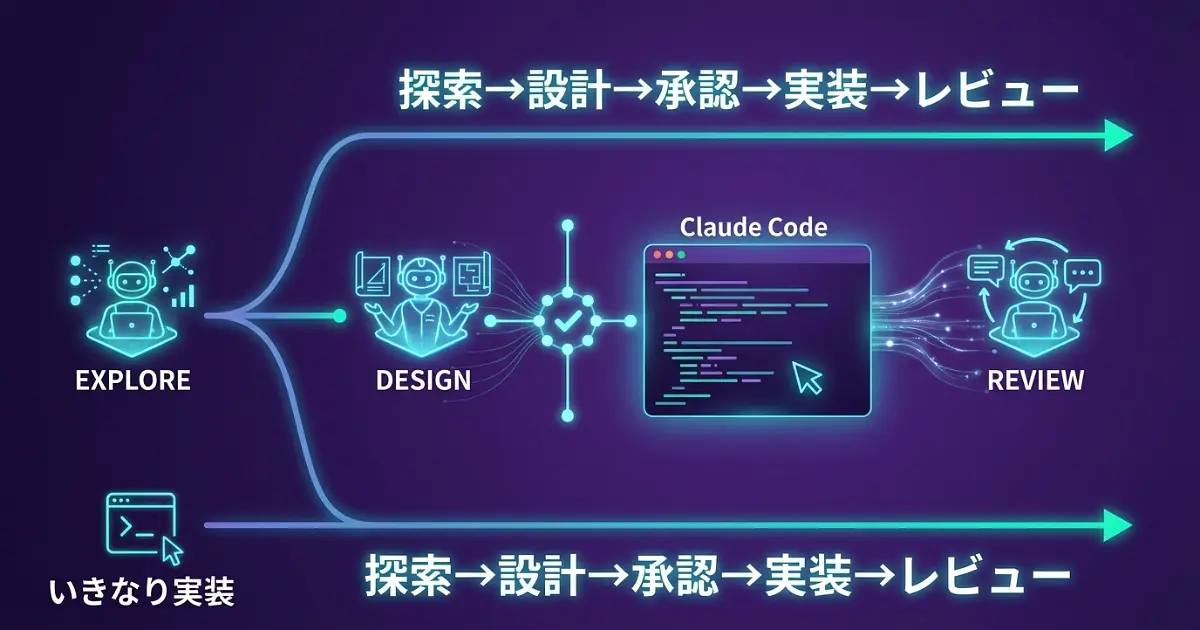
feature-devプラグインとは何か
「この機能を作って」とClaude Codeに投げたら、プロジェクトの規約をガン無視して独自路線の実装が始まった。
既存のユーティリティ関数があるのに、似たような関数をゼロから書き始めた。
設計の相談なんて一切なし。
完成してから「いや、そのアプローチじゃないんだけど......」と頭を抱える。
これ、めちゃくちゃ心当たりありませんか?
Claude Code feature-devプラグインは、この「いきなり実装」問題を根本から解決するAnthropicのプラグインです。
イメージとしては「新しいプロジェクトに参加した初日のシニアエンジニア」。
まずコードベースを読み、設計案を複数提示し、ユーザーの承認を得てから実装に進んでくれます。
これを支えているのが、7つのフェーズと3つの専門エージェントによる構造化されたワークフローです。
この記事では、feature-devプラグインの仕組みを7フェーズのワークフローに沿って解説し、インストール方法からCLAUDE.mdとの連携、Plan Modeとの使い分けまで、実務で活用するために必要な知識をまるっとまとめています。
「インストール方法だけ先に知りたい!」という方は「インストール方法と基本的な使い方」セクションまでスキップしてください。
プラグインとしての位置づけ
feature-devは、Anthropicが公開しているClaude Codeのプラグインの1つです。
GitHubリポジトリ(anthropics/claude-code)のplugins/feature-devディレクトリで提供されており、作者はAnthropicのSid Bidasaria氏。
バージョンは1.0.0です。
デモマーケットプレイス(anthropics/claude-code)内で提供されているプラグインの1つに位置づけられています。
Claude Codeのプラグイン機構は、基本機能を拡張するための仕組みです。
feature-devはその中でも「機能開発ワークフロー」に特化していて、単なるコード生成ではなく、探索から設計、実装、レビューまでの一連のプロセスを構造化して実行してくれます。

解決する問題:「いきなり実装」が引き起こすトラブル
Claude Codeに素の状態で機能開発を依頼すると、こういうことが起きがちですよね。
- 既存コードの規約を無視する: プロジェクトで使われているデザインパターンやディレクトリ構成を考慮しない
- 類似機能の存在を見落とす: 既にある共通関数やユーティリティを使わず、重複した実装を作る
- 設計の選択肢を提示しない: 1つのアプローチでいきなり書き始め、後から「別の方法のほうが良かった」と気づく
- 品質チェックが甘い: 実装後のレビューが形式的になりがち
要するに、AIが「手は早いけど空気を読まない新人」になってしまうんです。
feature-devプラグインは、これらの問題に対して「まずコードベースを読む」「設計案を複数提示する」「レビューを並列実行する」という仕組みで対処します。
この仕組みを支える3つの専門エージェントを見ていきましょう。
3つの専門エージェントを理解する
feature-devプラグインの核心は、役割の異なる3つのサブエージェントが分業する点にあります。
ここがミソなんですが、1つのAIがすべてを担当するのではなく、「読む人」「設計する人」「レビューする人」が分かれているんです。
それぞれがSonnetモデルで動作し、特定のフェーズで並列に起動されることで、効率的な分析と設計を実現しています。
code-explorer:コードベースを読み解く探偵
code-explorerは、コードベースの調査を専門とするエージェントです。
ターミナル上では黄色のラベルで表示されます。
主な役割は以下の4つです。
- エントリーポイントの発見: 関連するファイルとその行番号(
file:line形式)を特定 - コードフローのトレース: 処理がどの順番で実行されるかを追跡
- アーキテクチャの分析: プロジェクト全体の構造とパターンを把握
- 実装詳細の調査: 具体的な実装方法や使用されている技術を調べる
これが地味にすごいんですよ。
code-explorerはコードベースの調査に必要なツールセット(Glob、Grep、Read等の読み取り系ツールに加え、BashOutput等)を使用する一方で、Write/Editといった直接ファイルを書き換えるツールは持っていません。
つまり、絶対にコードを壊さない。
「読んで理解する」に徹する専門家というわけです。
出力として得られるのは、エントリーポイントの一覧、実行フロー、キーコンポーネント、アーキテクチャに関する洞察、そして「必ず読むべきファイル」のリストです。
code-architect:複数の設計案を提示する建築家
code-architectは、アーキテクチャ設計と実装計画の策定を担当するエージェントです。
ターミナル上では緑色のラベルで表示されます。
code-architectの最大の特徴は、1つのタスクに対して複数の異なるアプローチを並列で検討する点です。
「これしかない」じゃなくて「こっちもあるけど、どうする?」と聞いてくれるんです。
それぞれが異なる設計哲学に基づいた提案を行います。
出力には、検出されたパターンと規約、アーキテクチャ上の決定事項、コンポーネント設計、実装のロードマップ、データフロー、そしてビルド順序が含まれます。
ここが面白いところなんですが、code-architectが提案を出した後、feature-devがそれらを比較して推奨案を提示し、ユーザーの選択を待つんです。
自動的に実装が始まることはありません。
ここで人間がジャッジを下す。
この「人間がハンドルを握り続ける」設計が、feature-devの思想を象徴しています。
code-reviewer:品質を担保するレビュワー
code-reviewerは、実装後のコードレビューを担当するエージェントです。
ターミナル上では赤色のラベルで表示されます。
これ何が嬉しいかっていうと、code-reviewerに「信頼度スコアリング」という仕組みが組み込まれているんです。
発見した問題に0〜100のスコアを付け、80以上の問題のみを報告します。
これにより偽陽性(実際には問題ないのに警告される)を最小限に抑えています。
AIレビューでありがちな「大量の些末な指摘で本当の問題が埋もれる」あの問題、スコアリングで解決しているわけです。
3つのcode-reviewerがそれぞれ異なる観点からコードを精査します。
- Simplicity / DRY / Elegance: コードのシンプルさ、重複の排除、設計の美しさ
- Bugs / Correctness: バグの有無、ロジックの正確性
- Conventions / Abstractions: プロジェクト規約への準拠、抽象化の適切さ
さらに、code-reviewerはCLAUDE.mdに記載されたプロジェクト固有のガイドラインとも照合を行います。
CLAUDE.mdにコーディング規約やアーキテクチャルールを記載しておくと、レビューの精度がグッと上がります。
3つのエージェントが「読む、設計する、レビューする」を分担する構造を把握したところで、次はこれらが実際にどう動くのかを7つのフェーズで見ていきます。
Claude Code feature-devの7フェーズワークフロー完全解説
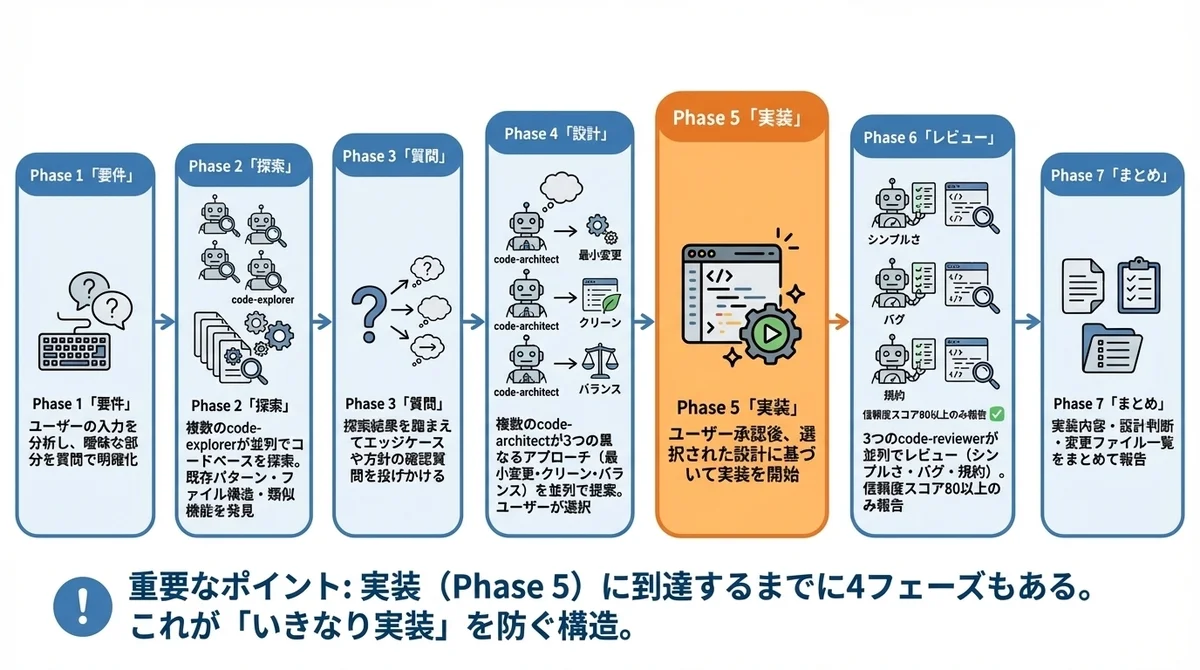
feature-devプラグインのワークフローは、7つのフェーズで構成されています。
全体の流れはこんな感じです。
Discovery → Codebase Exploration → Clarifying Questions → Architecture Design → Implementation → Quality Review → Summaryここがポイントなんですが、Implementationに到達するまでに4つものフェーズがあるんです。
これが「いきなり実装」を防ぐ構造的な仕掛けになっています。
各フェーズで何が起き、ユーザーは何をすればよいのかを順番に解説していきます。
Phase 1 Discovery:要件の明確化
最初のフェーズでは、ユーザーが入力した機能の説明文を分析し、要件を整理します。
入力された説明が曖昧な場合、feature-devはこの段階で質問を投げかけてきます。
たとえば「検索機能を追加して」という指示に対して、「全文検索かフィルター検索か」「リアルタイム検索は必要か」といった制約条件を確認してくれます。
要件が十分に明確であれば、すぐに次のフェーズに進みます。
つまり、最初の指示を具体的に書けば書くほど、このフェーズは一瞬で終わるんです。
Phase 2 Codebase Exploration:並列コード探索
Phase 2では、code-explorerエージェントが2〜3個並列で起動されます。
それぞれが異なるフォーカスを持ち、たとえば以下のような観点で同時に探索を行います。
- 類似機能の探索: 既に実装されている似た機能のパターンを発見
- アーキテクチャの把握: ディレクトリ構成、命名規則、デザインパターン
- UI/コンポーネントパターン: フロントエンドの場合、使用されているUIパターンを特定
これ、正直めちゃくちゃ便利です。
人間のエンジニアが新しいプロジェクトに入って「まず既存コードを読むか」とやるあの作業を、複数のエージェントが並列でやってくれるんです。
各code-explorerの結果は集約され、発見された重要なファイルはfeature-dev自身が実際に読み込みます。
公式READMEに掲載されているOAuth認証機能を追加する場合の出力例(公式READMEより)は以下の通りです。
Found similar features:
- User authentication (src/auth/): Uses JWT tokens, middleware pattern
- Session management (src/session/): Redis-backed, 24hr expiry
- API security (src/api/middleware/): Rate limiting, CORS
Key files to understand:
- src/auth/AuthService.ts:45 - Core authentication logic
- src/middleware/authMiddleware.ts:12 - Request authentication
- src/config/security.ts:8 - Security configuration既存の認証機能の場所、使用しているパターン(JWT、ミドルウェア)、参照すべき具体的なファイルと行番号まで特定されています。
今まで手動で「grepして、ファイルを開いて、関連コードを追いかけて......」とやっていた探索が、数十秒で完了するんです。
これらの情報が後続のフェーズに引き継がれることで、コードベースと一貫性のある設計・実装が可能になります。
Phase 3 Clarifying Questions:曖昧さの解消
Phase 3は、feature-devワークフローの中で最も重要なフェーズの1つです。
Phase 2の探索結果を踏まえ、以下のような観点で質問が投げかけられます。
- エッジケースの取り扱い
- エラーハンドリングの方針
- 既存コードとの統合ポイント
- 後方互換性の要件
- パフォーマンス要件
「コードベースを読んだ上での質問」が来るのがポイントです。
素のClaude Codeだと「何も見ずにとりあえず聞く」か「何も聞かずに突っ走る」かの二択になりがちですよね。
feature-devはPhase 2の探索結果を踏まえて質問するので、質問の精度が全然違います。
**ここではユーザーの回答を待ってから次に進みます。 ** 質問を無視したり、曖昧な回答をすると、以降のフェーズの精度が下がります。
具体的かつ明確に回答することが、feature-devの効果を最大化するポイントです。
Phase 4 Architecture Design:3つの設計アプローチを比較
Phase 4では、code-architectエージェントが2〜3個並列で起動されます。
各code-architectは異なる設計哲学に基づいて提案を行います。
feature-devは各案の比較をまとめた上で推奨案を提示します。
公式READMEに掲載されているOAuth認証機能を追加する場合の出力例(公式READMEより)は以下の通りです。
Approach 1: Minimal Changes
- Extend existing AuthService with OAuth methods
- Add new OAuth routes to existing auth router
Pros: Fast, low risk
Cons: Couples OAuth to existing auth
Approach 2: Clean Architecture
- New OAuthService with dedicated interface
- Separate OAuth router and middleware
Pros: Clean separation, testable
Cons: More files, more refactoring
Approach 3: Pragmatic Balance
- New OAuthProvider abstraction
- Integrate into existing AuthService
Pros: Balanced complexity and cleanliness
Cons: Some coupling remains
Recommendation: Approach 33つのアプローチそれぞれのメリット・デメリットが並んで示されるので、要件や状況に応じた判断ができます。
「本番リリースが来週だからMinimal Changesで」「長期運用するサービスだからClean Architectureで」といった意思決定が、根拠を持ってできるようになるんです。
最終的にどの設計を採用するかはユーザーが決定します。
推奨案をそのまま採用してもよいし、「Aの方針で、ただしデータフローはBを参考にして」のような指示も可能です。
設計が承認されれば、いよいよ実装に入ります。
Phase 5 Implementation:承認後の実装開始
Phase 5では、ユーザーの明示的な承認を受けてから実装が開始されます。
実装はPhase 4で選択されたアーキテクチャ設計に従い、Phase 2で発見された既存コードのパターンやコーディング規約を踏襲して行われます。
事前のフェーズで得られた情報がすべてここに集約されるんです。
素のClaude Codeとの違いが最も顕著に表れるのがこのフェーズです。
Phase 1で要件が明確化され、Phase 2で既存コードが把握され、Phase 3で曖昧さが解消され、Phase 4で設計が承認されている。
この4段階の積み重ねがあるからこそ、既存コードとの一貫性が保たれた実装が生成されます。
「なるほど、だから4つもフェーズを挟んでいたのか」と腹落ちするポイントです。
Phase 6 Quality Review:並列コードレビュー
Phase 6では、code-reviewerエージェントが3個並列で起動されます。
各レビュワーのフォーカスは以下の通りです。
3つのレビュワーが発見した問題は集約され、信頼度スコアが80以上のものだけがユーザーに提示されます。
提示された問題に対して、ユーザーは以下の3つの対応を選択できます。
- 今すぐ修正する: feature-devがその場で修正を実行
- 後で修正する: 記録だけして先に進む
- そのまま進行する: 問題を受け入れて完了へ
ここでも人間が判断します。
「修正する」「しない」「後回しにする」という選択肢があるのは、実際のコードレビューのフローとまったく同じですよね。
Phase 7 Summary:実装内容のまとめ
最終フェーズでは、以下の情報がまとめられます。
- 構築された機能の概要
- 重要な設計上の決定事項とその理由
- 変更されたファイルの一覧
- 推奨される次のステップ(テストの追加、関連ドキュメントの更新など)
これがまた嬉しいんですが、このSummaryはプルリクエストの説明文としてそのまま活用できる粒度で出力されます。
PRを作るときに「何を変えたんだっけ」と振り返る手間がなくなるんです。
ワークフローの全体像を把握できたところで、実際にインストールして使い始める方法を見ていきましょう。
インストール方法と基本的な使い方
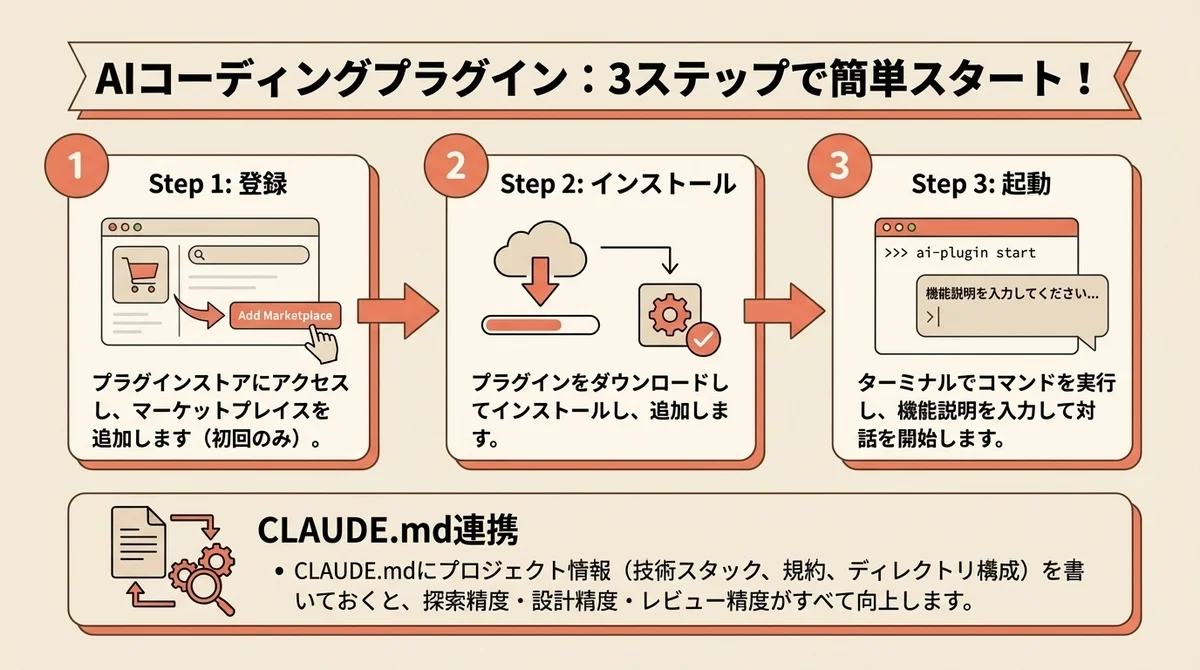
feature-devのインストール手順
feature-devプラグインのインストールは2ステップで完了します。
Claude Code上で以下のコマンドを実行してください。
# ステップ1: デモマーケットプレイスを追加(初回のみ)
/plugin marketplace add anthropics/claude-code
# ステップ2: feature-devプラグインをインストール
/plugin install feature-dev@anthropics-claude-codeステップ1はマーケットプレイスの登録で、2回目以降は不要です。
インストールが完了したら、/feature-dev コマンドが認識されるか確認してください。
たったこれだけで、7フェーズのワークフローが使えるようになります。
基本コマンドの使い方
feature-devの起動は、スラッシュコマンドで行います。
/feature-dev ユーザープロフィール編集機能を追加するコマンドの後に、実装したい機能の説明文を続けます。
説明文は日本語でも英語でも構いません。
ポイントは、最初の説明文はある程度具体的に書くことです。
Phase 1のDiscoveryで余計なやり取りが減り、スムーズにPhase 2へ進めます。
たとえば以下のように比較すると違いがわかります。
# 曖昧な指示(Phase 1の質問が多くなる)
/feature-dev 検索機能
# 具体的な指示(スムーズにPhase 2へ進みやすい)
/feature-dev 記事一覧ページにタイトルと本文の全文検索機能を追加する。
検索結果はリアルタイムで絞り込み表示し、ページネーションに対応する起動後は、各フェーズで質問や選択肢が提示されるので、対話形式で進めていきます。
CLAUDE.mdとの組み合わせで精度を上げる
feature-devの精度を大きく左右するのがCLAUDE.mdの内容です。
特にcode-explorerがコードベースを探索する際と、code-reviewerがレビューを行う際にCLAUDE.mdの情報が参照されます。
「本当にCLAUDE.mdでそんなに変わるの?」って思いますよね。
仕組みを考えると納得できます。
code-explorerは「何を探すべきか」の手がかりとしてCLAUDE.mdを使い、code-reviewerは「何が正しいか」の基準としてCLAUDE.mdを使います。
つまり、探索の方向性とレビューの判断基準の両方がCLAUDE.mdに依存しているわけです。
feature-devと組み合わせる場合、CLAUDE.mdに以下の情報を含めておくと効果的です。
# CLAUDE.md
## プロジェクト概要
- 技術スタック(言語、フレームワーク、ライブラリ)
- 主要なディレクトリ構成と各ディレクトリの役割
## コーディング規約
# ここが最重要:命名規則を具体的に書くほどcode-explorerの認識精度が上がる
- 命名規則(変数、関数、クラス、ファイル名)
- インポートの順序
- エラーハンドリングの方針
## アーキテクチャルール
# code-reviewerはここを参照して規約準拠をチェックする
- デザインパターン(例: Service層を必ず経由する)
- 状態管理の方針(例: Reduxは使わずContext APIを使う)
- テストの方針(例: ビジネスロジックには必ずユニットテストを書く)
## 禁止事項
# 使用禁止のライブラリや避けるべきパターンを明示する
- 使用禁止のライブラリやパターン
- 避けるべきアンチパターンCLAUDE.mdが充実しているほど、code-explorerはプロジェクトの文脈を正しく理解し、code-architectは規約に沿った設計案を提示し、code-reviewerは適切な基準でレビューを行ってくれます。
Plan Modeとの比較:どちらをいつ使うか
Claude Codeには標準で「Plan Mode」が搭載されています。
feature-devとPlan Modeは一見似ていますが、目的と仕組みがけっこう違います。
使い分けの判断基準(タスク規模別)
/feature-dev [説明]こう並べると、違いが一目瞭然ですよね。
Plan Modeは「1人のエンジニアが計画を立てて実装する」イメージ。
feature-devは「探索チーム・設計チーム・レビューチームが分業する」イメージです。
使い分けの目安はこんな感じです。
- バグ修正、小さな機能追加、既知のパターンの適用 → Plan Mode
- 新規機能の設計が必要、複数ファイルにまたがる変更、既存コードとの整合性が重要 → feature-dev
- 単純なリファクタリング、1ファイルの修正 → Plan Modeも不要(素のClaude Codeで十分)
判断に迷ったら、「設計の選択肢が複数ありえるか?」を基準にしてください。
選択肢が1つしかないタスクにfeature-devを使うのはオーバーキルです。
トークン消費量の目安
feature-devは7フェーズを通して複数のサブエージェントを起動するため、素のClaude CodeやPlan Modeと比べてトークン消費量が多くなります。
ここは正直に言っておきます。
消費量はプロジェクトの規模や機能の複雑さによって大きく変動します。
以下の表はあくまで構造上の相対感を示したもので、正確な数値はプロジェクトや機能の複雑さにより大きく異なります。
Phase 2のcode-explorer並列起動(2〜3個)、Phase 4のcode-architect並列起動(2〜3個)、Phase 6のcode-reviewer並列起動(3個)がトークン消費の主要因です。
コスト意識が高い方は、「feature-devが真に必要な場面」を見極めて使い分けることが大事です。
毎回のタスクでfeature-devを使う必要はありません。
「ここぞ」という設計判断が必要な場面で使うのが、コスパの良い使い方です。
効果的な使い方と注意点
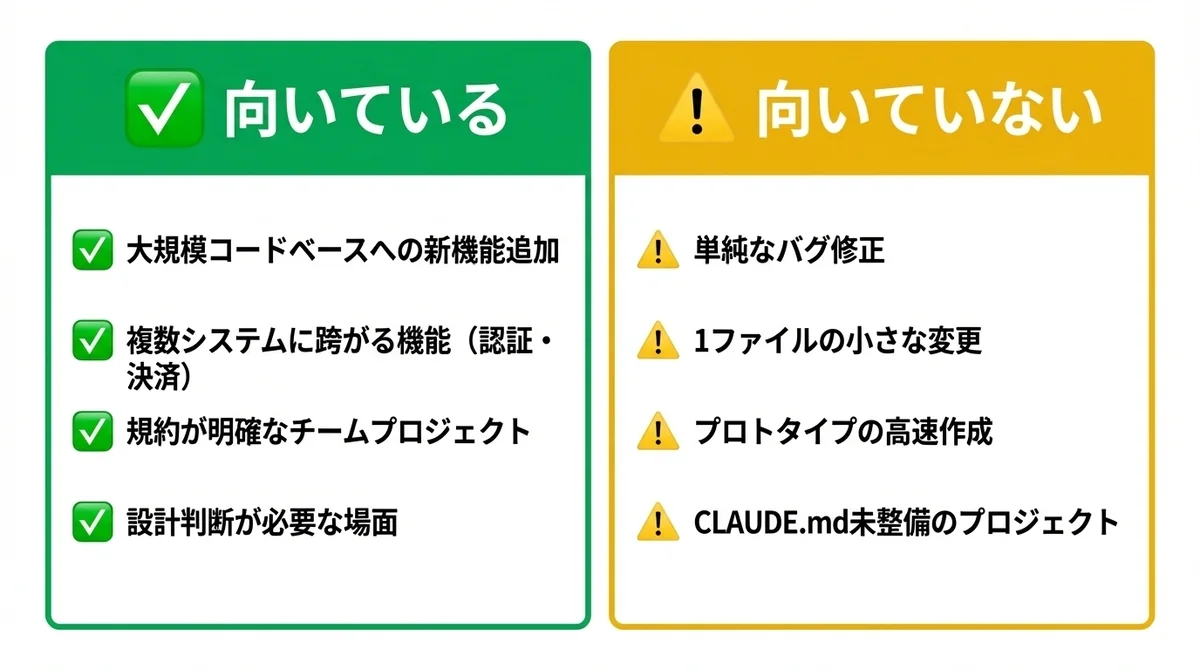
効果が出やすいユースケース
feature-devが特に力を発揮するのは以下のようなシーンです。
- 既存の大規模コードベースへの新機能追加: code-explorerが既存パターンを把握した上で設計・実装するため、コードの一貫性が保たれます
- 認証・決済など複数システムに跨がる機能: Phase 3の質問フェーズでエッジケースが洗い出され、Phase 4で安全な設計が選べます
- チームの規約が明確なプロジェクト: CLAUDE.mdに規約を定義しておけば、code-reviewerが規約準拠を自動チェックしてくれます
- 設計判断が必要な場面: 3つの設計アプローチを比較検討できるため、「とりあえず実装して後悔」を防げます
要するに、「間違った設計で実装してしまうコスト」が高い場面ほど、feature-devの7フェーズが効いてきます。
向いていないシーン
一方で、以下のケースではfeature-devを使うメリットが薄くなります。
- 単純なバグ修正: 原因が明確なバグ修正に7フェーズは不要です。
素のClaude Codeで十分です
- 1ファイルの小さな変更: 探索フェーズのオーバーヘッドが変更内容に見合いません
- プロトタイプの高速作成: 設計の品質より速度を優先する場面では、承認ステップが足かせになります
- CLAUDE.mdが未整備のプロジェクト: code-reviewerの精度が落ちるため、事前にCLAUDE.mdを整備してから使うほうが効果的です
よくある失敗と対処法
失敗1: Phase 3の質問に曖昧な回答をする
「適当に判断して」「いい感じにして」のような回答は、以降のフェーズの品質を下げます。
Phase 3の質問には具体的に回答しましょう。
わからない場合は「現時点では未定。
デフォルトの挙動でよい」のように明示するほうが、曖昧にするよりもずっと良い結果が得られます。
AIに「いい感じ」の判断を丸投げすると、結局「いい感じ」じゃない結果が返ってくるんですよね。
これはfeature-devに限らず、AI活用全般に言えることです。
失敗2: Phase 4で設計を選ばずにスキップする
feature-devが推奨案を提示した後、何も指定せずに進めるとデフォルトの推奨案で実装されます。
推奨案で問題ない場合も「推奨案で進めてください」と明示的に承認するほうが安全です。
失敗3: CLAUDE.mdが空の状態で使う
CLAUDE.mdが空だとcode-explorerの探索精度とcode-reviewerのレビュー精度が低下します。
最低限、技術スタック、ディレクトリ構成、主要な規約を記載してから使いましょう。
CLAUDE.mdの整備は、feature-devだけでなくClaude Code全体の使い勝手を向上させる投資でもあります。
失敗4: すべてのタスクにfeature-devを使う
小さなタスクにfeature-devを使うとトークンの無駄遣いになります。
前述の使い分け基準を参考に、「設計判断が必要か」「複数ファイルに影響するか」を基準に判断してください。
まとめ:feature-devで変わるAI駆動開発のワークフロー
Claude Code feature-devプラグインは、AIコーディングツールの使い方を「指示して生成する」から「対話して設計し、承認して実装する」に変えてくれるものです。
ポイントを整理します。
- 3つの専門エージェント: code-explorer(探索)、code-architect(設計)、code-reviewer(レビュー)が役割を分担
- 7フェーズのワークフロー: Discovery → Codebase Exploration → Clarifying Questions → Architecture Design → Implementation → Quality Review → Summaryの順に進行
- ユーザーが主導権を持つ: 質問への回答、設計の選択、レビュー対応など複数の承認ポイントがあります
- CLAUDE.mdとの連携が重要: プロジェクト情報を充実させるほど精度が向上します
- Plan Modeとの使い分け: 設計判断が必要な中〜大規模タスクにはfeature-dev、小規模タスクにはPlan Modeか素のClaude Code
「Claude Code プラグイン 使い方」を調べてここに辿り着いた方へ。
まずはCLAUDE.mdを整備するところから始めてみてください。
そして、次に取り組む中規模以上の機能開発で試してみてください。
インストールは以下の2コマンドで完了します。
# ステップ1: デモマーケットプレイスを追加(初回のみ)
/plugin marketplace add anthropics/claude-code
# ステップ2: feature-devプラグインをインストール
/plugin install feature-dev@anthropics-claude-code「まず読んでから書く」というfeature-devの基本動作は、考えてみれば人間のエンジニアがやっていることと同じです。
それをAIが構造的にやってくれる。
AIとの協業の質を一段引き上げてくれるプラグインですので、ぜひ試してみてください。
よくある質問
Q. feature-devはClaude Codeのどのバージョンから使えますか?
feature-devはAnthropicが公式に提供するプラグインです。
プラグイン機構に対応したClaude Codeであれば利用可能で、インストールは /plugin コマンドで実行します。
最新の対応状況は公式GitHubリポジトリ(anthropics/claude-code)で確認してください。
Q. feature-devを使うと毎回7フェーズすべてを通りますか?
はい、feature-devは常に7フェーズを順に実行します。
ただし、Phase 1やPhase 3で要件・疑問点がない場合は自動的に次のフェーズへスキップされるため、実際の対話が発生するのは一部のフェーズのみになることもあります。
Q. CLAUDE.mdがない状態でfeature-devを使っても動きますか?
動作はしますが、code-explorerの探索精度とcode-reviewerのレビュー精度が低下します。
特にプロジェクト固有の規約チェックが機能しなくなるため、事前にCLAUDE.mdを整備してから使うことをおすすめします。
Q. feature-devとPlan Modeを同時に使うことはできますか?
通常は一方を選んで使います。
feature-devは独自の7フェーズワークフローを持つため、Plan Modeとの併用は想定されていません。
小〜中規模タスクにはPlan Mode、設計判断が必要な中〜大規模タスクにはfeature-devという使い分けが基本です。
Q. 日本語で指示を出してもfeature-devは正常に動きますか?
動作します。
/feature-dev コマンドの後に続ける機能の説明文は日本語でも英語でも構いません。
内部処理はモデルが適切に解釈します。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます