
こんにちは。もるふぉです。
2026年6月12日、Google CloudがOpen Knowledge Format(OKF)v0.1を公開しました。
「またひとつAIエージェント向けの仕様が増えたか」というのが正直な第一印象でした。
MCPがあり、llms.txtがあり、AGENTS.mdやCLAUDE.mdまである中で、これ以上何を統一したいのか。
SPEC.mdを読み、最小バンドルを手で書いて検証してみたところ、OKFの立ち位置はかなり明確でした。
同時に、v0.1の段階で本番投入するのは早すぎるという結論にも至っています。
この記事では、OKFの正体・既存仕様との役割分担・採用判断の基準を、賛美抜きで整理します。
Open Knowledge Format(OKF)とは何か、一言で言うと
OKFは「YAMLフロントマター付きMarkdownファイルを置いたディレクトリ」を、AIエージェント向け知識バンドルの最小フォーマットとして標準化する仕様です。
それ以上でも以下でもありません。
公開元はGoogle Cloud、リポジトリはGoogleCloudPlatform/knowledge-catalogのokf/配下にSPEC.mdが約450行で置かれています。
v0.1はドラフト扱いで、現時点では「これから議論する叩き台」というステータスです。
YAMLフロントマター付きMarkdownの「ディレクトリ」が全て
OKFバンドルの実体は、ただのGitリポジトリかディレクトリです。
各.mdファイルが1つのコンセプトを表し、ファイルパス自体が識別子になります。
/tables/customers.mdならパスがそのままIDです。
コンセプト同士はMarkdownのリンク記法で相互参照します。
特別なランタイムもサーバーも要りません。
git cloneして、好きなツールで読めばそれで終わりです。
スキーマレジストリも中央機関も置かない設計で、llms.txt以来の「軽さ重視」の流れを汲んでいます。
必須フィールドはtypeのみ──この一点から設計思想が読める
フロントマターで必須なのはtypeだけです。
title・description・resource・tags・timestampは推奨ですが、義務ではありません。
typeの値さえ自由に決められます。
BigQuery TableでもAPI EndpointでもPlaybookでも好きにつけてよく、消費者側(エージェント)は知らないtypeが来ても落ちずに処理する責務を負います。
この「必須はtypeだけ」という設計が腹落ちすると、既存Markdownにフィールドを1個足すだけで動き出せる、という現実が見えてきます。
ここに「プロデューサーとコンシューマーを独立させる」「フォーマットであってプラットフォームではない」というv0.1の思想がそのまま出ています。
標準化を最小に抑え、運用の自由度を最大化する選択です。
この最小仕様が、既存フォーマットとどこで役割が分かれるのかを次に整理します。
OKF・CLAUDE.md・MCP・llms.txtの役割分担を整理する
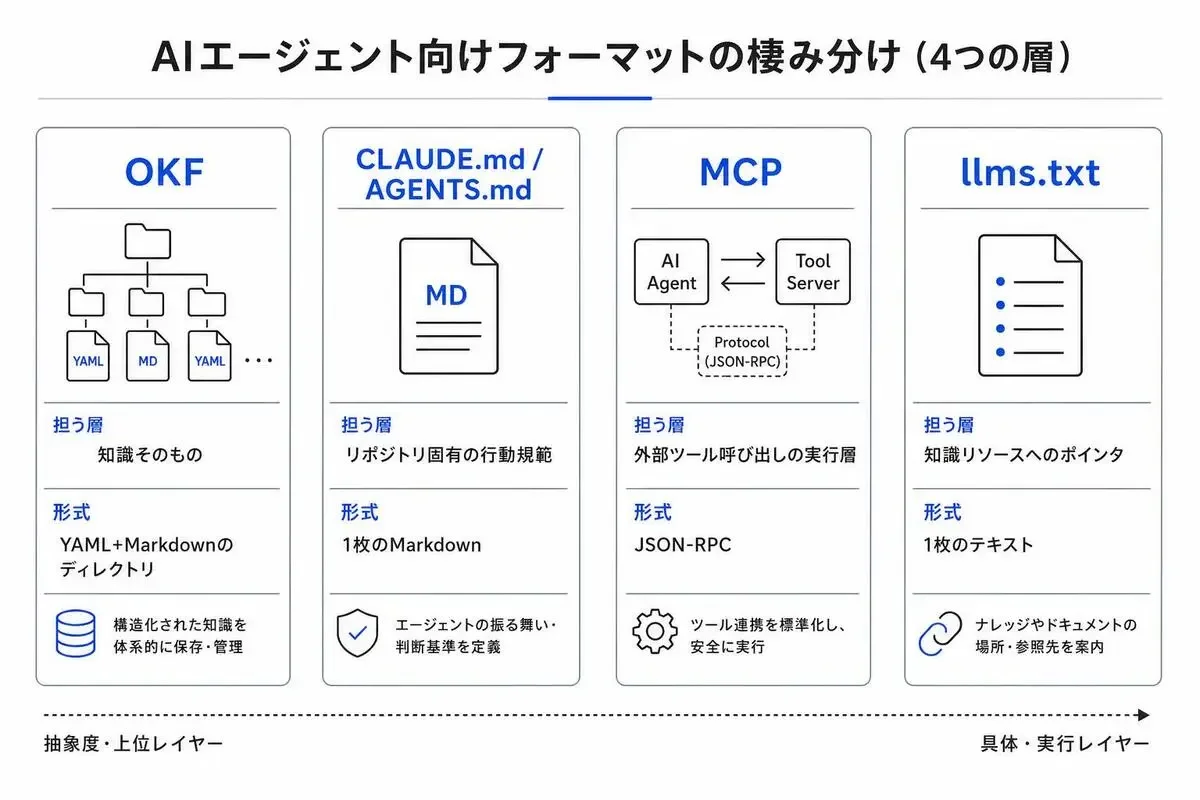
「OKFはMCPと何が違うのか」「llms.txtで十分では?」という疑問は当然出ます。
競合ではなく、それぞれが担う層が違います。
各フォーマットが担う「層」の違い
整理するとこうなります。
この表を見ると、4つがそれぞれ食い合わずに棲み分けているのがわかります。
MCPは「動詞」の標準化、OKFは「名詞」の標準化、と言うとイメージしやすいかもしれません。
MCPがツール呼び出しの仕様であるのに対し、OKFはツールを呼んだ先にある「テーブル定義」「APIの意味」「業務ルール」自体をどう書くかの仕様です。
CLAUDE.mdやAGENTS.mdとの具体的な差分
Claude Codeを日常的に使っている方には、ここが一番気になる論点だと思います。
CLAUDE.mdは「このリポジトリでClaude Codeにどう振る舞ってほしいか」を書く慣習ファイルで、行動規範や開発ガイドラインを1ファイルにまとめるスタイルです。
対してOKFは、知識を複数ファイルに分解し、type付きで構造化します。
CLAUDE.mdが「うちのチームの暗黙知をAI向けに明文化したもの」なら、OKFは「その知識を他チーム・他エージェントに渡せる形に正規化したもの」と捉えると差が見えます。
両者は共存できます。
リポジトリ内の運用ガイドはCLAUDE.mdに残し、外に出していい知識資産だけをOKFバンドルに切り出す、という分け方が現実的です。
ただし「切り出す価値があるか」の判断は、次のセクションが評価の分かれ目です。
「Markdownでいいのでは?」という疑問に正直に答える
ここがOKF評価で一番ごまかしてはいけない論点です。
「type付けるだけなら自分で運用ルール決めれば済む話では?」という疑問には、私も否定しきれない部分があります。
単独チームならYesかもしれない
自社内で1チームが運用するだけなら、命名規則を決めたMarkdownリポジトリで十分動きます。
私が関わっている案件の多くは、CLAUDE.mdとMarkdownメモの組み合わせで現状回っています。
typeをフロントマターに足したところで、ツール側が読んでくれなければ何も変わりません。
OKFが効くのは「自分たちが作った知識を、自分たちが書いていないエージェントが読む」局面です。
知識を「他エージェントに渡す」時に差が出る理由
OKFの本質的な価値は、消費者側(エージェント側)に「未知のtypeも処理する」という規約を課している点にあります。
プロデューサーがtype: Playbookと書けば、その意味を知らないエージェントも汎用コンセプトとして扱える。
ここに、独自Markdownでは出せない移植性があります。
別の言い方をすると、OKFは「ナレッジのCSVみたいなもの」です。
CSVの中身が何を意味するかはアプリ次第ですが、カンマ区切りで読める保証だけは共有されている。
OKFも同じ立て付けで、最小規約だけを共有し、中身の意味づけは各プレイヤーに委ねています。
社内ナレッジを将来別のエージェントやベンダーに渡す可能性があるなら、最初からOKF準拠で書く価値はあります。
その予定がないなら、Markdownのままで十分です。
OKF v0.1バンドルの最小構成を手で書いてみた

文章だけだと掴みにくいので、最小バンドルを手で書いてみました。
SPEC.mdに従えば、これだけで「OKF準拠バンドル」を名乗れます。
ディレクトリ構造と最小ファイル例
my-knowledge/
├── index.md
├── log.md
└── tables/
└── customers.mdコンセプトファイルtables/customers.mdはこんな形です。
---
type: BigQuery Table
title: Customers
description: 全チャネルの顧客マスタ。1行=1顧客
resource: https://console.cloud.google.com/bigquery?p=acme&d=sales&t=customers
tags: [sales, customers]
timestamp: 2026-06-12T09:00:00Z
---
# Customers
顧客マスタテーブル。注文情報は [orders](./orders.md) を参照。フロントマターはtypeだけ書けば仕様としては合格です。
title以降はあくまで推奨で、運用上の親切さの問題です。
既存のMarkdownメモがあるなら、フロントマターを1行足すだけで今日から試せます。
index.md / log.md の予約ファイルの意味
index.mdとlog.mdは仕様で予約されている特殊ファイルです。
index.mdはディレクトリ内のコンテンツ一覧を人間とエージェントの両方に提示するためのもので、基本的にフロントマターは不要です。
階層の各レベルに置けます。
log.mdはそのディレクトリ配下の変更履歴で、ISO 8601日付でグループ化して書きます。
バンドルを受け取った側が「何がいつ変わったか」を機械的に追えるようにする仕掛けです。
仕様がこれだけ小さいと「自分で決めた方が速い」と感じるかもしれません。
それでもこの2ファイルだけは予約しておくのが、後で別エージェントに食わせる時の保険になります。
OKF v0.1の限界──今すぐ本番採用すべきでない理由
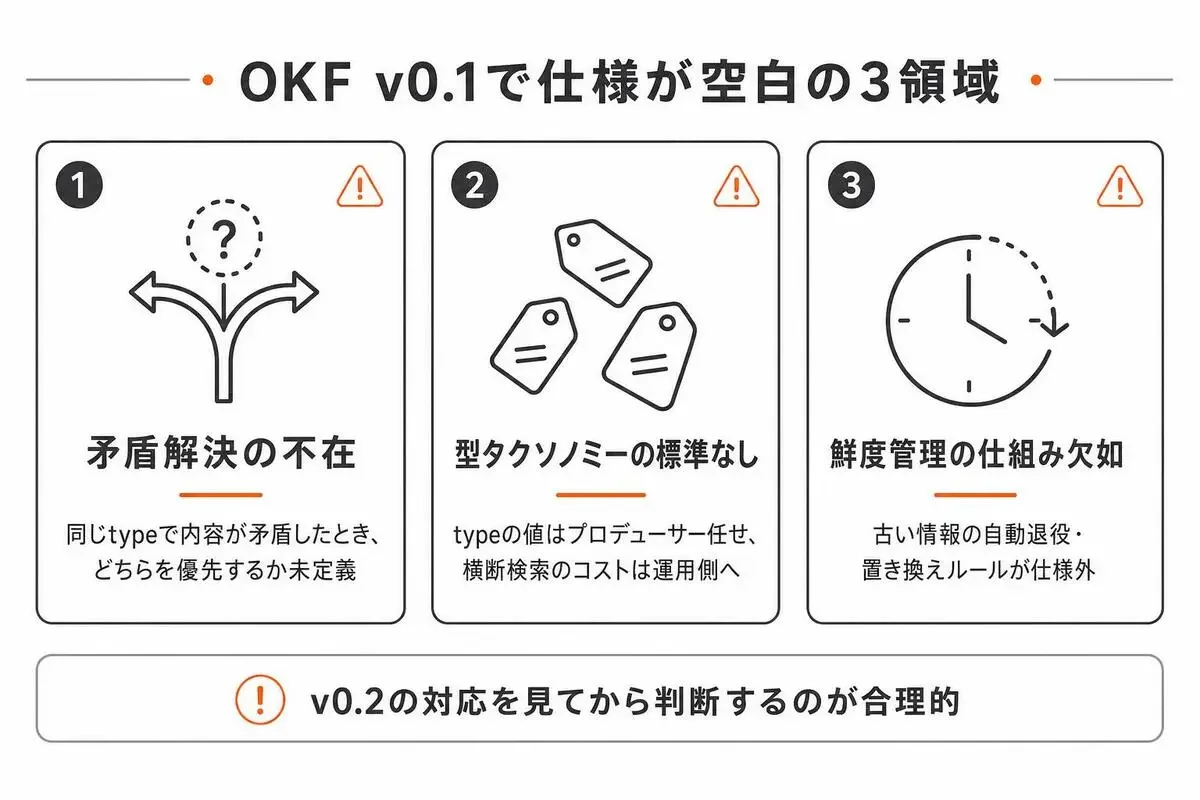
OKFの設計は筋がいいですが、v0.1の段階で本番のナレッジ基盤に据えるのは早いと判断しています。
理由は3点あります。
どれも「仕様が小さすぎる」ことの裏返しです。
仕様で未定義の3つの領域
1つ目は矛盾解決の不在です。
同じtypeで内容が矛盾する2ファイルが存在した時、どちらを優先するかの仕様がありません。
バンドルが大きくなるほどこの問題は顕在化します。
2つ目は型タクソノミーの標準なし。
typeの値はプロデューサー任せなので、Aチームがtype: Table、Bチームがtype: BigQueryTable、Cチームがtype: bq_tableと書いてもすべて準拠です。
横断検索や正規化のコストが運用側に丸投げされます。
3つ目は鮮度管理の仕組み欠如です。
timestampは書けますが、古い情報の自動退役や置き換えのルールは仕様外です。
ナレッジは古くなった瞬間に害になるので、ここは運用設計で埋める必要があります。
この3点はv0.2での対応を見てから判断するのが合理的で、今は「仕様の空白を自分で埋める覚悟があるか」が採用基準になります。
採用タイミングの判断基準
採用判断は、自分がどちら側かをまず分けると決めやすくなります。
今すぐYesでよい読者: 社内ナレッジMarkdownにtypeを足す程度の運用変更で済む人。
実装コストはほぼゼロで、v0.2へのアップグレードも文字列追加で済みます。
待った方がいい読者: 自社プロダクトにOKFパーサーを組み込む、全社ナレッジ基盤をOKFに寄せる、といったコードベースの本番投入を計画している人。
仕様がドラフトのうちに踏み込むと、後方互換性のないバージョンアップに追われる側に回ります。
仕様策定に関わる気がないなら、v0.2のRFC議論が落ち着くまで待つのが合理的です。
Open Knowledge Formatの結論:何をすれば今動き出せるか
OKFは「最小限の規約で知識をポータブルにする仕様」で、v0.1段階では本番投入より試運転が妥当です。
今日から手を動かすための最小アクションを置いておきます。
今日から始めるOKF準拠の最小アクション
- 既存のナレッジMarkdownに
typeフィールドを足す(値は自分たちで決めてOK) - ディレクトリのトップに
index.mdを置き、コンテンツ一覧を書く - 変更が走り始めたら
log.mdを作って日付ごとに残す
これだけでOKF v0.1準拠を名乗れます。
フォーマット自体に学習コストはほぼなく、明日のチーム作業で試せる軽さです。
v0.1→v0.2での注目ポイント
次バージョンで注目しているのは、型タクソノミーへの公式ガイダンスと、矛盾解決ルールの追加です。
この2つが入ると、OKFは「気軽に試す仕様」から「本番投入できる標準」に化けます。
逆にここが入らなければ、独自Markdown運用との差は埋まりません。
仕様の議論はGitHubで公開されているので、自分のチームのナレッジ運用を持ち込んで議論に参加する価値はあります。
Googleが出した最小仕様を「使うか・無視するか」の二択ではなく、「どこまで採るか」を自分で決められる距離感で扱うのが、今のOKFとの正しい付き合い方だと思っています。
まずは手元のMarkdownメモを1つ開いて、type:を1行足してみてください。
OKFとの距離感は、その1行から見え始めます。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 1
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
- 2
- 0















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます