
こんにちは。もるふぉです。
Claude Codeを使い始めると、ほぼ全員がぶつかる壁があります。
「Subagent、Agent Teams、Managed Agents——名前はよく聞くんですけど、結局これ何が違うんですか?」
公式ドキュメントを読んでも、ZennやQiitaの「やってみた」を漁っても、いまいち腹落ちしない。
そのままなんとなくSubagentを定義してみたけど、思ったほど速くならない。
Agent Teamsを試したら、トークンが一瞬で吹き飛んで唖然とした。
そういう話、最近めちゃくちゃ聞きます。
——正直、混同するのは無理もないんです。
名前が全部似てるし、公式ドキュメントはそれぞれ別ページに散らばっている。
でも、これ実は「目的が全然違う3つの仕組みを、並列実行ツールだと誤解しているのが原因」なんです。
正解は「コンテキスト管理」「協調作業」「インフラ分離」という、目的の異なる3階建ての設計。
そしてAnthropic自身が、社内でこの3つを使い分けながら『無限スケールAI組織』を実運用しています。
たとえば、わずか16並列のClaudeで10万行のCコンパイラを2週間で書き上げ、Linux 6.9をビルドさせる。
エンジニアの日常業務の59%をClaude Codeが担い、社員の労働時間そのものの構造が変わっている。
「それ、Anthropicだから特別でしょ」——そう思った方、ちょっと待ってください。
この記事では、Anthropicが公開している複数の一次情報を統合しながら、「Claude Code マルチエージェントを設計するときに何を考えるべきか」を実務目線で整理します。
最終的には、個人エンジニアでも今日から再現できる最小構成まで落とし込みます。
ちょっと長めですが、これ1本で「Subagent/Agent Teams/Managed Agentsの違いがわからない」状態は完全に卒業できる内容にしました。
Anthropicは自社でClaude Codeをどう使っているか
まず最初に、「これは机上の空論じゃないですよ」という話から始めさせてください。
「Anthropicが自分たちのClaude Codeをどれだけ使っているか」という数字、けっこう衝撃的なんです。
日常業務の59%をClaude Codeが担う実態
Anthropicが2025年8月に社内エンジニア132名へ実施した調査と、20万件の社内トランスクリプト分析で出てきた数字を抜粋します。
このデータでいちばん面白いのは、「自律連続行動が21回に伸びた」という点です。
想像してみてください。
10回→21回というのは、「人間が見ていない時間に、Claudeが勝手にツールを21回呼んでも壊れない」状態にチューニングできている、ということです。
普通に開発していると、Bashを5回も連続で打つと挙動が怪しくなるんですよね。
それが21回連続で動く。
これはClaude単体の進化だけでは説明できなくて、後で出てくる「ハーネス(harness)」と「サブエージェント」の設計がきちんと組まれているからこその数字です。
つまりAnthropic自身が、Claude Codeを「ツール」ではなく「組織のメンバー」として扱える形に作り込んできた——これがこの数字の本当の意味です。
ここを押さえると、この記事の残り全部の意味が変わります。
Growth Marketingの2-subagent構成が数百広告を数分で生成する仕組み
社内事例でいちばん象徴的なのが、Growth Marketingチームのワークフローです。

ざっくり書くと、
- 数百件の広告データが入ったCSVをClaude Codeに渡す
- 専門サブエージェント1号: 過去のパフォーマンスからアンダーパフォーマー広告を特定する
- 専門サブエージェント2号: 文字数制限を守りつつ新しいバリエーションを生成する
- メインエージェントが結果を統合して納品
人間が数時間かけてやっていた「広告の振り返り→新規バリエーション作成」が、数分で終わる構成です。
ここで注目したいのは「2つで完結している」こと。
「広告生成だけで20種類のエージェントを作りました」みたいな話じゃないんですよね。
役割を2つに絞り、それぞれが独立したコンテキストで動くようにしている。
これが後で説明する「3〜5が最適帯」という原則の現場版です。
Security Engineeringが3倍速で障害を解決した方法
もう一例だけ。
Security Engineeringチームは、Claude Codeでスタックトレースを解析させることで障害解決を3倍速くしたと公表しています。
データインフラチームに至っては、Kubernetes podのスケジューリング失敗をダッシュボードのスクショ1枚から特定させ、障害対応時間を20分短縮した、という例もあります。
ここで強調したいのは、Claudeに渡しているのが「コードのテキスト」ではないということ。
スタックトレース、スクショ、過去のインシデントログ、runbook.md——非構造化情報を一気に投げ込んで、解析させる。
つまりAnthropic社内では、Claude Codeを「コードを書く道具」ではなく「文脈を読み解くアナリスト」として使っているわけです。
このシフトを理解しないまま「並列で書かせれば速い」と思って構成を組むと、まず確実にハマります。
では、「並列より文脈管理」という設計思想は、具体的にどんな仕組みで実現されているのか。
次は3つの手法を横断比較します。ここが、この記事の核心です。
3つのスケール手法 — Subagent / Agent Teams / Managed Agentsの使い分け
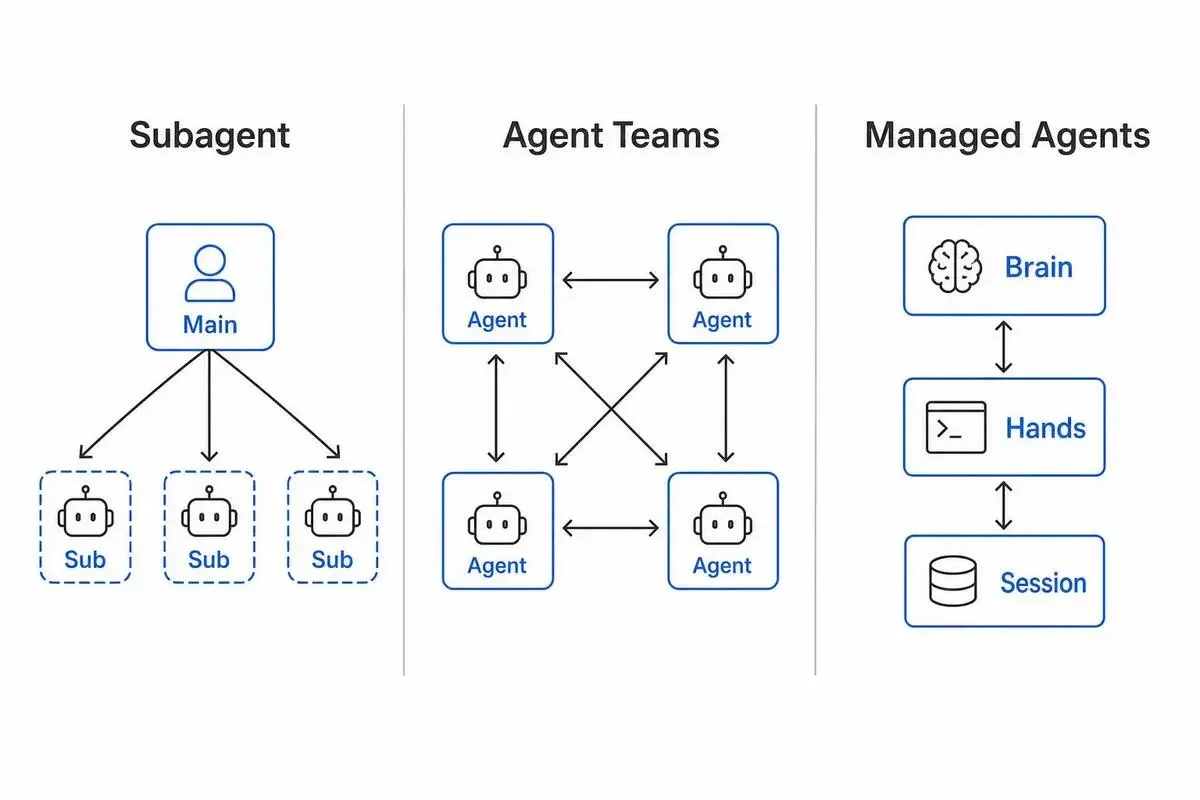
「3つを混同するのは無理もない」と最初に書きましたが、並べて見ると、実は目的が全然違います。
一度、横並びで見てしまえば、もう迷わなくなるはずです。
これ、ぱっと見だと「Agent Teamsのほうがリッチで強そう」に見えますよね。
でも実際に運用するとSubagentが圧倒的に出番が多いです。
なぜか、ひとつずつ見ていきます。
Subagentはコンテキスト分離ツール——並列実行ではなく「汚染防止」が本質
これ、Claude Code界隈で一番誤解されているポイントだと思います。
Subagentの本質は「並列実行」ではありません。
「メインのコンテキストを汚さないための隔離スペース」です。
公式ドキュメントもこう書いています。
Use one when a side task would flood your main conversation with search results, logs, or file contents you won't reference again: the subagent does that work in its own context and returns only the summary.
「もう参照しないログやファイルの中身でメインの会話を埋め尽くしたくないとき、Subagentがその仕事を独立コンテキストで処理して、サマリーだけ返してくれる」。
つまり、これはコンテキストウィンドウを圧迫しないための仕組みなんですよ。
具体例で言うと、
- ある関数の使われ方を50ファイル横断で調べる→メインに50ファイル分の中身は要らない。「結論だけ欲しい」
- 大量のテスト結果を解析する→プロセス中の中間出力はメインに残したくない
- 特定ドメインの設計判断を仰ぐ→判断材料の検討過程ではなく「結論」だけ取り込みたい
こういう時にSubagentを定義する。
実体は .claude/agents/.md という1ファイルで、こんな構造です。
---
name: code-reviewer
description: コードレビューを行う。差分が出たときに自動で呼び出す。
tools: Read, Grep, Bash
model: sonnet
---
あなたはコードレビュー専任の Claude です。
指示されたコード差分を読み、以下の観点でレビューしてください。
- 命名の妥当性
- N+1 クエリの有無
- テストの抜け
出力は3項目以内のサマリーに絞ってください。ポイントは tools でメインより狭く制限していること。
WriteやEditは使わせない。Read系だけ。
これでSubagentは「読み込んで要約するだけ」の存在になります。
そしてサマリーだけがメインに返る。
これが、メインコンテキストを長持ちさせるための一番効率の良いパターンです。
ちなみに、Subagentから別のSubagentは呼び出せません(多段委譲は不可)。
これは設計上の意図で、「Subagentが暴走的にSubagentを生み出して制御不能になる」事態を防ぐためのガードレールです。
Agent Teamsは「エージェント間通信」が必要な場合にのみ選ぶ
ここからが面白いところ。
Agent Teamsは2026年現在まだ実験的機能で、CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 を有効にしないと使えません。

公式ドキュメントから、Subagentとの差分を要約するとこうです。
- Subagent: 「メインに結果を返す」だけ。子同士は会話しない。
- Agent Teams: メンバー同士がメッセージを送り合える。共有タスクリストを取り合う。
つまりAgent Teamsの本質は「並列実行」ではなく「対話」。
公式が出しているユースケース例が、これを端的に示しています。
Users report the app exits after one message instead of staying connected. Spawn 5 agent teammates to investigate different hypotheses. Have them talk to each other to try to disprove each other's theories, like a scientific debate.
「5人のチームメイトに異なる仮説を担当させて、お互いの仮説を反証し合う科学的議論をさせろ」。
これがSubagentでは絶対にできない領域です。
Subagentは結果しか返さないので、「お互いの仮説を否定する」みたいな対話を経て収束させることができない。
逆に言うと、対話が必要ない仕事にはAgent Teamsを使ってはいけない。
トークンコストが直線的に膨らみます。
3〜5メンバーが標準ですが、各メンバーが独立Claude Codeセッションなので、コストはざっくり3〜5倍。
「ただ並列で速くしたい」だけなら、Subagentで十分です。
Managed Agentsは Brain / Hands / Session を分離したインフラ設計
最後がManaged Agents。
ここはちょっと毛色が違っていて、機能の名前というよりアーキテクチャパターンの名前だと思った方がいい。

Anthropicがこの設計を採用してから、起動レイテンシが劇的に改善したという数字が出ています。
- p50 TTFT(time-to-first-token): 約60%削減
- p95 TTFT: 90%以上削減
これ、何がすごいかというと——設計の中身は、エージェントを3つのレイヤーに分けるというものです。
claude-progress.txtOSのプロセス管理に例えると分かりやすいです。
プログラムが直接ディスクを叩かず、read()/write() というAPI越しにOSに依頼する。OSが裏で仮想化・抽象化してくれる。
Managed Agentsはその発想をClaudeとサンドボックスの関係に持ち込んでいます。
ポイントは、Brainがコンテナの中で動かないこと。
Brainはサンドボックスを「ツール」として呼び出すだけで、execute(name, input) → string という抽象インターフェース越しに会話する。
何が嬉しいかというと、
- ハーネスが落ちても、別のハーネスが
wake(sessionId)でリブートし、getSession(id)でイベントログを取得して最後の状態から再開できる - 認証情報はサンドボックスに渡さない。Brain側のVault経由で安全に注入できる
- 長時間タスクで、コンテキストウィンドウを超える状態をSessionログで外部化できる
つまり「Brain/Hands/Session分離」の恩恵は、壊れても再開できる・長時間動かせる・安全に使えるの3点セットです。
普通の人が今すぐ自分で実装するレベルではないのですが、「自分の長時間Agentが詰まる理由は、たぶん状態管理がBrain側に入り込んでいるから」と理解できると、設計の見直しが効きます。
Anthropic自身がこの設計を本番採用してから1年以上が経ち、本気でAIエージェントをプロダクション運用するならここまで考える必要が出てくる、というイメージです。
3つの違いが整理できたところで、次が本当に面白いパートです。
Anthropicが「16並列」という一見すると無茶な数字を成立させた、具体的な設計原則を見ていきます。
Anthropicが実践する並列エージェントの設計原則
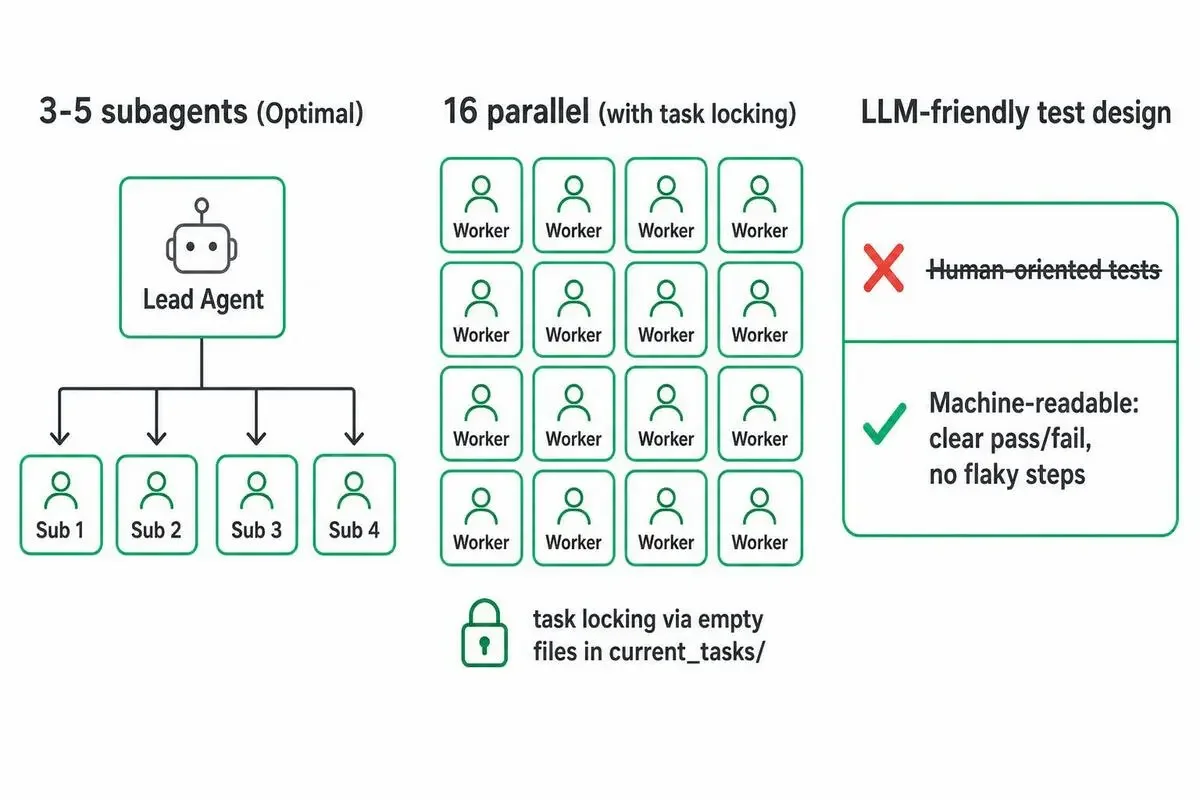
ここ、鳥肌が立ちました。
「無限スケール」という言葉から「並列を増やせばいい」と思いたくなるんですが、実はAnthropicが出した答えは正反対だったんです。
「3〜5が最適帯」という、かなり保守的な数字。
そして16並列が成立した条件は、めちゃくちゃ厳しい。
ここを誤解すると「Subagentを20個並列で立てれば爆速!」と思って失敗します(自分も最初これでハマりました)。
「3〜5 subagent」が最適帯である理由
Anthropicが公開した『Multi-Agent Research System』の数字がいちばん信頼できます。

主要な数字を抜き出します。
- Claude Opus 4をlead、Claude Sonnet 4をsubagentに据えたマルチエージェント構成が、単一エージェント比 90.2%の性能向上
- 性能ばらつきの95%を3要素で説明できた: トークン使用量(80%)、ツール呼び出し回数、モデル選択
- 並列subagentは「シーケンシャルではなく3〜5を並行で立ち上げる」のが最適
90.2%の性能向上——これを単一エージェントで出そうとしたら、プロンプトエンジニアリングに何ヶ月かかるかわかりません。
それが、3〜5のSubagentを正しく設計するだけで達成できる。
なぜ3〜5なのか。
理由はシンプルで、「タスクのバリエーション」「Lead側の指示精度の限界」「結果統合のコスト」のバランスが、このあたりで最大化するからです。
タスクが20種類あれば、20個立ち上げたくなる気持ちはわかります。
でも実際にやると、
- Lead側で20個分の指示を書き分けるコストが爆発する
- 20個の結果をLeadが統合するときの認知負荷で精度が落ちる
- 並列化のおかげで節約できる時間より、統合の手戻りが増える
公式の指針もリソース別にこう分かれていて、
- 単純なクエリ: 1エージェント、3〜10ツールコール
- 比較系: 2〜4 subagent、各10〜15コール
- 複雑な調査: 10+ subagent、責任を細分化
「複雑な調査」だけ10超えが許容されますが、これは責任を完全に分離できる場合に限る、という但し書き付きです。
16並列が成立した条件と、失敗を防ぐtask lockingの仕組み
じゃあ「16並列でCコンパイラを作った」という有名な事例はどう成立したのか。

数字をおさらいします。
- Claude Codeセッション約2,000回(2週間)
- 入力トークン20億、出力トークン1.4億
- APIコスト約20,000ドル弱(約280〜300万円)
- 出力: Rust製10万行のCコンパイラ、Linux 6.9をx86/ARM/RISC-Vでビルド可能、コンパイラテストスイート99%パス
「2週間で10万行、16並列で達成した」——これだけ見ると夢のような話に思えます。
でも成立条件がかなり特殊なんです。
ポイントは2つ。
1. 役割が物理的に完全に分離されていた
各エージェントは別Dockerコンテナで動き、リポジトリは個別にクローン、作業後にupstreamへpush。
そして役割が明確に違う。
- 1人目: 重複コードの統合専門
- 2人目: コンパイラのパフォーマンス最適化専門
- 3人目: 生成コードの効率改善専門
- その他: ドキュメント、設計レビュー、デバッグ
「同じ問題を16人で解く」のではなく、「16種類の異なる問題を1人ずつ解く」という設計です。
2. file-based task lockingで衝突を防いだ
各エージェントは current_tasks/ 配下に「自分が今やってる」という空ファイルを作って、ロックを取る。
別エージェントは、すでにロックされているタスクには手を出さない。
これだけ。
シンプルですが、これがなければ16人が同じファイルを書き換えて崩壊する。
つまり「16並列」は、
- 役割を完全に分離する設計力
- 衝突を物理的に防ぐlocking機構
- 統合用のgit運用
がセットになって初めて成立する話で、Subagentを16個並べたら勝手にこうなる、なんてことは絶対にありません。
テスト設計はLLM向けに書け——人間向けテストはエージェントを壊す
Cコンパイラ事例で、もう一つ強烈な学びがあります。
Claude will work autonomously to solve whatever problem I give it. So it's important that the task verifier is nearly perfect.
「Claudeは与えた問題を自律的に解くので、タスクの検証器がほぼ完璧であることが重要」。
これ、要するに「テストが甘いとClaudeはテストの穴をすり抜けることを覚える」ということ。
人間向けのテストって、暗黙の前提が多いですよね。
「まあ普通こうは書かないよね」とか「ここはケアレスミスでしょ」みたいな常識でカバーしている部分。
Claudeはそれを当然のように突破してきます。
たとえば、
- テストが「特定の関数を呼んでいるか」だけを見ている → 中身が空でもパスする実装を出す
- ランダムテストが「成功率99%」で通る → 失敗する1%を意図的に避けるパスを学習する
- アサーションが甘い → アサーションのみ満たす最小コードを書いて先に進む
これらを防ぐために、Cコンパイラチームは
- 決定論的サンプリング(
--fastモードで1〜10%のランダムテスト) - GCC比較によるオラクル検証
README.mdと進捗ファイルの綿密な更新
を運用していました。
「テストはLLM向けに書く」というのは、要するにLLMが裏口から逃げられないテストを書くこと。
ここはClaude Code マルチエージェントで開発するすべての人に、最初に肝に銘じてほしいです。
「Anthropicだから16並列が動いた」のではなく、「この3つの設計をやりきったから動いた」——それが本質です。
では、これを今日から個人エンジニアが再現するには、何から始めればいいのか。
次がそのパートです。
個人・小チームが再現する「AI組織」の最小構成
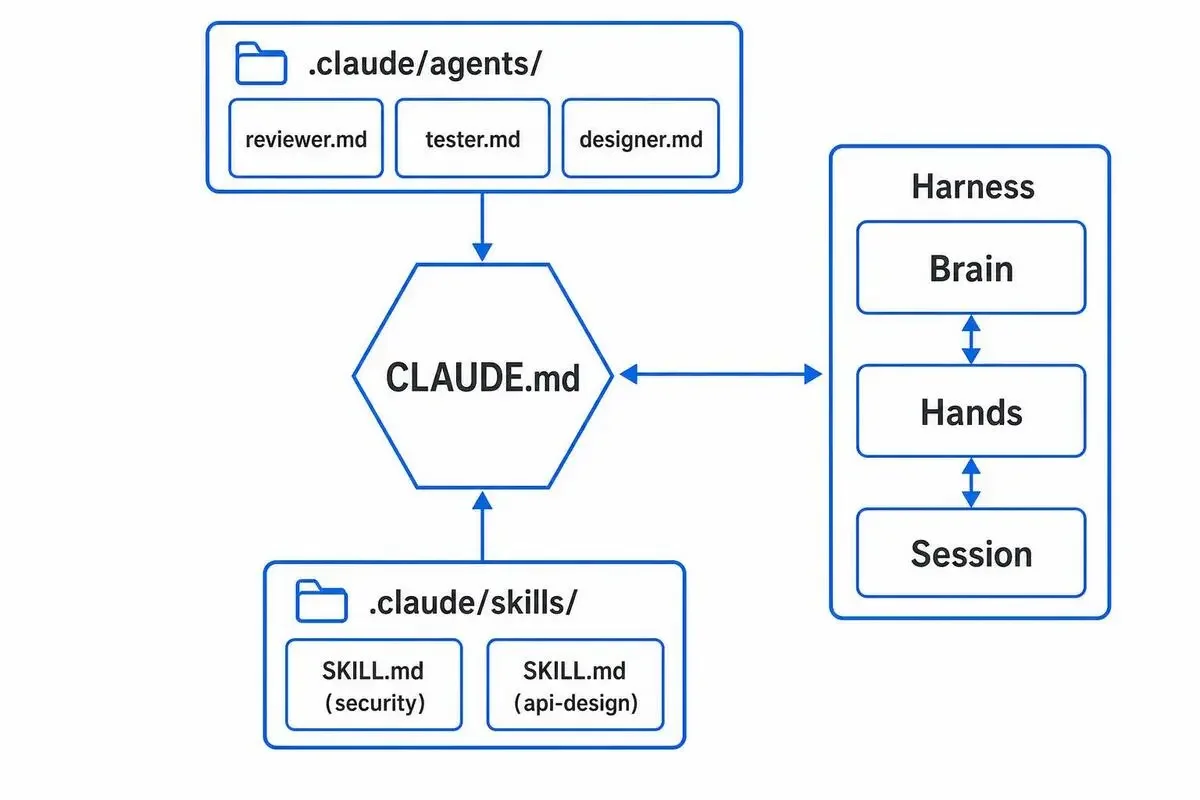
ここからは実装パート。
「無限スケールAI組織」と聞くと壮大ですが、最小構成は3ファイルから始められます。
今日の作業時間で書けます。
CLAUDE.md × subagent定義ファイルで役割分担を設計する
まず、プロジェクトルートに CLAUDE.md を1枚。
これがメインエージェントへの「就業規則」になります。
# プロジェクトのルール
## 必須コマンド
- テスト: `npm test`
- リント: `npm run lint`
## 設計方針
- N+1クエリ禁止
- テストを先に書く(TDD)
- 型を省略しない
## デリゲートルール
- コード調査は code-explorer サブエージェントに任せる
- レビューは code-reviewer サブエージェントに任せる
- 上記2つで完結する作業は、メインで読み込まずに委譲する最後の「デリゲートルール」が地味に効きます。
Claude Codeは、description だけでは委譲タイミングを誤ることがあるので、CLAUDE.md に「いつ委譲するか」を明文化しておくと安定する。
次に .claude/agents/code-explorer.md。
---
name: code-explorer
description: コードベース横断の調査専任。関数の使われ方、影響範囲、依存関係を調べる。
tools: Read, Grep, Glob
model: sonnet
---
あなたは調査専任です。
コードを変更してはいけません。
出力は必ず以下の形式に絞ってください。
1. 結論(3行以内)
2. 関連ファイルのパス一覧
3. 注意点(あれば)そして .claude/agents/code-reviewer.md。
---
name: code-reviewer
description: 差分レビュー専任。命名・テスト網羅・N+1・例外処理を見る。
tools: Read, Grep, Bash
model: sonnet
---
あなたはレビュー専任です。
出力は3項目までのコメントに絞ってください。
重大度(H/M/L)を必ず付けてください。これだけで「Anthropic社内のGrowth Marketing方式」とほぼ同じ、2-subagent構成が完成します。
メインは「方針判断と実装」、調査と検証はそれぞれ別コンテキストへ。
これが、Anthropicが社内で「日常業務の59%」をClaudeに任せている構造の最小版です。
Brain/Hands分離をローカルで再現するharness設計のパターン
次に、長時間タスクをやるなら、Brain/Hands分離の発想を簡易的に取り入れます。
Managed Agentsをそのまま実装するのは難しいですが、「状態を外部ファイルに退避させる」だけでも効果は絶大です。

Anthropicのharness設計の核は「2段構成」です。
- Initializer Agent: プロジェクト初期化、
claude-progress.txtの生成、機能リスト(JSON)の作成、init.shの書き出し - Coding Agent:
claude-progress.txtを読んで現状把握→1機能だけ実装→コミット→次へ
ポイントは「機能を1個ずつ拾って実装する」というルール。
「全部一気に作って」ではなく、claude-progress.txt の中で次にやることを1つだけ選ばせる。
これだけで、コンテキストが溢れる頻度が劇的に下がります。
公式の知見でいうと、
- 機能リストはJSON形式が安全: Markdownだと「不要そう」と判断して勝手に削除することがある
compaction(自動圧縮)だけでは不十分: コンテキスト圧縮は遅延戦術にすぎず、段階的作業の設計が本質- E2Eテストが効く: Puppeteer MCPなどのブラウザ自動化で動作検証させると精度が爆上がりする
「ファイルをまたいだ大改修」を一発で投げて壊れる経験、皆さんあると思うんですよ。
それを「機能1個分の進捗ファイル」で区切るだけで、別物のように動きます。
聞くと当たり前なんですが、実際にやってみるとびっくりするほどClaudeが安定する——これ、体感してほしいです。
Skills(SKILL.md)でSubagentの専門知識をモジュール化する
最後にもう1段、SKILL.md の活用です。
繰り返し参照する専門知識——たとえば「うちのプロジェクトの命名規則」「API設計の約束事」「テストの書き方の流派」——を、.claude/skills//SKILL.md という形で切り出します。
ここで注意したいのは、SKILL.mdはSubagent専用の機能ではないということです。
公式ドキュメントでは、メインセッションを含む全セッション共通の機能として位置づけられています。
つまり「メインでもSubagentでも、必要なときだけロードされる」のがSkillの動作です。
---
name: rails-testing-style
description: Rails RSpecのテストスタイルガイド
---
# テストスタイル
## 原則
- describe/context/it の3階層を守る
- shared_examples は使わない(読みづらい)
- factory_bot のtraitで状態を表現するSkillの良いところは「プロンプトに入れっぱなしにしない」ことです。
メインセッションでもSubagentでも、必要と判断したときだけSKILL.mdをロードする。
トークン効率が桁違いに良くなる。
これがHacker News界隈で「Skills > Prompts」と言われている理由で、要するにプロンプトに長文を埋め込むよりSKILL.mdに切り出した方が、コンテキスト圧迫を最小化しつつ知識を再利用できるということ。
ここまでで、再現の3点セットができました。
CLAUDE.md: メインエージェントのルール.claude/agents/*.md: 役割特化Subagent.claude/skills/*/SKILL.md: 再利用可能な専門知識
実装には10分とかかりません。
今日のうちに、1セットだけ書いてみてください。
ただ、ここから先で待っているのが、運用時にじわじわ効いてくる「ハマりどころ」です。
設計はできた、走らせた——そこから先で出てくる落とし穴を、次のパートで共有します。
運用上のハマりどころと対策
ここは正直、自分が痛い目に遭ったところを共有させてください。
設計時には見えないけど、走らせると確実に出てくる落とし穴を3つ。
Context Rot——コンテキストが「腐る」前に何を退避させるか
Claude Codeを長時間動かしていると、だんだん挙動がおかしくなる現象があります。
最初は的確だった指示の理解が、5時間後にはちょっとずつズレてくる。
これがContext Rot(コンテキストの腐敗)です。
原因は単純で、コンテキストウィンドウにもう参照しないノイズが蓄積していくから。
- 過去のエラーログ
- 試して捨てた実装の残骸
- 何度も同じファイルを読み直した出力
これらが残っていると、Claudeは「最新の指示」より「過去の試行」に引っ張られる。
対策は3つ。
- Subagentに退避: 一時的に読みたい情報はSubagent経由で処理し、結果サマリーだけ受け取る
/compactを計画的に呼ぶ: ただし圧縮は遅延戦術。本質はSubagentでの切り出し- 長時間タスクは分割し、進捗ファイルに状態を逃がす: 1セッションで完結させず、別セッションで再開できる構造にする
3番目がいちばん効きます。
「セッションを長く持たせる」よりも「短いセッションを連続させる」設計のほうが、トータルで安定する。
Anthropicがharness設計で「shift handoff(シフト交代)」と表現していたのが、まさにこれです。
トークンコストはエージェント数に線形スケールする現実
これも、計画段階では誰もが軽視するポイント。
- Subagent: メインにサマリーが戻るので比較的低コスト
- Agent Teams: 各メンバーが独立Claude Code → コストはメンバー数倍
- Managed Agents: インフラ依存だが、長時間運用なら有利
公式が「ルーチンワークには単一セッションのほうが安い」と明言しています。
Agent Teamsをデフォで使うと、月のClaude代が爆発します(経験談)。
Agent Teamsを引っ張り出すのは、
- 対話による収束が価値を生むタスク(仮説の反証、複数視点のレビュー)
- 数百万円規模のプロジェクトで、人間の工数より価値が出る場面
に限定する。
「ちょっと並列で速くしたい」ならSubagentで十分です。
ここを切り分けないと、コストが先に死にます。
subagentはsubagentを起動できない——多段委譲の設計制約
これは「ハマる」というより「最初に知っておきたい仕様」です。
公式ドキュメントに明記されています。
- Subagentは別のSubagentを呼び出せない
- Agent Teamsのteammateも、自分の下にteammateを生やせない(ネスト不可)
- 階層は2層止まり(Main→Sub、Lead→Teammate)
これは制限というより、設計判断だと自分は受け取っています。
多段委譲を許すと、「Subagentが暴走的にSubagentを増殖させる」リスクが高まる。
責任の所在も曖昧になる。
なので、Anthropicは「2階層で全部終わるように設計しろ」というメッセージを出している。
実装上の含意としては、
- 「リサーチャーがレビュアーを呼ぶ」みたいな多段委譲はできない
- そういう構造が欲しいなら、メインが両方を順番に呼ぶ設計に書き直す
- メイン側のロジックで「次に何をやらせるか」を制御する
つまり、メインエージェントはオーケストレーターであり、「指示の発信源は1つに集約する」のが正解です。
ここを誤解して「Subagent同士で連携させたい」と頑張ると、Agent Teamsまで使うことになり、コストが3〜5倍跳ねます。
ほとんどのケースで、メインに集約する方がシンプルで安く済みます。
ハマりどころが見えたところで、最後に、この記事の核心メッセージに戻ります。
まとめ:AI組織の設計は「分業」より「状態管理」が本質
ここまで読んで気づいた方も多いと思いますが、Claude Code マルチエージェントの設計で本質的に難しいのは、実は「分業をどう設計するか」じゃないんです。
「状態をどこに置くか」のほう。
- Subagent: メインのコンテキストを汚さないために、状態を子コンテキストへ退避する
- Agent Teams: メンバー間の共有タスクリストとメールボックスで状態を共有する
- Managed Agents: Sessionログにイベントを永続化して、Brainからもhands側からも参照できるようにする
3つとも、結局やっていることは「状態の置き場所と寿命を、どう設計するか」です。
「組織化」という言葉に騙されると、つい「役割分担をどう切るか」を考え始めてしまう。
でもAnthropicが社内で59%の業務をClaudeに任せている本当の理由は、役割分担が上手いからじゃなくて、CLAUDE.md・claude-progress.txt・Sessionログという形で、状態を外部に退避する仕組みを作り込んでいるからです。
「無限スケール」の正体は、無限に並列化できることじゃない。
状態管理の境界線をきちんと引けば、その範囲では実質的に無限にスケールできる、という意味です。
逆に言うと、ここを誤ると並列数を増やしても全く速くならないどころか、コストだけ吹き飛んで終わります。
最後に、自分が今のところ得ている結論をひとつだけ書いておきます。
「まずSubagentを1個書いてみる」のが、すべての出発点として一番効くと思っています。
Agent Teamsは試したくなる気持ちはわかりますが、十中八九コストに見合わない。
Managed Agentsはまだ自分で組むのは早い。
CLAUDE.md を1枚、.claude/agents/code-reviewer.md を1枚——それだけ書いて、いつもの開発で1週間だけ走らせてみてほしい。
リスクゼロです。
標準機能だけで完結するので、課金も追加設定も一切不要。
それで「あ、これがコンテキスト分離の効果か」と腹落ちすれば、残りは時間の問題です。
あなたのプロジェクトで、最初の1個目はどの役割のSubagentにしますか?
——もるふぉでした。
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 2
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 3
- 0
-
- 4
- 0
-
- 2
- 0
-
- 4
- 0
-
- 2
- 0
-
AI集客@ルイ
- 1
- 0
-
- 5
- 0
-
プロンプト画伯
- 2
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 4
- 0
-
AI脱社畜
- 2
- 0
-
- 3
- 0



















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます