
こんにちは。
もるふぉです。
「音声AIって、結局OpenAIが一番じゃないですか?」——正直、ここ1年ずっとそう思ってました。
OpenAI Realtime APIは速くて自然、でも料金が地味に重い。
Gemini Liveは安いけど会話の流れが少しぎこちない。
Metaの音声会話は「おまけ機能」。
そんな空気感の中、2026年5月12日にMetaがMeta AI Voice ConversationsとLive AIの本格展開を発表しました。
中身を見た瞬間、「あ、これで勢力図変わるかも」と思ったんです。
エンドユーザー向けは完全無料、かつ割り込み・言語切り替え・画像生成の同時実行まで持ってきた。
コードを書かない側の視点から、「何がどう変わるのか」「業務でどれを選ぶべきか」を整理します。
Meta AI Voice ConversationsとMuse Sparkとは何か
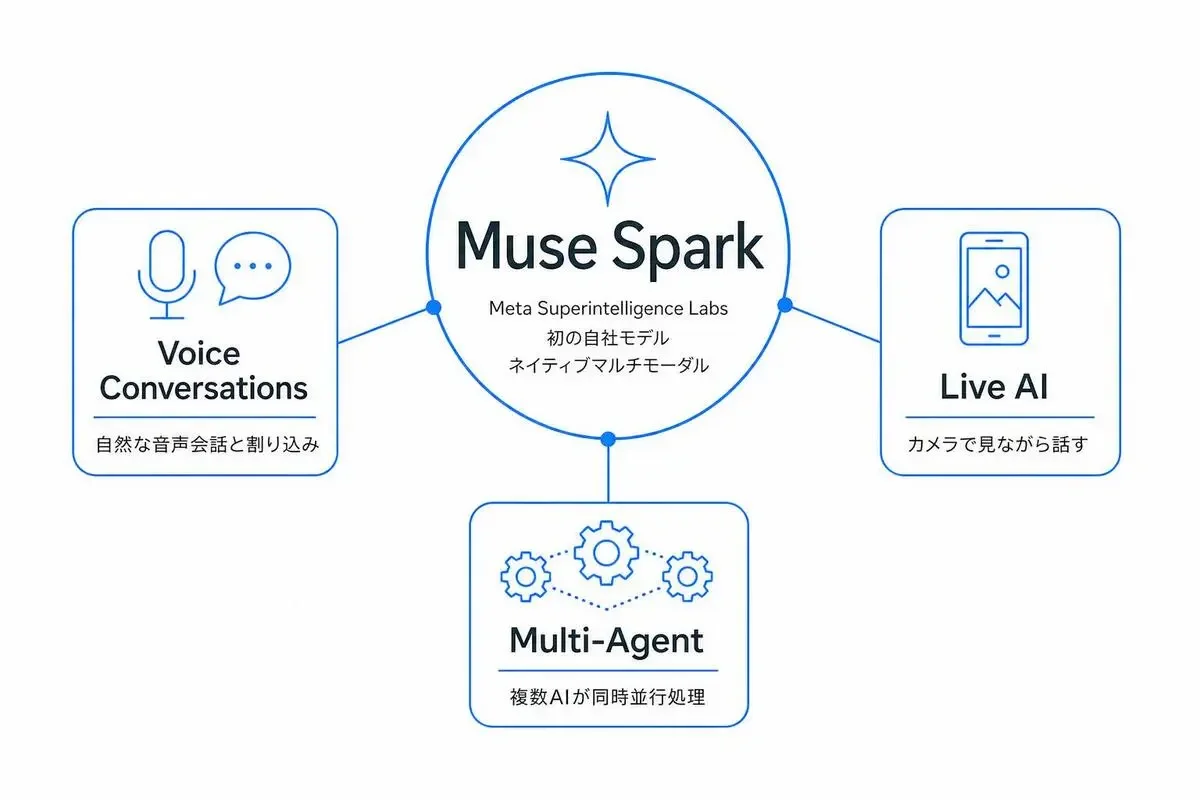
まずは「2026年5月12日に何が発表されたのか」を整理します。
「なんか発表あったらしいけど、Muse Sparkって何者で、Voice Conversationsって何が新しいの?」——そこをクリアにしてから比較に入ります。
Muse Sparkは何が「新しい」のか——前モデルからの根本的な違い
Muse Sparkは2026年4月8日に発表された、Meta Superintelligence Labs(MSL)による新シリーズの最初のモデルです。
前モデルからの違いを一言で言うと、「テキストを返す賢いやつ」から「見て、考えて、複数のサブエージェントを走らせるやつ」に作り直されました。
公式ブログでアピールされている特徴を、コードを書かない読者向けに翻訳するとこうなります。
- ネイティブにマルチモーダル——テキスト・画像・音声を「最初から一緒に学習」している。後付けで画像理解をくっつけたモデルとは中身が違う
- マルチエージェントが並列で動く——たとえば「フロリダ家族旅行の計画」を投げると、行程作成・地域比較・子ども向けアクティビティ検索を別々のエージェントが同時に進める
Contemplating modeという深く考えるモードがあり、GPTやGemini Deep Thinkに近い長考型推論ができる
Contemplating modeを業務視点に翻訳するとこういうことです。
「速さ重視の普通会話」と「少し待たせていいから精度を上げるモード」を、利用者側で切り替えられる。
「速さ vs 賢さのトレードオフを自分でコントロールできる」——これ、PoCをやる現場だと意外と効くんです。
普段の質問は瞬時に返って、本気の調べ物は少し時間をかけて深く考える。そのスイッチを自分で持てるのは、地味に嬉しい設計です。
これが今回の土台で、次がいよいよ5月12日に何が来たかです。
Meta AI Voice Conversationsで何ができるか——割り込み・言語切り替え・画像生成の同時実行
Meta AI Voice Conversationsの新しさを一言で言うと、「Muse Sparkに音声会話の皮をかぶせた」ところです。
公式発表ベースで、Metaが推している具体機能はこの3つです。
- 割り込み(Barge-In)——AIが話している途中で「あ、ちょっと違う」と被せて言うと、ちゃんと止まって聞き直してくれる
- 言語切り替え——会話の途中で日本語から英語に切り替えても話の流れが続く
- 画像生成・Reels・地図レコメンドの同時実行——会話しながら「その料理の写真出して」「近くの店を地図で」が同じセッションで返ってくる
3番目が、正直いちばんアツいと思いました。
GPT-4oのVoice Modeも音声会話として自然なんですが、「画像を生成して」「地図を出して」と言うと、別モードに切り替わる感覚がある。
Meta AIはこれを「同じセッションのなかで」やってくる。音声会話を中断せずに、画像出力・地図・Reels推薦が流れてくる。
会話のリズムを切らずにメディアを織り交ぜられる——これ、使ってみると「あ、全然違う体験だ」ってなるはずです。
ただし、誠実に書いておきます。
5月12日発表時点で、これらの機能は米国のMeta AIアプリとmeta.aiから順次ロールアウトされている段階で、日本での全機能利用はまだ限定的です。
「いま日本でも全部触れる」と書くと誤情報になるので、日本ユーザーは「順次広げます」のスケジュール次第と覚えておいてください。
Live AIとは——スマホカメラで「見ながら話す」体験がアプリに初展開
もうひとつの目玉がLive AIです。
「スマホのカメラを向けながら話しかけると、AIが見ているものを認識して答えてくれる」機能です。
街を歩いていて知らない建物が見えたとき、カメラを向けて「あれ何?」と話しかけるだけで答えが返ってくる。
家のなかで「この家電のここ、どこ押したらいいの」と聞けば、見たままに答えてくれる。
この機能、もともとはRay-Ban MetaなどのMeta AIメガネ専用機能でした。
今回はじめて、メガネを持っていない人でも手元のスマホで同じ体験ができるようになった——それがLive AI周りの一番大事な変化です。
「画像を撮ってアップロード→質問する」という従来の3アクションが「カメラ向けながら話す」1アクションに変わる。
家電のマニュアルを探さずに「これどこ押したらいい?」、料理の途中で「この野菜、これで合ってる?」が即座に聞ける。
メガネを買わなくても試せる——これが大きい。「いきなり数万円のメガネを買う前に、自分がLive AIを本当に欲しがるかをスマホで確かめられる」環境が整いました。
ここまでで「何が発表されたか」は揃いました。次は、なぜ「割り込みできる音声会話」が技術的に成立するのか、コードを書かない側の言葉で整理します。
Meta AI Voiceの技術背景——なぜ自然な割り込み会話が実現できるのか
割り込みできる音声会話と聞いて「いやそれくらい普通でしょ」と思った方、ちょっと待ってください。
実装側からすると、これはめちゃくちゃ難しいタスクです。
ここ数年でやっと「人間と話してる感じ」に近づいてきたエリアで、仕組みを知ると「あ、だからGPT-3.5時代のVoice Modeと体感が全然違ったんだ」と腹落ちします。
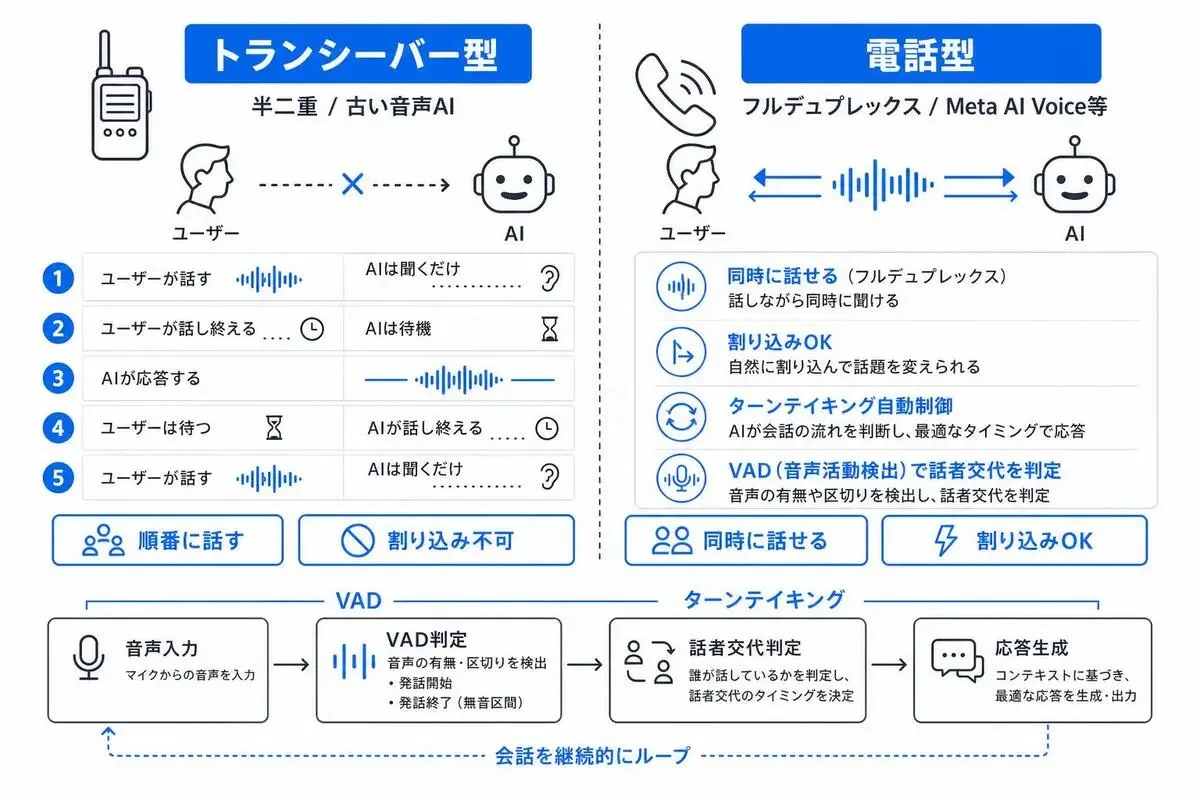
フルデュプレックス音声とVADの仕組み(コード不要で理解する)
まずフルデュプレックスという言葉です。
電話とトランシーバーの違い、と思ってください。
トランシーバーは「片方が話し終わるまで、もう片方は喋れない」。電話は「お互いが同時に喋れる」。これがフルデュプレックスです。
ChatGPTの初代Voice Modeは「トランシーバー型」でした。
ユーザーが話し終わってからAIが応答するので、被せて喋ろうとすると会話が崩れたんです。「あ、ちょっと待って」が言えないヤツだった、とイメージしてください。
最近の音声AI——GPT-4o Realtime API、Gemini Live、そしてMeta AI Voice——はみんなフルデュプレックス型を志向しています。
「電話型」にしているから、AIが話している途中でも「いや違う違う」と被せられる。
ここで重要になるのがVAD(Voice Activity Detection)、日本語で「音声活動検出」です。
VADは「いま音声ストリームに人間の発話が乗ったかどうか」を常時監視しています。
人間が話し始めた瞬間にVADが「発話開始」フラグを立てる→AIが自分の話を止める。これが割り込み(Barge-In)の基本構造です。
ただ、VADだけだと困った問題があります。
「ユーザーが0.5秒だけ言葉に詰まった」とき、ナイーブなVADだと「あ、終わったな」と判断してAIが喋り出してしまう。
「ちょっと待って、言葉考えてるだけなのに!」——そういう割り込まれ方、された覚えないですか? これです。
ここを解決するのがターンテイキング(turn-taking)モデルです。
ターンテイキングは「ユーザーが本当に話し終わったか」を、声の高さの変化(プロソディ)や文の完結度から推定する仕組みで、VADの上位レイヤーとして動きます。
Meta AI Voiceで「自然に割り込めるのに、こちらが詰まっても勝手に話し始められない」感覚があるとしたら、このターンテイキングがうまく効いているからです。
まとめると、自然な割り込み会話はフルデュプレックス・VAD・ターンテイキングの3点セットで成立しています。
レイテンシの壁——人間の会話として成立する閾値はどこか
「割り込める」だけじゃ実は足りないんです。
レイテンシ——応答までの遅延——が一定以下じゃないと、人間は「会話してる」と感じない。
音声AI業界でよく引用される研究によると、人間同士の自然な会話では、話者交代の間(gap)は多くの研究で0〜300ミリ秒の範囲に収まるとされており、全言語を通じた中央値は100〜200ms前後で揃っています。
つまり、人間同士は実際にはかなり素早くキャッチボールしているわけです。
AIが応答を返すまでの遅延が300msを超えると、人間側は「あ、AIだ」と感じる。300msを切ると、急に「人間と話してる感じ」になる。
これが300msの壁で、最近の音声AIプロバイダがこぞって叩こうとしている数字です。
報道ベースの数字を並べると、OpenAI Realtime APIは本番運用で300〜800msの範囲、ByteDanceのSeeduplexのようなフルデュプレックス専用モデルは半二重型より約250ms短縮、というレベル感です。
Meta AI Voiceの正確なレイテンシは公式数値が公開されていないので断定できませんが、「人間会話として成立する閾値が300ms前後」「Metaも各社もそこを狙っている」——これが現状の正しい理解です。
「音声入力→テキスト出力→音声合成」を捨てた設計の意味
ここは少し技術寄りの話ですが、コードを書かない方にも知っておいてほしい部分です。
旧世代の音声AIは、3ステップで動いていました。
- 音声入力をテキストに変換(STT、Speech-to-Text)
- テキストをLLMに投げて、テキストで応答を受け取る
- 応答テキストを音声に変換(TTS、Text-to-Speech)
カセットテープをCDに変換してまた戻す、みたいなことを毎回やっていたわけです。
各ステップで遅延が積み上がるし、「声の抑揚や感情情報」がテキストに変換した時点で消える——これが旧世代の根本的な限界でした。
GPT-4oやMuse Spark系のモデルは、ここを根本から作り直しています。
音声を直接モデルに入れて、音声を直接モデルから出す——speech-to-speech型と呼ばれる設計です。
何が嬉しいかというと、
- 中間のテキスト変換がないのでレイテンシが大幅に減る
- 「ちょっと早口だな」「迷ってるな」みたいな声の情報がモデルにそのまま届く
- 笑い声や息継ぎなど、テキストにしづらいニュアンスが応答にも反映できる
「機械音声と話してる感」が薄れる根本的な理由は、このアーキテクチャ変更にあります。
傍から見ると地味な変化ですが、体感の自然さに直結する——使ってみると「あ、なんか違う」ってなる部分です。
仕組みが分かったところで、次は実際にどう触るか、具体的な手順に入ります。
Meta AI Voice / Live AIの実際の使い方——今日から試せる手順
ここからは実用パートです。「で、結局どこから触ったらいいの?」に答えます。
5分あれば最初の音声会話は始められます。
Meta AIアプリで音声会話を始める手順(日本からの注意点含む)
Meta AIアプリ(iOS / Android)から触るのが一番早いです。
手順はこんな感じです。
- App StoreかGoogle PlayでMeta AIアプリをインストール(既存のFacebook / Instagramアカウントでログイン可)
- ホーム画面下部のマイクアイコンをタップして音声モードを起動
- 話しかけると応答が音声で返ってくる
- 途中で割り込んで質問を変えてもOK、「英語で答えて」と言えばそのまま英語切り替え
インストールからここまで、5分かかりません。
Meta AI Voice Conversationsの新機能群は米国から順次ロールアウト中という言い方が一番正確です。
地域や時期によっては「音声モードは使えるが割り込み・Live AIはまだ来てない」ということがあり得ます。日本からのアクセスでは、もし一部機能が出ない場合は「まだ自分のリージョンに来てない」と理解してください。
ちなみにエンドユーザー利用は完全無料です。
API利用料も発生しないので、「PoCでとりあえず一番安く音声AIを試したい」という用途にはど真ん中で刺さります。
Live AIで試せること・試せないこと——スマホとRay-Ban Metaの機能差
Live AIはスマホアプリ版とAIメガネ版で、できることに差があります。
Live AIの「体験そのもの」はスマホでも触れるようになりましたが、「ハンズフリーで歩きながら」「常時視野共有」みたいなメガネならではの強みは引き継がれていません。
ただ、家のなかで料理しながら「この野菜の切り方どれが正解?」みたいな用途なら、スマホアプリ版で十分実用になります。
「いきなり数万円のメガネを買う前に、自分がLive AIを本当に欲しがるかをスマホで確かめられる」——まずここから始めてみてください。
音声会話中にReelsや地図レコメンドを引き出すユースケース例
Meta AI Voice Conversationsのもう一つの売りが、「音声会話の流れを切らずに、Reels・地図・画像生成を引き出せる」点でした。
具体的な使い方をいくつか挙げます。
- 旅行計画——「東京で美味しいラーメン屋を3つ教えて。地図で出して」と言うと、音声で説明しながら地図カードが画面に出る
- 料理レシピ——「今日の夜、鶏胸肉で作れるやつ提案して。動画も見せて」でReels(短尺動画)が引き出される
- イメージ確認——「カフェの内装こんな感じにしたい、絵で出して」で会話中に画像生成
従来は音声モード→画像生成モード→地図モードと、モードを切り替えるたびに会話の流れが分断されていました。
Meta AI Voice Conversationsでは、これを音声会話の延長として扱える。
「で、地図は?」「画像も出せる?」と聞くたびにモードを切り替えていたあの手間が、会話の自然な流れの一部になる——これ、家で一回やってみるとほんとに「あ、こっちのほうが自然だ」となりますよ。
ここまでで「Metaで何ができるか」「実際にどう触るか」は揃いました。次がこの記事のメインディッシュ、業務で選ぶならどれかという比較です。
Meta AI Voice vs OpenAI Realtime API vs Gemini Live——エンジニアが選ぶならどれか
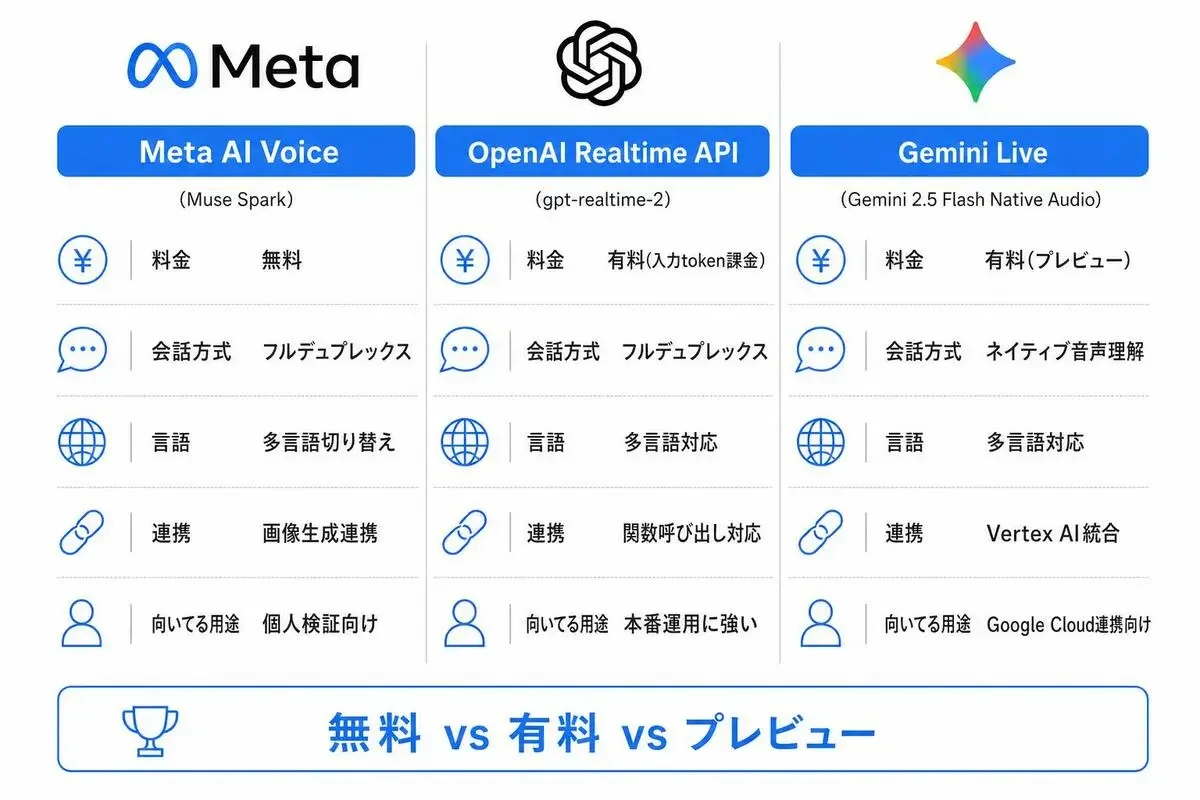
OpenAI Realtime API、Gemini Liveとの実用比較です。
ここがもるふぉ的に一番書きたかった部分です。「料金表を眺めても、自分の業務にどれを使えばいいか分からない」——それを解消します。
料金比較——「無料のMeta」と「有料のOpenAI/Gemini」の使い分け
結論から書きます。
無料のMetaを試して当たりを引くのが、今の音声AIのベストな入り方です。ただし「ベスト」は段階によって変わるので、用途別に整理します。
まず料金感です。
Meta AI Voice ConversationsOpenAI Realtime APIGemini 2.5 Flash Live数字の前提を書いておきます。
OpenAI Realtime APIの1分あたりコストは、システムプロンプトの長さ・キャッシュ有無・出力比率で大きく振れます。本番運用では0.25〜0.35ドル前後に着地するのが各社の検証ベースです。なお、ここでの料金は主力モデルを前提とした目安です(2026年5月時点)Gemini Liveは1分の音声を約1,500トークンに換算した試算(2026年5月時点、Native Audioはプレビュー扱いのため正式版で価格改定の可能性あり)- Metaはまだ商用APIを公開していないので「個人利用は無料、API商用は未定」が正確
この表を見て、「業務PoC視点でMetaを最初に触るべき理由」が3つあります。
- 料金ゼロでフルデュプレックス体験を確認できる——「自分のユースケースで音声AIが本当に効くか」の判断材料が無料で手に入る
- ベンチマーク基準として使える——「Metaでこのレベルなら、OpenAI課金してさらに上が必要か」が見える
- 並列でGemini Live無料枠と比較できる——Geminiにも開発者向け無料枠があるので、両方触れば「同じタスクの精度差」が分かる
逆に、有料を払う意味があるのは以下のケースです。
- APIで自社プロダクトに音声機能を組み込みたい——MetaはAPIなしなので必然的に
OpenAIかGemini - ファインチューニングや細かい制御が必要——
OpenAI Realtime APIはツール呼び出しやfunction callingの制御が強い - 大量に流す本番運用——
Gemini 2.5 Flash Liveは約3.4円/分と圧倒的に安く、ボリュームで効く
ぶっちゃけ、業務で音声AIを本気で組み込むなら最後はOpenAIかGeminiにAPIで行きます。
でも「最初に勘所を掴む」段階ではMetaが無料で触れるのは大きい。
「Metaで触感を掴む→Geminiで安く回す→精度足りなければOpenAIに乗り換え」——これが現実的なステップです。
機能比較——割り込み・多言語・画像生成連携の実力差
料金だけでは決まらないので、機能面の比較も入れます。
Live AIで対応Video Inputで対応DALL-E連携が必要Imagen連携が必要function callingここを見ると棲み分けが一目で分かります。
Metaは「エンドユーザー体験は最強だがAPI組み込みは弱い」、OpenAIは「API組み込みと制御性が最強」、Geminiは「コストと汎用性のバランス型」。
特に注目したいのが、Live AI相当の「カメラ映像のリアルタイム認識」をGemini Live APIがVideo Inputで実装している点です。
カメラ映像の連続認識という意味では、MetaとGeminiが現状並んでいて、OpenAIはVision APIと組み合わせる必要がある。
「カメラ連動UXを作りたい」という業務なら、Metaで体験設計をしてGeminiで実装する、というルートが現実的です。
業務活用シナリオ別おすすめ——PoC・プロダクション・個人実験での選択基準
シナリオ別にどれを選ぶかをまとめます。
「料金表を読んだ後、自分の業務でどれを選べばいいか」——これで迷わなくなるはずです。
- 個人実験・触感の確認 →
Meta AI Voice一択。無料で全機能触れる - 業務PoC・社内検証 →
Meta AI Voiceでユースケース成立を確認、その後Gemini Live無料枠でAPI実装可能性を検証 - 本番組み込み・コスト重視 →
Gemini 2.5 Flash Live。1分3.4円で大量に回せる - 本番組み込み・制御性重視 →
OpenAI Realtime API。function callingの安定性とエコシステムが強い - カメラ連動UX →
Meta AI Live AIで体験設計、本番はGemini LiveVideo Inputで実装 - AIメガネ統合前提 → Meta一択。Ray-Ban Metaとの連携が圧倒的に強い
複数の業務システム案件でAI関連の選定をやってきた経験から言うと、最初のPoCで全部を有料APIで試すのは時間もコストも無駄です。
無料で触れるところで「ユースケースが本当に成立するか」を見極めて、成立しそうなら有料APIで実装に進む——このステップを踏むほうが結果的に速くて安く済みます。
今回の発表でMeta AI Voiceが無料利用枠として一気に強化されたので、このPoCフェーズの選択肢が明確に増えた、というのが現場視点での意味です。
次の章で、これがエンジニアの仕事にどう響くかを締めます。
Muse Spark搭載Meta AI Voiceがエンジニアの仕事に与えるインパクト
ここまで機能・技術・比較を見てきました。最後に「自分の仕事に何が起こるか」に翻訳します。
コードを書かなくても音声AIを業務に組み込む3つの現実的なシナリオ
Meta AI Voiceがエンドユーザー向けに無料公開されたことで、「コードを書かなくても音声AIを業務に組み込む」シナリオが現実的になりました。
具体的には3つ見えています。
- ヒアリング業務の音声化 — 客先での要件ヒアリングを音声会話モードで進めて、議事録・確認事項をAIに整理してもらう。記録係を1人減らせる
- マニュアル代替の
Live AI運用 — 新人や非エンジニア社員に「分からなかったらカメラ向けて聞いて」と教える。FAQ整備が不要になる - アイデア出しの音声ブレスト — ホワイトボードに向かう時間が取れない日、移動中に音声で壁打ち。会話中に画像生成で視覚化までできる
どれもAPIを叩く必要がなく、Meta AIアプリがあれば今日からできる話です。
「コードを書かずに業務改善ができる選択肢」が増えると、エンジニアの時間配分が変わります。
API組み込みが必要な部分だけコードを書いて、それ以外は既製のアプリで済ませる——という割り切りが現実的になる。
「無料のフルデュプレックス音声AI」が普及した世界で何が変わるか
最後に、もう少し広い視点で締めます。
OpenAI Realtime APIが出たとき、業界の空気は「ついに音声AIが実用になった」でした。
でも料金が0.30ドル/分前後だったので、本番運用は「ROIが合うユースケースだけ」に絞られていたんです。
今回Meta AI Voiceが無料で公開されたことで、「とりあえず音声AIを試してみる」のハードルがゼロに落ちます。
PoCの心理的ブロックが消えるので、「うちの業務、これ音声化できるかも」を皆が同時に試し始める。
想像してみてください。
音声AIを業務に組み込んだチームと、「まだ様子見」のチームが、半年後に同じ速度で仕事ができると思いますか?
明確に差がつき始めるはずです。
今やるべきは「組み込む決断」ではなく、「まず触ること」です。
Meta AI Voiceを5分触ってみて、自分の業務のなにが音声で楽になりそうかをイメージする。
その引き出しを持っておくだけで、半年後の選択肢の幅が変わります。
インストールから最初の会話まで5分。無料で触れるうちに、まず一回試してみてください。
Meta公式の発表詳細はこちらにまとまっています。

5月12日のアップデート詳細は9to5Macの速報が一番分かりやすいです。

- 3
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 2
- 0
-
- 4
- 0
-
- 3
- 0
-
- 2
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 1
- 0
-
プロンプト画伯
- 2
- 0
-
AI脱社畜
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 2
- 0
-
AI経営者の参謀@ひで
- 3
- 0
-
AI集客@ルイ
- 5
- 0
-
- 2
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 4
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
- 3
- 0
-
- 3
- 0
-
AI経営者の参謀@ひで
- 2
- 0
-
AI集客@ルイ
- 3
- 0
-
AI経営者の参謀@ひで
- 3
- 0

















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます