
こんにちは。
もるふぉです。
「AIのPR、なんとなく通してしまっている気がする」——この感覚、最近ありませんか。
テストは緑、CIも通っている、説明文もそれらしく書いてある。
でも読み終えた後に「本当に大丈夫か?」という薄い違和感が残る。
かといってどこを怪しむべきか言語化できない。
結果、いつもより少し速くapproveしてしまう。
AIが書いたコードだと分かっているのに、そのAIの自信を自分の自信に上書きして「まあいいか」と押してしまう。
GoogleのAddy Osmaniさんはそれを "borrowed confidence"(借り物の自信) と呼んでいます。
この借り物の自信を解体する方法が、Osmaniさんの長編エッセイ「Agentic Code Review」に整理されています。
手元の現場感とよく一致していたので、5つの実務原則として整理します。
AIが書いたコードのレビューは何が違うのか
人間が書いたコードには「意図の影」が残ります。
コミットコメント、Slackでの相談跡、捨てた設計の痕跡、変数名に滲む癖。
レビュアーはそれを手がかりに、著者の頭の中を再構築できます。
AIが書いたコードには、その影がほとんどありません。
動くコードはあるけれど、なぜそのアプローチを選び、何を捨てたかが分からない。
Osmaniさんの言い方を借りれば、「レビューはもともと、欠けた意図を復元するために作られたものではない」のです。
数字を見ると、この「見えない負荷」が現場に何をもたらしているかが分かります。
Faros AIが22,000人・4,000チームを2026年に計測した結果です。
- code churnが
+861% - 開発者一人あたりの欠陥率が
9% → 54% - レビュー所要時間の中央値が
+441.5% - レビューゼロのままマージされたPRが
+31.3%
+441.5%というのはイメージしづらいですが、「AI前に10分で済んだ1本のPRレビューが、今は40分以上かかっている」という計算になります。
最後の+31.3%が示すのは、誰も「レビューしなくていい」と決めていないのに、レビュアーが追いつかなくなった結果としてコードが読まれずにマージされる流れが自然とできてしまっているということです。
GitClearの調査では、毎日AIを使う開発者のアウトプットが前年比4倍なのに、実質的な生産性の伸びは12%。
書く量だけ4倍で、届く価値はほぼ伸びていません。
「全部レビュー」を維持しようとすると、こうなります。
ここからは、このAIコードレビューの現実に対して現場で取れる5つの手を整理します。
受付条件を先に決める——レビューに値しないPRは差し戻す
PRが上がってきてから判断するのをやめる、が1つ目です。
レビューに入る前に「受付ゲート」を作ります。
最低ラインは3つです。
- 説明: なにを変えたか、なぜその変更が必要か、どこを動かしたかが本文に書いてある
- テスト: 既存テストが落ちていない。新しい挙動には新しいテストが付いている
- サイズ: diffの上限を決める(私は500行を目安にしています)
このどれかが欠けたPRはレビューせずに差し戻します。
ここで弾かないと、後段のレビュアーの時間が指数関数的に溶けます。
Farosのデータでは、AIが生成したPRは平均で人間のPRより51%大きい。
PRが大きくなるほどレビュアーの集中力は保てず、最終的に「rubber-stampするかrejectするか」になります。
どちらもコードの品質には貢献しない。
なのでエージェントへの指示の段階で「変更は小さなcommitに分割して」「1つのPRには1つの意図だけ」と書くようにしています。
出力フォーマットを変えるほうが、後ろで人間が頑張るより安いからです。
blast radiusでレビュー深度を変える——全部を同じ深さで見ない
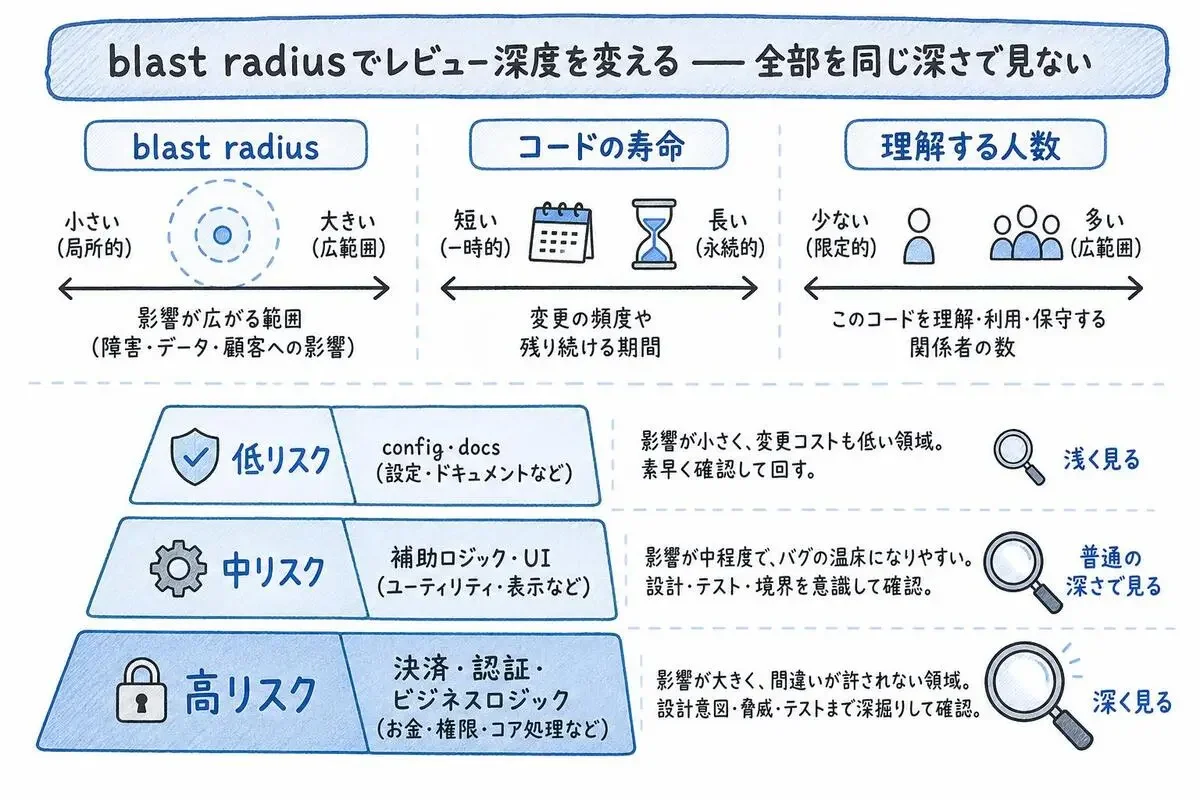
全PRを同じ深さで見るのをやめる、が2つ目です。
Osmaniさんはレビュー深度を決める3軸を提示しています。
- blast radius: 壊れたときに何が起きるか
- how long the code lives: 来週捨てるプロトタイプか、5年保守するコードベースか
- how many people need to understand it: 自分の頭の中だけか、チームで共有するか
実務では3層に切ると扱いやすいです。
- 低リスク層(config変更・ドキュメント・型定義のみ): lintとtestが通っていればざっと
- 中リスク層(補助ロジック・UI調整・新規エンドポイント): 普通に読む
- 高リスク層(決済・認証・ビジネスロジックの中心・スキーママイグレーション): 腰を据えて、テストも手元で走らせる。可能ならレビュアー2人
PRテンプレに「これは低/中/高どれか」を著者が宣言する欄を作ると機能します。
コード本体より「テスト変更」を厳しく見る
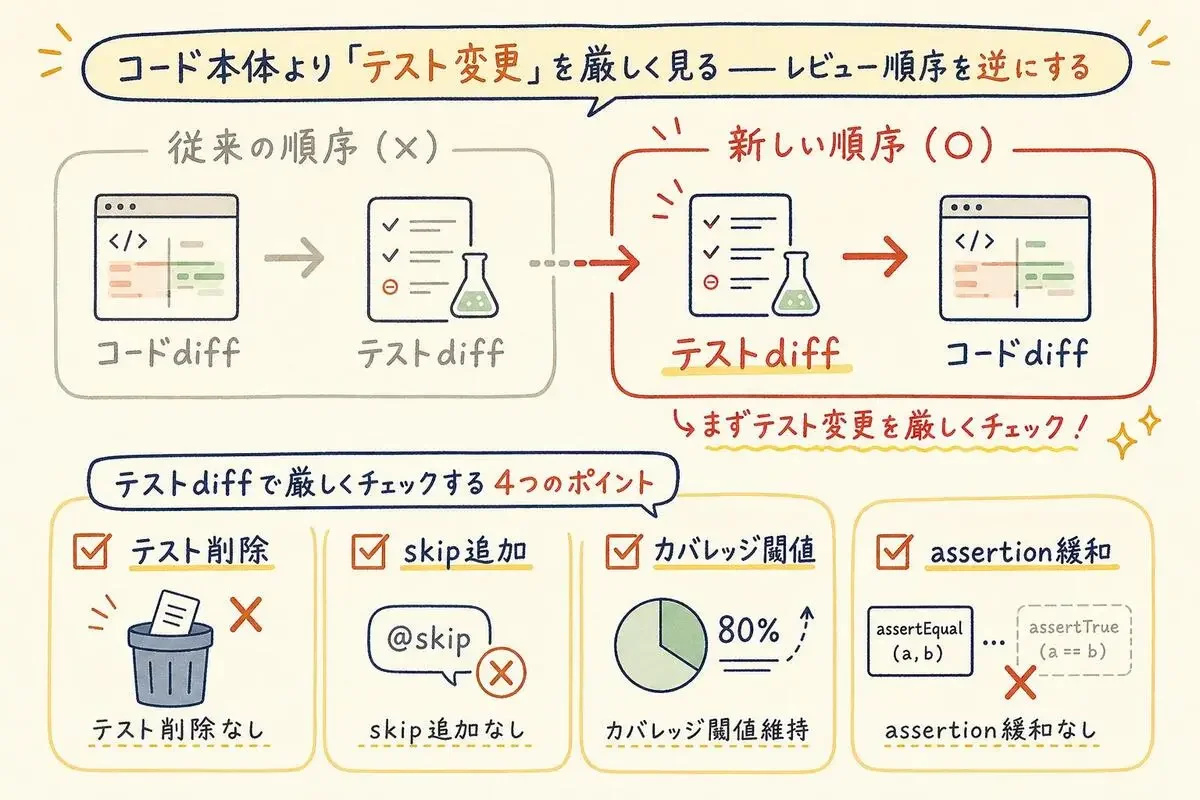
レビュー順序を逆にする、が3つ目です——そして、実務で最も見落とされやすい箇所でもあります。
AIエージェントに「テストを通せ」と指示すると、コードの方を直すべき場面でもテストの方をいじって通そうとする失敗パターンがあります。
エージェント由来の不具合の中でいちばん検知しにくいのがこれです。
「全テスト緑、CIも通った、レビューでも気づかれず、本番で挙動が変わっていた」という順番で問題が出てくる。
気づかなかったでは済まない場所です。
レビュー順序を 「テストのdiff → コードのdiff」 にひっくり返します。
テストファイルを先に開いて、次の4点を確認します。
- 削除されたテストはないか
skip/xfail/pendingが追加されていないか- カバレッジ閾値が下げられていないか
- assertionが緩められていないか(厳密一致が部分一致に変わっていないか)
1つでも引っかかったら、本体のdiffに入る前にコメントを返します。
CIはPRに合わせて動かすのではなく「動かない壁」として扱うのが原則です。
AIレビューワーは1本に絞らない——4ツール並列の研究が示した重なりの薄さ

1本に絞らない、が4つ目です。
これが今回のテーマで最もインパクトの強いデータを持っています。
あるエンジニアが2026年に、4つのAIレビューワー(CodeRabbit / Sentry Seer / Greptile / Cursor BugBot)を146件の実PRに並列で当てる実験を3週間半続けました。
検知された総findingsは679件、重複を除いた指摘箇所は617箇所。
- その617箇所のうち
93.4%が「1つのツールだけが拾った指摘」 - 2つのツールが同じ箇所を指摘したのは
6% - 3つ以上のツールが拾った指摘は ゼロ
93.4%——この数字を見たとき、少し立ち止まってください。
「1ツールで信用していた」なら、617箇所のほぼすべてで何かを見逃していた計算になります。
単一ツールで安心していた時代は、構造的に終わっています。
各ツールは別の視点で別の問題を見ています。
CodeRabbitは2026年のMartianベンチマークでF1スコアトップでprecisionが高い。
Greptileはprecisionを犠牲にしてrecallで82%のバグ検知率。
Sentry Seerは本番ログから推論する強み。
Cursor BugBotはエディタ統合の文脈読み。
全部入れるべきという話ではなく、「重要パスだけ2本目を走らせる」運用が現実的です。
普段はCopilot reviewにまかせて、決済や認証など高リスク層のPRが上がったときだけ別系統のレビュアーを追加する。
1ツール依存だと「そのツールが見ない領域」が構造的な盲点になります。
エージェントの出力品質を上げる仕組みについては前回のAgent Skills解説で整理しています。
出力の信用をどう判断するか、という今回のテーマはその続きにあたります。
「mergeする人」が責任を持つ——AIレビューはセンサーであって判定ではない
最終責任を必ず人間に置く、が5つ目です。
Anthropicの公式blogは、Claudeのcode reviewでengineerに「これは間違い」と判定された指摘が1%未満だと公表しています。
精度は高い。
ただし「指摘した内容の精度」と「拾わなかったもののリスト」は別物です。
AIレビューが「指摘ゼロ」を返してきても、それは「問題ゼロ」を意味しません。
AIが言語化できなかった懸念、訓練データにないパターン、設計の不協和音はサイレントに通過します。
Osmaniさんがエッセイで繰り返す "borrowed confidence" という表現があります。
AIが自信を持って書いたコードを、人間がそのまま自分の自信として受け取ってしまう現象です。
冒頭で触れた「なんとなくOKで通してしまう」は、まさにこれです。
処方箋として彼が使うのが Human in the loop から Human on the loop へ という言い方です。
ループの中に入って一行ずつチェックするのではなく、外側からサンプリング・スポットチェック・監査する立ち位置に変える。
AIレビューの出力は判定(verdict)ではなくセンサーのデータとして扱う。
mergeボタンを押すのは人間です。
AIはページングできないし、本番障害で起こされることもない。
責任を取れる主体はそこにしか居ないので、最終判断はそこに帰します。
Simon Willisonさんの言葉がここにぴたりとはまります。
"your job is to deliver code you have proven to work"
エージェントが出力した瞬間ではなく、「動くことを証明できた瞬間」を仕事の完了と定義し直す、ということです。
2026年のエンジニアの仕事は、「コードを書く」から「これは信用してマージしてよいか判断する」に重心が移っています。
書ける量が増えるほど、信用の判断が割の合う仕事になります。
月曜日の朝、最初にレビューに入るPRのdiff画面で、まずテストファイルを開く。
それだけです。
5つのうち1つだけ選ぶなら、テスト変更を先に見る習慣から始めるのをすすめます。
コストゼロで今日から変えられて、エージェント由来のバグを最も早い段階で止められます。
- 1
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 2
- 0
-
- 1
- 0
-
- 1
- 0
-
- 5
- 0
-
- 1
- 0
-
- 3
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
- 3
- 1
-
- 1
- 0
-
- 1
- 0
-
- 6
- 0
-
プロンプト画伯
- 1
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 4
- 0
-
- 2
- 0
-
- 2
- 0
-
- 1
- 0
-
- 1
- 0










AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます