
ねえ、ちょっと聞いてほしいんだけど。
画像生成AIで「これ最高じゃん!」って1枚完成させたとき、次の瞬間になに思う?
「……これ、2Dのままか」って。
世界観バリバリのファンタジー風景を作っても、建物の細部まで作り込んだSF都市を生成しても、結局スクリーンショットを眺めるだけ。
その世界に「入れない」。
後ろを振り返ることもできない。歩き回ることもできない。
ずっとそれがモヤモヤしてたんだよね。
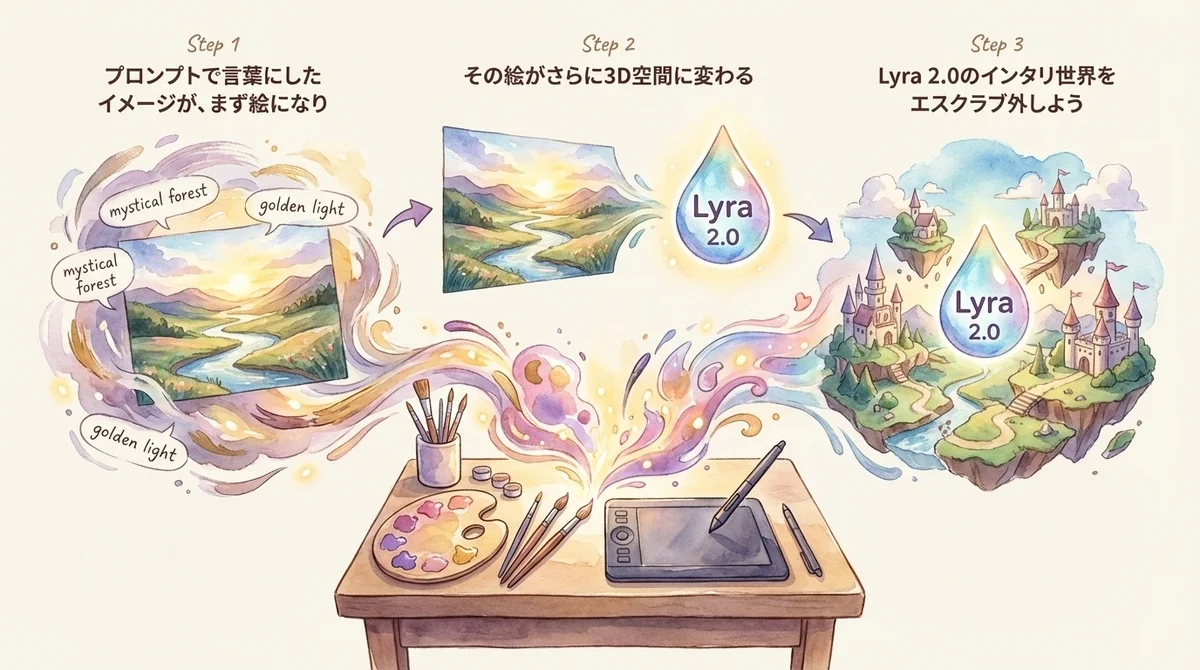
NVIDIAが「NVIDIA Lyra 2.0」という、画像1枚から歩き回れる3Dワールドを生成するAIをオープンソースで公開した。
しかも100%オープンソース。
自分が作った1枚の絵の「中に入れる」。
後ろを振り返れる。
歩き回れる。
ちょっと意味がわからないレベルの進化なので、クリエイター目線で全力で解説していく。
NVIDIA Lyra 2.0とは何か

画像1枚から3Dワールドを生成するしくみ
NVIDIA Lyra 2.0は、1枚の画像を入力するだけで、その中を自由に探索できる3Dワールドを生成するAIだ。
普通の「画像から3Dモデルを作るAI」とは根本的にやっていることが違う。
Lyra 2.0のパイプラインはこんな流れになっている。
- ユーザーが1枚の画像とカメラの移動経路を指定する
- AIがその経路に沿った「ウォークスルー動画」を生成する
- 生成された動画から3Dシーン(3D Gaussian Splatting / メッシュ)に変換する
つまり、まず「この方向に歩いたら何が見えるか」を動画として想像してから、それを3D空間に落とし込むという二段構えのアプローチなんだよね。
これが嬉しいのは、「AIが3Dを直接作る」んじゃなくて「AIが動画を想像してから3Dにする」という順番なおかげで、画像の雰囲気や世界観がちゃんと3Dに引き継がれること。
ベースモデルにはWan 2.1-14B DiT(Diffusion Transformer)を採用していて、動画生成のクオリティ自体がかなり高い。
作業解像度は832x480ピクセルで、ここから3DGSやメッシュへの変換にはDepth Anything 3という深度推定モデルを使っている。
3D Gaussian Splattingをわかりやすく説明すると
「3D Gaussian Splatting(3DGS)って何?」ってなるよね。
ここ数年で急速に広まった3D表現技術なんだけど、一言で言うと「霧の粒で3Dを作る技術」だ。
従来の3Dモデルはポリゴン(三角形の面)で物体を表現していたけど、3DGSは「色のついた半透明の点の集まり」で空間を表現する。
- 従来の3D: レゴブロックを組み合わせて形を作る
- 3DGS: 色のついた霧の粒を大量に配置して空間を表現する
だから曲面も、反射も、透明感も自然に表現できる。
「なるほど、それで何がいいの?」って思うよね。
レンダリングも爆速で、リアルタイムでグリグリ動かせるのが最大の強みだ。
つまり、「重いレンダリングを待たなくていい」。
歩き回りながらリアルタイムで描画できるから、ゲームエンジンみたいにサクサク動く。
Lyra 2.0が3DGSを採用しているのは、「歩き回れる3D空間」をリアルタイムで描画するためにベストな選択だからなんだよね。
で、「なにがどう変わるのか」の核心は次のセクションで一気に見せていく。
Google Genie 3との違い -- なぜLyra 2.0が重要か
Genie 3はなぜ使えないのか
「Genie 3っていうのも似たことできるんじゃないの?」って声、わかる。
Google DeepMindが発表したGenie 3も、テキストや画像からインタラクティブな3D環境を生成できるAIだ。
24fpsでリアルタイムにナビゲートできるという触れ込みで、話題になったのを覚えている人も多いと思う。
ただ、Genie 3には致命的な問題がある。
- 一般公開されていない(限定リサーチプレビューのみ)
- オープンソースではない
- Google AI Ultraサブスクリプション契約者(現時点では米国限定)にのみ公開されており、日本のユーザーはアクセスできない
つまり、日本のクリエイターが「今すぐ触れる」状態ではない。
すごいのはわかってる、でも使えない。
それが今のGenie 3の現実だ。
Lyra 2.0がオープンソースである意味
ここがLyra 2.0の最大の価値だと思っている。
ある意味、Google Genie 3のオープンソース版みたいなもの。
これ、地味にすごいんですよ。
ソースコードはApache 2.0ライセンスでGitHubに公開されている。
モデルウェイトのライセンスはHugging Faceのモデルカードで別途確認が必要だ。
特に注目したいのが最後の行。
Genie 3はリアルタイム映像として3D空間を見せてくれるけど、3Dアセットとしてエクスポートできるかは明確ではない。
一方、Lyra 2.0は3DGSやメッシュとして出力できるので、他のツールに持っていける。
これはクリエイターにとって決定的な差だ。
「見せてもらえる3D」じゃなくて「自分で持ち帰れる3D」。
ここ、ほんとに大事なポイントだから覚えておいてほしい。
では、具体的にLyra 2.0で何ができるのか、一個ずつ見ていこう。
Lyra 2.0でできること3つ

画像から探索可能な3Dワールドを生成する
最も基本的な機能がこれだ。
「これだけでもう十分すごい」って話でもある。
風景写真でも、イラストでも、画像生成AIで作った絵でも、1枚入力すれば「その中を歩き回れる3Dワールド」に変換できる。
今まで: 1枚の絵を眺めるだけ。
Lyra 2.0以降: その絵の中を歩き回れる。
GUIが用意されていて、カメラの軌跡を自分で計画できる。
「この方向に進みたい」「ここを曲がりたい」というのをインタラクティブに設定して、AIがその先の世界を生成してくれるしくみだ。
後ろを振り返れる、長距離カメラ移動ができる
これが地味にすごいところなんだよね。
従来のこの手のツール(Lyra 1.0を含む)が苦手だったのが「空間的忘却(Spatial Forgetting)」と「時間的ドリフト(Temporal Drifting)」という問題だった。
難しそうな名前だけど、要はこういうことだ。
- 空間的忘却: 前に進んだら、後ろの景色を忘れてしまう。振り返ったときに別の風景になる
- 時間的ドリフト: 長距離移動すると、映像がどんどん劣化していく。色がおかしくなったり、形が崩れたりする
想像してみてほしい。
苦労して作った風景の中を歩いてみたら、振り返った瞬間に別の世界になってた。
長距離歩いたらぐちゃぐちゃの映像になってた。
……これ、使えなくないですか?
Lyra 2.0はこの2つを解決した。
空間的忘却に対しては、フレームごとの3D幾何情報を保持して、過去のフレームを検索・参照する仕組みを導入している。
時間的ドリフトに対しては「自己拡張訓練」という手法で、モデル自身が出力した劣化データを使って「劣化を修正する方法」を学習している。
結果として、後ろを振り返っても一貫した風景が見える。
長距離を移動してもクオリティが落ちない。
「当たり前じゃん」って思うかもしれないけど、これを実現できたのがLyra 2.0だということだ。
ロボットをシミュレーション環境として配置(Isaac Sim連携)
ここが技術者向けの話になるけど、かなり面白い。
Lyra 2.0で生成した3DシーンはNVIDIA Isaac Simに直接エクスポートできる。
Isaac Simはロボットの物理シミュレーション環境だ。
つまり、写真1枚から作った3D空間にロボットを配置して、そこで歩行テストや衝突回避のシミュレーションができるということになる。
これまでロボット研究者が手動で3D環境を構築していた作業を、画像1枚から自動生成できるようになる可能性がある。
クリエイター的にはピンとこないかもしれないけど、「画像生成AIが作った世界でロボットが動く」って、相当SFな話だと思う。
技術の話はここまでにして、いよいよ「実際にどう試すか」に入っていこう。
Lyra 2.0を実際に試す方法(Hugging Face + GitHub)
必要なもの・動作環境
正直に言うと、現時点(2026年4月16日)ではコードが公開された直後で、セットアップドキュメントがまだ整備中の状態だ。
ここは「いますぐ試せる!」とは言えない。
ただし、論文の情報からわかっている動作環境はこうなっている。
- GPU: NVIDIA製の高性能GPU(学習にはGB200が使われている。推論にもそれなりのVRAMが必要と推測される)
- Python環境: 必須(リポジトリの99.8%がPythonコード)
- ライセンス: Apache 2.0(ソースコード。モデルウェイトは別途確認)
現実的には、ローカルで動かすにはVRAM 24GB以上のGPU(RTX 4090やA6000クラス)が必要になる可能性が高い。
「ハードル高いな」って思った人、その感覚は正しい。
でも、環境を用意できる人にとっては、これがフルオープンで使えるというのは相当な価値だ。
モデルのダウンロード手順
モデルはHugging Faceで公開されている。

ダウンロードにはHugging Face CLIを使う。
pip install huggingface_hub
huggingface-cli download nvidia/Lyra-2.0ソースコードはGitHubから取得する。
git clone https://github.com/nv-tlabs/lyra.git
cd lyra/Lyra-2具体的なインストール手順やrequirements.txtの内容は、リポジトリ内のLyra-2ディレクトリに今後追加されていく予定だ。
入力画像の準備と推奨サイズ
Lyra 2.0の内部処理は832x480ピクセルの解像度で統一されている。
入力画像もこのアスペクト比(約16:9)に合わせるのがベストだろう。
画像生成AIで入力画像を作る場合のポイントをまとめておく。
- アスペクト比: 16:9に近い横長がおすすめ
- 解像度: 832x480以上を推奨(内部でリサイズされる)
- 被写体: 風景・空間が中心の画像が向いている。人物のアップなどは不向き
- 奥行き: パースがしっかりした画像のほうが3D変換の精度が上がりやすい
環境が整ったら、次はどんな絵を入力するかだよね。
ここからがプロンプト画伯的に一番ワクワクする話だ。
Lyra 2.0 × 画像生成AI -- クリエイターへの応用アイデア
Stable DiffusionやMidjourneyの画像をワールド化するワークフロー
ワークフローはシンプル。
- Stable Diffusion / Midjourney / DALL-E等で風景画像を生成する
- 16:9にトリミングして832x480以上に調整する
- Lyra 2.0に入力してカメラ経路を設定する
- 3Dワールドとして探索する
これで「プロンプトで作った世界の中を歩く」という体験が、個人のPC上で実現する。
今まで: 画像生成→眺める→終わり。
Lyra 2.0以降: 画像生成→その世界に入る→歩き回る。
コマンド4ステップだよ、これ。
クリエイターが試してみたい5つの使い方
「具体的に何に使えるの?」って思ってる人のために、アイデアを5つ出しておく。
- ファンタジー世界のウォークスルー動画を作る -- Midjourneyで生成したファンタジー風景を入力して、その世界を歩き回る動画をSNSに投稿する。没入感のあるコンテンツとして映える
- 建築パースの簡易プレビュー -- AI生成した建物の外観イメージを3D化して、周囲を歩き回るプレビューを作る。本格的な3Dモデリングなしでクライアントにイメージを伝えられる
- ゲーム背景のプロトタイプ -- コンセプトアートを入力して、実際にその空間を探索する。ゲームデザイン初期段階の「空間の手触り」を確認するのに使える
- AIアートのポートフォリオを3D体験にする -- 静止画のポートフォリオを「歩き回れる空間」として見せる新しい展示方法。オンラインギャラリーとしてかなり面白い
- 物理シミュレーション用の環境生成 -- Isaac Simとの連携を使って、生成した空間にロボットやオブジェクトを配置するシミュレーション。研究目的だけでなく、クリエイティブな実験としても面白い
センスじゃない、言語化だ。
どんな世界観を作りたいかを言葉にして、その世界に実際に入れる時代になってきた。
まとめ -- NVIDIA Lyra 2.0が画像生成AIの「次の遊び場」になる理由
NVIDIA Lyra 2.0は、画像1枚から探索可能な3Dワールドを生成するオープンソースAIだ。
正直、「画像を3Dにする」系のツールはこれまでもあったけど、「歩き回れる」「後ろを振り返れる」「長距離移動しても破綻しない」というレベルのものは初めてだ。
しかもオープンソース。
Google Genie 3が限定公開で手が届かない中、NVIDIAがApache 2.0でソースコードを全部公開してくれた。
まずやることは2つだけ。
- GitHubのリポジトリをスターして動向を追う(
git cloneはまだドキュメント整備待ちでOK) - 入力用の素材を今のうちに作り始める(16:9の風景画像を数枚生成しておく)
リポジトリを眺めるだけなら今すぐ5分でできるし、入力画像を作っておけば環境が整った瞬間に試せる。
「プロンプトで作った絵の中を歩く」。
この体験を、ぜひ自分の手で試してみてほしい。
- 5
- 0

元デザイナー → AI画像職人。絵心ゼロだったけどプロンプト極めたらなんとかなった。「センスじゃない、言語化だ」 使えるプロンプト&失敗例を晒していく




こちらもおすすめ
-
コードを読まないAIエンジニア
- 8
- 0
-
プロンプト画伯
- 10
- 0
-
- 1
- 0
-
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 2
- 0
-
- 4
- 0
-
- 4
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
- 2
- 0
-
- 4
- 0
-
- 3
- 0
-
- 1
- 0
-
- 3
- 0
-
- 3
- 0
-
- 3
- 0
-
- 3
- 0
-
AI集客@ルイ
- 4
- 0














AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます