
こんにちは。
もるふぉです。
Google I/O 2026でGemini 3.5 FlashとOmni Flash、2つ同時に発表されましたね。
「Flashの新バージョンが2種類出た」「どっちを使えばいいの」と混乱した人、結構多いんじゃないでしょうか。
実はこの2つ、名前は似てるけど役割がまったく別物なんです。
この記事では、5分でこの混乱を整理して、そのうえで「開発者として今日何をすればいいのか」まで落とし込みます。
ベンチマークの実数とAPI料金の実務換算まで入れるので、自分のプロダクトで使うかどうかの判断材料になるはずです。
まず結論:名前は似てるけど、Gemini 3.5 FlashとOmni Flashは別物
先に結論から言います。
Gemini 3.5 FlashとOmni Flash、この2つは「速いモデル/遅いモデル」みたいな性能差の話ではありません。
そもそも担当している仕事が違います。
ここを最初に押さえておかないと、後の話が全部ぼやけます。
まずここだけ腹落ちさせてください。
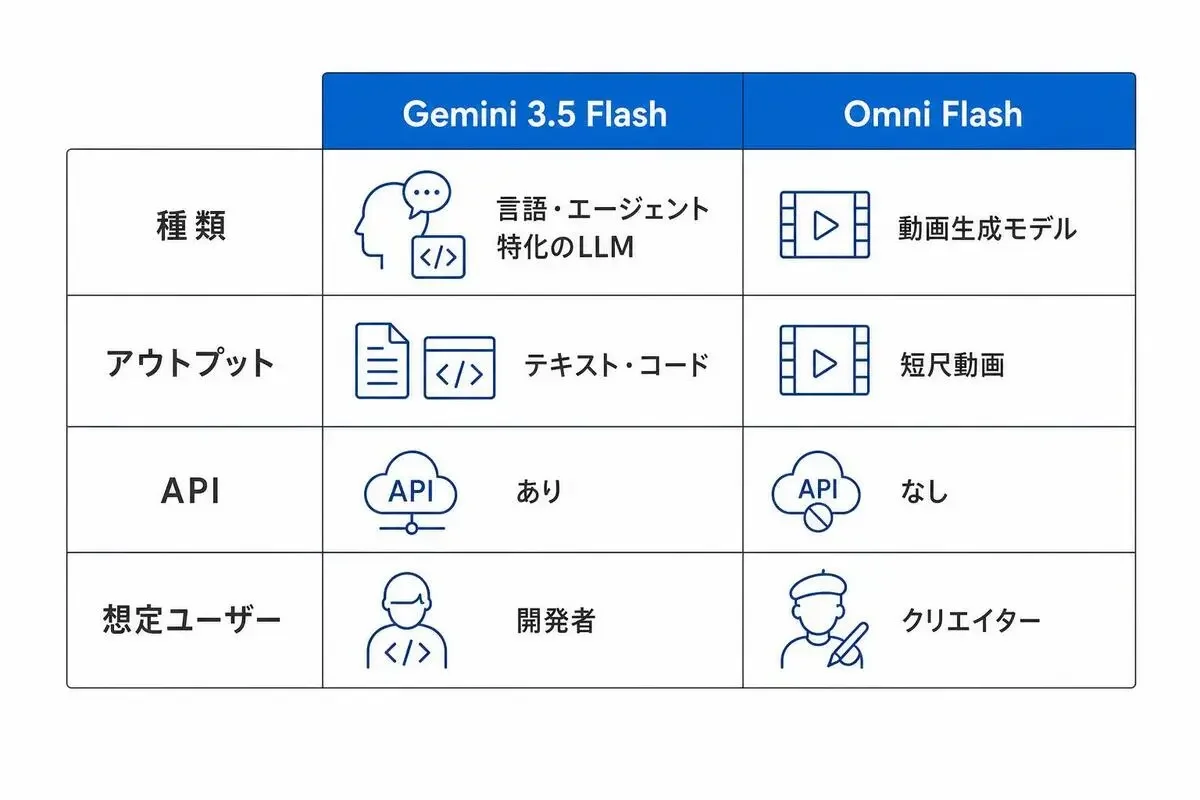
Gemini 3.5 Flash=言語・エージェント特化のLLM
Gemini 3.5 Flashは、いわゆる普通の大規模言語モデル(LLM)です。
テキストを入れたらテキストが返ってくる、コードを書かせる、ツールを呼ばせる、複数ステップのタスクを自動でこなす。
ChatGPTやClaudeと同じ土俵にいるモデル、と思ってもらえれば大きく外しません。
ポジションとしては「速くて安いのに、賢さは前世代のPro級」というところを狙っています。
実際、GoogleはGemini 3.5 FlashをGeminiアプリのデフォルトモデルに据えてきました。
「特別なときに呼ぶ高級モデル」ではなく「普段使いの主力」という位置づけです。
ここが地味に重要で、エージェントを大量に回す用途だと、この「普段使いで安くて賢い」が効いてきます。
Gemini Omni Flash=動画生成マルチモーダルモデル
一方のOmni Flashは、LLMじゃありません。
こっちは動画を作るモデルです。
テキストから短い動画を生成したり、静止画を動かしたり、「このシーンもうちょっと夜っぽくして」みたいな指示で動画を編集したりする。
入力もテキスト・画像・音声・動画を混ぜて受け取れる、いわゆるマルチモーダルモデルです。
だから、Gemini 3.5 Flashに「動画作って」と頼むのと、Omni Flashに頼むのは、そもそも頼む相手が違うわけです。
gemini-3.5-flash)この表の一番下、「想定ユーザー」のところがこの記事の肝です。
Gemini 3.5 Flashは開発者がAPIで叩いてプロダクトに組み込むモデル、Omni Flashは今のところエンドユーザーがアプリで動画を作るためのモデル。
ここを混同したまま「Flash使ってみよう」と言うと、話が噛み合わなくなります。
ここからは、それぞれを実務目線で深掘りします。
まずは開発者に直接効いてくるGemini 3.5 Flashから。ここが今回の記事の本題です。
Gemini 3.5 Flashの何が変わったか(ベンチマーク実数で見る)
「速くて安くて賢い」だけだと、正直どのモデルの発表でも言っている気がしますよね。
なので、ここはベンチマークの実数で見ます。
数字を見ると、今回のGemini 3.5 Flashが「Flashなのに」というレベルじゃないことが分かります。
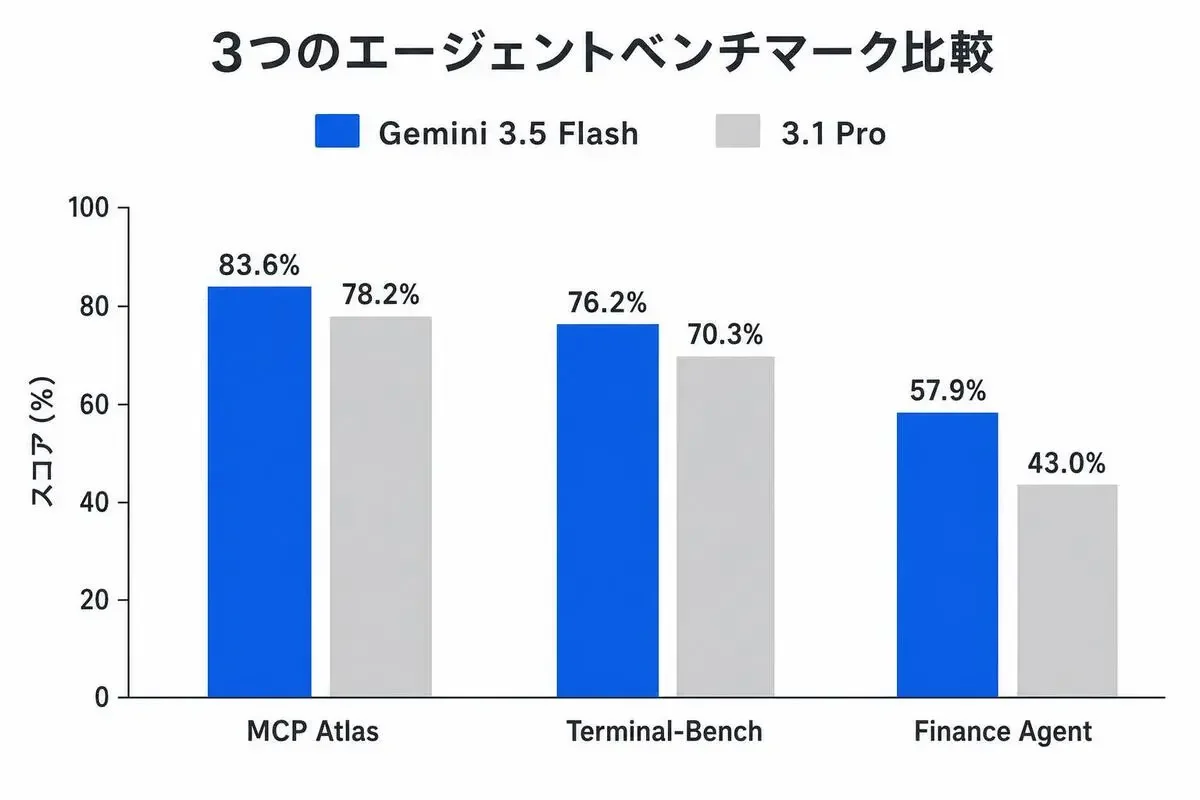
エージェント性能が3.1 Proを超えた(MCP Atlas 83.6%)
一番びっくりしたのがここです。
Flash系って今まで「Proの廉価版」みたいな立ち位置だったんですが、Gemini 3.5 Flashはエージェント系のベンチマークで前世代のProを普通に上回ってきました。
公式が出している数字を並べるとこうなります。
特にMCP Atlasを見てほしいんですが、これはツールを複数回呼びながらタスクを進める、まさにエージェント的な性能を測るベンチです。
Flashで83.6%、前世代Proが78.2%。廉価版のはずのFlashが、Proを5ポイント以上上回っている。
Finance Agent v2に至っては57.9%対43.0%で、14ポイント以上の差です。
これが何を意味するかというと、「複雑な自動化タスクを、もう廉価モデルに任せられる時代になった」ということです。
今までエージェントのオーケストレーター(指揮役)にはProクラスを使って、サブタスクだけFlashに振る、みたいな使い分けをしていた人も多いと思います。
それが「サブエージェントの実行モデルとして3.5 Flashで十分回る」となると、構成がかなりシンプルになります。
「賢さはProクラス、でもコストはFlash」。この組み合わせが成立するのは、正直これまでなかったことです。
出力速度4倍がエージェントループで効く理由
Gemini 3.5 Flashは、出力速度も売りにしています。
公開されている情報では、他社のフロンティアモデル比でおよそ4倍の出力速度とされています。
「速いって言っても、体感そんな変わる?」と思いますよね。
普通のチャットなら、正直そこまで変わらないかもしれません。
でも、エージェントだと話が別なんです。
エージェントって、1回の指示に対して内部で何度もモデルを呼びます。
たとえば「このリポジトリのバグを直して」と頼むと、ファイルを読む→原因を考える→修正案を出す→テストを実行する→結果を見てまた直す、みたいにループが回りますよね。
このループが10回、20回と回るとき、1回あたりのレスポンスが速いと、合計時間が劇的に変わります。
仮に1ステップで2秒短縮できるとして、20ステップ回れば40秒。
しかもエージェントを並列でいくつも動かすと、この差はもっと開きます。
つまり、出力速度は「待ち時間」だけじゃなく「単位時間あたりにこなせるタスク量」に直結するんです。
ここがエージェント開発者にとっての本当のメリットです。
次は気になるコストの話。ここも実務換算で見ていきます。
API料金$1.50/100万トークンを実務コストに換算する
ベンチが良くて速くても、コストが見合わなきゃプロダクトには載せられません。
Gemini 3.5 FlashのAPI料金(有料ティア)は公式の料金ページにこう載っています。
数字だけ見てもピンと来ないと思うので、実務のユースケースに換算します。
たとえば、社内向けの問い合わせ対応エージェントを作っていて、1リクエストあたり入力500トークン・出力500トークンだったとします。
月に10万リクエスト処理する想定で計算してみます。
- 入力: 500トークン × 10万 = 5,000万トークン → $1.50 × 50 = $75(約11,600円)
- 出力: 500トークン × 10万 = 5,000万トークン → $9.00 × 50 = $450(約7万円)
- 合計: 月$525(約81,000円)
月10万リクエストでこれです。
「思ったより出力のほうが高いな」と感じた人、鋭いです。
Gemini 3.5 Flashは入力$1.50に対して出力$9.00と、出力が6倍高い。
なので、コスト最適化の勘所は「いかに出力トークンを短く絞るか」になります。
エージェントの中間思考をダラダラ吐かせると、ここがそのまま請求に跳ね返ります。
さらに、同じ前提でバッチ処理(リアルタイム性が不要な処理)を使うと、入力$0.75・出力$4.50なので合計は月$262.5(約4万円)まで下がります。
ちょうど半額ですね。
夜間にまとめて処理するようなバッチ系なら、ここを使わない手はないです。
加えて、同じシステムプロンプトを毎回投げているなら、キャッシュ入力($0.15)が効きます。
入力の大部分が固定のプロンプトテンプレートなら、ここをキャッシュに乗せるだけで入力コストが10分の1になる。
「賢くて速い」の裏で、ちゃんとコスト設計の余地も用意されているのがGemini 3.5 Flashの好きなところです。
ここまでが言語・エージェント側の話。
次は、もう一人の主役、動画担当のOmni Flashにいきます。
Omni Flashで動画生成が変わる3つのポイント
ここからはOmni Flashです。
繰り返しますが、こっちは動画生成モデルです。
LLMの話はいったん頭から外して、「動画を作る道具」として見てください。
Omni Flashで何が変わるのか、ポイントを3つに絞って整理します。
「会話で動画を編集できる」の具体的な意味
Omni Flashの目玉は「会話で動画を編集できる」ことです。
言葉だけだと「ふーん」で終わっちゃうんですが、具体的に想像すると結構すごいです。
たとえば、テキストで「夜の都会を歩く人」と打って動画を生成したとします。
従来の動画生成だと、ここから手直ししたいとき、プロンプトを書き直してまた一から生成し直すのが普通でした。
Omni Flashは、そこで「もっと雨を強くして」「カメラをもう少し引いて」「主人公の服を赤に変えて」と会話で指示を重ねていけます。
一からやり直すんじゃなくて、今ある動画を会話で詰めていく感じです。
しかも入力はテキストだけじゃなく、画像・音声・動画も混ぜられます。
「この写真の人物を、このBGMに合わせて動かして」みたいな複合指示ができるわけです。
物理演算(重力や流体の動き)も改善されていて、水や布の動きが以前より自然になっているとされています。
地味なポイントですが、生成された動画にはSynthIDという電子透かしが自動で埋め込まれます。
AI生成であることを後から判別できる仕組みで、コンプライアンスを気にする現場には安心材料です。
Google Flowとは何か─Omni Flashの実行環境として整理
ここで「Google Flow」という名前が出てきます。
Omni Flashを調べると必ずこれが出てくるので、関係を整理しておきます。
ものすごく雑に言うと、Omni Flashが「エンジン」で、Google Flowが「そのエンジンを積んだ車」です。
エンジンがいくら高性能でも、それだけで道は走れない。
Google Flowは、動画を作るためのアプリケーション(制作ツール)で、この「車」にあたります。

テキストから動画を作ったり、参照画像を最大3枚渡してキャラクターの見た目を一貫させたり、生成したクリップをタイムライン上で編集したりできます。
その内部で動いている動画生成モデルの一つがOmni Flash、という関係です。
だから「Omni Flashを使う」というのは、多くの場合「Google Flowを通して使う」ことになります。
モデル単体がポンと使えるわけじゃなくて、Flowという制作環境の中に組み込まれている、と理解しておくと混乱しません。
なお、Google FlowでOmni Flashを利用できるのはGoogle AI Plus/Pro/Ultra加入者のみです。
YouTube Shortsで無料、Geminiアプリはプレミアム限定
「じゃあOmni Flashって全部有料なの?」というと、そうでもありません。
ここがちょっとややこしいので整理します。
- Google FlowでのOmni Flash利用 → 有料プラン限定
- Geminiアプリでの動画生成 → 有料プラン限定
- YouTube Shorts/YouTube Create → 無料で利用可能
YouTube Shorts経由なら無料で触れます。
「とりあえずOmni Flashってどんなもんか試したい」という人は、YouTube Shortsの作成機能から入るのが一番ハードルが低いです。
逆に、本格的に動画制作のワークフローに組み込みたいなら、Google FlowなりGeminiアプリの有料プランを契約する流れになります。
「無料で味見 → 良ければ有料で本格運用」という導線が用意されている、と捉えておけばいいと思います。
ここまでで2つのモデルの正体は見えたはずです。
最後に、開発者として「今日何をするか」に落とし込みます。
Gemini 3.5 FlashとOmni Flash:開発者が今日やること・来月以降考えること
正体が分かったところで、一番大事な「で、自分は何をすればいいの?」です。
Gemini 3.5 FlashとOmni Flash、それぞれで動き方が全然違うので、分けて説明します。
すぐ試せる:Gemini API(gemini-3.5-flash)とAI Studio
Gemini 3.5 Flashは、もう触れます。
APIのモデルIDはgemini-3.5-flash。
すでにGeneral Availability(正式提供)になっていて、本番投入も可能な状態です。
「いきなりAPIキー発行してコード書くのはちょっと」という人は、Google AI Studioから入るのがおすすめです。
ブラウザ上でプロンプトを投げて、レスポンスの速さや賢さを体感できます。
ここで手応えを掴んでからAPI実装に進めば、無駄がありません。
仕様面でも開発者向けに整っていて、
- コンテキストウィンドウ:入力が
1,048,576トークン(約100万)、出力が65,536トークン - 知識カットオフ:2025年1月(Google DeepMind公式)
- 提供形態:Gemini API、Google AI Studio、Vertex AI、Android Studioなど
100万トークンの入力枠があるので、長いドキュメントを丸ごと食わせるような使い方も現実的です。
私だったら、今エージェントのサブタスク実行に使っているモデルを、まずgemini-3.5-flashに差し替えて、ベンチ用のテストを流して比較します。
いきなり全部乗り換えるんじゃなくて、テストで「精度が落ちないか」を確認してから本番に入れる。
ここは慎重にいったほうがいいです。
モデルを変えると、今まで通っていたケースが微妙に崩れることが普通にあるので。
Omni Flashは現時点でAPIなし─プロダクト組み込みはまだ待ち
一方、Omni Flashは開発者目線だと「今は待ち」です。
理由はシンプルで、現時点で公式のAPIが提供されていないからです。
使えるのはGoogle FlowやGeminiアプリ、YouTube Shortsといったエンドユーザー向けの入口だけ。
つまり、自分のプロダクトに「Omni Flashで動画生成」を組み込もうと思っても、現時点では叩く口がありません。
なので、Omni Flashについては「自分で触って、どんな品質の動画が作れるかを把握しておく」のが今やるべきこと。
プロダクト組み込みは、APIが公開されてから動けば十分間に合います。
ここを混同して「Flash系のAPIが来たから動画もAPIで作れる」と勘違いすると、設計を間違えます。
Gemini 3.5 FlashはAPIあり、Omni FlashはAPIなし。
このラインだけは、はっきり引いておいてください。
まとめ:Gemini 3.5 FlashはエージェントLLMの新しい標準解になる
最後に3行で整理します。
Gemini 3.5 Flashは言語・エージェント特化のLLMで、APIあり(gemini-3.5-flash)。今日から本番投入できる- Omni Flashは動画生成モデルで、APIなし。Google Flow等のアプリ経由で使うものなので、プロダクト組み込みはまだ待ち
- 名前は似てるけど役割は別物。混同しないことがすべての出発点
そのうえで、私の見立てを正直に書いておきます。
Gemini 3.5 Flashは、エージェント開発のデフォルトモデルの有力な選択肢になります。
エージェント系ベンチで前世代のProを超え、出力が速く、入力$1.50(約230円/100万トークン)という価格。
この3つが揃ったFlash系は、今までなかったんですよ。
特に「オーケストレーターはProクラス、実行は安いモデル」という構成を組んでいた人は、実行側をgemini-3.5-flashに寄せられるかどうか、一度テストで検証する価値があります。
うまくハマれば、構成がシンプルになって、コストも体感速度も両方良くなる可能性があります。
とはいえ、モデルの差し替えはテストありきです。
AIを実務に入れるときの命綱はテストコードです。
新しいモデルに変えるときも、まず比較テストを流して「精度が落ちないか」を確認してから本番へ。
ここを飛ばすと、速くて安いけど結果がズレた、という一番もったいない事態になります。
まずはGoogle AI Studioでgemini-3.5-flashを5分触ってみるところから始めてみてください。
話が「なるほど」で終わらず、自分の手を動かす起点になれば幸いです。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
AI集客@ルイ
- 1
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
AI脱社畜
- 2
- 0
-
- 3
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます