コードを書かないAIエンジニア@もるふぉです。
ソフトウェアエンジニアとして10年以上開発をしてきましたが、今はClaude Codeを使って「コードを書かない開発」を実践しています。
この記事では、2026年4月に登場したClaude Advisor Strategy(アドバイザー戦略)を解説します。
あなたも、こんな葛藤ありませんか?
「Opusは確かに賢い。でも全部Opusにすると月の請求額が怖くなる。Sonnetにすると複雑なアーキテクチャ判断でたまにこける。かといって両方使い分けるのも面倒くさい」——エージェント開発をやっていると、この「知能とコスト」のジレンマ、地味にしんどいんですよね。
2026年4月9日、Anthropicがそのジレンマをそのまま解決する機能を出してきました。
Claude PlatformへのAdvisor Strategy(アドバイザー戦略)の追加です。
一言でまとめると、Opusの頭脳をSonnetやHaikuのコストで使えるようにする仕組みです。
「そんな都合のいい話が?」と思いますよね。でも数値がはっきり出ているんです。
SWE-bench Multilingualでは、Sonnet+Opusアドバイザーの組み合わせが単独Sonnetより2.7パーセントポイント高いスコアを出しつつ、コストは11.9%削減という結果が出ています。
性能が上がってコストが下がる。普通は相反する2つの指標が同時に改善しているんです。
この記事では、Advisor Toolの仕組みからAPI実装、コスト制御、使いどころの判断基準まで、エンジニアが知りたいポイントを一通り解説していきます。
Claude Advisor Strategyとは?発表の背景
Opusの知能をもっと安く使いたいという課題
エージェントワークロードを触っている方なら肌感としてわかると思うんですが、実際にOpus級の判断が必要な場面ってタスク全体の中の一部なんですよね。
大半の処理は「Sonnetで十分」です。
でも現実は——Sonnet単体だと複雑なアーキテクチャ判断やエッジケースの処理で品質が落ちる場面がある。かといって全部Opusにすると予算が厳しい。
この「知能とコストのジレンマ」を解消するのがAdvisor Strategyです。
つまり、「Sonnetを走らせながら、本当に難しい判断ポイントだけOpusに聞く」という構造です。
学術的背景 -- Dimakisらの「Advisor Models」論文
面白いのは、これに学術的な背景があるところなんですよ。
この論文では、小さなオープンウェイトモデルを「アドバイザー」として使い、プロプライエタリなフロンティアモデルに自然言語ガイダンスを与える手法が提案されています。
この論文では、GPT-5のRuleArenaスコアが71%向上、Gemini 3 ProのSWEエージェントタスクのステップが24.6%削減されたと報告されています。
AnthropicのAdvisor Strategyはこの概念を逆方向に応用しています。
より大きなモデル(Opus)をアドバイザーにして、より小さなモデル(Sonnet/Haiku)の判断を引き上げるというアプローチです。
研究ベースで裏付けがある機能なのは、個人的には信頼感がありますね。
では次からいよいよ具体的な仕組みに入ります。
Advisor Toolの仕組み -- ExecutorとAdvisorの役割分担
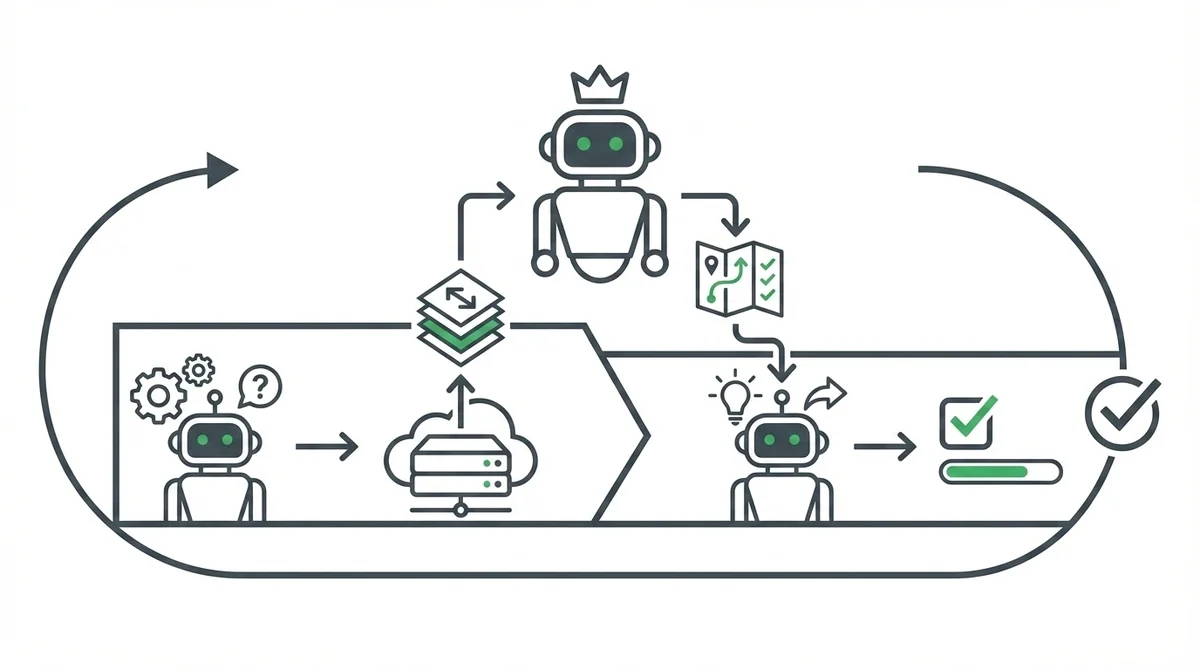
エグゼキューターが判断に迷ったとき何が起きるか
構造としては非常にシンプルで、いわばシニアエンジニアと若手エンジニアのペアプログラミングのような関係です。
- エグゼキューター(Sonnet/Haiku): 実際にタスクを実行するモデル
- アドバイザー(Opus): 難しい判断に直面したときに相談されるモデル
若手(Sonnet)が通常の作業はテキパキ進めて、「これちょっと設計の判断が難しいな」という場面でシニア(Opus)にさっと相談する。シニアは全体のコンテキストを把握した上でアドバイスを出し、若手が方針に沿って作業を続ける。そういう動きです。
エグゼキューターは通常通り処理を進め、複雑な判断が必要な場面に遭遇すると自動的にアドバイザーに相談します。
アドバイザーは会話の全コンテキストを把握した上で計画やガイダンスを返し、エグゼキューターがその方針に沿って続行します。
単一APIリクエスト内で完結する設計
「複数モデルの連携というと、クライアント側でAPIコールを何回も管理しないといけないのでは?」と思いますよね。
ここが嬉しいところなんですよ。この一連のやり取りが単一の /v1/messages リクエスト内で完結するんです。
クライアント側で複数のAPIコールをオーケストレーションする必要がありません。
動作フローは4ステップです。
- エグゼキューターが
server_tool_useブロックを発行(name: "advisor",input: {}) - サーバー側でアドバイザーモデルの推論を実行(会話の全トランスクリプトを渡す)
- アドバイザーの応答が
advisor_tool_resultブロックとしてエグゼキューターに返る - エグゼキューターがアドバイスに基づいて生成を継続
外から見ると1回のAPIコールです。
既存のクライアントコードへの組み込みがシンプルで済むのは、実運用面でかなり助かりますね。
モデルの組み合わせ
現時点で対応している組み合わせは以下の通りです。
アドバイザーは現在Opus 4.6のみです。
Opus同士の組み合わせも可能で、セルフレビュー的な使い方ができます。
数値でどう変わるか、次のベンチマーク結果が面白いんですよ。
ベンチマーク結果 -- コスト削減と性能向上の実数値
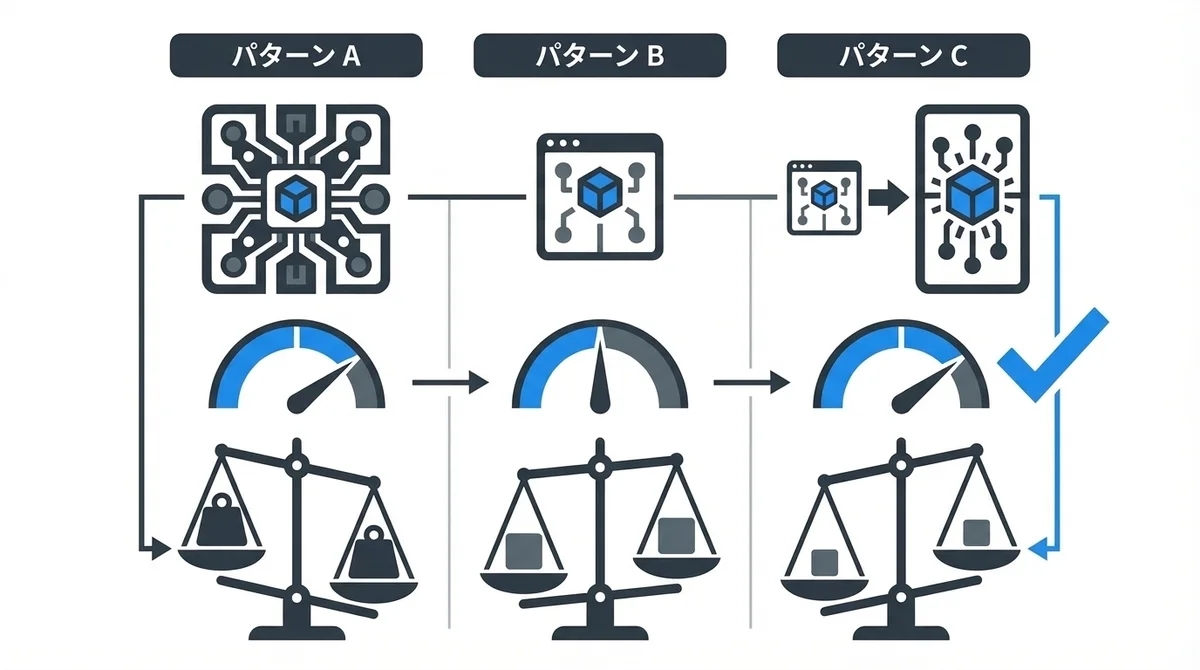
SWE-bench Multilingual:Sonnet+Opus vs 単独Sonnet
「実際の数値を見せてくれ」ということで、Anthropicが公開したベンチマーク結果を見てみます。
SWE-bench Multilingualでの結果がもっとも印象的です。
- Sonnet + Opusアドバイザー: 単独Sonnetより2.7パーセントポイント高いスコア
- コスト: 単独Sonnetより11.9%少ないコスト
正直、最初に見たとき「え?」ってなりました。
性能が上がるのにコストは下がる——通常はトレードオフになる2つの指標が同時に改善しているんです。
これが実現するのは、アドバイザーの出力が非常にコンパクトだからです。
アドバイザーの出力は通常400〜700テキストトークン程度(thinking含めて1,400〜1,800トークン)に収まります。
想像してみてください。エグゼキューターが方向性を見失って試行錯誤しながら余計なトークンを大量消費するより、早い段階でOpusに「こっちの方向で行け」と一言もらった方が、全体のトークン消費が少なく済む。そういう仕組みなんですよ。
コストシミュレーション:3パターン比較表
実際の利用シナリオを想定して、3パターンのコスト感を整理してみます。
特にエージェントワークロード(数十ターン以上の処理)では、Sonnet+Opusアドバイザーが「コスパ最強」のポジションになる可能性が高いです。
数値で確認できたところで、実際に動かしてみましょう。
API実装 -- advisor toolの使い方
ここからは実装の話です。
Advisor Toolは現在ベータ版で、betaヘッダー advisor-tool-2026-03-01 を付与して利用します。
最低限の実装(curlコマンド)
まずは最小構成で動作確認してみましょう。curlコマンド1発で試せます。
curl https://api.anthropic.com/v1/messages \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "anthropic-beta: advisor-tool-2026-03-01" \
--header "content-type: application/json" \
--data '{
"model": "claude-sonnet-4-6",
"max_tokens": 4096,
"tools": [
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6"
}
],
"messages": [{
"role": "user",
"content": "Build a concurrent worker pool in Go with graceful shutdown."
}]
}'ポイントは tools 配列にアドバイザーの定義を追加するだけという手軽さです。
既存のコードに type: "advisor_20260301" と model: "claude-opus-4-6" の定義を1ブロック足すだけ。つまり、既存のエージェント実装に後付けで組み込めます。
type にベータ版の型名 advisor_20260301、model にアドバイザーとして使うモデルを指定します。
Pythonでのマルチターン会話実装
実際のアプリケーションではマルチターン会話になることが多いですよね。
まずは単発リクエストの基本形です。
import anthropic
client = anthropic.Anthropic()
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["advisor-tool-2026-03-01"],
tools=[
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6",
}
],
messages=[
{
"role": "user",
"content": "Build a concurrent worker pool in Go with graceful shutdown.",
}
],
)マルチターンに拡張する場合は、advisor_tool_result ブロックを含むレスポンス全体を次のターンにそのまま渡します。
tools = [
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6",
}
]
messages = [
{"role": "user", "content": "Build a concurrent worker pool in Go with graceful shutdown."}
]
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["advisor-tool-2026-03-01"],
tools=tools,
messages=messages,
)
# advisor_tool_resultブロックを含む全レスポンスを次のターンに渡す
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": "Now add a max-in-flight limit of 10."})
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["advisor-tool-2026-03-01"],
tools=tools,
messages=messages,
)response.content をそのまま assistant ロールに入れるだけです。
アドバイザーの応答ブロックも含まれた状態で次のターンに渡されるので、特別な加工は不要です。
max_usesとcachingでコストを制御する
本番環境ではコスト制御が重要ですよね。
max_uses で1リクエストあたりのアドバイザー呼び出し回数に上限を設定できます。
tools = [
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6",
"max_uses": 3, # 1リクエストあたり最大3回
"caching": {"type": "ephemeral", "ttl": "5m"}, # 3回以上呼ぶなら有効
}
]caching オプションはエフェメラルキャッシュで、同一セッション内で3回以上アドバイザーを呼ぶ場合にコスト効率が良くなります。
TTLは "5m"(5分)または "1h"(1時間)から選択します。
「使いたい場面だけOpusを呼んで、あとは制限をかける」という細かいチューニングができるのは、実際の運用で助かるポイントです。
他ツール(web_search等)との組み合わせ
Advisor Toolは他のツールと並列で定義できます。
tools = [
{"type": "web_search_20250305", "name": "web_search", "max_uses": 5},
{"type": "advisor_20260301", "name": "advisor", "model": "claude-opus-4-6"},
{"name": "run_bash", "description": "Run a bash command", "input_schema": {"type": "object", "properties": {"command": {"type": "string"}}}},
]エグゼキューターはWeb検索やBash実行を行いながら、必要に応じてアドバイザーに相談する複合エージェントを構成できます。
これが1回のAPIコールで完結するのは非常に強力です。
コストの把握という観点で、もう一点抑えておきたい話があります。
課金の仕組み -- iterations配列の読み方
コストを正確に把握するには、レスポンスの usage フィールドの構造を理解しておく必要があります。
ここ、ちょっと注意が必要なので確認しておきましょう。
トップレベルの usage はエグゼキューターのトークンのみを反映します。
アドバイザーのトークン消費は usage.iterations[] 配列の中に type: "advisor_message" として記録されています。
usage.iterations = [
{ type: "message", ... }, // エグゼキューターのトークン
{ type: "advisor_message", ... }, // アドバイザーのトークン
]「なんかコストが想定より多い気がする」となったとき、トップレベルの usage しか見ていないと実態を見誤ります。
iterations[] の中身まで追いかけることで、どのタイミングでアドバイザーが何トークン消費したかを正確に把握できます。
もう一点。max_tokens もエグゼキューター出力にのみ適用されます。
アドバイザーの出力トークンには別の上限が適用されるため、max_tokens を小さく設定してもアドバイザーの応答は制限されません。
課金の構造を把握できたところで、実際に「どこで使うか」の判断基準を整理します。
いつ使うべきか・使わないべきか
効果が高い場面
Advisor Toolが真価を発揮するのは以下のようなケースです。
- 長期的なエージェントワークロード: コーディングエージェント、コンピューター操作、マルチステップリサーチなど。数十ターンにわたる処理で、途中の判断品質が最終結果に大きく影響するケース
- Sonnetを複雑タスクに使っている場合: Opusアドバイザーを付けることで品質が向上し、コストは同等以下に抑えられる
- Haikuで知能をステップアップしたい場合: コストはHaiku単体より上がりますが、Sonnet単体よりは安くSonnet級の品質を実現できる
効果が低い場面
一方で、以下のケースではAdvisor Toolの恩恵は薄いです。
- 単発のQ&A: 計画を立てる必要がないシンプルな質問。アドバイザーを呼ぶオーバーヘッドが無駄になる
- ユーザーがモデルを選ぶpass-throughパターン: APIを単にプロキシしているだけの構成では効果なし
- 毎ターン本当にOpus級の判断が必要な場合: 全ターンでアドバイザーを呼ぶならOpusを直接使った方がシンプルでコスト効率も良い
判断基準はシンプルです。
「タスク全体の中で、Opusが必要な判断ポイントが一部に集中しているか?」
Yesなら Advisor Tool、Noなら素直にOpus単体を選ぶのが良いですね。
使う場面が整理できたところで、実運用前に知っておきたい注意点を確認しましょう。
注意事項と現時点の制限
ストリーミング時の一時停止
アドバイザーの出力はストリーミングされません。
エグゼキューターがアドバイザーを呼び出すと、サブ推論が完了するまでストリームが一時停止します。
ユーザー向けのリアルタイム表示を実装している場合は、この一時停止をUIで適切にハンドリングする必要があります。
「考え中...」のインジケーターを表示するなどの対応が考えられます。
会話レベルの呼び出し上限は自前管理
max_uses は1リクエスト内の上限ですが、会話全体を通じた呼び出し回数の上限は組み込みでは提供されていません。
長時間のエージェントセッションでコストが膨らむリスクがあるため、クライアント側でカウンターを持って管理することをお勧めします。
「月末の請求書を見て青ざめる」を避けるための自衛策として、早めに入れておいたほうが安心です。
Priority Tierの扱い
Priority Tierはモデル別に管理されます。
エグゼキューターに設定したPriority Tierがアドバイザーモデルに自動適用されるわけではありません。
本番環境でレイテンシを気にする場合は、両方のモデルについてPriority Tierを確認しておくのが無難です。
Beta版ステータス
Advisor Toolは現時点でベータ版です。
betaヘッダー advisor-tool-2026-03-01 が必要であることからもわかる通り、APIの仕様は今後変更される可能性があります。
本番導入する場合はAPIバージョニングに注意して、変更に追従できる体制を整えておきましょう。
まとめ -- エージェント設計の新しい選択肢
Claude Advisor Strategyは、「Opusの知能」と「Sonnet/Haikuのコスト効率」を両立するための新しいアプローチです。
ポイントを整理すると以下の通りです。
- Opusをアドバイザー、Sonnet/Haikuをエグゼキューターとして組み合わせる
- 単一の
/v1/messagesリクエスト内で完結する - SWE-bench Multilingualで性能2.7ポイントUP、コスト11.9%削減を実証
tools配列にアドバイザー定義を追加するだけで実装可能max_usesとcachingでコストを細かく制御できる
個人的には、「エージェント全体のコストを下げつつ、判断品質の底上げができる」というのが一番のメリットだと感じています。
特にClaude Codeのようなコーディングエージェントを自社で構築している方にとっては、すぐに検証する価値がある機能ですね。
ベータ版なのでAPIの変更リスクはありますが、仕組み自体は非常にシンプルなので、既存のエージェントに後付けで組み込みやすいはずです。
まずはcurlで動作確認して、手元のエージェントでコストと品質がどう変わるか確かめてみてください。
5分あればすぐ試せます。
- 4
- 0

日系メガベンチャー → 外資系ITプログラマー → ベンチャーCTOを経て独立。 現在はAI駆動でコードを読まずに開発しています。
クリエイターの他の記事
-
コードを読まないAIエンジニア
- 35
- 1
-
- 26
- 1
-
- 11
- 1
-
- 9
- 0




こちらもおすすめ
-
AI脱社畜
- 3
- 0
-
プロンプト画伯
- 3
- 0
-
- 3
- 0
-
 たく
たく
- 1
- 0
-
- 3
- 0
-
- 2
- 0
-
- 2
- 0
-
たく
- 4
- 0
-
 AI経営者の参謀@ひで
AI経営者の参謀@ひで
- 3
- 0
-
- 1
- 0
-
- 3
- 1
-
- 3
- 0
-
- 3
- 0
-
- 4
- 0
-
 カイ@プロダクトマネージャー
カイ@プロダクトマネージャー
- 3
- 0
-
- 3
- 0
-
 AI集客@ルイ
AI集客@ルイ
- 5
- 1
-
- 9
- 0
-
- 4
- 0
-
- 5
- 0
















AimanaVo
あなたのAI知見も、資産にしませんか?
読んだ・試した・気づいた — そんな体験が誰かの力になる。 有料記事で収益化も、アフィリエイトも。
💬 コメント
ログイン か 会員登録 するとコメントできます