
こんにちは。もるふぉです。
「AIに頼んだら、頼んでいないコードまで30行書き換えられた」——そういう経験、AIコーディングをやっていると一度は通る道ですよね。
今回は話題の「Karpathy(カーパシー)CLAUDE.md」を実際に開いて中身を検証しつつ、AIコーディングの手戻りを減らすCLAUDE.mdの書き方を整理します。
結論から言うと、巷で出回っている数字はかなり盛られています。
でも、中身の4原則は本物です。
ここがこの記事で一番伝えたいところなので、数字に踊らされる前に、何が本当で何が誇張なのかを一緒に見ていきましょう。
そのバズ、ちゃんと中身を見ましたか——CLAUDE.md騒動の実態
タイムラインを眺めていると、定期的にこういう投稿が流れてきます。
「KarpathyのCLAUDE.mdがGitHubで22万スター」「これを入れるだけでコーディング精度が65%から94%に跳ね上がる」。
この手の「○○を入れるだけで激変する」系の触れ込みって、開けてみると中身がスカスカなことが多いんですよね。
でも、数字が気になって仕方なかった。
65行のテキストファイル1枚で精度が30ポイント近く上がるって、本当ならとんでもない話です。
ということで、SNSの要約を信じる前に、自分でリポジトリを開いてみました。
結果として「数字は誇張、中身は本物」という、ちょっと面白い結論にたどり着いたので、その過程を順番に共有していきます。
まずはリポジトリ自体を、正確に把握するところからいきましょう。
「KarpathyのCLAUDE.md」という言い方は、半分本当で半分違う
最初に引っかかったのが、名前です。
SNSでは「KarpathyのCLAUDE.md」と紹介されることが多いんですが、リポジトリのandrej-karpathy-skillsを開くと、正式名称はこうなっています。
「Karpathy-Inspired Claude Code Guidelines」。
Inspired、つまり「Karpathyに着想を得た」です。
本人が書いたものではありません。
実際の作者はjiayuan_jyさん。
Multicaというコーディングエージェント管理プラットフォームを作っているエンジニアで、Karpathy本人とは別の人物です。
ここ、地味だけど大事なポイントです。
「Karpathy製の公式ガイドライン」だと思って崇め奉るのと、「Karpathyの問題提起を、ある開発者が65行に落とし込んだコミュニティ作品」だと理解して使うのとでは、向き合い方が変わってきます。
そもそも何に着想したのか。
元ネタはKarpathyのポストです。
LLMにコードを書かせていると毎回ぶつかる「あるある」を、彼が言語化したものでした。
要約すると、こういう問題提起です。
- モデルはユーザーの代わりに勝手な仮定を置いて、確認せずに突き進む。混乱を管理せず、明確化を求めず、矛盾を表に出さず、トレードオフを示さず、反論すべき時に反論しない
- モデルはコードとAPIを過剰に複雑化したがる。抽象化を膨らませ、デッドコードを片付けず、100行で済むものを1000行の肥大化した構造で実装する
- タスクと無関係なのに、十分に理解していないコメントやコードを副作用的に書き換えたり消したりする
これ、AIにコードを書かせたことがある人なら全部「うわ、わかる」ってなるはずです。
「勝手に走り出す」「肥大化する」「関係ないところまで触る」——この3つは、AIコーディングの三大あるあるといっていい。
そもそもKarpathyって誰?という人もいるはずです。
彼がAnthropicに参画した経緯や、彼が提唱した「バイブコーディング」の話は別の記事で詳しく書いたので、本人の背景が気になる人はそちらを読んでみてください。

さて、この問題提起を受けて、CLAUDE.mdに落とし込まれたのが4つの原則です。
ここからが本題。
1つずつ、何が書いてあって、どのAIの「癖」に効くのかを見ていきます。
原則1「Think Before Coding」——AIが確認せずに走り出す問題
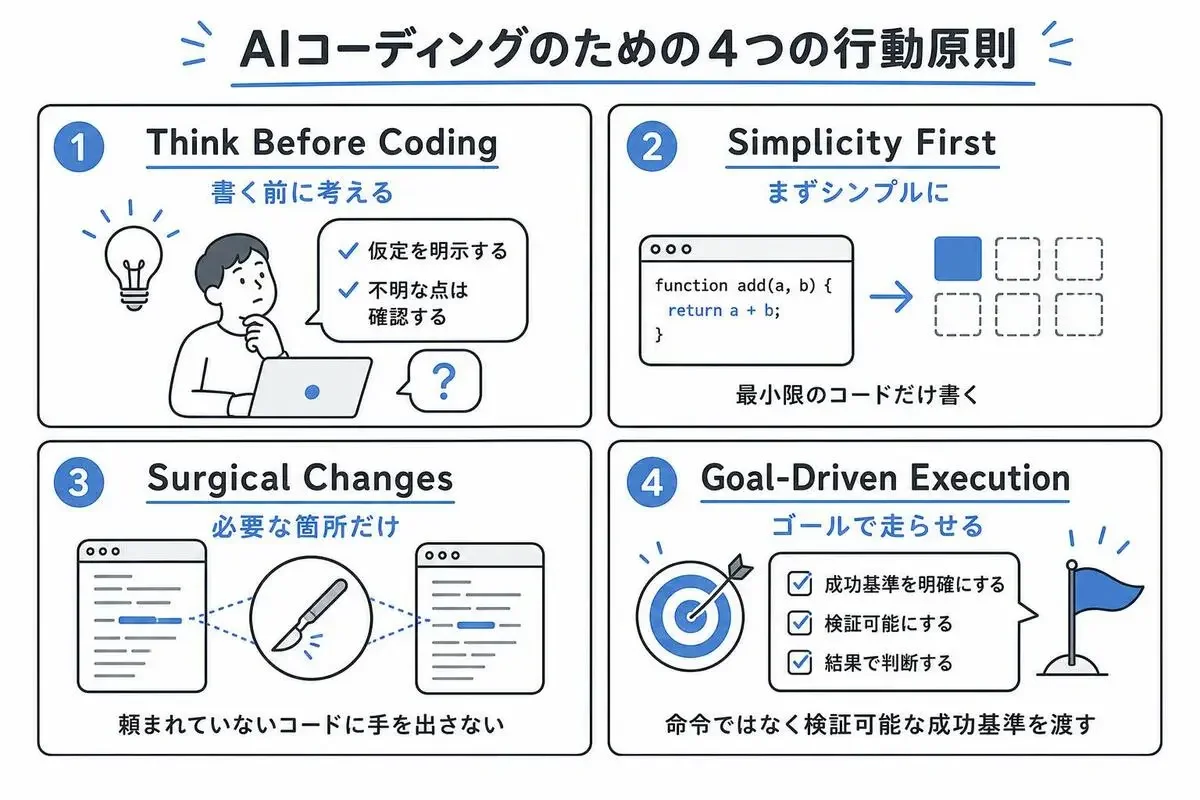
最初の原則は、コードを書く前に考える、です。
原文の要点はシンプルで、「Don't assume. Don't hide confusion. Surface tradeoffs.」。
仮定するな、混乱を隠すな、トレードオフを表に出せ、ということです。
具体的にはCLAUDE.mdにこういう行動を求めます。
- 仮定を置くなら明示する。不確かなら聞く
- 複数の解釈があるなら全部提示する。黙って1つを選ばない
- もっとシンプルな方法があるなら言う。必要なら反論する
- 不明な点があれば止まる。何が不明なのかを名指しして聞く
これがなぜAIコーディングのルールとして効くのか。
AIエージェントの一番やっかいな癖って、「曖昧な指示でも、それっぽく解釈して全力で走り出す」ことなんですよ。
たとえば「ユーザー登録機能を追加して」と頼んだとします。
人間のエンジニアなら「メール認証は要りますか?」「パスワードのバリデーションはどこまで?」と聞き返してくるところを、AIは黙って自分の判断で全部決めて、200行のコードを書いてきます。
で、出てきたものを見て「いや、そこは違う」となって、また指示し直す。
この往復が、手戻りの最大の発生源です。
Think Before Codingは、この「黙って走り出す」を「走る前に一回止まって確認しろ」に変える指示です。
実装が始まる前に「ここ、こういう前提で進めていいですか?」と確認の質問が来るようになるだけで、出戻りの回数が明確に減ります。
「完成したコードを直す」より「着手前の認識合わせ」のほうが、時間もコストも圧倒的に安い——これをCLAUDE.mdの1行が勝手にやってくれるわけです。
次は、走り出したあとのAIがやらかす「もう一つの定番」の話です。
原則2「Simplicity First」——過剰設計はAIがいちばん得意な失敗
2つ目は、まずシンプルに、です。
原文は「Minimum code that solves the problem. Nothing speculative.」。
問題を解く最小限のコードだけ書け、投機的なものは何も書くな、ということです。
CLAUDE.mdに落とすと、禁止事項がずらっと並びます。
- 頼まれていない機能は作らない
- 単一用途のコードに抽象化を持ち込まない
- 頼まれていない「柔軟性」や「設定可能性」を足さない
- 起こり得ないシナリオのエラーハンドリングを書かない
- 200行書いて50行で済むなら書き直す
そして個人的に一番好きなのが、最後の自問ルールです。
「シニアエンジニアがこれを見て『過剰だ』と言うか?」と自分に問え、と。
言うならシンプルにしろ、というわけです。
これ、Claude Codeの過剰実装に悩んだことがある人なら刺さるはずです。
AIって、放っておくと本当に「立派なコード」を書きたがるんですよ。
「設定ファイルから読み込めるようにしておきました」「将来の拡張に備えてインターフェースを切っておきました」「念のため例外処理を3パターン入れておきました」。
頼んでないんですよ、そんなの。
Karpathyの言葉を借りれば「100行で済むものを1000行で実装する」。
これがAIのいちばん得意な失敗です。
なぜ得意かというと、学習データに「ちゃんとした設計のコード」が大量に含まれているからだと思います。
だから「良かれと思って」過剰にやってくる。
悪気がないぶん、たちが悪い。
Simplicity Firstは、この「良かれと思った肥大化」に明確にブレーキをかけます。
YAGNI(You Aren't Gonna Need It)を、人間が毎回口で言う代わりにCLAUDE.mdが機械的に強制してくれる、と考えると分かりやすいかもしれません。
これが効くと、レビューの負担がガクッと変わります。
50行の差分なら全部読めますが、1000行の差分は誰も真面目に読みません。
差分が小さいことは、それ自体が品質なんです。
その「差分」の話、次の原則でさらに核心に入ります。
原則3「Surgical Changes」——頼んでいないコードをAIに触らせない
3つ目は、外科手術のような変更、です。
これがClaude Codeの暴走を防ぐうえで、僕がいま一番重要だと思っている原則です。
原文は「Touch only what you must. Clean up only your own mess.」。
必要なところだけ触れ、片付けるのは自分が散らかしたぶんだけ、です。
ルールはこうなっています。
- 隣接するコードやコメント、フォーマットを「改善」しない
- 壊れていないものをリファクタしない
- 自分なら違うやり方でも、既存のスタイルに合わせる
- 無関係なデッドコードに気づいたら、指摘はするが消さない
- 自分の変更で不要になったimportや変数だけ消す。元からあるデッドコードは頼まれない限り消さない
そして基準が明快です。
「変更したすべての行が、ユーザーの要求に直接たどれること」。
ここ、AIにコードを書かせる人にとっては死活問題です。
「バグを1個直して」と頼んだだけなのに、AIが「ついでに」周辺のコードまで整形して、変数名を変えて、コメントを書き直してくる。
差分を開くと、3行直してほしかったのに30行変わってる。
「え、この27行って安全なの?」——結局、レビューする側は全部確認するハメになります。
Karpathyの言う「タスクと無関係なのに副作用的に書き換える」が、まさにこれです。
Surgical Changesは、AIに「自分の縄張りから出るな」と言い聞かせる原則です。
頼んだことだけやれ、と。
これが効くと、差分が「読めるもの」になります。
「この変更は何のため?」が1行ずつ説明できる状態——これって、人間同士のコードレビューでも本来求められる規律なんですよね。
AIにそれを徹底させるだけで、レビューの心理的負荷がガクッと下がります。
ここまでの3つは「やりすぎを止める」原則でした。
最後の1つは、毛色が違います。
AIを止めるのではなく、AIを正しく走らせ続けるための原則です。
原則4「Goal-Driven Execution」——AIには命令でなく検証可能な基準を渡す
4つ目は、ゴール駆動の実行、です。
原文は「Define success criteria. Loop until verified.」。
成功基準を定義し、検証できるまでループしろ、です。
具体例がそのままCLAUDE.mdに書かれていて、これが分かりやすい。
- 「バリデーションを追加して」→「無効な入力のテストを書いて、それを通して」
- 「バグを直して」→「バグを再現するテストを書いて、それを通して」
- 「Xをリファクタして」→「前後でテストが通ることを保証して」
ポイントは、命令を「検証可能なゴール」に変換していることです。
なぜこれが効くのか。
Karpathy自身がこう言っています。LLMは特定のゴールに到達するまでループするのが異常に得意だ、と。
だから「何をするか」を指示するんじゃなくて、「どうなったら成功か」を渡して走らせろ、という発想です。
ここがミソなんですが、成功基準の「強さ」で、AIの自律性がまるで変わります。
弱い基準、たとえば「動くようにして」だと、AIは何度も「これでいいですか?」と人間に確認してきます。
だって「動く」の定義が曖昧だから、自分で合否を判定できないんですよ。
一方で「このテストが緑になるまで」という強い基準を渡すと、AIは人間に聞かずに自分でテストを回して、落ちたら直して、また回して、を勝手にループしてくれます。
人間が介在する回数が激減します。
多段のタスクなら、まず簡潔なプランを示させてから走らせる。
これを徹底すると、AIエージェントが「指示待ちの作業者」から「ゴールに向かって自走するエージェント」に変わります。
「何をするか」を細かく指示し続けてきた人ほど、この原則を試したときの変化が大きいはずです。
さて、原則の中身は分かりました。
ここで最初の疑問に戻ります。
「精度65%→94%」って、結局本当なんでしょうか。
「65%→94%」の数字は信じていいのか——CLAUDE.mdベストプラクティスの本当の価値

ここがこの記事の核心です。
結論を先に言います。
この数字、出典がありません。
僕はリポジトリのREADMEも、CLAUDE.md本体の65行も、全部読みました。
「coding accuracy 65% → 94%」みたいな数字は、どこにも書いていません。
READMEにもない。CLAUDE.mdにもない。
つまりこの数字は、リポジトリ発の公式な数字ではなく、SNSで拡散される過程で誰かが付け加えたものです。
何を根拠に算出されたのか、どんな条件で測ったのか、一切確認できません。
「精度94%」って言われると、なんとなく科学的でちゃんとした実験があったように聞こえますよね。
でも、その実験の中身は誰も提示していない。
エンジニアとしては、出典のない定量データは「無い」のと同じ扱いにするべきだと思っています。
ついでに言うと、スター数も盛られています。
SNSでは「220,000 stars」と紹介されることがありますが、実際に僕が確認した時点でのスター数は146,352。
約14.6万です。
22万ではありません。
ただ、ここは公平に書いておきたい。
14.6万でも、65行のテキストファイル1枚に付くスター数としては異例のバズです。
そこは間違いなく事実です。
数字が盛られているからといって、リポジトリの中身まで価値がない、という話には全くなりません。
じゃあ、効果をどう判断すればいいのか。
ここでREADMEが正直なのが、僕は好印象でした。
READMEは「精度が何%上がる」みたいな定量的な約束を一切していません。
代わりに、定性的な変化をこう挙げています。
- 差分に無駄な変更が減る
- 過剰実装による書き直しが減る
- 実装に入る前に、確認の質問が来るようになる
- プルリクエストが小さくクリーンになる
これ、4原則とちゃんと対応しているんですよね。
確認の質問が来る、は原則1。
書き直しが減る、は原則2。
差分の無駄が減る、は原則3。
派手な数字はないけど、こっちのほうがよっぽど誠実です。
「○%上がる」より「差分が読めるようになる」のほうが、現場のエンジニアにはずっとリアルに響きます。
なので僕のスタンスはこうです。
数字は無視していい。
でも、4原則は試す価値がある。
最後に、じゃあ実際にどう取り入れるか、という話をします。
自分のCLAUDE.mdに組み込むなら——書き方のベストプラクティスと始め方
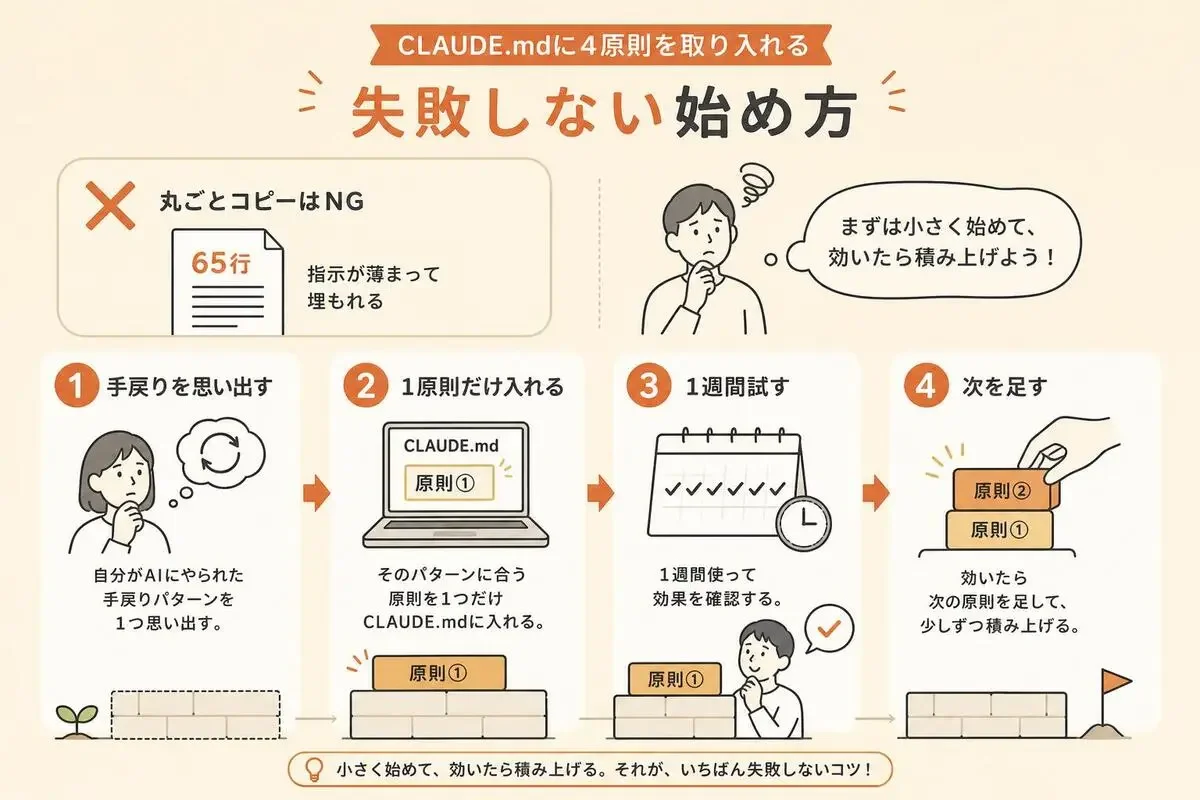
「よし、じゃあこの65行を丸ごと自分のCLAUDE.mdにコピペするぞ」。
ちょっと待ってください。
CLAUDE.mdのベストプラクティスとして、これは僕はあまりおすすめしません。
理由は2つあります。
1つ目。CLAUDE.mdは長くなるほど、個々の指示が守られにくくなります。
あれもこれも書き込むと、AIにとっては「重要な指示」が薄まって埋もれてしまう。
他人のルールを丸ごと足すと、自分のプロジェクト固有のルールと混ざって、全体がぼやけます。
2つ目。65行の中身が、全部あなたのプロジェクトに刺さるとは限りません。
刺さる原則と、そうでもない原則があるはずです。
なので、おすすめの順番はこうです。
まず、自分が今までAIにやられた「手戻りパターン」を1つ思い出してください。
勝手に走り出して違うものを作られたのか。
過剰に実装されたのか。
頼んでないコードを触られたのか。
ゴールが曖昧で何度も確認されたのか。
そのパターンに対応する原則を、1つだけCLAUDE.mdに入れてみる。
たとえば「勝手に走り出す」のが悩みなら、原則1のこの1行だけでいい。
不確かな点があれば、実装に入る前に必ず確認する。仮定で進めない。これを入れて1週間使ってみて、効果を実感してから次の原則を足す。
この「1原則ずつ」が、いろんなプロジェクトのCLAUDE.mdをいじってきて行き着いた、いちばん失敗しないやり方です。
全部入れて「効いてるのか効いてないのか分からない」状態になるより、1つずつ入れて「あ、これは明らかに変わった」を確認しながら積み上げるほうが、結果的に質の高いCLAUDE.mdになります。
今日から試せます。
CLAUDE.mdがなければ新規作成するだけで、コストはゼロです。
最後に、この記事で一番伝えたかったことをもう一度。
「22万スター」も「精度94%」も、盛られた数字です。
そこに踊らされる必要はありません。
でも、その奥にある4原則——Think Before Coding、Simplicity First、Surgical Changes、Goal-Driven Execution——は、AIにコードを書かせる全員に効く、本物の知見です。
数字は疑っていい。
中身は試したほうがいい。
このバランスで向き合えば、あなたのCLAUDE.mdは確実に良くなります。
まずは1原則、今日のうちに足してみてください。
それでは、よいAIコーディングを。
- 3
- 1

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます