
「AIエージェントフレームワーク、結局どれを使えばいいの?」——正直、もう選びきれなくないですか?
AutoGen、CrewAI、LangGraphと選択肢が増え続ける中、2026年2月末にByteDanceがオープンソースで公開したDeerFlow 2.0が、リリース24時間以内にGitHub Trending 1位を獲得しました。
なぜこれほど注目されたのか。
答えは「提案するAI」から「実行するAI」への本質的な転換にあります。
DeerFlow 2.0は、サブエージェント・サンドボックス・長期メモリ・MCP対応を備えたオープンソースのAIエージェント実行基盤です。
単にタスクの提案をするだけじゃありません。 実際にコードを書き、ファイルを操作し、Webサイトを構築し、レポートを生成する。
いわば「AIに自分専用のパソコンを渡して仕事を任せる」——そんなコンセプトのSuperAgentハーネスなんです。
この記事では、DeerFlow 2.0のアーキテクチャから主要機能、セットアップ方法、そして競合フレームワークとの違いまでを一気に解説していきます。
DeerFlowの名前の由来:Deep Exploration and Efficient Research Flow
DeerFlowは「Deep Exploration and Efficient Research Flow」の頭文字を取った名前です。
名前の通り、もともとは深い調査・リサーチを効率的に回すためのフレームワークとして生まれました。
開発元はTikTokの親会社として知られるByteDance。
MITライセンスで公開されているので、誰でも無料で利用・改変・商用利用ができます。
v1からの完全書き直し:Deep ResearchツールからフルスタックSuperAgentへ
ここが面白いところなんですが、DeerFlow 2.0はv1のコードを一切引き継いでいません。
完全にゼロから書き直されています。
v1は2025年5月頃にDeep Research(深い調査)に特化したフレームワークとして公開されました。
ところが、コミュニティが実際に使い始めると、リサーチだけでなくデータパイプラインの構築、スライドデッキの作成、ダッシュボードの生成など、想定を超えた使い方がどんどん広がっていったんです。
「DeerFlowはリサーチツールではなく、仕事を片付けるためのハーネスだった」——開発チームがこの事実に気づき、v2では設計思想そのものを転換しました。
LangGraphとLangChainをベースに、あらゆるタスクを実行できる「SuperAgentハーネス」として再構築したわけです。
v1を現在使っている方は、v2への移行は「アップグレード」ではなく「乗り換え」と考えた方が現実的です。
APIや設定ファイルの互換性はなく、スキルやワークフローの再定義が必要になります。
ただし、DeerFlowの根本的な動き方を知っているユーザーであれば、学習コストは低く抑えられるはずです。
GitHubリリース24時間以内に急上昇1位・39,000スターを獲得した背景
2026年2月末の公開後、翌2月28日にはGitHub Trendingで1位を獲得しました。
その後約1か月で39,000スターを超え、3月下旬時点では46,000スターに迫る勢いです。 AIエージェント関連プロジェクトとしては異例のペースですよね。
この勢いの背景には、v1で培われたコミュニティの期待感と、「フレームワークではなく完全なランタイム」という明確なポジショニングがあります。
では、具体的にどんなアーキテクチャでこれを実現しているのか、見ていきましょう。
DeerFlow 2.0のコアアーキテクチャ:LangGraph + LangChainベースの設計
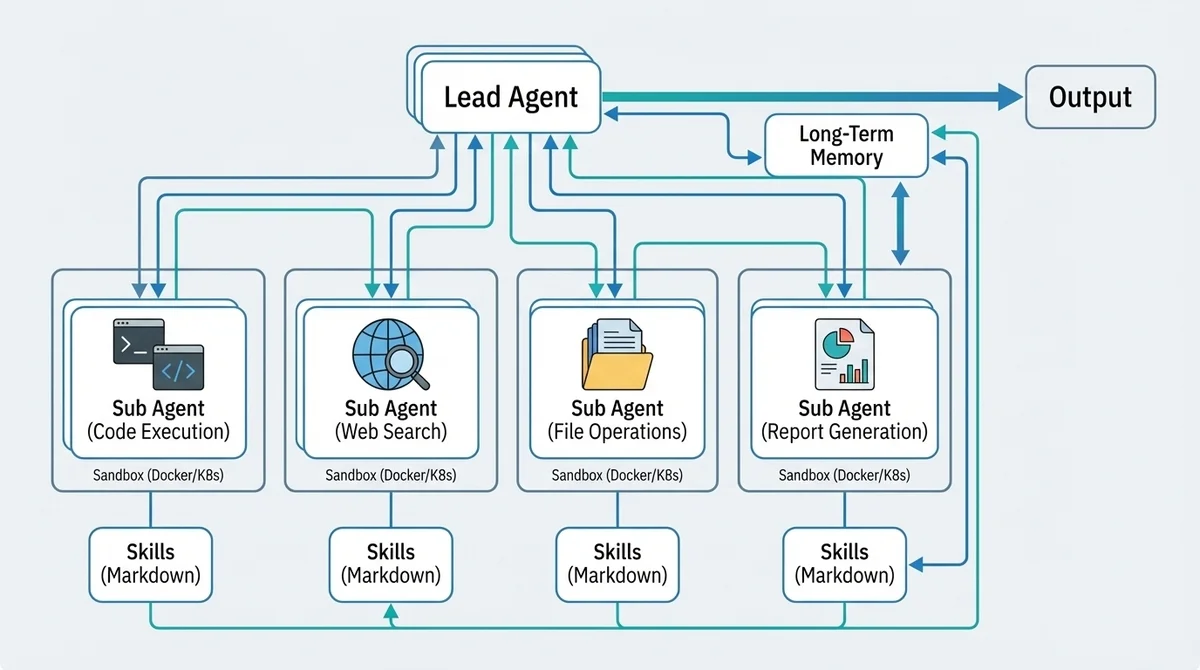
DeerFlow 2.0の技術基盤はLangGraphとLangChainです。
バックエンドはPython 3.12+、フロントエンドはNode.js 22+で構成されています。
ただし、LangGraphをそのまま使っているわけではありません。
DeerFlowはLangGraphの上に「SuperAgentハーネス」という独自の実行層を積み上げています。
サブエージェント管理・メモリ・サンドボックス・スキルシステムを統合的に扱える構成で、これが地味にすごいんですよ。
リードエージェント + サブエージェントのトポロジー
DeerFlow 2.0の中核は「リードエージェント + サブエージェント」の階層構造です。
リードエージェントがタスクを受け取ると、必要に応じてサブエージェントをオンデマンドで生成します。
各サブエージェントは独自のコンテキスト、ツール、終了条件を持ち、隔離された環境で並列に実行されます。
完了すると構造化された結果をリードエージェントに返し、リードエージェントがそれを統合して最終的な出力を組み立てるという仕組みです。
料理に例えると、リードエージェントはヘッドシェフで、サブエージェントは各セクションを担当する料理人たち。
前菜・メイン・デザートを並行して準備し、ヘッドシェフが全体のコースとして仕上げるイメージが近いですね。
サンドボックス実行:DockerコンテナとKubernetesによる安全な隔離環境
「AIエージェントにコードを実行させるのは怖い」——この気持ち、めちゃくちゃ分かります。
その懸念に対するDeerFlowの答えがサンドボックス実行です。
DeerFlow 2.0では、エージェントに実際のコンピュータ環境を与えます。
隔離されたDockerコンテナ内に専用のファイルシステム(アップロード用、作業用、出力用の3つのパス)とbashターミナルが用意され、安全にコードを実行できるんです。
実行モードは3種類用意されています。
- ローカル実行: ホストマシン上で直接実行(開発・テスト用)
- Docker実行: 隔離されたコンテナ内で実行(推奨)
- Kubernetes実行: Podとしてプロビジョニング(大規模運用向け)
つまり、エージェントは「提案する」だけじゃなくて「実行する」んです。
コードを書いて走らせ、結果を確認し、必要なら修正する——という一連の作業を自律的にこなせます。
これが何が嬉しいかっていうと、今まで人間が手を動かしていた「コード実行→確認→修正」のサイクルを丸ごとエージェントに任せられるんですよ。
スキルシステム:Markdownで定義する拡張可能な能力モジュール
個人的にかなり筋が良いと感じた設計がこのスキルシステムです。
スキルとは、Markdownファイルで定義された「構造化された機能モジュール」のこと。
ワークフロー、ベストプラクティス、リソース参照がひとつのファイルにまとまっています。
リサーチ、レポート生成、スライド作成、Webページ構築、画像・動画生成などの組み込みスキルが同梱されており、カスタムスキルは /mnt/skills/custom/ に配置するだけで自動認識されます。
ここがミソなんですが、スキルはプログレッシブロード(必要な時に必要な分だけ読み込む)に対応しているため、コンテキストウィンドウを圧迫しません。
しかもMarkdownで書けるので、プログラミングの知識がなくてもスキルを作成・カスタマイズできます。
「え、Markdownだけでエージェントの能力を拡張できるの?」って思いますよね。 はい、本当にそれだけなんです。
DeerFlow 2.0の5つの主要機能
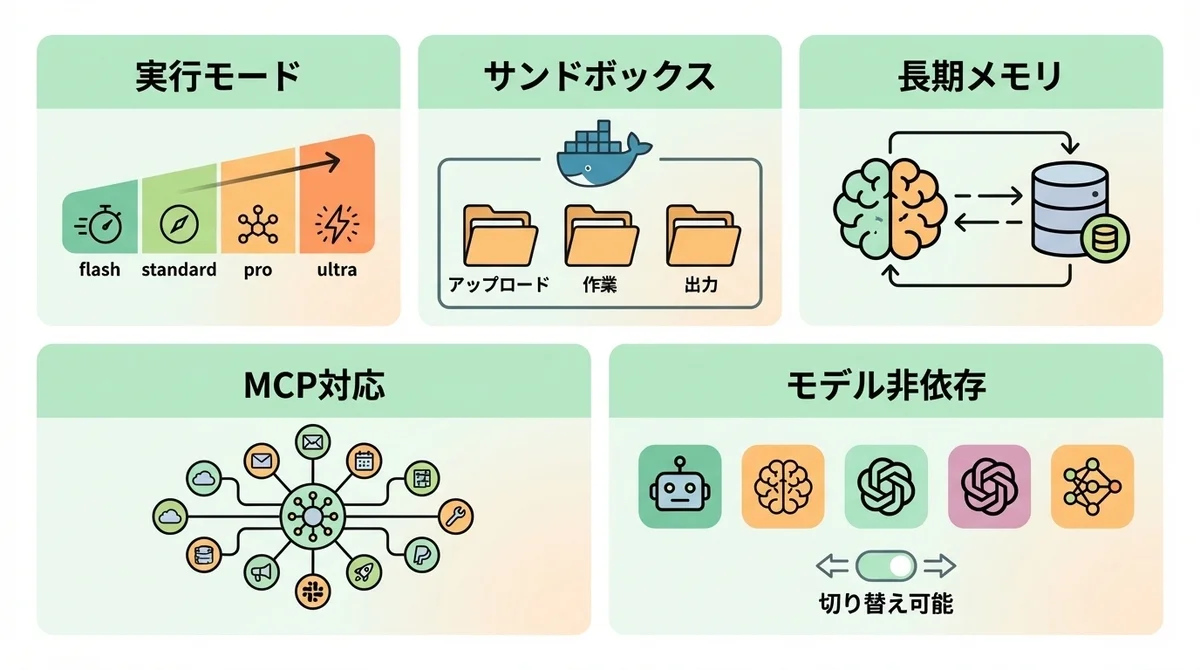
1. 実行モードの使い分けで、コストとパフォーマンスを最適化
アーキテクチャで述べたサブエージェントの仕組みを、実際にどう使い分けるか。 DeerFlowには4段階の実行モードが用意されています。
- flash: 高速応答(簡単な質問・タスク向け)
- standard: 標準的な処理
- pro: 計画を立ててから実行(複雑なタスク向け)
- ultra: サブエージェントを活用した本格的なマルチエージェント実行
「ちょっとした質問にultraモードは使わない」という当たり前のことが、フレームワークレベルで設計されているのがありがたいです。
API費用を気にする場面ではflash、本気で複雑なタスクを任せたい場面ではultra——この切り替えが設定一つでできるのは、実用上かなり助かります。
2. サンドボックスのファイルシステム設計
サンドボックス内のファイルシステムは、用途ごとに明確に分離されています。
/mnt/user-data/uploads: ユーザーがアップロードしたファイル/mnt/user-data/workspace: エージェントの作業スペース/mnt/user-data/outputs: 成果物の出力先
たとえば「このCSVを分析してグラフを作って」と依頼すると、エージェントはuploadsからファイルを読み込み、workspaceでPythonコードを書いて実行し、完成したグラフをoutputsに出力します。
ホストマシンの重要なファイルに触れるリスクを排除しつつ、実際のファイル操作ができる。
これ、セキュリティと実用性のバランスがすごく上手いんですよ。
3. セッションをまたぐ長期メモリ(Long-Term Memory)
ここが最も実用上の差が出るポイントかもしれません。
DeerFlow 2.0はセッション間で知識を蓄積する永続メモリを備えています。
あなたの書き方の癖、プロジェクトの構造、過去の指示の傾向——こうした情報をセッションをまたいで記憶し、次回以降の対話に反映してくれます。
メモリはローカルに保存されるため、外部に情報が漏れる心配もありません。
さらに、コンテキスト最適化として、完了したサブタスクの自動要約や中間結果のファイルシステムへのオフロードが行われます。
これにより、長時間のタスクでもコンテキストウィンドウが溢れにくくなっています。
ただし正直に言うと、エージェントシステムにおける永続メモリは「設計上は解決済みだが実装上はまだ粗い」領域でもあります。
過度に期待せず、徐々に学習が蓄積されていく感覚で使うのが良いと思います。
4. MCP(Model Context Protocol)対応とClaude Code統合
DeerFlow 2.0はMCP(Model Context Protocol)に対応しており、外部ツールやサービスとの接続を拡張できます。
OAuthトークンフロー(クライアントクレデンシャル、リフレッシュトークン)にも対応しているため、認証が必要なサービスとの連携も可能です。
さらに注目したいのがClaude Codeとの統合です。
claude-to-deerflow というスキルが用意されており、Claude Codeのターミナルから直接DeerFlowにタスクを投げることができます。
ストリーミングメッセージの送信、実行モードの選択、スレッド管理、ファイルアップロードなど、本格的な連携が可能になっています。
Claude Codeユーザーにとっては、これだけでも試す価値がありますよね。
5. モデル非依存:GPT・Claude・Gemini・DeepSeekに対応
DeerFlowはモデルに依存しない設計になっています。
OpenAI互換のAPIであれば何でも接続できるため、以下のようなモデルが利用可能です。
- OpenAI GPT系
- Anthropic Claude系
- Google Gemini系
- DeepSeek
- Ollamaを通じたローカルモデル
config.yaml で複数のモデルを設定でき、タスクの性質に応じて使い分けることもできます。
ByteDanceが推奨するモデルはDoubao-Seed-2.0-Code、DeepSeek v3.2、Kimi 2.5の3つですが、もちろんこれに縛られる必要はありません。
自分の好きなモデルを自由に組み合わせられるのは嬉しいポイントです。
DeerFlow 2.0のセットアップと使い方
必要環境(Python 3.12+、Node.js 22+、Docker)
DeerFlow 2.0を動かすために必要な環境は以下の通りです。
- Python 3.12以上
- Node.js 22以上(フロントエンド)
- Docker(サンドボックス実行に必要)
- pnpm、uv、nginx(ローカル開発の場合)
GUIインストーラーは用意されていないため、ターミナル操作、Docker、YAML設定ファイルの基本的な知識は必要になります。
Dockerを使った起動手順
最も簡単な方法はDocker経由のセットアップです。
公式リポジトリ(bytedance/deer-flow)をクローンするところから始めましょう。
# 1. リポジトリをクローン
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
# 2. 設定ファイルを生成
make config
# 3. config.yaml でモデルを設定(使いたいLLMのAPI情報を記入)
# 4. サンドボックスイメージを取得(初回のみ)
make docker-init
# 5. サービスを起動
make docker-startこれで http://localhost:2026 にアクセスすれば、DeerFlowのWebインターフェースが使えます。
「え、これだけ?」って思いますよね。
本当にこれだけなんです。
ローカル開発環境で動かしたい場合は、make check で依存関係を確認し、make install でインストール、make dev で開発サーバーを起動します。
日本語環境での注意点とコスト感
日本語環境でDeerFlowを使う際には、いくつか知っておくべきことがあります。
まず、Web検索結果が英語に偏りやすいという点。
v1時代からの既知の課題で、リサーチタスクで日本語の情報を収集したい場合は、プロンプトで明示的に日本語での検索を指示する必要があります。
ここはちょっとしたひと手間ですが、知っておけば対処できます。
次にコスト感について。
マルチエージェント構成の性質上、シングルエージェントと比較してAPI呼び出し回数は増えます。
これはDeerFlow固有の問題ではなくマルチエージェントアーキテクチャ全般の特性ですが、ultraモードで複雑なタスクを実行すると相応のAPI費用がかかる点は把握しておきたいところです。
flashモードで簡単なタスクを処理する分にはコストは抑えられます。
また、メッセージング統合としてTelegram、Slack、Feishu/Larkに対応しています。
チャットからタスクを投げられるのは便利ですが、日本で主流のSlack以外はやや馴染みが薄いかもしれませんね。
DeerFlow 2.0 vs AutoGen vs CrewAI vs LangGraph:フレームワーク比較
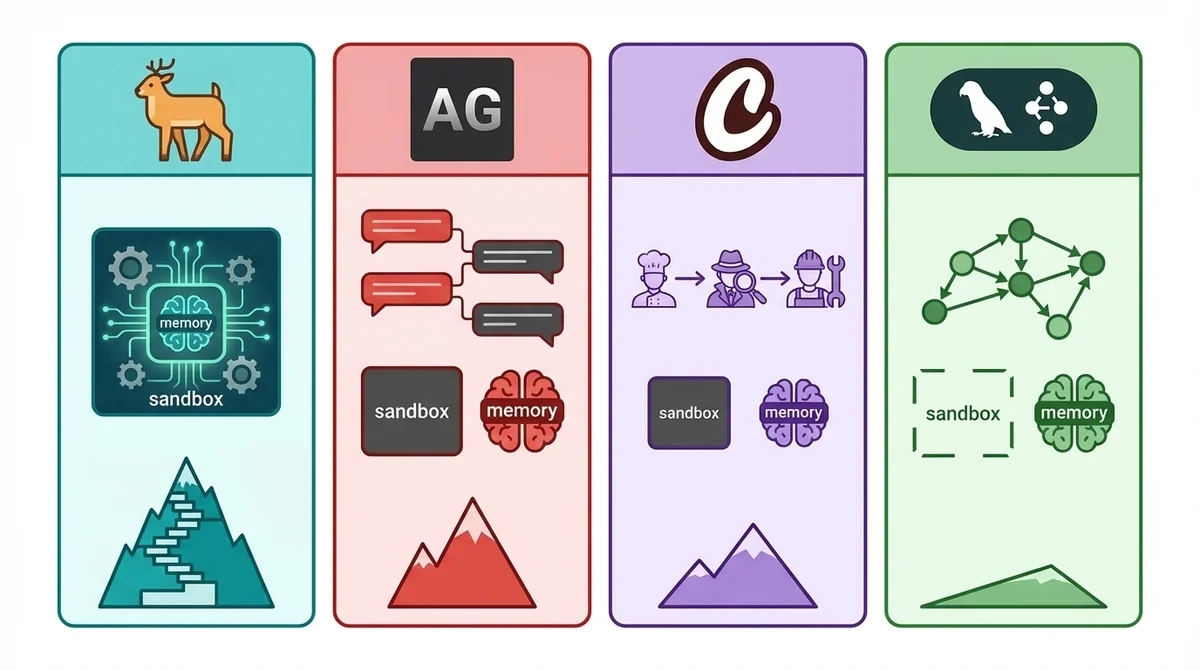
アーキテクチャ・学習コスト・ユースケース比較表
DeerFlowを選ぶべきか、それともAutoGenやCrewAIの方が自分のユースケースに合うのか——その判断基準を比較表で整理してみましょう。
なお、AutoGenは2026年2月にMicrosoft Agent Framework(AutoGen + Semantic Kernelの統合)のRC1がリリースされ、単体としてはメンテナンスモードに移行しつつあります。
AutoGenを新規採用する場合は、Microsoft Agent Frameworkの動向も確認しておくのがおすすめです。
DeerFlowはLangGraphの上に構築されている点がポイントです。
LangGraph単体で同等の機能を実現しようとすると、サンドボックス・メモリ・スキルシステムをすべて自前で実装する必要があります。
DeerFlowは、そうした「バッテリー同梱」のアプローチでLangGraphの上位レイヤーとして機能しているんです。
つまり、LangGraphの面倒な部分をDeerFlowがまるっと引き受けてくれている感覚ですね。
DeerFlowが最適なケース・向いていないケース
DeerFlowが向いているケース:
- コード実行を含む長時間タスクを自律的に処理したい
- サンドボックス環境で安全にエージェントを動かしたい
- セッション間で学習を蓄積したい
- MCPをネイティブレベルで外部ツールと統合したい
- 自社のワークフローに合わせたスキルをMarkdownで定義したい
DeerFlowが向いていないケース:
- 「今日中にとりあえず動くものを作りたい」→ CrewAIの方が立ち上がりが早い
- 研究目的で会話型のマルチエージェントを試したい → AutoGenの方が適している
- Docker環境を用意できない / したくない → DeerFlowのサンドボックスの恩恵を受けにくい
- API呼び出しコストを最小限に抑えたい → マルチエージェント構成はコストが増える
DeerFlow 2.0の主なユースケース
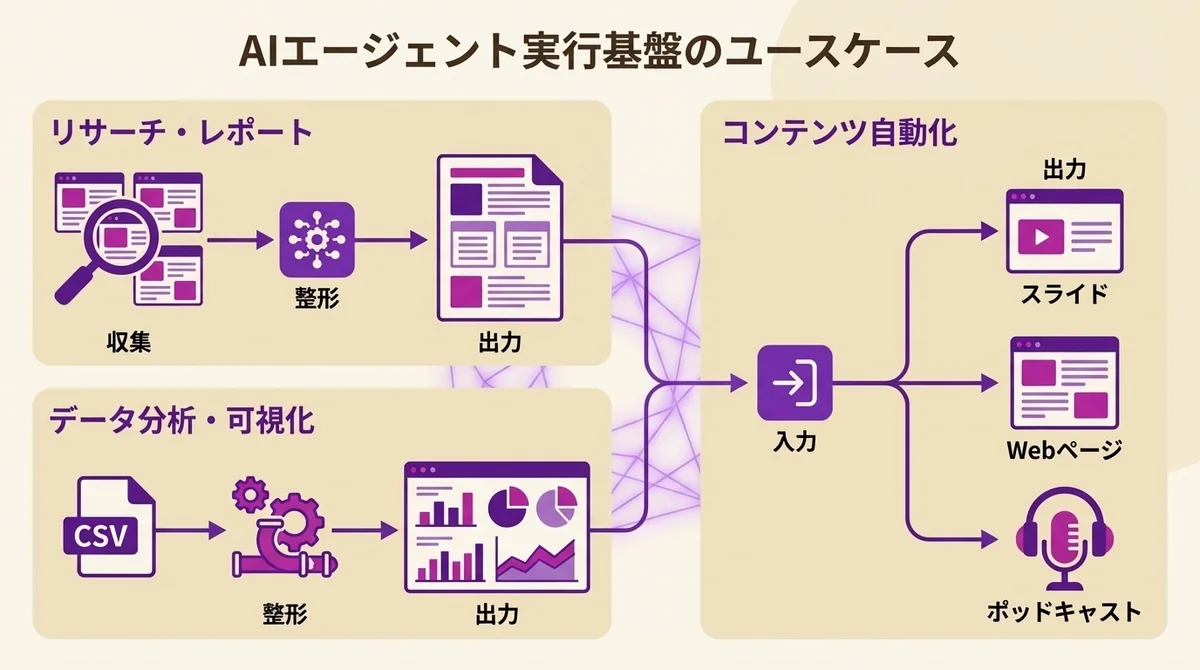
リサーチ・レポート自動生成
DeerFlowのルーツであるリサーチ機能は、v2でも健在です。
テーマを投げると、Web検索・情報収集・要約・レポート構成を自動で行い、構造化されたレポートを出力してくれます。
複数のサブエージェントが並行して情報を収集し、リードエージェントが統合するため、人間が手作業で行うよりも網羅的な調査が可能です。
「とりあえずこのテーマで調べて」と投げるだけで、しっかりしたレポートが上がってくるのは体験として新鮮ですよ。
データパイプラインとダッシュボード構築
サンドボックス実行の恩恵が最も出るのがこの領域です。
「CSVファイルを読み込んで、データを整形して、可視化ダッシュボードを作って」というタスクを投げると、エージェントがサンドボックス内でPythonコードを書いて実行し、成果物を /mnt/user-data/outputs に出力します。
今まで手作業で30分かかっていたデータ整形+可視化が、指示を出すだけで完了するのは感動モノです。
コンテンツ自動化ワークフロー
スライドデッキの作成、Webページの構築、さらにはポッドキャストの生成まで、DeerFlowの組み込みスキルでカバーされています。
スキルシステムが拡張可能なため、自社独自のコンテンツワークフローをMarkdownで定義して組み込むこともできます。
「自分の仕事に合わせてエージェントをカスタマイズできる」——これが一番ワクワクするポイントかもしれません。
まとめ:DeerFlow 2.0は「AIスタッフ」の実現にどこまで近づいているか
DeerFlow 2.0は、AIエージェントフレームワークの中でも「完全なランタイム」を目指している点でユニークです。 サブエージェント、サンドボックス、永続メモリ、スキルシステム、MCP対応——これらを統合的に備えた実行基盤は、現時点ではDeerFlowが最も包括的と言えます。
一方で、いくつかの留意点もあります。
ByteDance発のプロジェクトという点は、組織によっては追加のセキュリティ審査が必要になるかもしれません。 コードはMITライセンスでGitHubに公開されており監査可能ですが、規制の厳しい業界ではサプライチェーン分析を実施した上で判断するのが安全です。
また、GUIインストーラーがなく、Docker・YAML・ターミナル操作の知識が前提となるため、エンジニア以外のユーザーにはハードルが高めです。 39,000スターという数字が示すコミュニティの熱量は本物ですが、「AIエージェントの永続メモリ」のように、設計上は解決済みでも実装上はまだ成熟途上の部分もあります。
それでも、DeerFlow 2.0は今すぐ試す価値があります。
git clone して make docker-start するだけで、AIエージェントが自律的にタスクをこなす世界を体験できるんです。
「AIスタッフ」の実現はまだ道半ばです。
しかし、その最前線がどこにあるかを自分の目で確かめておくことは、2026年のAI活用を考えるすべての開発者にとって意味があります。
まずはflashモードで簡単なリサーチタスクを投げてみてください。 きっと「おっ、これは......」と感じるはずです。
- 2
- 1

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
AI集客@ルイ
- 4
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます