
こんにちは。もるふぉです。
AIエージェントに頼むほどコードがふくらんでいく、という現場の悩みはないでしょうか。
Claude Codeスキル「Ponytail」は、公開から日が浅いうちにGitHub starsを6万超まで集めた注目株で、この「書きすぎる癖」を仕組みで止めにきました。
今日はこのスキルが何をどう抑えているのか、実務目線で読み解いていきます。
AIエージェントが「書きすぎる」のは性能ではなく性格の問題
Claude Codeで起きる「できるから書く」エージェントの癖
「ユーザー入力を検証する関数を1つ作って」と依頼すると、バリデータークラスとカスタム例外、ロガーラッパー、テスト雛形、ついでにREADMEまで返ってきます。
要件は関数1個だったはずなのに、新しいファイルが5つ生まれて型定義まで肥大化している。
これはエージェントの性能の問題ではなく、「書ける手札があるなら全部使う」という性格の問題です。
学習データには「丁寧な設計」のサンプルが大量にあるので、AIは放っておくと最大公約数的な手厚い実装へ寄ります。
経験のある開発者なら「いや、それ標準ライブラリで1行だよね」で終わる場面でも、エージェントは生真面目に全部書ききってしまう。
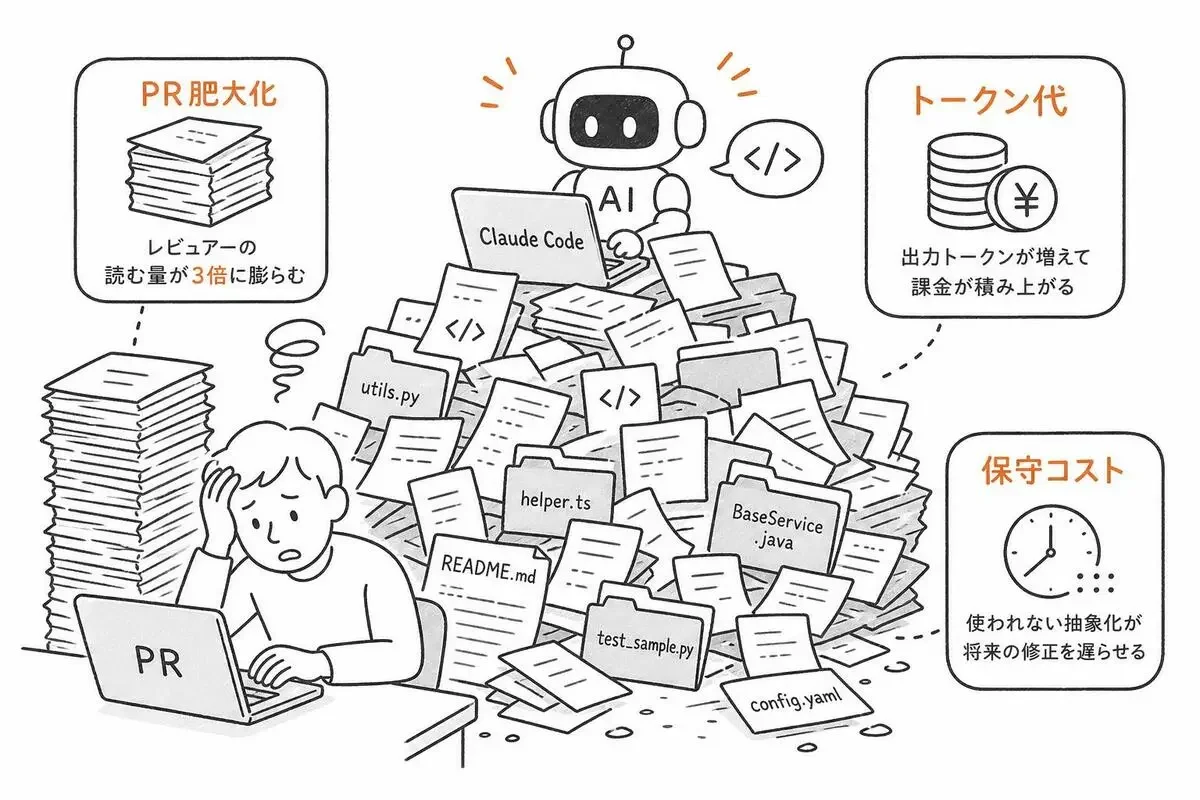
過剰実装が膨らませる3つのコスト
PRを開くたびにあの脱力感、ありますよね。
過剰実装は書いた瞬間にレビューと運用へ跳ね返ります。
- PR肥大化: レビュアーの読む量が3倍に膨らみ、本質的な指摘が埋もれる
- トークン代: 出力トークンが増えるほど課金が積み上がる。月で均すと無視できない金額になる
- 保守コスト: 使われない抽象化は将来の修正を必ず1テンポ遅らせる
「ちょっと書きすぎ」を放置したリポジトリは、半年後に確実に可読性が落ちます。
Ponytailはこの「書きすぎ」を仕組みで止めにきました。
Ponytailとは——6万starsの「怠惰なシニア」をAIに植えるClaude Codeスキル
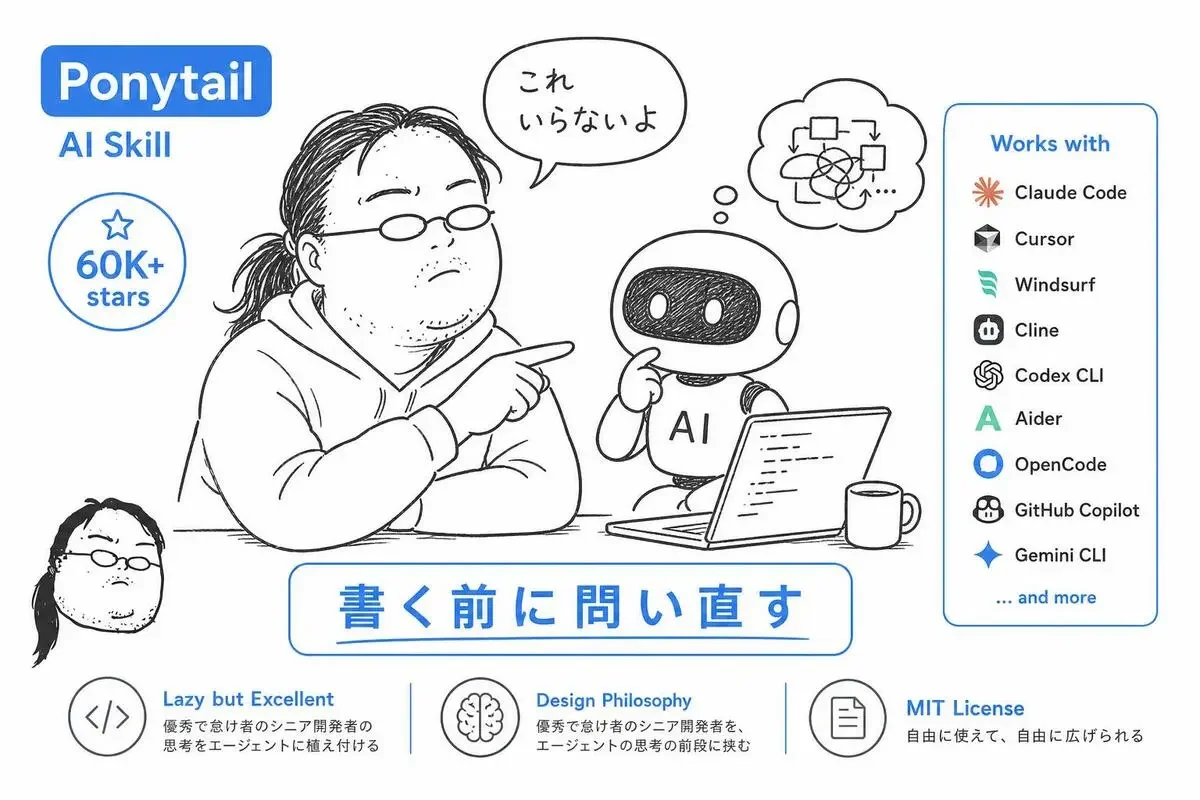
ponytailは、AIエージェントに「書く前に問い直す」癖を植えるためのスキルです。
MITライセンスで公開されていて、Claude Codeから2コマンドで導入できます。
設計思想はシンプルで、「優秀で怠け者のシニア開発者を、エージェントの思考の前段に挟む」というもの。
書く前に「そもそも要るのか」「標準ライブラリで済むか」「既存依存で代替できないか」を7段階で問い直してから、ようやくコードに手を付けるという判断フローを内蔵します。
公開9日で4万stars、現在6万超のトレンド速度
このスキルは公開からたった9日でGitHubの星を4万突破し、執筆時点では6万を超えています。
Claude Codeスキル単体としては破格のスピードで、ほぼ前例のない伸び方です。
背景にあるのは、エージェントを使い込んでいる現場ほど「コードが太る問題」を痛感している現実でしょう。
問題の認知度が高い領域に、誰もが納得する解決策が出てきた——その合致が伸びを押し上げています。
対応エージェントの広さ
主役はClaude Codeですが、ponytailは他のエージェントにも幅広く対応しています。
- Claude Code
- Cursor
- Windsurf
- Cline
- Codex CLI
- Aider
- OpenCode
- GitHub Copilot
- Gemini CLI
普段使いのエージェントがこのリストにあれば、すぐ試せます。
Claude Codeスキルとして実装されていながら本質は「思考フローの教示」なので、プラグイン機構を持つエージェントへ横展開が効きます。
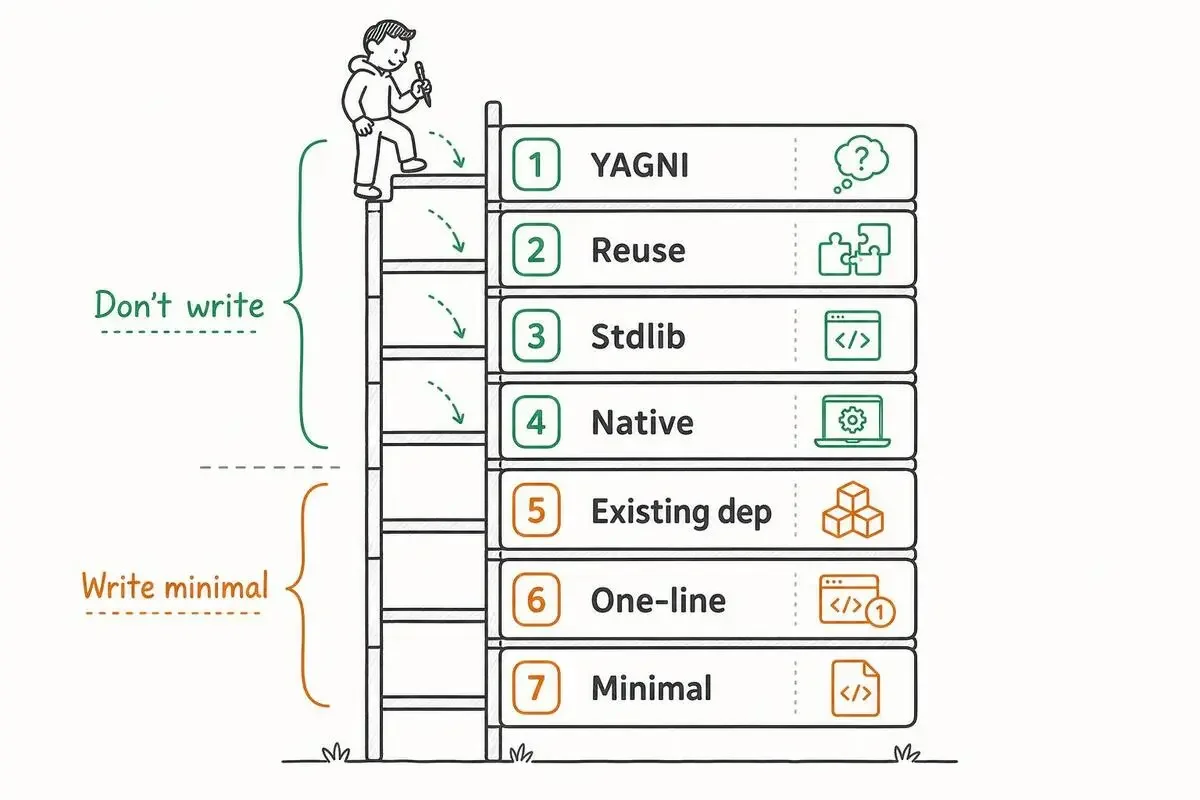
7段階の判断ラダー——書く前に必ず問い直す思考フロー
ここがponytailの本体です。
エージェントは新しいコードに着手する前に、次の7段階を上から順に確認します。
1〜4段階: YAGNI → 既存コード再利用 → 標準ライブラリ → ネイティブ機能
- 1段階:
YAGNI——そもそもこの機能、本当に今要るのか - 2段階: コードベースに既にある——同じ処理がリポジトリ内にあれば再利用する
- 3段階: 標準ライブラリ——その処理、stdlibの1関数で終わらないか
- 4段階: プラットフォーム/ネイティブ機能——フレームワークや言語の組み込みで済まないか
最初の4段階は「書かずに済ます」フェーズです。
YAGNIは「You Aren't Gonna Need It」の略で、「今すぐ要らない機能は書かない」というエクストリーム・プログラミング由来の古典原則。
2段階目の「コードベース再利用」は、同じ処理がリポジトリ内に既にないかを先に確認するステップです。
「書き直すな、再利用しろ」——その判断をエージェントに内蔵させています。
実務でいちばん効くのがここで、経験を積んだ開発者が無意識にやっている「書く前の自問」を、エージェント側に丸ごと渡してしまう発想が面白い。
5〜7段階: 既存依存 → 1行実装 → 最小カスタム
- 5段階: 既存依存——プロジェクトに入っているライブラリで実装できないか
- 6段階: 1行で済むなら1行で
- 7段階: どうしても必要なら最小限のカスタムコード
最後の3段階は「書くなら最小で」フェーズです。
レビューでよく出る指摘——「これlodashで1行になるよね」「自前のutilsを作る前に既存のhelperで足りる」——を、エージェント自身が問い直してくれる構造です。
「なぜこう書いた?」と聞かなくていい。
エージェントが先に考えてくれます。
セキュリティ・バリデーションは削らない設計
「書かない」を徹底すると、必要な防御まで削られそうな不安があります。
そこは設計で押さえてあって、ponytailはtrust-boundary validation(信頼境界の入力検証)、データ損失処理、アクセシビリティ要件を削減対象から明示的に外しています。
つまり、「無いと事故るもの」は削らない。
削るのは「気を利かせて書いたが要件にない」装飾的なコードだけ。
判断ラダーは品質を落とすための仕組みではなく、必要十分まで切り詰めるための仕組みです。
Ponytailの実測値とインストール——5分で試せる
導入手順の前に、公式が公開している数値の読み方を整理しておきます。
54%削減・コスト20%減・速度27%向上の前提条件
※「最大94%」は単発生成タスク(5本)のベンチで観測された別条件の数値です。
数字だけ見ると派手ですが、前提を押さえないと判断を誤ります。
これはHaiku 4.5で12タスク・n=4のベンチマークを取った値です。
実プロジェクトでは要件の複雑さ・モデル・言語・既存依存の量で結果はぶれます。
「自分の環境で54%出る」とは限らない、というのが正確な読み方です。
ただし「書きすぎ」の傾向はモデル横断で見られる現象なので、削減方向の効果は十分に期待できます。
導入コストが低いので、自分のリポジトリで1度ベンチを取るのが一番早い。
/plugin marketplace add を含む2コマンドで導入
インストールは公式の手順に沿えば数分で終わります。

Claude Codeなら、次の2コマンドをそれぞれ別プロンプトで送ってスキルを追加できます。
/plugin marketplace add DietrichGebert/ponytail
/plugin install ponytail@ponytailその後、Claude Code内で/ponytail-reviewや/ponytail-auditのコマンドが使えるようになります。
既存リポジトリでお試し実行してBefore/Afterの差分を見る、までが体感5分。
導入直後からエージェントの振る舞いが目に見えて変わります。
「最小で書く」「組み込みを優先する」というお説教を毎回プロンプトに書く必要がなくなる——翌日のコードレビューで、ファイル数がどれだけ減っているか確かめてみてください。
「書かない選択」をAIに委ねる時代の始まり
ponytailの面白いところは、コードを生成する技術ではなく「コードを書かない判断」を技術として実装した点にあります。
これまでエージェントは「もっと書ける」「もっと丁寧に書ける」方向で進化してきました。
そこに「書かない判断を植える」スキルが現れて6万starsを集めている事実は、現場の関心が「生成量」から「適切量」へ移った合図です。
エージェントが書いたコードを毎回切り詰めるレビューに疲れたら、まずponytailの判断ラダーをエージェント側へ丸ごと渡してみる。
それだけで翌日のPRが明らかに軽くなります。
今夜、2コマンドで試してみてください。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 4
- 1
-
- 9
- 0
-
- 2
- 0
-
- 3
- 0
-
- 1
- 0
-
- 3
- 0
-
- 1
- 0
-
- 4
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 4
- 0
-
- 1
- 0


















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます