに超えるパターンを学習しています。
しかもGeminiで合成データを生成することで、レアなファイル形式のトレーニングデータ不足も解消しています。
「ルールのメンテナンスを人間からAIに委譲した」と捉えることもできますね。
自社サービスでMagika導入を判断するチェックリスト
「うちのサービスでもMagikaを使うべきか?」を判断するためのチェックリストを整理してみました。
- ユーザーからのファイルアップロードを受け付けているか?
- 拡張子やMIMEタイプだけでファイル検証をしていないか?
- ファイルの種類によって処理を分岐させているか(PDF→テキスト抽出、画像→リサイズ等)?
- ファイルアップロード経由のセキュリティインシデントを過去に経験したか?
- 処理するファイル数が多く、手動でのチェックが追いつかないか?
3つ以上該当するなら、Magikaの導入を検討する価値があります。
導入の敷居は低いです。
pip install magikaで入るので、まず既存のバリデーションロジックに追加する形で試してみるのがいいでしょう。
いきなりlibmagicを置き換えるのではなく、libmagicの結果とMagikaの結果を突き合わせて不一致を検出するという併用パターンから始めるのが安全です。
まとめ——Google Magikaを今すぐ試すべきか?
結論から言うと、ファイルアップロード機能を持つサービスを運用しているなら、今すぐ試す価値があります。
理由をまとめます。
- Googleが週数千億ファイルの処理で実証済み
- 99%の精度で200種類以上のファイルタイプを識別
pip install magikaでインストールできる手軽さ- Rust版は1ファイルあたり5ms以内、1,000ファイル/秒の処理速度
- Apache 2.0ライセンスで商用利用も問題なし
- VirusTotal・abuse.chとの連携実績あり
ただし、万能ではないです。
パッキングされたマルウェアの内部構造は見抜けないし、暗号化されたファイルの元タイプも推定できません。
あくまでセキュリティの「第一防衛線」として、既存のツールと併用する形で導入するのがベストです。
個人的に一番印象的だったのは、Googleが「handcrafted rulesの限界をAIで超える」という判断を下し、しかもそれをOSSとして公開したことです。
これはセキュリティツールの民主化とも言えるし、エンジニアにとっては「ルールベースをAIに移行するタイミングの判断基準」を学べる実例でもあります。
まずは手元のファイルでmagika -rを走らせてみてください。
「あれ、このファイル、拡張子と中身が違う……?」という発見が、セキュリティ強化の第一歩になるはずです。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 4
- 0
-
- 2
- 0
-
- 2
- 0
-
プロンプト画伯
- 5
- 0
-
- 3
- 0
-
AI集客@ルイ
- 4
- 0
-
AI脱社畜
- 4
- 0
-
- 3
- 0
-
- 1
- 0
-
- 2
- 0
-
- 3
- 1
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 2
- 0
-
- 4
- 1
-
- 2
- 1
-
- 26
- 1
-
カイ@プロダクトマネージャー
- 3
- 0
-
AI経営者の参謀@ひで
- 4
- 0
-
- 1
- 0
-
- 2
- 0














AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます