
コードを書かないAIエンジニア@もるふぉです。
普段はフリーランスエンジニアとして開発をしていますが、最近はClaude Codeにどっぷり浸かった生活を送っています。
エージェントハーネスとメモリの所有権——この話題、AIコーディングツールを本格的に使い始めたエンジニアなら一度は引っかかるポイントだと思います。
コードを「書く」のではなく「設計して指示する」スタイルに完全移行した身として、今回のテーマはちょっと見逃せませんでした。
「Claude Code、便利に使ってるけど……そのうちAnthropicに縛られちゃうんじゃない?」
そういう漠然とした不安、感じたことありませんか?
この記事を読むと、その不安の正体がクリアになります。
そして「じゃあ自分はどうすればいいか」の判断軸も整理できます。
Harrison Chaseさん(LangChain共同創業者・CEO)が2026年4月11日に公開したブログ記事「Your harness, your memory」の内容を軸に、エンジニア目線で解説していきます。
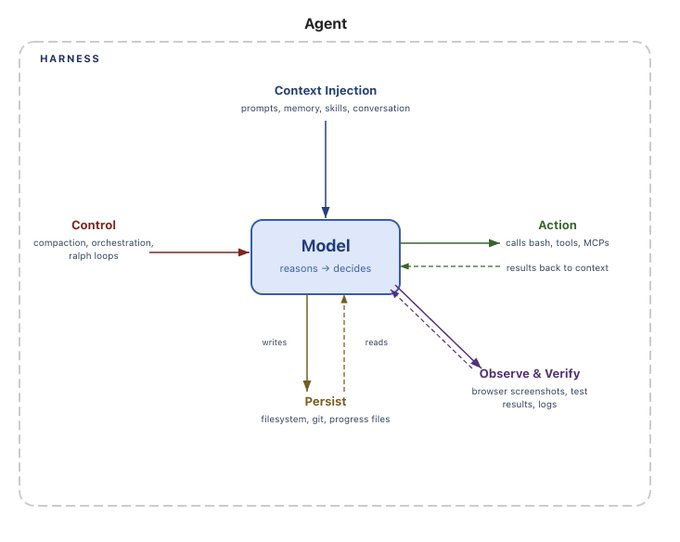
AIエージェントにとって「ハーネス」とは何か
まず「エージェントハーネス」という言葉を整理しておきます。
ハーネスとは、AIモデルを実際に動かすためのインフラ全体のことです。
モデルそのものはあくまで「頭脳」であって、ファイルを読む、コマンドを実行する、Webを検索する、タスクを分割する——こうした行動を可能にしているのがハーネスです。
Claude Code、OpenAI Codex、LangChain Deep Agents、OpenCodeなど、今主流のコーディングエージェントはすべてハーネスの上で動いています。
モデルだけではエージェントは動かない——512,000行のインフラ
この話を象徴するのが、2026年3月のClaude Codeソースコードリーク事件です。
npmパッケージに.mapファイルが含まれたまま公開され、512,000行以上のTypeScriptコードが流出しました。
512,000行ですよ。
これがまさにハーネスの実体です。
モデル自体は別のところで動いていて、それを「どう使うか」「どう制御するか」を決めているのがこの巨大なコードベースだったわけです。
Harrison Chaseさんはブログの中で、「モデルがスキャフォールディングを吸収するから、ハーネスはいずれなくなる」という意見に対して明確に反論しています。
Anthropicがこれだけの投資をしてハーネスを構築している時点で、ハーネスは消えるどころかますます重要になっている、と。
モデルがどれだけ賢くなっても、CLAUDE.mdの読み込み、ファイルシステムへのアクセス、サブエージェントの起動といった「外側の仕組み」がなければ、実用的なエージェントにはなりません。
つまり、私たちがClaude Codeを使うたびに価値を生んでいるのは、AIモデルだけじゃなくてハーネスでもある、ということです。
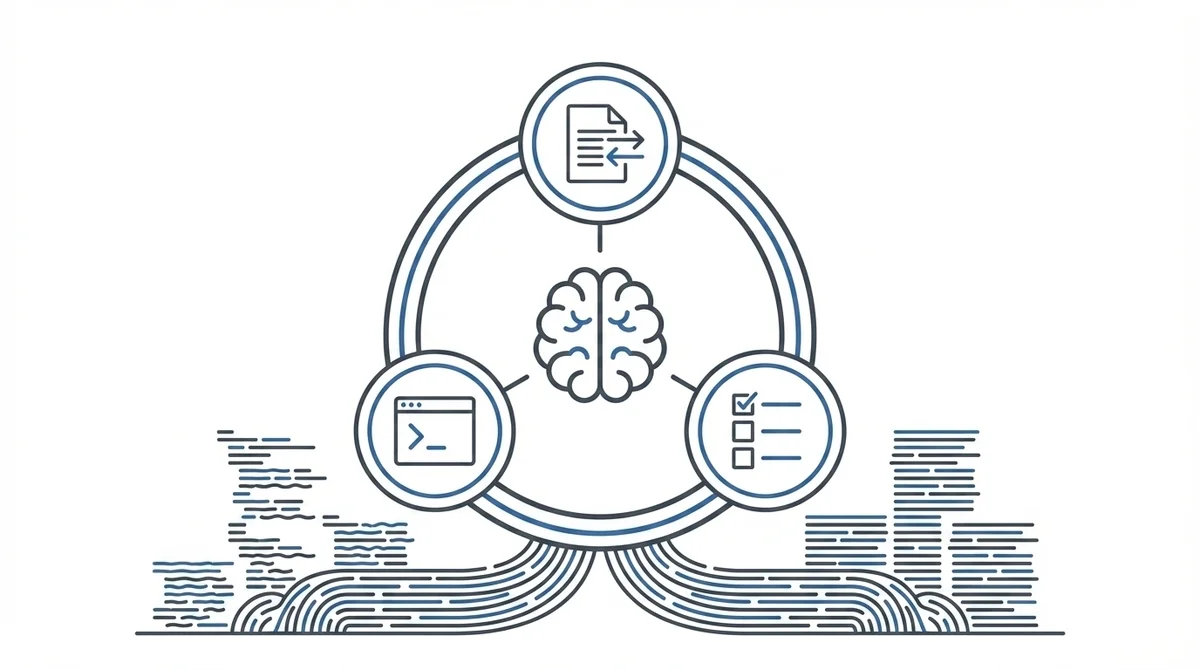
ハーネスが担う3つの役割(コンテキスト管理・ツール実行・タスク計画)
ハーネスの責務を整理すると、大きく3つに分かれます。
1. コンテキスト管理
会話履歴の保持、コンテキストウィンドウの圧縮(コンパクション)、CLAUDE.mdやAGENTS.mdの読み込み。
モデルに「何を見せるか」を決めるのがハーネスの仕事です。
2. ツール実行
ファイルの読み書き、シェルコマンドの実行、Web検索。
OpenAIやAnthropicのAPIにWeb検索が組み込まれているのも、実はツールコーリングによるオーケストレーション、つまりハーネスの一形態です。
3. タスク計画
複雑なタスクの分割、サブエージェントへの委譲、進捗管理。
この3つが絡み合って初めて「使えるエージェント」になります。
ここで注目してほしいのが、この3つのうち「コンテキスト管理」は、実はメモリ管理とほぼ同義だということです。
さて、ここからが問題の核心です。
メモリはハーネスと不可分——「プラグインではなく構造そのもの」
Harrison Chaseさんのブログで特に印象的だったのが、Sarah Woodersさん(Letta/MemGPT共同創業者・CTO)の発言の引用です。
Sarah Woodersのたとえがすべてをあらわしている
Sarah Woodersさんは「メモリをエージェントハーネスにプラグインできますか?」という質問に対して、こう答えています。
> 「それは『運転を車にプラグインできますか?』と聞いているのと同じです」
これ、すごく的を射たたとえだと思います。
ハンドルやアクセルが「後から取り付けるオプション」じゃないように、メモリもエージェントに後から差し込めるプラグインではなく、ハーネスの構造そのものだということです。
考えてみれば当然で、CLAUDE.mdを読み込むのも、長い会話をコンパクションで要約するのも、前回のセッションで学んだことを次回に引き継ぐのも、全部ハーネスの仕事です。
メモリの「何を覚えるか」「何を忘れるか」「どう呼び出すか」は、ハーネスの設計そのものに組み込まれています。
コンテキスト管理とメモリ管理は同義である
Harrison Chaseさんはこれをさらに分解しています。
- 短期メモリ: 会話のメッセージ、ツール呼び出しの結果。コンテキストウィンドウに載っている情報
- 長期メモリ: セッションをまたいで保持される知識。ユーザーの好み、過去の指示、学習した行動パターン
短期メモリはコンテキストウィンドウの管理そのものですし、長期メモリはハーネスがストレージに読み書きする仕組みに依存します。
どちらもハーネスの設計から切り離せない、ということですね。
そしてここが重要なポイントなのですが、長期メモリはまだ多くのエージェントでMVP(最小限の製品)にすら含まれていない、まだ初期段階の機能です。
いわば、今はエージェントの「記憶力」がまだ育ちきっていない段階。
だからこそ今のうちにメモリの所有権について考えておかないと、育ちきった頃に「あ、全部ベンダー側にあった」となりかねません。
で、具体的にどうなるの?という話をしますね。
クローズドハーネスを使うと「何を失うか」
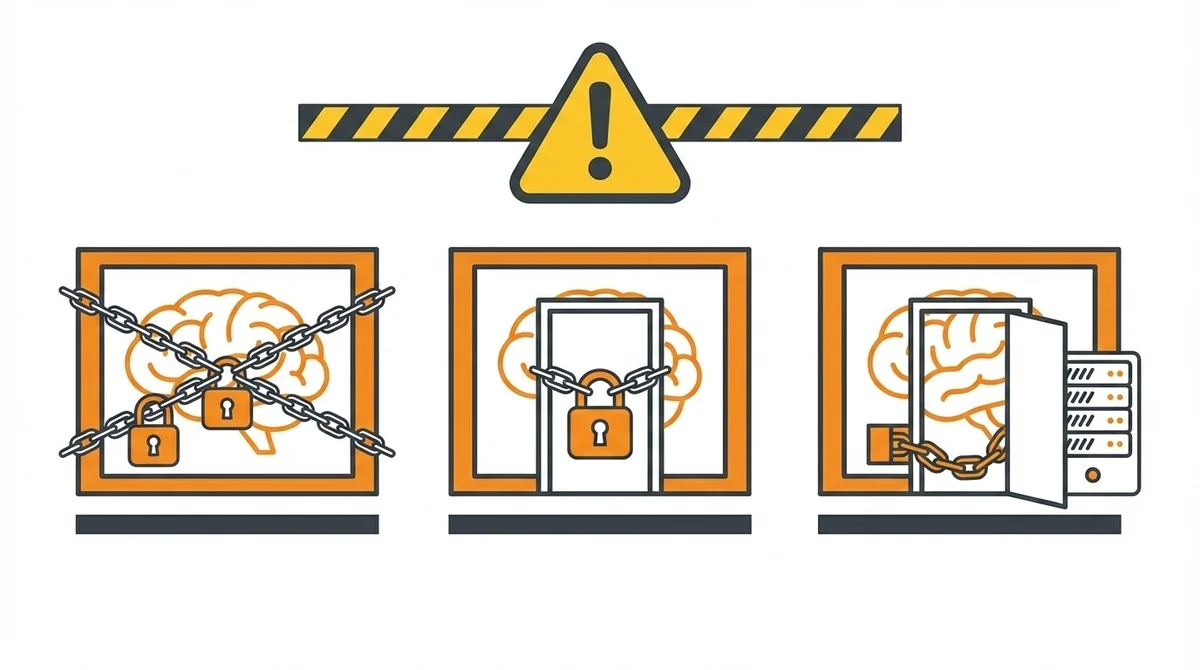
ここが今回の記事でいちばん「知っておいてほしい」部分です。
Harrison Chaseさんはブログの中で、メモリの所有権を失うパターンを3段階で整理しています。
影響が大きい順に紹介します。
パターン1: API完全ロックイン(Claude Managed Agents型)
最もロックインが深刻なのが、ハーネス全体と長期メモリがAPI越しに提供されるパターンです。
2026年4月8日にパブリックベータとして公開されたClaude Managed Agentsがこれに該当します。
Managed Agentsでは、エージェントの実行環境、サンドボックス、ツール実行、そしてメモリのすべてがAnthropicのインフラ上で動きます。
セッション1時間あたり$0.08の課金に加えて、トークン使用量も標準API価格で課金されます。
問題は、メモリの内部構造やコンパクションの挙動が外部から検証しにくいことです。
なお、Anthropicはresearch previewとしてmemory機能の一部を提供していますが、エージェントが何を覚えているのか、どう要約しているのかは一般ユーザーにとって不透明な部分が多く残っています。
別のプロバイダーに移行しようとしても、メモリを持ち出す手段がありません。
つまり、「このサービス良いな、乗り換えよう」と思ったとき、エージェントの「記憶」だけが置いてけぼりになる状態です。
Sarah Woodersさん自身もXで指摘していましたが、Managed Agentsの設計はLettaが1年前から提供していたAPIと酷似しているものの、クローズドソースでベンダーロックインを伴うという決定的な違いがあります。
パターン2: オープンソースでも暗号化(Codexの実態)
「Codexはオープンソースだから大丈夫」——と思っている方、ここはちょっと注目してください。
OpenAI Codexはオープンソースとして公開されています。
しかし、コンテキストウィンドウの上限に達したときのコンパクション(圧縮要約)の仕組みに注目すると、話は単純ではありません。
Codexがコンパクションを実行すると、会話内容はOpenAIのサーバーに送られ、別のLLMが要約を生成します。
その要約はAES暗号化された不透明なデータ(opaque blob)として返されます。
次のターンでは、サーバー側で復号されてモデルに渡される仕組みです。
暗号化キーはOpenAIのサーバー上にあります。
コード自体はオープンソースでも、メモリの実体はOpenAIのエコシステム外では使えない。
「オープンソースだから安心」と思っていたのに、メモリだけは実質的にロックインされている——この落とし穴は地味に盲点だと思います。
パターン3: ステートフルAPI(サーバー保存型)の問題
最も「軽度」とされるのが、OpenAI Responses APIやAnthropicのサーバーサイドコンパクションのようなステートフルAPIです。
これらは会話の状態をサーバー側で保持してくれる便利な仕組みです。
ただ、その状態はプロバイダーのサーバーに保存されます。
モデルを切り替えたいと思ったとき、その会話スレッドは移行できません。
今日のAI業界のように、数ヶ月でベストなモデルが入れ替わる状況では、「このモデルのほうが良いけど、過去の会話履歴を捨てるのはもったいない」というジレンマが日常的に発生し得ます。
Harrison Chaseさんは、メモリがなければエージェントは「同じツールにアクセスできる誰にでも複製可能」だと指摘しています。
逆に言えば、メモリこそがエージェントの価値の源泉であり、それをプロバイダーに握られることのリスクは大きいわけです。
じゃあどうすればいいの?というのが次の話です。
オープンハーネスという選択肢——LangChain Deep Agentsの立ち位置
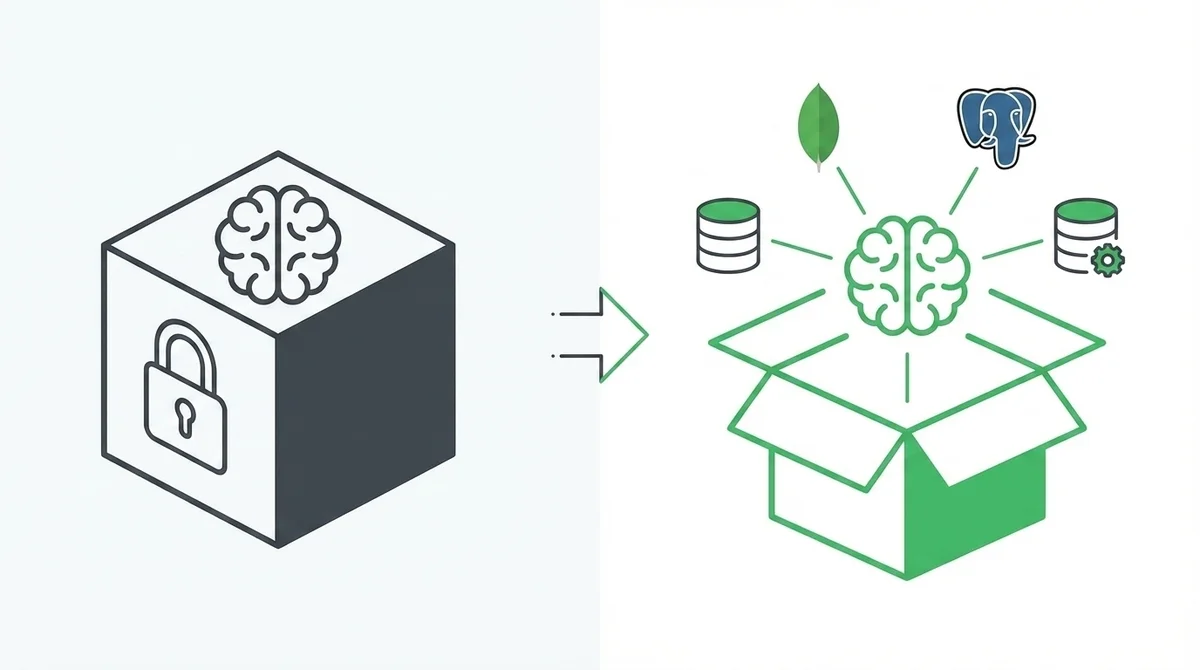
Harrison Chaseさんはもちろん、自社プロダクトであるLangChain Deep Agentsをオープンな代替として提案しています。
正直に言うと、この記事にはLangChainのポジショントーク的な側面があるのは否めません。
自社のオープンソース製品を推す文脈で書かれていることは意識しておくべきです。
ただ、提起している問題自体は本質的だと思います。
モデル非依存・標準フォーマットでメモリを自分のDBに
Deep Agentsの設計思想で特徴的なのは以下の点です。
- オープンソース(MITライセンス): コードが完全に公開されている
- モデル非依存: ツールコーリングに対応していればどのLLMでも動く
- オープン標準の採用: agents.mdやAgent Skills(agentskills.io)といった標準フォーマットを使用
- データベースプラグイン: メモリの保存先としてMongoDB、PostgreSQL、Redisなどを選択可能
- セルフホスト対応: LangSmithでのデプロイのほか、標準的なWebフレームワークでの自前ホスティングも可能
メモリが自分のデータベースに保存されるということは、モデルを切り替えても、ハーネスを変えても、データは手元に残るということです。
いわば「通帳の中のお金がどの銀行でも使える」状態。
クローズドハーネスは特定の銀行でしか使えない電子マネーに近い、と考えると違いがわかりやすいかもしれません。
LangChain Deep Agentsとオープンな代替の選択肢
ここで冷静に整理しておくと、Deep Agentsが万能というわけではありません。
リリース後に注目を集めているプロジェクトではありますが、Claude CodeやCodexと比較して機能面や使い勝手で差がある部分もあります。
ただし、「メモリの所有権を維持する」という観点では、オープンソースでモデル非依存のハーネスを選ぶことに明確なメリットがあります。
もう一つ注目すべきは、Lettaの存在です。
LettaはMemGPTから発展したプロジェクトで、「メモリファースト」のエージェントハーネスを標榜しています。
モデル非依存でオープンソース、Terminal-Benchではプロバイダー固有のハーネスと同等のパフォーマンスを出しているとのことです。
Harrison Chaseさんのブログで引用されているSarah Woodersさんの知見は、まさにLettaでの実践から来ているものです。
選択肢は一つではありません。
重要なのは「メモリがどこに保存され、誰がコントロールしているか」を意識してハーネスを選ぶことです。
エンジニアとして今どんな判断をすべきか
ハーネス選択は「今後の技術的負債」に直結する
Harrison Chaseさんが記事の中で触れている自身の体験が印象的でした。
メールアシスタントをうっかり削除してしまい、再構築したものの、過去のインタラクションで蓄積されたメモリが失われたため「再教育」が必要だったそうです。
Claude Codeの設定ファイルを一から作り直した経験がある人なら分かると思いますが、ツールとの「文脈の共有」が失われる感覚は地味につらいものがあります。
長期メモリが成熟したとき、その失われ方はもっと深刻になる可能性があります。
エージェントは使えば使うほど賢くなる。
その「賢さ」の蓄積がメモリです。
今の段階では、多くのエージェントで長期メモリはまだ初期段階の機能です。
でも、これから確実に重要度が増していく領域です。
今クローズドなハーネスに深く依存すると、メモリが蓄積されればされるほど移行コストが上がっていくことになります。
これはまさに技術的負債そのものです。
「今は便利だから使う」という判断は正しいと思います。
ただ、いつかの乗り換えを想定しておくかどうかで、将来の選択肢の広さが変わります。
移行コストを下げるための3つのチェックポイント
今すぐハーネスを乗り換える必要はありません。
5分もかからないので、以下の3つだけ確認してみてください。
1. メモリの保存先を確認する
自分が使っているエージェントのメモリはどこに保存されていますか。
ローカル?プロバイダーのサーバー?エクスポート可能?
CLAUDE.mdやAGENTS.mdのようにファイルベースで管理されているものは可搬性が高いです。
一方、サーバーサイドのコンパクション結果や暗号化されたサマリーは持ち出せません。
2. コンパクションの透明性を確認する
コンテキストが圧縮されるとき、何が残って何が失われるのか把握していますか。
Codexのように暗号化されている場合、圧縮結果を検証する手段がありません。
3. 標準フォーマットを意識する
agents.md、Agent Skills、CLAUDE.mdといったオープンな設定ファイルは、ハーネス間で移植可能な資産です。
プロバイダー固有の設定にすべてを委ねるのではなく、標準フォーマットで管理できる部分は標準フォーマットで管理する。
これだけでも移行コストは大きく変わります。
まず一歩目として、CLAUDE.mdやAGENTS.mdをGitで管理しておくだけでも、ハーネスを変えたときの移植性が大きく高まります。
まとめ——「ハーネスを選ぶことはメモリを選ぶこと」
Harrison Chaseさんの「Your harness, your memory」が伝えているメッセージはシンプルです。
エージェントハーネスとメモリは不可分であり、ハーネスの選択がメモリの所有権を決める。
Claude CodeもCodexも、今の段階では非常に優れたツールです。
自分もClaude Codeを毎日使っていますし、その生産性の高さは間違いありません。
ただ、メモリの重要性がこれから増していく中で、「自分のデータがどこにあるか」を意識しておくことは大切です。
今回の記事のポイントを整理すると以下のようになります。
自分も記事を書きながら、Claude Codeのメモリがどこに保存されているか改めて確認しようと思いました。
今すぐ何かを乗り換える必要はありません。
ただ、次にハーネスを選ぶとき、あるいは本番環境にエージェントを組み込むとき、まず「このエージェントのメモリはどこに保存されるのか」を一つ確認してみてください。
それだけで、将来の選択肢が大きく変わるはずです。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 3
- 0
-
 たく
たく
- 1
- 0
-
プロンプト画伯
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
たく
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 4
- 0
-
- 5
- 0
-
- 3
- 0
-
- 5
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます