
動画からオブジェクトを消したことありますか?
「人物を消したのに影だけ残る」「物が宙に浮いたまま」「コップを消したら支えていた手だけ不自然に残る」——あのいらっとする感じ、地味にストレスたまりますよね。
RunwayやProPainterで格闘した経験があるなら、今回の話は刺さると思います。
Netflixが2026年4月にオープンソースで公開した動画オブジェクト削除AI「VOID」(Video Object and Interaction Deletion)、これが異次元なんですよ。
正直、見たとき「ついにここまで来たか」と思いました。
VOIDが普通のツールと何が違うかというと、消した物体が引き起こしていた物理的な相互作用まで自然に処理するという点です。
たとえば、人がトレイを持っている動画から人を消すと、トレイが自然に落下する。
影が消え、反射が消え、物理法則に従った「もしその物体が最初からなかったら」という反事実の映像を生成するんです。
しかもApache 2.0ライセンスで商用利用可能。
Netflix VOID modelの仕組みから実際の動かし方まで、エンジニア目線で解説していきます。
Netflix VOIDとは何か - 動画オブジェクト削除AIの新基準
従来の動画インペインティングの限界
まず従来のツールが何をやっていたかから整理しましょう。
従来の動画インペインティング(video inpainting)ツールは、基本的に「消す/消さない」の2値マスクで動作していました。
物体を消して背景で埋める。
やっていることはシンプルで、それゆえに限界も明確でした。
たとえば、テーブルの上にコップを置いている人を消した場合、従来の動画オブジェクト削除 AIだとコップが宙に浮いたままになる。
影は残り、反射は中途半端に消え、「消したはずなのに不自然な痕跡が残る」という問題が常につきまとっていたんです。
これ、実際にやってみると本当に頭を抱えますよね。フレーム単位で手作業修正するしかなくて、数秒のシーンに数時間溶けていく。
VOIDはここに正面から取り組んでいます。
物体を消すだけでなく、その物体が存在することで生じていた物理的相互作用(影、反射、衝突、支持関係)まで含めて「なかったこと」にする。
これが「Video Object and Interaction Deletion」の名前の由来です。
Netflix VOID modelとRunwayの比較 - 人間評価で64.8% vs 18.4%
数字で見ると差は歴然です。
25名の人間評価テストで、VOIDの preference score は64.8%。
対するRunwayは18.4%。
3倍以上の差がついています。
これ、ちょっと想像してみてください。10人が動画を見て「こっちが自然」と判断したとき、VOIDを選ぶ人が6〜7人、Runwayを選ぶ人が2人以下。それくらいの差です。
この差が生まれる最大の要因が、VOIDの「物理インタラクション認識」です。
Runwayを含む既存ツールは、マスク領域を背景で埋めることには長けていますが、消した物体と周囲の物理的関係を理解していません。
VOIDは後述するQuadmask(4値マスク)とVLM(Vision Language Model)による因果関係分析で、この問題を構造的に解決しています。
では、この仕組みがどう動いているのか。ここからが本題です。
VOIDのコア技術 Quadmask - 4値マスクで物理インタラクションを制御する仕組み
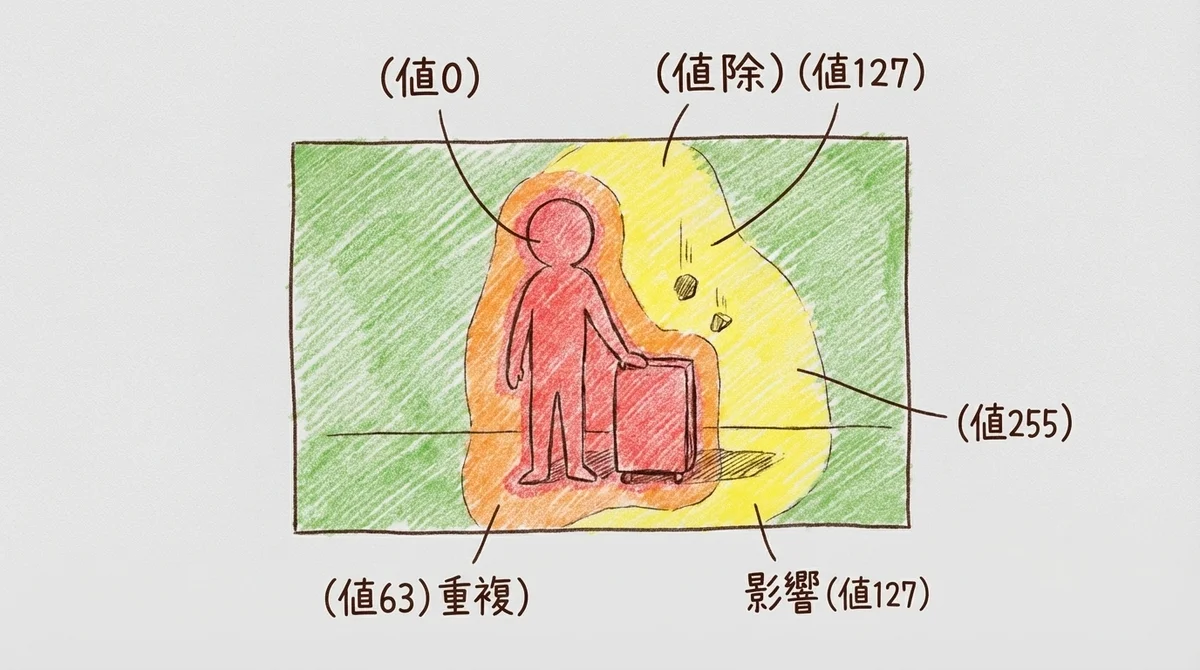
VOIDのアーキテクチャを理解するうえで、最も重要な概念がQuadmask(4値マスク)です。
「4値マスク?」って思いますよね。従来の「消す/消さない」の2択に対して、VOIDは4つの状態を使い分けます。いわば「消す」「消す(境界部分)」「影響を受けて変化する」「そのまま」の4段階です。
なぜ4段階が必要なのか——それは、物体を消した「後」の世界を物理的に正しく再構成するためです。「消す」だけを伝えるのでは、その物体が支えていたもの、落としていた影、写り込んでいた反射をどう処理すればいいかをモデルが判断できません。この4つの区別があって初めて、拡散モデルに「次に何が起きるか」を正しく伝えられるんです。
ここで特に重要なのが値127の「影響領域」です。
人がトレイを持っているシーンで人を消す場合、トレイは「影響領域」としてマークされます。
すると拡散モデルは、トレイを「支持を失った物体」として扱い、物理的に妥当な落下アニメーションを生成するわけです。
つまり、「消す」だけじゃなくて「消したせいで何が変わるか」までモデルに教えてあげている。これが他のツールとの根本的な違いです。
VOIDはこのQuadmaskを使って、物体が最初から存在しなかった場合の映像(反事実ビデオ)を生成します。この「反事実ビデオ」の生成精度こそが、VOIDが既存の動画オブジェクト削除 AIを大きく上回る理由です。
VLMによる影響領域の自動検出
「でも、影響領域って誰が決めるの?」って疑問が当然出てきますよね。
毎回手動でマスクを描くとしたら、それはそれで面倒な話です。
ここで活躍するのがVLM(Vision Language Model)です。
VOIDのパイプラインではGoogle AI API経由でGemini(公式リポジトリでは推奨モデルとしてGeminiを使用)がシーンを分析し、削除対象の物体が周囲にどのような物理的因果関係を持っているかを推論します。
「この人はトレイを支えている」「この物体は影を落としている」といった関係性をVLMが特定し、影響を受ける領域をQuadmaskの値127に割り当てる。
セグメンテーション自体はMeta製のSAM2が担当しています。
つまり、パイプライン全体の流れはこうなります。
- ユーザーが削除したいオブジェクトを選択
- Gemini(Google AI API経由)が物理的因果関係を分析し、影響を受ける領域を特定
- SAM2がセグメンテーションとマスク生成を実行
- Quadmaskで拡散モデルの生成を制御
- 必要に応じてPass2で形状を安定化
単体のモデルではなく、VLM + セグメンテーション + 拡散モデルのパイプラインとして設計されている点が、VOIDの設計思想として面白いところです。
Geminiが「なぜこのオブジェクトは影響を受けるか」を言語的に推論してくれるので、あいまいな物理関係も適切に処理できる。この組み合わせ方、なかなかうまいなと思います。
では、この後処理の品質を担保するもう一つの仕掛けが2パスアーキテクチャです。
2パスアーキテクチャ - CogVideoXベースのベース修復と時間的一貫性の確保
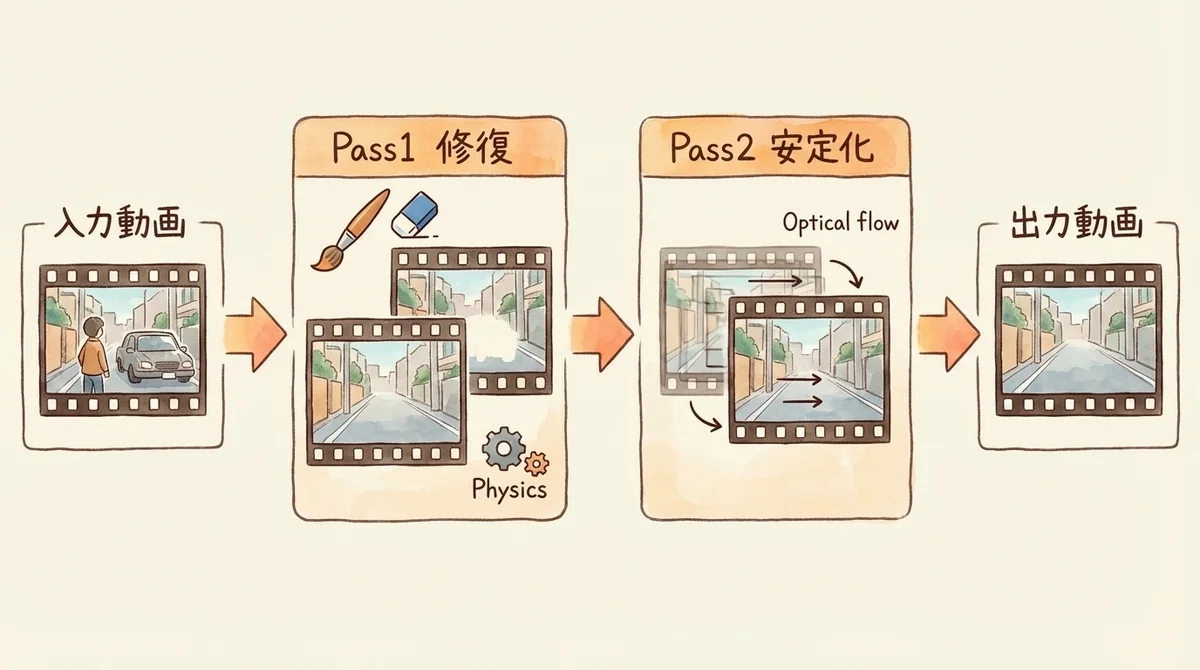
Pass1: 物理的に妥当な反事実ビデオの生成
VOIDのベースモデルは、Alibaba製のCogVideoX-Fun-V1.5-5b-InP(50億パラメータ)です。
3D Transformerアーキテクチャを採用しており、入力解像度は384x672、最大197フレームに対応しています。
Pass1では、Quadmaskに基づいて物理的に妥当な「反事実ビデオ」を生成します。
つまり「最初からその物体が存在しなかった場合の映像」を生成するわけです。
メモリ効率化のための量子化が適用されており、チェックポイントはvoid_pass1.safetensorsとして提供されています。
Pass2: 光学フロー補正による形状安定化
Pass2はオプションですが、実用上はかなり重要です。
「なんかフレーム間で物体の形がじわじわ変わる」という現象、動画生成AIを触ったことがある人なら心当たりがあると思います。
拡散モデルには「object morphing」という既知の失敗モードがあります。
フレーム間で物体の形状が微妙に変化してしまう現象で、特に動画生成では致命的な問題です。
Pass2はこのmorphingを検出した場合に、フローベースのワープノイズ(flow-based warped noise)で推論を再実行し、時間的な形状一貫性を確保します。
チェックポイントはvoid_pass2.safetensorsで、Pass1だけでも動作しますが、品質を追求するならPass2の適用が推奨されます。
2パス構成にすることで、「物理的に正しいかどうか」と「時間的に安定しているかどうか」を分離して解決している。この設計の合理性が好きです。
さて、「実際に動かすにはどうすればいいか」という話に入りましょう。ここはかなり現実的な話になります。
実際に動かすには - VRAM要件とセットアップ手順
ハードウェア要件: VRAM 40GB以上の壁
正直に言います。
個人のローカル環境で動かすのは現状かなり厳しいです。
VRAM 40GB以上が必要で、NVIDIA A100が推奨環境です。
RTX 4090(24GB)では足りません。
これは50億パラメータのCogVideoXベースモデルに加えて、動画フレーム全体を処理する3D Transformerの特性上、避けられない要件です。
現実的な対処法
「持ってない」「そんなGPU買えない」——それが普通の反応ですよね。
VRAM 40GBのGPUを個人で持っている人は少ないので、現実的な選択肢を整理します。
- Google Colab: 公式でColabノートブックが提供されています。A100ランタイムを使えば動作可能
- HuggingFace Spaces: デモが公開されており、ブラウザから試せます(https://huggingface.co/spaces/sam-motamed/VOID)
- クラウドGPU: AWS p4d/p5インスタンス、Lambda Cloud、RunPod等でA100を時間課金で利用
まずはHuggingFace Spacesのデモで挙動を確認してから、本格的に使うかどうか判断するのが合理的です。
ブラウザを開いてURLを貼るだけなので、今この記事を読みながらでも試せます。
セットアップ手順
ローカルまたはクラウドGPUで動かす場合の手順を整理します。
# 依存関係のインストール
pip install -r requirements.txt
# SAM2を別途インストール
git clone https://github.com/facebookresearch/sam2.git
cd sam2
pip install -e .
cd ..
# ベースモデルのダウンロード
huggingface-cli download alibaba-pai/CogVideoX-Fun-V1.5-5b-InP
# VOIDチェックポイントのダウンロード
huggingface-cli download netflix/void-model
# 推論の実行
python inference/cogvideox_fun/predict_v2v.py \
--config config/quadmask_cogvideox.py入力データは以下のディレクトリ構造で準備します。
my-video/
input_video.mp4 # ソース動画
quadmask_0.mp4 # 4値マスク動画
prompt.json # {"bg": "削除後のシーン説明"}prompt.jsonのbgフィールドには、オブジェクト削除後のシーンを自然言語で記述します。
これが拡散モデルへの生成ガイドになります。
なお、VLMによる自動パイプラインを使う場合はGEMINI_API_KEYの設定が必要です。
GeminiがGoogle AI API経由でシーン解析と影響領域の特定を担当するためです。
学習データとライセンス - Apache 2.0で商用利用はどこまでOKか
Google Kubric + Adobe HUMOTOの学習データ構成
VOIDの学習には2つのデータセットが使われています。
- Google Kubric: 合成データセット。物理シミュレーションで生成されたシーンのペアデータ
- Adobe HUMOTO: Adobe Researchが提供する、人間と物体のインタラクションをモーションキャプチャしたデータセット。VOIDではBlenderで物理再シミュレーションを行い、反事実データを生成して学習に利用している
学習に使われるのは「paired counterfactual removal examples」、つまり入力ビデオ・Quadmask・正解の反事実出力のトリプレットです。
「物体がある状態」と「物体がない状態」のペアが正解データとして存在するため、物理的に正しい削除結果を学習できるわけです。
なるほどと思ったのがここで、物理的正しさを「評価指標」で後から計測するのではなく、学習データ設計の段階で担保しているんですよ。物理シミュレーターで反事実を生成してトリプレットにする。それがQuadmaskのコンセプトと一貫していて、設計として一貫性があります。
Apache 2.0ライセンスの実務的な意味
VOIDはApache License 2.0で公開されています。
これはエンジニアにとって非常に重要なポイントです。
- 商用利用: OK
- 改変: OK
- 再配布: OK(ライセンス表示は必要)
- 特許権の明示的付与あり
ただし、注意点が1つあります。
ベースモデルのCogVideoX-Fun-V1.5-5b-InPはAlibaba製であり、こちらのライセンスも確認が必要です。
VOID自体がApache 2.0でも、ベースモデルのライセンスが商用利用に制約をかけている可能性があります。
実務で組み込む場合は、VOIDのライセンスだけでなく、ベースモデル側のライセンスも必ず確認してください。
VOIDが変える動画編集の未来 - 映像制作ワークフローへのインパクト

VFX・ポストプロダクションへの影響
VOIDが実用レベルに達すると、映像制作のワークフローが大きく変わる可能性があります。
現在のVFXワークフローでは、不要な物体の除去はAfter EffectsやNukeで手作業に近い形で行われています。
フレーム単位の調整が必要で、数秒のシーンに数時間かかることも珍しくありません。
ここが自動化されるインパクトはかなり大きいです。特に物理インタラクションまで自動処理される点は、手作業では最も時間がかかる部分だけに、「あの数時間が消える」という話です。
VOIDのアプローチが成熟すれば、この工程を大幅に効率化できます。
今後の注目ポイント
現時点の制約と、今後の発展として注目すべきポイントを整理します。
- 解像度の向上: 現在の入力解像度384x672は実用には物足りない。高解像度対応が進むかどうか
- VRAM要件の緩和: 量子化や蒸留による軽量化で、コンシューマーGPUで動くようになるか
- リアルタイム処理: 現状はオフライン処理。ストリーミング対応の可能性
- コミュニティの発展: Apache 2.0でOSS化されたことで、コミュニティによる改善が期待できる
個人的に最も注目しているのは、このQuadmaskという概念の汎用性です。
「削除対象」だけでなく「影響領域」を明示的にモデルに伝えるという設計は、動画インペインティングに限らず、さまざまな動画編集タスクに応用できる可能性があります。
Apache 2.0で公開されたということは、コミュニティがこのアーキテクチャをベースに拡張できるということでもあります。半年後にどんなforkが出てくるか、それだけでも楽しみですね。
まとめ
Netflix VOID modelは、動画オブジェクト削除AIにおいて「物理的正しさ」という新しい基準を示したモデルです。
Quadmask(4値マスク)による物理インタラクションの明示的な制御、VLM + SAM2 + 拡散モデルのパイプライン設計、そしてApache 2.0でのオープンソース公開。
技術的にも、ライセンス的にも、エンジニアが注目すべき要素が揃っています。
VRAM 40GBという要件は現時点では大きな壁ですが、まずはHuggingFace Spacesのデモを開いてみてください。
百聞は一見にしかずで、「宙に浮くはずのトレイが落下する」映像を一度見ると、このモデルが何をやっているかが一瞬で腹落ちします。
デモのURLはこちら: https://huggingface.co/spaces/sam-motamed/VOID
動画AIの世界は急速に進化しています。
VOIDがオープンソースで公開されたことで、この分野の発展がさらに加速するのは間違いありません。
今のうちにQuadmaskの概念を押さえておくと、この先出てくる関連ツールや論文が読みやすくなるはずです。
リソースまとめ
- 3
- 1

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 1
- 0
-
プロンプト画伯
- 3
- 0
-
- 4
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 4
- 0
-
- 2
- 0
-
- 2
- 0
-
- 2
- 0
-
- 2
- 0
-
- 4
- 0
-
- 3
- 0
-
- 1
- 0
-
- 5
- 0
-
- 3
- 0
-
- 3
- 0
-
- 3
- 0
-
- 3
- 0
-
AI集客@ルイ
- 4
- 0
-
AI脱社畜
- 4
- 0
-
- 3
- 0
-
 ゆい@海外AI副業ラボ
ゆい@海外AI副業ラボ
- 5
- 0















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます