こんにちは。
もるふぉです。
Claude Codeに「このURL読んで要約して」って投げたら、いきなり403返ってきて作業が止まること、ありませんか。
「また弾かれた」と分かった瞬間、コピペして渡すか諦めるかを迫られる、あの判断コストが地味に積み重なります。
私は最近これが増えてきて対処法を調べたんですが、解決策が拍子抜けするほどシンプルでした。
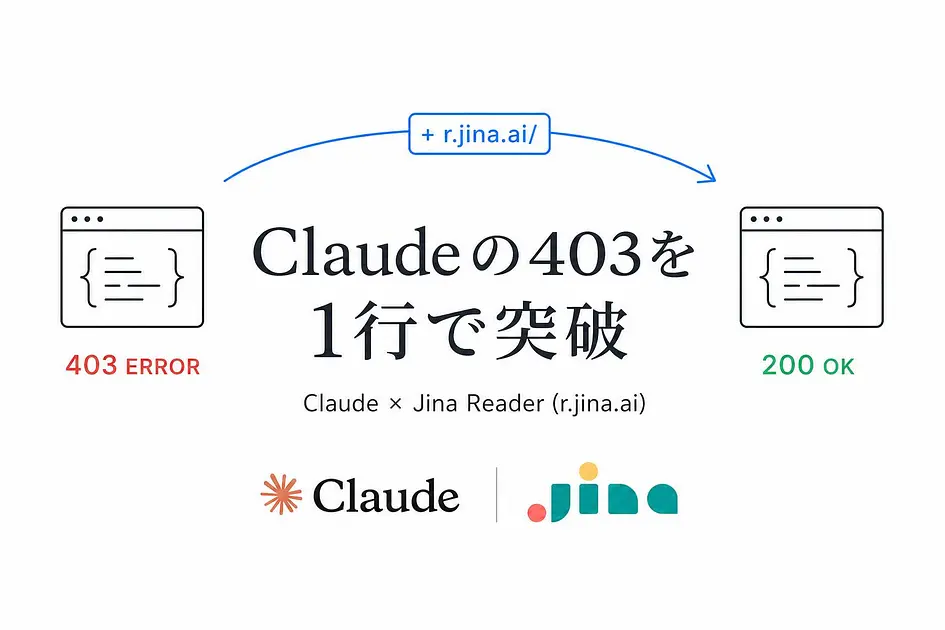
r.jina.ai をURLの頭に付けるだけで、Claudeが読めなかったページを読めるようになります。
今日はその仕組みと使い方を、コピペで試せる形で共有します。
ClaudeのWebFetchが403で弾かれる理由
Claude CodeのWebFetchツールが403を返してくる原因は、ほぼひとつに集約されます。
アクセス先のサイトがbotやヘッドレスクローラーをブロックしているからです。
Cloudflareの保護やWAF、robots.txtベースの制限、User-Agent判定など、サイト側の対策はバリエーションが多い。
Claudeのフェッチは正規のブラウザ偽装をしないので、こうしたフィルタに引っかかると素直に403やキャプチャ画面が返ってきます。
私の手元でも、技術ブログ・ニュースサイト・SaaS公式ドキュメントなど「ちゃんとしたサイトほど」蹴られる印象があります。
回避策としてユーザーがブラウザでコピペして渡す手もありますが、毎回それをやるとAIに任せる意味が半分くらい消えます。
そこで役立つのが、LLM向けのプロキシ的サービスであるr.jina.aiです。
URLを一手間加えるだけで、Claudeが直接届かないページを迂回して取得できます。
r.jina.aiで一発解決:URLの前に1行足すだけ
使い方は本当に1行です。
読みたいURLの先頭にhttps://r.jina.ai/を貼り付ける、これだけ。
# 元のURL(Claudeが403で読めない場合がある)
https://example.com/article/123
# r.jina.aiを通したURL(LLM向けMarkdownで返ってくる)
https://r.jina.ai/https://example.com/article/123Claude Codeで使うなら、プロンプトの中でURLを直接書き換えるだけで十分です。
「次のページを要約して: https://r.jina.ai/https://example.com/article/123」と投げれば、Claudeはそのまま中身を取りに行ってくれます。
Jina Readerが裏側でページをレンダリング・抽出して、LLMが食べやすいMarkdownに変換して返す仕組みです。
サイト側から見るとアクセスしているのはJinaのクローラーなので、Claudeが直接叩くより通りやすい。
返ってくるテキストもナビゲーションや広告が除去された本文中心なので、要約や引用にそのまま使えます。
リリースノートやSaaS公式ドキュメントを大量に読ませる場面で、403で作業が止まる回数が露骨に減りました。
r.jina.aiを使うときの制限と注意点
使うときに知っておいたほうがいい制限がいくつかあります。
X-Respond-Withでhtml/text/screenshot等に切替可)カジュアルに使う分には認証なしの20 RPMでまず困りませんが、Claude Codeで連続して複数URLを読ませると意外と早く頭打ちになります。
Jinaのダッシュボードで無料APIキーを発行してAuthorizationヘッダで投げれば500 RPMまで伸びるので、本格的に使うなら最初にキー取得を済ませておくのがおすすめです。
注意点もいくつか。
JavaScriptで重く動的生成しているSPAは、たまに本文が取り切れずスケルトンだけ返ってくることがあります。
ログインが必要なページや有料記事の本文は取れません。
社外秘ドキュメントや認証付きのURLを通すと内容がJina側を経由することにもなるので、機密性の高いコンテンツは手元でコピペするほうが安全です。
次にWebFetchで403が返ってきたときは、プロンプト内のURLの頭にhttps://r.jina.ai/を足してそのまま投げ直してみてください。
書き換えは5秒、通過率は体感でかなり変わります。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
- 2
- 0















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます