こんにちは。もるふぉです。
今回は 12-factor-agents を解説します。LLMエージェントを「本番で本当に使えるソフトウェア」にするための12個の設計原則をまとめたGitHubリポジトリで、GitHubスター2万超え、いまAIエージェント界隈で最も読まれているドキュメントのひとつです。
「デモは完璧に動いたのに、本番に出した途端、壊れる」——AIエージェントを触ったことがある人なら、この感覚に覚えがあるんじゃないでしょうか。
問題は実装の腕ではなく、設計のアプローチそのものです。12-factor-agentsは、そのモヤモヤにものすごくキレのいい答えを出しています。「名前は聞いたことあるけど中身は読んでない」という人がめちゃくちゃ多いので、この記事で12原則を「現場でやりがちな失敗 → どのFactorで直せるか」という実装改善の視点で一気に整理していきます。
12-factor-agentsとは何か

まず結論から言うと、12-factor-agentsは「AIエージェントを魔法の自律エージェントだと思うのをやめて、ちゃんとしたソフトウェアとして設計し直そう」という主張の集合体です。
ここがこのドキュメントの一番おもしろいところなんですが、作者は「本番で成功しているエージェントの大半は、実は魔法でも何でもない。要所要所にLLMを慎重に振りかけた、よくできた普通のソフトウェアだ」と言い切っています。エージェント開発の幻想を、いい意味でぶっ壊してくれるんですよね。
なぜAIエージェントは「70〜80%の壁」で止まるのか
12-factor-agentsが繰り返し指摘するのが、いわゆる「70〜80%の壁」です。
何が起きるかというと、こうです。フレームワークを使ってエージェントを組むと、最初はびっくりするほど簡単に動きます。デモなら8割くらいの完成度まですぐ行く。
ところが、残りの2割、つまり「本番顧客の手に渡せる品質」に上げようとした瞬間に地獄が始まります。フレームワークの内部を逆向きに解析して、隠れたプロンプトや制御フローを引っ張り出して……と格闘した挙げ句、結局ゼロから作り直すハメになる。これ、本当に「あるある」なんですよ。
重要なのは、「70〜80%で止まるのはあなたの実装が下手だからではなく、設計のアプローチがそもそも違う」という視点です。12-factor-agentsは、その正しいアプローチを12個に分解して見せてくれます。
元ネタ「Twelve-Factor App」との関係
名前でピンと来た人も多いと思いますが、これはHerokuが2011年に提唱した Twelve-Factor App のオマージュです。
Twelve-Factor Appは「モダンなWebアプリをクラウドで動かすための12の原則」で、設定は環境変数に出す、ログはストリームとして扱う、プロセスはステートレスにする、といった話でしたよね。SaaSを作っているエンジニアなら一度は通る古典です。
12-factor-agentsは、その精神をLLMアプリの世界に持ち込んだもの。「当時Webアプリでやったことを、今度はエージェントでやろう」というわけです。前置きはこのくらいにして、ここからはAIエージェント固有の話にどんどん入っていきます。
作者Dex HorthyとHumanLayer
作者は Dex Horthy さん。AIエージェントを本番運用するためのインフラを手がける HumanLayer の創業者です。
このドキュメントが説得力を持つのは、机上の理論ではなく、100社以上のSaaSビルダーと話して得た実地の知見から生まれているからなんですよね。2025年4月にGitHubで公開され、Hacker Newsのフロントページに掲載されたことで一気に注目を集め、同年6月のAI Engineer World's Fairでの講演でさらに広まりました。
背景がわかったところで、いよいよ12個の中身に入ります。ここからが本題です。
12の設計原則を現場視点で読む
ここからは12のFactorを、AIエージェントの設計原則として一気に見ていきます。
ひとつ先に言っておくと、12個すべてを今すぐ実装する必要はありません。まずは全体像を眺めて、「あ、自分のエージェントこれ守れてないわ」というポイントを見つけてください。特に重要なFactor 2・8・12は少し厚めに解説します。
Factor 1 – 自然言語をツール呼び出しに変換する(Natural Language to Tool Calls)
エージェントの基本動作は「ユーザーの自然言語を、構造化されたツール呼び出し(関数の実行)に変換すること」だ、という原則です。
「APIを叩いて」という曖昧な指示を、{"action": "fetch_data", "params": {...}} のような決定論的に実行できる形に落とす。これがエージェントの一番コアな仕事だと最初に定義してくれます。ここを土台に、残りの11個が積み上がっていきます。
Factor 2 – プロンプトを自分で管理する(Own your prompts)★
個人的に、ここが12個の中で一番効くポイントだと思っています。
多くのフレームワークは「いい感じのプロンプト」をブラックボックスとして内部に持っています。最初は便利なんですが、いざ精度を詰めたいときに「結局LLMにどんなトークンが渡ってるの?」が見えなくて詰む。フレームワークのプロンプトを逆解析する作業、やったことある人いますよね……?
12-factor-agentsの主張はシンプルで、プロンプトはファーストクラスのコードとして自分で持て、です。フレームワーク任せにせず、自分で書いて、バージョン管理して、テストする。
これが地味にすごくて、プロンプトをコードとして扱えると次のことが全部できるようになります。
- LLMに渡る指示を完全にコントロールできる
- プロンプトをコードのようにテストできる
- 精度を見ながら高速にイテレーションできる
- エージェントの挙動が透明になる
「プロンプトなんてただの文字列でしょ」と思うかもしれませんが、エージェントの品質はここで8割決まると言っても過言じゃないです。
フレームワークにプロンプトを握られた状態は、いわばシェフが「食材も調理法もキッチンも全部おまかせ」で料理を作るようなもの。どんなに腕があっても、手が出せなければ味の改善はできませんよね。
Factor 3 – コンテキストウィンドウを自分で設計する(Own your context window)
LLMに渡すコンテキストを、フレームワーク任せにせず戦略的に設計しろ、という原則です。
会話履歴やツールの実行結果を、何でもかんでもコンテキストに詰め込むとLLMは混乱します。必要な情報だけを選び、圧縮して渡す。「LLMに何を見せて、何を見せないか」を握るのは開発者の仕事だ、という話です。
コンテキストの設計は、Factor 2のプロンプト管理と表裏一体です。「何を渡すか」と「どう指示するか」の両方を握ってはじめて、LLMの挙動をコントロールできます。
Factor 4 – ツールは構造化出力に過ぎない(Tools are just structured outputs)
「ツール」と言うと何か特別な能力のように聞こえますが、実態はLLMが出力するJSON(構造化データ)に過ぎない、と捉え直す原則です。
ツールを「魔法の機能」ではなく「決まったスキーマの出力」だと考えると、設計がグッとシンプルになります。LLMはあくまで「次に何をすべきか」を構造化して吐き出すだけ。それを実際に実行するのはあなたのコードです。
この視点が腹落ちすると、「LLMが変なツールを選んでしまう問題」がスキーマ設計の問題として扱えるようになります。テストもしやすくなりますし、デバッグの糸口が掴みやすくなります。
Factor 5 – 実行状態とビジネス状態を一元管理する(Unify execution state and business state)
エージェントの「実行状態(今どのステップか)」と、アプリの「ビジネス状態(注文データなど)」を別々に持つと整合性が崩れます。これらを一元的に管理しよう、という原則です。
「実行状態はエージェントフレームワーク内、ビジネス状態はDB」と別々に管理していると、途中で落ちたときに両者のズレが生じて修復不能になります。一元管理すると、再開や監査もシンプルになります。
Factor 6 – 起動・一時停止・再開をAPIで制御する(Launch/Pause/Resume with simple APIs)
エージェントの処理を、シンプルなAPIで起動・一時停止・再開できるように設計しろ、という原則です。
長時間動くエージェントや、途中で人間の承認を待つエージェントでは、「いったん止めて、あとできれいに再開する」が必須になります。これができないエージェントは「一発勝負の処理」でしか使えない。Factor 8とも密接につながってきます。
Factor 7 – 人間への確認もツール呼び出しで実装する(Contact humans with tool calls)
「人間に確認を取る」という動作を、特別扱いせず、ほかのツール呼び出しと同じ仕組みで実装しろ、という原則です。
たとえば「この内容で本番デプロイしていいですか?」という確認を、Slackに投げるrequest_human_approvalというツール呼び出しとして扱う。作者のHumanLayerがまさにこれを製品化しているだけあって、Human-in-the-Loopの設計思想がきれいに整理されています。
「承認フローは専用UIを作るもの」と思い込みがちですが、ツール呼び出しとして統一すると既存の制御フローにそのまま乗れます。Factor 6・8と組み合わせると、人間の承認待ちを含む長時間プロセスが一気に書きやすくなりますよ。
Factor 8 – 制御フローを自分で握る(Own your control flow)★
ここも超重要です。Factor 2と並んで、僕が「まずここから直せ」と言いたいFactorです。
何が問題かというと、多くのフレームワークは「ツールを選ぶ → 即実行する」というループを内部で勝手に回します。この「選ぶ」と「実行する」の間に割り込めないのが致命的なんですよ。
その結果、開発者はこんな三択を迫られます。
- メモリ上で止めて待つ(途中で落ちたらデータが消える)
- リスクの低いタスクしかエージェントにやらせない
- 危険な操作も人間のレビューなしで実行させてしまう
どれも嫌ですよね。そこで12-factor-agentsは、制御フローを自分で書けと言います。ツール呼び出しの種類によって、処理を出し分けるイメージです。
if tool == "deploy_production":
# 高リスク → いったん中断して人間の承認をWebhookで待つ
pause_and_wait_for_approval()
elif tool == "fetch_data":
# 低リスク → 結果をコンテキストに足して即続行
append_result_and_continue()高リスクな操作は「中断して待つ」、低リスクな取得は「そのまま続行」と、自分で制御ロジックを持つ。こうすると、危険な操作の前に人間が止められるし、途中で落ちても再開できる。フレームワークの暗黙ループに乗っかるのをやめた瞬間、エージェントは一気に安全で運用しやすくなります。
Factor 9 – エラーはコンテキストに圧縮して渡す(Compact Errors into Context Window)
エラーが起きたとき、スタックトレースを丸ごとLLMに渡すと、コンテキストを圧迫するうえに混乱の元になります。
そうではなく、エラー情報を要約・圧縮してからコンテキストに入れろ、という原則です。「何が失敗したか」をLLMが理解できる粒度に整えてあげると、自己修復(リトライ)の精度が上がります。
スタックトレース100行をそのまま渡すのと、「fetch_dataが404を返した」という1行を渡すのとでは、LLMのリカバリ品質がまるで違います。エラーハンドリングはLLMに渡す情報設計の問題でもあるんですよね。
Factor 10 – エージェントは小さく絞り込む(Small, Focused Agents)
「何でもできる万能エージェント」を作ろうとすると、だいたい失敗します。
タスクを絞った小さなエージェントを複数組み合わせるほうが、テストしやすく、デバッグしやすく、精度も安定する。マイクロサービスの発想に近いですね。1つのエージェントに役割を詰め込みすぎないのがコツです。
「万能エージェントを1つ作る」より「得意分野を持つ小さなエージェントを束ねる」ほうが、結果的に速く本番化できます。最初から完璧な1体を目指すのをやめるだけで、デバッグの速度は劇的に変わりますよ。
Factor 11 – どこからでもトリガーできる設計にする(Trigger from anywhere)
エージェントを「チャット画面の中の住人」に閉じ込めるな、という原則です。
Slack、メール、Webhook、cronなど、いろんなトリガーから起動でき、ユーザーがいる場所に結果を返せるようにする。「ユーザーがいる場所で会え(meet users where they are)」というメッセージが、いかにもプロダクト視点で好きなんですよね。
実際の業務では、チャットUIからではなく既存のSlackや社内ツールから呼び出したい場面のほうが多い。最初からトリガーを汎用化しておくと、エージェントの活用範囲が一気に広がります。
Factor 12 – ステートレスなReducerとして実装する(Make your agent a stateless reducer)★
最後は、ちょっと頭のいいエンジニアがニヤッとするやつです。
エージェントを「(現在の状態, 入力イベント) → 新しい状態」を返す純粋関数、つまりステートレスなReducerとして設計しろ、という原則です。ReduxのreducerやLispのfold(畳み込み)を知っている人なら、一発で腹落ちすると思います。
何が嬉しいかというと、エージェントが状態を内部に抱え込まなくなるので、
- 同じ入力なら必ず同じ出力になる(予測可能)
- 純粋関数なのでユニットテストが書きやすい
- 状態遷移を1つずつ追えるのでデバッグしやすい
つまり「エージェント=普通のソフトウェア」という、このドキュメント全体の主張がきれいに収束する原則なんです。作者自身は「これはちょっとお遊び的」とも言っていますが、考え方としては超強力です。
「エージェントは難しいもの」という先入観が、この原則でスパッと切れる感覚があります。普通のユニットテストが書けて、再現テストが書けて、デバッグできる——それだけで、エージェントの品質保証が一気に現実的になるんですよ。
12-factor-agents:今すぐ着手すべきFactorはどれか
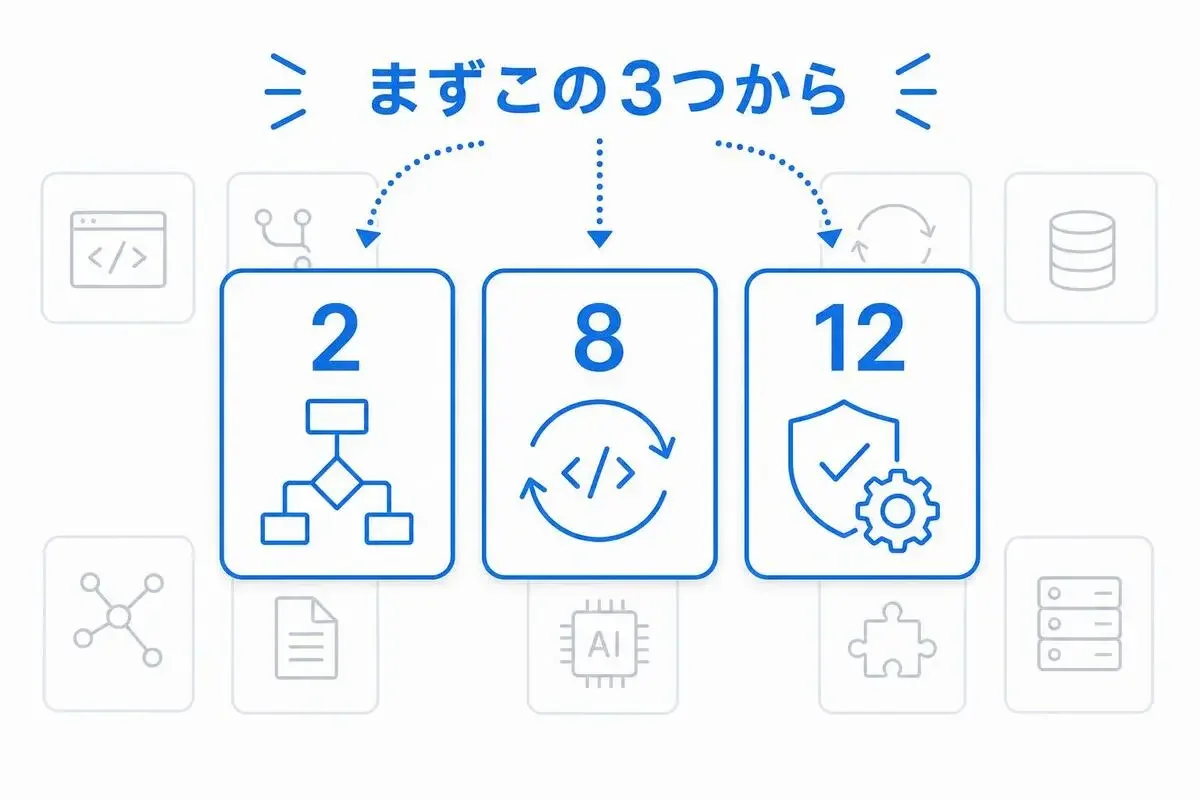
ここまで12個見てきて、「全部やるの無理では?」と思いましたよね。わかります。なので優先度の話をします。
よくある失敗パターンと対応するFactor
現場でよく見る失敗と、それを直すFactorを対応表にしました。自分のエージェントに思い当たるものがないか、チェックしてみてください。
既存フレームワーク(LangGraph・AutoGen等)利用者が意識すべき3原則
ここ、誤解してほしくないんですが、12-factor-agentsは「フレームワークを捨てろ」とは言っていません。僕もそう読んでいません。
LangGraphやCrewAI、あるいはAutoGen(2025年にメンテナンスモードへ移行)のようなフレームワークを使っていても、抜け落ちやすい観点を補うチェックリストとして使うのが正解です。フレームワーク活用者が特に意識すべきは、この3つ。
- Factor 2(Own your prompts): フレームワークのデフォルトプロンプトに頼り切らず、本番品質を狙うなら自分のプロンプトに差し替える前提で設計する
- Factor 8(Own your control flow): 暗黙のエージェントループに乗るだけでなく、危険な操作の中断ポイントを自分で持つ
- Factor 12(Stateless reducer): 状態をフレームワークに丸投げせず、(状態, イベント)→新状態で考える癖をつける
逆に言うと、まずこの3つだけ意識すれば、エージェントの本番化率はグッと上がります。LLMエージェントの本番設計でつまずく原因の多くは、この3点に集約されます。
12-factor-agents設計チェックリスト
最後に、自分のエージェントを点検するためのチェックリストを置いておきます。手元のプロジェクトを思い浮かべながら、YES/NOで見ていってください。
- プロンプトを自分でコードとして管理し、テストできているか(Factor 2)
- コンテキストに何を入れて何を入れないか、自分で設計しているか(Factor 3)
- ツールを「LLMの構造化出力」として捉えられているか(Factor 4)
- 実行状態とビジネス状態が一元管理されているか(Factor 5)
- エージェントを途中で止めて、きれいに再開できるか(Factor 6)
- 人間への確認をツール呼び出しとして実装しているか(Factor 7)
- 危険な操作の前に割り込める制御フローを自分で持っているか(Factor 8)
- エラーを圧縮してLLMに渡しているか(Factor 9)
- エージェントの役割を小さく絞れているか(Factor 10)
- チャット以外の場所からも起動・応答できるか(Factor 11)
- (状態, イベント)→新状態のステートレスな構造になっているか(Factor 12)
全部YESなら、あなたのエージェントはかなり本番に近いです。NOが多くても落ち込まないでください。むしろ「伸びしろが可視化された」と捉えるのが正解です。
まとめ
12-factor-agentsの核心は、最初に言ったこの一言に尽きます。「AIエージェントを魔法だと思うのをやめて、ちゃんとしたソフトウェアとして設計しよう」。
70〜80%の壁にぶつかるのは、あなたの腕が悪いからではなく、設計のアプローチが違うだけ。プロンプトを自分で握り(Factor 2)、制御フローを自分で握り(Factor 8)、ステートレスに考える(Factor 12)。この3つから手をつければ、エージェントは確実に本番へ近づきます。
まずは元のリポジトリを眺めて、自分のエージェントを今回のチェックリストで採点してみてください。「あ、ここ守れてないわ」が1つ見つかれば、この記事の役目は果たせたかなと思います。
それではまた次の記事で。もるふぉでした。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 3
- 0
-
 たく
たく
- 1
- 0
-
プロンプト画伯
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
たく
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 4
- 0
-
- 5
- 0
-
- 3
- 0
-
- 5
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます