こんにちは。もるふぉです。
discoveryはもう自動化できる、ボトルネックは次のフェーズに移った
Claude Codeに書かせたコード、PRを開いてから本当の作業が始まりますよね。
生成は速い。でも書かせたコードに脆弱性が紛れていないか、結局確認しているのは人間です。
Anthropicが2026-05-22時点で開示した数字を見てください。ClaudeにOSSをスキャンさせて見つけた脆弱性は1,596件。
うちパッチが確認できたのは97件です(Anthropicが把握している範囲で)。
.jpg)
「見つかった件数」と「直った件数」のあいだに、16倍以上の差がある計算になる。
これ、Claude Codeで業務システムを扱うときの感覚とまったく同じです。コードを書くより、書かせたコードを検証して、直すかどうか判断するほうが、はるかに時間を食う。
Anthropicも公式ブログで同じ構造の話をしています。「discovery is now straightforward to parallelize, and the bottleneck has shifted to verification, triage, and patching」。発見はもう並列化できる、ボトルネックは検証・トリアージ・パッチに移ったと。
ここで興味深いOSSが出てきました。AnthropicがGlasswing(AWS・Apple・Microsoftらとの共同イニシアチブ)での協業知見をもとに公開した参照実装、defending-code-reference-harness です。
商用ではなく、考え方を理解するための参照実装。これを読み解くと、AI時代のセキュリティが何を目指しているのかが見えてきます。
ここからが面白いところです。
defending-code-reference-harnessは何のためのOSSか
このリポジトリは、AIに脆弱性を「見つけさせて、検証させて、直させる」までの一連のパイプラインを、Anthropic自身がどう設計しているかを示す実装です。
商用利用したい人向けにはClaude Securityという有料SaaSが別途あります。

リポジトリ自体は「メンテナンス停止、貢献は受け付けない」というスタンスで公開されています。参照実装に振り切っている、という割り切りが潔いですね。
security-guidanceプラグインとの違いを整理する
Claude Code セキュリティ周辺の日本語記事を読むと、security-guidanceプラグインとdefending-code-reference-harnessが混ざって紹介されている記事が結構あります。
別物です。
security-guidanceはClaude Codeに組み込むプラグインで、コードを「書いている最中」にリアルタイムで脆弱な書き方を指摘してくれる仕組み。エディタの肩越しにレビュアーがいる感覚に近い。
defending-code-reference-harnessは、「すでに書かれたコードベース」に対して自律的にスキャン → 検証 → トリアージ → パッチを回すパイプライン。CIに近い使い方です。
予防がプラグイン、探索がハーネス。どちらかではなく、両方あって補完関係です。
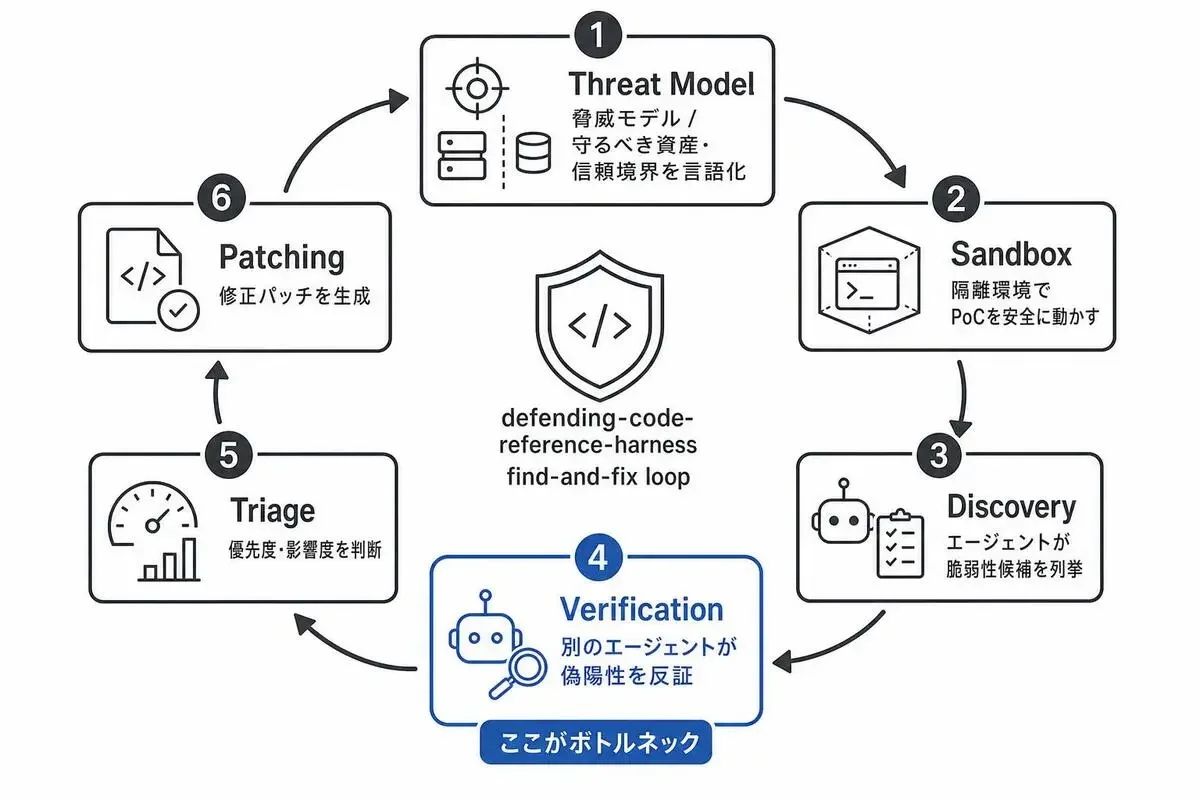
6つのfind-and-fix loop
ハーネスが提示するfind-and-fix loopは6ステップで構成されています。
この6つを全部AIに回させるのがゴールです。
リポジトリのスキルも、この6ステップに対応した/quickstart, /threat-model, /vuln-scan, /triage, /patch, /customizeの6つが提供されています。
実装はC/C++のメモリ脆弱性検出に最適化されていて、ASANとDocker、隔離用のgVisorを組み合わせて動きます。PythonやRubyで使いたい場合は/customizeを通して自分で書き換える前提です。
「全部入り」ではなく「読み解いて移植する」ためのOSSなんですよ。
で、このパイプラインを読むほど、1,596 vs 97 の差を生んでいる構造が見えてきます。
verificationがボトルネックになる理由
discoveryをAIに任せる発想自体は、もう珍しくないですよね。
問題はそのあとです。verificationを軽く見ると、現場で破綻します。
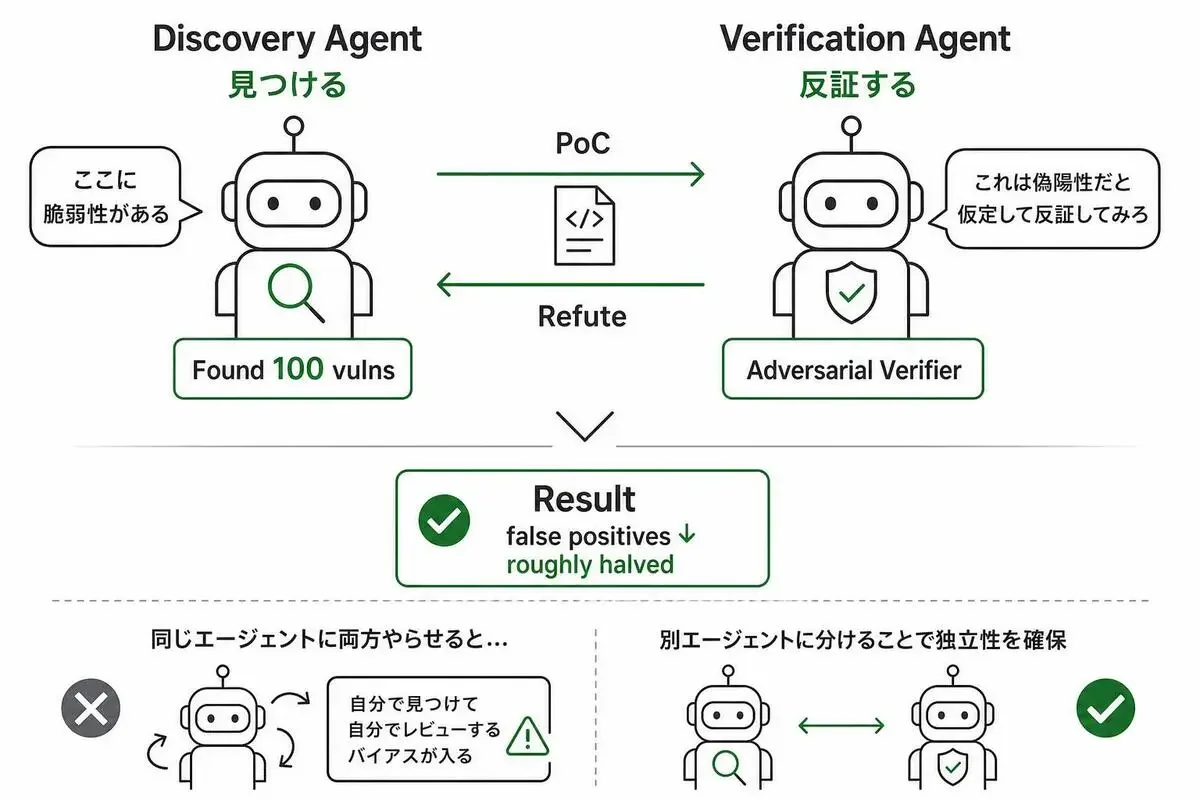
discoveryとverificationを分けると偽陽性が半分になる
同じエージェントに「見つけて、自分で検証して」と言うと、人間でもありがちな失敗をします。自分の見つけたものを正当化する方向に動いてしまう。
コードレビューでいえば、自分が書いたコードを自分でレビューする状態です。バグを見落とすのと同じ構造で、エージェントも自分の検出結果を甘く見る。
Anthropicが公式ブログで報告しているのは、別のエージェントを立てて「これは偽陽性だと仮定して反証してみろ」と指示する、いわゆるadversarial verifierを噛ませる構成です。要は「自分でレビューさせるな」ということ。
複数チームでの結果として、悪用不可能な検出結果(non-exploitable findings)の割合が約半分に削減されたと書かれています(roughly halved)。
複数のverifierで多数決を取る構成にすると、さらに精度が上がるとのこと。
LLM ソースコード セキュリティでは、discoveryとverificationを別人格に分けるのがAnthropicの推奨する設計になっています。
脅威モデルがないとAIは「組織の文脈」を知らない
もう1つ、AnthropicがCISO発言として引用していたフレーズが刺さりました。
「モデルはコードの文脈はよく知っているが、私たちのことはよく知らない」
つまり、どの資産が守るべきもので、どの信頼境界を越えると致命的なのか、そうした「うちの組織ならではの判断軸」はモデルの中にはない、ということです。
公式ブログでは、threat modelがちゃんと整備されたチームでは、検出された脆弱性が実際に悪用可能であった割合が90%まで上がったと報告されています(exploitable 90 percent of the time)。
ハーネスの/threat-modelスキルがbootstrap(初回作成)とinterview(対話で補完)の二段構えになっているのは、ここを最初に固めないと先のフェーズが全部精度ガタ落ちになるからなんですよ。
逆に言えば、脅威モデルさえ整えばあとのパイプラインは一気に意味を持ち始める。その体験を、スキルだけで手軽に試せます。
Claude Codeスキルだけで今日から始める最小構成
自律パイプライン側(harness/配下)は、gVisorによる隔離やDockerでのPoC実行を含むので、いきなり全部動かすのはハードルが高いです。
でも、スキル側だけなら今日から触れます。
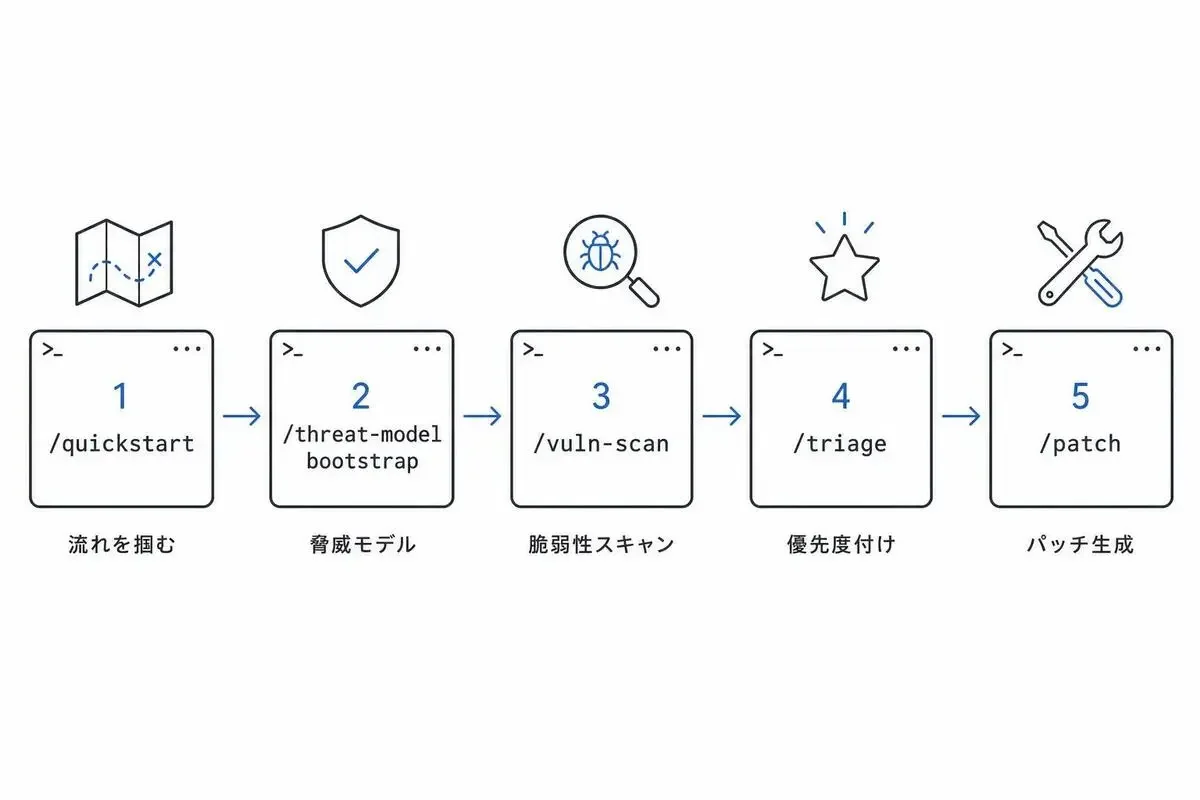
具体的にはこの順番で試せます。
/quickstartでスキル全体の流れを掴む/threat-model bootstrapで対象リポジトリの脅威モデルを起こす/vuln-scanで対話的にスキャンを回す/triageで検出結果に優先度を付ける/patchで修正パッチを生成する
/customize以外のスキルはread/write中心で、サンドボックスなしでも動かせます。自律パイプラインに進むのは、スキルで一周回して「自分のコードで何が引っかかるか」が見えてからで十分です。
私のおすすめは、まず/threat-modelから入ることです。脅威モデルを言語化するだけで、検出結果の意味が変わってきます。「これは確かにうちのシステムでは致命的だな」と腹落ちする件数が、明らかに増えるんですよ。
自動脆弱性スキャンを「とりあえず回してみる」と、検出結果の山に潰されます。逆に脅威モデルから始めると、最初から「自分が直すべき脆弱性」だけが手元に残ります。
AIが見つけて直す時代に、エンジニアは何をするのか
discoveryはもうAIに任せられます。ここはAnthropicの数字を見ても疑いの余地がない。
そのうえで、エンジニアに残る仕事は私の整理だと3つです。
1つめは、脅威モデルを言語化することです。何が守るべき資産か、何を信頼するか、どの境界を越えたら致命的か。AIはコードは読めても、ここを勝手に決めてくれません。
2つめは、検証フローを設計することです。AI 脆弱性検出においてverificationを誰に(どのエージェントに)やらせるか、偽陽性をどう削るか、PoCをどの隔離環境で動かすか。1,596件と97件の差を埋めるのは、まさにこの設計です。
3つめは、パッチの妥当性を判断することです。症状を消すパッチでいいのか、根本を直すべきなのか。これは組織の優先順位とリスク許容度の問題なので、人が判断するしかありません。

Glasswingはコードを守る側にAIを使う複数企業の取り組みで、defending-code-reference-harnessはそこで得た知見をAnthropicが参照実装に落としたものです。
「コードを書かない」の次に来るのは、「コードを守らない」ではなく「守る設計を考える」だと私は思っています。
週末に/quickstartを試してみてください。脅威モデルを書く行為が、自分のシステムのどこが本当に危ないかを整理する時間にもなります。それだけでも、やる価値はあると思っています。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 10
- 0



こちらもおすすめ
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 7
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 9
- 0
-
AI脱社畜
- 10
- 0
-
- 5
- 0
-
 たく
たく
- 7
- 0
-
- 8
- 0
-
- 8
- 0
-
- 10
- 0
-
- 9
- 0
-
- 8
- 0
-
- 1
- 0
-
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 3
- 0
-
カイ@プロダクトマネージャー
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 2
- 0
-
- 3
- 0
-
AI経営者の参謀@ひで
- 1
- 0














AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます