こんにちは。もるふぉです。
GPT-5.5(コードネーム「Spud」)が2026年4月23日に公開されて、タイムラインが朝からザワザワしていました。
「乗り換えるべきかな……でも料金2倍か」——自分も同じことを考えました。
新しいフロンティアモデルが出るたびに「今使ってる環境を捨てるべきか」という判断を迫られる、あの感じ、地味にストレスたまりますよね。
しかも今回はGPT-5.4のリリースからわずか約7週間後の追加投入で、OpenAIの矢継ぎ早な攻勢感が、その判断をさらに急かしてくる。
自分は普段Claude Code(Opus 4.7)で案件を回しているので、「Claude Codeから乗り換える必要があるのか」という視点で一日かけて触って検証してみました。
結論から言うと、乗り換えではなく併用が現実解、というのが現時点での自分の判断です。
この記事では3つを明確にします。
- ベンチマークの実態: どの項目でGPT-5.5が勝ち、どの項目でClaudeが勝つか
- Codex新機能の意味: 400Kコンテキストとブラウザ操作が開発ワークフローをどう変えるか
- 料金2倍問題の採用判断: 「fewer tokens」という主張を実務コストで検証するフレーム
ベンチマークの数字を並べるだけの記事なら他にもあるので、自分はClaude Code愛用者として「どっちを選ぶか」「どう使い分けるか」という現場判断の部分を重めに書きます。
GPT-5.5(Spud)とは:GPT-5.4から約7週間での異例リリース
まず前提を整理します。
GPT-5.5は2026年4月23日(木)に公開されたOpenAIのフロンティアモデルで、GPT-5.4リリースからわずか約7週間後のアップデートです。
7週間弱というリリース間隔、普通じゃないです。
これまでのGPTシリーズを振り返っても、マイナーバージョンアップがこの速度で出るのは異例で、AnthropicのClaude Opus 4.7やGoogleのGemini 3.1 Proとのフロンティア争いがいよいよ日単位・週単位の戦いになってきたと感じています。
コードネーム「Spud」の由来と社内の温度感
社内コードネームは「Spud」、ジャガイモです。
地味な名前ですが、OpenAI共同創設者・社長のGreg Brockmanさんは発表の中で「a faster, sharper thinker for fewer tokens compared to something like 5.4(GPT-5.4と比べて、より速く、より鋭く、より少ないトークンで考えられる)」と位置付けていました。
最高科学責任者のJakub Pachockiさん、最高研究責任者のMark Chenさん、技術スタッフのMia Glaeseさんも登壇しており、OpenAIが今回を「単なるマイナー更新」ではなく「新しい知能クラス」として打ち出したい意図が透けて見えます。
GPT-5.4からの主要な変更点サマリー
GPT-5.4との違いを一言で言うと「同じタスクに必要なトークン数が減って、より高精度になった」です。
単純な性能向上というより、トークン効率を軸にした再設計という色が濃いですね。
- 推論の効率化(同じタスクにより少ないトークンで到達)
- Codex統合でブラウザ操作機能を追加
- コンテキストウィンドウが拡張(Codex経由で400K、API経由では最大1Mトークン)
- GDPval(知識労働ベンチマーク)で業界プロフェッショナルと並ぶスコアを記録
- API料金は入力・出力ともに2倍に
利用可能プランはChatGPTのPlus、Pro、Business、Enterpriseで、上位版のGPT-5.5 ProはPro、Business、Enterpriseのみ。
APIは独立提供が「very soon(まもなく)」とされていて、Codex経由では既に利用できる状態です。
OpenAIは独立API提供には「different safeguards(別のセーフガード)」が必要と説明していて、このあたりの慎重さは金融・医療系クライアントへの配慮でしょうね。
ここからが本題です。「で、実際どっちが強いのか」を数字で見ていきます。
ベンチマーク徹底比較:GPT-5.5 vs Claude Opus 4.7でどちらが勝つか
ここが本記事の核です。
Claude Code愛用者の視点で、忖度なしに数字を並べます。
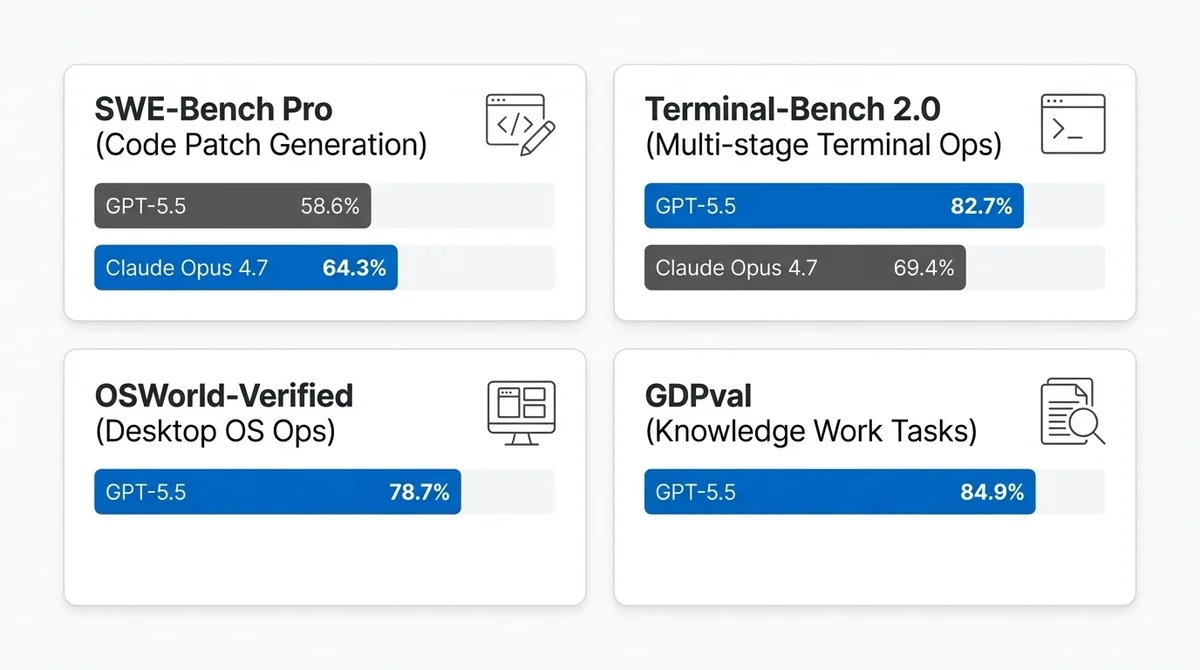
SWE-Bench Pro: Claudeが64.3%でリード、GPT-5.5は58.6%
まず、コード生成能力の指標として最もよく使われるSWE-Bench Pro。
5.7ポイント差でClaudeの勝ちです。
自分はGPT-5.5の発表時の盛り上がりを見て「さすがにコード精度でもClaudeを超えてきたのか」と身構えていたんですが、実際は逆でした。
え、Claudeが勝ってるの?——そうなんです、これ意外と知られていない事実。
ここ、注目してほしいです。
OpenAIは発表会で多くのベンチマークを強調しましたが、SWE-Bench Proのスコアは公式発表であまり前面に出ていません。都合の悪い数字を黙って出さないのはどの会社もやりがちなので、自分のようなユーザー側は必ず第三者ベンチマークを確認する習慣が大事だと改めて思いました。
既存のコードベースにパッチを当てる、リアルなOSSのIssueを解決する、といった「実務で一番多い作業」では、Claude Opus 4.7が依然として優位に立っています。
Claude Code使いは焦らなくていいです。
Terminal-Bench 2.0: GPT-5.5が82.7%で圧勝
一方で、Terminal-Bench 2.0はGPT-5.5が圧勝しています。
13.3ポイント差は大きいです。
Terminal-Benchはターミナル上でコマンドを組み立てて実タスクを解く評価で、「ls叩いて、grepして、sedで整形して、APIに投げる」みたいな多段ツール呼び出しが評価対象です。
ここで13ポイント差がつくということは、GPT-5.5は「環境を観察して次の手を決める」という部分がかなり強くなった証左と言えます。
エージェントとして自律実行させるシナリオでは、GPT-5.5のほうが信頼できると読めます。
自分のように「夜寝てる間に長時間タスクを回したい」系の使い方をする人には刺さる話です。
OSWorld-Verified・GDPvalなど他ベンチマークの結果
他の主要ベンチマークも整理しておきます。
GDPval 84.9%の意味、これ見逃せないです。
GDPvalは弁護士・会計士・金融アナリストなど実際の業界プロフェッショナルの仕事とAIの出力を比較するベンチマークで、「マッチまたは上回る」スコアが84.9%。要は知識労働の8割以上で人間のプロと並ぶ、という主張です。
ここ、盛ってる可能性もあるので鵜呑みは危険ですが、少なくともOpenAIがこの方向(単なるコーダーではなく汎用知識労働者として売る)に寄せていることは明確です。
ベンチマークから読み取る「使い分けの正解」
ここまでを整理すると、ベンチマーク上の使い分けは次のようになります。
- コードを書く精度(SWE-Bench系): Claude Opus 4.7が優位
- ターミナル・OS・ブラウザ操作(Terminal-Bench、OSWorld): GPT-5.5が優位
- 知識労働・調査タスク(GDPval): GPT-5.5が優位
個人的にはここがアツいです。
「コードエディタに張り付いて差分を書く仕事はClaude、外部環境を触りながら仕事する部分はGPT-5.5」という棲み分けが、ベンチマーク上ははっきり出ています。
これは自分の体感と一致します。
そして、ここからが自分的に今回一番テンションが上がった話です。
GPT-5.5で進化したCodex:ブラウザ操作と400Kコンテキストが開発を変える
次にCodexの話です。
正直、今回のアップデートでここが一番「ワクワクする」と思っています。ベンチマークの数字よりも、開発の日常が具体的に変わる話なので、少し丁寧に書きます。
自分はGitHub上のCodexリポジトリも追っているんですが、今回のアップデートは単なる性能向上ではなく、ワークフロー自体が変わるレベルの変更を含んでいます。
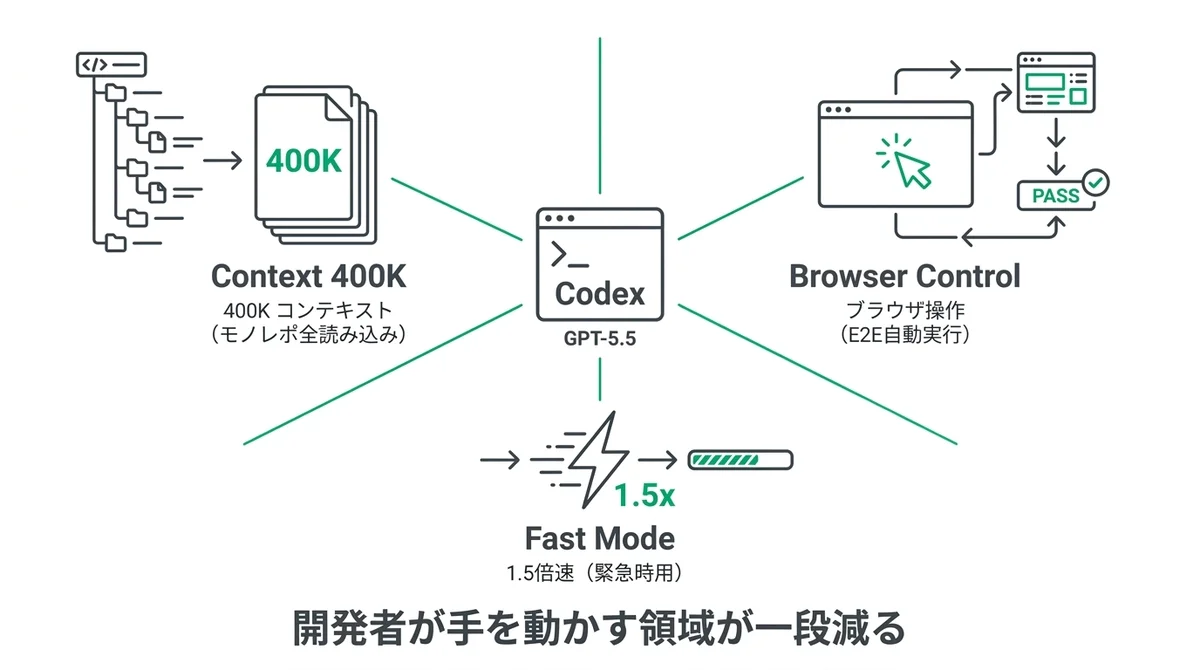
400Kコンテキストウィンドウの実務的意味
まず拡張されたコンテキストの話です。
Codex経由では400Kコンテキストウィンドウ、API経由では最大1Mトークンまで拡張されています。
モノレポで複数サービスのコードを一気読みさせたい、長いマイグレーション履歴を読ませたい、といったシーンで効きます。
自分の在庫管理システム(Rails 8 + Hotwire構成)で試した感触だと、アプリケーション全体のコード+スキーマ+主要テストをほぼ一発で読ませられる規模感です。
Claude Code(Opus 4.7時点)でも十分広いコンテキストを持ってますが、「repo全体+過去PR履歴」までまとめて投入できるのは強みです。
長文コードベースを対象にした仕様変更・リファクタ提案では、GPT-5.5+Codexの組み合わせが使いやすくなったと言えます。
ブラウザ操作機能とE2Eテスト自動化への応用可能性
個人的に今回一番ワクワクしたのはここです。
Codexがブラウザを操作して、Webアプリをクリックして、スクリーンショットを取って、テストフローを実行できるようになりました。
想像してみてください。
毎回Chromeを立ち上げて、ログインフォームに認証情報を入力して、目当ての画面まで遷移して、フォームを埋めて、挙動を確認して……この「手動E2E確認」、自分は地味にストレスが溜まる作業の筆頭だったんですよね。
バックエンドのロジックを直すのはClaude Codeで爆速で終わるのに、「それが画面で本当に動くか」の確認だけが手動で残る。そのたびにブラウザを触る、という非対称さが気になっていました。
そこにCodexのブラウザ操作が入ってくる。
この「手動E2Eテスト相当の動作確認」をCodexが巻き取れるなら、テスト駆動AI開発の守備範囲が一気に広がります。
自分のワークフローだと、テストコード設計→バックエンド実装(Claude Codeで高速に書ける)→E2E動作確認(GPT-5.5+Codexに任せる)という分業が成立しそうです。
エンジニアが手を動かさなくていい領域がまた一段広がる——そういう更新です。
もちろん、まだ実戦投入して数日なので「本当に安定するか」は検証が必要です。
ただ、方向性としては明らかに「コードを書かないエンジニア」の武器が増える更新だと見ています。
今夜試すなら、まずCodexに「このページのログインフローをブラウザで動作確認して」と投げてみてください。どこまで動くか、自分の手で確かめてみる価値があります。
Fastモード(1.5倍速・2.5倍コスト)の使いどころ
Codexには新たにFastモードが追加されました。
スペックは1.5倍速・2.5倍コストです。
コスパだけ見ると明らかに悪化なんですが、使いどころはハッキリしています。
- クライアントMTG直前に動くデモが必要なとき
- 本番障害対応で一刻も早く原因切り分けしたいとき
- 小さな修正をとにかく速く試したいとき
逆に、夜間バッチ的に長時間回すタスクや、雑多な調査作業には標準モードで十分です。
「自分の時間単価」と「APIコスト」を比較して、時間価値が勝る局面で使うのが正解ですね。
GPT-5.5のAPI料金が2倍に:「fewer tokens」で実コストはどう変わるか
さて、一番ザワついているトピック、料金です。
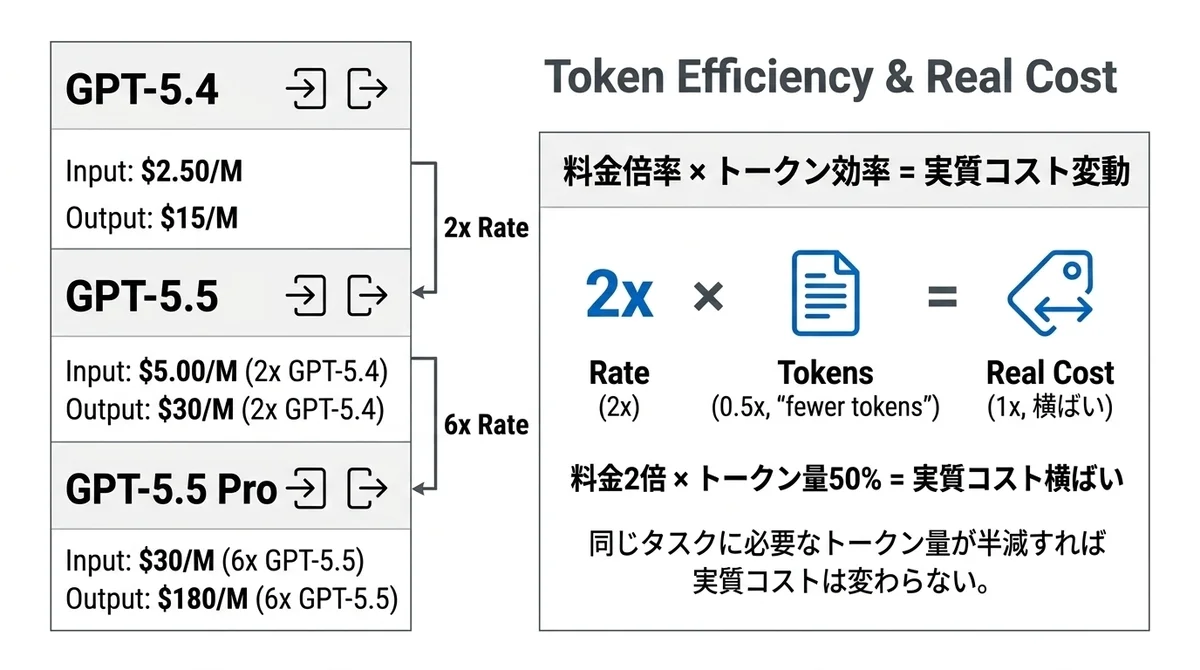
GPT-5.4との料金比較表
まず数字を並べます。
素直に2倍です。
月末のAPI請求書を開いて「あれ、先月より増えてる」と気づいた経験、ありませんか。
API料金って積み上がるまで気づきにくいので、「2倍」というのは思ったより大きいインパクトになりえます。
自分も最初に料金表を見たとき「えっ、そのまま2倍乗せる感じ?」とSlackで独り言をつぶやきました。
「fewer tokens」発言をコスト試算で検証
ただ、Greg Brockmanさんは発表で「fewer tokens」を強調しています。
これが本当なら、単純な2倍ではなく「同じタスクを完了するために必要なトークン数」が減るので、ネットコストは必ずしも倍にならない、という話です。
ここを自分なりに試算してみます。仮に同じタスクの完了に必要なトークン量が、GPT-5.4に比べて以下のように変化したとします。
- パターンA: トークン量60%(=40%減) → 実質コスト比: 2.0倍 × 0.6 = 1.2倍
- パターンB: トークン量50%(=半減) → 実質コスト比: 2.0倍 × 0.5 = 1.0倍(つまり同額)
- パターンC: トークン量40%(=60%減) → 実質コスト比: 2.0倍 × 0.4 = 0.8倍(安くなる)
トークン量が半減するならコスト横ばい、6割減なら値下げ相当になります。
逆に言えば「同じトークン量で同じタスクを解く」なら、そのまま倍額の負担になる。
ここで実務的な話をすると、トークン効率が本当に改善されているかはワークロードによってブレます。
短い単発質問なら効率改善の恩恵は小さく、長いマルチターン会話や複雑なコード生成では効く可能性が高い。
自分のおすすめは、採用判断の前に必ず自分の代表的ワークロードで1週間ほど併用テストを回すことです。これやらずに決めると、絶対後悔します。
GPT-5.5 Pro(入力$30/M)の対象ユースケース
GPT-5.5 Proの入力$30/M・出力$180/Mはかなり高価です。
GPT-5.5の6倍ですからね。
これが刺さるユースケースは限定的で、自分の見立てでは以下の3つです。
- 法務・会計・金融の高精度ドキュメント解析(誤りが許容されない案件)
- 医療・製薬の文献調査・一次情報読解
- 大規模研究開発のコアループ(失敗コストが極めて高い)
逆に、一般的な受託開発・SaaS開発では標準のGPT-5.5で十分で、Proを恒常的に回すのはROI的に厳しいと思います。
クライアントMTG前の最終チェックだけProを使う、みたいなスポット運用がバランスいいです。
導入事例から見るGPT-5.5の実力:数学教授11分アプリとBank of New York
ベンチマークの数字だけだと現実感が薄いので、発表会で紹介された事例2つを紹介します。
数学教授が単一プロンプトで代数幾何アプリを11分で構築
ある数学教授が、代数幾何のインタラクティブなアプリを単一プロンプトで11分で構築した事例がOpenAIから紹介されました。
11分って、どれくらいの感覚かというと——コーヒーを淹れて、一口飲んで、「あ、できてる」くらいの時間です。
自分も似たことを在庫管理システム開発で感じていて、「仕様を1発でドンと渡すと、下手に対話するより遥かに速く動くものが返ってくる」んですよね。
プロンプト設計が上手ければ上手いほど、この「単発プロンプト完結」の恩恵はデカい。
GPT-5.5は、仕様がすでに頭の中で固まっている人ほど強く使える道具です。
逆に仕様が曖昧なまま投げると、それっぽく動くけど的外れなものが出てくる。これはどのフロンティアモデルでも共通ですが、GPT-5.5はより「仕様に忠実に一発完結させる」方向に振られている印象があります。
Bank of New York「hallucination resistance」発言の意味
もう1つがBank of New York(BNY)のCIOのコメントです。
「impressive hallucination resistance(印象的なハルシネーション耐性)」「step change(段階的進化ではなく階段状の飛躍)」という言葉が使われていました。
BNYは220以上のAIユースケースを社内で管理している金融大手です。
金融業界は規制が厳しく、ハルシネーション(誤情報生成)が1件でも致命的になる業界。そこでこの評価が出たのは、地味に大きいです。
MagicPath CEOのPietro Schiranoさん(外部テスター)も「It genuinely feels like I'm working with a higher intelligence(本当に高次の知能と一緒に仕事している感覚)」というコメントを出しています。
賛否ある表現ですが、少なくとも「単なる言い換えマシン」から一歩踏み込んだ、という感覚は信頼していいのかもしれません。
ハルシネーション許容度が低い案件(法務・金融・医療・監査レポート系)では、GPT-5.5が採用検討候補に入りやすくなったと言えます。
Claude Opus 4.7もこの領域は強いですが、選択肢が増えるのは発注側にもエンジニア側にも嬉しい変化ですね。
Claude CodeユーザーとしてGPT-5.5をどう位置付けるか:使い分けの正解
最後に、自分の現時点での結論を正直に書きます。
今すぐClaude CodeからGPT-5.5に乗り換えるべきか
結論から言うと、乗り換えません。
自分はClaude Code(Opus 4.7)を引き続きメインで使います。
理由はシンプルで、SWE-Bench Proで5.7ポイントの差があるからです。
実務で一番時間を使うのは「既存コードベースにパッチを当てる」作業で、ここの精度がClaudeのほうが高い以上、メインを変える理由はありません。
ちなみにChatGPTの週間アクティブユーザーは9億人以上、サブスクライバー5000万人以上、有料ビジネスユーザー900万人以上、Codex利用者は400万人以上とされています。
数字だけ見ると圧倒的ですが、個人のエンジニアとしての選択は、シェアではなく自分のワークロードで決めるべきです。
この記事の読者の方も、流行りに流されず自分の代表タスクで測ってほしいです。
併用するならどう役割分担するか
一方で、GPT-5.5は確実に新しい使い道を持ってきています。
自分の現時点の役割分担案は次です。
- Claude Code: コード生成・リファクタリング・OSSコントリビュート・既存コード読解(メイン作業の8割)
- GPT-5.5 + Codex: ブラウザ操作込みのE2E検証・長時間エージェントタスク・GDPval系の知識労働(2割)
- GPT-5.5 Pro: 法務文書レビュー・金融ドキュメント解析(スポット)
この比率は自分の案件構成前提なので、読者のみなさんは自分のタスク構成に合わせて調整してください。
たとえばE2Eテスト自動化の割合が多いプロジェクトならGPT-5.5の比率が上がるし、純粋なバックエンド実装中心ならClaude Codeの比率が上がる。
6ヶ月後に起こりそうな変化
予想も書いておきます。
- Anthropicの対抗アップデート: Claude Opus 4.8(または5.0)が出てきて、Terminal-Bench系のスコアを伸ばしてくる可能性が高い
- OpenAIのsuper app構想: ChatGPT + Codex + AIブラウザ統合が進み、「エディタを開かずにAIだけで仕事する」層が増える
- 料金競争: 半年後には「トークン効率で勝負する」ことが業界標準になり、$30/Mなどの出力価格はコモディティ化する
今急いで全面移行する必要はない、というのが自分の見立てです。
まずは併用、数ヶ月使って代表ワークロードのデータを貯めて、それから最適比率を再計算する。これが一番損しない進め方だと思います。
まとめると、GPT-5.5は「コードを書く精度ではClaude Opus 4.7に及ばない」一方で「ターミナル・ブラウザ操作とエージェント自律実行では明確に優位」という位置付けです。
料金2倍も「トークン効率の改善で相殺されるかどうか」を自分のワークロードで検証してから判断すべきで、ベンチマーク数値だけで決めるのは早計です。
自分はまずはCodexのブラウザ操作から日常的に試して、2週間後くらいに改めて役割分担を見直す予定です。
今夜5分だけ試すなら、codex --model gpt-5.5 で普段Claude Codeに投げている代表的なバグ修正を1件投げてみてください。それが一番手っ取り早い比較になります。比べてみて初めて「自分の仕事にどう効くか」の肌感がつかめます。
エンジニアにとって一番信頼できるベンチマークは、自分の代表タスクでの使い心地だけです。
それではまた。
- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 34
- 1
-
- 25
- 1
-
- 10
- 1
-
- 8
- 0



こちらもおすすめ
-
- 1
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 1
- 0
-
- 3
- 0
-
プロンプト画伯
- 1
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
AI脱社畜
- 2
- 0
-
- 2
- 0
-
- 2
- 0
-
- 1
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 1
- 0
-
- 2
- 0
-
クロージング師匠
- 1
- 0
-
- 3
- 0
-
 たく
たく
- 3
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 1
- 0


















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます