こんにちは。もるふぉです。
2026年5月29日、Claude Code に「動的ワークフロー(Dynamic Workflows)」という機能が research preview(研究プレビュー)として出てきました。
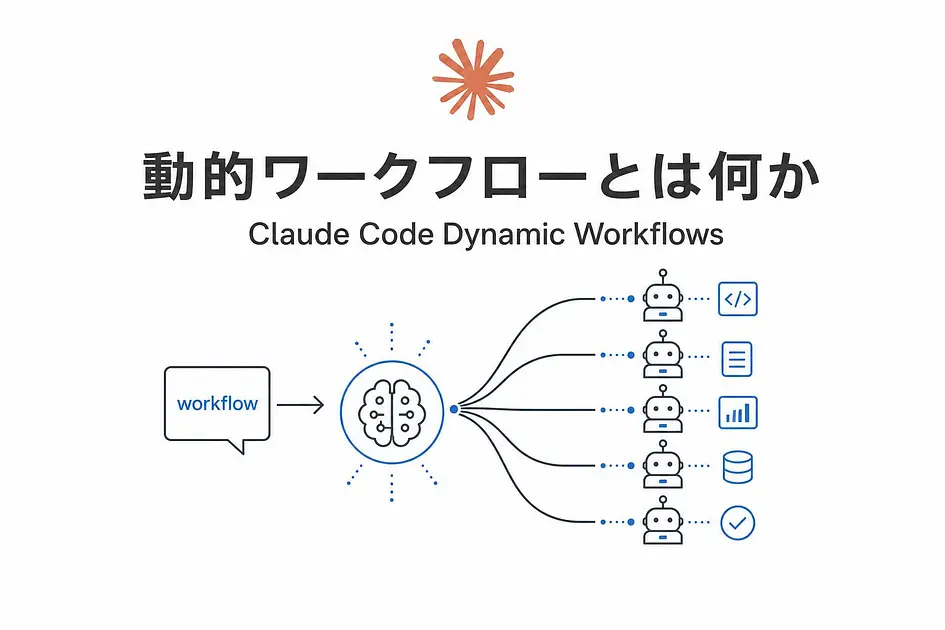
ざっくり言うと、Claudeがタスクに応じてその場でオーケストレーション用のスクリプトを書き、サブエージェントの艦隊を並列で起動して、複雑なタスクをまとめて片付けてくれる仕組みです。
プロンプトに「workflow」という単語を入れると起動できる、というのも面白いポイントですね。
最初にこの話を見たとき、正直「サブエージェントとどう違うの?」と思いました。
Claude Code はもともとサブエージェントを並列で動かせます。複数の業務システムをClaude Codeで作ってきた身からすると、「並列で動かせるなら、もう十分じゃないか」と。
でも、この動的ワークフローの中身(生成されるスクリプトの構造や使える関数)を読み込んでみると、これは「サブエージェントの上位互換」ではなくて、まったく別の発想の道具でした。
この記事では、機能の宣伝ではなく、現場でClaude Codeを使うエンジニア視点で「これは自分のどのタスクに使うべきで、どこでは使うべきでないのか」という判断軸を整理します。
なお、これは2026年5月29日時点の research preview の情報です。
仕様が今後変わる可能性は十分あるので、その前提で読んでください。確定していないことは、正直に「未確定」と書きます。
動的ワークフローとは何か、何を解決するのか
動的ワークフローは、Claudeがタスクに応じて即席で生成する、JavaScriptで書かれたオーケストレーションスクリプトです。
ここが一番のポイントですが、ワークフロー自体は「設定ファイル」でも「YAMLの定義」でもありません。
れっきとした実行可能なJavaScriptのコードです。
その中で、サブエージェントを起動したり、並列で走らせたり、結果をまとめたりといった「処理の段取り」を組み立てていきます。
サブエージェントを手で並べるだけでは足りなかった
これまでのサブエージェントの使い方を思い出してみてください。
「このファイル群を読んで」「このテストを書いて」みたいに、基本は1個ずつタスクを投げる発想でした。
並列で動かすこともできますが、それも「いくつかまとめて投げる」の延長です。
でも、たとえばこういうタスクだと一気に苦しくなります。
- コードベース全体をレビューして、見つかったバグを1個ずつ別のエージェントに検証させたい
- 数が読めない(何個見つかるか分からない)課題を、出尽くすまで探させたい
- 30個のファイルを「読む→変換する→検証する」の3段階で処理したい
共通しているのは、「処理の途中で枝分かれしたり、ループしたり、条件で分岐したりする」という点です。
サブエージェントを手で並べる発想だと、こういう「構造のある処理」を人間が毎回口頭で指揮し続けないといけません。
エージェントAの結果を見て、次にBとCを投げて、その結果次第でDを投げて……というのを、チャットで延々とやることになります。
正直、これはしんどいです。
「計画そのものをコードに書く」という発想の転換
ここで動的ワークフローの発想が効いてきます。
「エージェントを1個ずつ投げる」のではなく、「処理の構造そのものをスクリプトとして宣言する」んです。
料理で例えると分かりやすいかもしれません。
これまでのサブエージェントは、シェフ(あなた)が一人ひとりの調理スタッフに「次はこれ切って」「次はこれ焼いて」と都度指示を出している状態です。
動的ワークフローは、レシピそのものを最初に書いてしまうイメージです。
「この10品は同時に仕込む」「メインができたら3人で別々の角度で味見する」「OKが出るまで作り直す」といった段取りを、最初にコードとして書き切ってしまう。
あとはそのレシピ通りに、Claudeがサブエージェントの艦隊を動かしてくれます。
何が嬉しいかというと、人間が処理の途中に張り付かなくてよくなることです。
「fan-out(タスクを枝分かれさせる)→ verify(検証する)→ synthesize(まとめる)」という構造を一度書いてしまえば、あとは見ているだけでいい。
ここが、サブエージェントを手で並べるのとは本質的に違うところです。
「で、それをどう構造化するのか」——ここからが技術の話です。
サブエージェント・スキル・動的ワークフローの違い
Claude Code には、似たような「自動化」「拡張」の機能がいくつかあります。
サブエージェント、スキル、そして今回の動的ワークフロー。
この3つが混在しやすいので、整理しておきます。
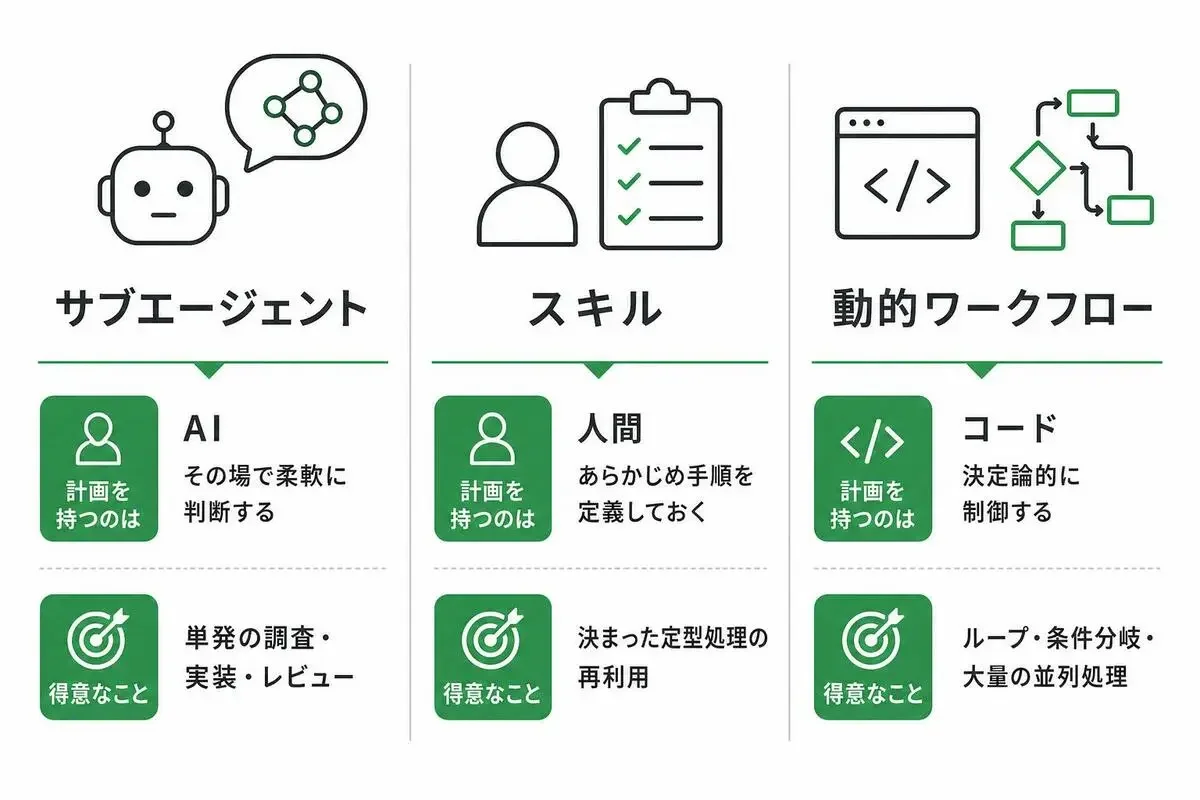
「誰が計画を持つか」で3つを整理する比較表
私が一番しっくりきた整理軸は、「誰が処理の計画(段取り)を持っているか」です。
サブエージェントは、計画をClaude自身がその場で考えます。
柔軟ですが、「30個のタスクを確実に全部、同じ手順で処理する」みたいな決定論的な制御は苦手です。途中で手順がブレることがあります。
スキルは、人間があらかじめ「こういうときはこうする」という手順を定義しておくものです。再利用できる定型処理に向いています。
動的ワークフローは、その中間でもあり、別物でもあります。
処理の構造(ループする、N個に分ける、結果を待ち合わせる)をコードで決定論的に制御しつつ、各ステップの中身はサブエージェント(=Claude)に任せる。
「段取りはコードでカッチリ、中身の判断はAIで柔軟」というハイブリッドですね。
ワークフローを選ぶべき具体的な判断軸
比較表だけだと抽象的なので、現場の判断軸に落とします。
私の中の線引きはシンプルです。
- 単発で終わるタスク → サブエージェントで十分。ワークフローは過剰
- 決まった定型処理を繰り返したい → スキル
- ループ・条件分岐・大量のfan-outが必要 → 動的ワークフロー
たとえば「このファイルをレビューして」は単発なのでサブエージェントです。
でも「コードベース全体を5つの観点でレビューして、見つかった指摘を1個ずつ反証検証して、最後にレポートにまとめて」となると、ループと並列と段階処理が絡むので動的ワークフローの出番です。
逆に言うと、ほとんどの日常タスクはサブエージェントで足ります。
全部ワークフローにすると、後で触れますが、トークンを無駄に食います。
動的ワークフローのアーキテクチャを理解する
ここからが、この記事の技術的な核です。
動的ワークフローが内部でどういう仕組みになっているのか、生成されるスクリプトの構造を見ていきましょう。
ここを理解すると、「なぜこの道具がこういうタスクに強いのか」が腹落ちします。
JavaScriptスクリプトの基本構造(export const meta)
動的ワークフローのスクリプトは、必ず export const meta = {...} で始まります。
ここにワークフローの名前・説明・フェーズ(処理の段階)を宣言します。
export const meta = {
name: "review-codebase",
description: "コードベースを多角的にレビューし、指摘を検証してまとめる",
phases: ["find", "verify", "synthesize"],
};
// 本体はここから。async文脈なので await を直接書ける
phase("find");
const findings = await agent("コードベースを読んでバグ候補を列挙して");
phase("verify");
const verified = await agent(`次の指摘に反証を試みて、生き残ったものだけ返して: ${findings}`);
phase("synthesize");
const report = await agent(`次の指摘をレポートにまとめて: ${verified}`);
log("レビュー完了");ポイントを押さえておきます。
meta は純粋なリテラルでなければなりません。
変数を参照したり関数を呼んだりして組み立てることはできず、その場に直接書いた値だけが使えます。ここはスペックとして決まっています。
本体はJavaScriptです(TypeScriptは使えません)。
async の文脈で動くので、await を直接書けるのが地味に便利です。エージェントの呼び出しは非同期なので、これがないと書きにくいんですよね。
agent() / parallel() / pipeline() の役割の違い
スクリプト本体では、いくつかの専用関数(フック関数)が使えます。
agent(prompt, opts?): サブエージェントを1体起動するparallel(thunks): 複数タスクを並列実行する(全部の完了を待つ)pipeline(items, stage1, stage2, ...): 各アイテムを複数ステージに流す(ステージ間で待ち合わせない)phase(title): 処理のフェーズを区切る(進捗表示のグループ化)log(message): 進捗メッセージをユーザーに表示する
agent() は基本の1体起動です。
地味にすごいのが schema オプションで、JSON Schema を渡すと、サブエージェントの出力を構造化された検証済みオブジェクトとして受け取れます。
「この形のデータで返してね」を強制できるので、後続処理でデータとして扱いたいときに効きます。文字列を自前でパースする手間がなくなる、というのは実装している身としては地味に助かります。
この章の核が parallel() と pipeline() の違いです。
誤解している人が多いので、じっくりいきます。
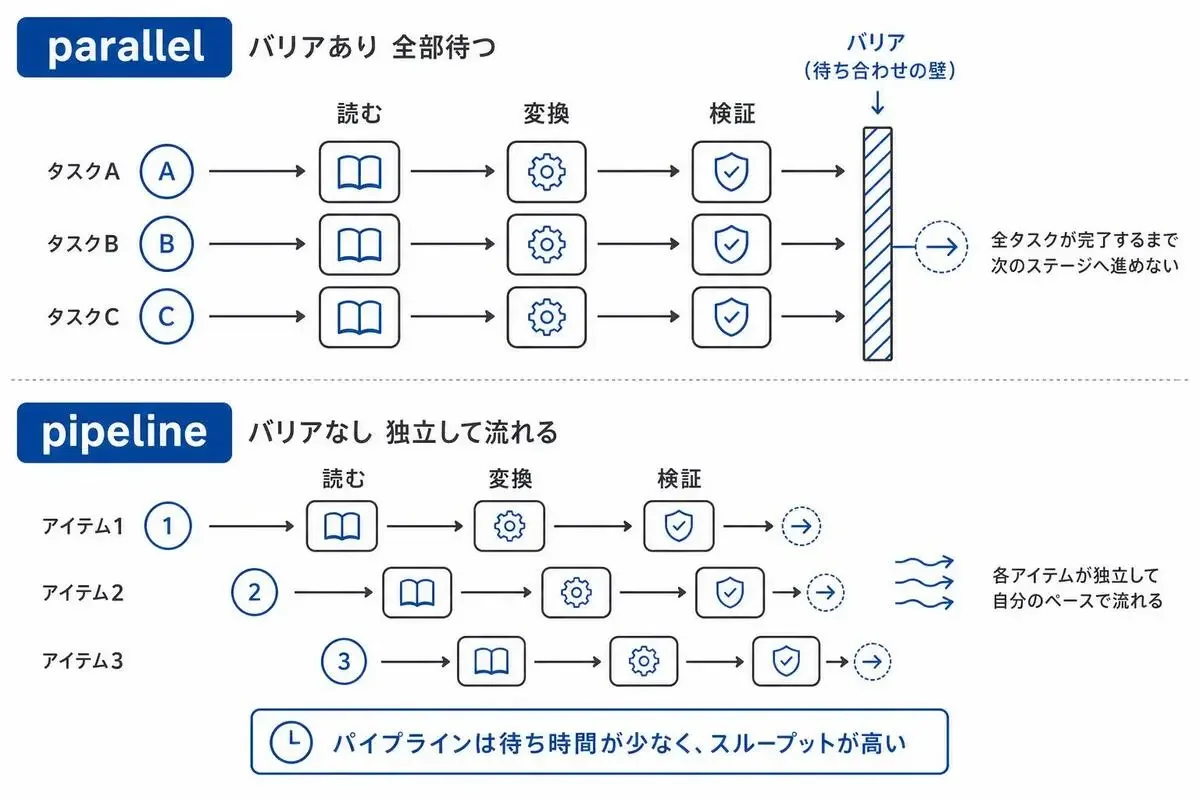
parallel と pipeline はバリアの有無で別物
両方とも「並列で動かす」関数なので、似て見えます。
でも本質的な違いは「バリア(待ち合わせ)があるかどうか」です。
parallel() はバリアありです。
渡した全タスクが完了するのを待ってから、次に進みます。「全員揃うまで次のドアは開かない」イメージですね。
pipeline() はバリアなしです。
各アイテムが独立して、自分のペースで全ステージを流れていきます。アイテムAが3段目を処理中でも、アイテムBはまだ1段目にいてOKです。
具体例で確認しましょう。
「30個のファイルを、読む→変換する→検証する、の3段で処理する」とします。
parallel() 的な発想だと、「30個全部読み終わるのを待つ→30個全部変換し終わるのを待つ→30個全部検証する」になります。
各段で一番遅い1個に全体が引きずられるので、待ち時間は「全ステージの合計」に近づきます。
一方 pipeline() だと、最初のファイルが読み終わった瞬間に変換に進めます。
読むのが速いファイルはどんどん先に進む。結果として、全体の待ち時間は「一番遅い1本のチェーン」で済みます。
これはかなり大きい差です。
マルチステージ処理のデフォルトは pipeline() だと考えてください。
parallel を使うべきは「全部の結果が要るとき」だけ
じゃあ parallel() はいつ使うのか。
答えは、「次のステップが、前のステップの全結果を必要とするとき」だけです。
たとえば、こういうケースです。
- 全件をまたいで重複を除去(dedup)したい
- 全件をまとめて1つにマージしたい
- 「合計がゼロなら以降の処理を打ち切る」みたいな早期終了判定をしたい
こういう「全部揃ってからじゃないと判断できない」処理は、バリアが必要なので parallel() が正解です。
よくあるアンチパターンも挙げておきます。
「結果を flatten / map / filter したいから parallel() を使う」――これはやめたほうがいいです。
その変換は pipeline() のステージの中でやれます。
ただ並べ替えたい・整形したいだけなら、バリアで全体を止める理由はありません。「とりあえず全部待つ」は楽ですが、遅くなります。
同時実行の上限と1ランあたりの制約
実務で必ず知っておくべき制約も、スペックとして決まっています。
- 同時に動くエージェント数の上限は
min(16, CPUコア数 - 2)。超過分はキューに入り、空きが出たら順次実行される - 1ワークフローの生涯で起動できる総エージェント数の上限は1000(暴走を止めるためのバックストップ)
Date.now()/Math.random()/ 引数なしのnew Date()はスクリプト内で使えない
最後の「時刻・乱数が使えない」は意外に思うかもしれません。
これは resume(中断したワークフローの再開)を壊さないための制約です。
毎回違う値が返ってくる関数があると、再開したときに前回と挙動が変わってしまう。だから禁止されているわけですね。設計として筋が通っています。
同時16という上限も、「無限に並列できるわけではない」という現実的なラインとして覚えておくといいです。
動的ワークフローの4つの品質パターンと使いどころ
動的ワークフローの本当の価値は、「並列で速い」ことではありません。
私が一番アツいと思ったのは、「もっともらしいけど間違った結論を、構造的に潰せる」という点です。
AIに何かを調べさせたり判断させたりすると、たまに「自信満々に間違える」ことがありますよね。
動的ワークフローには、それを防ぐための定番パターンがいくつかあります。
代表的な4つを紹介します。
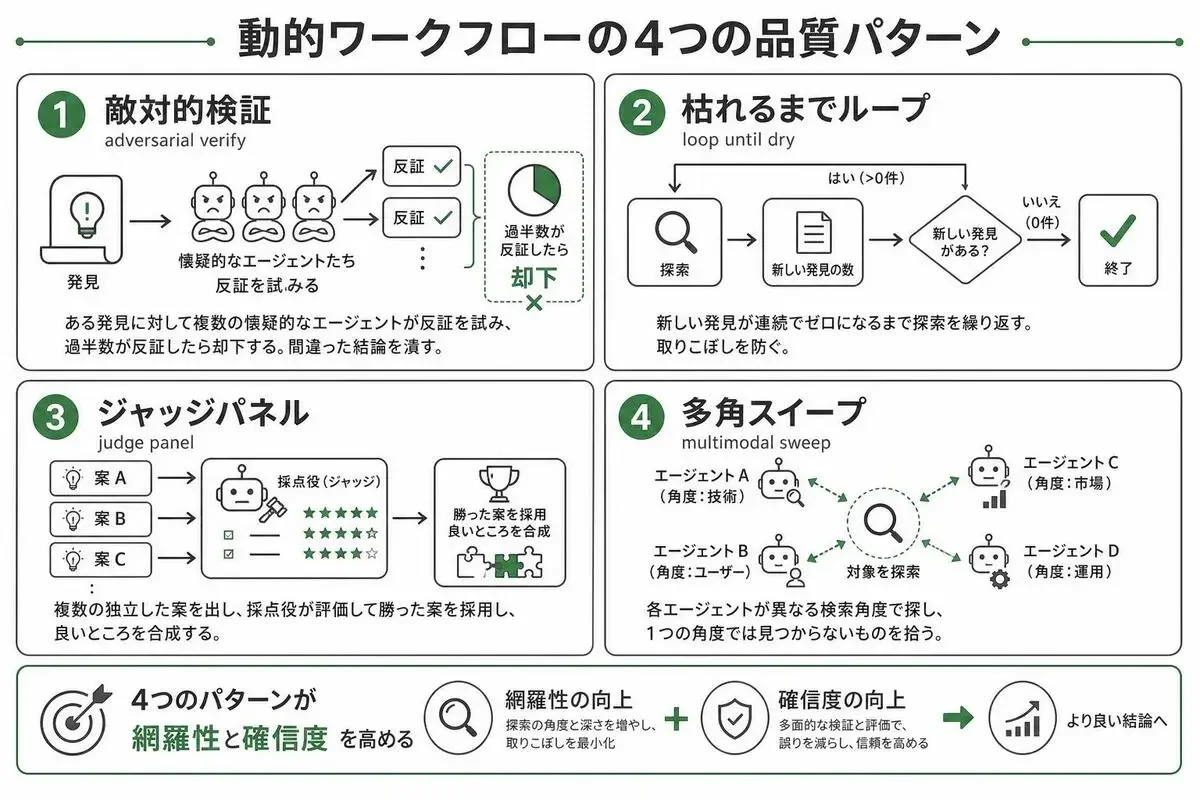
adversarial verify(懐疑的エージェントで反証させる)
一番強力なのが、敵対的検証(adversarial verify)です。
ある「発見」が出てきたとき、それをそのまま信じるのではなく、N体の独立した懐疑エージェントを起動して、わざと反証(REFUTE)を試みさせるんです。
「この結論、本当に正しい?間違っている証拠を探して」と複数体にやらせる。
そして、過半数が「これは間違っている」と反証したら、その発見を却下します。
これが効くのは、1体のエージェントに「合ってる?」と聞くと、忖度して「合ってます」と言いがちだからです。
最初から「間違いを探せ」という役割を与えた独立部隊にチェックさせることで、もっともらしいだけの誤りが生き残りにくくなる。
人間のレビューでも、肯定的に読むより「粗探しするつもりで読む」ほうがバグが見つかりますよね。あれを並列でやるイメージです。
つまり「AIが自分の出した答えを自分で検証する」という構造的な欠陥を、「別のAIが反証する」という構造で補う。これは地味に根本的な解決策だと思いました。
loop-until-dry(新しい発見が尽きるまで探索する)
バグ探し、課題の洗い出し、エッジケースの発見――こういうタスクは「何個見つかるか事前に分からない」のが厄介です。
「5個見つけて」と件数で指定すると、6個目以降を取りこぼします。
loop-until-dry は、「K回連続で新しい発見がゼロになるまで、ファインダー(探索エージェント)を起動し続ける」という発想です。
たとえば「3ラウンド連続で新しいバグが出なくなったら終了」とする。
こうすると、件数上限では拾えなかった「末尾の方の見つけにくいやつ」まで掘り切れます。
数が読めない探索タスクには、これがハマります。
judge panel(複数案を独立採点して合成する)
これは「解き方が一通りじゃない」タスクで効きます。
設計の選択肢、リファクタの方針、文章の構成案――こういう「正解が複数ありうる」ものに対して、まず異なる角度からN個の独立した案を出させます。
そして、それを並列のジャッジ(採点役)に採点させて、勝った案を採用する。
面白いのは、勝った案をそのまま使うだけでなく、次点の案の良いところを接ぎ木できることです。
「A案が一番だけど、B案のこの部分は優れているから取り込もう」みたいに合成する。
1つの案をひたすら磨き続けるより、解空間が広いときはこっちのほうが強い、というのは納得感があります。
multimodal sweep(異なる検索角度の並列展開)
何かを「探す」とき、検索の角度が1つだと取りこぼしが出ます。
multimodal sweep は、各エージェントにそれぞれ違う検索角度を割り当てます。
「コンテナ別に探す」「内容別に探す」「エンティティ別に探す」「時間軸で探す」といった具合に、切り口を分けて並列で投げる。
1つの角度では見つからないものを、別の角度を担当したエージェントが拾ってくれます。
リサーチ系のタスクで網羅性を上げたいときの定番手法です。
ちなみに、似た発想で「検証者ごとに違うレンズ(正しさ・セキュリティ・性能・再現性)を割り当てる」多角検証(perspective-diverse verify)というパターンもあります。
同じチェックを冗長に繰り返すより、異なる失敗の仕方を別々に捕まえるほうが、結果的に多くの問題を見つけられます。
4つのパターンに共通しているのは、「1体のAIが出した答えを、別の構造がチェックする」という二重構造です。
つまり、これらはどれも「AIが一人で考える限界を、アーキテクチャで補う」発想だと思っています。
動的ワークフローの起動方法と実用例
仕組みが分かったところで、「で、どうやって使うの?」という話です。
プロンプトに「workflow」と書く単発起動
一番シンプルな起動方法は、プロンプトに「workflow」という単語を含めることです。
これが明示的なopt-in(自分から有効にする)の合図になります。
冒頭で紹介した発表投稿にあった「プロンプトでworkflowという単語を使うと開始できる」というのは、この挙動のことですね。
普段のチャットでは普通にサブエージェントが動き、「workflow」と書いたときだけオーケストレーションスクリプトが生成される。必要なときだけ呼び出せるので、わりと気軽に試せます。
もう一つ、「ultracode」と呼ばれる常時オンの設定にすると、実質的にすべてのタスクでデフォルトでワークフローを作成・実行する挙動になります。
ただ、これをどう有効化するかの具体的な手順(コマンド名やプラン別の設定方法)は、research preview 段階で情報が揺れているので、ここでは断定しません。
現時点では「ultracodeという常時オンのモードがある」という機能ベースの理解にとどめておくのが安全です。
そして、一度作って良かったワークフローは .claude/workflows/ に保存しておけば、名前で呼び出して再利用できます。
毎回ゼロから生成させるのではなく、定番の段取りは保存して使い回す、という運用になっていくはずです。
大規模レビュー・移行・リサーチでの使いどころ
起動方法より大事なのは、「どんなタスクで効くのか」です。
一次情報として整理されている用途の型を、現場のイメージに翻訳して紹介します。
コードベースの理解(Understand)
サブシステムを複数のreader(読み役)エージェントで並列に読ませて、構造化されたマップ(全体像)にまとめる。
大きなリポジトリに途中から入るとき、全体像を一気に把握したい場面で効きます。
レビュー(Review)
観点(次元)ごとにレビューエージェントを走らせ、各発見を敵対的検証にかける。最後に合成する。
ここで pipeline() が効くのが面白くて、「バグの検証」と「性能のレビュー」が同時並行で進められます。バリアで全部止めないので、無駄な待ちが出ません。
移行・マイグレーション(Migrate)
変換対象を洗い出し、各変換を git の worktree で分離して並列実行する。最後に検証する。
worktree で分けるのは、並列で同じファイルをいじって衝突するのを避けるためですね。大規模な書き換えで効いてきます。
リサーチ(Research)
multimodal sweep で多角的に集めて、deep-read(深く読む)して、synthesize(統合)する。
調査タスクで網羅性を担保したいときの定番フローです。
共通しているのは、どれも「単発では終わらず、構造のある処理」だということです。構造のないタスクにこれを持ち出す必要はありません。
Claude Code 動的ワークフロー: research preview 段階での制約と注意点
正直に書きます。
動的ワークフローは強力ですが、2026年5月29日時点では research preview です。
万能ツールとして全タスクに使うものではありません。
現状の制約と、過信しないための線引き
まず、トークン消費が大きいことは覚悟しておくべきです。
サブエージェントを何体も並列で起動し、検証のためにさらに複数体を回す構造です。
1体に聞くより、当然コストは膨らみます。
「とりあえず全部workflowで」とやると、トークンがあっという間に溶けます。
だからこそ、前半で書いた判断軸が効いてきます。
単発で済むタスクはサブエージェント、構造があって網羅性・確信度が要るタスクだけワークフロー、という使い分けです。
次に、これは research preview 全般に言えることですが、仕様や挙動が今後変わる可能性があります。
セッションを跨いだときの状態の扱いや、有効化の手順、対象プランといった運用まわりの細かい仕様は、現時点で情報が固まっていません。
ここを断定して書いている記事もありますが、私は「現時点では未確定」と正直に言っておきます。
公式の挙動が変わったら、書き換えます。
そしてもう一つ。
並列で動くからといって、結果が正しい保証はありません。
品質パターン(敵対的検証など)は「正しさを上げる構造」であって、「正しさを保証する魔法」ではないです。
最終的に出てきたアウトプットを人間が確認する工程は、なくなりません。
私自身、AIに任せるときは必ずテストコードで挙動を縛るようにしていますが、それと同じで、ワークフローの結果も検証の網にかける前提で使うべきです。
まとめ: どのタスクにワークフローを使うべきか
この記事の結論を一行でまとめます。
動的ワークフローは「速さ」のための道具ではなく、「網羅性・確信・スケール」のための道具です。
判断軸を整理しておきます。
- 単発で終わるタスク → サブエージェントで十分。ワークフローは過剰でトークンの無駄
- 決まった定型処理の再利用 → スキル
- ループ・条件分岐・大量のfan-outがある → 動的ワークフローの出番
- マルチステージ処理 →
pipeline()がデフォルト。全結果が要るときだけparallel() - 間違った結論を潰したい → 敵対的検証や多角検証などの品質パターンを組み込む
技術的なポイントもおさらいします。
スクリプトは export const meta = {...} で始まるJavaScriptで、agent() で1体起動、parallel() はバリアあり、pipeline() はバリアなし。
同時実行は min(16, CPUコア数 - 2) まで、1ランの総エージェント数は最大1000。
このあたりの数字は、使う前に頭に入れておくと判断が早くなります。
繰り返しになりますが、これは2026年5月29日時点の research preview の情報です。
私も実案件でどう組み込むか、いろいろ試しているところです。
まだ触っていないなら、まず自分のコードレビューや調査タスクにプロンプトで「workflow」と書いて一度走らせてみてください。実際に手を動かして「処理の構造をコードで持つ」感覚を掴むのが、一番早い理解の近道だと思います。
「人間が途中に張り付かなくてよくなった」という感覚が掴めたら、それがこの道具の本質です。
新しい知見が溜まったら、また記事にします。それでは。

- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 3
- 0
-
 たく
たく
- 1
- 0
-
プロンプト画伯
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
たく
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 4
- 0
-
- 5
- 0
-
- 3
- 0
-
- 5
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます