
こんにちは。もるふぉです。
最初に結論から言います。これは「AIに書かせたコードを1行も読まないのは危険だ」と警告する記事ではありません。むしろ逆です。
Claude Code や Codex を使っていて、気づいたらAIが書いたコードをほとんど読まなくなっている。そんな自分に「これでいいのか」とモヤモヤしているエンジニアに向けて、「それは手抜きでも無責任でもありませんよ」と腹落ちしてもらうための記事です。
バイブコーディングやAIコーディングで「コードを読まない」現象が、なぜ退化ではなく抽象化の自然な続きなのか。そして読まない代わりに何を読むべきなのか。実践レベルで整理します。
念のため言っておくと、自分は「読む派」を雑に煽るつもりはありません。後半では読む派の最強の反論、つまり負債化・オンコール・責任に、一つひとつ正面から答えます。読むべきだと考えている人ほど、最後まで読んでほしい内容です。
なぜ今「1行も読まない」がAIコーディングの現実になったのか
正直に言うと、自分自身もう何ヶ月も、AIが書いたコードの「行」をまともに読んでいません。プルリクの差分を1行ずつ追う、という作業をほぼやめました。
最初は「さすがにマズいかな」と思っていたんです。
でも続けるうちに、これは怠惰でも事故でもなく、エンジニアリングの歴史がずっと繰り返してきたことの延長線上にある、と気づきました。
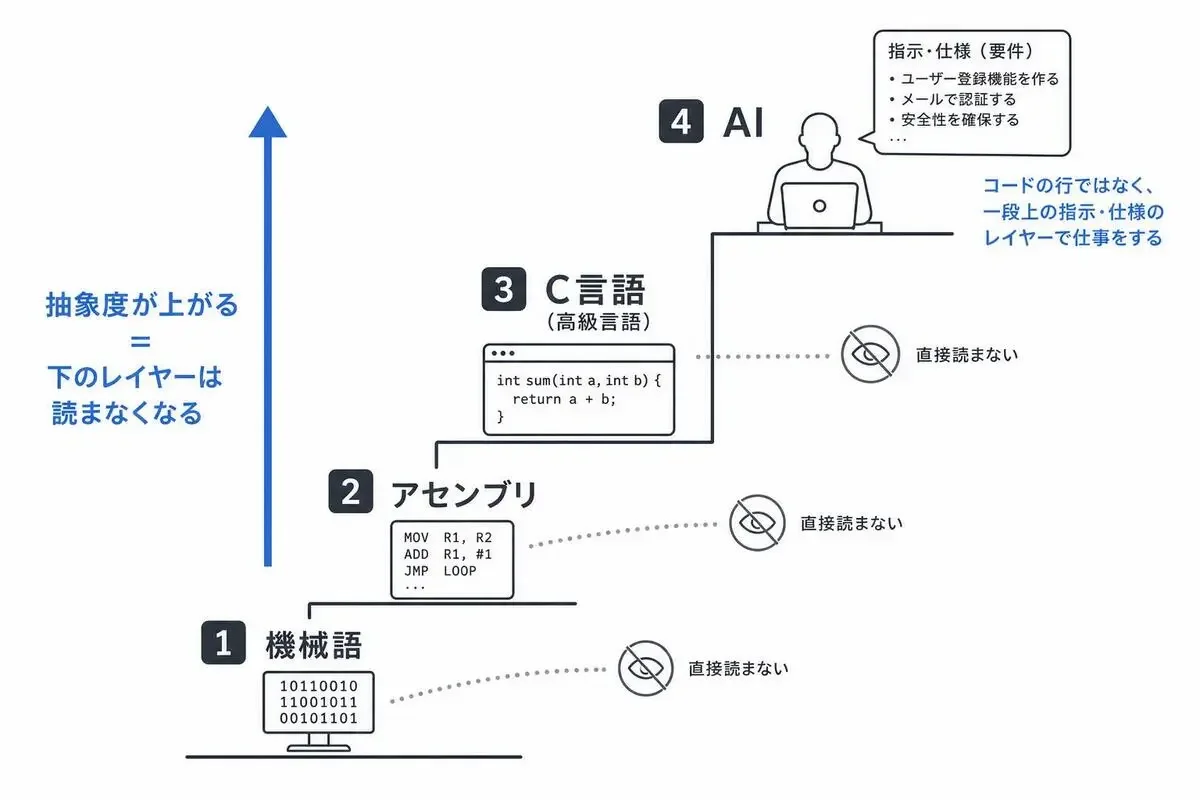
機械語→アセンブリ→Cと同じ、抽象化の続きとして読む
ちょっと歴史を巻き戻します。
その昔、エンジニアは機械語を直接書いていました。10110000 01100001 みたいなビット列です。やがてアセンブリができて、MOV AL, 61h と書けるようになりました。さらにC言語が登場して、char c = 'a'; と書けば済むようになりました。
ここで質問です。今のあなたは、自分の書いたCコードがどんなアセンブリにコンパイルされ、最終的にどんな機械語のバイト列になるか、毎回読んでいますか?
読んでいませんよね。コンパイラを信頼して、出力された機械語は「見ない」。
よく考えるとこれ、すごい話なんです。最終的にCPUが実行するのはあくまで機械語の側なのに、私たちはそっちを読まずに平気で本番リリースしている。「自分が手を下していない下のレイヤーを読まない」のは、AI時代に始まった話じゃない。コンパイラというツールを信頼して、一段上のレイヤーで仕事をする、これをもう何十年もやってきた。
Claude Code や Codex がやっていることは、構造的にはこれと同じです。AIという新しい「翻訳機」が、自然言語に近い指示をコードに変換してくれる。だから私たちは、その下のコードの行ではなく、もう一段上のレイヤーで仕事をするようになった。
「いや、コンパイラは決定論的だけどAIは確率的だろ」というツッコミは正しいです。これは本質的な違いで、後半のガードレールの話と反論への回答で正面から扱います。ここで言いたいのは、「下のレイヤーを読まなくなる」という現象そのものは退化ではなく、抽象化の歴史がずっと繰り返してきたパターンだ、ということです。
「読む対象」がコードの行から一段上の層に移った
ここが今日いちばん伝えたいことです。
「コードを読まない」と聞くと、多くの人は「何も見ていない」「丸投げしている」と解釈します。でも実際に起きているのは、読む対象が一段上のレイヤーに移ったということ。何も見なくなったのではなく、見る場所が変わった。
機械語を読まなくなったエンジニアは、代わりにC言語のソースを読むようになりました。アセンブリのレジスタ操作ではなく、関数とロジックを読むようになった。抽象化が一段上がると、読む対象もまるごと一段上がる。
AI時代も同じです。コードの「行」を読まなくなったエンジニアは、代わりに仕様を読み、テストを読み、型を読み、アーキテクチャの境界を読むようになる。実装の細部はAIに任せて、人間は「このシステムは何をすべきか」「どう振る舞うべきか」という、より高い解像度の判断を担う。
この「読む対象が上がった」というフレームを持っていないと、議論が永遠にかみ合いません。読む派は「コードを読め」と言い、読まない派は「もう読まなくていい」と言う。でも本当の論点は、どのレイヤーを読むかです。
Claude CodeとCodexが変えたコーディングの粒度
少し前までのAIコーディングは、せいぜい関数1個、数行のスニペットを補完してくれる程度でした。だから人間が読んで、つなぎ合わせて、整合性を取る必要があった。「行」を読むのが普通だった。
ところが Claude Code や Codex のようなエージェント型のツールは、扱う粒度がまるで違います。「この機能を追加して」と指示すると、複数ファイルにまたがる変更を一気に書き、テストを走らせ、エラーが出たら自分で直すところまでやる。人間が介入する単位が「行」から「タスク」や「機能」に上がった。
地味にすごいのが、人間が指示を出す粒度と確認する粒度がセットで上がっている点です。「行」を渡して「行」を確認していた時代から、「要件」を渡して「振る舞い」を確認する時代になった。だから「行」を読まなくなるのは、当然の帰結なんですよ。
とはいえ「読まない」という言葉には、まだ大きな誤解が残っています。
「コードを読まない」というバイブコーディングへの最大の誤解を解く
「コードを読まない」という言葉は、ものすごく誤解されやすいです。ここを先に潰しておかないと、この先の話が全部「無責任な奴の言い訳」に聞こえてしまうので、丁寧にいきます。
誤解は大きく3つあります。
読まない ≠ 動作確認しない
いちばん多い誤解がこれです。「コードを読まない=動くかどうかも確かめていない」という解釈。
違います。むしろ逆で、行を読まないからこそ、動作確認はより厳密にやります。
考えてみてください。自分で1行ずつ書いたコードなら、「ここはこう動くはず」という確信が頭の中にあります。でもAIが書いたコードは、その確信がない。だからこそ「本当に意図どおり動くか」を、テストと実際の挙動で確かめる比重がむしろ増えるんです。
私の感覚では、行を読まなくなってから、テストを走らせる回数も、実際にアプリを触って確認する回数もはっきり増えました。読まない分の保証を、別のところで取りにいっている感覚です。
読まない ≠ 振る舞いを理解しない
2つ目の誤解は「コードを読まない=システムが何をしているか分かっていない」というもの。
これも違います。コードの行を読まなくても、システムの振る舞いは理解できます。理解していないと使い物になりません。
たとえば、ある決済処理のコードがあったとして。私は if 文の分岐や変数名を1行ずつ追わなくても、「カード認証に失敗したらどうなるか」「二重決済を防ぐ仕組みはどう入っているか」「リトライはどういう条件で走るか」は説明できます。テストと仕様と実際の挙動から理解しているからです。
「行を読む」ことと「振る舞いを理解する」ことは、実はイコールではないんです。行を全部読んでも振る舞いを理解していない人はいるし、行を読まなくても振る舞いを正確に把握している人もいる。ここを混同すると議論が雑になります。
読まない = コードの行より上のレイヤーを読む
「コードを読まない」の正体は、「コードの行という最下層を読まない代わりに、その上のレイヤーを読む」ということです。
ここで、競合の議論でよく出てくる「理解負債」「認知負債」という概念に触れておきます。AIに書かせたコードを誰も理解しないまま積み上げると、後で誰も手を入れられなくなる、という警告ですね。これは問題提起として完全に正しい。実在するリスクです。
ただ、その負債を返す方法は「全員がコードの行を読み直すこと」ではありません。仕様・テスト・型という上のレイヤーで理解を担保し、後から読んでも振る舞いが分かる状態を維持すること。理解負債への正しい対処は「行を読む」ことへの回帰ではなく、「読む対象を上げたうえで、その上のレイヤーをちゃんと整備する」ことです。
じゃあ、その「上のレイヤー」って具体的に何なのか。1つずつカタログにします。
読まない代わりに「何を見るか」——AIコーディングで上がった先の読む対象
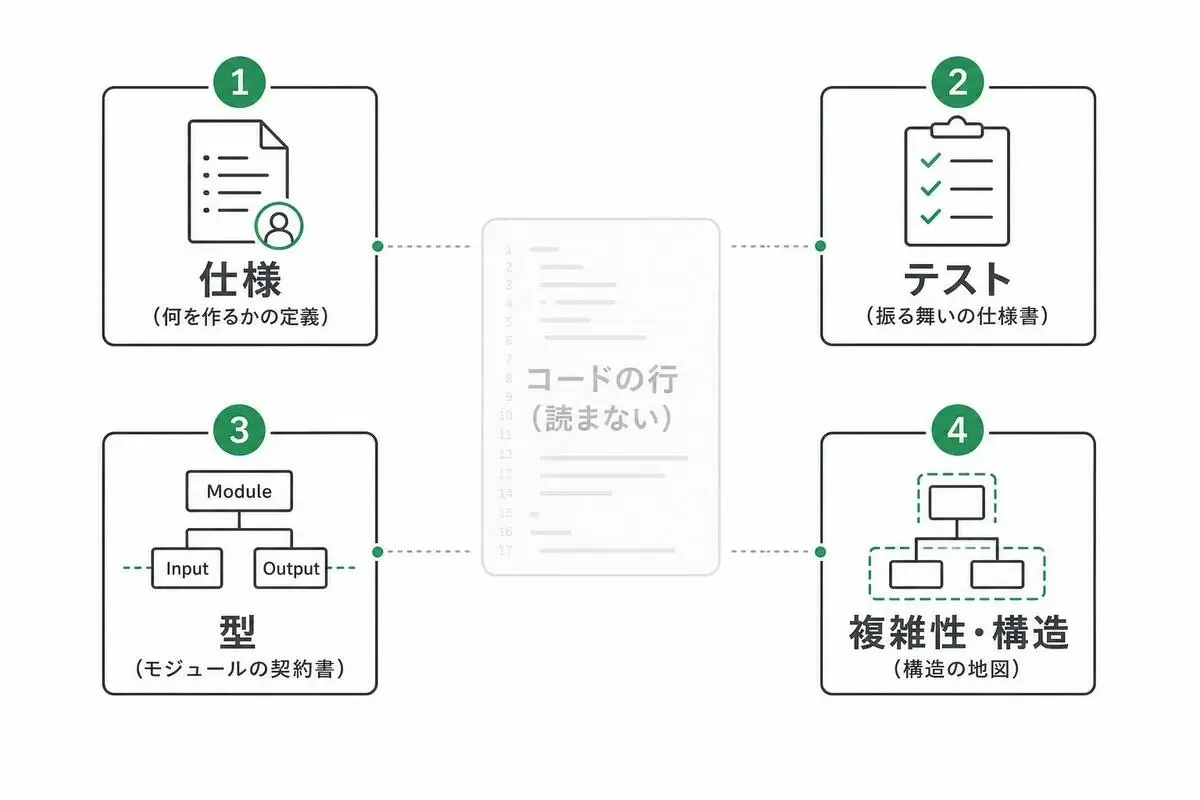
バイブコーディングで「コードを読まない」を実践するうえで、いちばん大事なのがここです。読む対象を上げると言っても、上のレイヤーがスカスカだったら、それはただの丸投げです。
私が実際に「行の代わりに」読んでいる対象を、4つ挙げます。
仕様を読む
まず、仕様です。
AIにコードを書かせる前に、「何を作るのか」を言語化しておく。書かせた後は、「その仕様どおりになっているか」を確認する。読む対象の筆頭はこれです。
ここでいう仕様は、分厚い設計書である必要はありません。「この機能は何を入力に取り、何を出力し、どういうエラーケースを想定するか」が書いてあれば十分です。最近よく聞く仕様駆動開発(Spec-Driven Development)も、根っこはこれです。AIに渡す仕様が曖昧だと、出てくるコードも曖昧になる。逆に仕様がカチッとしていれば、AIの出力もブレません。
行を読まなくなった分、私は仕様を書く・読む時間が確実に増えました。これは責任の所在が「コードを書くこと」から「何を作るかを決めること」に移動した、ということでもあります。
テストを読む(振る舞いの仕様書として)
個人的にここが一番アツいポイントです。
テストは「コードがどう振る舞うべきか」を機械が検証できる形で書いた仕様書です。よく書かれたテストを読めば、そのコードが何をするものなのか、実装の行を読まなくても分かる。
たとえば、こういうテストがあったとします。
describe "出金申請" do
context "残高が申請額以上のとき" do
it "申請を受け付け、ステータスを requested にする"
end
context "残高が申請額に満たないとき" do
it "申請を拒否し、残高不足エラーを返す"
end
context "同一申請が二重に来たとき" do
it "2回目を冪等に無視する"
end
endこのテストを読むだけで、「出金申請がどう振る舞うべきか」が全部分かりますよね。実装の if 文を1行ずつ追う必要はありません。テストが振る舞いを語ってくれている。
だから私は、AIにコードを書かせるとき、テストを「振る舞いの仕様書」として最重要視します。実装は読まなくても、テストは読む。むしろ実装よりテストのほうをじっくり読みます。ここが「行を読まない」運用の心臓部です。
型とインターフェースを読む
型がしっかり付いている言語なら、関数のシグネチャを見るだけで「何を受け取って何を返すか」が分かります。createUser(input: CreateUserInput): Result というシグネチャを読めば、中身を読まなくても、この関数が何をするか・どう失敗しうるかが見えます。
インターフェースや型は、いわばモジュール同士の「契約書」です。実装の中身(行)は契約を果たすための手段にすぎない。契約書さえ読めていれば、手段の細部はAIに任せられる。型はAI時代において、読む対象として価値が上がっていると感じます。
複雑性とアーキテクチャの境界を読む
4つ目、これがいちばん上のレイヤーです。
個々のコードの行は読まなくても、「このモジュールとあのモジュールがどう依存しているか」「責務の境界はどこにあるか」「どこに複雑性が溜まっているか」は読まないといけません。
なぜなら、AIは局所最適は得意でも、システム全体の構造を健全に保つのは苦手だからです。放っておくと、あちこちに似たようなコードが増えたり、依存関係がぐちゃぐちゃになったりする。この「アーキテクチャの腐敗」は、行を読んでも見えません。一段引いて、構造の地図として読む必要があります。
ここはエンジニアの経験がものを言うところです。「この依存の向きはまずい」「ここに責務が漏れている」という嗅覚は、AIにはまだ任せきれない。行を読まなくなったからこそ、構造を読む目に集中できる、とも言えます。
読む対象は分かった。でも鋭い人はこう思っているはずです。「上のレイヤーを読むのは分かった。そもそもAIが下のレイヤーで変なコードを書いてたらどうするの?」と。
AIに低品質コードを書かせない仕組み化
バイブコーディングで「コードを読まない」運用には、前提条件があります。それは、読まなくても済む品質のコードをAIに書かせる仕組みを、こちら側で用意しておくことです。
ここを飛ばして「読まない」だけやると、それはただの無責任になります。読まない自由には、仕組みを整える責任がセットでついてくる。ここは正直に書きます。
CLAUDE.mdで守らせるルールの設計
Claude Code には CLAUDE.md という、プロジェクトの作法をAIに伝えるファイルがあります(Codex なら AGENTS.md が近い役割です)。これが「読まない」運用の生命線です。
ここに何を書くか。たとえば、こんな項目です。
## コーディング規約
- 命名は既存ファイルの慣習に合わせる
- 複雑なロジックを足したら必ず対応するテストを書く
- 外部APIの呼び出しは必ずリトライとタイムアウトを入れる
## 禁止事項
- 既存の公開インターフェースを勝手に変更しない
- テストを通すためにテスト自体を緩めない
## 確認の作法
- 変更後は必ずリンターとテストを実行し、結果を報告するポイントは、「自分がコードの行を読んでチェックしていたこと」を、ルールとして言語化してAIに肩代わりさせる、という発想です。レビューで毎回指摘していたことを CLAUDE.md に書けば、AIが最初からそれを守ってくれる。人間のレビュー観点を、仕組みに移植するわけです。
CLAUDE.md は一度書いて終わりではありません。「あ、またこのパターンでミスったな」と気づくたびに追記して育てていく。これが行を読む代わりの、新しい品質管理の作業です。
コーディング規約とリンターのガードレール
CLAUDE.md のルールは、あくまでAIへの「お願い」です。確率的に動く以上、守らないこともある。だから機械的に強制するガードレールを別途かぶせます。
リンター、フォーマッター、型チェッカー、テスト。これらをCIに組み込んで、規約を満たさないコードはそもそもマージできないようにする。ここが「決定論的な歯止め」です。
さっき「コンパイラは決定論的だがAIは確率的」という違いに触れました。その確率的なブレを、決定論的なガードレールで挟み込んで吸収するわけです。AIが何を書こうと、リンターと型チェックとテストという関所を通らなければ本番に出られない。だから私は、AIの出力という「川の流れ」そのものを1行ずつ見るのをやめて、関所のほうを固くする方向に労力を振っています。
振る舞いテストを先に書かせてからコードを生成させる
これは特に効きます。実装より先に、振る舞いのテストをAIに書かせるんです。
順番はこうです。まず「この機能はこう振る舞うべき」というテストを書かせて、人間がそのテストを読んでレビューする。テストの粒度や観点がOKなら、次に「このテストを通す実装を書いて」と指示する。
何が嬉しいかというと、人間がレビューする対象がテストに集中するんです。実装は全部AIに任せて、人間は「振る舞いの定義」だけをしっかり読む。テストという仕様書を先に固めるので、実装がそこからズレようがない。テストが通れば振る舞いは仕様どおりなので、実装の行を読まなくても安心できる。
「テストを通すためにテストを緩める」という抜け道だけは塞いでおく必要があります(だから CLAUDE.md の禁止事項に入れる)。そこさえ押さえれば、かなり強力なやり方です。
ここまで読んで「なるほど、理屈は分かった」と思ってもらえたかもしれません。でも、「それでもやっぱり読まないのは怖い」という反論には、もっと正面から向き合う必要があります。
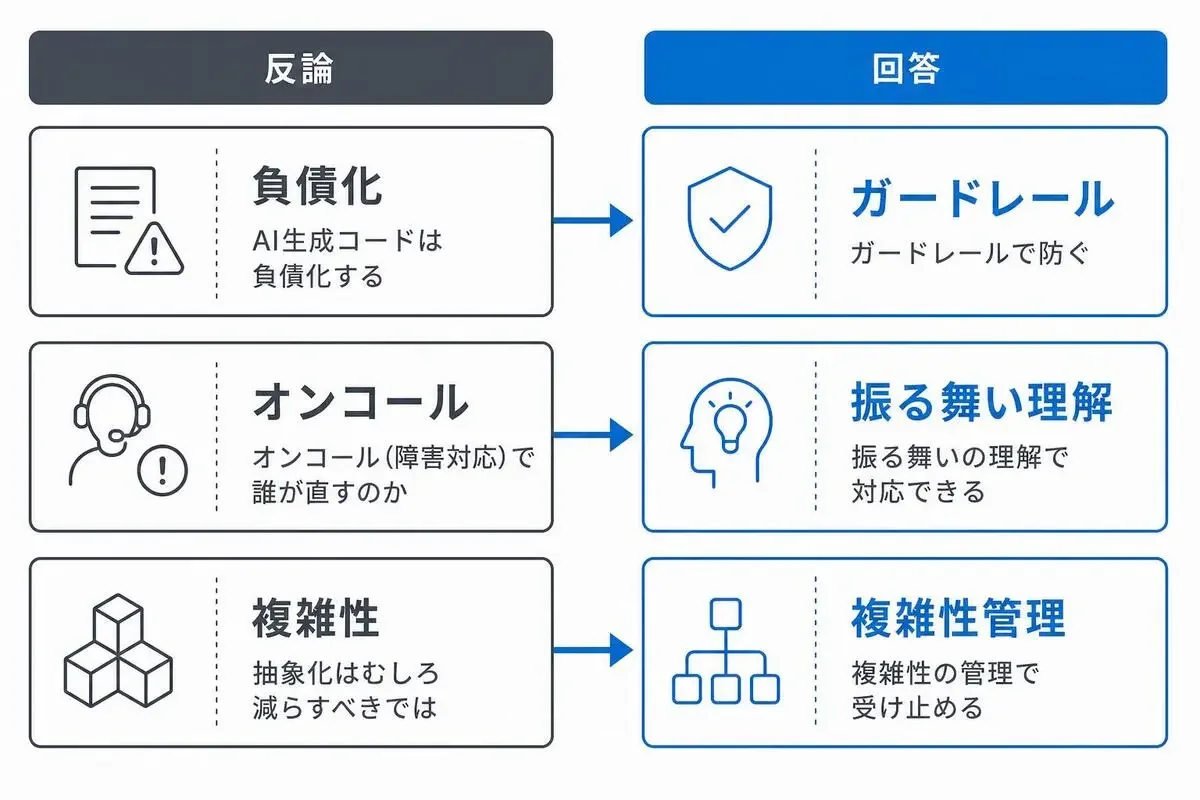
読む派の最強の反論に答える
「コードを読まない」を肯定する記事はたくさんあります。でもその多くは、読む派の反論を「時代遅れ」と切り捨てるか、感情論でかわすだけ。それでは誠実じゃないと思っています。
読む派の反論には、傾聴に値する正論がたくさんあります。現役エンジニアの間で実際に語られている、最も鋭い3つの反論に、逃げずに答えます。
「AI生成コードは負債化する」——ガードレールで防ぐ
「AIに書かせたコードは、誰も理解しないまま積み上がって、いずれ手のつけられない負債になる。実際そういう現場を見ている」というもの。
これは正しいです。反論の余地はありません。何の仕組みもなくAIに書かせ続ければ、コードベースは確実に腐ります。
ただ、ここで論点をはっきりさせたい。負債化するのは「読まないから」ではなく「整備しないから」です。
人間が手書きしたコードだって、テストもレビューも規約もなければ負債化します。逆にAIが書いたコードでも、仕様が明確で、テストが振る舞いを保証し、リンターと型でガードされ、アーキテクチャの境界が守られていれば、後から読んでも理解できる状態を保てる。
負債化を防ぐ手段は「全行を人間が読むこと」ではなく、「読まなくても理解を維持できる仕組みを整えること」です。前の章で書いた CLAUDE.md・ガードレール・テストファーストは、まさにこの反論への具体的な回答です。
「読まないなら、その分だけ仕組みで品質を担保しろ」。この反論は、むしろ追い風です。読まない自由には整備の責任が伴う、という私の主張と、向いている方向は同じなので。
「オンコールのとき誰が直すのか」——振る舞い理解で対応できる
「本番が深夜に落ちた。オンコールで叩き起こされた。コードを読んでこなかった奴に、その障害が直せるのか?」というもの。
これは本当に重い反論です。エンジニアは本番システムに責任を持ち、夜中だろうが障害対応する。その現実を知っている人ほど、この問いは刺さります。
正直に答えます。障害対応に必要なのは「コードの行を読んできたこと」ではなく「システムの振る舞いを理解していること」です。ここを分けて考えないといけません。
深夜の障害対応で実際にやることを思い出してください。まずログとメトリクスを見る。どのコンポーネントで何が起きているか、エラーの種類は何か、いつから始まったか。これは「振る舞い」の話であって、平常時にコードの行を暗記していたかどうかとは別軸です。
むしろAI時代の障害対応は、こう変わります。「この NullPointerException がここで出ているんだけど、原因と修正案を出して」とAIに投げる。AIが原因箇所と修正を提示する。それを人間が「この修正で副作用は出ないか」と判断して適用する。ここで効くのが、振る舞いとアーキテクチャの理解です。「この修正を入れると、あっちの処理に影響が出るな」という判断ができるかどうか。
ただし。ここは正直に認めます。全くシステムを理解せずに「読まない」をやっていたら、オンコールで詰みます。だからこそ、前の章の「複雑性とアーキテクチャの境界を読む」が効いてくる。行は読まなくていい。でも振る舞いと構造は理解していないといけない。「全部AIに任せて何も理解しない」のは、読む派の言うとおり無責任です。
つまりこの反論への答えは、「読まなくても大丈夫」ではなく、「読む対象を行から振る舞いと構造に上げておけば対応できる。逆にそこをサボったら詰む」です。読む派の警告は、ここでは正しく機能しています。
「抽象化はむしろ減らすべきでは」——複雑性管理の視点
これがいちばん知的に手強い反論です。「そもそも抽象化を増やすのが間違いだ。依存を減らし、ベンダリングして、システムをシンプルに保て。AIで複雑性を上塗りするな」という主張。
コンピュータサイエンスと優れたソフトウェアの歴史を踏まえた、極めてまっとうな指摘です。安易に反論できません。
私の立場はこうです。この反論は「抽象化 vs AI」の話ではなく、「複雑性をどう管理するか」の話として受け取るべきだと思っています。
「抽象化を減らしてシンプルに保て」という主張の本質は、「不要な複雑性を持ち込むな」ということですよね。これは100%正しい。AIを使うと、雑に指示するだけで複雑性がどんどん増殖しうる。だから「依存を減らす」「シンプルに保つ」という規律は、AI時代だからこそむしろ重要度が上がる。
さっき挙げた「複雑性とアーキテクチャの境界を読む」が、ここでも効いてきます。行を読まない代わりに構造を読むのは、まさに「複雑性を野放しにしない」ための営みです。AIに任せるからこそ、人間は「この複雑性は必要か」を問い続けないといけない。
だからこの反論への答えは、「抽象化を上げるべきか下げるべきかは、戦う問題による」です。シンプルさを死守すべき場面もあれば、抽象化を一段上げて任せたほうがいい場面もある。大事なのは、どちらの場合も「複雑性を管理する責任」から逃げないことです。
この3つの反論、どれも「だからお前は間違っている」と切り捨てられるものではありませんでした。むしろ全部、私の主張の前提を補強してくれる正論です。読まない自由は、これらの正論に答え続ける責任とセットなんだと、改めて思います。
AI生成コードの時代、エンジニアの価値はどこへ移るのか
ここまでの話を、エンジニアの「価値」という観点でまとめ直します。
「コードを読まなくなる」という変化に不安を感じる根っこには、「じゃあ自分の価値はどこにあるんだ」という問いがあると思うんです。そこに向き合います。
「書く量」から「判断と説明責任」へ
身も蓋もないことを言います。エンジニアの価値は、もともと「コードを書いた量」ではありませんでした。
タイピング量で給料をもらっていたわけじゃない。「この問題をどう解くか」「この設計は妥当か」「このトレードオフをどう取るか」という判断と、その判断に責任を持つことに価値があった。コードを書くのは、その判断を形にする一手段にすぎなかった。
AIが「書く」という手段を肩代わりしたことで、隠れていた本質、つまり判断と説明責任がむき出しになった。書く作業に埋もれていた本来の価値が、前面に出てきたとも言えます。
「なぜこの設計にしたのか」「なぜこの選択をしたのか」を説明できること。AIの出力に対して「これでいい」「これはダメ」と理由つきで判断できること。これが残る価値であり、AIには代われない部分です。
ディレクションと要件定義が主戦場になる
価値の重心が、開発力からディレクションに移ります。
AIにコードを書かせる時代、成果物の質を決めるのは「どれだけうまく書けるか」ではなく「どれだけ的確に要件を定義し、指示を出せるか」です。曖昧な要件を渡せば、AIはそれなりに動くけど的外れなものを返す。要件が研ぎ澄まされていれば、AIの出力も鋭くなる。
これは、ベテランのエンジニアが昔からやってきた「何を作るべきかを定義し、チームに伝える」という仕事が、全エンジニアの主戦場になる、ということでもあります。コードを書く下流工程をAIが担い、人間は上流の要件定義と判断に軸足を移す。「読む対象が上がった」のと同じように、「やる仕事」も上がるんです。
「AIを叱れる人」が希少になる
最後に、これが地味に重要だと思っているポイントです。
AIの出力を見て、「これは違う、こうすべきだ」と理由つきで突き返せる人。これがこれから希少になります。
AIは、それっぽいコードをいくらでも返してきます。動くけど不格好な抽象化、肥大化したコピペ、微妙にズレた実装。これを「それっぽいからOK」と通してしまう人と、「ここがおかしい、こう直せ」と叱れる人の差は、これからどんどん開きます。
叱れるためには、振る舞いを理解し、構造を読み、何が良い設計かの基準を持っていないといけない。この記事でずっと言ってきた「上のレイヤーを読む力」が、そのまま「AIを叱る力」になる。コードの行を読む力ではなく、AIの仕事を評価し、ダメ出しできる力。これが価値の中心に来ます。
「読まない」に移行するAIコーディングの実践ステップ
ここまでの内容を、明日から動ける形に落とし込みます。いきなり全部やる必要はありません。上から順に1つずつで十分です。コピペできるコードブロックも、コマンド数も関係ない。ほぼ「考え方と習慣を変えるだけ」の話です。
Step1: CLAUDE.mdを整備して読む基準を定義する
まず CLAUDE.md(Codex なら AGENTS.md)を用意します。最初は完璧じゃなくていいです。
書くのは、「自分がいつもコードレビューで指摘していること」。命名のルール、テストを必ず書く範囲、禁止事項、確認の作法。レビューで口酸っぱく言っていたことを、そのまま文章にするだけです。これが「人間が読んでいた基準」をAIに移植する第一歩になります。
Step2: 振る舞いテストをAIに先に書かせる
実装より先にテストを書かせる流れを試します。
「この機能の振る舞いをテストで書いて」と指示して、出てきたテストを読む。観点が足りなければ「異常系のケースも足して」と返す。テストがOKになったら、「このテストを通す実装を書いて」と進む。人間が読む対象を、実装からテストに移す練習です。
Step3: 仕様をドキュメントとして管理する
書いたコードの「行」ではなく、「何を作るか」を残す習慣をつけます。
機能ごとに、入力・出力・想定するエラーケースを書き留めておく。仕様駆動開発のような大げさな仕組みでなくてOKです。AIに渡す指示そのものが仕様になるので、その指示を使い捨てにせず、ドキュメントとして蓄積していく。後から「これ何で作ったんだっけ」を行ではなく仕様で追えるようにします。
Step4: 定期的にアーキテクチャの境界を確認する
週に1回でも、コードの行ではなく「構造」を眺める時間を取る。依存関係はおかしくなっていないか、責務が漏れていないか、似たようなコードが増殖していないか。AIは局所最適で構造を腐らせがちなので、ここは人間が定期的にメンテする。行を読まない分の目を、構造に向けるわけです。
Step5: 「なぜそうなっているか」を口頭で説明できるか確認する
これがいちばん大事かもしれません。
自分が関わっている機能について、「なぜこういう設計になっているか」「この処理はどう振る舞うか」を、コードを見ずに口頭で説明できるか試してみてください。
スラスラ説明できるなら、行を読まなくても、あなたはちゃんと理解しています。逆にここで詰まるなら、「読まなさすぎ」のサインです。説明できる範囲を超えてAIに任せていないか、ここでセルフチェックする。この「口頭で説明できるか」が、無責任な丸投げと健全な「読まない」を分ける、いちばんシンプルな線引きだと思っています。
まとめ:コードを読まないのは、抽象化の続きであって退化ではない
- AIにコードを書かせて「行を読まない」のは、機械語やアセンブリを読まなくなったのと同じ、抽象化の歴史の続きです。退化でも手抜きでもありません。
- 読まなくなったのではなく、読む対象が一段上がりました。仕様・テスト・型・アーキテクチャの境界。これが新しい読む対象です。
- ただし「読まない自由」には「仕組みで品質を担保する責任」がセットです。
CLAUDE.md・ガードレール・テストファーストで、読まなくても腐らない状態を作る。 - 読む派の反論(負債化・オンコール・複雑性)は、どれも正論です。そしてそのどれにも、「読む対象を上のレイヤーに上げる」ことで答えられます。逆にそこをサボれば、読む派の言うとおり詰みます。
- エンジニアの価値は、もともと「書く量」ではなく「判断と説明責任」にありました。AIはその本質をむき出しにしただけです。
念のため。AIにコードを書かせる開発を続けてきた実感として、「1行も読まない」という言葉だけが独り歩きすると危ういとも感じています。実際、Rubyの生みの親であるまつもとゆきひろさんは、AI時代こそ「AIが書いたコードが正しいかを読んで判断する力」が重要になる、という趣旨のことを各所で語っています。これは私の主張と矛盾しません。「コードの行を読む」のか「上のレイヤーを読む」のかという解像度の違いはあれど、読む力そのものはむしろ重要になる、という点では完全に同じことを言っているからです。
「読まない」は「何も見ない」ではない。「下を読まずに、上を読む」。その線引きさえブレなければ、それは無責任でも手抜きでもありません。胸を張ってAIに書かせていきましょう。
参考までに、バイブコーディングという言葉の出どころと、提唱者本人の最新の見解を置いておきます。提唱者であるAndrej Karpathyさん自身、最近では「AIの出力には美的感覚・判断・監視の面でまだ人間の責任が必要だ」と述べていて、ここも本記事の立場と地続きです。

- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 3
- 0
-
 たく
たく
- 1
- 0
-
プロンプト画伯
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
たく
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 4
- 0
-
- 5
- 0
-
- 3
- 0
-
- 5
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます