こんにちは。もるふぉです。
Claude Codeでリポジトリ全体のリファクタを頼んだら、途中でコンテキスト切れして力尽きた経験、ありませんか。
サブエージェントを複数走らせようとしても、「どのエージェントに何を頼むか」の分割設計で頭が疲れて、結局1つずつ手動で回す羽目になる、あの地味なストレス。
そんなところに、2026年4月20日にMoonshot AIが「300並列・4,000ステップ」という完全に桁違いのスペックのKimi K2.6をリリースしてきました。
ネタ元はこちらの公式ポストです。
この記事では次のことが分かります。
- Kimi K2.6 Agent Swarmの仕様と、K2.5からの具体的な進化ポイント
- 300並列エージェントで「実際に何ができるのか」の実証事例4選
- エンジニアが明日から自分のプロジェクトに落とし込むためのユースケース
- Claude Codeとの設計思想の違いと、どう使い分けるかの現実解
- Kimi Code CLIのインストールから基本的な呼び出し方まで
1兆パラメータのオープンウェイト、かつ商用利用可能なModified MITライセンスということで、セルフホストの選択肢も含めて検討できるモデルになっています。
順に見ていきます。
Kimi K2.6 Agent Swarmとは何か
Kimi K2.6は、中国の北京に拠点を置くMoonshot AIが2026年4月20日に公開したフロンティアモデルです。
総パラメータは1兆(MoE構造で推論時のアクティブパラメータは32B)、コンテキスト長は262,144トークン、ライセンスはModified MITで商用利用も可能になっています。
モデルの重みはmoonshotai/Kimi-K2.6としてHuggingFaceに公開されているので、セルフホストしたい場合はそこから取ってくる形です。

で、このモデルの一番の売りが「Agent Swarm」という仕組みです。
ざっくり言うと、1つの大きなタスクを受け取ったKimi K2.6が、自分自身でサブエージェントを大量に生成し、並列で動かしながらタスクを片付けていくという機能になります。
ここで重要なのは、このスウォーム機構のコーディネーター役をK2.6自身が担っている点です。
Moonshot AIはこの仕組みを「adaptive coordinator(適応的コーディネーター)」と表現しています。
つまり「LangGraphやCrewAIで並列を自分で組む」のではなく、「モデルがコーディネーターを兼務して300並列で動く」という思想なんですね。
いわばPMが「全体を見渡してタスクを振り、失敗した担当を即座に差し替える」ところまで自分でやってくれるイメージです。
K2.5からK2.6への進化(100→300並列、1,500→4,000ステップ)
K2.5からK2.6への進化は、スケールが文字通り桁違いです。
主要指標を整理するとこうなります。
並列数が3倍、ステップ数が約2.7倍になっています。
ただ、数字の中で一番インパクトを感じるのは「継続実行時間」です。
「数時間」から「5日間」——これ、次元が違います。
従来のAIエージェントは、途中でコンテキストを見失ったりタスクの整合性が取れなくなったりして、長時間稼働ができませんでした。
K2.6は「長時間走り続ける」こと自体を設計目標にしているので、夜寝てる間に動かしておいて朝結果を見る、みたいな使い方が現実的に視野に入ってきます。
ベンチマークでもSWE-Bench Proで58.6%、SWE-Bench Verifiedで80.2%、BrowseComp (Swarm)で86.3%というスコアを出していて、コーディング系タスクではGPT-5.4やClaude Opus 4.6と正面から競える数字を出しています。
ここまで聞くと「で、具体的に何ができるの?」と気になりますよね。
次のセクションがその答えです。
「ファイル出力」という設計思想の転換
個人的に一番面白いと思ったのが、K2.6が「チャットで答える」から「ファイルを出力する」にシフトしている点です。
公式ブログが挙げている出力例を見ると、1回の実行で次のようなアウトプットが出ます。
- 100以上のファイル(100+ files in a single run)
- 20,000行規模のデータセット
- 40ページ・7,000語の研究論文 + 20,000エントリ以上の構造化データ + 14の天文学グレードチャート
これ、チャットUIで出す発想じゃないんですよ。
Claude Codeで似たようなことをやろうとすると、1ファイルずつ書いてもらって、レビューして、次のファイルに行って……という手動オーケストレーションになります。
K2.6は最初から「大量のファイルを吐き出すこと」をデフォルトの出力モードとして想定しているので、プロンプトも「◯◯についての100ファイルを生成して」という雑な指示で動きます。
この発想転換が、地味に効いてきます。
なぜなら人間が確認するループを挟まずにAIが作業を完結できる範囲が、一気に広がるからですね。
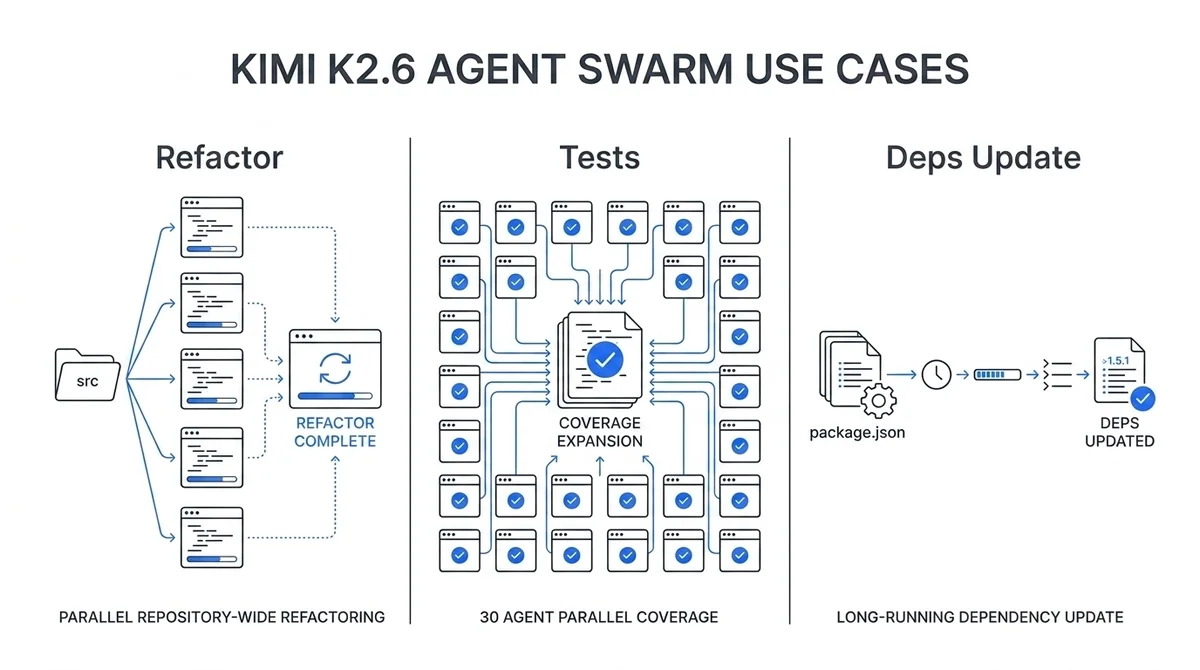
Kimi K2.6 Agent Swarmで実際に何ができるのか——主要な実証事例4選

「300並列って言われても、自分の仕事に使えるの?」——そこが一番気になるポイントだと思います。
Moonshot AIの公式ブログに載っている実証済みユースケースを4つ紹介します。
どれも派手ですが、ここを押さえておかないと「自分の仕事にどう使えるか」のイメージが湧かないはずです。
金融分析レポートを半導体100銘柄に一括展開
1つ目は金融分析です。
「5つの定量戦略を、グローバル半導体100銘柄に横展開して、McKinsey形式のPPTにまとめて」というプロンプトを1発投げると、K2.6はそれを300並列のサブエージェントで処理します。
各サブエージェントがそれぞれ1つの資産を担当して分析し、最終的にコーディネーター役のK2.6本体がそれを集約してPPTを組み立てる、というフローです。
従来のエージェントで同じことをやろうとすると、5戦略×100銘柄で500タスクを順番に回すか、自前でキューイング機構を組む必要があります。
それが1プロンプトで済む——業務レポート系の仕事を持っている人には刺さるはずです。
学術研究の完全自動化(論文+データセット+チャート)
2つ目がかなり攻めていて、天体物理学の研究論文を入力にして、次のような成果物を一気に作ります。
- 40ページ・7,000語の研究論文
- 20,000エントリ以上の構造化データセット
- 14の天文学グレードチャート
論文を読んでまとめるだけじゃなくて、データセットの再構築、チャートの描画まで含めて一気通貫です。
ポイントは「チャートの描画」まで入っていることで、数値分析ステップとビジュアライゼーションステップを別々のサブエージェントが担当する構造になっているということですね。
文献レビューの深掘りを仕事にしている人や、リサーチャーポジションの人は、このアウトプット構造をテンプレとして使えるはずです。
履歴書100枚カスタマイズ生成
3つ目は個人でも使える事例です。
「100の職種に対応した、カスタマイズ済みの履歴書100枚を生成して」という指示で、各職種の職務要件を読み込みながら、応募者の経験を最適な形で並び替えた履歴書が100枚出てきます。
これは転職エージェントやフリーランス仲介の業務に直結しそうな使い方です。
自分がエンジニアとして「100社に別々の見せ方で履歴書出す」ことはまずないですが、クライアントへの提案書を100社分カスタマイズする、みたいな営業活動には転用できる構造に見えます。
13時間自律コーディングでOSSのスループットを185%改善
4つ目がエンジニア的には一番テンションが上がる事例です。
「exchange-core」という8年もののOSS金融エンジンを、K2.6が13時間連続で自律的に最適化し、スループットを185%向上させたという事例が公式に公開されています。
この間に1,000回以上のツール呼び出しと、4,000行を超えるコード修正が行われたとのこと。
もう1つ、macOSでの推論最適化をZig言語で12時間連続実行した事例もあって、こちらはトークン生成速度を15トークン/秒から193トークン/秒まで引き上げたそうです。
4,000回以上のツール呼び出しが1セッション内で発生しています。
「寝てる間にOSSをチューニングしておく」——これが現実的な運用になりつつある、ということですね。
個人的にここが一番アツいと思っていて、次のセクションでエンジニア向けに具体的なユースケースを設計してみます。
エンジニアが今日から使えるKimi K2.6のユースケース
公式事例は派手ですが、そのまま自分の仕事に持ち込めるとは限りません。
ここからは、Kimi K2.6のAgent Swarmをエンジニアが普段の業務に落とし込むなら、というユースケースを現実的な範囲で設計してみます。
※あくまで「仕様上こう使えるはず」という想定であり、全ケースを動作検証したわけではない点はご了承ください。
リポジトリ全体のリファクタリングを並列で走らせる
大規模リポジトリで「このパターンを全ファイルで直したい」みたいな作業、ありますよね。
たとえばRailsプロジェクトでN+1の疑いがあるクエリを全コントローラで点検する、とか、型定義を全TypeScriptファイルで厳格化する、とか。
Claude Codeで同じことをやると、1ファイルずつ地道にレビューするか、サブエージェントを手動で分散させるかになります。
Kimi K2.6のAgent Swarmなら、理論上は「このリポジトリの全コントローラをスキャンして、N+1になりそうな箇所を1つずつ別サブエージェントで修正して、それぞれPR単位で出して」という指示が通ります。
Claude Codeで1ファイルずつ頼んでいたのを、300人に一斉発注できる——そのくらいのスケール差です。
4,000ステップの実行予算があるので、中規模リポジトリのファイル数なら、全ファイルを1サブエージェントずつ担当させても枠内に収まる計算です。
ただし、本当に300エージェントを同時に走らせると、APIレート制限やテスト環境への副作用が発生するので、実運用では「並列度を制限する」という指示を最初にプロンプトで入れておくのが現実的だと思います。
テストスイートを30エージェントで並列カバレッジ拡張
これは自分が一番試してみたいユースケースです。
テストカバレッジが低いレガシープロジェクトで「カバレッジ50%を80%に上げたい」みたいな仕事、地味にしんどいんですよ。
各モジュールごとにテスト対象を洗い出して、仕様書を読んで、ケースを設計して、テストコードを書いて、を延々と繰り返します。
K2.6なら、30モジュールに対して30サブエージェントを割り当てて、それぞれが担当モジュールのテストケース設計とテストコード生成を並列で進めることができます。
ここで効いてくるのが「ファイル出力」という設計です。
チャットで返されてもコピペ作業が発生しますが、最初からテストファイル群をそのまま出力してくれるので、人間は「Pull Requestのレビュー」だけに集中できます。
テスト生成自体が並列化できると、開発サイクル全体の律速段階が変わってきます。
長時間稼働で依存ライブラリを一括アップデート
もう1つ、5日間自律実行の具体的な使い道として、依存ライブラリの一括アップデートがあります。
package.jsonやGemfileの全パッケージをメジャーバージョンまで上げて、失敗したテストを修正しながら、ブレイキングチェンジに対応していく、という作業。
これを人間が1週間かけてやっていたのが、K2.6なら「夜走らせて朝結果を見る」が可能になる可能性があります。
実際、先ほどの「exchange-core 13時間自律最適化」の事例がこの領域の証明になっていて、長時間稼働での依存関係調整はK2.6の得意分野に見えます。
ここで大事なのは、作業前にテストコードを厚く書いておくことです。
AIに長時間自律作業を任せる場合、命綱はテストコードになります。
テストで失敗を即座に検知できる状態を作っておけば、K2.6は自律的に修正を試みて、動く状態に戻してくれる設計になっているからですね。
「Claude Codeとどう使い分けるか」が気になってきた方のために、次のセクションで整理します。
Kimi K2.6 vs Claude Code——設計思想の違い
ここは多くのエンジニアが気になるポイントだと思います。
結論から言うと、両者は「何を解きたいか」が違うので、どちらかが一方的に優れているという話ではないです。
ただ、設計思想の違いを理解しておくと、使い分けの判断が楽になります。
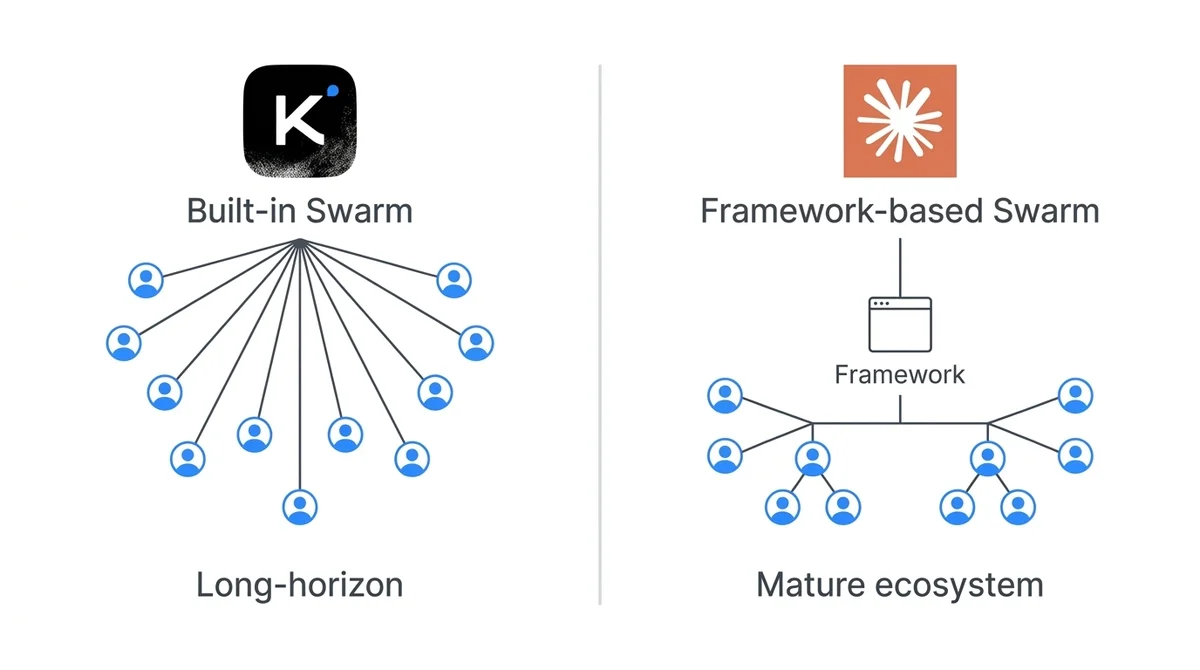
モデルがコーディネーターを兼務するスウォーム vs 外部のフレームワークが制御するスウォーム
一番大きな違いは、スウォーム機構がどこに実装されているかです。
Kimi K2.6はモデル自体がadaptive coordinator(適応的コーディネーター)として機能し、受け取ったタスクを自己分解して300並列にディスパッチし、失敗したエージェントを自動リアサインする、までをモデル主導で完結させています。
一方、Claude Codeのサブエージェント機構は、Claude Code側のフレームワークがオーケストレーションを担当する形です。
タスクを投げる人(エンジニア)がある程度サブエージェントの役割を設計して、明示的に割り振る流れになります。
どっちが良い悪いではなくて、次のような使い分けになります。
- Claude Code: タスクの分解を人間側でしっかり設計したいとき。各エージェントの役割を明確に切りたいとき
- Kimi K2.6: タスクの分解までモデルに任せたいとき。大量並列が必要で、分解パターンが定型化しにくいとき
自分の感覚では、Claude Codeは「明示的な設計」が効く案件に強く、Kimi K2.6は「物量で押す」タイプの案件に強い印象です。
Claude Codeが勝つシーン / Kimi K2.6が勝つシーン
もう少し具体的にシーンを分けます。
Claude Codeが勝つシーン。
- 日本語の複雑な仕様書から設計を詰めていく要件定義フェーズ
- コードレビューや、プルリクエスト単位での丁寧な修正
- エコシステム(VSCode拡張、各種プラグイン、mdファイルでのプロンプト制御)の成熟度が効く場面
- チーム開発でレビュアーとしてのAIが必要なとき
Kimi K2.6が勝つシーン。
- 大量のファイル生成(100+ファイル、レポート大量生成)
- 長時間自律実行(12時間以上の最適化タスク)
- APIコストを圧縮したい場面(後述の料金比較参照)
- オープンウェイトでセルフホストしたい場面(Modified MIT)
あと、これは運用面ですが、ライセンスが商用利用可能なModified MITであることは地味に大きいです。
自社プロダクトにモデルを組み込む場合、Claude SonnetやGPTはクローズドAPI依存ですが、Kimi K2.6はmoonshotai/Kimi-K2.6をダウンロードして自前でホストする選択肢が取れます。
SaaS構成で「バックエンドにモデルを直接組み込む」ケースでは、この差はかなり本質的です。
「コスト面はどうなの?」という話を次のセクションで数字ベースで整理します。
Kimi K2.6の料金と現実的なコスト試算
料金面は、K2.6の採用判断においてかなり重要な要素です。
正直、ここは驚くほど安いです。
APIコスト比較(Kimi vs Claude)
Platform Kimiの公式料金表を整理します。
比較として、Claude Sonnet 4.6の入力は$3/1Mトークン程度です(最新料金はAnthropic公式の料金ページで確認してください)。
つまりKimi K2.6は、入力コストだけで見るとClaude Sonnet 4.6の約3分の1です(キャッシュヒット時の$0.16ベースなら約19分の1)。
Agent Swarmは性質上、大量のトークンを消費します。
300並列エージェント×4,000ステップで動かすような長時間タスクは、入力コンテキストと出力の両方でトークンが積み上がっていくので、単価が3分の1というのは実運用で効いてきます。
ただし「Claude Sonnet 4.6とKimi K2.6のベンチマークが全タスクで同等」ではないので、単純なコスト割りだけで判断するのは危険です。
コードレビュー系・複雑仕様のキャッチアップ系はClaude、物量系・長時間系はKimi、という棲み分けを前提に、コスト試算は各ワークロードで行うのが現実的です。
オープンウェイトでセルフホストする選択肢
もう1つの選択肢が、HuggingFaceからmoonshotai/Kimi-K2.6の重みをダウンロードしてセルフホストすることです。
ライセンスはModified MIT(商用利用可、ただし大規模サービスでは一部表示義務あり)なので、自社のGPUクラスタで動かす構成も取れます。
もちろん1兆パラメータのMoEモデルを動かすには相応のVRAMが必要なので、個人の環境で動かすのは厳しいです。
ただ、スタートアップが自社製品にモデルを埋め込むケースだと「API料金を青天井で払い続ける」か「一定規模のGPUクラスタを持ってセルフホストする」かの分岐点がある程度現実的に見えてきます。
たとえば月次でAPI料金が数百万円を超えるような規模になってきたら、セルフホスト移行の試算を始めるタイミングになるはずです。
Kimi K2.6 Agent Swarmが向いていないケース
K2.6は強力ですが、万能ではありません。
フェアに言っておきたい注意点を共有します。
日本語指示の精度・エコシステムの現状
現時点(2026年4月)で気になるのは次の2点です。
1つ目は、日本語の細かなニュアンスを含んだ複雑指示のフォロー精度です。
英語のベンチマークではGPT-5.4やClaude Opus 4.6と互角ですが、日本語の仕様書をそのまま流し込んで設計判断をさせるようなシーンでは、Claudeの方が細かく指示を拾ってくれる感覚があります(これは主観なので、試すタスクの種類にもよります)。
2つ目は、エコシステムの成熟度です。
Claude Codeは2025年からの蓄積で、mdファイルでのプロンプト制御、各種エディタ拡張、サブエージェント設計パターンなどのナレッジが相当溜まっています。
Kimi Code CLIは2026年4月に公開されたばかりで、まだコミュニティのナレッジが少ない状態です。
「使いこなすための試行錯誤コスト」という意味では、少なくとも数ヶ月はClaude Codeの方が楽です。
この辺は半年〜1年経てば埋まってくるはずですが、今すぐ実務に投入するなら「Claude Codeをメイン、Kimi K2.6を物量系のサブ」という組み合わせが現実的だと思います。
あと、当然ですが300並列を走らせる場面では、対象のAPIやテスト環境側のレート制限・副作用に注意が必要です。
外部APIを叩くタスクで300並列を投げると普通に相手側を壊しにいくので、プロンプトで並列度を制限する指示を入れるのは必須です。
「注意点は分かった、実際にどう試せばいい?」——その答えが次のセクションです。
Kimi Code CLIのセットアップと使い方
実際に試したい人向けに、Kimi Code CLIのセットアップ方法を書いておきます。
コマンド1発で入ります。
Kimi Code CLIは、ターミナルから直接Kimi K2.6のAgent Swarmを呼び出せる公式CLIツールです。
5分でインストールする手順
インストールはコマンド1発です。
curl -LsSf https://code.kimi.com/install.sh | bashこれだけでkimi-cli(実行コマンドは環境により異なる場合があるのでインストール後の案内に従ってください)が使える状態になります。
APIキーの設定は、Platform Kimiでアカウントを作って発行します。

APIキーを環境変数KIMI_API_KEYにセットしておけばCLI側が拾ってくれる構成になっているはずです(具体的な環境変数名は公式ドキュメントの最新版を確認してください)。
正直、curlのワンライナー系インストーラーは内容を確認してから実行したい派の人もいると思うので、気になる場合はinstall.shを先にダウンロードして中身を見てから実行するのが安全です。
Agent Swarmを呼び出す基本構文
Kimi Code CLIでAgent Swarmを呼び出す場合、基本的には通常のプロンプトの中で「並列で」「複数ファイルに出力」のような指示を入れる流れになります。
モデル自体がスウォーム判断をするので、明示的に「300エージェントを起動せよ」という低レイヤのコマンドは通常は不要です。
たとえば「このリポジトリ全体を分析して、各モジュールごとのREADMEを並列で生成してください」というプロンプトを投げると、モデル側が自律的に並列度を決めてサブエージェントを起動してくれる設計になっています。
VSCodeやZed、JetBrains系とはACP(Agent Communication Protocol)で連携が取れるので、IDE内から呼び出したい場合はそれぞれのエディタ向けのKimi拡張をインストールする形です。
エディタ統合はClaude Codeの方が現時点では完成度が高いと思うので、最初はCLIで使い方に慣れてから徐々にIDE連携を追加するのが無難だと思います。
まとめ:Kimi K2.6がエンジニアの働き方に何をもたらすか
Kimi K2.6のAgent Swarmを一通り追いかけてみて、個人的には次の3点が本質的な変化だと感じています。
1つ目は「物量が律速じゃなくなる」ということ。
100ファイル生成、40ページの研究論文、20,000行のデータセット出力が1プロンプトで完結する世界線は、ホワイトカラーの業務設計を変えます。
エンジニアの仕事で言えば、リファクタ対象のファイル数、テストケース数、依存ライブラリ数といった「物量でしんどかった作業」のしんどさが、一気に消えます。
2つ目は「人間の確認ループが減る」ということ。
従来はAIに作業させて、人間が確認して、次の作業を投げる、という往復が発生していました。
K2.6はファイル出力を前提にしていて、失敗時の自動リアサインもモデルが担っているので、人間はレビュー工程だけに集中できる構造になります。
テスト駆動でAIを制御する手法と、この設計は相性がすごく良いです。
3つ目は「オープンソース×商用利用可能」という文脈。
Modified MITで商用利用可能な1兆パラメータモデルが公開された意味は、中長期で見ると結構大きいです。
API依存リスクがない、コスト構造を自社でコントロールできる、モデルを自社用にファインチューニングできる、という選択肢が企業にとっても個人にとっても取れるようになった、ということですね。
とはいえ、現時点ですべてをKimi K2.6に寄せるのは時期尚早です。
Claude Codeの成熟したエコシステム、日本語指示の細やかさ、レビュアーとしてのAIの使い方は、まだClaude側が強い領域です。
自分の運用方針としては、Claude Codeは今まで通り「設計・レビュー・複雑指示」で使いつつ、Kimi K2.6を「物量・長時間自律・セルフホスト検討」のレイヤで追加する、というハイブリッドが現実解になりそうだと思っています。
まずはcurl -LsSf https://code.kimi.com/install.sh | bashでKimi Code CLIを入れて、小さいタスクを1つ投げてみるところから始めるのが良いと思います。
コマンド1発で入るので、試すハードルは低いです。
動かしてみないと分からない体感値が、このモデルは特に多いです。
気になる機能や検証して欲しいユースケースがあれば、Xで@morphox_aiに教えてもらえると嬉しいです。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 3
- 0
-
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
AI脱社畜
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0

















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます