こんにちは。もるふぉです。
Claude Codeをローカルや小さなプロジェクトで触っていて「これはすごい」と感じた人ほど、いざ大規模コードベースやチームに広げようとした瞬間に、ある違和感にぶつかります。
「個人で動かしているときの賢さが、組織のコードベースでは出ない」
数万行のリポジトリではあれだけ的確だったClaudeが、モノレポに繋いだ瞬間に的外れな提案を始める。
ファイルを5個も読まないうちに「もう十分です」と言いたげな顔をする。
CLAUDE.mdをルートに書き足していくと、なぜか指示の遵守率が下がっていく。
これ、現場で見ている範囲ではかなり一般的な現象です。そしてここがポイントなんですが、原因はモデルの賢さではありません。
Claude Codeをコードベースに繋ぐ「土台のつくり」の問題なんです。
ちょうどこのテーマを正面から扱った記事を、Anthropicが公開していました。「How Claude Code works in large codebases: Best practices and where to start」というタイトルで、Claude Code at scaleシリーズの一本として公開されています。
この記事が良かったのは、「CLAUDE.mdをこう書け」みたいなTips集ではなく、Claude Codeがそもそもどうコードを読んでいるのか、そしてどの拡張点に投資すれば組織で効くのかという、設計レイヤーの話を書いている点でした。
ここでは、その記事で示された設計思想と、私が複数の案件で観測してきた「ハマりポイント」を混ぜながら、大規模コードベースでClaude Codeを使いこなすための全体像を解説していきます。
Claude Codeはどうコードを読むのか — agentic searchがRAGより速い理由
まず最初に、ここを押さえないと後段の話が腹落ちしません。
Claude Codeは、皆さんがイメージしているのとはおそらく違う方法でコードを読んでいます。
「コードを検索する」のではなく「コードを歩く」アプローチ
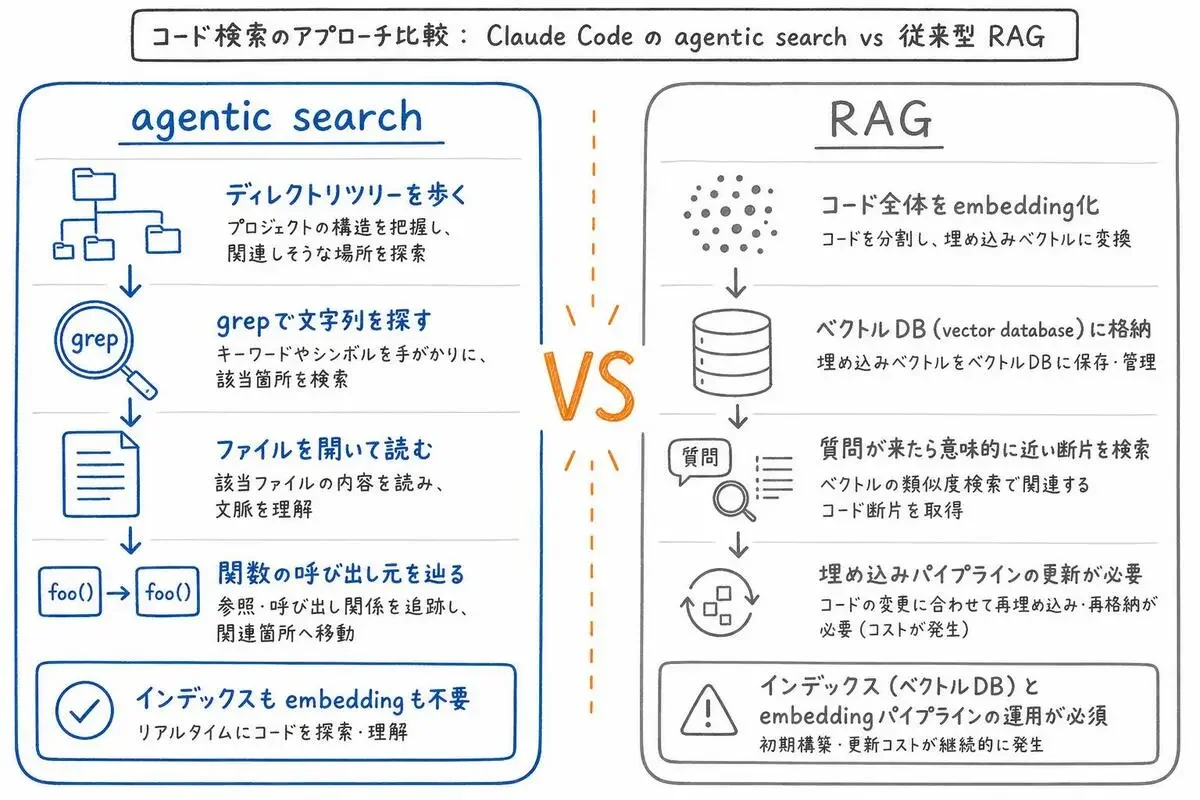
LLMをコードベースに繋ぐ実装と聞いて多くの人がまず思い浮かべるのは、RAG(Retrieval-Augmented Generation)です。コード全体をembeddingにしてベクトルDBに入れておき、質問が来たら意味的に近い断片を引っ張ってきてモデルに渡す、あの仕組みです。
Claude Codeは、これをやっていません。
Claude Codeが採用しているのは「agentic search」と呼ばれるアプローチです。具体的には、人間のエンジニアが新しいリポジトリに入ったときと同じことをやります。
- ディレクトリツリーを眺める
- ファイル名から当たりをつけて開く
grepで関係しそうな文字列を探す- 見つけた関数の呼び出し元を辿る
- 必要があれば隣のファイルも開く
これだけです。embeddingも、ベクトルDBも、インデックスも作りません。
この差は、最初は地味に見えます。でも大規模コードベースでは、これが決定的に効いてくるんです。
RAGの埋め込みパイプラインで詰む3つのケース
RAGには、コードに使うときに構造的に困るポイントがあります。私の観察では、これは3つに整理できます。
ひとつ目は、埋め込みパイプラインが追いつかないケース。コミットのたびにembeddingを更新する仕組みを組んでも、大規模リポジトリだとパイプラインが詰まる。結果、2週間前にrenameされた関数を、古い名前のまま返してくる、なんてことが起きます。
ふたつ目は、検索精度の問題。コードの意味的類似度は、自然言語ほど素直ではありません。「認証まわり」で検索すると、auth以外にも「checkout」や「subscription」が混ざって出てくる。RAGの精度を上げようとすると、再ランキングやら何やらを足すことになって、システムが重くなっていきます。
みっつ目は、機密データの扱い。コードをembeddingに変換して外部に出す前提自体が、エンタープライズだと話が複雑になります。
agentic searchは、このどれも踏みません。なぜなら、その場でファイルを開いてgrepして読むだけだからです。
しかも、Claude Code自身が「次にどのファイルを開くか」を毎回判断します。質問の文脈に合わせて読む対象を変えられるので、RAGの「あらかじめ仕込んだインデックス」よりも柔軟なんです。
起点コンテキストが薄いと急に弱くなる、という弱点
ただし、agentic searchには弱点もあります。これも知っておかないと、後で「あれ、Claudeが急にバカになった」と感じることになります。
agentic searchは、起点のコンテキストが薄いと急に弱くなります。
エンジニアの探索を想像するとわかりやすいです。「このリポジトリ、認証はどこ?」と聞かれたとき、まずauth/というディレクトリ名があれば誰でも当たりをつけられます。でも非標準的なディレクトリ構成で、認証ロジックがplatform/services/identity_v2/の下にあったら、最初の一手がそもそも踏み出せません。
Claude Codeにとっての「起点」を作るのが、まさに次に話すハーネスなんです。ここがミソなんですが、agentic searchの賢さは、ハーネスの作り込みによって決まる、と言っていいくらいの相関があります。
ここからが本題です。次は、そのハーネスの中身を見ていきます。
モデルよりハーネスが効く — Claude Codeを支える5つの拡張点
元記事のいちばんの主張がここです。
The Harness Matters as Much as the Model(ハーネスはモデルと同じくらい重要だ)
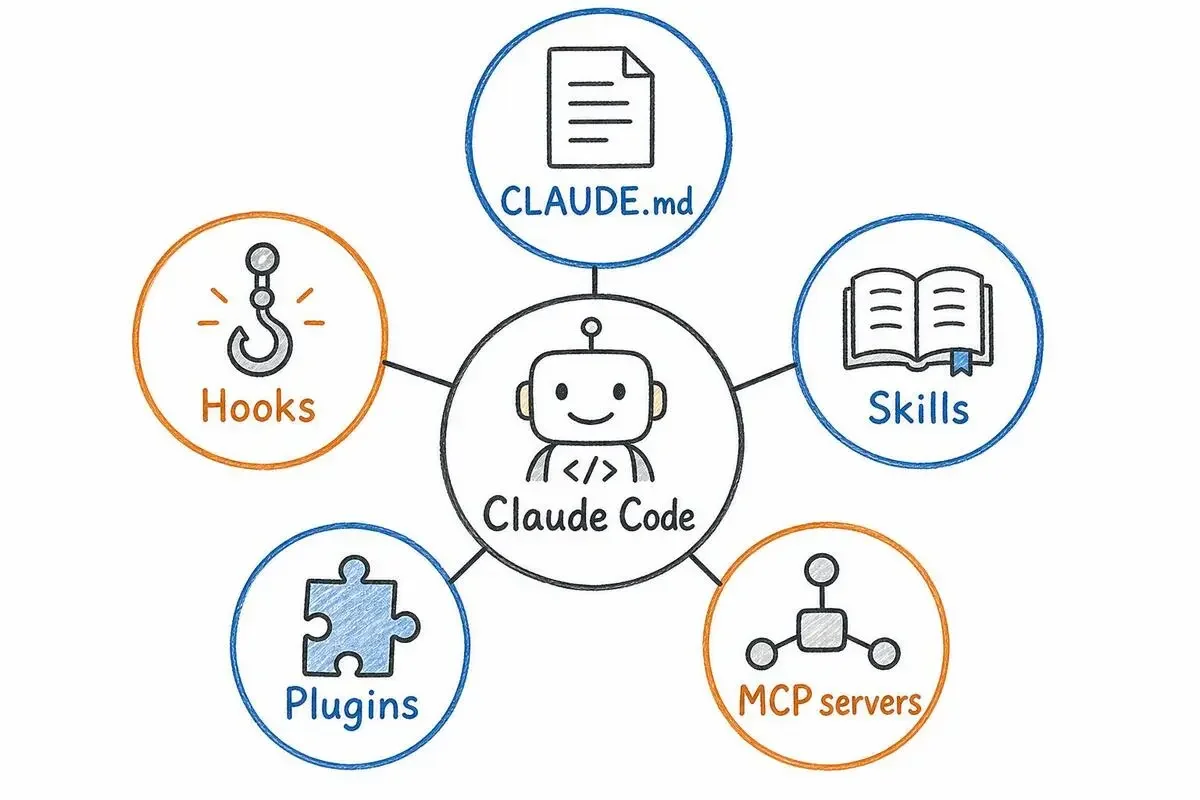
「ハーネス」というのは、Claude Codeをコードベースや組織に繋ぎ込むための拡張点の総称です。馬具の「ハーネス」と同じ意味で、強力なモデルを実用的な仕事に向ける装具、というニュアンスです。
Claude Codeのハーネスは、5つの拡張点で構成されています。それぞれが「何を担い、どこで効くか」を整理してみます。
CLAUDE.mdここから5つを順に見ていきます。
CLAUDE.md — セッションごとに必ず読まれる基礎ファイル
CLAUDE.mdは、Claude Codeが起動時に必ず読み込むファイルです。プロジェクトのルートに置けばリポジトリ全体に効きますし、サブディレクトリに置けばその配下に効きます。
ここがポイントなんですが、Claudeはディレクトリ階層を上に登りながら、見つかったCLAUDE.mdを全部「足し算」で読みます。重ねがけです。
なので大規模コードベースでは、こういう設計になります。
- ルートの
CLAUDE.md: 全体に効く「大局のガイダンス」のみ。100行以下が目安 - サブディレクトリの
CLAUDE.md: そのパッケージ固有の規約、ビルドコマンド、依存関係の制約
書き方の方針は「lean & layered(薄く・階層的に)」です。ルートに何でも書き込むと、後段で説明する「肥大化問題」を踏みます。
Hooks — 「予防」より「継続的改善」のための道具
Hooksは、Claude Codeのセッションのイベント駆動スクリプトです。具体的には、セッションの開始時・終了時・特定のツール実行時に、任意のシェルスクリプトを発火させられます。
最初に思いつく使い方は、lintやformatの強制でしょう。Claudeが書いたコードに対して、Stop hookで自動的にprettierとeslintを走らせる。これは予防的な使い方です。
でも、現場で見ている範囲では、もっと効くのは「継続的改善」の文脈です。
- Stop hookで「今回のセッションで
CLAUDE.mdに追加すべき発見はあったか」をClaude自身に提案させる - Start hookで、その日のチーム固有のコンテキスト(バグチケットのリスト、進行中のレビュー)を動的に読み込ませる
Hooksを「自動チェッカー」だけに使うのはもったいないんです。「セッションのたびにチームのナレッジを少しずつ太らせる仕組み」として使うと、Claude Codeが組織のインフラに育っていきます。
Skills と Plugins — 知識をオンデマンドで供給する仕組み
Skillsは、必要なときだけ読まれる専門知識のパッケージです。CLAUDE.mdは毎回読まれますが、Skillsは「タスクの内容によって、必要な知識だけが引き出される」という点が違います。これを公式は「progressive disclosure(段階的な開示)」と呼んでいます。
たとえば「セキュリティレビュースキル」を作っておくと、セキュリティ関連のタスクのときだけそれがアクティブになる。普段は読み込まれません。これでCLAUDE.mdが肥大化せずに済むわけです。
Pluginsは、Skills・Hooks・MCPサーバ設定をひとつにまとめた配布パッケージです。社内向けの「managed marketplace」を立てれば、承認済みのpluginだけを配布する、というガバナンスができます。
私の観察では、SkillsとPluginsの違いを「機能の違い」だと捉えると混乱します。そうではなく、「知識のスコープ」の違いとして見るとスッキリします。Skillsは1つの知識単位、Pluginsはそれらをチームに配るための器、です。
MCP servers — 構造化された情報源とのつなぎ
MCP servers(Model Context Protocol)は、Claude Codeを内部ツール・データソース・APIに繋ぐための5番目の拡張点です。

社内のIssue管理、メトリクスDB、デプロイパイプラインみたいな構造化された情報源に、Claudeから「検索ツール」として呼び出させます。agentic searchがgrepで歩けるのはファイルシステムだけですが、MCPサーバを立てることで、コードベースの外にある構造化データにも同じ感覚でアクセスできるようになる。
これが、RAGに頼らずに「構造化された世界への窓口」を実現する方法です。
5つの拡張点の外側にある追加ケイパビリティとして、LSP統合とSubagentsが元記事に登場します。
LSP統合は、pluginレイヤー経由で導入される強力な補助機能です。agentic searchの基本動作はgrepですが、grepには限界があります。「getUserByIdという関数の定義はどこ?」と聞いたとき、grepは文字列マッチしかしないので、同名の関数が複数あれば全部ヒットします。数千件マッチした、なんてことが普通に起きます。
LSP(Language Server Protocol)統合を入れると、Claudeは「シンボル単位」の検索ができるようになります。「UserRepositoryインターフェースの実装一覧」みたいな、grepでは不可能な検索です。
サブエージェント(Subagents)は「拡張点」ではなく「委譲機能」です。独立したコンテキストウィンドウを持つClaudeインスタンスで、タスクを受け取って処理を完遂し、最終結果だけを親に返します。親セッションのコンテキストを汚さずに、別の文脈で作業を完遂してくれる使い方に向いています。たとえば「このサブシステム全体をmapしてfileに書き出して」みたいな探索タスクをメインセッションから切り離す、といった用途です。
サブエージェントは便利ですが、注意点があります。並列探索する分、トークン消費が単一スレッドの何倍にもなることがある。「とりあえずサブエージェント」は財布に優しくないので、コンテキスト分離が本当に必要なときに絞るのがコツです。
ここまでが5つの拡張点と追加ケイパビリティの全体像でした。ただ、これを「知っている」のと「現場で機能させる」のはまた別の話です。次は、大規模コードベースでハマる具体的なポイントを見ていきます。
大規模コードベースでClaude Codeがハマる5つのポイント(実装の現場感)
ここからが、たぶんいちばん読みたいパートです。
公式記事が「べき論」レベルで触れている設定を、実装者目線で「やらないとどうなるか」に翻訳します。複数の案件で観測した内容なので、当てはまるものから先に対処してください。
1. CLAUDE.mdをルートに集約すると性能が落ちる
これ、けっこう詰みます。
ルートのCLAUDE.mdに「あれもこれも」と書き足していくと、ある閾値を超えたところから、Claudeが指示を雑に扱い始めます。具体的には、最初の方に書いた規約は守るが、後ろの方の指示は無視する、みたいな挙動です。
原因はシンプルで、CLAUDE.mdは毎セッション必ず読まれるので、ここが膨らむと「すべての会話のコンテキスト予算」が常に圧迫されるからです。指示が多いほどモデルの注意が分散して、全体の遵守率が下がる、というメカニズムが効いてきます。
対策は、元記事にも書かれている通り「ルートから全体を見渡すのではなく、作業対象のサブディレクトリにスコープを絞って起動する」ことです。リポジトリ全体に効くべきルールだけをルートに置き、パッケージごとの規約はそのパッケージのディレクトリに置いたCLAUDE.mdに書く。Claude Codeはディレクトリ階層を登りながら読むので、これで「必要な場所で、必要な規約だけ」が効く状態が作れます。
2. テスト・ビルドコマンドのスコープを切らないとタイムアウト連発
モノレポでありがちなのがこれです。
CLAUDE.mdに「テストはnpm testで実行」とだけ書くと、Claudeはリポジトリルートからモノレポのテストをまとめて走らせようとします。大規模モノレポではこれが数十分かかって、たいていタイムアウトします。
対策は、CLAUDE.mdにビルド・テストコマンドを書くときに、「このパッケージのスコープでだけ走らせる」という制約を必ず添えることです。
サブディレクトリのCLAUDE.mdに書く例を出すと、こんなイメージです。
# packages/auth/CLAUDE.md
build_command: "pnpm --filter @org/auth build"
test_command: "pnpm --filter @org/auth test"「ルートから走らせない」ことを明示しないと、Claudeは素直にルートから走らせます。ここはClaudeが悪いというより、指示が雑なんです。
3. 「grep汚染」を防ぐ .ignore と .claude/settings.json
agentic searchがgrepに依存しているので、grepの結果がノイズだらけだとClaudeは混乱します。
大規模コードベースでgrepを汚すのは、たいてい3つです。
- ビルド成果物(
dist/、build/、.next/) - 自動生成コード(protobufから生成された
.pb.go、GraphQLのcodegen成果物) - third-party依存(
node_modules/、vendor/、Pods/)
これらを.ignoreファイルや.claude/settings.jsonの除外設定に入れておかないと、getUserByIdを探したつもりが、生成コードとvendor/内のコピーが大量にヒットして、本物のソース定義が埋もれます。
私の観察では、これをやっていないチームほど「Claudeが見当違いのファイルを開く」と感じています。原因は半分くらいこれです。
4. 非標準ディレクトリ構成にはcodebase mapを置く
agentic searchの弱点である「起点コンテキストの薄さ」が、もっとも露骨に出るのがこのケースです。
たとえば、認証ロジックがauth/じゃなくてplatform/services/identity_v2/の下にある。ドメインロジックがdomain/じゃなくてcore/business/にある。こういう非標準構成だと、Claudeは最初の一手で迷子になります。
対策は、リポジトリのトップにCODEBASE_MAP.mdのようなmarkdownを置いて、「どの機能がどのディレクトリにあるか」を一覧化しておくこと。50行程度の短いmapで十分です。Claudeはこれを「最初に読む地図」として参照します。
「自分が書くんじゃなくて、Claudeに書いてもらえばいい」のが、ここの面白いところです。サブエージェントに「このリポジトリの構造をmapしてCODEBASE_MAP.mdを書いて」と頼めば、初回のmapがすぐ手に入ります。あとはチームで磨いていくだけです。
5. LSP統合をしないと「同名関数が数千件」で詰む
さっき触れた話の繰り返しになりますが、ここは独立した「ハマりポイント」として強調しておきたいんです。
C++のレガシーコードベースとか、TypeScriptでhandleという名前のハンドラ関数が500個あるNext.jsプロジェクトとか、Goのインターフェース実装が分散しているmicroservicesとか。こういう環境でLSPなしのClaude Codeを使うと、grepが文字列マッチしかしないせいで、ノイズだらけのリストがClaudeに渡ります。
LSP統合を入れると、Claudeは「型情報を持ったシンボル検索」ができるようになります。「UserRepositoryインターフェースの実装一覧」みたいな、grepでは不可能な検索です。
これ、入れるかどうかで「Claudeの賢さ」が体感で1段階変わります。元記事のエンタープライズ事例で「Claude Code展開前にLSP統合を全社展開した」というのは、これを経験した会社が出した投資判断なんだろうな、と思います。
5つ並べてみると気づきますが、ここまでの話の大半は「Claude Codeに見せる景色をきれいに整える」ことです。ハーネスというのはそういう仕事なんです。次は、その景色が時間とともに古くなる問題を扱います。
モデル進化に合わせてCLAUDE.mdを書き換え続ける
ここ、地味に重要なポイントです。
CLAUDE.mdは「書いたら終わり」じゃありません。モデルの世代が変わるたびに、見直す必要があります。
「古いモデル向けの制約」が新モデルの足を引っ張る
具体例を出します。
少し前のモデルは、複数ファイルにまたがる編集が苦手でした。1回のレスポンスで複数ファイルを編集させると、整合性が崩れることがあった。なのでチームのCLAUDE.mdに「1セッションで編集するファイルは1つに絞れ」というルールを書いていた、としましょう。
これは、当時は正しいルールだったんです。
ところが新世代のモデルは、クロスファイル編集が驚くほど上手くなっています。それなのに古いルールがCLAUDE.mdに残っていると、新モデルの強みを自分から潰すことになる。「クロスファイル編集して」と頼んでも、ルールに従って1ファイルずつ直そうとする、みたいな状態です。
これは「制約のついた優秀な人」を採用しているような状況で、もったいないんです。
「性能が頭打ちに見える」ときに最初に疑うこと
元記事に、いい指針が書かれていました。
メジャーモデル更新後にパフォーマンスが頭打ちに見えるときが、設定見直しのサインです
新しいモデルがリリースされて、世間では「賢くなった」と評判なのに、自分のチームでは大して変わっていないと感じる。
このとき疑うべきは、モデル本体ではなく、ハーネス側の制約です。古いルール、古い.claudeignore、古いhooks、古いskills。これらが新しいモデルの足を引っ張っている可能性が高い。
目安としては、3〜6ヶ月ごとにCLAUDE.mdとskills全体を見直す。新モデルのリリース直後は特に集中して見直す。これだけで、「モデル進化のメリットを取りこぼさない」状態が維持できます。
設定ファイルは資産であると同時に、負債にもなります。古い制約を捨てる勇気も、大規模運用ではけっこう重要なんです。
組織サイズ別「Claude Code、どこから始めるか」
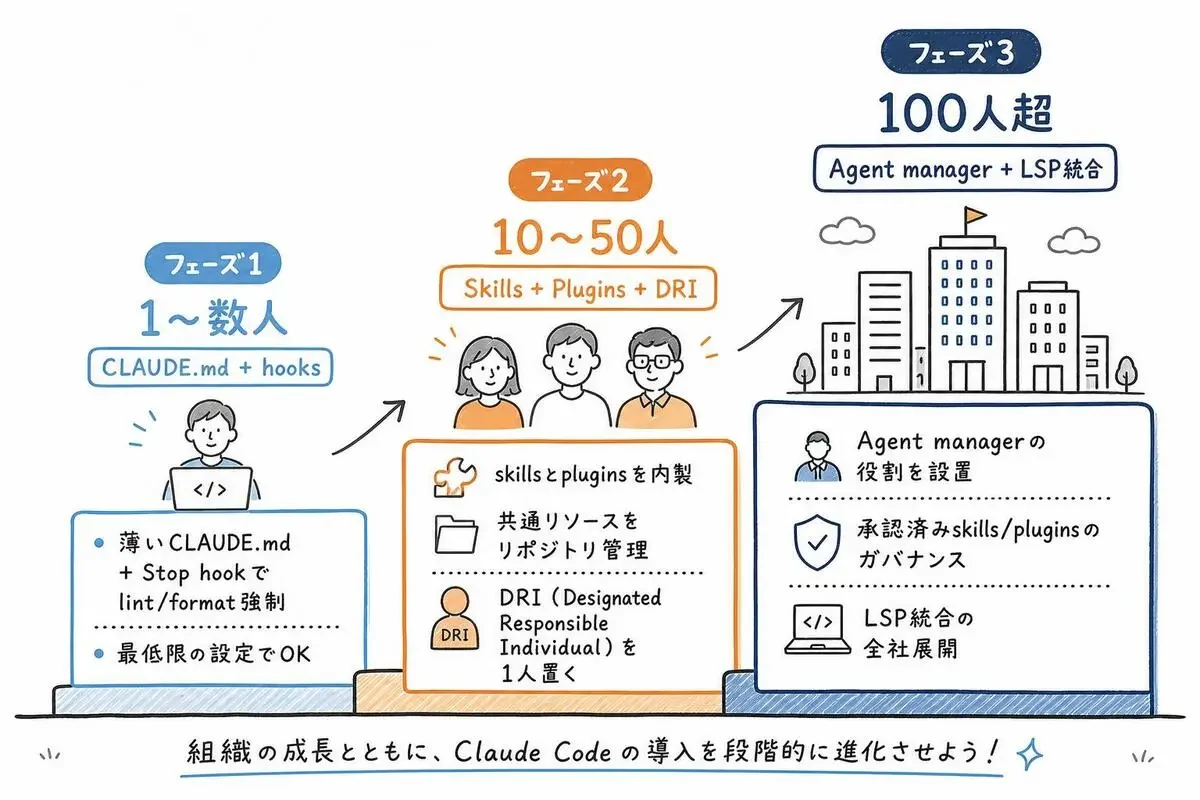
ここまでの話を、組織のサイズ別に「実際に何から始めるか」に落とし込みます。元記事も組織サイズへの言及はありますが、具体的なステップまでは踏み込んでいません。私の観察ベースで翻訳しておきます。
一人〜数人: CLAUDE.mdとhooksだけで十分回る
この規模なら、凝った設定は不要です。
最低限やるべきは2つだけ。
- ルートに薄い
CLAUDE.mdを1枚書く。プロジェクトの概要、よく使うコマンド、避けたい操作を箇条書きで - Stop hookで
prettierとeslintを強制する程度の自動化を入れる
サブエージェント・MCP・LSP・Pluginsはあとで考えればいい。最初に大事なのは「習慣として使い続ける」ことなので、設定の凝りすぎは逆効果です。
10〜50人のチーム: skillsとpluginの内製を始める
この規模になると、チーム内のばらつきが課題になってきます。
「Aさんが使うClaudeは賢いが、Bさんが使うClaudeはイマイチ」みたいな状況です。原因はだいたい、各自のCLAUDE.md設定や.claude/配下のローカル設定が違っているからです。
対策は2つです。
- 共通のskillsをリポジトリ管理する。コードレビュー用、テスト生成用、リファクタ用、みたいに用途別に切る
- それらをPluginとしてパッケージし、社内のmanaged marketplaceで配布する
「DRI(Designated Responsible Individual、専任担当者)」を1人決めるのもこの段階です。Claude Codeの設定を「みんなで触る」状態にすると、誰も触らなくなります。1人がオーナーになって、変更レビューを通る形にする方が機能します。
100人超の組織: DRIを置き、レビュープロセスとガバナンスを設計する
この規模では、もはやインフラの一種として扱う必要があります。
元記事に印象的な指摘がありました。
成功している組織は「広く展開する前のインフラ投資」をしていた
つまり、いきなり全社展開ではなく、小規模なインフラチーム(1人〜数人)が事前にツーリングを整備してから、社内に広げていた、ということです。
具体的にやることは増えます。
- 「Agent manager」のような新しい役割を置く。PMとエンジニアのハイブリッドで、Claude Codeのチーム展開と運用を見る
- 承認済みskills・pluginsのリストを管理する仕組み
- 限定的な初期アクセス → クロスファンクショナル作業部会 → 全社展開、という段階的ロールアウト
- LSP統合の全社展開(型付き言語が中心ならこれは早めに)
元記事では、Zooxのエンジニアがフィードバックを提供したと書かれています。

LSP統合とSubagentsの設計が大規模コードベースへの早期投資として効く、という示唆だと読みました。
100人を超えると、もはや「個人がClaude Codeを使う」ではなく「組織がClaude Codeを使う」設計が必要になります。これは、CIやモニタリングやKubernetesと同じ、組織のインフラだと考えた方がいいです。
まとめ — 大規模コードベースでClaude Codeを「組織のインフラ」にするために
ここまでの話を、いちばん持ち帰ってほしいところに圧縮します。
Claude Codeが大規模コードベースで効くかどうかは、モデルの賢さではなく、ハーネスの作り込みで決まります。
そのハーネスは5つの拡張点で構成されていて、それぞれ役割が違います。
CLAUDE.mdの階層化これに加えて、LSP統合(pluginレイヤー経由で導入)とSubagents(委譲機能)が大規模コードベースでは特に効きます。
そして「どこから始めるか」は組織サイズで変わります。
- 一人〜数人:
CLAUDE.mdとhooksだけ - 10〜50人: skillsとpluginsの内製、DRIの設置
- 100人超: agent managerを置き、LSP統合とガバナンスを整備
最後に、私が現場で繰り返し感じていることをひとつ。
設定にコストをかけたチームほど、後半で楽になります。逆に「とりあえず使い始めて、設定は後回し」にしたチームは、半年後に「Claude Codeが期待ほど効いていない」と感じて、結局そこから設定の見直しに時間を割くことになる。
元記事のシリーズ名が「Claude Code at scale」なのは象徴的です。個人で使うClaude Codeと、スケールするClaude Codeは、別物です。
「個人のお供」から「組織のインフラ」へ。この移行を意識的に設計できているかどうかが、2026年のチーム開発で差を生むポイントだと、私は見ています。
最後まで読んでくれてありがとうございます。
よければXもフォローしてもらえると嬉しいです → X(@morphox_ai)
- 4
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
- 3
- 0
-
- 3
- 0
-
AI脱社畜
- 2
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます