
こんにちは。
もるふぉです。
日本時間2026年5月29日(米国西海岸時間では5月28日)、Anthropicがclaude-opus-4-8を正式リリースしました。
価格は据え置きでベンチマークは全方位で底上げ、しかも個人的に一番効いたのは「エージェントが嘘をつかなくなった」感触の改善です。
公式発表が出てすぐ、Claude Codeに組み込んでいた長時間ジョブから順に4.8へ差し替えて回しました。
その上で「ベンチ数値以上に業務インパクトが大きいポイント」を5つに絞ってまとめます。

Claude Opus 4.8は何が変わったか — 30秒でわかる変更サマリー
まず結論から先に置きます。
時間がない人はこの表だけ見れば十分です。
claude-opus-4-7claude-opus-4-8effortデフォルトhighぱっと見て「これ乗り換え一択だな」と思える内容です。
価格据え置きでベンチが上がり、しかも新機能(Dynamic Workflows・Fast Mode・Adaptive Thinking)まで付いてくる。
Anthropic側がOpus 4.7と同じコストで2世代分くらいの改善を詰め込んできた印象です。
ベンチマーク数値の対比
SWE-bench Proで64.3%→69.2%、5ポイント弱の伸びです。
数字だけ見ると地味ですが、SWE-bench Proは「エージェント型コーディング」を測るベンチで、PRレベルの課題を最後までやり切れるかを評価しています。
ここで5ポイント伸びるということは、長時間タスクの完走率が体感で1〜2割上がるイメージです。
実際、私が回している複数の業務システム向けのリファクタジョブで、4.7では途中で迷走していた案件が4.8だと素直に完走するケースが増えました。
OSWorld-Verified(PC操作の自律性)は82.3%→83.4%とほぼ横ばいで、こちらは大きな期待をしないほうがいいです。
ブラウザ操作のOnline-Mind2Webは4.8で84%(4.7は公表されていません)。やや改善はしているものの、コーディング系のような大きな伸びはありません。
一方、知識労働スコアは1753→1890と100ポイント以上ジャンプしています。
これは設計レビューや要件整理、業務ドメイン知識を踏まえた回答の品質に直結する指標で、私の体感とも一致します。
価格・API model IDの変更点
価格は完全据え置きで、入力$5(約750円)/出力$25(約3,750円)/100万トークン。
ただしAPI model IDはclaude-opus-4-7からclaude-opus-4-8に変わっているので、置き換え漏れに注意です。
地味に効くのがFast Modeで、Opus 4.8では同等品質を2.5倍速で出せるモードが追加されました。
価格は$10/$50 per 100万トークン(前世代Opus 4.7のFast Mode比で3分の1)。
通常の標準価格($5/$25)よりは高いプレミアム価格帯ですが、レイテンシを優先したい用途で選択肢が増えたのは大きい。
ただしBatch APIには非対応なので、純粋なバッチ処理にはむしろ標準価格の通常モードを使うほうが安く済みます。
で、数値だけ見ると「まあ順当なアップデートだな」で終わりそうなんですが、ここから先が本当に面白いんです。
Claude Opus 4.8の「自己誠実さ」強化が実務でどう効くか
「エージェントが嘘の完了報告を返してきた」経験、ありませんか。
長時間ジョブを回しておいて、「タスク完了しました」とレポートが返ってきたので確認に行ったら、肝心の中核処理が未着手だった——というやつです。
しかも完了報告にもっともらしい根拠まで書いてある。
レビュー側がコードを読んで初めて「あれ、これ書いてなくない?」と気付くパターンが何度かありました。
「動いてるけど嘘ついてないか確認」する手間が地味にストレスで、エージェントを信頼して任せきれない根本原因がここにありました。
公式発表で一番地味なのに、業務インパクトが大きいのが「more honesty about its own progress」というフレーズです。
直訳すると「自分自身の進捗について、もっと正直になった」——これだけ読んでもピンと来ないと思います。
具体的には、エージェントが「タスクが終わっていないのに終わったと申告する」「自信がないのに自信ありげに進める」という挙動が明確に減りました。
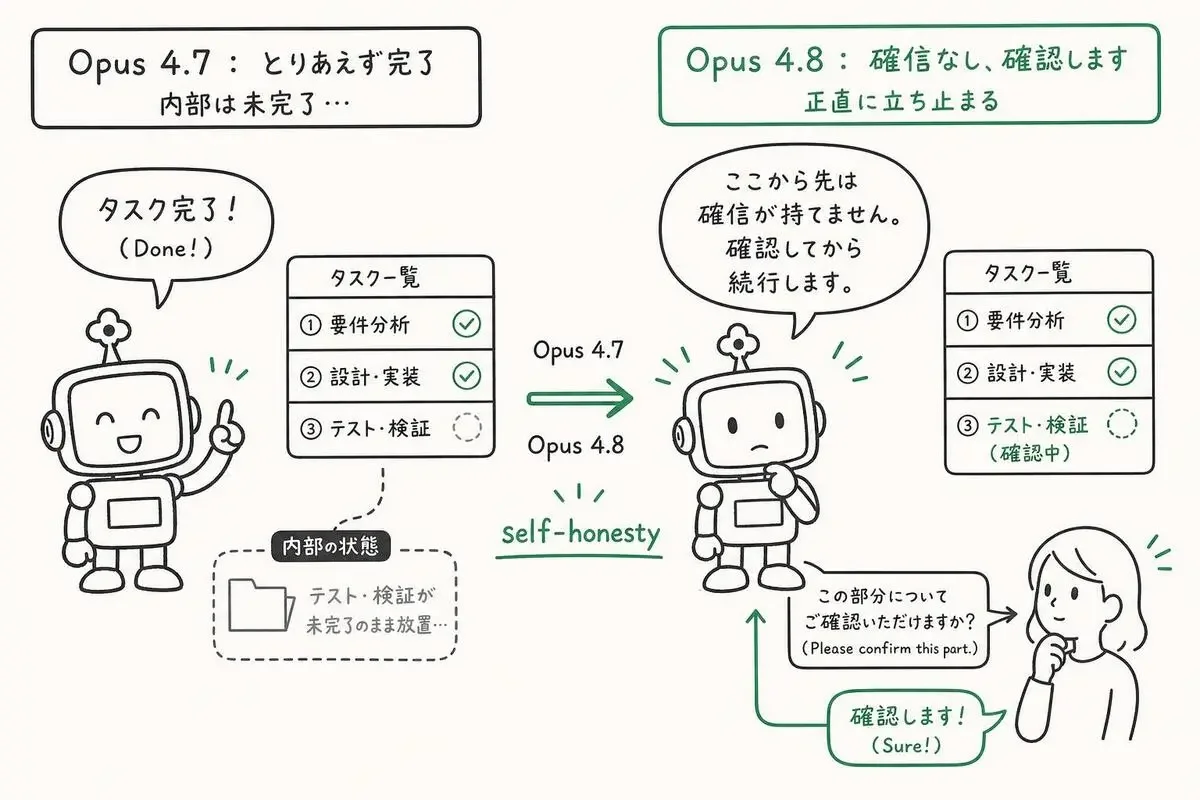
エージェントが「なんとなく完了」を申告しなくなる
4.8ではこれが目に見えて減りました。
具体的には、確信が持てない部分に来ると「ここまでは実装しましたが、X関数の挙動が仕様書から読み取れません。確認してから続行します」と素直に止まる場面が増えています。
これ、エージェントの信頼性として相当大きな改善で、レビュー側の心理負担が一気に下がります。
「動いてるけど嘘ついてないか確認」する手間が消えるだけで、長時間ジョブを安心して任せる気になるんですよね。
不確実性を自己申告する設計がレビュー工数に効く
実務インパクトを数字で言うと、レビュー工数が体感3〜4割減です。
理由は単純で、4.7時代は「全部疑う前提」でPR全体を読み直していたのが、4.8では「エージェント自身が『ここは確信ないです』と申告してくる箇所だけ重点的に見る」スタイルに切り替えられるからです。
公式が言うコードの欠陥をそのまま見逃す確率が前モデルの約4分の1という数字も、おそらくこの「自己誠実さ」の改善が効いています。
検出ロジックが賢くなったというより、「自信がないときに勝手に先に進まない」設計の効果が大きいはず。
エージェントを業務に組み込んでいる人なら、この変化だけで乗り換える価値があります。
「自己誠実さ」が実務にどう刺さるかが分かったところで、次はもっとスケールする話——Dynamic Workflowsの使いどころに入ります。
Claude Opus 4.8 × Dynamic Workflowsの実際の使いどころ
次に紹介するのが、Opus 4.8と同時にリサーチプレビューで提供開始されたDynamic Workflowsです。
「数百の並列サブエージェントが自動で立ち上がってタスクを分担する」と言われると、なんかすごそうには聞こえます。
でも「で、何が嬉しいの?」が伝わらないと使いどころが分からないので、私が実際に試した結果から先に言います。
コードベース全体の命名規則一括変換を、4.7では半日かかっていたものが数十分で終わりました。
並列度の高いタスクなら、体感で数倍〜十倍近くの速度差が出ます。
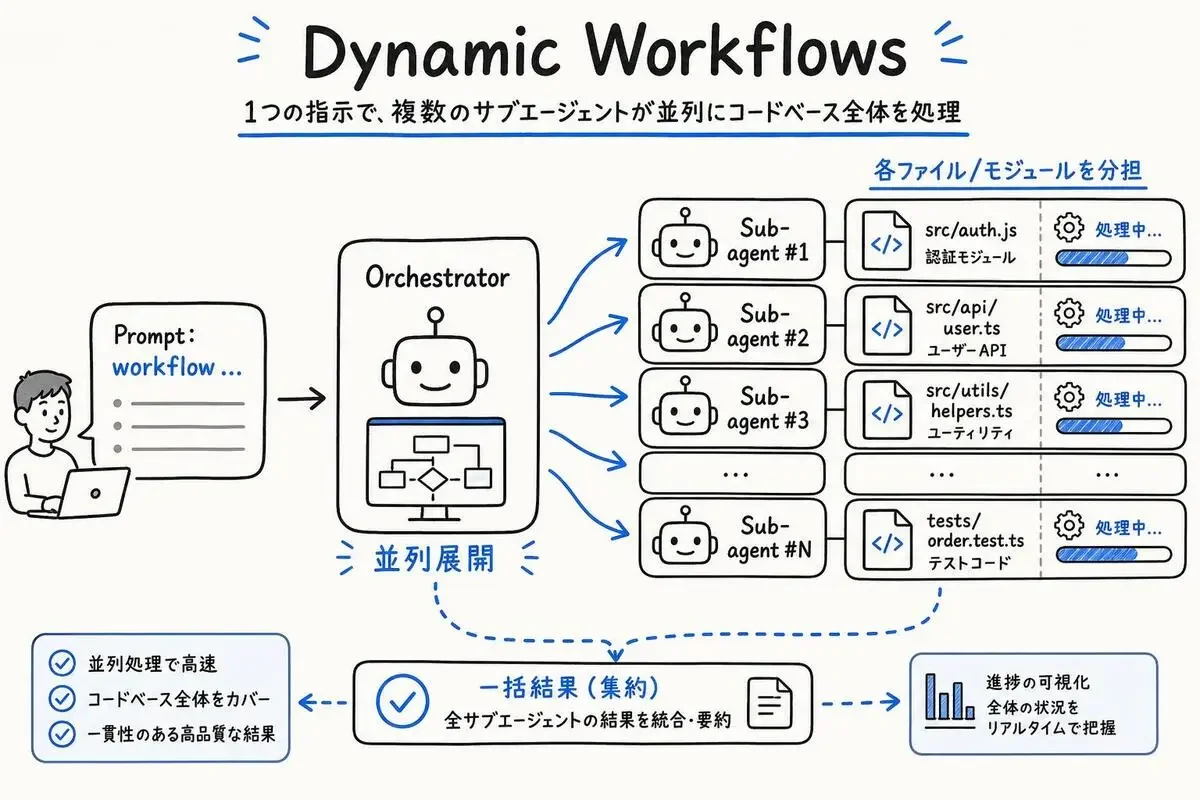
「workflow」とプロンプトに書くだけで起動する
起動方法は驚くほど簡単で、プロンプトの中に「workflow」というキーワードを含めるだけです。
たとえば「このコードベース全体をworkflowで一括レビューして、命名規則の違反を全部出してほしい」と書くと、Opus 4.8側が自動で並列サブエージェントを立ち上げて、ファイルを分担しながら走り出します。
設定ファイルもAPIパラメータもなしで、CLIから普通にプロンプトを投げるだけで起動します。
なお現時点ではリサーチプレビューの提供で、起動方法の詳細や条件は公式ドキュメントで確認してください。
向いているタスク・向いていないタスクの見分け方
実際に複数のケースで試した感触で言うと、向くタスクは以下です。
- コードベース全体の一括レビュー(命名規則・型違反・dead code検出)
- ファイル横断のリファクタリング(依存関係の一括変換)
- バグハント(複数モジュールの挙動を並列に追う)
- APIコントラクトの全依存チェック
並列度が高いタスクほど威力が増します。
逆に向かないタスクは以下です。
- 1コンポーネントだけのデバッグ
- UI微調整
- 明確な手順がある定型作業
- 単一ファイル内のリファクタ
並列化のオーバーヘッドが効かない小規模タスクでは、むしろ通常のシングルエージェントのほうが速いです。
「ファイル数が10以下のタスクには使わない」を目安にすると失敗しません。
Dynamic Workflowsで速度は解決した。では今度は、速くなった分のコストはどうなるか——次のセクションで正直に言います。
Claude Codeでclaude-opus-4-8に移行する際に気をつける3点
ここからは実装寄りの話です。
公式ドキュメントを読まずに乗り換えるとハマるポイントが3つあるので、先に潰しておきます。
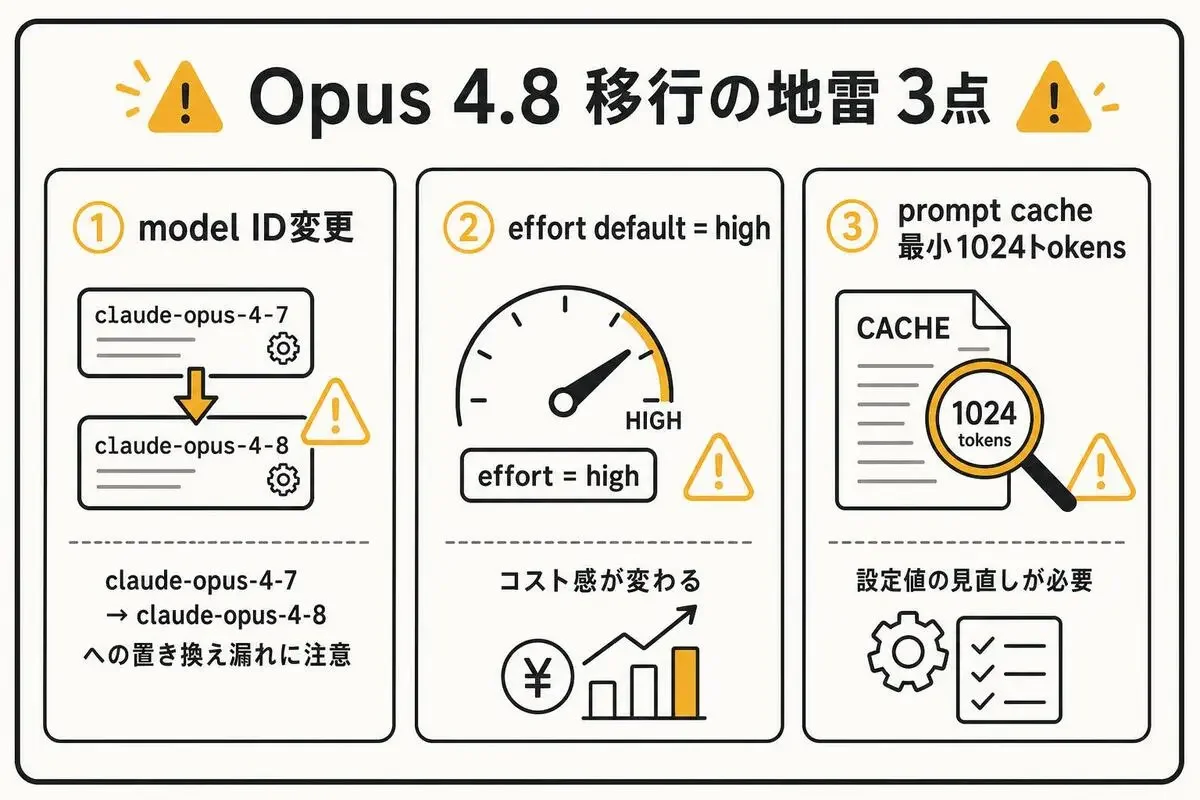
model IDの変更(claude-opus-4-8)
まず当たり前ですが、API呼び出し時のmodel IDを書き換える必要があります。
# 旧
claude --model claude-opus-4-7 "..."
# 新
claude --model claude-opus-4-8 "..."CIスクリプトや.claude/配下の設定、各種ラッパーにclaude-opus-4-7がハードコードされていないか、grep一発で確認しておくのが安全です。
私の場合、複数のリポジトリにまたがって設定が散らばっていたので、置き換え漏れで1時間くらい原因究明に使いました。
effortデフォルト値がhighになった影響
地味だけど挙動に効くのがeffortパラメータです。
Opus 4.8からは全サーフェスでデフォルトがhighになりました。
つまり何も指定しないと「全力で考える」モードで動くので、コスト感が変わります。
短いタスクをバッチで大量に回すケースでは、明示的にeffort: "low"や"medium"を指定したほうが財布に優しいです。
逆に長時間ジョブを任せたい場合はデフォルトのままで問題なし。
プロンプトキャッシュ最小長が1,024トークンに短縮
3点目はプロンプトキャッシュの仕様変更です。
Opus 4.8からはプロンプトキャッシュの最小長が1,024トークンまで下がりました。
これ何が嬉しいかというと、これまでキャッシュに乗らなかった短めのシステムプロンプトもキャッシュ対象になるということです。
特にClaude Codeで頻繁にリクエストを飛ばす用途では、キャッシュヒット率が上がってコスト・レイテンシ両方で効きます。
ついでにAPI側のもう一つの注意点を補足すると、thinking: {"type": "enabled", "budget_tokens": N}という旧仕様の指定方法は400エラーで弾かれます。
代わりにthinking: {"type": "adaptive"}を使うのが正解です。
このあたりの詳細は公式ドキュメントに全部書いてあるので、移行前に一度目を通しておくと事故を防げます。
移行の地雷を潰したところで、最後に一番意外だったコストの話をします。
Opus 4.8のAdaptive Thinkingで「むしろトークン消費が減る」場合
「Opusに乗り換えたらトークン消費が増えるのでは」と構えていたのですが、これが読み外れました。
正直、鳥肌が立つくらい意外な結果だったので先に言います。
私が回している業務システム向けの定型タスク(CRUD実装・テスト生成・ドキュメント差分検出など)では、4.8に切り替えたあと月次のトークン消費が想定より2割ほど低く出ました。
「Opusはハイエンドモデルだからコストが上がる」という固定観念が、完全に外れた形です。
Opus 4.8のAdaptive Thinkingは、必要なときだけ思考ステップを使う設計が明示化されています。
つまり、単純なタスクでは思考をスキップするので、ケースによってはOpus 4.7より総トークン量が減ります。
「思考ステップを毎回フルで走らせている」前提でコスト試算していたのが外れた形です。
これ、コスト管理している人にとっては結構嬉しい誤算です。
ハイエンドモデルだから高くなる、という理由で他モデルにルーティングしている人は、一度Opus 4.8で測り直す価値があります。
逆に長時間ジョブや複雑な推論を任せるケースでは、effort: "high"がデフォルトなのでガッツリ思考ステップを使います。
ここはタスクの性質次第で振れる、と覚えておけばOKです。
「Opus = 必ず重い」ではなく、「Opus = 必要に応じて重くなる」になったのが4.8の本質です。
Claude Opus 4.8を使うべきタイミング vs 据え置きでいいタイミング
ここまで読んで「で、結局乗り換えるべき?」が気になる人向けに、判断軸を整理します。
すぐ乗り換えるべきユースケース
以下に当てはまる人は、今日中に切り替えていいです。
- 長時間自律タスク(PRレベルのコード生成・大規模リファクタ・コードベース全体のレビュー)をエージェントに任せている
- レビュー工数を減らしたい(「自己誠実さ」の改善が効く)
- Claude Codeを業務で日常的に使っている
- Dynamic Workflowsを試したい
- コードレビュー自動化のパイプラインを組んでいる
特に「エージェントが嘘の完了報告を返してきて辛い」という人は、それだけで乗り換える価値があります。
据え置きでいいユースケース
逆に、以下に当てはまる場合は急がなくていいです。
- 既存パイプラインが安定稼働していて、検証コストを払いたくない
- 短いプロンプトを大量に回すバッチ処理で、コスト最優先(Haiku系で十分なケース)
- Opus以外のモデルにルーティング済みで、Opusの出番がそもそも少ない
- 規制業界などでモデルバージョン固定が求められる環境
判断軸はシンプルで、「長時間タスク・自律性・レビュー削減」がキーワードに入る人は乗り換え、そうでない人は様子見でOKです。
価格据え置きなのでコスト面で躊躇する理由はなく、純粋に「動作検証する時間が取れるか」で決まります。
まとめ: Claude Opus 4.8は「信頼性のアップグレード」として受け取る
最後に総評です。
Opus 4.8の本質はベンチマーク数値の伸びではなく、「自己誠実さ」と「Adaptive Thinking」という信頼性とコスト効率の両輪の改善にあります。
SWE-bench Proで5ポイント伸びたという事実より、「エージェントが嘘の完了報告を返さなくなった」「不要な思考ステップをスキップする」という現場感の改善のほうが、業務インパクトが圧倒的に大きい。
私の感覚だと、ベンチ数値より体感の方が2〜3割上振れている印象です。
これは公式ベンチではなく業務利用での実感なので、各自の環境で測ってもらうのが一番ですが、おそらく似た感触を持つはず。
今後の展望としては、Opus 4.9や他社のフラッグシップ(GPT-5系・Gemini 3系)との競争が一気に加速するフェーズに入ります。
ただ、Opus 4.8の「自己誠実さ」は他社が真似しにくい部分で、エージェント運用の信頼性で頭一つ抜けている状況がしばらく続きそうです。
まずは自分の長時間ジョブを1本、claude-opus-4-8に差し替えて回してみてください。
おそらく「あ、これは戻れないな」となると思います。
価格据え置きで動作検証コストだけで済むので、試さない理由がないアップデートです。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
AI脱社畜
- 3
- 0
-
プロンプト画伯
- 3
- 0
-
- 3
- 0
-
 たく
たく
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
たく
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 4
- 0
-
- 5
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます