
こんにちは。
もるふぉです。
「もうプロンプトは書かない。ループを書いてる」——AnthropicでクロードコードのHeadを務めるBoris Chernyさんがそう言い、GoogleのAddy Osmaniさんがそれを「Loop Engineering」という名前で整理しました。
正直、最初にこの話を読んだとき「えっ、もうプロンプト書かないの?」と戸惑いました。
「毎回ちゃんとプロンプト書いて、丁寧に指示してるのに」と思った方、います? 私も全く同じでした。
あの戸惑い、多分みんな通る通過点だと思います。
でも自分のクロードコードの使い方を振り返ると、確かに「毎回プロンプトを書く」段階はとうに過ぎていて、ループとmdファイルでAIが勝手に走る状態をどう作るかに頭を使っている時間のほうがはるかに長いんです。
同じ時期にPeter Steinbergerさんも同じ趣旨の発言をしていて、英語圏のAI駆動開発界隈で一気に概念が固まった感があります。
プロンプトを書くのをやめた話——Loop Engineeringの始まり
ことの発端は、Peter Steinbergerさんのこの一言でした。
「もうコーディングエージェントにプロンプトしてる場合じゃない。エージェントにプロンプトするループを設計するんだ」。
続いてBoris Chernyさんが
「自分はもうクロードにプロンプトしない。クロードにプロンプトして次に何をするか決めるループを動かしてる。私の仕事はループを書くことだ」
と発言しました。
そしてAddy Osmaniさんがこの動きを「Loop Engineering」として整理した長文ポストがこちらです。
3者に共通するのは、AIエージェントを「呼び出す対象」から「常時走らせる対象」に切り替えたという感覚です。
プロンプトを毎回書くのは、エージェントを毎回起動して指示する手動運転。
ループ設計は、エージェントが自走する道路と信号を整備する仕事です。
では、その「道路と信号」はどう作るのか。
次が本題です。
Loop Engineeringとは何か——5つの構成要素の全体像
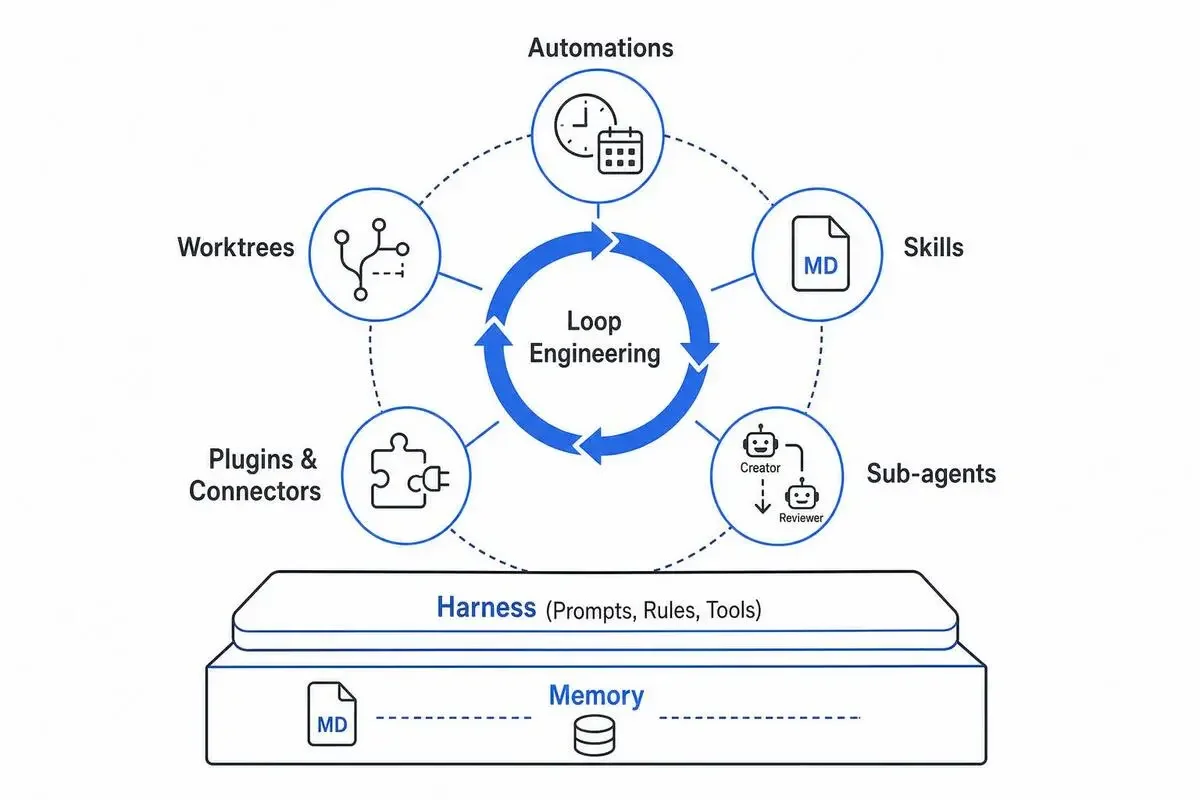
Addyさんの定義をかみ砕くと、Loop Engineeringは「再帰的なゴールに向かって、AIエージェントが自走する仕組みを設計する技術」です。
位置づけとしては、いわゆるハーネス(プロンプト・ルール・ツール群)の一階上にあります。
ハーネスが「1回のやり取りをどう成立させるか」なら、ループは「やり取りを何百回繰り返しても劣化しない状態をどう保つか」を扱います。
ループの定義と「ハーネスの上の階」という位置づけ
Addyさんが挙げる構成要素は5つ+1つ(メモリ)です。
- Automations(スケジュール実行・トリガー)
- Worktrees(並列エージェントの隔離)
- Skills(プロジェクト知識のmd化)
- Plugins & Connectors(MCP経由の実ツール接続)
- Sub-agents(作成者と検証者の分離)
- Memory(セッション間で持ち越す外部mdファイル)
カタログ通りに上から実装すると、たいてい途中で破綻します。
ここから先は、私が実務で詰まった順番に並べ直して解説します。
どこで詰まるかを知っておくだけで、同じ轍を踏まずに済むはずです。
実装順1: Skills——CLAUDE.mdから始めると詰まらない
最初に手をつけるべきは間違いなくSkillsです。
具体的にはCLAUDE.mdに「このプロジェクトで守るべきこと」「使う技術スタック」「やってはいけない実装パターン」を書き出す作業から始めます。
Skillsが先で他4要素が後な理由
Skillsを後回しにしたまま他のものから触り始めると、毎セッションで同じ前提を再導出するAIを延々と眺めることになります。
「N+1クエリは避ける」「Tailwindのプレフィックスはtw-」みたいな当たり前のことを、ループのたびに毎回プロンプトで渡すのは消耗戦です。
「もしかして前も同じこと言ったっけ?」と気づいた時点で、すでにSkillsが必要な状態に来ています。
Addyさんが警告している「意図のデッド化」もここに直結します。
Skillsが整っていないループは、回数を重ねるほど書き手の意図から離れていきます。
逆にSkillsが整っていれば、AutomationsもSub-agentsも全部楽になります。
土台がないままループを組んで「なぜか精度が落ちる」と悩むのは、私が最初にやらかしたパターンそのものです。
Skillsが固まったら、次はループを「動かし続ける仕組み」の話に入ります。
実装順2: Automations——/loop・hooks・GitHub Actionsの使い分け
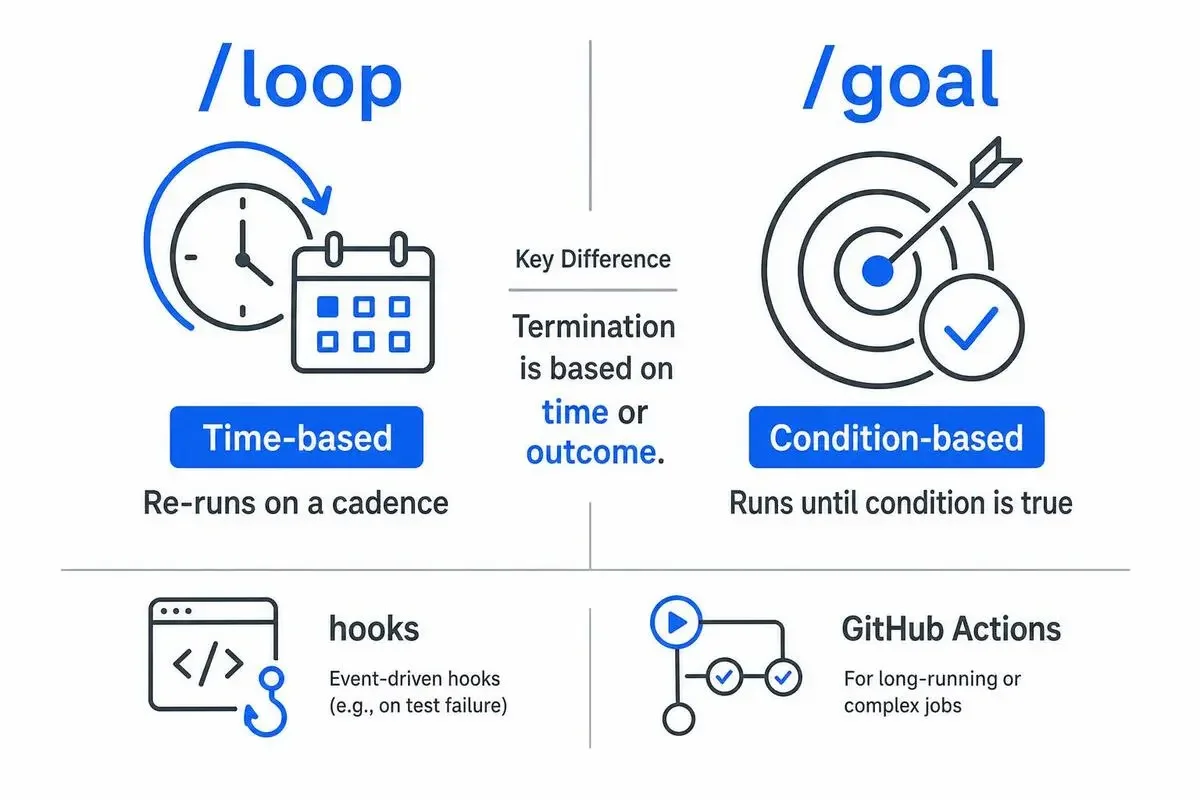
Skillsが整ったら次はAutomationsです。
クロードコードでよく使うのは/loop、/goal、hooks、そしてGitHub Actionsの4種類です。
/loop と /goal の違いと使い分け
4種類あると聞いて「どれを使えばいい?」と悩みますよね。
私も最初は全部/loopに投げていて、終了条件のないタスクが延々と走り続けて半笑いになったことがあります。
/loopは「指定した間隔でタスクを再実行する」コマンドで、/goalは「条件が達成されるまで継続する」コマンドです。
両者の違いは終了条件が時間か成果かという点にあります。
私の感覚だと、リファクタリング系は/loop、バグ修正系は/goalが向いています。
hooksはコミット前後やテスト失敗時のフックに使い、長時間走らせたいものはGitHub Actionsに持ち出します。
ここを混ぜると、ローカルで動かしっぱなしのループとCI上のループが二重に走って、Pull Requestがめちゃくちゃになる事故が起きます。
ループを動かし続ける仕組みができたら、次は「複数のループを同時に走らせる」話になります。
ここで多くの人が最初の大きな壁にぶつかります。
実装順3: Worktrees——並列エージェントの衝突を消す
並列でエージェントを走らせ始めると、ほぼ確実に出会うのがファイル衝突です。
worktreeを使わないと何が起きるか
git worktreeを使わずに3つのエージェントを同時に動かすと、同じファイルを別々のエージェントが上書きし、片方の修正がもう片方の修正で消える事故が起きます。
最悪なのは、消えた変更がコミットされる前のステージング状態だったときで、何が消えたかすら追えなくなります。
「あれ、さっき直したはずなのになぜ戻ってる?」——この疑問が出たら、たいていWorktrees不在が原因です。
これに気づいてからは、並列ループを組むときは必ずgit worktreeで物理的にディレクトリを分け、エージェントごとに独立した作業空間を渡すようにしています。
クロードコードの--worktree相当のフラグを使えば、新しいブランチと作業ディレクトリを同時に切れます。
並列エージェントを動かす予定がないうちはWorktreesは無視していいですが、Sub-agentsに進む前に必ず通る話です。
衝突を解消したら、次は「並列エージェントの中身の質」を上げる話に入ります。
実装順4: Sub-agents——作成者と検証者を分離する
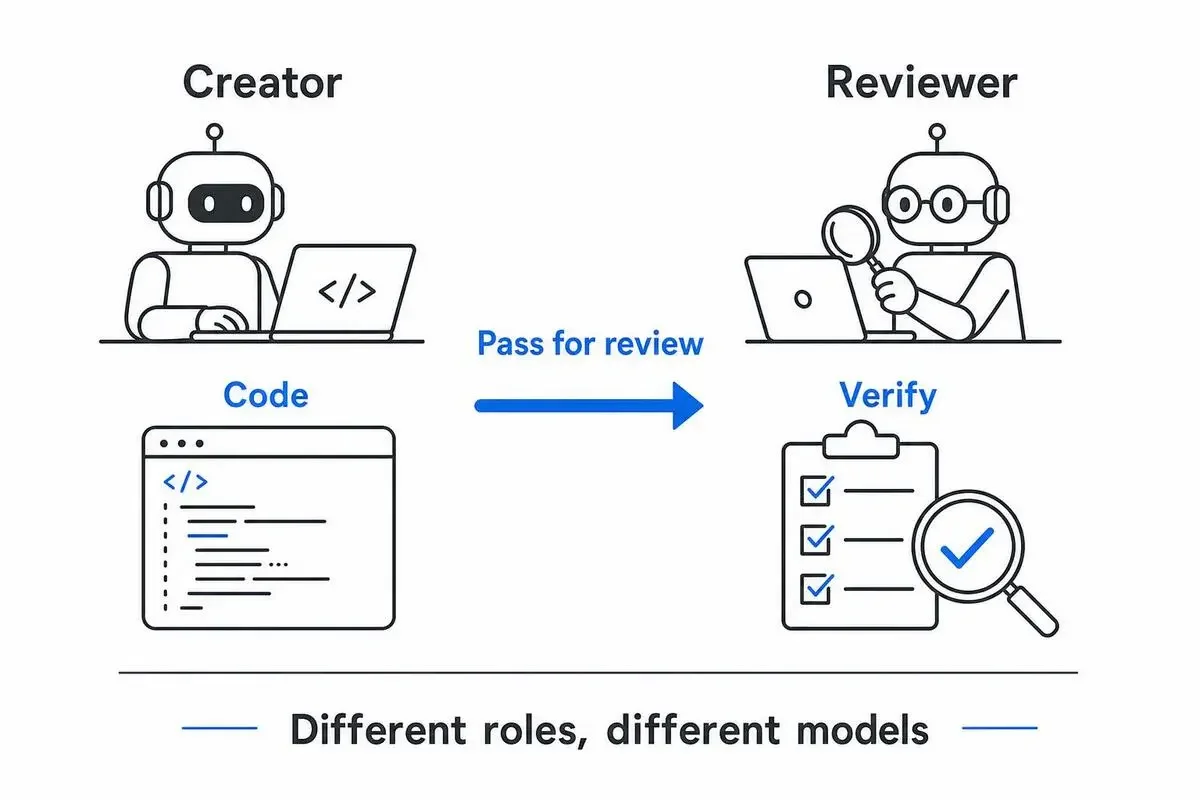
Sub-agentsは「コードを書くエージェント」と「それを検証するエージェント」を別々に立てる構造です。
自己評価が甘いAIへの構造的な対処
書いた本人に「これでいいですか?」と聞くと、AIは基本的に「いいです」と答えます。
人間も同じで、書いた直後の自己評価は甘くなるものです。
「テストが通った。
問題ない」と思って本番に出したら落ちた、という経験がある人は、このコスト感が刺さるはずです。
だから検証はSub-agentに、できれば別モデルにやらせます。
私の実装パターンは、実装役にOpus系、検証役にSonnetかGPT系を当てるというものです。
同じモデルだと同じ盲点を持つので、わざわざ別系統のモデルを混ぜる意味があります。
ここを「コストがもったいない」と省略すると、テストが通っているのに本番で落ちるコードが量産されます。
Sub-agentsはコストではなく保険です。
最後のピースは、これらのループを実ツールに接続する部分です。
ただし、ここは順番を守らないと一番派手に事故ります。
実装順5: Plugins & Connectors——MCPは最後に乗せる
最後がMCP(Model Context Protocol)経由のツール接続です。
GitHub、Slack、社内DB、Notionなど、実ツールにエージェントを繋ぐ部分です。
MCPから入って失敗するパターン
MCPから先に入ると100%失敗します。
私自身、最初にMCPで色々繋いでから「さあループ組むぞ」と進めて、毎回手動で介入する羽目になりました。
SkillsもAutomationsもSub-agentsも整っていない状態でMCPを繋ぐと、「強力な道具を持ったまま暴走するエージェント」が生まれます。
Slackに勝手にメッセージを送り、GitHubに変なPRを立て、後始末で半日溶けます。
MCPは便利ですが、ループの設計が整ってから最後に乗せる順番が正解です。
便利さより事故のコストが先に来ます。
ここまで5要素の実装順を追ってきました。
でも、これだけ読んで「じゃあ全部揃えれば完璧だ」と思ったなら、最後にもう一つ読んでほしい話があります。
ループを設計しても「エンジニアであること」をやめない
最後にAddyさんの警告に触れます。
彼はLoop Engineeringの記事の末尾で2つの言葉を強調しています。
- comprehension debt(理解の負債)
- cognitive surrender(認知的降伏)
ループを組んだことがある人なら、覚えがあると思います。
ループが優秀になればなるほど、コードの中を覗く回数が減る。
「動いてるから問題ない」と思い始める。
これがcomprehension debtです。
ある日バグが起きたときに「どこで何が壊れたか」を追えなくなって、初めて気づく。
cognitive surrenderはさらに深刻で、「AIがそう判断したならそれが正しい」と思考停止することを指します。
ループの設計者が意図と理解を保たなければ、ループは静かに劣化していきます。
優秀なループが自分の理解を超えたとき、あなたはもう設計者ではなく管理人になっています。
これ、ループを回してない人には「そんな状態になるわけない」と聞こえるかもしれません。
でも、なります。
静かに、気づかないうちに。
Addyさんはこう締めくくっています。
Build the loop. Stay the engineer.(意訳)——ループを組め、けれどエンジニアであり続けろ。
私の解釈はこうです。
ループを組むのは仕事ですが、ループに飲み込まれたら仕事ではなくなります。
Loop Engineeringは、もはや個別テクニックではなく前提です。
やらない人は確実に取り残されます。
けれど、ループを組んだ瞬間に「組んだ自分」が手を抜き始めることも事実です。
設計者として残り続けることだけが、この時代のエンジニアの本業だと私は思っています。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
- 2
- 0















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます