こんにちは。もるふぉです。
Sakana Fuguで、マルチエージェントの設計判断が変わり始めています。
LangGraphでノードとエッジを手書きして、Stateにどのキーを持たせるか悩んで、モデル切替のIF文を積み上げて——あの作業、書いている間は楽しいんですよね。
でも運用が始まった瞬間に景色が変わります。
新しいモデルが出るたびに役割割当を見直して、ベンチが変わるたびに分岐を追加して、Autogenで書いたエージェント定義がモデルのバージョンアップで動かなくなって。
「オーケストレーターのメンテ」だけで半日消えた経験、一度はあると思います。
そこにSakana Fuguが出てきました。
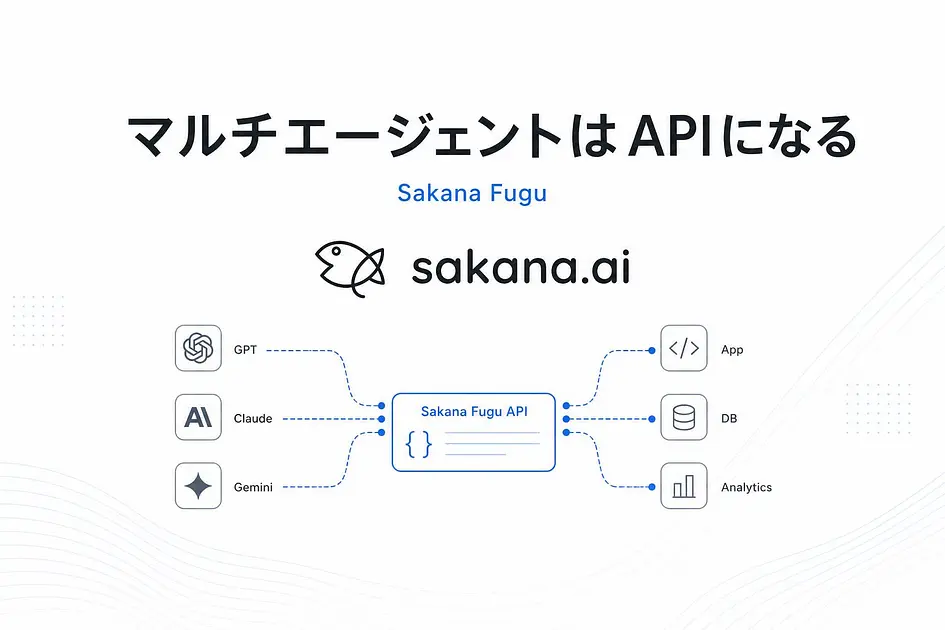
「OpenAI互換の単一APIで、GPT・Claude・Geminiを動的に束ねてくれるマルチエージェント基盤」です。
エンドポイントを差し替えるだけで、今まで自前で書いていたオーケストレーション層がまるごと消える。
設計判断として正直かなりインパクトがありました。
今回は、Sakana Fuguが「自前オーケストレーターを捨てる」候補になりうるのか、技術基盤のTRINITY/Conductorから実際のAPIの組み込み方、SWE-bench Pro 73.7という数値の正しい読み方、そしてOpenRouter Fusionとの違いまで、設計判断する人の視点で整理します。
Sakana Fuguとは — 「モデルを動かすモデル」という発想
Sakana Fuguは、Sakana AIが「Multi-agent System as a Model」と呼んでいるプロダクトです。
複数のフロンティアモデル(OpenAI、Anthropic、Googleの最新モデル群)を1つのタスクに対して動的に組み合わせ、1個のモデルのように振る舞わせます。
ここが重要なんですが、Fuguは「ハンドコードされたワークフロー」ではありません。
誰が何の役割をやるか、どのモデルに何を投げるか、どう通信するかを、Fugu自身が学習で最適化します。
LangGraphでノードとエッジを手で書く世界とは設計思想が根本的に違います。
単一のOpenAI互換APIで、フロンティアモデルを動的に統括
実装面で一番大きいのは、OpenAI互換APIで提供されていることです。
base_urlを差し替えて、API keyを入れ替えるだけで動きます。
chat.completions.createの呼び出しはそのまま使える。
今までOpenAI SDKやAnthropic SDKで書いてきた既存コードに対して、外側のオーケストレーション層を捨ててエンドポイントだけ差し替える、という移行パスが取れます。
「マルチエージェント基盤を試すコスト」がほぼゼロに近い。
検証目的なら半日で組み込めます。
Fugu と Fugu Ultra の使い分け
Fuguには2系統あります。
Fugu(バランス型・低レイテンシ向け)と、Fugu Ultra(最高精度用途向け)です。
Ultraのほうが複数のフロンティアモデルを多段で組み合わせるぶん、コストもレイテンシも上がります。
実務感覚で言うと、ユーザー対話系・分類系・ルーティング系はFugu、コーディング・コードレビュー・複雑な分析タスクはFugu Ultra、という分け方が無難です。
ユースケースを切り分けて両方使うのが正解だと思います。
TRINITYが解いた問題 — 0.6Bのコーディネーターが大型モデル群を動かす仕組み
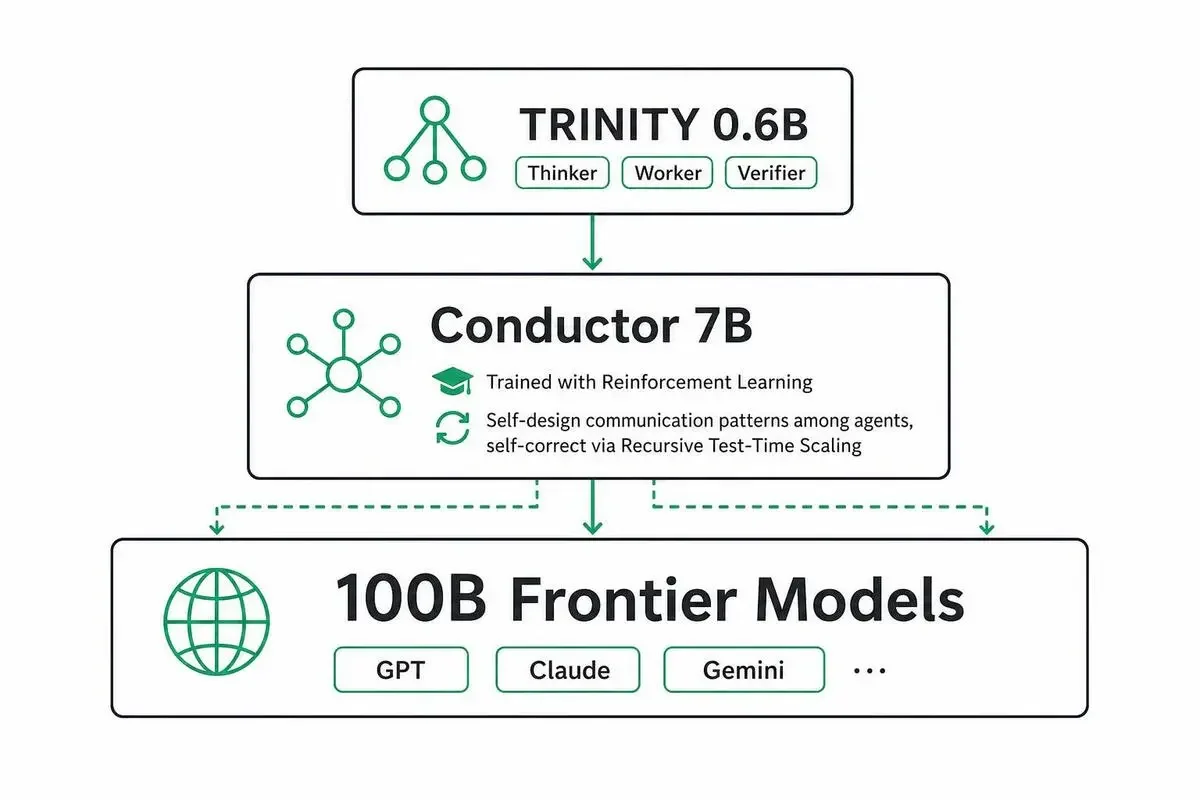
Fuguの内側で動いているのが、ICLR 2026採択のTRINITYとConductorという2つのコンポーネントです。
設計思想として面白い部分です。
Thinker / Worker / Verifier の役割割当
TRINITYは、約0.6Bパラメーターの軽量な進化型コーディネーターです。
役割は「複数の大型LLMに対して、Thinker(考える役)/ Worker(実行する役)/ Verifier(検証する役)を割り当てる」こと。
面白いのがこのサイズ感です。
0.6B——つまりほぼ最小クラスの軽量モデルが、10B・100B級のフロンティアモデル群を統括する。
コーディネーターを小さく保つから、推論コストもレイテンシも軽い。
重い思考処理は外部のフロンティアモデルに投げて、TRINITYは「誰に何を頼むか」だけを判断します。
いわば、タスクの指揮を担う人間は必ずしも最も詳しい専門家でなくてもいい、という構造です。
チームを一番動かせるのは専門知識の深さではなく、誰に何を振るかの判断力——それをモデルサイズで体現したような設計ですね。
Conductorが強化学習で自己設計するエージェント通信
Conductorのほうは強化学習で訓練されていて、エージェント間の通信パターンと、各エージェントに渡すプロンプトの絞り込みを「自己設計」します。
TRINITYが0.6B、Conductorが7B、その下に100B級のフロンティアモデル群がいる、というサイズ階層になっています。
LangGraphで言えば、Stateの中身とノード間で渡すコンテキストを毎回手書きしている部分です。
Conductorはこれを学習で決める。
さらにConductorは自チームの出力を再帰的に読んで、最初の協調戦略が悪いと判断したら修正ワークフローをspin upする自己修正能力(Recursive Test-Time Scaling)を持っています。
「自前で書いていたDAGの大半は、学習されたコーディネーターのほうが上手くやる」可能性が現実的に出てきます。
少なくとも検証する価値はあります。
ここからが実装の話です。
Sakana Fugu APIの実際 — エンドポイント変更だけで既存コードに組み込める
既存のOpenAI SDKコードがあるなら、移行は本当にエンドポイントの差し替えで済みます。
移行コストの実態 — Sakana Fugu API組み込みの変更点
PythonのOpenAI SDKを使っているケース。
from openai import OpenAI
client = OpenAI(
base_url="https://api.sakana.ai/v1",
api_key=os.environ["SAKANA_API_KEY"],
)
response = client.chat.completions.create(
model="fugu-ultra",
messages=[{"role": "user", "content": "..."}],
)これだけです。
LangChainでもChatOpenAIのbase_urlを差し替えるだけで動きます。
LangGraphで書いていたノード分岐、Autogenで書いていたエージェント定義、CrewAIで書いていたチーム構成、これらが全部「Fuguへの1リクエスト」に畳めます。
もちろん全ケースが置き換えられるわけではありません。
エージェントの中間出力を細かく制御したいケース、社内ツールやMCPサーバーを介在させたいケースは、引き続き自前のオーケストレーションが必要です。
ただ「動的なモデル選定と役割割当」のレイヤーは外部に出していい、というのが私の今の判断です。
Sakana Fugu 料金プラン別のユースケース
料金は月額制でStandard $20(約3,000円)/Pro $100(約1.5万円)/Max $200(約3万円)の3プラン、加えて従量課金があります。
個人で検証するならStandardで十分動きます。
チームで本番に乗せるなら、レート制限とサポート観点でPro以上が現実的です。
エンタープライズ用途や大量バッチを回す場合はMaxを検討する流れ。
注意点として、EU/EEA域内は2026年6月時点で利用不可なので、ヨーロッパのユーザーを抱えるサービスは要確認です。
詳細はSakana Fugu GitHubリポジトリも合わせて見てください。
SWE-bench Pro 73.7の意味 — 数値を正しく読む
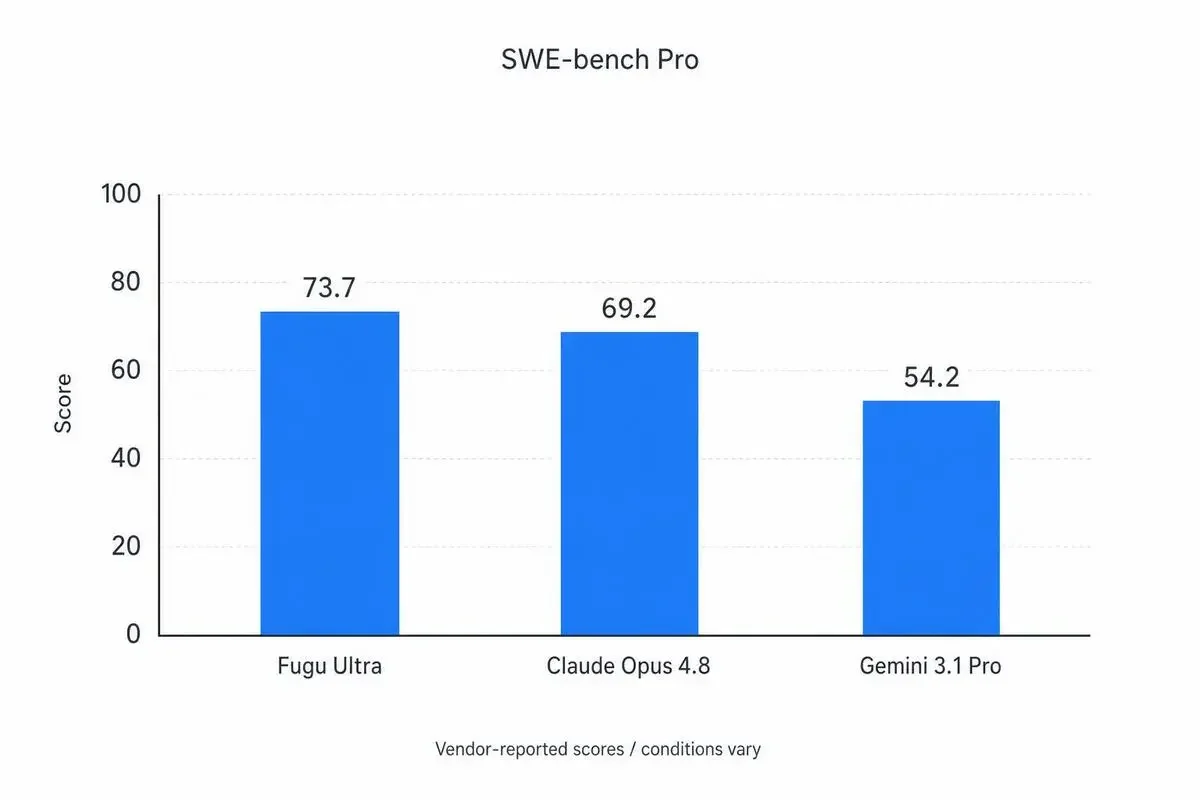
Fugu Ultraの公式リリースでは、SWE-bench Proで73.7というスコアが報告されています。
Claude Opus 4.8の69.2、Gemini 3.1 Proの54.2を上回る数値です。
「Fuguが単体モデルより強い」と読みたくなるところですが、ここは正直に書きます。
ベンダー発表のベンチマーク値は、評価条件・プロンプト・試行回数・サンプリング設定で大きく変動します。
SWE-benchのような複合タスクは特にそうで、独立機関による標準化スコアと、ベンダーが自社環境で測った値は別物として扱うのが安全です。
Fugu UltraはGPT・Claude・Geminiを組み合わせて回答を生成するため、単体モデルとの直接比較条件を揃えること自体が難しい。
現場での期待値としては、「単体モデルより数ポイント上の精度を、複数モデル分のコストとレイテンシで買う」というトレードオフだと考えるのが妥当です。
コードレビューや複雑な仕様分析のように、精度が直接生産性に効く領域では十分元が取れます。
単純な分類タスクで0.6%精度を稼ぐためにFuguを使うのはコスト的に合いません。
ベンチ数値は「使う動機」にはなりますが、「使う根拠」にはなりません。
自分のユースケースで実測する一手間は省かないほうがいいです。
OpenRouter Fusion vs Sakana Fugu — どちらを選ぶべきか
2026年6月にOpenRouter Fusionが発表されて、マルチモデル統合APIの選択肢が一気に2つになりました。
両方とも「複数のフロンティアモデルを束ねる」と言っているので混乱しやすいんですが、設計が根本的に違います。
アーキテクチャの根本的な違い
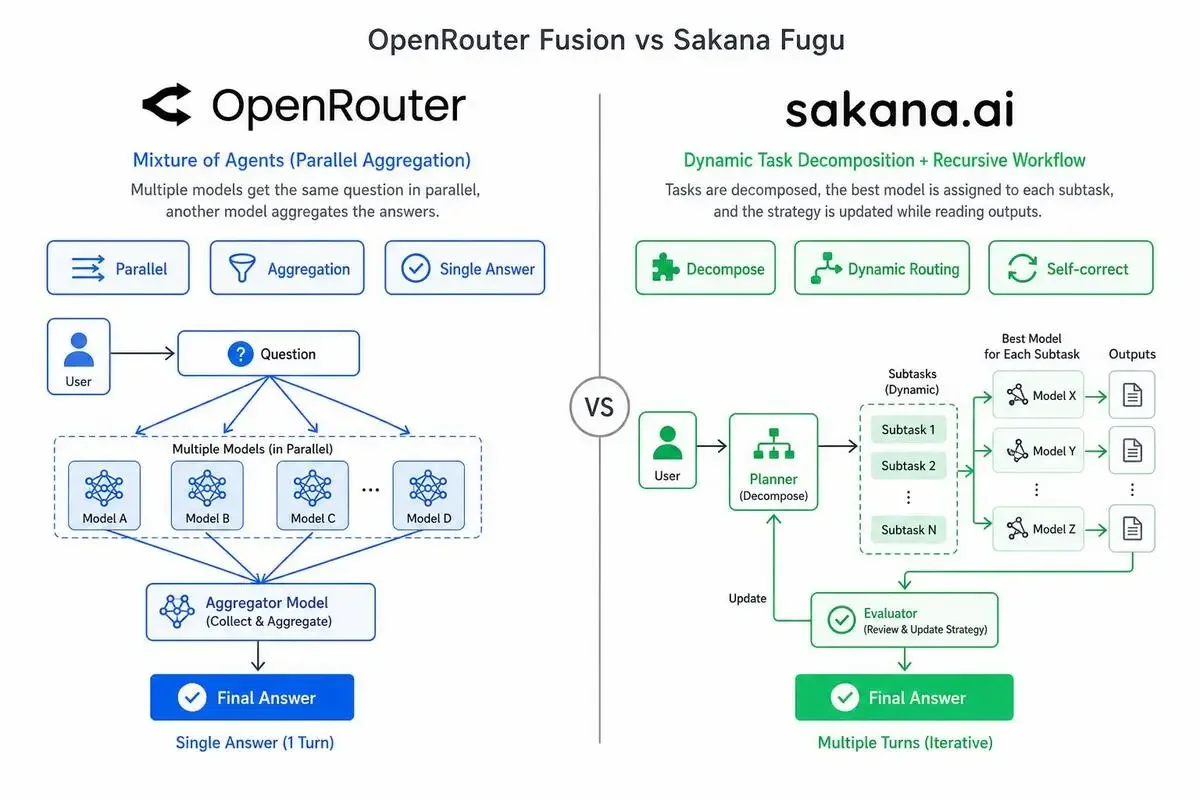
OpenRouter Fusionは複数モデルへの並列投入と集約(MoAに近い方式)。
複数モデルにそれぞれ回答させて、その回答群を別のモデルが集約して単一の最終回答にまとめます。
1ターンの推論を多並列で回して質を上げるアプローチです。
Sakana Fuguは動的タスク分解+再帰的ワークフロー修正方式。
タスクを分解し、各サブタスクに最適なモデルを割り当て、出力を読みながら必要なら戦略を修正します。
複数ターンの推論を学習されたコーディネーターが指揮します。
「単一高精度回答」vs「動的タスク分解+自己修正」
選択基準はこう整理できます。
Fusionが向くのは、1問1答型のタスクで回答品質を上げたいケース。
質問応答、要約、コード生成のような短サイクルで完結する用途です。
実装も単純で、レイテンシも予測しやすい。
Fuguが向くのは、複数ステップの計画・実行・検証が必要なタスク。
コードレビュー、複雑な分析、エージェント的に動くべき業務フローなどです。
自己修正があるぶんレイテンシは伸びますが、出力の到達点は高くなります。
両方の選択肢を持っておくのが現実的で、ユースケースごとに使い分けるのが正解だと思います。
Sakana Fuguを使うべき場面、使わない場面
使うべき場面は、まず「マルチエージェントを自前で書いていてメンテに疲れている」ケース。
Fuguへ移行する検証は半日で終わります。
次に「複数モデルを切り替えながら高品質な出力を取りたい」ケース。
コードレビュー、複雑な仕様分析、業務システムのバッチ処理など、精度が直接価値に変わる領域です。
使わない場面は、「単一モデルで十分な精度が出るタスク」「中間出力やツール呼び出しを細かく制御したいケース」「EU/EEA域内のユーザーが主体のサービス」。
このあたりはまだ既存のスタックを使うほうが現実的です。
今取れるアクションは1つです。
Sakana AI公式からコンソールに登録して、fugu(バランスモデル)で自分のユースケースを30分試してみる。
エンドポイントを差し替えるだけなので、判断材料は1日で揃います。
設計判断は実測してからのほうが速いです。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます