
「Stable Diffusionで作ったキャラクター、動かせないかな」って思ったことない?
画像生成AIで作ったオリジナルキャラがいる。
でも静止画のまま。
「これをリアルタイムで動かして配信できたら最高なんだけど……」というやつ。
それ、Deep Live Camで解決できた。
写真を1枚用意するだけで動く顔交換 AI ツールで、Webカメラの映像をリアルタイムにフェイスチェンジできる無料のオープンソースだ。
しかも画像生成AIで作ったキャラの顔を素材にして、自分の表情をリアルタイムでトレースさせることもできる。
GitHubで87,800スター超え、Ars Technicaをはじめ多数のメディアでも取り上げられた、今ちょっとアツいやつ。
今回はインストールから実際の使い方、クリエイター的な活用アイデアまで一気に試してまとめてみた。
Deep Live Camとは?写真1枚でリアルタイム顔交換できるAIツール

Deep Live Camは、AIを使ったリアルタイムフェイススワップツールだ。
一言でいうと「写真1枚で、Webカメラに映る自分の顔を別の顔に変換できる」ソフトウェアになる。
2024年にGitHubで公開されて以降、爆発的にスターを集めて、2026年4月時点で87,800スター、フォーク数は12,700を超えている。

ライセンスはAGPL-3.0で、ソースコードは完全にオープン。
商用のフェイススワップサービスが月額何千円も取る中で、ローカル環境で無料で動かせるのは正直すごい。
できること — Webカメラ顔交換・動画処理・ライブ配信対応
できることを整理するとこんな感じだ。
- リアルタイムWebカメラ顔交換: カメラの前に座るだけで、指定した顔に変わる
- 動画ファイルのフェイススワップ: 既存の動画に対して顔を差し替え
- 画像のフェイススワップ: 静止画の顔交換もOK
- OBSでのライブ配信対応: 仮想カメラ出力でYouTubeやTwitchに配信可能
- Mouth Mask機能: 元の口の動きを保持して、より自然な表情に
- Face Mapping: 複数人が映っている場面で、それぞれ別の顔を適用
特に「たった1枚の写真で」というのがポイントで、3Dスキャンとか動画学習とか面倒な準備は一切不要。
正面向きの顔写真を1枚放り込めば、それだけで動く。
いわば「顔のスキン着替え機能」が、写真1枚でできてしまうわけだ。
これが87,000スターの理由なんだと思う。
他のフェイススワップツールとの違い(比較表あり)
「フェイススワップAIって他にもあるよね?」という疑問に答えておく。
DeepFaceLiveは先駆者的な存在だったけど、2024年11月にリポジトリがアーカイブされ開発終了している。
Akoolはクラウド型で手軽だけど、有料だしデータをサーバーに送る必要がある。
Deep Live Camは「無料」「ローカル実行」「活発な開発」「マルチプラットフォーム対応」という4拍子が揃っていて、フェイスチェンジ(顔交換)AI のOSS界隈では現時点で一強と言っていい。
でも「一強ってわかった。で、実際に何に使えるの?」という話が本番だ。
次の章で、これがクリエイターにとっていかに面白いツールかを先に見てもらいたい。
Deep Live Camのクリエイター向け活用アイデア5選 — 画像生成AIとの連携がアツい
ここが個人的に一番ワクワクした部分なんだよね。
Deep Live Camは「フェイススワップツール」だけど、クリエイター目線で見ると「表現の幅を広げるツール」なんだ。
「どうせ顔を変えるだけでしょ」と思ってたら、画像生成AIとの組み合わせで全然違う景色が見えてきた。
Stable Diffusion / Midjourney で生成したキャラを「顔素材」にする
これがプロンプト画伯的に一番推したい使い方だ。
Stable DiffusionやMidjourneyで生成したキャラクターの顔画像を、Deep Live Camの「ソース顔」として使う。
やり方はシンプル。
- 画像生成AIで「正面向きポートレート」を生成する
- 生成画像をDeep Live Camに読み込ませる
- Webカメラの前で表情を動かす
- AIキャラが自分の表情に合わせて動く
つまり、自分が作ったオリジナルキャラが、自分の表情をリアルタイムでトレースしてくれるわけだ。
「キャラを作る」だけだった画像生成AIが、「キャラを動かす」ところまで連携できる——これは正直鳥肌が立った。
Stable Diffusionで生成するときのポイントは以下の通り。
- プロンプトに
portrait, front view, looking at cameraを入れる - 背景はシンプルに(
plain background) - 解像度は512x512以上
- リアル系よりもセミリアル〜アニメ系のほうが意外とうまくいく
Midjourneyの場合は--ar 1:1で正方形、portrait photography系のプロンプトで正面顔を生成するといい。
これ、VTuber的な使い方の入口としてもかなり面白い。
VTuber的な配信演出としての活用
VTuberといえばLive2DやFaceRigが定番だけど、Deep Live Camを使えば別のアプローチが可能になる。
- 2Dイラスト系ではなく実写系の「キャラ」で配信できる
- Live2Dモデルの制作コスト(数万〜数十万円)が不要
- 写真1枚から即スタートできる手軽さ
- 表情のニュアンスがそのまま伝わる(AIが補完してくれる)
もちろん本格的なVTuberを目指すならLive2Dのほうが表現力は上だ。
でも「まずは試してみたい」「サブキャラを気軽に作りたい」「コラボ配信で遊びたい」といった用途なら、Deep Live Camのほうが圧倒的にハードルが低い。
画像生成AIで作ったキャラ + Deep Live Cam + OBS という組み合わせで、初期費用ゼロでVTuber的な配信環境が作れてしまう時代なんだよね。
YouTube / TikTokのネタ動画・ショート動画制作
「有名人のモノマネ動画」みたいなことを言いたいわけじゃない(後述する倫理面で問題がある)。
ここで提案したいのは、こういう使い方だ。
- 自作キャラによるスキットコメディ: 複数キャラを演じ分ける一人芝居
- 架空のインタビュー動画: AI生成のキャラ同士の対談(Face Mappingで複数人対応)
- ビフォーアフター系コンテンツ: 「この顔をDeep Live Camに通したらこうなった」
- メイキング動画: フェイススワップの過程自体をコンテンツにする
特にショート動画との相性がいい。
「え、これAIなの?」という驚きは、TikTokやYouTube Shortsで再生を伸ばすフックになる。
自分で作ったオリジナルキャラなら権利問題もクリアだし、画像生成AIを使えば素材の量産もできる。
「こういう使い方があるんだ」とわかったところで、次はじゃあどうやってセットアップするかだ。
Deep Live Camのインストール方法(Windows / Mac対応)
ここからは実際のセットアップ手順を解説する。
コマンドラインが苦手な人へ 公式サイト(deeplivecam.net)でプリビルド版(インストーラー付き)を提供している。 GUIでポチポチするだけでインストールが完了するので、「Pythonとか仮想環境とか無理」という人はまずこちらを試してほしい。 公式サイト: https://deeplivecam.net
ソースからセットアップしたい人は以下の手順を進めよう。
動作環境と必要なもの
まず動作環境から。
- OS: Windows 10/11、macOS(Apple Silicon M1/M2/M3/M4)、Linux
- Python: Windows/Linuxは3.10または3.11、macOS Apple Silicon(CoreML)は3.10が必須(3.11以上は非対応)
- FFmpeg: 動画処理に必要
- Git: リポジトリのクローンに使用
- GPU(推奨): NVIDIA(CUDA対応)、AMD(DirectML)、Apple Silicon(CoreML)
- メモリ: 8GB以上推奨
GPUがなくてもCPUで動くけど、リアルタイム処理はかなり遅くなる。
快適に使いたいならGPUは欲しいところだ。
Windows + GPU(CUDA)でのセットアップ手順
WindowsでNVIDIA GPUを使う場合の手順はこうなる。
1. Python 3.10のインストール
公式サイトからPython 3.10をダウンロードしてインストール。
インストール時に「Add Python to PATH」に必ずチェックを入れる。
python --version
# Python 3.10.x が表示されればOK2. FFmpegのインストール
公式サイトからダウンロードして、PATHを通す。
ffmpeg -version
# バージョン情報が表示されればOK3. CUDA Toolkitのインストール
NVIDIAの公式サイトからCUDA Toolkit 12.8.0(cuDNN v8.9.7も合わせて)をインストール。
4. リポジトリのクローンとセットアップ
git clone https://github.com/hacksider/Deep-Live-Cam.git
cd Deep-Live-Cam
# 仮想環境の作成
python -m venv venv
venv\Scripts\activate
# 依存パッケージのインストール
pip install -r requirements.txt5. モデルファイルの配置
以下の2つのモデルファイルをダウンロードして、models/フォルダに配置する。
inswapper_128_fp16.onnx(顔交換モデル)GFPGANv1.4.pth(顔補正モデル)
ダウンロード先はGitHubのREADMEにリンクがある。
6. 起動
python run.pyGUIが立ち上がれば成功だ。
手順数は多いけど、「Pythonのバージョン」さえ間違えなければ詰まるところはほぼないと思う。
よくあるエラーは次のセクションでまとめているので参考にしてほしい。
Mac(Apple Silicon)でのセットアップ手順
M1/M2/M3/M4のMacユーザー向けの手順。
日本語での解説記事が少ないので、ここは丁寧にいく。
重要: Apple Silicon + CoreMLではPython 3.10が必須
Python 3.11以上ではCoreMLが動作しない。
必ずpython@3.10を使うこと。
ここが一番ハマりやすいポイントなので先に強調しておく。
1. Homebrewで必要なものをインストール
brew install python@3.10 ffmpeg git2. リポジトリのクローンと仮想環境
git clone https://github.com/hacksider/Deep-Live-Cam.git
cd Deep-Live-Cam
python3.10 -m venv venv
source venv/bin/activate3. 依存パッケージのインストール
pip install -r requirements.txt4. モデルファイルの配置
Windows編と同様に、inswapper_128_fp16.onnxとGFPGANv1.4.pthをmodels/に配置。
5. CoreMLで起動
python run.py --execution-provider coremlApple SiliconのNeural Engineを使うことで、専用GPUがなくてもそこそこの速度で動く。
M2 Pro以上なら、リアルタイムのWebカメラ顔交換も実用的な速度で動作した。
よくあるエラーと解決策
インストールでハマりやすいポイントをまとめておく。
「Python 3.12でpip installが失敗する」
Deep Live CamはPython 3.10または3.11が必須。
3.12以降では依存パッケージがビルドできないことがある。
pyenvやCondaでバージョンを切り替えよう。
「onnxruntimeのインストールでエラー」
CUDAのバージョンとonnxruntime-gpuのバージョンが合っていない可能性がある。
現在の推奨構成はCUDA 12.8.0 + onnxruntime-gpu==1.21.0だ。
古いバージョンを指定していないか確認しよう。
「ModuleNotFoundError: No module named 'XXX'」
仮想環境が有効になっているか確認。
# Windows
venv\Scripts\activate
# Mac / Linux
source venv/bin/activate仮想環境の外でpip installしてしまうと、実行時にモジュールが見つからない。
「Webカメラが認識されない」
他のアプリがカメラを占有していないか確認。
Zoom、Google Meet、Discordなどを閉じてから起動してみよう。
セットアップが終われば、あとは遊ぶだけだ。
Deep Live Camの基本的な使い方 — 実際に顔交換してみた
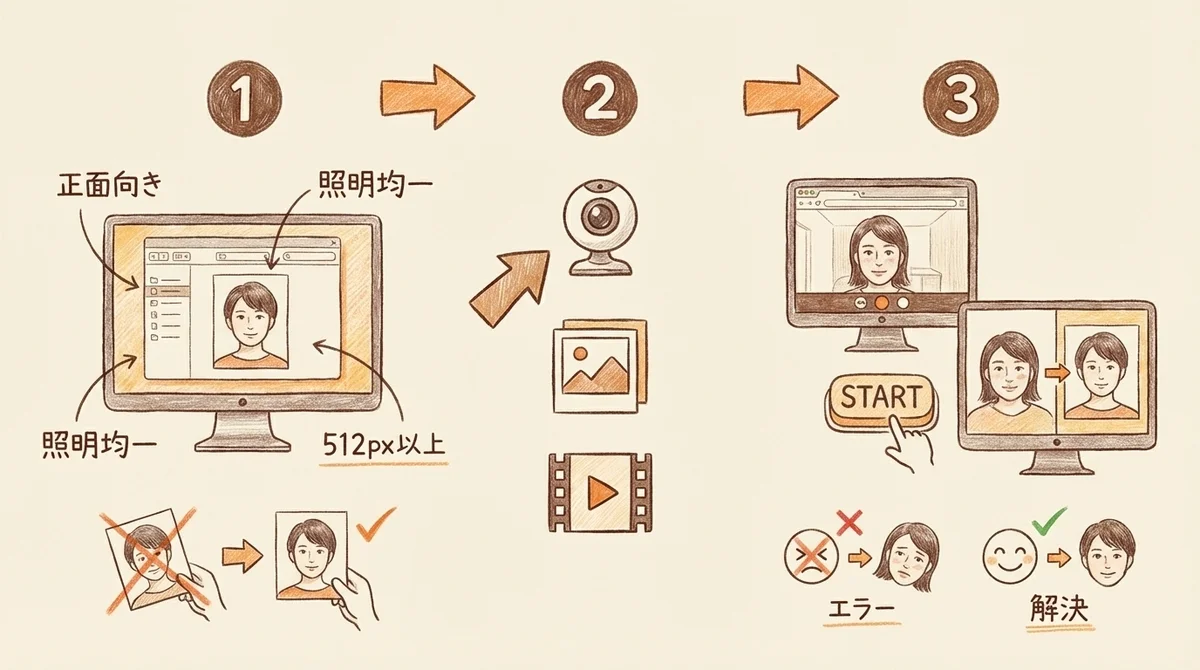
インストールが終わったら、実際に顔交換を試してみよう。
GUIの操作方法と顔写真の選び方
起動すると、シンプルなGUIが表示される。
基本的な操作の流れはこうだ。
- 顔写真を読み込む: 「Select Face」ボタンから、なりたい顔の画像を選択
- 入力ソースを選ぶ: Webカメラ(リアルタイム)、画像ファイル、動画ファイルのいずれか
- 「Start」をクリック: 処理が始まる
「え、これだけ?」って思うかもしれないけど、本当にこれだけだ。
顔写真の選び方にはコツがあって、ここで精度がガラッと変わる。
- 正面向きの写真を使う(斜め顔だと精度が下がる)
- 顔がはっきり写っている写真(解像度が低すぎると認識失敗する)
- 照明が均一な写真が理想的
- 512x512px以上あると安定する
AI生成の顔画像を使う場合は、Stable Diffusionで正面顔のポートレートを生成するのが相性がいい。
実際に試してみてわかったこと。
最初、Midjourneyで出力した斜め45度のキャラ顔を素材に使ったら、顔認識が安定せずに「顔が見つからない」エラーが何度も出た。
「なんで?」ってなったけど、正面顔で生成し直したら即座に認識した。
顔交換の顔認識速度だけど、RTX環境だと最初の1フレームは1〜2秒ラグがあって「あれ、動いてない?」と思うけど、そこから先はほぼリアルタイムで追随する。
眉を上げる、口角を上げる、小首を傾けるといった細かいニュアンスも拾ってくれて、正直びっくりした。
「静止画だったキャラが自分の表情で動いてる」という瞬間、なんか妙に感動したんだよね。
フェイススワップAIって「顔が変わる」だけだと思ってたけど、表情のトレースまでここまでやれるとは予想以上だった。
出力品質を上げる設定のコツ
デフォルト設定でも動くけど、品質を追求するならいくつか調整したいポイントがある。
- Face Enhancer(顔補正)をON: GFPGANによる補正が入り、顔のディテールがグッと改善される
- 解像度の調整: 高解像度ほど品質は上がるが処理が重くなる。720pあたりがバランスよし
- Mouth Mask: 口元の動きを自然に保ちたいならON推奨。特に喋りながらの配信では効果大
- フレームレート: リアルタイム利用なら15〜30fpsが現実的。GPUスペック次第で調整
動画ファイルへの処理(非リアルタイム)なら、品質を最大にしても時間はかかるが確実に仕上がるので、じっくり設定を追い込める。
次はここまでの設定をOBSに繋げて、ライブ配信に持っていく方法だ。
OBS Studioと組み合わせてリアルタイム配信する方法
Deep Live Camの真骨頂のひとつが、OBS Studioとの連携によるリアルタイム配信だ。
「顔交換AIの映像を、そのままYouTubeやTwitchに流す」——これ、ちょっと前なら映画の撮影スタジオでしか実現できなかった技術だ。
それが個人PCで、無料のOSSで、今夜にでもできてしまう。
マジでやばくない? という気持ちを抑えながら手順を書く。
OBS連携のリアルタイム仮想カメラ設定手順
手順はシンプル。
- Deep Live Camを起動し、Webカメラでの顔交換を開始する
- Deep Live Camのメニューから仮想カメラ出力を有効にする
- OBS Studioを開き、ソースの追加で「映像キャプチャデバイス」を選択
- デバイス一覧から「Deep Live Cam Virtual Camera」(または「OBS Virtual Camera」)を選ぶ
- OBSのプレビューに顔交換後の映像が表示されれば成功
あとはOBSから通常通りYouTubeやTwitchに配信すればいい。
「配信でキャラを演じたい」という入口として、これ以上シンプルな構成はないと思う。
画像生成AIで作ったキャラを素材に使えば、事実上ゼロ円でVTuber的な配信が始められる。
「個人PCで映画レベルの顔交換技術が配信に乗せられる」という、ちょっと前には想像できなかった状況がいま普通にできるわけで、ここに来て一番「時代変わったな」と感じた部分だ。
配信時の映像品質と遅延のバランス調整
ライブ配信では「品質」と「遅延」のトレードオフが発生する。
実用的な設定の目安をまとめておく。
リアルタイム配信ではFace Enhancerをオフにするだけで、かなり処理が軽くなる。
画質とのトレードオフだけど、配信解像度720p程度ならEnhancerなしでも十分見られるレベルだ。
遅延が気になる場合は解像度を480pに下げるのも手。
OBS側のエンコーダー設定(x264 vs NVENC)でも体感が変わるので、配信環境に合わせて試行錯誤してみてほしい。
ただし、ここで一度立ち止まって確認してほしいことがある。
Deep Live Camを使う前に知っておくべき注意点と倫理的な話
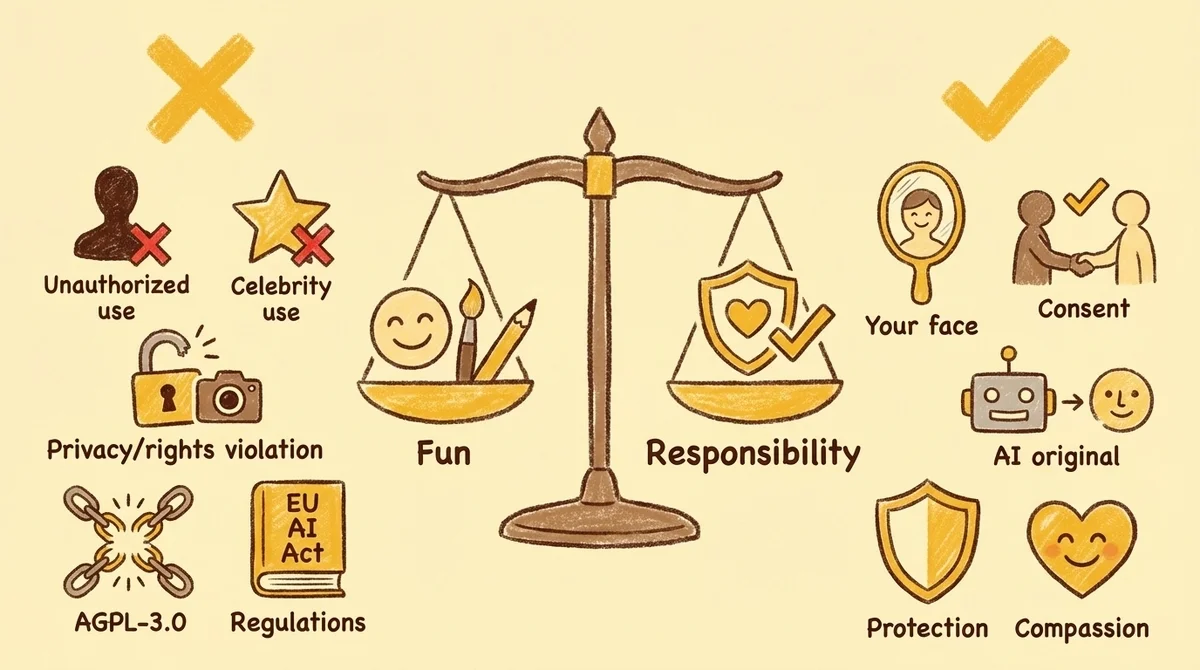
ここからは真面目な話。
フェイススワップは便利で面白い技術だけど、使い方を間違えると法的・倫理的に大きな問題を引き起こす。
むしろこの章が一番大事だと思っている。
肖像権・プライバシー・本人の同意について
大前提として、他人の顔を無断で使うのはNGだ。
- 本人の明示的な同意なしに、他人の顔でフェイススワップすることは肖像権の侵害にあたる可能性がある
- SNSのプロフィール画像や検索で見つけた写真を勝手に使うのもダメ
- 有名人・芸能人の顔を使った動画を公開するのは、パブリシティ権の侵害リスクがある
- ポルノや詐欺目的での利用は、刑事罰の対象になりうる
Deep Live Camの開発者自身も、READMEで「責任ある利用」を強く求めている。
自分の顔、家族や友人(本人の同意あり)の顔、そしてAIで生成したオリジナルの顔。
使う素材はこの範囲に留めるのが安全だ。
AGPL-3.0ライセンスと商用利用の注意
Deep Live CamはAGPL-3.0ライセンスで公開されている。
これは通常のMITやApacheライセンスとは違って、結構厳しいライセンスだ。
- Deep Live Camを使ったサービスをネットワーク経由で提供する場合、自分のソースコードも公開する義務がある
- 個人利用、研究目的なら問題なし
- 商用利用する場合は、ライセンス条件をしっかり確認する必要がある
「動画を作ってYouTubeにアップする」程度の利用なら問題ないが、「フェイススワップをサービスとして提供する」場合はAGPLの制約に引っかかる可能性がある。
商用利用を検討しているなら、一度弁護士に相談したほうがいいだろう。
ディープフェイク規制の現状と「責任ある使い方」
世界的にディープフェイクに対する規制は強まっている。
- EU: AI Act(AI規制法)でディープフェイクの開示義務を規定
- 米国: 複数の州でディープフェイクポルノや選挙妨害目的の使用を犯罪化
- 日本: 現時点では包括的なディープフェイク規制法はないが、名誉毀損・肖像権侵害・不正競争防止法等で対応。2025年以降、法整備の議論が活発化
技術そのものは中立だ。
包丁と同じで、料理にも使えるし、悪いことにも使える。
Deep Live Camの開発者も「この技術は教育やエンターテインメントのために開発された」と明言している。
クリエイターとしては「作る楽しさ」を享受しつつも、「公開する責任」を忘れないでほしい。
自分で作ったキャラクター、自分の顔、同意を得た相手の顔。
この範囲で遊ぶ分には、純粋に楽しい技術だと思っている。
まとめ — Deep Live Camはクリエイターの「新しい表現ツール」になるか
Deep Live Camは「フェイススワップ」という一見キワモノ的な技術だけど、クリエイターの視点で見ると可能性の塊だった。
改めてポイントを整理しておく。
- 写真1枚でリアルタイム顔交換ができる無料のOSSツール
- Windows / Mac(Apple Silicon)で動作し、CPUだけでも使える
- OBS連携でYouTubeやTwitchへのリアルタイム配信も可能
- 画像生成AIで作ったキャラを「顔素材」にするという使い方が面白い
- 倫理的な使い方を守ることが大前提
個人的に一番グッときたのは、Stable Diffusionで作ったキャラクターがリアルタイムで自分の表情を追いかけてくれる体験だ。
プロンプト画伯として、ずっと「絵を作る」側だった。
生成して、調整して、また生成して——その繰り返しの中で、キャラクターはあくまで「完成した静止画」として存在していた。
それがDeep Live Camを使った瞬間、キャラが動いた。
自分の表情を追って、眉を上げて、口角を上げた。
「作る」で止まっていた画像生成AIの楽しみが、「動かす」「配信する」に繋がった——この体験は、正直今までのAIツールの中で一番「おっ、これ新しいな」と感じた瞬間だったかもしれない。
セットアップは少し手間がかかるけど、一度環境を作ってしまえばあとは遊ぶだけ。
まずはGitHubのREADMEを開いて、手順を眺めてみてほしい。
「あ、これできそう」と感じたら、そのままクローンしてしまおう。
- 4
- 1

元デザイナー → AI画像職人。絵心ゼロだったけどプロンプト極めたらなんとかなった。「センスじゃない、言語化だ」 使えるプロンプト&失敗例を晒していく




こちらもおすすめ
-
プロンプト画伯
- 2
- 0
-
- 4
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 4
- 0
-
- 2
- 0
-
コードを読まないAIエンジニア
- 2
- 0
-
- 2
- 0
-
- 2
- 0
-
- 4
- 0
-
- 3
- 0
-
- 1
- 0
-
- 5
- 0
-
- 3
- 0
-
- 3
- 0
-
- 3
- 0
-
- 3
- 0
-
AI集客@ルイ
- 4
- 0
-
AI脱社畜
- 4
- 0
-
- 3
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 5
- 0
-
- 1
- 0













AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます