
こんにちは。プロンプト画伯です。
元デザイナー、今はAI画像職人として「センスじゃない、言語化だ」をモットーに、毎日プロンプトを掘り下げています。
今日は、GPT Image 2とCodexを組み合わせた images-taste-skill で、画像生成からウェブサイト構築までを全自動化する話を書きます。
「画像は作れる、でもサイトにはできない」——これ、地味に一番しんどいやつじゃないですか。
せっかく2時間かけていい感じのビジュアルを作っても、SNSに投稿して終わり。
Figmaに貼ってもコードに落とすところでエンジニアを挟まないと進まない。
ノーコードツールを学ぼうとして、その操作を覚えるだけで1週間消えていく。
このもやもやを、たった1つのスキル集が丸ごと解決してくれました。
それが Leon Lin(@LexnLin)さんが公開している images-taste-skill です。
GPT Image 2がCodexに統合された今、画像生成から本物のウェブサイト構築まで、全部プロンプトだけで完結するようになったんだよね。
実際に試したので、手順と「何が効くのか」を画像職人の目線で全部書き起こします。
そもそも「images-taste-skill」って何?
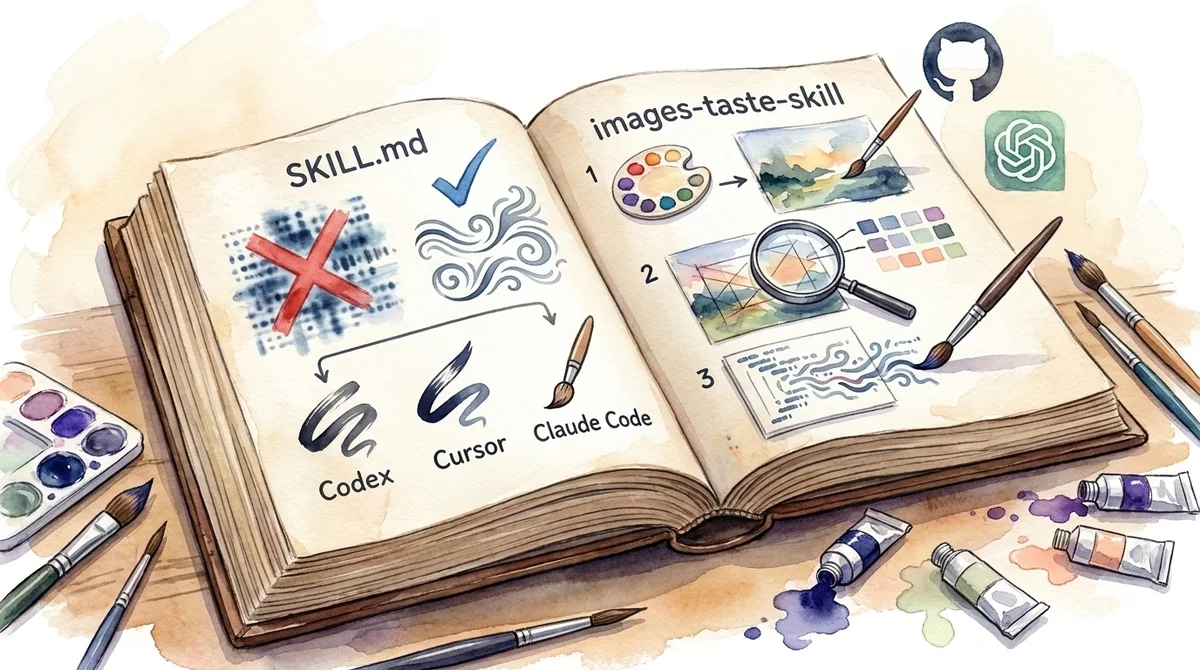
まずネタ元から整理します。
images-taste-skill は、GitHubで公開されているOSS taste-skill のバリアントです。
本家リポジトリはこちら。
執筆時点で スター11.9k / フォーク1.1k という、AIフロントエンド界隈ではかなり効いている規模のプロジェクトです。
taste-skillとは「AI生成UIのダサさ」を殺すためのスキル集
taste-skill の目的を一言でいうと、「AIが吐く、あの"AI臭いジェネリックUI"を根絶する」ためのルール集です。
Claude Code・Cursor・Codex系のAIコーディングエージェントが自動で読み込む SKILL.md というMarkdownファイルが中核で、インストールしておくとAIが勝手にそのルールに従ってくれます。
作者のLeonさんが面白いことを言っていて、Anthropicが公開しているClaude Code向けのフロントエンドデザインスキルには「pick an extreme aesthetic(極端な美学を選べ)」とか「be creative(創造的であれ)」みたいな抽象的な指示が並んでいるんです。
でもLLMって、ざっくり指示されると統計的に「平均的な答え」を返してくるんですよね。
だから抽象的な指示だけだと、結局「どこかで見たことあるAI UI」に収束しちゃう。
「じゃあ厳密なルールで縛れば、平均値から脱出できるよね」という発想で作られたのが taste-skill です。
センスを語らずに、禁止事項と手順で縛る。
このアプローチ、画像プロンプトで苦しんだ人間にはめちゃくちゃ刺さる考え方でした。
masterpiece, best quality だけ書いて祈るのをやめて、構図・光源・レンズを全部指定するタイプのプロンプトと、まったく同じ発想です。
images-taste-skillは「画像ファースト」特化のバリアント
taste-skill には複数のサブスキルがあって、その中の1つが images-taste-skill です。
これは「視覚品質が最優先のとき」に使う設計で、特徴は以下の3ステップを強制すること。
- 画像を先に生成する
- その画像を深く分析する
- 分析結果に忠実にコードを書く
この順序、当たり前っぽく聞こえるんですけど、普通にCodexやClaude Codeにサイト作ってと頼むと、いきなりHTMLから書き始めるんですよ。
画像を見ずにコードを書くから、ビジュアルが「AIっぽい」平均顔になる。
images-taste-skill は、この悪癖を構造ごと封じにきてるんです。
次のセクションで、この構造を支えた「GPT Image 2」の話をします。
GPT Image 2 × Codexで何が変わったのか
ここで時事ネタを。
2026年4月21日、OpenAIが gpt-image-2 を発表しました。
そして翌日の4月22日から、ChatGPTとCodexユーザーがWebで利用可能になっています。
GPT Images v2がCodexに統合されて起きた地殻変動
これまでの画像職人の仕事って、だいたいこういう流れでした。
- MidjourneyやGPT Imageで画像を生成
- 画像を保存してFigmaに貼る
- エンジニアに渡す or ノーコードツールで実装
画像を作る環境と、サイトにする環境が完全に分断されてたんですよね。
それが、GPT Image 2がCodex(デスクトップアプリ)に統合されたことで、1つのエージェントの中で
- 画像生成
- 画像分析
- コード生成
が全部完結するようになった。
この統合、エンジニアより「画像を作っている人」のほうが恩恵がデカいと思ってます。
なぜなら、プロンプターが蓄積してきた言語化スキルが、そのままサイト品質に直結するから。
images-taste-skillが「今」ようやく本来の威力を発揮できるようになった理由
ここが、この2つの組み合わせで一番大事なポイントです。
images-taste-skill 自体は、GPT Image 2の統合より前から存在していたOSSです。
ただ、統合前はどうなっていたかというと、「画像生成を別ツール(Midjourney・GPT Image単体)で行い、生成した画像を手動でCodexに渡す」というフローが必要でした。
これだと、images-taste-skill が設計している「画像生成→分析→コード」の3ステップが、ツールの壁をまたいで手動でつながれている状態になる。
同じエージェント内で連続して流れないと、分析の精度が落ちるし、何より「一発で動く」感覚が出ない。
GPT Image 2がCodexに統合されたことで、同じエージェントの中で「生成した画像をそのまま分析する」ことが初めて可能になりました。
これによって、images-taste-skill の3ステップがシームレスに、かつ1回のプロンプトで走るようになったんです。
道具(GPT Image 2のCodex統合)が先に完成を待っていた設計が、ようやく本来の形で動き出した——そういう構図だと思ってます。
「画像 → 分析 → コード」の3ステップが勝手に走る、その意味が分かるのが次です。
「画像 → 分析 → コード」の3ステップが勝手に走る
images-taste-skill を入れた状態でCodexに依頼すると、内部でこの順序が強制されます。
運用のコツとして、プロンプトに次の一文を添えるとさらに効きます。
follow rules strictly and generate images, then analyze, then codeこれを書いておくと、Codexが「先にコード書こうかな」という誘惑に負けず、画像生成→分析→実装の順を守ってくれるんです。
AIがサボらないように手綱を握る一文。
画像生成でネガティブプロンプトを書き慣れた人間なら、この発想はすぐ入ると思います。
ここまでが「なぜ効くのか」の話。次はいよいよ実際に手を動かしてみた話です。
実際に使ってみた:GPT Image 2 × Codexで画像生成からサイト構築するまで

ここから実践編です。
GPT Image 2 × Codex で、ウェブサイトを自動構築するやり方を、手順で追っていきます。
事前準備:Codexとスキル追加(3分で終わる)
必要なものは2つだけ。
- OpenAI Codex(デスクトップアプリ、macOS/Windows)がインストール済みのこと
- Node.js環境(
npxコマンドが使える状態であること)
スキル追加は、ターミナルでワンライナー。
npx skills add https://github.com/Leonxlnx/taste-skillこれだけで taste-skill と images-taste-skill を含む全スキルが、Codexが読み込むディレクトリに配置されます。
Codexを再起動すれば、そこに SKILL.md があるだけで自動で反応してくれます。
「設定画面を開いて何かを有効化する」みたいな儀式は不要で、ファイルを置くだけ。
この軽さ、画像プロンプトを管理している感覚に近くて好きなんだよね。
3分で終わったら、次がいよいよ本番です。
Step 1:GPT Image 2でサイトの「見た目」を生成する
Codexに対して、まずサイトの見た目を作らせます。
ここは画像生成の腕の見せどころです。
試しに書いたプロンプトがこちら。
Build a landing page for a Japanese ceramic tableware brand.
Hero section: large editorial typography, generous whitespace,
one dominant high-resolution product photo on the right.
Palette: off-white, deep indigo, warm beige.
No gradient overlays, no floating orbs, no futuristic shapes.
Follow images-taste-skill rules strictly.
Generate images first, then analyze, then code.ポイントは3つです。
- 構図(ヒーロー左右、余白の取り方)を具体的に指示
- パレット(色)を3色までに絞る
- 禁止事項を明記(グラデ・浮遊球体・未来風装飾)
images-taste-skill 側にも禁止パターンは書かれていますが、プロンプトで二重にガードをかけると事故率がガクッと下がります。
出てくる画像は、AWWWARDSに出てくるようなエディトリアル系。
「あ、これサイトに使えるやつだ」という品質で出てきます。
Step 2:Codexが画像を分析する(ここが本番)
ここが一番アツいポイントです。
画像が生成されたあと、Codexは勝手にその画像を「読み解く」工程に入ります。
読み取るのは、だいたい以下の要素。
この5項目がそのままStep 3のコードに反映される設計になっています。
これ、めっちゃいい仕組みじゃないですか。
画像生成を仕事にしてきた人なら気づくはずなんですが、このCodexの分析フロー——Midjourneyで山ほど生成した中から「これだ」と選ぶときの脳内処理と、構造が完全に同じなんです。
色の比率、余白の呼吸、視線の流れ。
プロンプターが暗黙知として持っているそのセレクション基準を、Codexが代わりに言語化して、そのままコードに反映してくれる。
つまり、プロンプターの暗黙知が、Codexに外注できるようになったということ。
画像プロンプトを磨いてきた人間には、ここが「あ、俺の仕事が広がった瞬間だ」と感じるポイントだと思います。
Step 3:Codexが忠実にコード化してサイトが建つ
分析が終わると、Codexは抽出したデザイン言語に従ってHTML/CSS(要望次第でNext.jsやReact)を吐き出します。
images-taste-skill が効いている状態だと、コードが「画像に寄せようとしてくる」んです。
具体的には、
- 画像で使っていた余白を、CSSの
gapやpaddingにそのまま反映 - タイポの階層を、
font-weightとline-heightの差で再現 - 禁止されているグラデや浮遊装飾を、こちらから頼んでもコードに書かない
この「画像に忠実」な姿勢、普通のCodexだと絶対に出てこないんですよ。
いつもなら「Bootstrapで整えときました」みたいな妥協コードが出てくるところを、画像のデザイン言語を崩さずに持ってくる。
出力されたサイトをブラウザで開いて、Step 1の画像と並べてみたとき、「同じ人がデザインしたサイト」として成立していました。
「なんでこういう差が出るのか」が気になった方は、次のセクションで詳しく解説します。
「AI臭いUI」と「images-taste-skillで作ったUI」の違い

AIでサイト作ると、だいたい「あ〜AI生成ですね」って分かるやつが出てきますよね。
ここの差がどこから来ているのか、言語化します。
よくある「スロップUI」が出る原因
AI生成のあるあるを挙げると、
- 紫〜青のグラデーションが背景全面に貼られている
- ヒーローに意味もなく浮遊する球体がある
- セクションがぜんぶ中央揃え
- カードが3列きっかりで繰り返される
- 「革新的」「シームレス」みたいな陳腐コピーが並ぶ
これ、全部 images-taste-skill の 禁止リスト に載ってます。
逆にいうと、世のAI UIはことごとくこの禁止パターンを踏み抜いている。
原因はシンプルで、LLMが「統計的に多いパターン」を返すからです。
抽象的な指示でUIを頼むと、学習データに多かった「無難なAIサイト」に収束する。
画像生成でも全く同じ現象があるんですよね。
「美しい女性」だけで指示すると、どこかで見た平均顔しか出てこない。
プロンプトの粒度が足りないと、AIは平均値を返してくる。
これは技術的な限界じゃなくて、言語化の解像度の問題です。
images-taste-skillが埋める「禁止パターン」
images-taste-skill の SKILL.md を読むと、禁止パターンがかなり細かく並んでいます。
抜粋するとこんな感じ。
ここが地味にすごいんですよ。
数値の基準が8項目にわたって定義されていて、特に核になるのがこの4つです(抜粋)。
- デザイン多様性: 8/10
- ビジュアル密度: 4/10(開放的に)
- 実装明確性: 9/10(開発者が再現できる水準)
- 画像使用優先度: 9/10
「センスで頑張れ」じゃなくて「このルールを守れ」という命令形で勝負しているから、成果物がブレないんです。
つまり、これは「AIにデザインの言語化を強制するルール集」です。
画像生成で言えば、 masterpiece, best quality だけ書いて祈るのをやめて、構図・光源・レンズを全部指定するタイプのプロンプトに近い。
この構造が分かると、次の「なぜ画像職人向けなのか」がすんなり入ってくると思います。
画像生成を仕事にしている人こそ、これを触るべき理由
最後に、なぜこれが「画像職人向け」なのかを書いておきます。
コーディング知識ゼロでも動く
このフロー、HTMLもCSSも書けなくて成立します。
ノーコードツール(Wix、Studio、STUDIOなど)と違うのは、学習コストの対象が変わるところ。
ノーコードは「ツールの操作」を覚える必要がありますが、 images-taste-skill は「プロンプトの言語化」を深めるだけでいい。
画像生成で鍛えてきた言語化スキルが、そのまま転用できるんです。
「ツールを覚える時間」と「言語化を深める時間」、どっちが自分の資産になるかと言われたら、後者だと思うんですよね。
プロンプターの仕事が「画像→サイト完成」まで伸びた
今までの「プロンプター」のアウトプットは、だいたい画像1枚かPSD素材までで止まっていました。
納品先はSNSバナーかサムネイル、あとはFigmaのモックアップ用の素材。
それが、 images-taste-skill × Codexによって、成果物が「実際に動くウェブサイト」まで拡張されます。
これ、仕事の射程が変わるってことです。
- LP制作の単価: 画像素材だけより、サイトまで完成させるほうが圧倒的に高い
- クライアントが納得する完成品: 画像だけより、URLで見れるサイトのほうが説得力が出る
- Vibe Codingの文脈: 「雰囲気で作って動かす」時代に、画像プロンプトの精度が勝負を決める
画像職人の肩書きが、そのまま「サイトまで作れる人」に更新される。
画像で言語化を磨いてきた人間には、これは追い風以外の何物でもないです。
まとめ:GPT Image 2 × images-taste-skillで、画像職人の仕事がウェブサイト構築まで広がった
改めて整理すると、
images-taste-skillは、AIの「平均的なUI」を禁止ルールで縛るOSS- GPT Image 2がCodexに統合されたことで、画像生成→分析→実装が1つのエージェントで完結するようになった
- 画像職人が持っている「言語化スキル」が、そのままサイト品質を決める武器になる
センスじゃない、言語化だ、を何度でも言いたくなる展開でした。
絵心ゼロだった僕がプロンプトを極めて画像を作れるようになったのと同じで、コードを書けない人間でも、言語化を極めればサイトが作れる時代です。
まずは npx skills add https://github.com/Leonxlnx/taste-skill の1コマンドから試してみてください。
設定ファイルをいじる必要もなく、3分で準備が整います。
画像プロンプトの腕が、そのままサイトのクオリティに直結する感覚を、ぜひ自分の手で体験してほしい。
次は、プロンプト画伯が実際に使っている「サイト生成用の画像プロンプトテンプレート集」を掘り下げていく予定です。
また会いましょう。
- 4
- 0

元デザイナー → AI画像職人。絵心ゼロだったけどプロンプト極めたらなんとかなった。「センスじゃない、言語化だ」 使えるプロンプト&失敗例を晒していく




こちらもおすすめ
-
コードを読まないAIエンジニア
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます