こんにちは。もるふぉです。
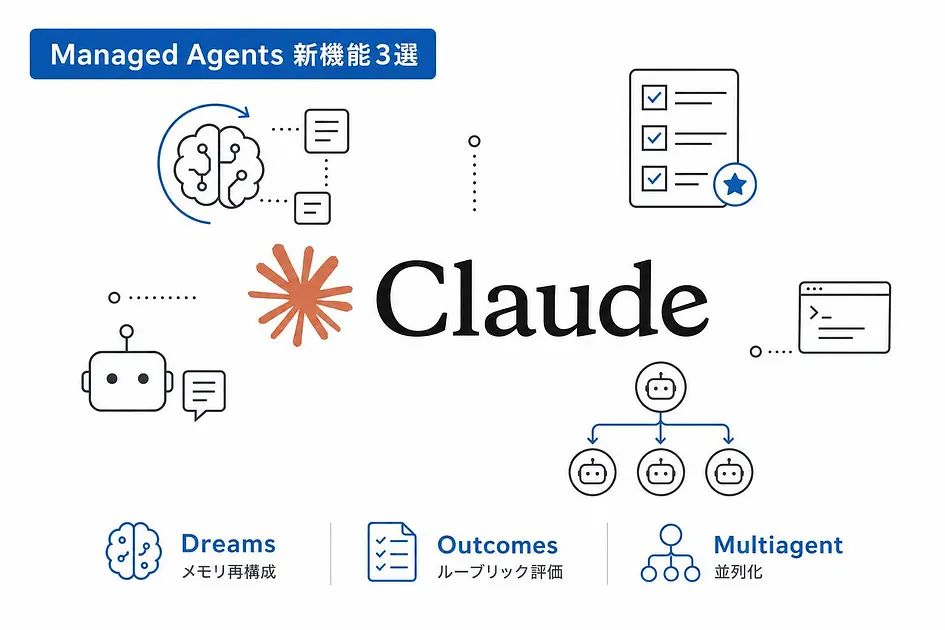
Claude Managed Agents 新機能の話をします。2026年5月6日に公開されたDreams・Outcomes・Multiagent Orchestrationの3機能です。
「エージェントを動かす」のは難しくなくなってきました。
難しいのは「動かし続ける」ことです。
メモリが腐る、品質が安定しない、単一エージェントでは処理が追いつかない——このあたりの課題、Managed Agentsを実運用に入れた人ならじわじわ感じてきているはずです。
公式ブログ(New in Claude Managed Agents)を読んだとき「なるほど、こう来たか」と声が出ました。
4月にManaged Agentsそのものが出たときは「インフラを丸ごと任せられる」のが主役でしたが、今回の3機能は「エージェントが長く動き続けたとき、品質と並列性をどう担保するか」という運用課題に踏み込んでいます。
ただ、公式ブログを読んだだけだと「結局この3機能、何ができていつ使うの?」が腑に落ちにくいと思うんですよ。
この記事では、3機能それぞれの動作原理と公式ドキュメント由来の制約値、そして実務でいつ使うかの判断軸までを一気に整理します。
なお、Managed Agentsそのものの基本構造(Brain/Hands分離、コアコンセプト、料金)は別記事でまとめているので、そちらを先に読むと理解が早いです。

この記事のゴールは、3機能の使い所が判断軸とともに頭に入って、明日からの実装に進める状態になることです。
それでは見ていきます。
Claude Managed Agents 新機能のステータス整理(Dreams / Outcomes / Multiagent)
最初に、3機能の「使える」と「まだ使えない」を分けます。
ここを最初に押さえておかないと、Dreamsを前提に設計してから「あ、本番で使えないのか」となるパターンが起きるので、地味に重要です。
実装に入る前に2分だけここを確認しておくだけで、後でのやり直しが防げます。
Research Previewの実務的な意味(Dreams)
Dreamsは現時点でResearch Previewです。
これは「触れるけど本番投入は時期尚早」というステータスで、具体的には次の制約があります。
- アクセス申請が必要(こちらのフォームから申請)
- API安定性は保証されない(破壊的変更の可能性あり)
- ベータヘッダーが2本必要
ベータヘッダーは managed-agents-2026-04-01 と dreaming-2026-04-21 の2本です。
公式ドキュメントを読み込んでいて気づいたんですが、ここで dreaming-2026-04-21 を忘れると400エラーになります。
つまり、Dreamsは「フィードバックを返しながら触っておくフェーズ」の機能です。
本番のミッションクリティカルな処理に組み込むのはまだ早い、というのが正直な感覚です。
Public Betaで今日から使える2機能(Outcomes / Multiagent)
一方でOutcomesとMultiagent Orchestrationは、どちらもPublic Betaです。
ベータヘッダーは managed-agents-2026-04-01 の1本だけで動きます。
本番利用は可能、ただし料金やレート上限は別途確認が必要、というレベル感です。
3機能の現状を表で整理しておきます。
managed-agents-2026-04-01, dreaming-2026-04-21managed-agents-2026-04-01managed-agents-2026-04-01ステータスを押さえたうえで、3機能それぞれを見ていきます。
最初は、Managed Agentsを長期運用すると必ずぶつかる「あの問題」への答えからです。
Dreams - Managed Agentsのメモリが腐る問題を解決する新機能
メモリストアを自前で運用していると、2〜3ヶ月後に「なんか壊れてきたな」という感覚になることがあります。
同じ事実が違う表現で重複していたり、古い情報と新しい情報が矛盾したまま残っていたり。
人間がレビューして整理すれば直りますが、エージェントの規模が上がるほど人手が追いつかなくなる。
Dreamsは、その問題に対するAnthropicの答えです。
なぜメモリストアは時間とともに劣化するのか
Managed Agentsはセッションをまたいで知識を蓄積できます。
ただ、運用していくと書き込みが累積していって、こんな問題が出てきます。
- 同じ事実が異なる表現で重複登録される
- 古い情報と新しい情報が矛盾したまま共存する
- セッション横断のパターン(「このユーザーは毎週金曜にこの種類の質問をする」など)が抽出されない
業務システムを運用していると、ナレッジベースが2〜3ヶ月経つと「なんか壊れてきたな」という感覚になることがあるんですが、それと似た現象です。
人間がレビューして整理すれば直りますが、エージェントの規模が上がると人手レビューが追いつかなくなります。
Dreamsが行う3つの処理(重複排除・矛盾解消・新知見抽出)
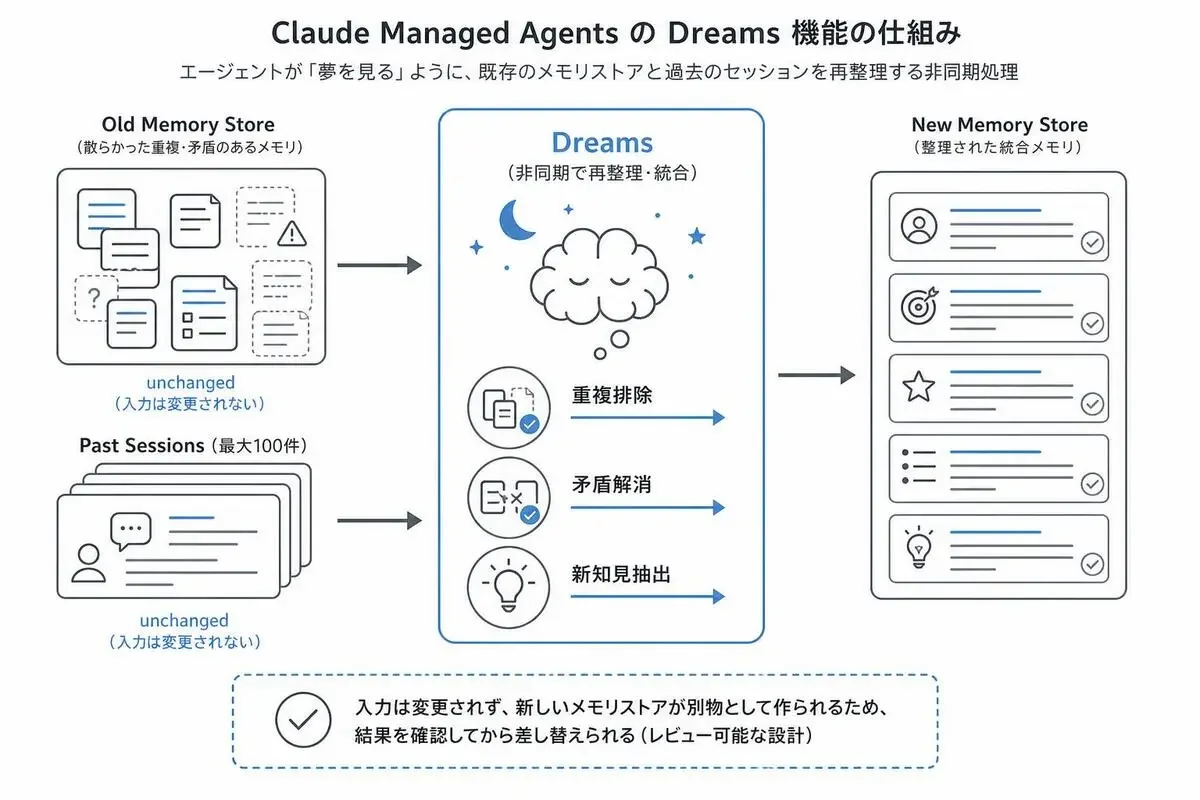
Dreamsはこの問題に対して、エージェントが「夢を見る」ように既存メモリと過去セッションを再整理する仕組みです。
ちょうど人間が睡眠中に記憶を整理するイメージ、と言うと分かりやすいかもしれません。
具体的には、inputs 配列で既存のmemory storeと過去のsession(最大100件)を受け取り、出力として新しいmemory storeを生成します。
ここがポイントなんですが、入力のmemory storeとsessionは変更されません。
新しいmemory storeが別物として作られるので、結果を確認してから差し替えられます。
これが地味にすごくて、本番のメモリを直接書き換えないので、レビュープロセスを挟めるんですよ。
「自動で整理してくれるのはいいけど、変なことになってないか確認したい」というニーズに、構造で応えています。
対応モデルは claude-opus-4-7 と claude-sonnet-4-6 の2つです。
Dreams APIの実装パターン(Python例)
Dreamsを起動する最小コードを見てみます。
非同期ジョブとして起動し、ステータスをポーリングして完了を待つパターンです。
import anthropic
import time
client = anthropic.Anthropic(
default_headers={
"anthropic-beta": "managed-agents-2026-04-01,dreaming-2026-04-21"
}
)
dream = client.beta.dreams.create(
inputs=[
{"type": "memory_store", "memory_store_id": store_id},
{"type": "sessions", "session_ids": ["sess_id_1", "sess_id_2"]},
],
model="claude-opus-4-7",
instructions="Consolidate duplicate facts and resolve contradictions.",
)
# pending → running → completed/failed/canceled
while dream.status in ("pending", "running"):
time.sleep(10)
dream = client.beta.dreams.retrieve(dream.id)
# 出力 memory_store の ID を取得
new_memory_store_id = next(
output.memory_store_id for output in dream.outputs if output.type == "memory_store"
)注目してほしいのは3点です。
1点目は、anthropic-beta ヘッダーに2つの値をカンマ区切りで渡している点です。
2点目は、inputs 配列で memory_store と sessions をそれぞれ型付きオブジェクトとして渡す点です。
3点目は、instructions に4,096文字までの自然言語指示を渡せる点で、「重複は最新を残す」「矛盾は最も信頼できるソースを優先」のように方針を制御できます。
ステータスは pending → running → completed / failed / canceled の遷移を辿ります。
課金は標準APIトークンレートで、夢を見ている間にエージェントが消費したトークン分が課金される形です。
いつDreamsを起動すべきか:実行タイミングの設計
Dreamsを「いつ起動するか」は、運用設計のキモになります。
いくつかパターンがあります。
- 定期実行型: 週次や月次でメモリ整理。運用が安定しているサービス向け
- イベント駆動型: メモリ書き込み回数が閾値を超えたら起動。スパイクが大きいサービス向け
- オフピーク型: 夜間にまとめて整理。ユーザーアクセスが昼夜で偏るサービス向け
個人的には、まずはイベント駆動型で「セッション数が80件溜まったらDreamsをキックする」あたりから試すのが扱いやすいと思います。
100件が入力上限なので、80件あたりで起動して新memory storeに切り替える設計です。
公式の事例だと、Harveyが法律ドキュメント作成タスクの完了率を約6倍に伸ばしたケースで、このDreamsを使っているとされています。
複雑な法務文書のような「過去の似た案件のパターンを参照したい」タスクで効くわけですね。
「6倍」という数字、最初は大げさに聞こえましたが、過去の判例や条文パターンをメモリが正確に持っているかどうかは、法務文書の場合それくらい品質差に直結するんだと読んで納得しました。
Dreams自体はResearch Previewですが、「メモリが腐ってきた」を感じているなら申請しておく価値はあります。
次は、今日から本番に投入できる機能の話です。自己評価のバイアスを構造で解決した、個人的に一番アツい機能です。
Outcomes - ルーブリックでエージェントを自己評価ループに入れる実装
LLMに自己評価させると採点が甘くなる問題、現場で扱ってきた人なら一度はぶつかっているはずです。
プロンプトで工夫しても、自分が作ったものを自分で審査するバイアスはなかなか取れない。
Outcomesは、この問題を「構造で」解決しています。
ここが本命だなと思った理由を説明します。
grader contextが独立している意味(なぜ別コンテキストが重要か)
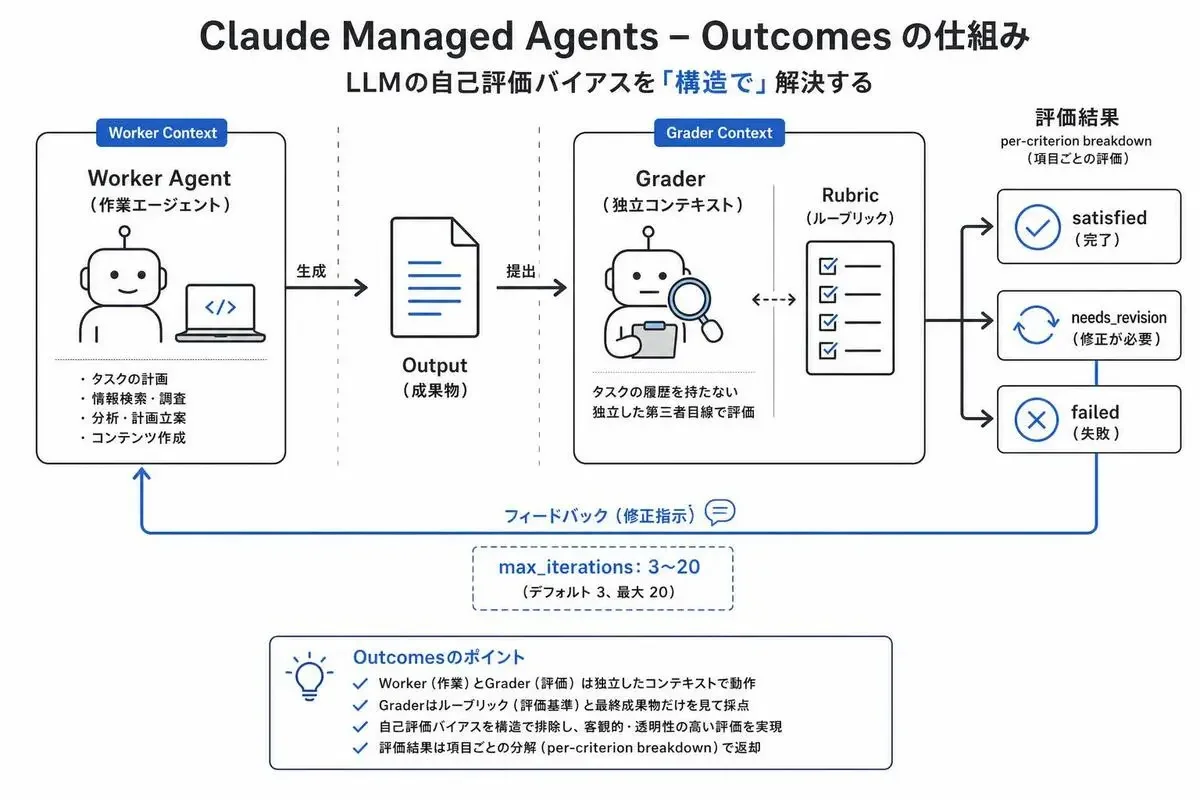
Outcomesの中核にある考え方は、graderが別コンテキストで動くという設計です。
graderというのは、エージェントの成果物を評価するLLMコールのことです。
いわば、自分の答案を別の試験官に採点してもらうイメージです。
ここがポイントなんですが、graderは作業エージェントとは独立したコンテキストで起動されます。
graderはタスクの履歴を持たず、ルーブリックと最終成果物だけを見て採点するので、独立した第三者目線になります。
最初にこの設計を読んだとき「なるほど、ここで答え合わせするのか」と声が出ました。
自己評価ループの精度問題を、プロンプトではなく仕組みで解決しているんですよ。
評価結果は per-criterion breakdown で返ってきて、ルーブリックの各項目について「どこを満たしていてどこが満たせていないか」が分解されます。
「なんとなく微妙」ではなく「項目Aはクリア、項目Bが不足」と返ってくるので、次のリビジョンで何を直すべきかが明確になります。
効果的なルーブリックの書き方(DCFモデル例をもとに)
ルーブリックはマークダウンで書きます。
公式ドキュメントのDCFモデル(割引キャッシュフローモデル)の例が分かりやすいので、考え方を引用します。
ルーブリックを書くときの大原則は「gradableな表現にする」ことです。
抽象的な「品質が高いこと」ではなく、検証可能な条件で書きます。
たとえば次のような書き方です。
# Output Requirements
## CSV Validation
- The CSV contains a `price` column with numeric values
- All rows have non-null values in `price` and `quantity`
- The CSV has at least 100 rows
## Calculation Accuracy
- The DCF terminal value uses a growth rate between 2% and 4%
- The discount rate is documented in cell B5ルーブリックは2通りの渡し方があります。
# テキストで直接渡す(rubricフィールドにcontentキーで指定)
rubric = {
"type": "text",
"content": "# Output Requirements\n\n## CSV Validation\n..."
}
# Files API経由でファイルとして渡す
rubric = {
"type": "file",
"file_id": "file_abc123"
}長いルーブリックや、複数のチームでテンプレート化したい場合はFiles API経由のほうが扱いやすいです。
注目してほしいのは、ルーブリックを「人間レビュアーへの指示書」と同じ粒度で書くことです。
graderがLLMである以上、曖昧な表現は曖昧に評価されます。
「品質が高い」ではなく「Aカラムに数値が100行以上ある」のように書く。これだけで評価の安定性がまったく変わります。
max_iterationsの設計:デフォルト3 vs 上限20のどこに設定するか
Outcomesは反復ループの上限を max_iterations で制御します。
デフォルトは3、最大は20です。
設計判断としては次のように考えます。
- 3〜5(デフォルト前後): 素早く成果物がほしいタスク。ドラフト生成、要約、定型レポート
- 5〜10(中程度): 品質要件があるタスク。技術文書、提案書ドラフト、データ検証
- 10〜20(上限近く): 高い品質が必要なタスク。法務文書、財務モデル、長文の調査レポート
max_iterations を上げるほどトークン課金は増えるので、コストと品質のトレードオフです。
私の感覚だと、最初は5あたりから始めて、graderの評価結果を見ながら調整するのが扱いやすいと思います。
評価結果が max_iterations_reached になった場合は、最終リビジョンを残してセッションがidle化します。
評価結果(satisfied / needs_revision / failed)ごとの処理分岐
graderの評価結果は5通りです。
satisfiedneeds_revisionmax_iterations_reachedfailedinterruptedfailed が出るときは、たいていルーブリックの記述とエージェントへのタスク指示の方向性が合っていないケースです。
たとえば「PDFを生成せよ」と指示しているのに、ルーブリックが「Markdownの構造を満たしているか」を見ているような噛み合わせの悪さですね。
成果物は /mnt/session/outputs/ に出力されるので、Files API(scope_id=session_id で)経由で取得します。
最小コードはこんな感じです。
import anthropic
client = anthropic.Anthropic(
default_headers={"anthropic-beta": "managed-agents-2026-04-01"}
)
# ステップ1: セッションを作成
session = client.beta.sessions.create(
agent=agent_id,
environment_id=environment_id,
title="Financial analysis on Costco",
)
# ステップ2: outcomeを定義(エージェントが即座に作業開始)
client.beta.sessions.events.send(
session.id,
events=[{
"type": "user.define_outcome",
"description": "Build a DCF model for Costco in .xlsx",
"rubric": {
"type": "text",
"content": "# DCF Model Rubric\n## Revenue Projections\n- Uses historical revenue data..."
},
"max_iterations": 5,
}]
)
# 成果物は /mnt/session/outputs/ に書き出されるので Files API で取得
files = client.beta.files.list(scope_id=session.id)実装のポイントは2ステップ構造です。
まずセッションを作成し、その後 sessions.events.send() で user.define_outcome イベントを送ることでエージェントが即座に作業を開始します。
ルーブリックは rubric フィールドに渡します。テキストで直接渡す場合は {"type": "text", "content": "..."} 、Files APIにアップロード済みのファイルを渡す場合は {"type": "file", "file_id": "..."} です。
なお、1セッションに同時に持てるoutcomeは1つですが、satisfied になったあとに続けて新しい user.define_outcome を送れば連鎖させることもできます。
公式ブログによると、Spiral(Every社)ではOutcomesを活用したAIライティングサービスを展開しているそうです。
リードエージェントにHaiku、起草を担当するサブエージェントにOpusを割り当て、Outcomesで品質基準を担保する構成だそうです。
軽量モデルでルーティング、重量モデルで起草、Outcomesで品質チェック——この三層構成は設計テンプレートとして覚えておくと汎用的に使えます。
Outcomesはルーブリック1枚から試せます。既存のManaged Agentsセッションに足すだけなので、まず試してみるハードルは思っているより低いです。
では次は、並列処理と専門化を一気に実現する3つ目の機能へ。
Multiagent Orchestration - 25スレッドと20エージェントで何ができるか
単一エージェントだと、処理時間か品質かのどちらかを犠牲にする選択を迫られる場面があります。
「並列で投げたいけど、別々のセッションを自前で管理するのが面倒」「ドメインごとに専門プロンプトを分けたいけど、ルーティングのロジックを書くのがしんどい」——そのあたりを解消するのがMultiagent Orchestrationです。
これも今日からPublic Betaで使えます。
coordinator + subagentの設計パターン3選(並列化 / 専門化 / エスカレーション)
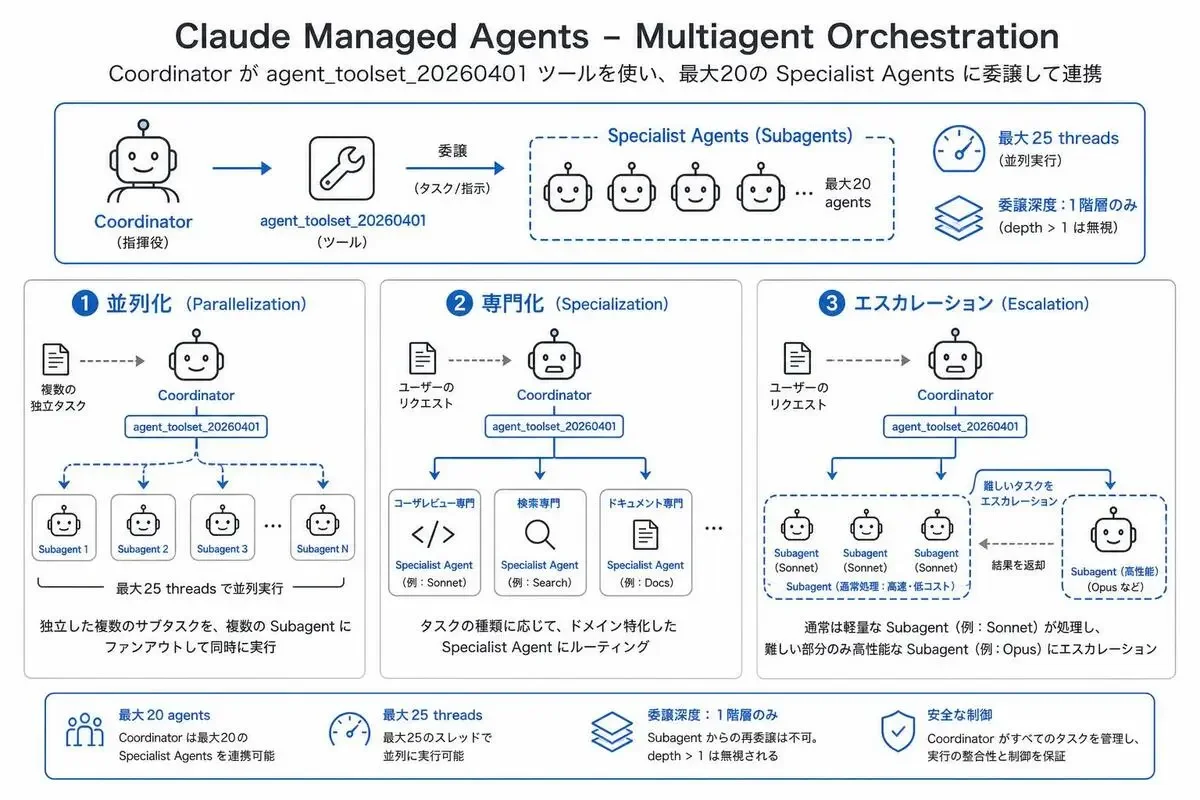
Multiagent Orchestrationは、coordinator(指揮役)が複数のsubagent(専門役)に作業を委譲する仕組みです。
料理に例えると、coordinatorがプロデューサーで、各subagentがセクション担当のシェフです。
プロデューサーがメニュー全体を見渡して「前菜はAさん、メインはBさん」と指示を振り、各シェフは自分の専門に集中して仕上げる。coordinator側は「何をどのsubagentに投げるか」を自動でやってくれるので、開発者がルーター実装を書かなくて済みます。
公式ドキュメントが整理している設計パターンは3つあります。
1. 並列化(Parallelization)
独立したサブタスクを並列で投げるパターンです。
たとえば「100件の顧客レビューを分析して、感情とトピックを抽出する」というタスクなら、subagentに10件ずつ振り分けて並列実行できます。
Netflixが数百のビルドログを並列で分析する事例で使っているのが、まさにこのパターンです。
2. 専門化(Specialization)
ドメイン特化のサブエージェントにルーティングするパターンです。
「コード生成は CodeAgent、ドキュメント執筆は DocAgent、データ分析は DataAgent」のように、それぞれ最適なシステムプロンプトとツール構成を持たせます。
3. エスカレーション(Escalation)
簡単な部分はHaiku、難しい部分はOpus、というように難易度に応じて重量級モデルにエスカレーションするパターンです。
コスト最適化と品質担保の両立に効きます。
agent_toolset_20260401とスレッドの仕組み
Multiagent Orchestrationを使うには、coordinator側に agent_toolset_20260401 というツールセットを渡す必要があります。
これを渡すと、coordinatorはサブエージェントに作業を委譲するための内部ツールを使えるようになります。
スレッドの仕組みは次のとおりです。
- 各サブエージェントの呼び出しは独立したスレッドで動く
- スレッドはエージェントごとに独立したコンテキストを持つ
- エージェント間で共有されるのは container と filesystem のみ
- 同時稼働できるスレッドは最大25(archiveで枠を解放可能)
- 委譲は1階層のみ(
depth > 1は無視される)
ここで気をつけたいのは、エージェント間でコンテキストが共有されないという点です。
つまり、subagent Aが知った事実をsubagent Bが直接参照することはできません。
共有したい情報はファイルに書き出してfilesystem経由で渡す、という設計になります。
このセキュリティ設計は地味に重要で、subagent間のプロンプトインジェクション伝播を構造的に防いでいます。
なお、{type: "self"} を指定するとcoordinatorの複製をsubagentとして使えます。
同じ役割の処理を並列で投げたいときに便利です。
実装コードの最小構成(Python)
coordinatorとsubagentのrosterを定義する最小コードはこんな形です。
import anthropic
client = anthropic.Anthropic(
default_headers={"anthropic-beta": "managed-agents-2026-04-01"}
)
# 専門エージェントを先に作っておく前提
# research_agent_id, writer_agent_id, reviewer_agent_id
coordinator = client.beta.agents.create(
name="Engineering Lead",
model="claude-opus-4-7",
system=(
"You coordinate engineering work. "
"Delegate research to the research agent, drafting to the writer agent, "
"and review to the reviewer agent."
),
tools=[{"type": "agent_toolset_20260401"}],
multiagent={
"type": "coordinator",
"agents": [
{"type": "agent", "id": research_agent_id},
{"type": "agent", "id": writer_agent_id},
{"type": "agent", "id": reviewer_agent_id},
],
},
)
# coordinator を agent として session を作成すると、自動的に委譲が始まる
session = client.beta.sessions.create(
agent=coordinator.id,
environment_id=environment_id,
)注目してほしいのは3点です。
1点目は、coordinatorに agent_toolset_20260401 を渡すこと。これがcoordinatorの必須ツールです。
2点目は、multiagent フィールドに "type": "coordinator" を明示すること。
3点目は、roster内の各エージェントを {"type": "agent", "id": ...} の形式で参照すること。{"type": "self"} を使えばcoordinator自身の複製もrosterに入れられます。
これだけで、coordinatorはタスクの内容を見て自動でsubagentに委譲します。
開発者側は「どのsubagentに何を投げるか」のロジックを書かなくていいんですよ。
これが地味にすごい点で、自前でルーター実装をしなくて済みます。
Harvey / Netflix / Wisedocs の事例から読む設計の勘所
公式ブログで紹介されている導入事例から、設計の勘所を読み解いておきます。
ここから読み取れる設計テンプレートは2つあります。
1つ目は「軽量モデルでオーケストレーション、重量モデルで起草、Outcomesで品質チェック」の三層構成です。
Spiralの構成がそのままテンプレートとして使えます。
2つ目は「Multiagentは独立性が高いタスクで効く」という点です。
Netflixの数百ビルドログのように、タスクが独立しているほど並列化のメリットが大きく、共有が必要な情報が多いほどfilesystem経由のコストが効いてきます。
3機能の動作を把握したところで、次は「実務でどれを選ぶか」を整理します。
実務でいつ使うか:Claude Managed Agents 新機能の判断フロー
「3機能の使い所はなんとなく分かった。でも自分のプロジェクトにどれを当てはめるか」——ここが一番迷うポイントだと思います。
迷ったときの初手として使えるよう、判断軸を整理します。
Dreamsを選ぶ条件(メモリセッション数・運用期間)
Dreamsは次の条件が揃ったときに検討します。
- メモリストアが肥大化してきた(数十〜数百セッション分のデータが溜まっている)
- 同じ知識を異なるセッションで重複して蓄積している
- 運用期間が長期で、過去セッションのパターンを抽出したい
- Research Previewであることを許容できる(本番ミッションクリティカルでない領域)
逆に「メモリがまだ少ない」「短期運用」「本番で安定性が必須」の場合は、Dreamsは時期尚早です。
Outcomesを選ぶ条件(品質担保が必要なタスク)
Outcomesは次の条件のときに刺さります。
- 成果物の品質基準を明文化できる(ルーブリックに落とせる)
- 人間レビューを挟まずに反復させたい
- 「LLMが途中で止まる」「中途半端な状態で出力する」課題がある
- 品質要件があり、コストよりも品質を優先したい場面がある
特に「品質基準を明文化できる」が重要です。
ルーブリックに書けない曖昧な品質はOutcomesでも解決できません。
「なんかいい感じに」では動きません。「Aカラムが数値型で100行以上」まで落とせるかどうか、が使えるかどうかの分岐点です。
Multiagentを選ぶ条件(並列処理・専門特化が必要なタスク)
Multiagentは次の条件で選びます。
- タスクが独立した複数の作業に分解できる
- ドメイン特化のシステムプロンプトを使い分けたい
- 単一エージェントだと処理時間か品質のどちらかを犠牲にしている
- 軽量モデルでルーティング、重量モデルで起草、のような構成を組みたい
タスクが分解できないモノリシックな処理だと、Multiagentのメリットは出にくいです。
判断フローを表でまとめておきます。
3機能は組み合わせて使えるので、課題が複合している場合は「OutcomesとMultiagentを併用」のような設計も視野に入ります。
判断軸が整理できたら、最後に実装前に確認しておきたい制約値をまとめて見ておきます。
実装前チェックリスト:Claude Managed Agents 新機能の制約まとめ
実装前に確認しておきたい数値・制約を、機能ごとに表にまとめます。
後から「あ、上限超えてた」「この制約、知らなかった」となるのを防ぐために、実装に入る前に一度ここを通しておくことをおすすめします。
Dreamsの制約
managed-agents-2026-04-01, dreaming-2026-04-21instructions 上限claude-opus-4-7, claude-sonnet-4-6Outcomesの制約
managed-agents-2026-04-01max_iterations{type: "text", content: "..."} または {type: "file", file_id: "..."}satisfied / needs_revision / max_iterations_reached / failed / interrupted/mnt/session/outputs/scope_id=session_id)Multiagent Orchestrationの制約
managed-agents-2026-04-01agent_toolset_20260401multiagent.typecoordinator を指定{"type": "agent", "id": ...} または {"type": "self"}depth > 1 は無視)特に、Multiagentの「委譲深度1階層のみ」は誤解しやすいポイントです。
「subagentがさらにsubagentを呼ぶ」という階層構造は組めないので、フラットな委譲構造で設計する必要があります。
「25 concurrent threads」という数字も、設計段階で頭に入れておくと実装後の驚きが防げます。
まとめ:Claude Managed Agents 新機能を試すならどこから
3機能を一言で再整理すると、こうなります。
- Dreams: メモリストアの腐りを再構成で解決する(Research Preview、申請必須)
- Outcomes: ルーブリックでエージェントを自己評価ループに入れる(Public Beta、今日から使える)
- Multiagent Orchestration: 25スレッド・20エージェントで並列・専門化・エスカレーションを実装する(Public Beta、今日から使える)
「まずどこから触るべきか」の個人的なおすすめ順は次のとおりです。
- Outcomesから始める: 既存のManaged Agentsセッションにルーブリックを足すだけで動くので、入口が一番低い
- 次にMultiagent: 既存エージェントを複数組み合わせるだけで動く。並列タスクがある人は効果が見えやすい
- 最後にDreams(申請して触る): 申請して、メモリ運用の知見を貯めながらフィードバックを返す
特にOutcomesは、今日からPublic Betaで使えます。
明日の朝イチで max_iterations: 3 の最小構成で投げてみてください。
ルーブリックは1枚でいい。「Aカラムに数値が入っていること」「出力ファイルが存在すること」、それくらいの粒度で十分動きます。
graderが別コンテキストで動くという設計、実際に触れると「自己評価のバイアスがいかに厄介な問題だったか」が体感できます。
3機能とも、エージェントを「動かす」段階から「運用する」段階へ進むための機能群です。
Managed Agents自体を触り始めたばかりの方は、まずは基本構造を押さえてから新機能に進むのが安全です。
新機能の検証や、実装でハマったポイントなど、X(@morphox_ai)やnote(note.com/morphox)でも発信しているので、よければフォローしておいてください。
それでは、よいエージェント運用を。
- 1
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 1
- 0
-
プロンプト画伯
- 1
- 0
-
AI脱社畜
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 1
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI集客@ルイ
- 5
- 0
-
- 2
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 4
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
- 3
- 0
-
- 3
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI集客@ルイ
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI集客@ルイ
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
- 3
- 0

















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます