
こんにちは、もるふぉです。
10年以上ソフトウェアエンジニアとしてコードを書いてきましたが、今はClaude Codeを相棒に「コードを書かない開発スタイル」を実践しています。
LLMアプリを開発していると、こんな経験ないですか。
プロンプトをあれこれ書き直して、RAGのチャンク数を変えて、Few-Shotの例を入れ替えて。
何時間も試行錯誤しているのに、性能が頭打ちになって「これ以上どこをいじればいいんだ…」と途方に暮れる。
あの詰まった感じ、地味にストレスたまるんですよね。
今回紹介するStanford大学らの論文「Meta-Harness」は、そのフラストレーションの根本原因を突き止め、解決策を提示しています。
プロンプトだけじゃなく、RAGのパイプラインも、前処理コードも、全部ひっくるめた「ハーネス」をAIエージェントが自動で最適化する。
結果、既存手法を+7.7pt上回り、しかもコンテキストトークンは4分の1に削減。
これ、マジで面白いんですよ。
TL;DR — 3行でわかるMeta-Harness
- LLMの性能を決めるのはモデル単体ではなく「ハーネス」(プロンプト+RAG+前処理コードの総体)であり、同じモデルでも本論文のLawBenchで7.0%→45.0%(約6.4倍)の性能差が出る
- Meta-Harnessは、Claude Code(Opus 4.6)をエージェントとして使い、ハーネス全体を自動で探索・改善するフレームワーク
- テキスト分類で+7.7pt、数学推論で+4.7pt、エージェントタスクでは小型モデル使用時に全手法トップを達成
LLMの性能は「ハーネス」で決まる
「モデルを良くすれば性能が上がる」——これは半分しか正しくありません。
実際には、モデルに何をどう渡すかという「ハーネス」の設計が、最終的なアウトプットの品質を決定的に左右します。
ハーネスとは何か — プロンプト・RAG・コードの総体
Meta-Harness論文が定義する「ハーネス」は、プロンプトテンプレートだけではありません。
モデルに提示する情報の保存・取得・表示方法を決定するコード全体を指します。
具体的には以下のすべてが含まれます。
- プロンプトテンプレート(システムプロンプト、Few-Shotの例)
- RAGパイプライン(検索クエリの構築、リランキング、取得件数)
- 前処理・後処理コード(入力の正規化、出力のパース)
- ルーティングロジック(タスクの種類に応じた処理分岐)
- エラーハンドリングやリトライ戦略
つまり、LLMアプリケーションの「モデルの重み以外のすべて」がハーネスです。
自分がClaude Codeで開発するときも、プロンプトの書き方だけじゃなく、CLAUDE.mdの構成、ファイルの渡し方、タスクの分割粒度——これら全部がハーネスに該当するわけですね。
同じモデルでもハーネス次第で約6.4倍の性能差
論文の中で特にインパクトがあるのが、「同一モデルでハーネスを変えただけでパフォーマンスが大きく変わる」という実験結果です。
例えば、215クラスの法律文書分類タスク(LawBench)では以下の結果が出ています。
Zero-ShotからMeta-Harnessまで、モデルは同じGPT-OSS-120Bです。
変わったのはハーネスだけ。
7.0%から45.0%へ、約6.4倍の差が生まれています。
想像してみてください。
同じモデルを使っているのに、ハーネスの設計次第で正解率が6倍以上変わる。
これを見ると「プロンプトエンジニアリング」という言葉の射程がいかに狭いかがわかります。
本当に最適化すべきは、プロンプトを含む「ハーネス全体」なんですよ。
でも、「それはわかった、じゃあどう最適化すればいい?」という問いが当然出てきますよね。
そこに人間の手作業では越えられない壁があって——次のセクションでその話をします。
手動ハーネス設計の限界
では、ハーネスが重要だとわかったところで、なぜ人間が手で設計するのでは不十分なのか。
人間が直感で設計するハーネスの問題点
現状、ほとんどのLLMアプリケーションのハーネスは人間が設計しています。
「このプロンプトが良さそう」「Few-Shotは5つくらい入れておこう」「RAGはコサイン類似度で上位3件を取得しよう」——こういった設計判断を、エンジニアの直感と経験に基づいて行っているわけです。
これ、まさにさっき言った「何時間いじっても頭打ち」の原因なんですよ。
3つの問題があります。
- 探索範囲が狭い: 人間が試せるハーネスのバリエーションはせいぜい数十パターン。
本来の探索空間は、プロンプト文面 × RAG設定 × 前処理ロジック × ルーティング規則の組み合わせで、とてつもなく広い。
- 因果推論が難しい: 「Few-Shotの例を変えたら性能が上がった」とき、本当にFew-Shotが効いたのか、それとも他の変更が効いたのか、人間には判断しづらい。
- 全タスクの実行トレースを追えない: 数百件の評価タスクそれぞれで「なぜ失敗したか」を分析するのは、人間には物理的に無理です。
既存のテキスト最適化手法が「圧縮しすぎる」問題
「じゃあ自動最適化すればいいでしょう」という発想は以前からあります。
DSPy、OPRO、TextGrad、AlphaEvolveといった手法が提案されてきました。
しかし、これらには共通の限界があります。
プロポーザー(次のハーネス候補を提案するモデル)に渡す情報が「圧縮されすぎている」のです。
具体的には、これらの手法は以下の情報しかプロポーザーに渡しません。
- スカラースコア(「正解率42%」のような数値だけ)
- 短い要約(「分類精度が低い」程度のテキスト)
ここで面白いのが、Meta-Harnessの ablation(除去実験)の結果です。
注目してほしいのは、「スコア+要約」が「スコアのみ」より最高スコアが低い点です。
要約すると逆に性能が落ちるんですよ。
これ、意外じゃないですか。
「丁寧に情報を整理して渡した方が良い判断ができるはず」という直感が完全に裏切られています。
人間が書いた要約が「重要ではない情報を強調し、重要な情報を落とす」バイアスを持っているため、プロポーザーの判断を歪めてしまうわけです。
これは自分もClaude Codeを使っていて実感があります。
コンテキストを「要約して渡す」より「生のログをそのまま渡す」方が、正確な修正案が返ってくる。
Meta-Harnessはこの「生のトレースを全部渡す」という発想を、フレームワークとして徹底的に実装しています。
その仕組みを次で詳しく見てみましょう。
Meta-Harnessの仕組み — エージェントがハーネスを自動改善する
ここからが本題です。
Meta-Harnessのハーネスエンジニアリング自動化の仕組みを解説します。
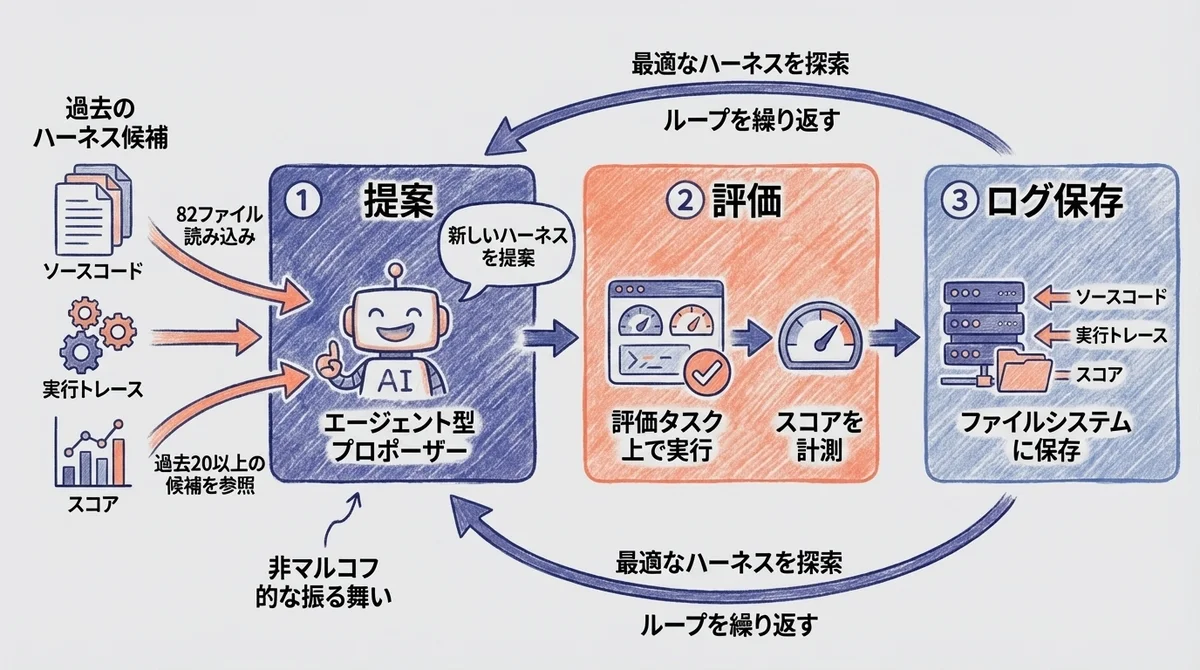
アーキテクチャ:提案→評価→ログのループ
Meta-Harnessの基本構造はシンプルな3ステップのループです。
- 提案(Propose): エージェント型プロポーザーが、過去のハーネス候補のソースコード・実行トレース・スコアをすべて読み込み、新しいハーネスを提案する
- 評価(Evaluate): 提案されたハーネスを評価タスク上で実行し、スコアを計測する
- ログ保存(Log): ソースコード・実行トレース・スコアをすべてファイルシステムに保存する
数式で表現すると以下のようになります。
H* = arg max_H E[x~X, τ~p_M(H,x)] r(τ, x)- H: ハーネス(状態を持つプログラム)
- M: 固定されたLLMモデル
- X: タスクの分布
- τ: ロールアウト軌跡(実行トレース)
- r: 報酬関数
要するに「モデルを変えずに、周辺コードだけ変えてスコアを最大化する」という定式化です。
ポイントは「モデルMは固定」という点です。
モデルの重みは一切変更せず、ハーネスHだけを最適化する。
これが従来のファインチューニングとの根本的な違いです。
エージェント型プロポーザー(Claude Code Opus 4.6)の動作
ここが一番アツいところです。
Meta-Harnessのプロポーザーには、Claude Code(Opus 4.6)が使われています。
各イテレーションでの動作を具体的に見てみましょう。
- 中央値で82ファイルを読み込む
- ファイルの内訳: ハーネスのソースコード41%、実行トレース40%、スコアや要約6%、その他13%
- 1イテレーションあたり約1,000万トークン(10 MTok)のコンテキストを処理
従来手法が1イテレーションあたり0.026 MTok程度だったのに対して、Meta-Harnessは桁違い(約385倍)のコンテキストを使っています。
つまり、過去の試行を圧縮せずそのまま読み込んで、そこから洞察を引き出しているわけです。
さらに重要なのが「非マルコフ的」な振る舞いです。
従来の手法は直前の候補のスコアだけを見て次の候補を提案します(マルコフ的)。
Meta-Harnessのプロポーザーは、過去20以上の候補のソースコードと実行トレースを同時に参照して提案を行います。
つまり「イテレーション3で試した方法Aはダメだったが、イテレーション7の方法Bと組み合わせたらいけるかもしれない」という推論ができるわけです。
Claude Codeを使っている人なら、この感覚はわかるはずです。
CLAUDE.mdに過去の試行結果を蓄積して、次の判断に活かす——Meta-Harnessはそれをシステムとして自動化したものと言えます。
なぜ「実行トレース」へのフルアクセスが決定的なのか
先ほどのablation結果をもう一度見てください。
スコアのみ→中央値34.6、完全トレース→中央値50.0。
この差は+15.4ptです。
なぜここまで差がつくのか。
論文のTerminalBench-2での実際の軌跡分析が示唆的です。
- イテレーション1-2: 構造的なバグ修正とプロンプト編集を同時にやろうとして回帰が発生
- イテレーション3: 実行トレースから「共有される有害なプロンプト書き換え」を因果的に識別
- イテレーション4-6: 修正ロジックを試すも継続する回帰
- イテレーション7: 戦略を根本から転換。「修正ロジックではなく、純粋に加法的なアプローチに切り替える」と判断し、環境ブートストラップという新手法を発見
- イテレーション8: 直交する修正案を組み合わせて最終的な改善を達成
ここで起きているのは、因果推論→仮説検証→戦略転換→改良案の合成、というエンジニアリングの思考プロセスそのものです。
スカラースコアだけでは「なぜ失敗したか」がわからないので、この種の推論は不可能です。
完全な実行トレースがあるからこそ、プロポーザーは「何が悪いか」を特定し、「何を変えるべきか」を正しく判断できる。
仕組みはわかりました。
では、実際に何がどれだけ改善したのか——数字を見ていきましょう。
実験結果 — 何がどれだけ改善したか
ここからは具体的な数字を見ていきます。
テキスト分類で+7.7pt、コンテキストトークン4分の1に削減
まずはオンラインテキスト分類の結果です。
3つのデータセット(法律文書215クラス、症状→疾患22クラス、化学反応180クラス)で評価しています。
Meta-Harnessは既存最良のACEを平均+7.7pt上回っています。
しかも、コンテキストトークンは50.8K→11.4Kと約4分の1に削減されています。
「性能が上がって、コスト(トークン消費)は下がる」——これがハーネス最適化の真価です。
プロンプトに例を詰め込むのではなく、「どの例をどう選んで提示するか」のロジック自体を最適化するから、こういう結果になるわけですね。
さらに、9つの未見データセットへの汎化(OOD評価)でも+2.9pt改善しており、過学習ではなく汎用的な改善であることが確認されています。
IMOレベル数学推論で+4.7pt(5つの未見モデルで転移)
次に数学推論の結果です。
50万問以上の解答済み問題コーパスから、200個の未見IMOレベル問題に対する検索ハーネスを最適化しています。
+4.7ptの改善自体も重要ですが、もっと重要なのは「5つの未見モデルで転移した」という事実です。
最適化に使ったモデルとは別の5つのモデルでも、同じハーネスで性能が向上した。
つまり、良いハーネスはモデルに依存しないんですよ。
これはハーネスエンジニアリングの投資対効果が非常に高いことを意味します。
一度良いハーネスを見つければ、モデルをアップグレードしても引き続き使える。
プロダクトのモデルを乗り換えるたびにプロンプトを書き直す、あの手間がなくなるわけです。
TerminalBench-2でHaiku使用時に全手法トップ
エージェント型タスク(TerminalBench-2、89個の困難なコマンドラインタスク)の結果も興味深いです。
Claude Opus 4.6の場合:
Claude Haiku 4.5の場合:
Opus 4.6では手動設計のForgeCodeに及ばないものの、Haiku 4.5では全手法トップです。
注目すべきは、Meta-Harnessだけが「自動設計」であること。
他の手法はすべて人間が設計したハーネスです。
小型モデルほどハーネスの質が性能に直結するため、自動最適化の恩恵が大きくなるという示唆も興味深いですね。
ここまでは数字の話でした。
でも個人的に一番刺さったのは、Meta-Harnessが「どんなハーネスを発見したか」の中身なんですよ。
発見されたハーネスの中身
テキスト分類:8つのパレート最適ハーネス
テキスト分類タスクでは、20イテレーション×2候補=40個のハーネスが探索され、そこから8つのパレート最適ハーネスが発見されました。
パレート最適とは「精度を上げるにはコンテキストを増やすしかない」というトレードオフの最前線にあるハーネスのことです。
具体的には、クラスのサンプル選択戦略やプロンプト構造が大きく異なる8パターンが発見されています。
人間が設計する場合、「全クラスの例を均等に入れる」か「類似度上位k件を入れる」の2パターンくらいしか思いつきません。
Meta-Harnessはそれをはるかに超える多様な戦略を自動で発見したわけです。
数学:4ルート検索ルーター(分野別に検索戦略を変える)
数学推論で発見されたハーネスの構造が特に面白いです。
Meta-Harnessは、問題を4つのカテゴリ(組み合わせ論・幾何・数論・その他)に自動分類し、それぞれに異なる検索戦略を割り当てるルーターを発見しました。
論文のFigure 8に示された構造は、おおむね以下のようになっています。
- 組み合わせ論: BM25で多めに候補を取得→重複排除→リランキングで絞り込み
- 幾何: 固定の参照例+BM25で少数取得(リランキングなし)
- 数論: BM25で中程度の候補を取得→リランキングで厳選
- その他(デフォルト): BM25ベースで、問題の難易度に応じて取得件数を適応的に調整
重要なのは、「分野ごとに検索戦略を変える」というアイデア自体を、人間が指示したのではなくMeta-Harnessが自動で発見したという点です。
全設計選択が探索から自動生成されています。
「言われてみれば確かにそうだけど、自分でそれを思いつけるかというと……」という感じのアイデアが出てくるんですよ。
人間のバイアスの外にある最適解を見つけられるのが、自動探索の強みですね。
エージェント:環境ブートストラップという発見
TerminalBench-2で発見された「環境ブートストラップ」も興味深い知見です。
これは、タスク実行前にサンドボックス環境のOS情報、インストール済み言語、利用可能なパッケージを事前に収集してプロンプトに注入するという手法です。
言われてみれば当たり前に思えるかもしれません。
でも、既存の手動設計ハーネス(Claude Code、Terminus-KIRA等)はこれをやっていなかった。
人間は「環境情報を最初に取得する」ことの価値を過小評価していたわけです。
Meta-Harnessはイテレーション7で、他の修正アプローチが軒並み回帰を引き起こす中、戦略を根本から変えてこの手法を発見しました。
これはまさに「人間には思いつかない、でも理にかなった最適化」の好例です。
では、こうした知見を自分たちの開発にどう活かすか。
現実的な話をします。
エンジニアにとって何が変わるか
ここからは、この論文の知見をどう実務に活かすか考えてみます。
「ハーネスを書く」から「ハーネスの評価基準を設計する」へ
Meta-Harnessが示唆する最大の変化は、エンジニアの役割のシフトです。
従来: プロンプトを手で書く → 試す → 直す → 試す(ハーネスの実装者)
Meta-Harness以降: 評価データセットを設計する → 報酬関数を定義する → 自動探索を回す(ハーネスの評価者)
これはソフトウェアテストにおける「テストを書く側にシフトする」という変化と似ています。
「良いプロンプトを書く力」よりも「良い評価基準を設計する力」の方が重要になる。
自分はClaude Codeを使った開発でも同じ変化を感じています。
コードを書くことより、CLAUDE.mdにどんな制約とルールを書くか(=ハーネスの設計)の方が成果に直結する。
Meta-Harnessはこの流れをさらに推し進め、「ハーネスの設計すら自動化する」世界を見せてくれたわけです。
現時点でできること・制限事項
ただし、今すぐMeta-Harnessを自分のプロジェクトに導入できるかというと、いくつかの制限があります。
制限事項:
プロポーザーとしてClaude Code(Opus 4.6)という非常に強力なエージェントに依存しており、1イテレーションあたり10 MTokというコンテキスト消費は個人やスモールチームには現実的ではないです。
異なるプロポーザーエージェントでの性能変動も未検証です。
今すぐ活かせるポイント:
一方で、論文から得られる「考え方」は今すぐ使えます。
- ハーネス全体を意識する: プロンプトだけでなく、RAG設定、前処理、ルーティングも含めて最適化対象として認識する
- 要約より生ログを渡す: LLMに判断材料を渡す際、要約せずに生の実行トレースを渡す方が良い結果が出る可能性がある
- 分岐戦略を検討する: 「全タスクに同じ処理」ではなく、タスクの種類ごとに異なるハーネスを割り当てるルーター構造を考える
- 評価基準を先に設計する: ハーネスの改善を始める前に、「何をもって良いハーネスとするか」の基準を明確にする
DSPy作者のOmar Khattabが共著者であることも示唆的です。
DSPyがテキストレベルの最適化(プロンプトテンプレート)だったのに対し、Meta-Harnessはコードレベルの最適化(ハーネス全体)へと検索空間を拡張した。
論文はSuttonの「苦い教訓(Bitter Lesson)」を引用しています。
検索空間が到達可能になると、汎用エージェントが手設計を上回る——この法則がハーネス設計にも当てはまることをMeta-Harnessは実証したわけです。
まとめ — ハーネスエンジニアリングの次のステージ
Meta-Harnessの核心を振り返ります。
- LLMの性能はモデルの重みだけでなく「ハーネス」に大きく依存し、同じモデルでもLawBenchで7.0%→45.0%(約6.4倍)の差が出る
- Meta-Harnessは完全な実行トレースへのアクセスが決定的であり、「要約すると性能が落ちる」という直感に反する発見がある
- Claude Code(Opus 4.6)をプロポーザーとして使い、1イテレーション10 MTokという圧倒的なコンテキスト量で、人間には発見できないハーネス構造を自動で見つけ出す
- テキスト分類+7.7pt、数学推論+4.7pt(未見モデルに転移)、エージェントタスクでHaiku使用時に全手法トップ
個人的に一番刺さったのは「要約が害になる」という発見です。
エンジニアとして「情報を整理してから渡す」のが良い習慣だと思い込んでいたけれど、LLMの文脈では生のトレースをそのまま渡す方が正しい判断につながる。
これは自分のClaude Codeの使い方を見直すきっかけにもなりました。
ハーネスエンジニアリングはまだ始まったばかりの分野です。
でも、LLMアプリケーションを開発しているエンジニアにとって、「プロンプトの先にある最適化の世界」を知っておくことは確実にアドバンテージになります。
まず今すぐできることは、自分のLLMアプリの「ハーネスを棚卸しする」ことです。
やることはシンプルで、プロンプト・RAG設定・前処理・ルーティングの4つを紙に書き出すだけ。
「あ、ここはデフォルトのまま放置してたな」「この前処理、本当に必要か?」——そういう気づきが出てきたら、それが最適化の第一歩です。
プロンプトの先にある最適化の世界、ぜひ覗いてみてください。
参考論文: Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, Chelsea Finn. "Meta-Harness: End-to-End Optimization of Model Harnesses." arXiv:2603.28052, 2026.
- 2
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
- 3
- 0
-
 たく
たく
- 1
- 0
-
プロンプト画伯
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
たく
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 4
- 0
-
- 5
- 0
-
- 3
- 0
-
- 5
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます